
15 Oct 2025
Scaffold-Aware Machine Learning QSAR Models for Adenosine A2A Receptor Ligands: Addressing Overfitting Through Rigorous Validation
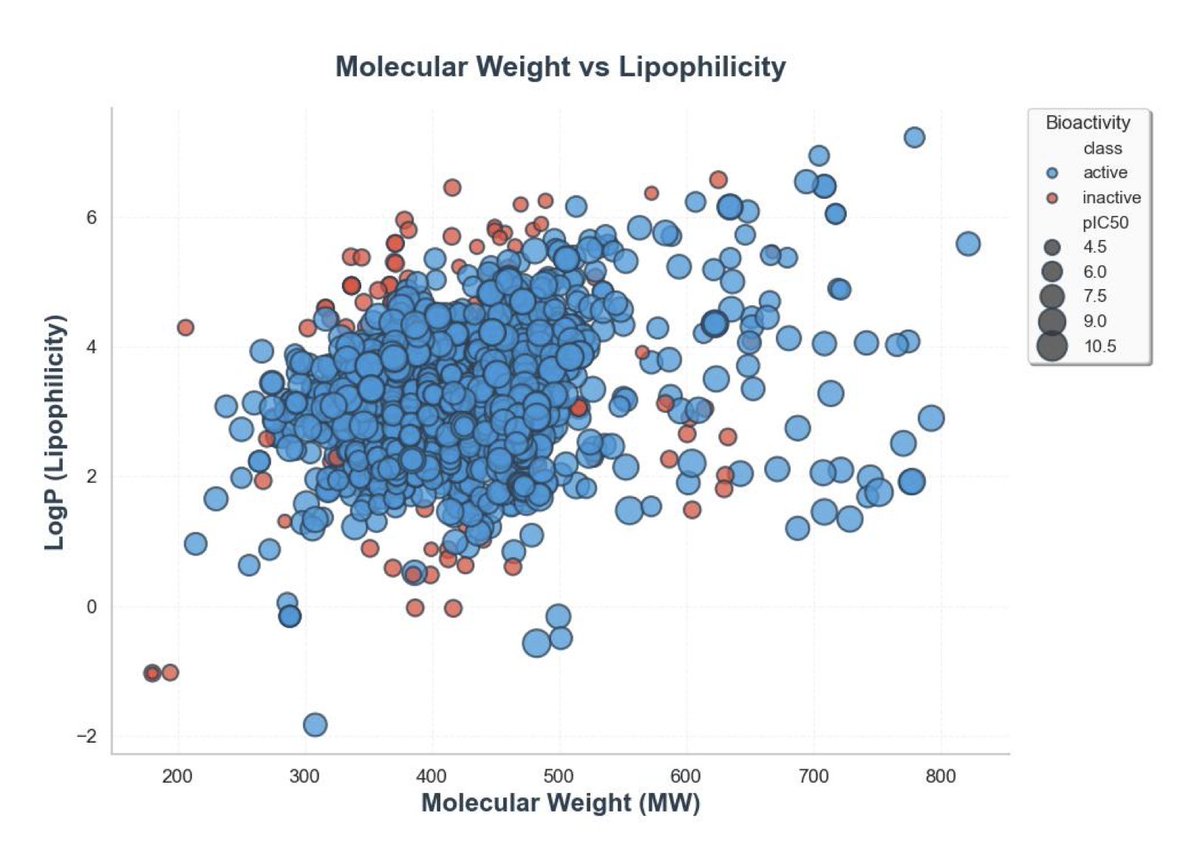
1. This study presents a novel approach to developing QSAR models for adenosine A2A receptor ligands, focusing on addressing overfitting through rigorous scaffold-aware validation. The authors curate a dataset of 1,730 ligands with a wide range of IC50 values and demonstrate that conventional random splitting can significantly overestimate model performance by around 40% due to scaffold leakage.
2. The researchers introduce a scaffold-based splitting strategy combined with descriptor augmentation, incorporating RDKit properties and ECFP4 fingerprints. This method significantly improves model generalization, achieving an external test R2 of 0.66 and an RMSE of 0.64 log units, which is comparable to experimental assay noise.
3. The study highlights the importance of scaffold-based validation in QSAR modeling, showing that it is indispensable for obtaining reliable performance metrics. Random splitting inflated apparent performance, while scaffold splitting provided a more accurate assessment of the model's ability to generalize to new chemotypes.
4. Feature importance analysis reveals that fingerprint bits encoding adenine-like heteroaromatics dominate, while classical descriptors such as TPSA, MolLogP, and hydrogen-bond acceptors also contribute significantly. This indicates that both local substructural patterns and global physicochemical properties are essential for predictive performance.
5. The authors conduct extensive cross-validation experiments, finding that while increasing the number of scaffold partitions from 5 to 284 narrows confidence intervals, the absolute performance gain is minimal. This suggests that the performance limitations are due to the intrinsic constraints of two-dimensional molecular representations.
6. The optimized QSAR model is suitable for virtual screening enrichment but not for fine-grained lead optimization. The study concludes that transformative improvements in A2AR QSAR performance will likely require three-dimensional representations or graph neural network architectures that capture binding geometry and receptor-ligand interactions.
📜Paper: doi.org/10.26434/chemrxiv-20…
#QSAR #MachineLearning #AdenosineA2AReceptor #DrugDiscovery #ModelValidation #ScaffoldSplitting #FeatureImportance #VirtualScreening
5
788

