
DeepRHP: A Hybrid Variational Autoencoder for Designing Random Heteropolymers as Protein Mimics
1. The paper introduces DeepRHP, a semi-supervised hybrid VAE that learns latent representations of random heteropolymer (RHP) sequence ensembles while explicitly constraining the latent space to reflect function-related chemical features, aiming to make RHP design more data-driven than empirical screening.
2. Key architectural idea: a classical sequence VAE is paired with a parallel feature-based VAE that reconstructs a deterministic chemical feature y derived from the same sequence x; both branches share the same latent variable z, encouraging z to encode both sequence-pattern statistics and chemically meaningful structure.
3. The training objective modifies the standard VAE ELBO by combining two reconstruction terms: (a) discrete sequence reconstruction (cross-entropy over monomer tokens) and (b) feature reconstruction (MSE on y), weighted by a tunable α, while keeping the KL regularization on q(z|x) vs p(z).
4. The “feature” used for semi-supervision is the sliding-window average hydrophilic–lipophilic balance (HLB), motivated by prior evidence that local hydrophobicity/solubility patterning is strongly tied to RHP behavior in protein stabilization and transport applications.
5. Data pipeline: the study simulates 10,000 RHP sequences per monomer composition using Compositional Drift (copolymer models Monte Carlo), focusing on a 4-methacrylate monomer set (MMA, EHMA, OEGMA, SPMA) spanning hydrophobic, very hydrophobic, hydrophilic, and charged chemistries.
6. To connect synthetic polymers to biology, ~30k membrane and ~30k globular protein sequences (UniProt, 50% identity threshold) are reduced into a 4-letter “monomer-equivalent” alphabet based on residue hydrophobicity/charge, enabling joint embedding and similarity analysis between proteins and RHP ensembles.
7. Design insight 1 (alphabet size): by comparing 2-monomer vs 4-monomer RHP libraries in the learned latent space (visualized via PCA of latent factors), the paper argues that 2-monomer sequence space is too broad relative to protein-like regions, whereas 4-monomer libraries yield more localized, protein-overlapping distributions—supporting why four monomers can be “enough” for protein-mimic behavior.
8. Design insight 2 (composition): within a fixed 70% hydrophobic / 30% hydrophilic constraint, varying the MMA:EHMA ratio produces distinct RHP ensembles; DeepRHP’s latent-space overlap with Aquaporin Z (AqpZ) projections highlights specific compositions (notably matching the published optimal formulation) as most similar to the target membrane protein.
9. Practical takeaway: DeepRHP reframes RHP design as an ensemble-level representation learning problem—enabling composition suggestion by latent-space similarity to target proteins—without requiring exact polymer sequences, 3D structures, or multiple sequence alignment, and with a plug-in pathway to incorporate other chemical features beyond HLB.
10. The authors report ablations indicating the hybrid (feature-guided) architecture outperforms a classical VAE alone for producing useful latent structure, while noting that current evaluation is largely qualitative and motivating future quantitative metrics and downstream tasks (e.g., membrane protein subclass discrimination, RHP–protein similarity scoring).
📜Paper: arxiv.org/abs/2606.11651
#ComputationalBiology #MachineLearning #DeepLearning #VAE #GenerativeModels #PolymerScience #MaterialsInformatics #ProteinEngineering #MembraneProteins #Cheminformatics

