
Jun 15
Vector search is compressing data and finding the correct answer in 99% of garbage.
This is a subset of RAG.
Combining this with prefiltering and relations makes it more powerful. This is a more advanced form of RAG. Prefiltering and relationships also help it scale.
This is why I think it’s a retarded take, people assume it just refers to chunking vector search. Which is also an excellent technology that works alone for countless use cases.
When you’re talking about Retrieval Augmented Generation, it’s not good enough on its own, which is why it continues to evolve
2
53


May 30
Also, there is (and should be) a good deal of prefiltering. Students usually aren't going to take a class if they don't expect to be able to understand the material and generally course listing/prerequisites are meant to give a sense of that.
2
13

May 9
All elite chess players have relatively high IQ. High IQ is a prefiltering step, after IQ is less meaningful, arguably because those with lower IQ in that group can't rely on it as much. Same reason why the most skilled NBA players tend to be shorter than avg.
4
9
568

May 1
$Darksol has been on heater so far,
$Darksol =Non-KYC Cards Private Payments (AnonPay) Memory as a Service Timerap.....more to come.
Basically infra for ZHC ai agents...
Tldr:
💳 Non-KYC Cards: Instant virtual Visa/Mastercard issued with crypto deposit; no KYC up to $1k per card, email delivery, agent/human compatible with API and holder fee waivers.
🔏Private Payments (AnonPay): Privacy-focused spend router for agents; crypto-native, no-headache payments allowing machines to transact anonymously in the dark.
Memory as a Service: Persistent, reliable agent memory infrastructure (beyond short context windows) for better reliability, prefiltering, and real-world agent ops.
TimeWarp (trend-to-token tiles/launches), prepaid/gift cards, Terminal, Clawsino casino, random oracle (free for large holders), open-source spend routing/receipts from onchain to real-world rails.

7
10
33
4,990

Apr 30
Modern GPU texture compressors have a secret (but dangerous) superpower: prefiltering (blurring). Sometimes an encoder way overfits edges, causing overall perceptual quality to collapse. One way to overcome this is to blur the input.
It's paradoxical: blurring can boost quality.
4
2
28
2,649

Apr 25
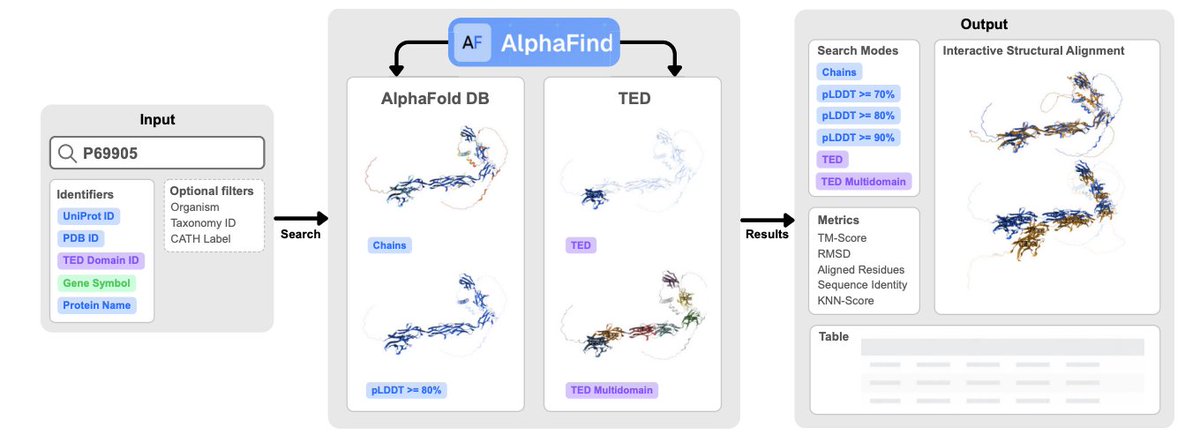
AlphaFind v2: Similarity search in AlphaFold DB and TED domains across structural contexts
1 AlphaFind v2 is a web server for fast, structure-based similarity search at AlphaFold DB scale, combining embedding-based prefiltering with alignment-based refinement to keep results biologically interpretable (TM-score/RMSD) while staying interactive.
2 The key design idea is “search across structural contexts”: users can search full chains, restrict comparisons to high-confidence regions using AlphaFold pLDDT thresholds (70/80/90), search TED domains, or run a TED Multidomain mode that captures domain combinations rather than single-domain matches.
3 The workflow is staged for responsiveness: Phase 2 returns immediate approximate kNN results from a vector database (top k=100 by cosine similarity), while Phase 3 runs asynchronously in the background to refine rankings using US-align and report TM-score, RMSD, aligned residues, and interactive superpositions.
4 pLDDT-aware search directly addresses a common AlphaFold-era problem: low-confidence/disordered regions can dominate alignments and hide true homologs. By trimming residues below chosen pLDDT thresholds, AlphaFind v2 focuses similarity on stable structural cores.
5 Domain-level search is integrated via TED: AlphaFind v2 supports direct TED domain retrieval and alignment restricted to domain residue boundaries, enabling more fine-grained detection of shared folds when full-length proteins differ in architecture.
6 TED Multidomain mode targets proteins where function/evolution is encoded in domain composition and order. It aggregates multiple domain-to-domain matches into a single score/alignment, aiming to recover “same architecture” relationships that single-domain hits would miss.
7 A distinctive interface feature in TED Multidomain is interactive weighting: sliders adjust each matched domain pair’s contribution, updating the 3D alignment view to move between (i) inspecting one domain precisely and (ii) assessing global multi-domain arrangement.
8 Under the hood, AlphaFold DB v4 chains are embedded into 1536D vectors using an ESM3-based pipeline; additional embeddings are computed after removing low-confidence residues (pLDDT < 70/80/90). TED domains use precomputed 128D Foldclass embeddings.
9 Engineering choices focus on scalable, low-latency search: OpenSearch vector DB with HNSW (16x compression, on-disk), a Python/Flask REST API, Celery Redis for async refinement jobs, PostgreSQL for state/caching, and Kubernetes for horizontal scaling.
10 Reported benchmarks show rapid retrieval plus strong refinement quality: approximate results in ~2.4 s for chains and ~0.49 s for domains, with refinement completing in tens of seconds; evaluation indicates higher average TM-scores than AlphaFind v1, FoldSeek server (TM computed separately), and Merizo-search (domains), with statistical significance (P < 0.05).
11 Case study (PIN3 auxin carrier): full-chain search struggles due to large disordered loops, but pLDDT ≥ 90 mode finds homologs with TM-score up to 0.947, illustrating how confidence-filtered structural search can recover relationships obscured by structural “noise”.
12 Case study (NCAM1): TED Multidomain mode captures the characteristic Ig-domain fibronectin type III arrangement, helping identify proteins with similar multidomain architecture; interactive reweighting helps resolve cases where domain positions differ across predictions.
📜Paper: doi.org/10.1093/nar/gkag372
#ProteinStructure #AlphaFold #StructuralBioinformatics #ProteinDomains #SimilaritySearch #Embeddings #WebServer #TMscore #CATH #TED #ComputationalBiology
1
6
41
2,635

