

May 22
#企業公式相互フォロー
データリーク対策は
「モデル精度を守る技術」であり
「法務リスクを軽減する統制」です。
山崎行政書士事務所では、次を技術チームと伴走:
MLパイプラインのデータ分離(train/test leakage防止)
Cross-validation / Hold-out の適用基準
データの転用可否(契約・プライバシー制約)
Azure ML / Synapse / Data Factory の構成レビュー
Feature Leakage のリスク分析
GDPR Art.5/32 / 個情法との整合性チェック
“モデルの正しさ”と“法務の正しさ”の両立を実現します。
#AIML #データ漏洩 #ModelValidation #FeatureLeakage #ガバナンス

10
82

Mar 31
What makes an #engineering model reliable and reusable? Join this #webinar to explore the three pillars of good modeling—fidelity, sensitivity, and efficiency—and how verification, validation, and traceability help build models you can trust with Dyad. juliahub.com/events/what-mak…
#julialang #Dyad #EngineeringModeling #SystemsEngineering #Simulation #ModelValidation
1
5
285

New collaborative paper #NucleicAcidsResearch @OxfordJournals is out 🇨🇿🇵🇱🇬🇧🇳🇱🇺🇸
New targets and procedures for validating the valence geometry of nucleic acid structures 👇#NucleicAcids #StructuralBiology #PDB #ModelValidation #NAR
academic.oup.com/nar/article…
3
72
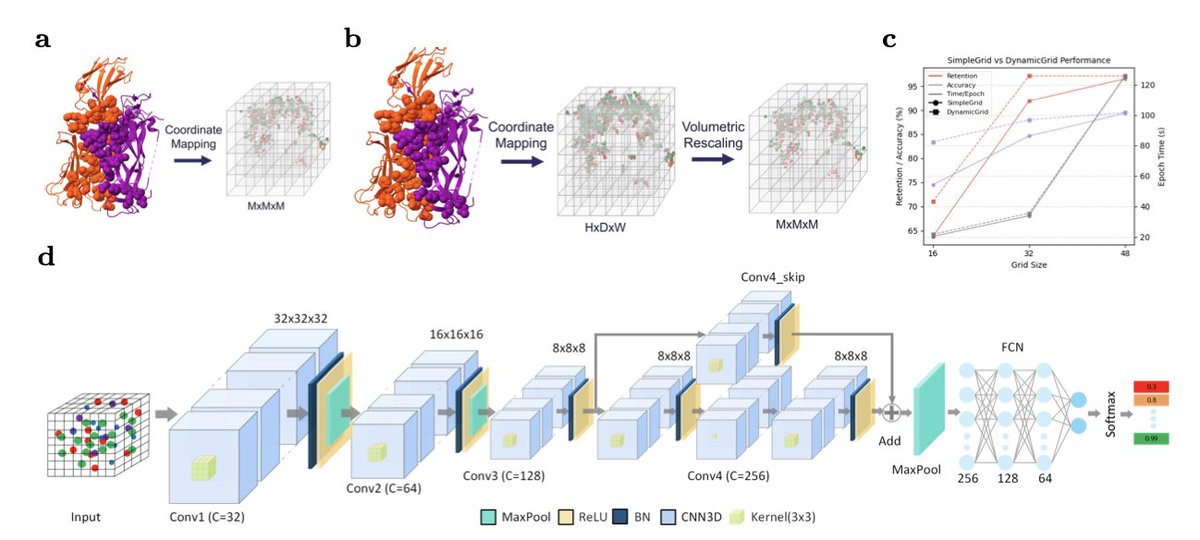
DPI-score: A deep learning-based metric for assessing protein-protein interfaces in cryo-EM derived assemblies
1. A new deep learning-based metric, DPI-score, has been developed to assess the quality of protein-protein interfaces in cryo-EM structures. This metric addresses the gap in existing validation tools by focusing specifically on interfaces rather than overall model quality or fit to density.
2. DPI-score achieves an impressive validation accuracy of 87.53% using only the raw structural coordinates of interface atoms, without requiring any derived features or map information. This makes it a highly efficient and practical tool for large-scale applications.
3. The study introduces a dynamic grid scaling approach to represent protein interfaces in 3D voxel grids. This method adapts grid size based on interface dimensions, balancing information retention and computational efficiency better than fixed-size grids.
4. DPI-score was tested on cryo-EM oligomeric targets from CASP15 and CASP16, as well as fitted models obtained using rigid body fitting methods. It demonstrated superior performance in distinguishing near-native interfaces from a pool of predicted models compared to existing methods.
5. When applied to fitted models in the Electron Microscopy Data Bank (EMDB), DPI-score identified errors at interfaces that were not detected by density-based scores alone, highlighting its value as a complementary validation metric.
6. The DPI-score model is available for academic use on GitLab, making it accessible for researchers to integrate into their cryo-EM model validation workflows.
📜Paper: biorxiv.org/content/10.64898…
💻Code: gitlab.com/ccpem/dpi
#CryoEM #ProteinInterfaces #DeepLearning #ModelValidation #StructuralBiology
1
24
2,014