2
14
1,014

Jun 13
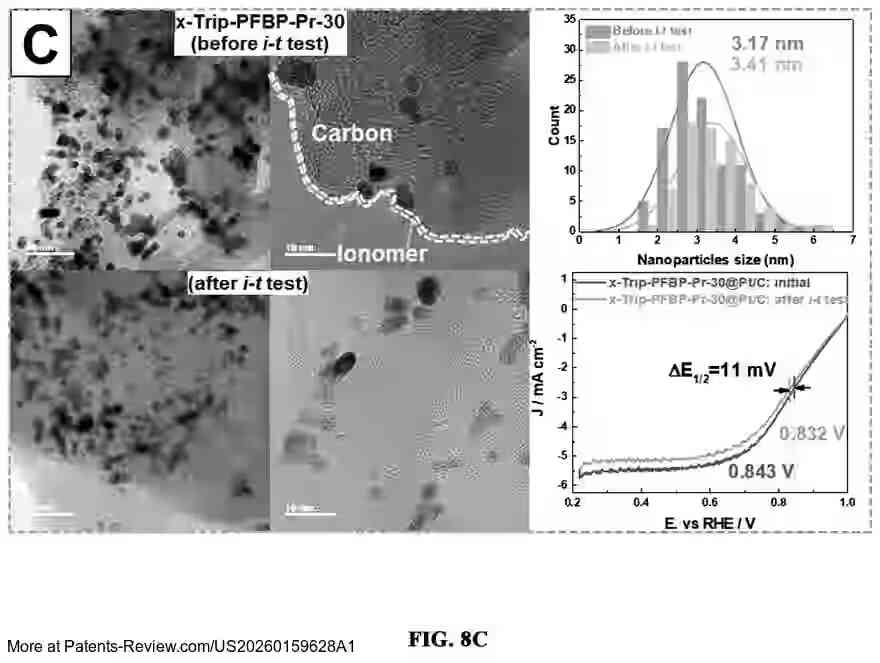
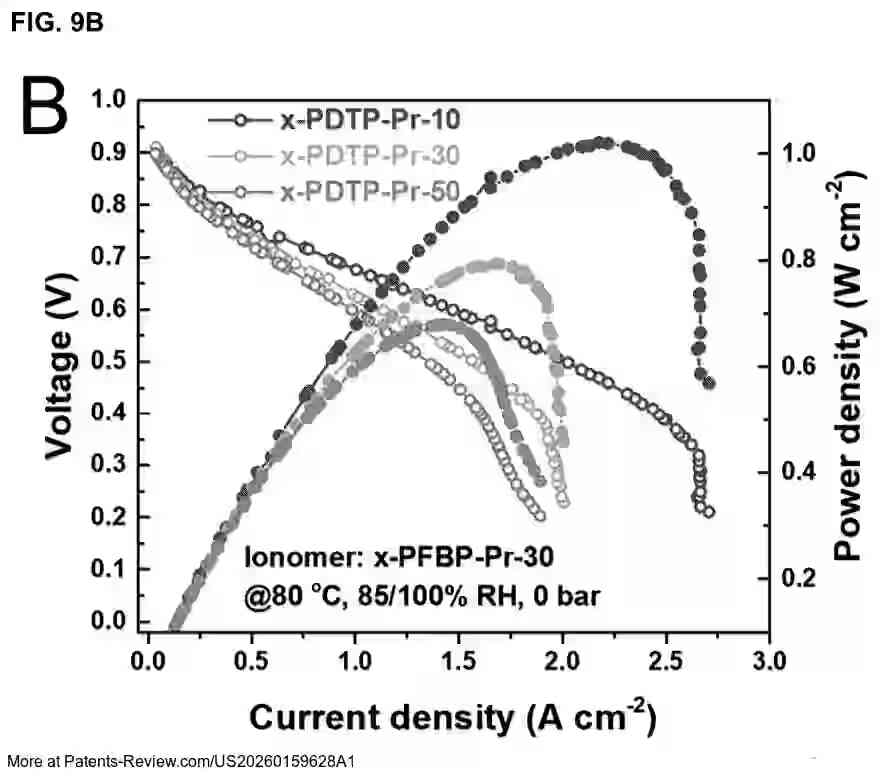
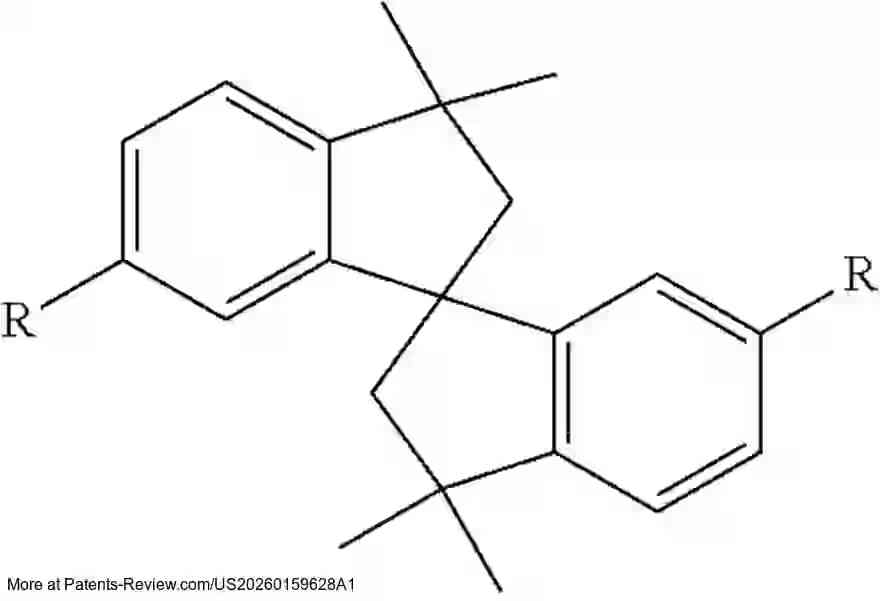
New #patent application #US20260159628A1 by #IUCFHYU reveals a poly(aryl piperidinium) copolymer ionomer grafted with propargyl group. This innovation enhances #FuelCell tech with improved chemical stability, ionic conductivity, and durability. The cross-linked anion-exchange membrane boosts catalyst layer interaction and stability.
#PolymerScience #CleanEnergy
2
35

