
19 Sep 2025
Great news from our #socialmedia team!
🚀 We’re excited to share that #JOHD is now on @LinkedIn!
Managed by our @mik_cil 👏
Follow us to stay updated on:
🔹 New papers
🔹 Call for papers
🔹 News about #OpenData
👉 tinyurl.com/35cv9eu5
#OpenScience #HumanitiesData #LinkedIn

3
5
337
19 Aug 2025
#johdnews from #YouTube 📢
You can now watch the talk that our editor-in-chief @BarbaraMcGilli gave last year at the @uccmainlibrary in Cork!
You will hear about #DataPapers, #HumanitiesData and #openaccess 📺
Find it here➡️youtu.be/2jCz42lwngk?si=smoJ…
2
3
533
#johdnews
We have (slightly) changed our paper formats:
1⃣ #datapaper👉1000-1500 words about a humanities research object with high reuse potential
2⃣ #discussionpaper👉3000-5000 words about creation, collection, management, etc. of #humanitiesdata
Info shorturl.at/jEucO

1
4
286

7 Jan 2025
⏳ Deadline Approaching! Submit your proposal to the International Conference on Data Ethics for Historical Research in a Digital Era by 19 January 2025. Details here: ieg-dhr.github.io/Data-Ethic… #DataEthics #DigitalHistory #History #HumanitiesData #CFP

3
5
400

29 Mar 2024
Please visit Memoirs of Girlhood en la Frontera to see the amazing work done by two UTSA students, Ramirez and Felisha Bocanegra.
Visit the site here: memoirsenlafrontera.omeka.ne…
#BorderlandsDH #PublicDigitalHumanities
#DigitalHistory #HumanitiesData #DataAnalysis

1
2
115
27 Mar 2024
▶️ Read about the launching of CEDISH here, written by Germaine Age Williams: lib.utsa.edu/cedish/news/uts…
#utsaDH #utsaCEDISH #utsacolfa #utsastudents #utsalanguages #utsaenglish #MultilingualDH #BorderlandsDH #PublicDigitalHumanities
#DigitalHistory #HumanitiesData #DataAnalysis

1
1
74
1 Mar 2024
Special thanks to Janet Chavez-Santiago for her enlightening presentation on her digital
We hope to see you again on March 13th for our upcoming CEDISH event – 'Data Wrangling Using OpenRefine' workshop
#PublicDigitalHumanities
#DigitalHistory #HumanitiesData #DigitalLibraries




1
38

9 Feb 2024
Exciting news to round off the working week - some of the #johdteam have won an award for their paper, showing that #datapapers for #humanitiesdata improve the visibility of #datasets, support research articles and add to #openresearch! Congratulations to all involved 🥳 🏆#OA

Great #johdnews 📢
Our paper "Deep Impact: A Study on the Impact of #DataPapers and #Datasets in the Humanities and Social Sciences" has won the Best Paper Award for the 10th Anniversary of @Public_MDPI @MDPIOpenAccess 🥳
👉mdpi.com/about/announcements…
1/3
2
2
6
685
#johdnews
Our editor-in-chief @BarbaraMcGilli will give a keynote presentation about #JOHD at the event "#Datapapers: Maximising potential and getting recognition and rewards for sharing #humanitiesdata"
📅March 6
⏰11:00-14:30 UK time
Info®istration👉libcal.ucc.ie/event/4108454
1
9
19
1,641
30 Jan 2024
The paper is part of our special collection "Representing the Ancient World through data"! Find all the other papers in the collection at rb.gy/x16pk1
#AncientWorld #HumanitiesData #DigiClass