🚨 Article Alert!
Title: FIGS: A Realistic Intrusion-Detection Framework for Highly Imbalanced IoT Environments
Authors: Z. Anbiaee, S. Dadkhah, & A. A. Ghorbani
Repository: Electronics
mdpi.com/2079-9292/14/14/291…
#GenerativeAdversarialNetwork #FeatureImportance #ImbalancedDataset
2
2
48
2 May 2025
OmiXAI: An Ensemble XAI Pipeline for Interpretable Deep Learning in Omics Data
1. OmiXAI is a novel ensemble explainable AI (XAI) pipeline designed for deep learning models applied to multi-omics data, enabling feature attribution that is both biologically meaningful and computationally scalable.
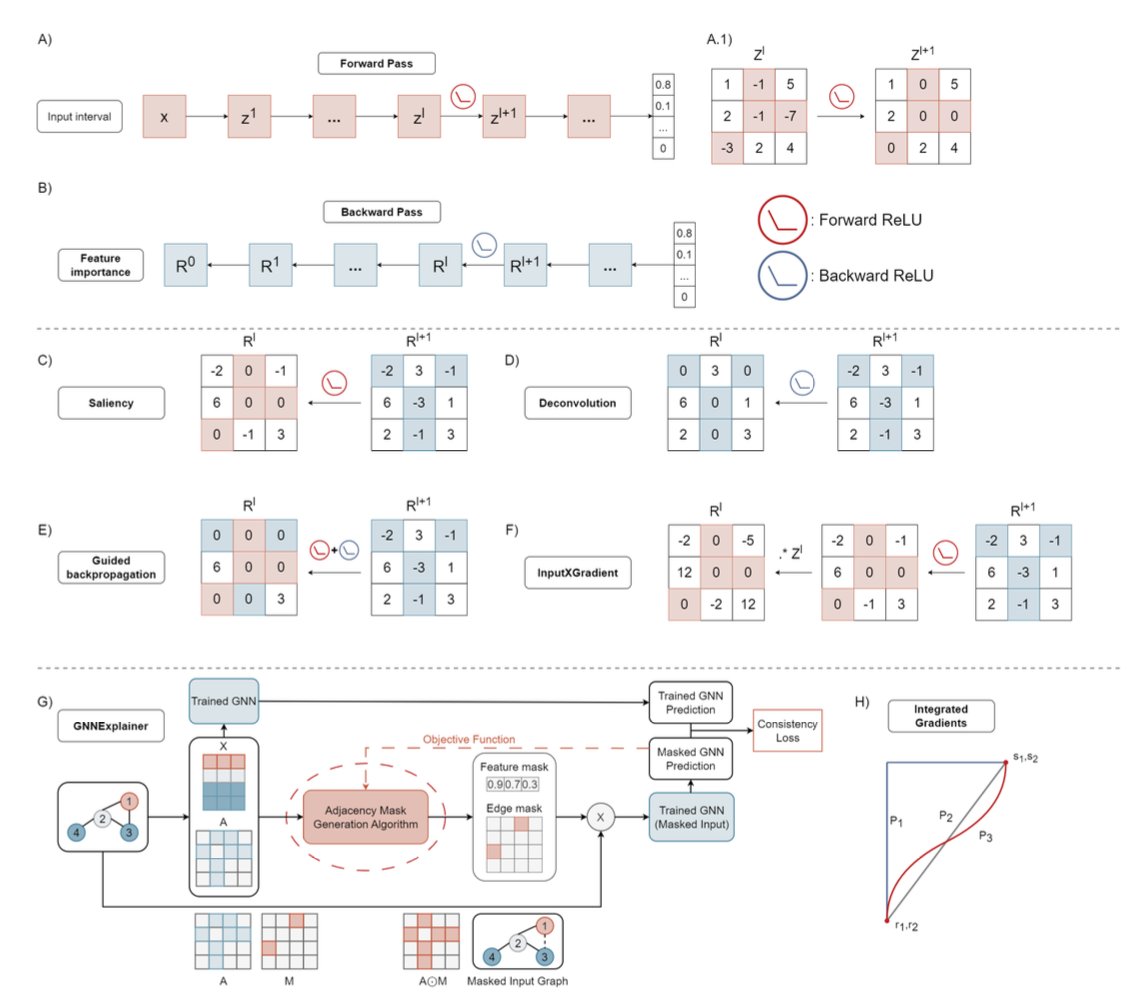
2. The framework integrates six model-aware gradient-based interpretation methods—Integrated Gradients, InputXGradients, Guided Backpropagation, Deconvolution, Saliency Maps, and GNNExplainer—applied to both CNN and GNN models.
3. OmiXAI was benchmarked on Z-DNA prediction using a dataset with 1,950 omics features and achieved high classification performance (ROC-AUC up to 0.98), while identifying a minimal set of just 50 highly predictive features without loss in accuracy.
4. The pipeline’s strength lies in its hybrid ranking approach: it combines relevance scores across methods to prioritize features, mitigating the inconsistencies often seen in standalone XAI outputs.
5. Two custom deep learning models were trained: ConvMZC (CNN) and GraphMZC (GNN). ConvMZC achieved an F1-score of 0.88, while GraphMZC reached 0.81—demonstrating the complementary value of both architectures.
6. OmiXAI is generalizable and supports interpretation of both nucleotide-based and omics features. It was also successfully adapted for k-mer-based feature analysis, identifying motifs consistent with Z-DNA structural signatures.
7. The study emphasizes that many gradient-based XAI methods—though efficient—can be noisy or biased. OmiXAI alleviates this through consensus scoring, providing more robust and interpretable results.
8. Compared to permutation feature importance (PFI) used in earlier work, OmiXAI provided more stable and biologically aligned rankings, identifying key histone marks, transcription factors, and RNA polymerase binding as top features.
9. Feature reduction experiments showed that reducing the feature set from 1,950 to 50 maintained predictive performance, highlighting the pipeline’s utility in omics-based feature engineering and dimensionality reduction.
10. Designed with modularity in mind, OmiXAI can be easily extended to other biological tasks and architectures, including transformers, by computing gradients with respect to either input features or attention weights.
💻Code: github.com/aameliig/OmiXAI