COF-modified Membranes for Advanced Fuel Cells ⚡
From Northwestern Polytechnical University and collaborators, this CJPS review highlights how covalent organic frameworks can create proton-conducting pathways in composite membranes for low-humidity and high-temperature fuel-cell applications.
DOI: 10.1007/s10118-026-3638-1
Read the full article: link.springer.com/article/10…
#PolymerScience #COFs #FuelCells #ProtonExchangeMembranes

7
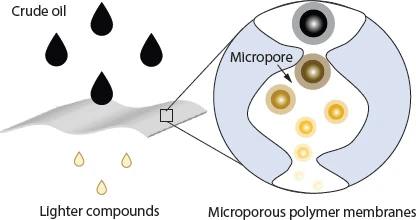
Microporous Membranes for Hydrocarbon Separation 🛢️
From University of Science and Technology of China, this CJPS review highlights how microporous polymer membranes could enable milder, membrane-based hydrocarbon separation by tailoring pore structures, anti-swelling properties, and selective transport.
DOI: 10.1007/s10118-026-3619-4
Read the full article: link.springer.com/article/10…
#PolymerScience #MembraneSeparation #PorousPolymers #Hydrocarbons
1
5
379

How much is outdated QC data costing your polymer operation? Real-time #polymer monitoring helps reduce off-spec product, improve process control, and accelerate R&D.
📘 Free eBook: fluenceanalytics.com/acomp-e…
#PolymerScience #ChemicalEngineering #SmartManufacturing #Industry40

1
8

A team of international researchers has developed a new class of ultrathin polymer membranes capable of rapidly and selectively separating complex hydrocarbon mixtures.
eurekamagazine.co.uk/content…
#PolymerScience #SustainableChemistry #MaterialsInnovation
12