3
122
22 Dec 2023
🎄 The #johdteam wishes you all a happy holiday season!🌟
As the year comes to a close, we want to express our gratitude for supporting us and our efforts in making #humanitiesdata OPEN 📚✨
Happy holidays everyone and here's to an inspiring 2024! 🎉
9
244
20 Jul 2023
#johdsuggestions
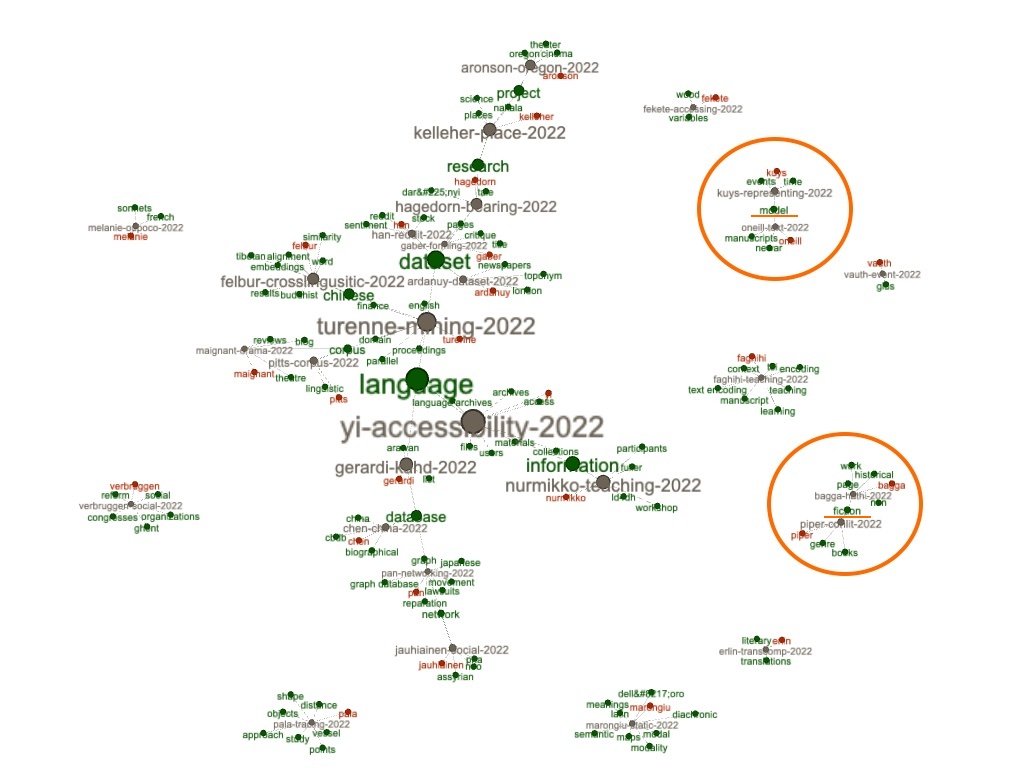
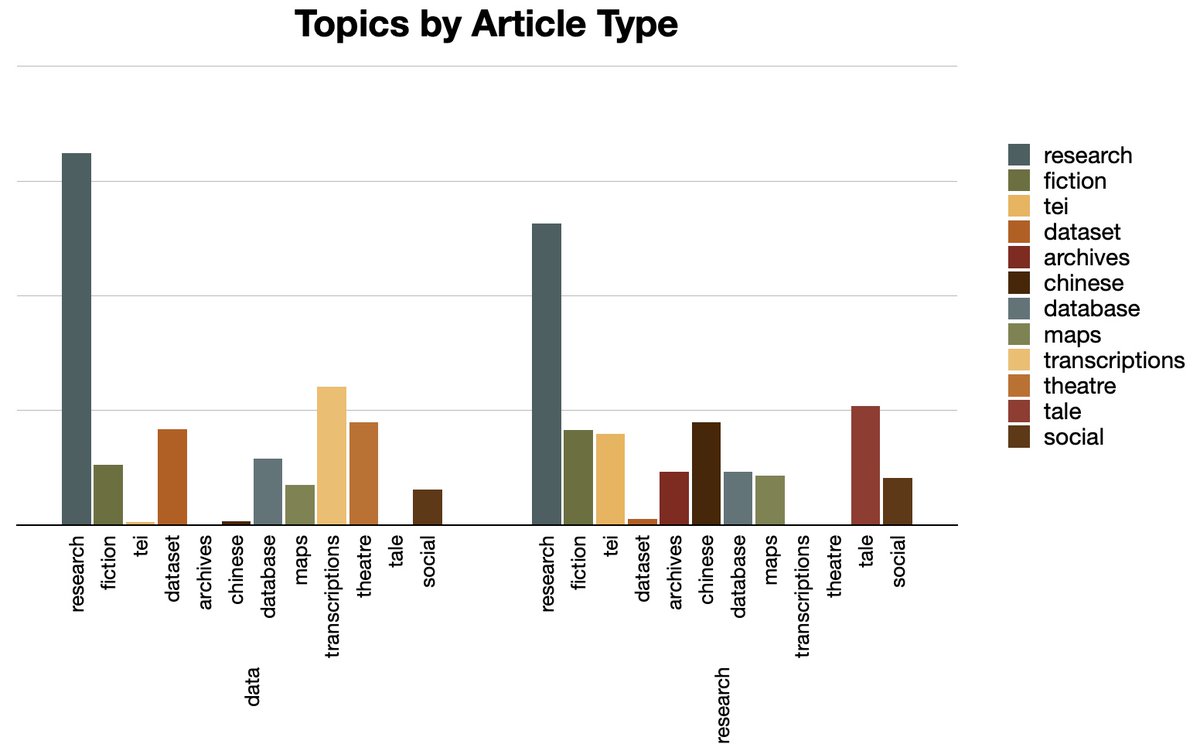
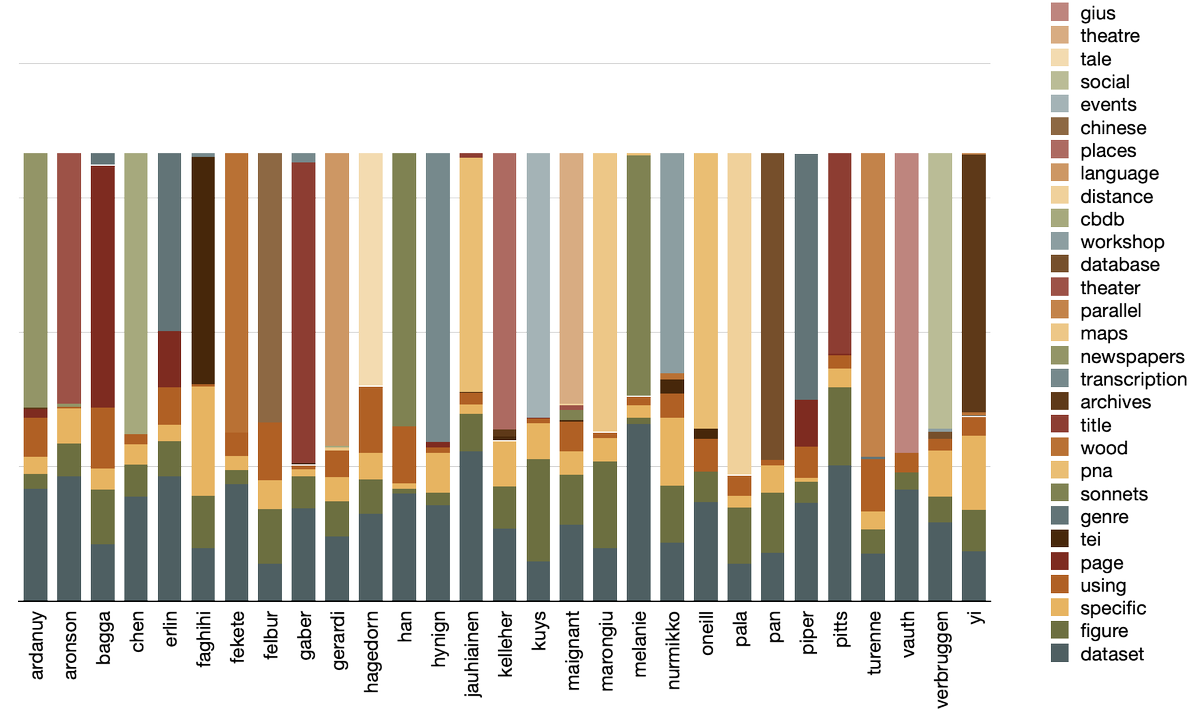
@ericleasemorgan has performed an interesting analysis of our publications by applying his @ReaderDistant tool to #JOHD papers published in 2022! 👏
Read all about it at👉 distantreader.org/stacks/car…
Thank you Eric for valuing our work! 🙏
#opendata #humanitiesdata
2
4
509