Jan 15
A healthier financial ecosystem starts with making high-level compliance accessible to everyone.
We’re honored to see Yanez Compliance featured by the Coalition Against Financial Crime (CAFC) in their latest practitioner’s guide. By removing the technical barriers to model validation, we are enabling broader adoption across both regulated and non-regulated entities.
When we reduce the time and effort required for rigorous validation, we don’t just help individual firms, we strengthen the entire industry.
Read the full guide on why validation is the key to a safer financial system:
cafc.org/post/sanctions-scre…
#FinancialCrime #AML #ModelValidation #FinTech #Compliance #CAFC #Yanez #RegTech
2
7
21
2,156

15 Oct 2025
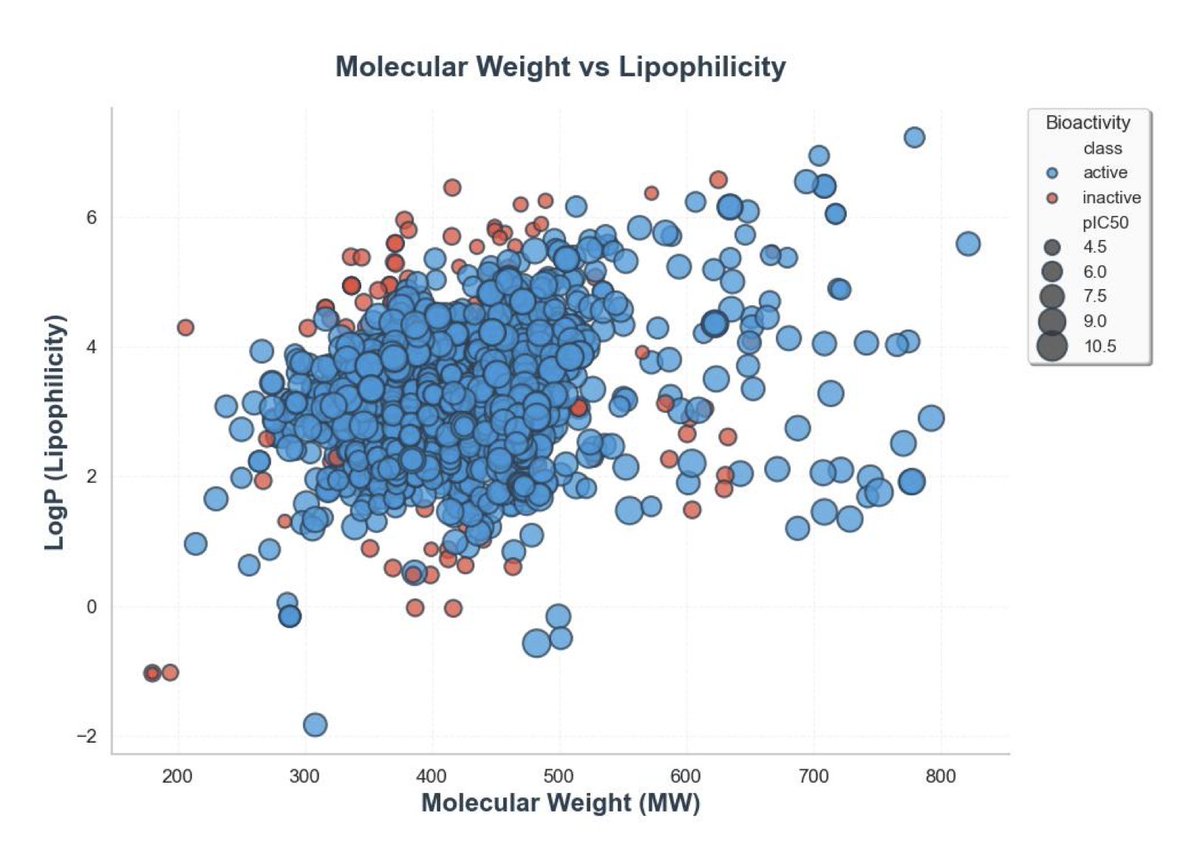
Scaffold-Aware Machine Learning QSAR Models for Adenosine A2A Receptor Ligands: Addressing Overfitting Through Rigorous Validation
1. This study presents a novel approach to developing QSAR models for adenosine A2A receptor ligands, focusing on addressing overfitting through rigorous scaffold-aware validation. The authors curate a dataset of 1,730 ligands with a wide range of IC50 values and demonstrate that conventional random splitting can significantly overestimate model performance by around 40% due to scaffold leakage.
2. The researchers introduce a scaffold-based splitting strategy combined with descriptor augmentation, incorporating RDKit properties and ECFP4 fingerprints. This method significantly improves model generalization, achieving an external test R2 of 0.66 and an RMSE of 0.64 log units, which is comparable to experimental assay noise.
3. The study highlights the importance of scaffold-based validation in QSAR modeling, showing that it is indispensable for obtaining reliable performance metrics. Random splitting inflated apparent performance, while scaffold splitting provided a more accurate assessment of the model's ability to generalize to new chemotypes.
4. Feature importance analysis reveals that fingerprint bits encoding adenine-like heteroaromatics dominate, while classical descriptors such as TPSA, MolLogP, and hydrogen-bond acceptors also contribute significantly. This indicates that both local substructural patterns and global physicochemical properties are essential for predictive performance.
5. The authors conduct extensive cross-validation experiments, finding that while increasing the number of scaffold partitions from 5 to 284 narrows confidence intervals, the absolute performance gain is minimal. This suggests that the performance limitations are due to the intrinsic constraints of two-dimensional molecular representations.
6. The optimized QSAR model is suitable for virtual screening enrichment but not for fine-grained lead optimization. The study concludes that transformative improvements in A2AR QSAR performance will likely require three-dimensional representations or graph neural network architectures that capture binding geometry and receptor-ligand interactions.
📜Paper: doi.org/10.26434/chemrxiv-20…
#QSAR #MachineLearning #AdenosineA2AReceptor #DrugDiscovery #ModelValidation #ScaffoldSplitting #FeatureImportance #VirtualScreening
5
788