“Microwave safe” is one of the most trusted labels in the kitchen.
But it is also one of the most misunderstood.
At Global Environmental Impact Solutions, we believe material claims should be clear, precise, and evidence-based — especially when plastics are used in direct contact with food.
“Microwave safe” generally means a container is designed to withstand microwave heating without melting, cracking, or deforming under intended use conditions.
That is important.
But it does not always answer the bigger question consumers assume it answers:
What happens at the material level when heat, food chemistry, repeated use, fat content, acidity, and time interact with the container?
That distinction matters.
Plastic is not one material.
Different polymers behave differently under heat.
Different additives, colorants, processing aids, residues, and use conditions can influence performance.
A rigid polypropylene food container is not the same as a thin film.
A single-use takeout container is not the same as a tested reusable container.
A scratched, aged, repeatedly heated plastic container is not the same as a new one.
And a label that speaks to structural performance does not always communicate the full material interaction picture.
This is not about creating fear.
It is about creating clarity.
Glass and ceramic behave differently because they are inorganic materials that do not rely on the same polymer structures, additives, or softening behavior as plastics.
That does not mean every plastic food container is unsafe.
It means the public deserves better language, better education, better material transparency, and better standards around what labels actually mean.
The real question is not only:
“Will this container survive the microwave?”
The better question is:
“What evidence supports the claim, under what conditions, for what material, and for how many uses?”
That is the future of material accountability.
Not vague labels.
Not consumer assumptions.
Not one-size-fits-all plastic language.
Clear standards.
Transparent claims.
Material-specific evidence.
Science-based communication.
At GEIS, we believe the next era of environmental and material accountability will be built on the same principle:
Claims should mean exactly what people think they mean.
And the evidence behind them should be strong enough to prove it.
Plastic Credits with Purpose and Precision.
#GEIS #PlasticAccountability #MaterialScience #FoodPackaging #PlasticSafety #PolymerScience #CircularEconomy #Sustainability #MaterialTransparency #ConsumerEducation #EnvironmentalImpact

4
8
54
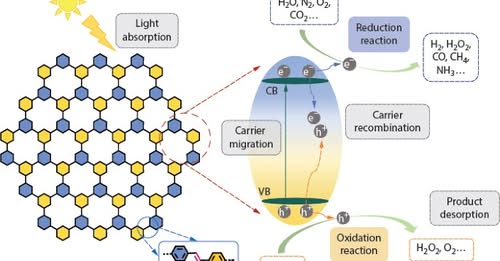
Designing sp²c-COFs for Photocatalysis ⚡
From Ningbo Institute of Materials Technology & Engineering, Chinese Academy of Sciences, this CJPS review summarizes how sp²-carbon-conjugated organic frameworks are designed, synthesized, and engineered for photocatalytic applications.
DOI: 10.1007/s10118-025-3550-0
Read the full article: link.springer.com/article/10…
#PolymerScience #COFs #Photocatalysis #PorousMaterials
1
22
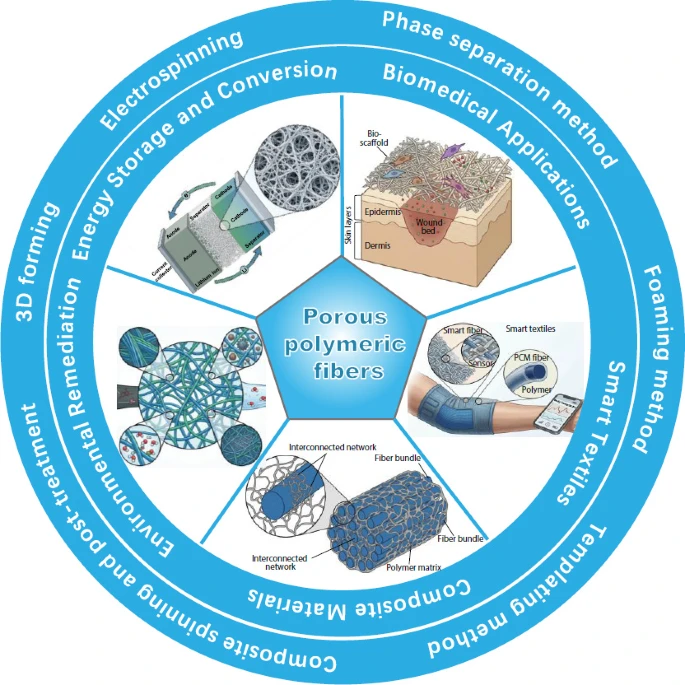
Engineering Porous Polymer Fibers 🧵
From Northwest Normal University and collaborators, this CJPS review maps how pore structures in polymer fibers can be controlled through electrospinning, phase separation, templating, and 3D printing for environmental, energy, biomedical, and smart textile applications.
DOI: 10.1007/s10118-026-3564-2
Read the full article: link.springer.com/article/10…
#PolymerScience #PorousMaterials #SmartTextiles #FunctionalFibers
13

