
📢#MDPIfutureinternet | Highly Cited Articles in #MachineLearning
📝 Future Internet Applications in Healthcare: Big Data-Driven Fraud Detection with #MachineLearning
🔗 mdpi.com/1999-5903/17/10/460
#artificialintelligence #healthcarefrauddetection #imbalanceddata
@ComSciMath_Mdpi

17
SMOTE y la falsa sensación de balanceo
💥𝗥𝗼𝗺𝗽𝗶𝗲𝗻𝗱𝗼 𝗺𝗶𝘁𝗼𝘀 𝗲𝗻 𝗠𝗟: 𝗲𝗹 𝗦𝗠𝗢𝗧𝗘 𝘆 𝗲𝗹 𝘀𝘂𝗯𝗺𝘂𝗲𝘀𝘁𝗿𝗲𝗼 podrían estar 𝗮𝗿𝗿𝘂𝗶𝗻𝗮𝗻𝗱𝗼 𝘁𝘂𝘀 𝗺𝗼𝗱𝗲𝗹𝗼𝘀
#stats #estadistica #cienciadedatos #ML #machinelearning #datascience #AI #imbalanceddata

3
6
34
2,615

19 Nov 2025
Spectra: Spectral Target-Aware Graph Augmentation for Imbalanced Molecular Property Regression
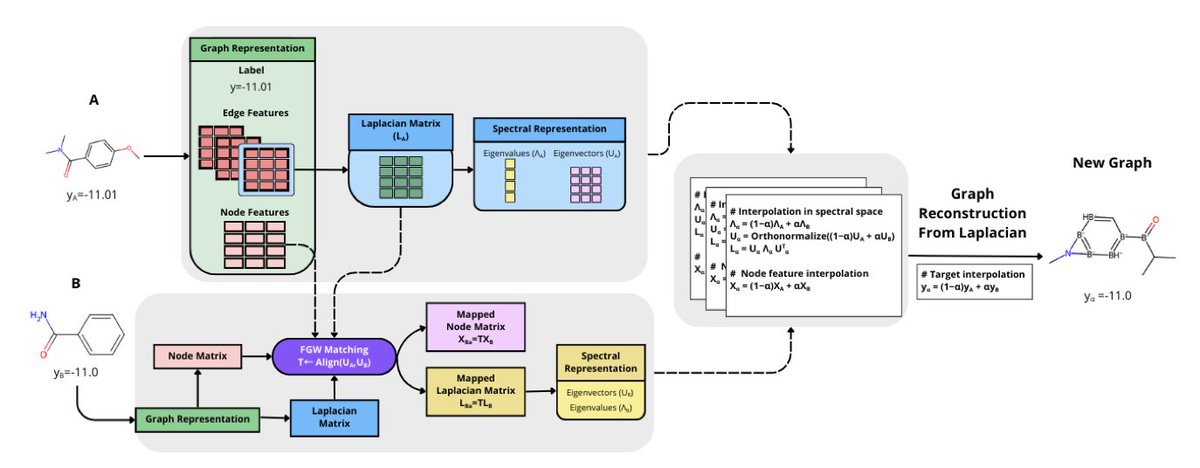
1. The paper introduces SPECTRA, a novel framework designed to address the challenge of imbalanced molecular property regression using spectral graph augmentation. This method leverages the spectral domain to generate realistic and chemically valid molecular graphs, specifically targeting underrepresented regions in the data.
2. A key innovation is the use of spectral alignment and interpolation. SPECTRA aligns molecular graphs via Gromov–Wasserstein couplings and interpolates Laplacian eigenvalues and node features in a shared basis. This process ensures that the generated molecules are structurally coherent and chemically plausible.
3. The rarity-aware budgeting scheme is another highlight. By estimating label density using kernel density estimation, SPECTRA focuses augmentation efforts on data-sparse regions, thereby improving model performance in critical but rare target areas without degrading overall accuracy.
4. SPECTRA achieves state-of-the-art results on benchmark datasets such as ESOL, FreeSolv, and Lipo. It consistently improves error rates in relevant target ranges while maintaining competitive overall mean absolute error (MAE). The synthetic molecules generated are interpretable and reflect the underlying spectral geometry.
5. The method combines spectral graph neural networks with edge-aware Chebyshev convolutions, providing an efficient and interpretable solution. SPECTRA demonstrates a favorable trade-off between accuracy and computational efficiency, outperforming transformer-based models in terms of runtime while maintaining high predictive performance.
📜Paper: arxiv.org/abs/2511.04838
#MolecularPropertyPrediction #GraphNeuralNetworks #SpectralMethods #ImbalancedData #ComputationalBiology
3
6
902