26 Sep 2025
💡 Mi regla personal: Si no puedo explicar por qué funciona mi modelo a mi abuela, entonces yo mismo no lo entiendo lo suficiente.
¿Cuál de estas preguntas te resulta más difícil de responder? 👇
#ModelValidation #Analytics #BusinessIntelligence #MachineLearning #ML #Modeling
3
639
8 Sep 2025
7️⃣ NO implica causalidad
Alto R² no significa que X cause Y. Cuidado con las interpretaciones.
8️⃣ NO necesitas un valor de R² específico para interpretar tu modelo.
#ModelValidation
1
3
146

16 Aug 2025
We continue our journey on the #Grow360 #Accelerator #Program (GAP), and this week’s focus was all about #Business #Model #Validation and #Innovation.
#GrowAfricaForMe #GROW360Accelerator #BusinessInnovation #ModelValidation #SMEGrowth #Entrepreneurship #ImpactDrivenBusiness
2
3
51

14 Aug 2025
Unlock the true potential of your AI models with @FractionAI_xyz's trustless evaluation framework. Ensure your models are robust and reliable. #AIEvaluation #ModelValidation

1
1
3
34

12 Aug 2025
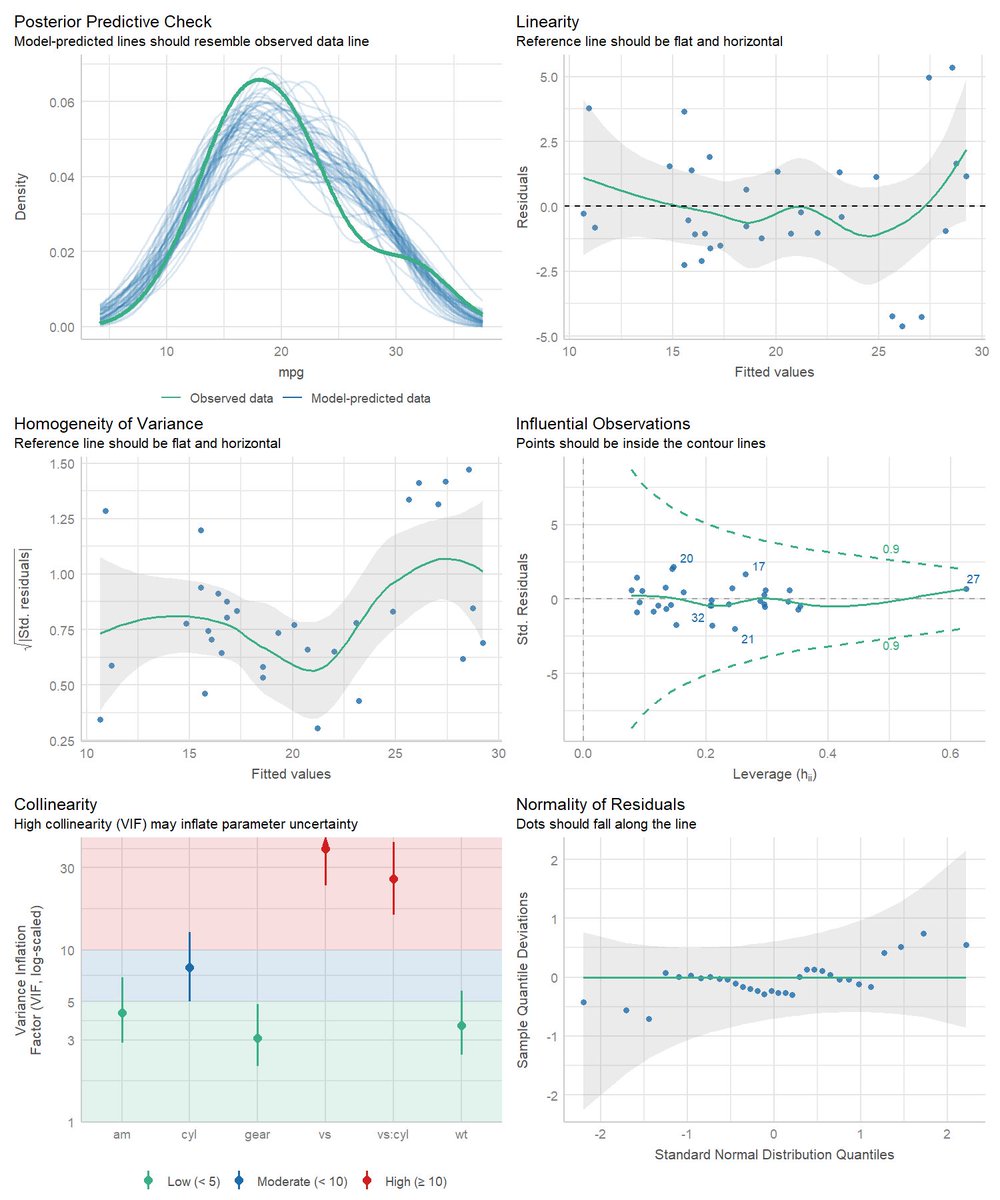
Ensuring a model’s performance isn’t just about building it — it’s about validating it thoroughly. This resource offers practical guidance for diagnosing regression models in R, helping you avoid common pitfalls and save time.
Thank you @RosanaFerrero for sharing this valuable tool.