The workshop “Machine Learning for Polymer Science” finished today after two days of activity.
The school provided a comprehensive overview of how data-driven approaches and artificial intelligence are transforming polymer science, offering a unique opportunity to bridge fundamental concepts with real-world applications in both academic and industrial contexts.
🎓Directors: Nicholas Ballard & Mónica Moreno Rodríguez @polymatsptl #EHU
#UIK #PolymerScience



72

Jun 9
Interesting:
The paper highlights the move toward depolymerization, early-stage LCA/TEA, and AI-driven discovery. The focus is now materials that are recyclable by design and fit within planetary boundaries. ♻️
#PolymerScience #Sustainability
nature.com/articles/s41578-0…
2
74
Microwave-assisted Routes to COFs ⚡
From Beijing University of Chemical Technology, this CJPS review highlights microwave-assisted synthesis as a rapid and efficient alternative to conventional solvothermal methods for constructing covalent organic frameworks.
DOI: 10.1007/s10118-026-3556-2
Read the full article: link.springer.com/article/10…
#PolymerScience #COFs #MicrowaveChemistry #PorousMaterials

14
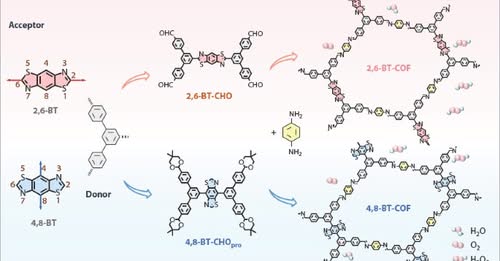
Molecular Connectivity Boosts COF Photocatalysis ⚡
From Jilin University, this CJPS study designs benzobisthiazole-based regioisomeric D-A COFs for photocatalytic H₂O₂ production, showing how 2,6-connectivity improves charge separation and boosts activity.
DOI: 10.1007/s10118-025-3551-z
Read the full article: link.springer.com/article/10…
#PolymerScience #COFs #Photocatalysis #HydrogenPeroxide
9

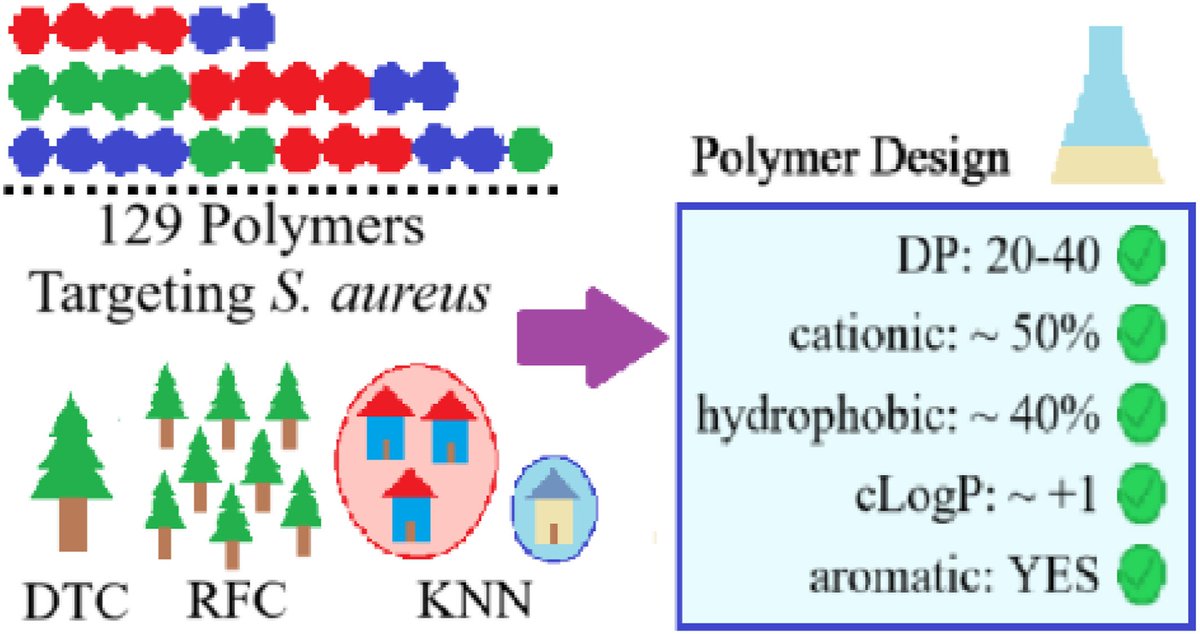
A new research in Carbon Innovation decodes the blueprint of antibacterial polymers against Staphylococcus aureus.
Read here: onlinelibrary.wiley.com/doi/…
#CarbonInnovation #AntibacterialPolymers #StaphylococcusAureus #PolymerScience
1
3
22