📜Paper: biorxiv.org/content/10.1101/…
#XAI #ExplainableAI #Omics #DeepLearning #Bioinformatics #FeatureImportance #NeuralNetworks #Genomics #ComputationalBiology #AI4Science
5
31
2,449
2 May 2025
OmiXAI: An Ensemble XAI Pipeline for Interpretable Deep Learning in Omics Data
1. OmiXAI is a novel ensemble explainable AI (XAI) pipeline designed for deep learning models applied to multi-omics data, enabling feature attribution that is both biologically meaningful and computationally scalable.
2. The framework integrates six model-aware gradient-based interpretation methods—Integrated Gradients, InputXGradients, Guided Backpropagation, Deconvolution, Saliency Maps, and GNNExplainer—applied to both CNN and GNN models.
3. OmiXAI was benchmarked on Z-DNA prediction using a dataset with 1,950 omics features and achieved high classification performance (ROC-AUC up to 0.98), while identifying a minimal set of just 50 highly predictive features without loss in accuracy.
4. The pipeline’s strength lies in its hybrid ranking approach: it combines relevance scores across methods to prioritize features, mitigating the inconsistencies often seen in standalone XAI outputs.
5. Two custom deep learning models were trained: ConvMZC (CNN) and GraphMZC (GNN). ConvMZC achieved an F1-score of 0.88, while GraphMZC reached 0.81—demonstrating the complementary value of both architectures.
6. OmiXAI is generalizable and supports interpretation of both nucleotide-based and omics features. It was also successfully adapted for k-mer-based feature analysis, identifying motifs consistent with Z-DNA structural signatures.
7. The study emphasizes that many gradient-based XAI methods—though efficient—can be noisy or biased. OmiXAI alleviates this through consensus scoring, providing more robust and interpretable results.
8. Compared to permutation feature importance (PFI) used in earlier work, OmiXAI provided more stable and biologically aligned rankings, identifying key histone marks, transcription factors, and RNA polymerase binding as top features.
9. Feature reduction experiments showed that reducing the feature set from 1,950 to 50 maintained predictive performance, highlighting the pipeline’s utility in omics-based feature engineering and dimensionality reduction.
10. Designed with modularity in mind, OmiXAI can be easily extended to other biological tasks and architectures, including transformers, by computing gradients with respect to either input features or attention weights.
💻Code: github.com/aameliig/OmiXAI
📜Paper: biorxiv.org/content/10.1101/…
#XAI #ExplainableAI #Omics #DeepLearning #Bioinformatics #FeatureImportance #NeuralNetworks #Genomics #ComputationalBiology #AI4Science