28 Aug 2025
Imbalanced datasets can mess with your ML models. 😬
ADASYN (Adaptive Synthetic Sampling) to the rescue! 🚀
Learn how it works when to use it in our latest blog 👇
f.mtr.cool/rqstrumpnx
#MachineLearning #DataScience #ImbalancedData #ADASYN
3
100

23 Jul 2025
Full access to the paper is available here:
👉 rdcu.be/euyMS
and here the main page:
👉link.springer.com/article/10…
#MachineLearning #ImbalancedData #DataComplexity #Sampling #AIResearch #HARS #ComplexityMeasures
3
3
104

9 Mar 2025
💥 Rompiendo mitos en el aprendizaje automático: ¿Las correcciones para el desequilibrio de clases como SMOTE y el submuestreo aleatorio podrían estar perjudicando a tu modelo en lugar de ayudarlo? 🤯 👇🧵
#MachineLearning #DataScience #AI #SMOTE #ImbalancedData #MLResearch

2
4
17
2,474

16 Oct 2024
Stop oversampling! Changing the cutoff in probabilistic classifiers is enough for imbalanced data.
In our new paper, Gabriel O. Assunção, Marcos O. Prates, and I explore this in depth. jds-online.org/journal/JDS/a…
#DataScience #MachineLearning #ImbalancedData #AI #Oversampling


1
4
17
1,466
4 Sep 2024
Are you curious 🤔about which calibration methods perform best with #imbalanceddata?
This article is a 𝗺𝘂𝘀𝘁-𝗿𝗲𝗮𝗱 📄. It compares various calibration methods across datasets with different imbalance ratios. ieeexplore.ieee.org/document…
#MachineLearning #DataScience
1
1
4
144
31 Aug 2024
Overview of the methods that we can use to work with imbalanced data 👇
More info and 🐍Python code in my course 🌐(buff.ly/3EKLyGh).
#machinelearning #imbalanceddata
1
198

11 Aug 2024
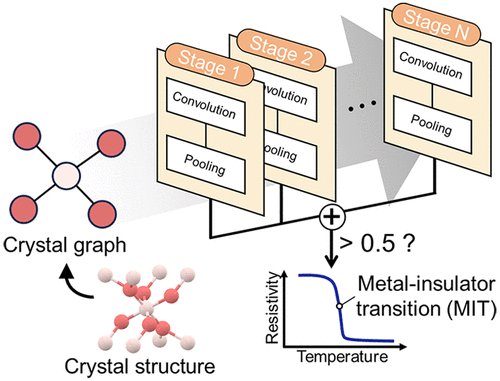
Boosting–Crystal Graph Convolutional Neural Network for Predicting Highly Imbalanced Data: A Case Study for Metal–Insulator Transition Materials
Dive more here: lnkd.in/gzTjMWyC
#MachineLearning #DeepLearning #NeuralNetworks #GraphConvolutionalNetworks #ImbalancedData #AI
3
110

8 Jul 2024
🔬📄I’m thrilled to announce that my latest research paper on Data-Centric Federated Learning for Anomaly Detection in Smart Grids is now available on IEEE Xplore!
🔗 doi.org/10.1109/NOMS59830.20…
#smartGrid #anomalyDetection #imbalancedData #causalInference #federatedLearning
3
879