May 28
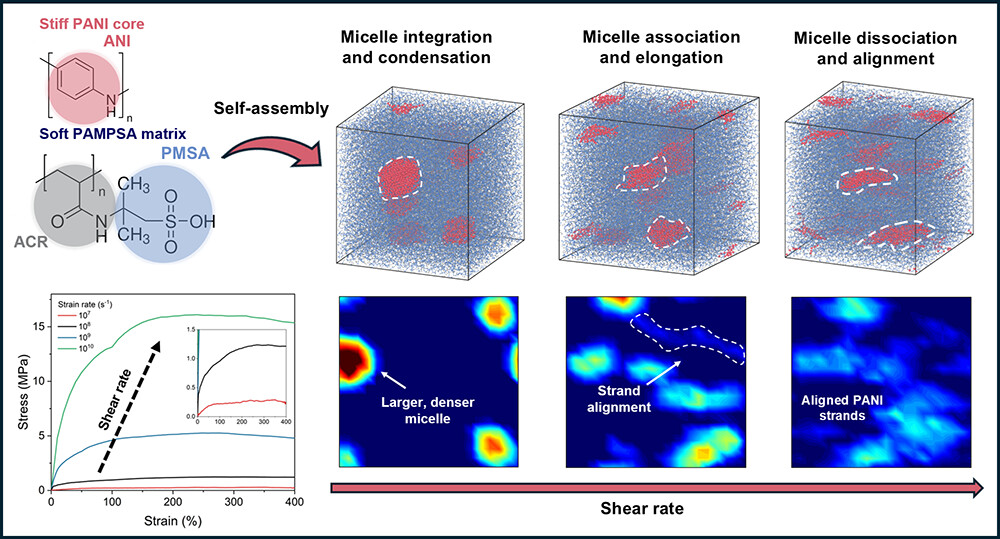
Published in Macromolecules: we used multiscale coarse-grained simulations to show how micellar PANI/PAMPSA conductive polymers stiffen with shear rate, shifting from micelle coalescence to aligned PANI load-bearing filaments. pubs.acs.org/doi/10.1021/acs… #PolymerScience #SoftMatter
2
9
363
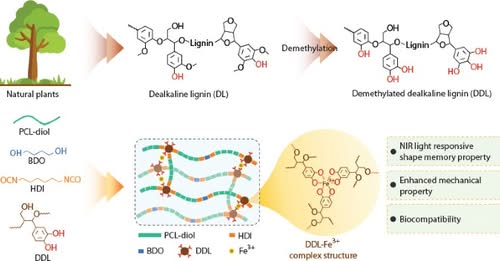
Lignin-powered Shape Memory Polyurethanes 🌿
From Beijing University of Chemical Technology and collaborators, this CJPS study enhances lignin’s photothermal performance via demethylation and Fe³⁺ complexation, enabling NIR light-responsive shape memory polyurethane for biomedical applications.
DOI: 10.1007/s10118-026-3574-0
Read the full article: link.springer.com/article/10…
#PolymerScience #ShapeMemoryPolymers #Biomaterials
3
15