#DataScience #RStats #RegressionAnalysis #ModelValidation
12 Aug 2025

📊 ¿Cómo sabes si tu modelo realmente funciona bien?
Muchos modelos se publican... pero pocos se diagnostican a fondo.
Si usas modelos de regresión en R, este recurso te va a ahorrar tiempo y sustos 🚨👇
#DataScience #RStats #stats #dataviz #modelling #regression #CienciaDeDatos
6
43
2,939
6 Aug 2025
What a great week so far. Another public multibillion dollar organization that becomes a client. One of the largest asset managers in the world looking to ensure their sanctions screening system is working properly, and streamlining their model validation so they can provide regulators proof of their compliance program. An otherwise multi-month effort reduced to hours thanks to our product and technology. The output of SN54 is very close to be the fuel to these important programs. We'll continue to focus in bringing real clients and solve real problems. That's the key to the success of SN54.
#FocusOnRevenue #SN54 #SanctionsScreening #ModelValidation #RegTech
11
19
77
12,621

🚀 Excited for the #AIVille x #SaharaAI AMA! Join at 4AM UTC/9PM PDT to dive into #DSPTaskBreakdown & #ModelValidation. Win $AIV $SAHARA tokens! Big props to @VitalikButerin, @cz_binance, @brian_armstrong for inspiring this #Blockchain & #AI fusion. Shape the future of #Web3