8 Jun 2023
Seen at yesterday posters session of #DARIAH2023 #DARIAHAE 😆 So True, isn't it? What do you think? #Humanists #humanities #data #datasteward #humanitiesdata #research #SSH

2
3
14
972

8 May 2023
Exploring the idea of hosting an online workshop on working with IIIF for research and outreach - for UCC researchers. Hope our researchers are as excited about this as I am! iiif.io/ #DigitalContent #Manuscripts #HumanitiesData
2
2
438

7 Oct 2022
wait, your library has all the data via API? i thought the API only goes back to 2008! that would be incredible.
or do you mean as like scans of actual pages of the Times?
7 Oct 2022
yeah i would have loved to do a paperback scrape but i have yet to find a comprehensive digitized source. the differences between the lists are very interesting even just for those years available via the NYT API
1
7 Oct 2022
not to be too much of a self-booster but yes, this is the correct answer! to my knowledge it has author, title, and date for every single hardcover fiction bestseller over the whole life of the NYT list, though there are probably a few uncaught scraping errors
1
5

5 Oct 2022
I'll be part of a panel discussion on Open Data for HSS next week, 13 October - not just discussing the challenges, but what happens when data is shared and can be reused!
Please join us!
think.taylorandfrancis.com/o… #humanitiesdata #opendata #openscience #hssdata
3
9
17

25 Sep 2022
Yup: rest assured, schmaltz holds a place of honor in my fridge. Same jar.
2
22 Sep 2022
I'm joining #OASPA2022 poster session 3 at 12 to talk about developing an Open Data policy that works for authors in the humanities 👇🏻
#opendata #openscience #humanitiesdata @f1000 @tandfnewsroom

ALT Poster describing the challenges of data sharing for humanities authors, the extent to which these authors are interested in sharing data, and the variety of sources used by authors in the humanities.
1
7
14