1 May 2024
In a typical 'self-help' book on data science, the foremost suggestion is often to... gather more data.
How brilliant! In reality, if acquiring more data was that simple, there wouldn't be a need for 'self-help' data science guides.
Why not also suggest we ask a few more clients to fail on their repayments? Sounds feasible, doesn't it?
The third piece of advice, which is the most emphasized when it comes to model development, unfortunately recommends... the least effective strategy.
Why is this strategy the least effective? Mainly because it does nothing to improve the essential metrics.
Moreover, it compromises calibration, making the classification model entirely ineffective for decision-making.
#imbalanceddata #smote

1
624
13 Jan 2024
Excellent points about #smote. The misguided smote paper that was cited by academia over 25k times tested smote on two ancient methods c4.5 and a methods aptly called “Ripper”.
The modern data science methods such as boosted trees are not improved by smote.
#imbalanceddata #smote

1
5
910
13 Jan 2024
Pay attention to what elite data scientists are saying about imbalanced classes - in particular point 8 and point 9.
#calibration #imbalanceddata
13 Jan 2024

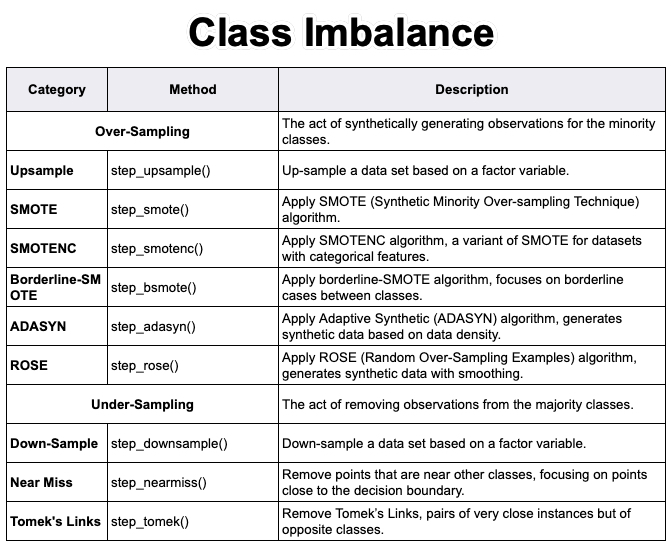
Class imbalance is a common problem in machine learning. Here's 2 years of knowledge in 2 minutes. Let's go!
1. Class imbalance: Class imbalance is a common problem in machine learning, especially in the context of classification tasks. It occurs when the number of instances of one class (or multiple classes) in a dataset is significantly higher or lower than those of the other classes.
2. Model Bias: The learning model may become biased towards the majority class, leading to poor performance on the minority class. For example, if you're building a fraud detection system and non-fraudulent transactions greatly outnumber fraudulent ones, the model might lean towards predicting non-fraud most of the time.
3. Evaluation Metrics Misleading: Traditional metrics like accuracy can be misleading. In the fraud detection example, a model that always predicts 'non-fraud' might appear highly accurate but is useless.
4. Overfitting to Majority Class: Models might overfit to the majority class and fail to capture the characteristics of the minority class.
5. Addressing Class Imbalance: To address class imbalance, various strategies are used, such as:
6. Undersampling/Oversampling: Balancing the dataset by undersampling the majority class or oversampling the minority class.
7. Synthetic Data Generation: Using techniques like SMOTE (Synthetic Minority Over-sampling Technique) to generate new, synthetic examples of the minority class.
8. Why I DO NOT Adjust for Class Imbalance: One problem with adjusting the class imbalance is that you are altering the data. Applying "Model Calibration" to the machine learning model is a different technique, adjusting the model's predicted probabilities to reflect the true likelihood of an outcome better.
9. Model Calibration: Some common methods for calibrating models are Platt Scaling, Isotonic Regression, and Ensemble Calibration. I'll cover these in another post soon!
You now know more about Class Imbalance. But, there's a lot more to learn to become an elite business data scientist.
===
Ready to learn Data Science for Business?
I put together a free on-demand workshop that covers the 10 skills that helped me make the transition to Data Scientist: learn.business-science.io/fr…
And if you'd like to speed it up, I have a live workshop where I'll share how to use ChatGPT for Data Science: learn.business-science.io/re…
If you like this post, please reshare ♻️ it so others can get value.
4
29
3,890
20 Sep 2023
Deep diving into imbalanced data while writing the chapter for my book, 'Practical Guide to Applied Conformal Prediction: Learn and apply the best uncertainty frameworks to your industry applications' (available here: a.co/d/8RF7eLR), was an enlightening journey.
The pitfalls data science has encountered, especially with the promotion of techniques like #smote, proved profound. It took weeks to sift through the information and discern the valuable insights from the noise.
Regrettably, many methods, including #smote, not only underperform but have consistently done so.
On a brighter note, conformal prediction offers a promising solution to the challenges of imbalanced classification. It also presents a remedy to the flawed outcomes produced by techniques such as smote.
This chapter promises to be a treasure trove, brimming with insights about machine learning for imbalanced data and the revolutionary solutions that conformal prediction brings to the table.
Just one more chapter to go!
#imbalanceddata
#classification #conformalprediction