4
161

30 Jul 2025
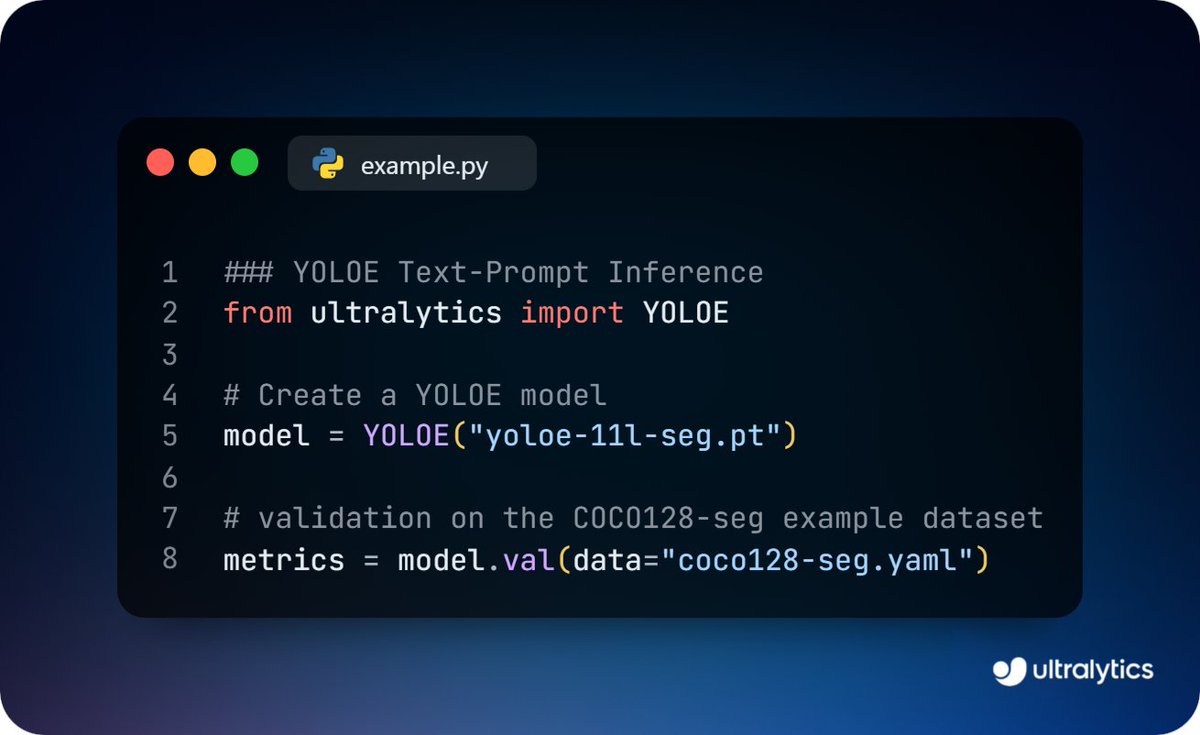
Validate YOLOE models with a single command using Ultralytics!
Run the model.val method on segmentation datasets like COCO128-seg and get precision, recall, and mAP to evaluate your model's performance.
Learn more ➡️ ow.ly/MOts50Wavpz
#YOLOE #ModelValidation #AI
1