May 26
As a chemist chasing solutions, a producer in industry, a creator on the canvas... Free from exaggeration, merely to share in all simplicity what I can achieve and the worlds I dedicate my efforts to... 🧪📚✨️
The rigid mathematical world defined by the Schrödinger equation, and the metaphorical periodic table distilled from human memory by Primo Levi… The former whispers the probability clouds of electrons, the instantaneous deviations in the Hartree-Fock method, and the uncompromising geometry of the Pauli exclusion principle; the latter narrates the human, the pain, and the resilience hidden between those strict laws.
On one side lies the microscopic determinism of the universe; on the other, the literary memory imposed upon elements by a chemist who survived Auschwitz. For us chemists, the periodic table is not merely a list; it is a universal mirror where wave functions intersect with human stories.
Yet, the narrative does not end there. On the other side, there is the lesser-known face of industry—the macroscopic reality of polymer yarn production and weaving. I took this world of theoretical knowledge and industrial production and transformed it into a micro-scale, high-resolution, and meticulously precise artwork based on Pierre Auguste Cot’s "Girl with Flowers". This time, polymers became more than just structural building blocks of industry; they became the canvas of patience, colors, and aesthetics.
I suppose there could be no finer, more elegant convergence of industry and art, of theory and practice. The cold equations of science, the rhythm of yarns, and the colorful world of art—all melted into a single crucible.
#PrimoLevi #ThePeriodicTable #QuantumChemistry #ScienceAndLiterature #PolymerScience #PierreAugusteCot #IndustrialArt #ArtAndScience #TheoreticalPhysics




1
45
498

🧪 Benzene (C₆H₆): The Fascinating Ring That Changed Organic Chemistry! ⚛️
Discover the unique hexagonal structure, resonance stability, industrial uses, and health hazards of one of chemistry’s most important aromatic hydrocarbons. 🔬📚
Perfect for students, science lovers, and chemistry enthusiasts! 💡
#Benzene #OrganicChemistry #Chemistry #Science #AromaticHydrocarbon #ChemicalScience #ChemistryNotes #ChemistryStudent #ChemistryTeacher #ScienceEducation #STEM #STEMEducation #LearnChemistry #MolecularStructure #Resonance #Hydrocarbons #ChemicalBonding #PeriodicTable #EducationalPost #ScienceFacts #ScienceCommunication #LabSafety #ToxicChemicals #IndustrialChemistry #Petrochemicals #Pharmaceuticals #PolymerScience #Biochemistry #FutureScientists #ChemistryLovers #ChemistryWorld #ScienceForStudents #ScientificLearning #InnovationInScience #OrganicCompounds #SciencePoster #EducationalContent #StudyMaterial #ChemistryDiagram #LearningMadeEasy
@ACSorg @RoySocChem @IUPAC @NobelPrize @NASAScience @ScienceMagazine @newscientist @chemistryworld @nature @UNESCO @WorldofEngineering @STEMLearningUK @PhysicsToday @compoundchem
8
12
341

👋 We’ve arrived!
Excited to join X. At jekinpolymer.com, we’re passionate about how advanced polymers shape a sustainable tomorrow. 🌍
Follow us for the latest projects, launches, and material breakthroughs! 🔔
#PolymerScience #Innovation #ChemicalIndustry

16
6
21
251

🏆 Congrats to Prof. William Dichtel, Spring 2026 PMSE Doolittle Award winner!
This Award recognizes outstanding innovation in polymer science.
Congratulations!
#PMSE #ACSSpring2026 #PolymerScience #MaterialsScience

3
193