2
672

16 Jan 2025
#Daily_Share
Welcome to read and share the newly published paper "Attribute Relevance Score: A Novel Measure for Identifying Attribute Importance".
Read via: mdpi.com/1999-4893/17/11/518
#featureimportance #featureselection #featureranking #dependencymeasures
2
44

スモールデータだと特徴量選定が必須だけどDataRobotのサンプルコードでは2種類のアプローチを提供しています。軽くやるならFIRE、本気でやるならRobust Feature Impactがおすすめです。ここら辺のAIアクセラレーターはドキュメントにもまとまっています。
github.com/datarobot-communi…
github.com/datarobot-communi…
docs.datarobot.com/ja/docs/a…
#DataRobot #AIaccelerators #AIアクセラレーター #Featureimportance #次元削減 #特徴量選定

4
379

12 Jan 2024
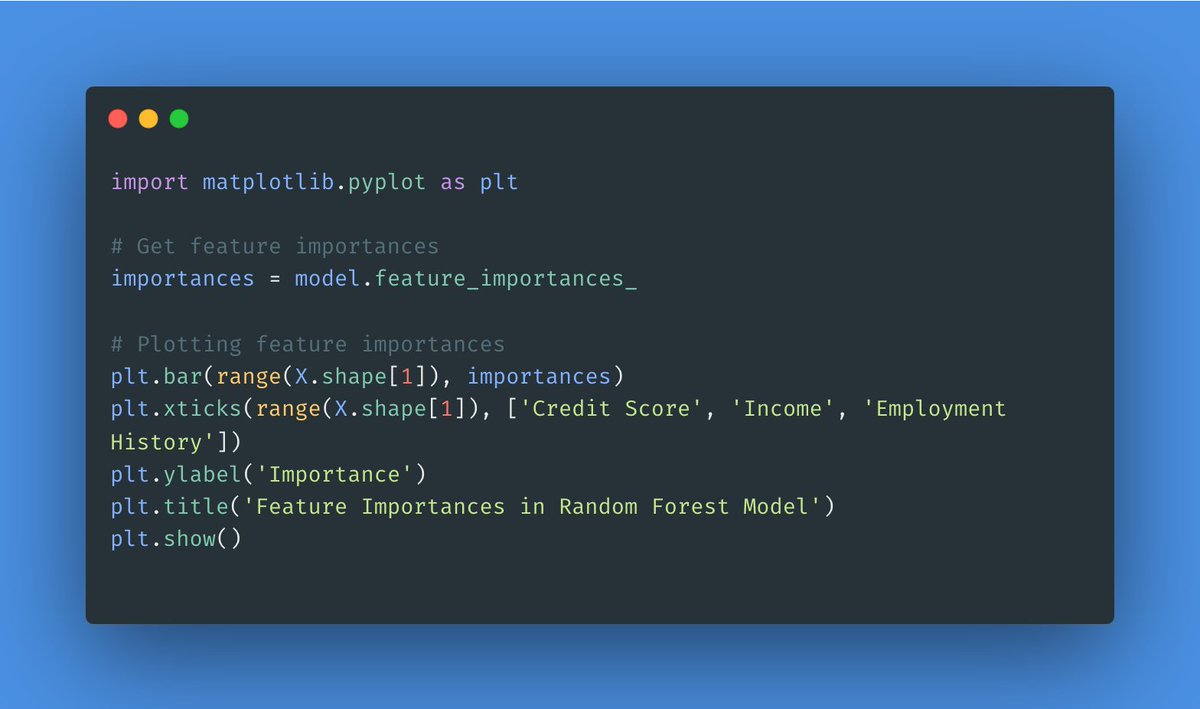
A key advantage of Random Forests is their interpretability. Let's see which features are most important in predicting loan approval. #DataVisualization #FeatureImportance
1
2
3
16