1
9
390
29 Jul 2025
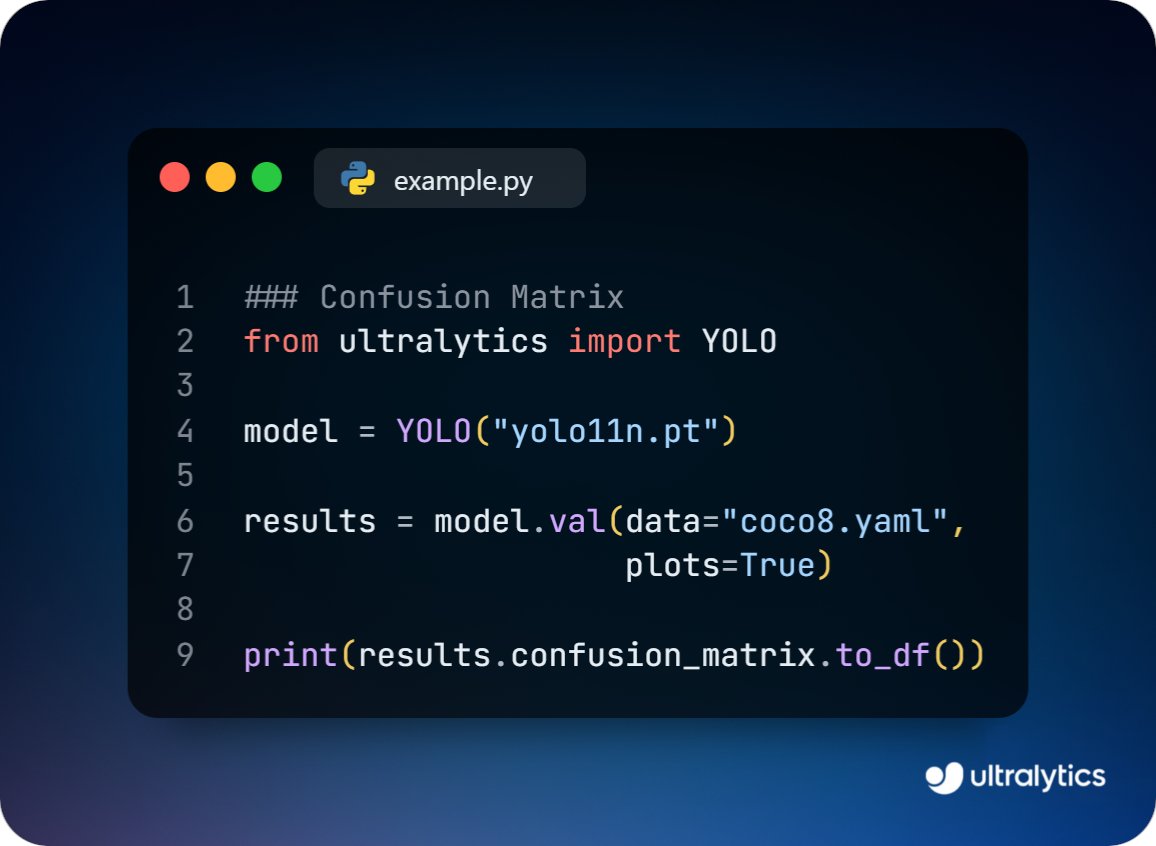
Validate Ultralytics YOLO models and export the confusion matrix!
Just set plots=True during validation and use results.confusion_matrix.to_df() to analyze class-wise performance as a Pandas DataFrame.
Learn more ➡️ ow.ly/98kF50W9UJ4
#ModelValidation #AI
2
7
369