3
8
39
6,044
20 Sep 2023
Got convinced that #smote is bad (good!) but still think that other resampling methods are 'ok'?
Below are the results from applying resampling methods on highly imbalanced dataset where 'doing nothing' produces great results.
After applying resampling methods:
* smote destroys calibration
* RandomOverSampler destroys calibration on scale comparable to smote
* RandomUnderSampler, ADASYIN and NearMiss destroy calibration even on bigger scale than smote.
#calibration #imbalanceddata

1
4
2,451
20 Sep 2023
In a typical 'self-help' book on data science, the foremost suggestion is often to... gather more data.
How brilliant! In reality, if acquiring more data was that simple, there wouldn't be a need for 'self-help' data science guides.
Why not also suggest we ask a few more clients to fail on their repayments? Sounds feasible, doesn't it?
The third piece of advice, which is the most emphasized when it comes to model development, unfortunately recommends... the least effective strategy.
Why is this strategy the least effective? Mainly because it does nothing to improve the essential metrics. Moreover, it compromises calibration, making the classification model entirely ineffective for decision-making.
#imbalanceddata #smote

1
8
3,169

18 Sep 2023
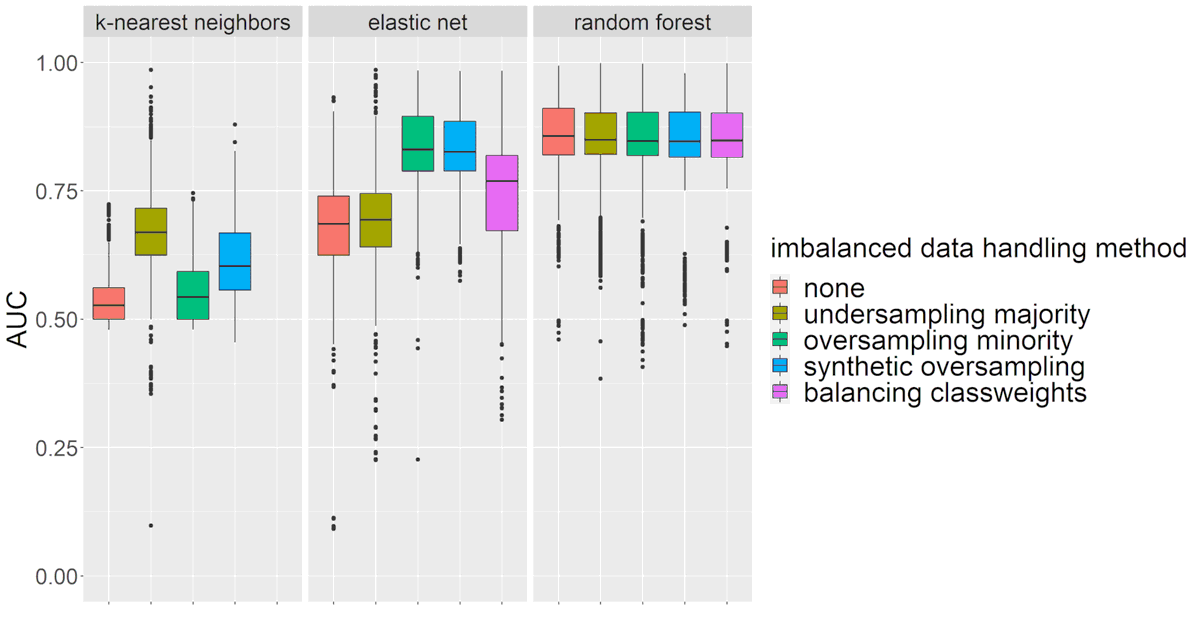
Predictive modeling on routine data for preoperative risk assessment: find out more in our talk today at @gmds2023, 14:45 in N.0.30/N-12: s.fhg.de/p8i
#GMDS2023 #ImbalancedData #MissingData #DataImputation #DataSplitting
1
2
213
12 Sep 2023
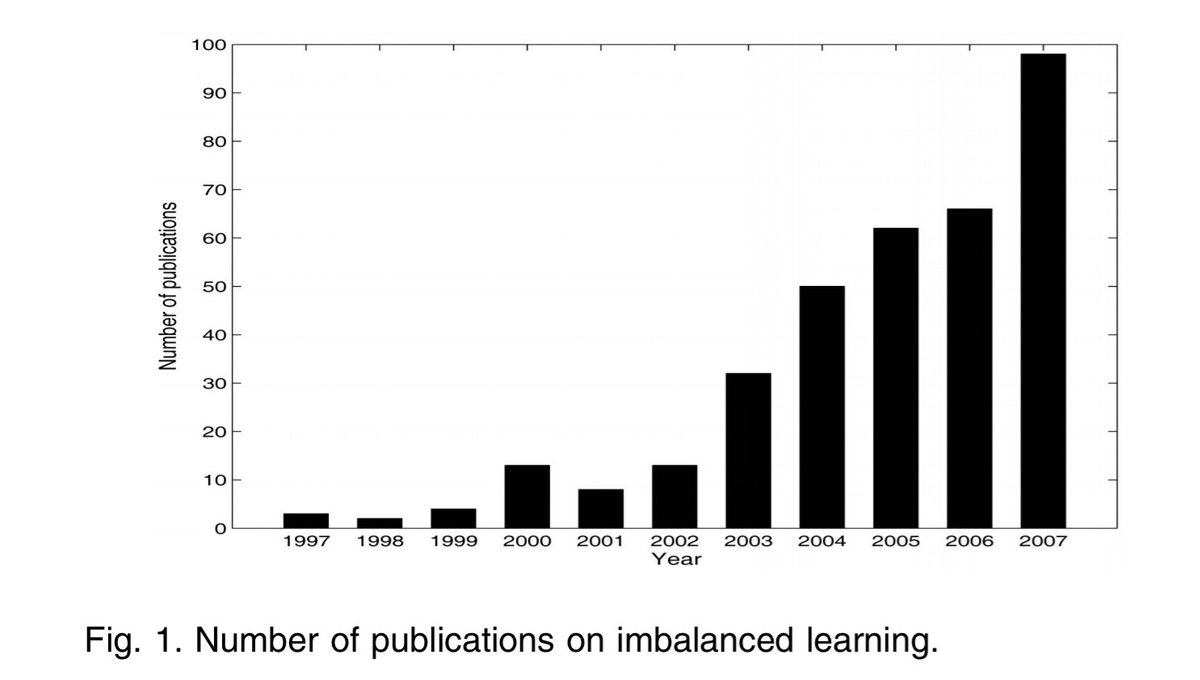
The hype of bygone data mining era, despite the massive number of publications the field has produced basically nothing to show even 15 years after.
#imbalanceddata
2
842

11 Sep 2023
💡 7 innovative techniques for successful analysis: hubs.la/Q021HQ9g0
#ImbalancedData #DataAnalysis #DataScience

6
20
4,001