🔍 Check out my new blog: Understanding Machine Learning Predictions with SHAP (SHapley Additive exPlanations): A Case Study on Taxi Cancellation Prediction
#MachineLearning #SHAP #ExplainableAI #DataScience #AIInterpretability #ResponsibleAI #FeatureImportance💡
1
1
2
479

4 Jul 2023
🚀 Discover how understanding attribute impact can enhance model performance, interpretability, and decision-making. Demystify feature importance in ML algorithms in this article. #MachineLearning #FeatureImportance #ShahFaesal #स्वामीविवेकानन्द
astconsulting.in/artificial-…
2
25

16 Jun 2023
Você recebe aquela arquivo CHEIO de colunas e não sabe o que fazer!? Let's Data te ajuda sempre, padawan! Seguem algumas técnicas de determinar importância de features! Seeegue o fio
#FeatureImportance #MachineLearning
1
14
606

15 Jun 2023
Are you all packed yet?🧳✈️🏝️
Don't miss @FumagalliFabian's talk on "Global #FeatureImportance in Dynamic Environments" next week @iwannConference! #IWANN23
Joint @trr_318 work with @Muschalik_Max @AIML_LMU.
See you in beautiful Ponta Delgada! 🇵🇹
1
6
300

11 Feb 2023
#MachineLearning #featureimportance #materialsscience #multitarget
I have posted a new tutorial on feature importance in machine learning using SHAP.
Here is the link for the same:
bjoyita.github.io/Tutorial_3…
2
2
121

30 Jan 2023
Day 196 since I've changed job from teacher
ML for job -- chapter 8 fin.
Today's new topics are dtreeviz for visible of Decision tree and shap for visible of FeatureImportance.
It's so good to teach me how to consider of value of output of ML in business.
95
6 Dec 2022
Barbara 🔨 showcased "Incremental Permutation #FeatureImportance (iPFI): Towards Online Explanations on Data Streams" by @FumagalliFabian - check it out @arxiv: arxiv.org/abs/2209.01939
1
1

30 Nov 2022
Curious about new AI based sea ice detection methods using a novel data source? Come have a chat, poster 37, 3pm today #gradientboosting #NeuralNetworks #crossvalidation #featureenginearing #pca #featureimportance #amos2022 @AMOSupdates @science_shane @CryoJess
5

27 Sep 2022
Key educational video (Part 4) in the series now available:
#MachineLearning #modeling, covering #algorithm selection, #hyperparameter #optimization, #evaluation #metrics, and #FeatureImportance estimation.
#DataScience @CedarsSinaiMed @UPennDBEI
youtube.com/watch?v=ZeMWtDyW…
1
5

21 Sep 2022
Our new open-source #featureimportance toolbox in #python called Ensemble Feature Importance (EFI) is now available for the #airesearch and #machinelearning community! @HorizonCDT @UoNComputerSci
👉🏿 lnkd.in/erXXYy47
#explainableAI #ai #machinelearning #fuzzy #data #XAI

1
10
10

26 Jul 2022
1/ Using random forest to calculate feature importance?
The importance score might be biased. #machinelearning #featureimportance Thanks @Matthew_N_B for pointing it out
A thread 👇
3
12
50

6 Jul 2022
Free Video tutorial for #Model #evaluation and #XAI #Shapely to explain mcc of features at global and #LIME to explain feature impact at local level as per industry best practices
#training #datascience #machinelearning #xai #featureimportance
youtu.be/LGXaHsmOZ0Y

1
1
4

28 May 2022
-やること:JPX_分析、Gitの復習
-やったこと:JPX_分析
株価銘柄それ自体のFeatureImportanceが高い
おそらく、銘柄同士の相関を生かす方法を検討する必要あり。
2