16 Jun 2025
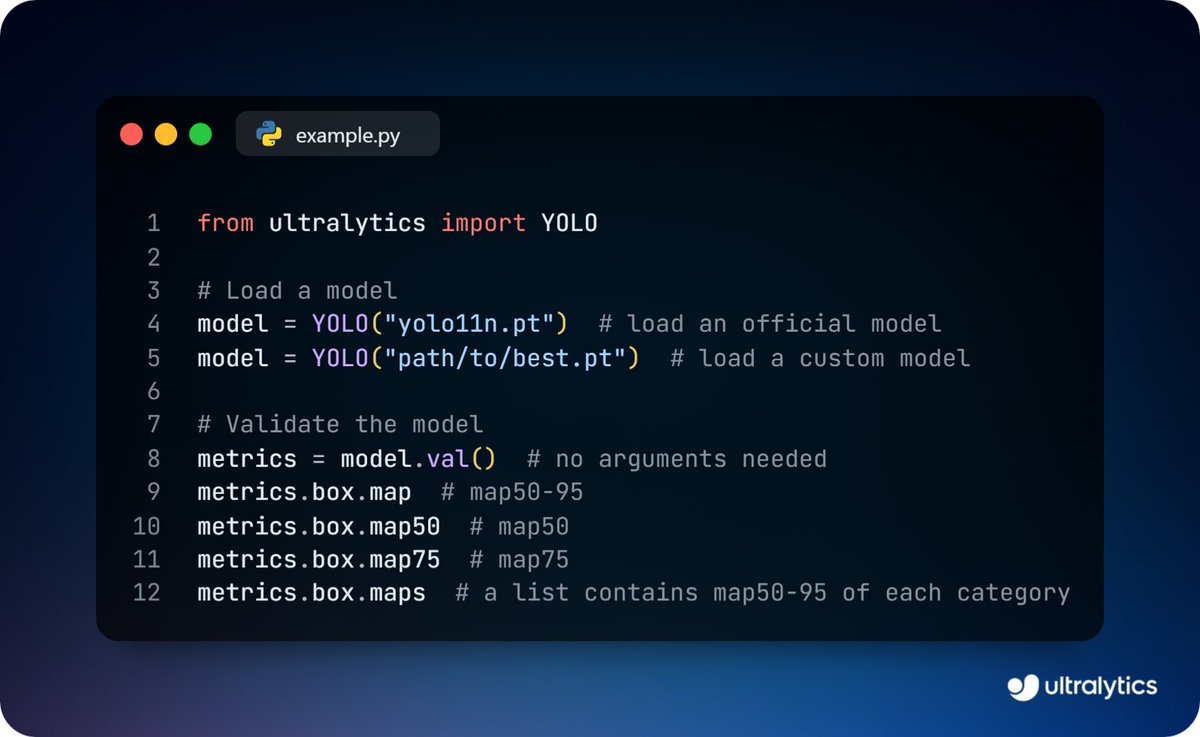
Validate Ultralytics YOLO models!
Measure performance using key metrics like precision, recall, and mean average precision (mAP). These are crucial steps for comparing results and improving model quality.
Learn more ➡️ ow.ly/7Ukz50VSnFs
#ModelValidation #ComputerVision
1
7
352
15 Apr 2025
Rethinking the Generalization of Drug Target Affinity Prediction Algorithms via Similarity Aware Evaluation
1. This paper challenges the prevailing evaluation schemes in drug-target affinity (DTA) prediction, showing that conventional random splits produce over-optimistic results by heavily favoring high-similarity samples in the test set.
2. The authors introduce Similarity Aware Evaluation (SAE), a principled framework for creating test splits with user-defined similarity distributions, enabling more realistic and robust assessments of model generalization to novel compounds.
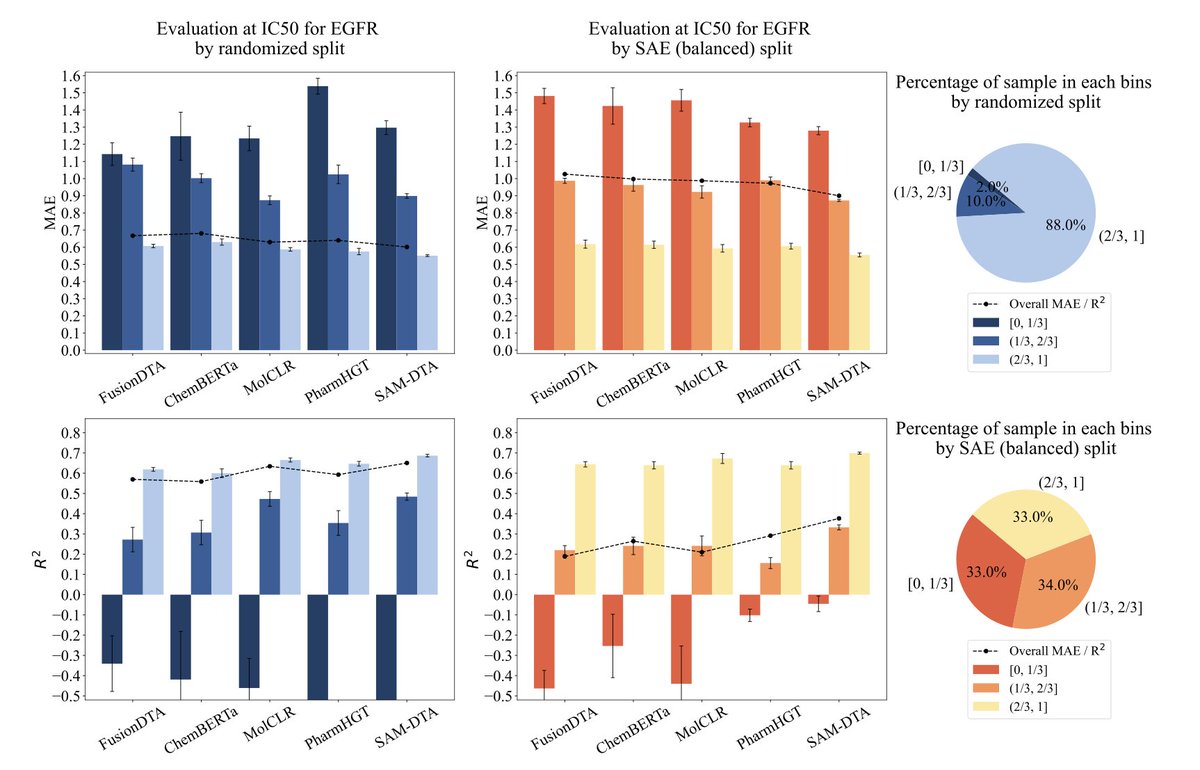
3. In standard random splits, over 88% of test samples are highly similar to the training data. Models like SAM-DTA show sharp performance drops (e.g., R² dropping from 0.65 to -0.64) on low-similarity samples—yet this is hidden in aggregate metrics.
4. SAE formulates test set construction as a constrained optimization problem, using relaxed continuous weights and differentiable approximations of similarity and bin-counting functions, allowing flexible and efficient test set splitting.
5. The authors propose both "balanced splits"—uniform across similarity bins—and "mimic splits" that replicate external test distributions. Both strategies significantly outperform random, scaffold, and SIMPD splits in reflecting real-world generalization.
6. Evaluations across four datasets (EGFR, BACE1, Carbonic anhydrase I/II) and five models (SAM-DTA, PharmHGT, FusionDTA, MolCLR, ChemBERTa) confirm that SAE provides clearer insight into performance degradation across similarity levels.
7. SAE-based splits enable more accurate hyperparameter tuning. Models optimized using mimic splits show improved performance on external datasets compared to those tuned using conventional splits, underscoring its utility in practical deployment.
8. SAE supports additional use cases like generating test sets with predefined maximum similarity (e.g., <0.4 or <0.6), useful for avoiding IP conflicts or targeting novelty in drug screening.
9. The authors open-source their full implementation, providing a PyTorch-based optimizer for test split generation, and demonstrate how SAE can be extended to QSAR, ADMET, protein-protein interaction, and drug-drug interaction prediction tasks.
10. Overall, SAE reframes how generalization in DTA prediction should be evaluated, advocating for similarity-aware testing to ensure models perform reliably when exposed to unfamiliar chemical space.
💻Code: github.com/Amshoreline/SAE
📜Paper: arxiv.org/abs/2504.09481
#drugdiscovery #DTAprediction #machinelearning #QSAR #bioinformatics #generalisability #AIinbiotech #deeplearning #datasetbias #modelvalidation
3
24
1,573
15 Apr 2025
Rethinking the Generalization of Drug Target Affinity Prediction Algorithms via Similarity Aware Evaluation
1. This paper challenges the prevailing evaluation schemes in drug-target affinity (DTA) prediction, showing that conventional random splits produce over-optimistic results by heavily favoring high-similarity samples in the test set.
2. The authors introduce Similarity Aware Evaluation (SAE), a principled framework for creating test splits with user-defined similarity distributions, enabling more realistic and robust assessments of model generalization to novel compounds.
3. In standard random splits, over 88% of test samples are highly similar to the training data. Models like SAM-DTA show sharp performance drops (e.g., R² dropping from 0.65 to -0.64) on low-similarity samples—yet this is hidden in aggregate metrics.
4. SAE formulates test set construction as a constrained optimization problem, using relaxed continuous weights and differentiable approximations of similarity and bin-counting functions, allowing flexible and efficient test set splitting.
5. The authors propose both "balanced splits"—uniform across similarity bins—and "mimic splits" that replicate external test distributions. Both strategies significantly outperform random, scaffold, and SIMPD splits in reflecting real-world generalization.
6. Evaluations across four datasets (EGFR, BACE1, Carbonic anhydrase I/II) and five models (SAM-DTA, PharmHGT, FusionDTA, MolCLR, ChemBERTa) confirm that SAE provides clearer insight into performance degradation across similarity levels.
7. SAE-based splits enable more accurate hyperparameter tuning. Models optimized using mimic splits show improved performance on external datasets compared to those tuned using conventional splits, underscoring its utility in practical deployment.
8. SAE supports additional use cases like generating test sets with predefined maximum similarity (e.g., <0.4 or <0.6), useful for avoiding IP conflicts or targeting novelty in drug screening.
9. The authors open-source their full implementation, providing a PyTorch-based optimizer for test split generation, and demonstrate how SAE can be extended to QSAR, ADMET, protein-protein interaction, and drug-drug interaction prediction tasks.
10. Overall, SAE reframes how generalization in DTA prediction should be evaluated, advocating for similarity-aware testing to ensure models perform reliably when exposed to unfamiliar chemical space.
💻Code: github.com/Amshoreline/SAE
📜Paper: arxiv.org/abs/2504.09481
#drugdiscovery #DTAprediction #machinelearning #QSAR #bioinformatics #generalisability #AIinbiotech #deeplearning #datasetbias #modelvalidation

2
599