Apr 15
Perhaps the context was that the SPUs are technically part of the CPU itself. So you’d do triangle prefiltering on the SPUs (PS3 CPU) but would never try that on the PS4 CPU.
3
1
9
1,171

Apr 14
most devs are burning tokens on agents that use grep or regex to find code because they don't realize how much of a bottleneck that search loop actually is. moving to rust and zig with simd for low level prefiltering is the move you are basically treating the entire codebase as a high speed data stream instead of a set of files. this is exactly how you enable coding agents to actually reason over a chromium sized repo in real time without hitting a timeout or context overflow every five minutes
1
2
7
2,741

ADIÓS REGEX… HOLA FUTURO DEL CÓDIGO
@neogoose_btw creó el buscador de código más brutal del planeta:
⚡ Más rápido que la luz
✅ Preciso al 100%
❌ SIN índice
❌ SIN regex
✅ Resultados perfectos en milisegundos
Lo probaron EN VIVO con:
→ Código leaked de Claude
→ Linux Kernel (100k archivos)
→ Chromium (500k archivos)
Y… funcionó de PUTÍSIMA MADRE ALWAYS.
Hecho en Rust Zig con SIMD, memory mapping, prefiltering y optimizaciones de bajo nivel (incluso inline assembly).
Esto no es una mejora.
Es un salto cuántico.
El repo que todos vamos a estar usando en 2076 ya existe hoy.
REPOOO👇
11
66
764
71,031

Apr 14
better to use an ensenble of sift aliked&lightglue superpoint&lightglue, with ransac as post processing. this should be fast enough plus a loose dino/netvlad prefiltering
1
4
404

Apr 12
Pre-filtering roughness is not too bad. Source2 goes smarter and uses sort of anisotropic prefiltering. Overall a good idea.
Playcanvas has runtime Toskvig implementation which approximates extra roughness from how much the normalmap is un-normalized (from mipmapping).
2
4
466

also for those who haven't read mempalace, the architecture is literally a decision tree. palace → wing (who?) → hall (what type of memory?) → room (what topic?) → drawer (the actual text). every node is a hand-coded classification step using keyword matching and regex. the whole thing is just successive prefiltering to narrow the search space before hitting chromadb. and that's exactly what a modern embedding model does in a single forward pass: zero-shot, multilingual, no hand-coded taxonomy needed. the "palace" is just a brittle, english-only approximation of what jina-v5 or voyage already do out of the box.

2
6
835
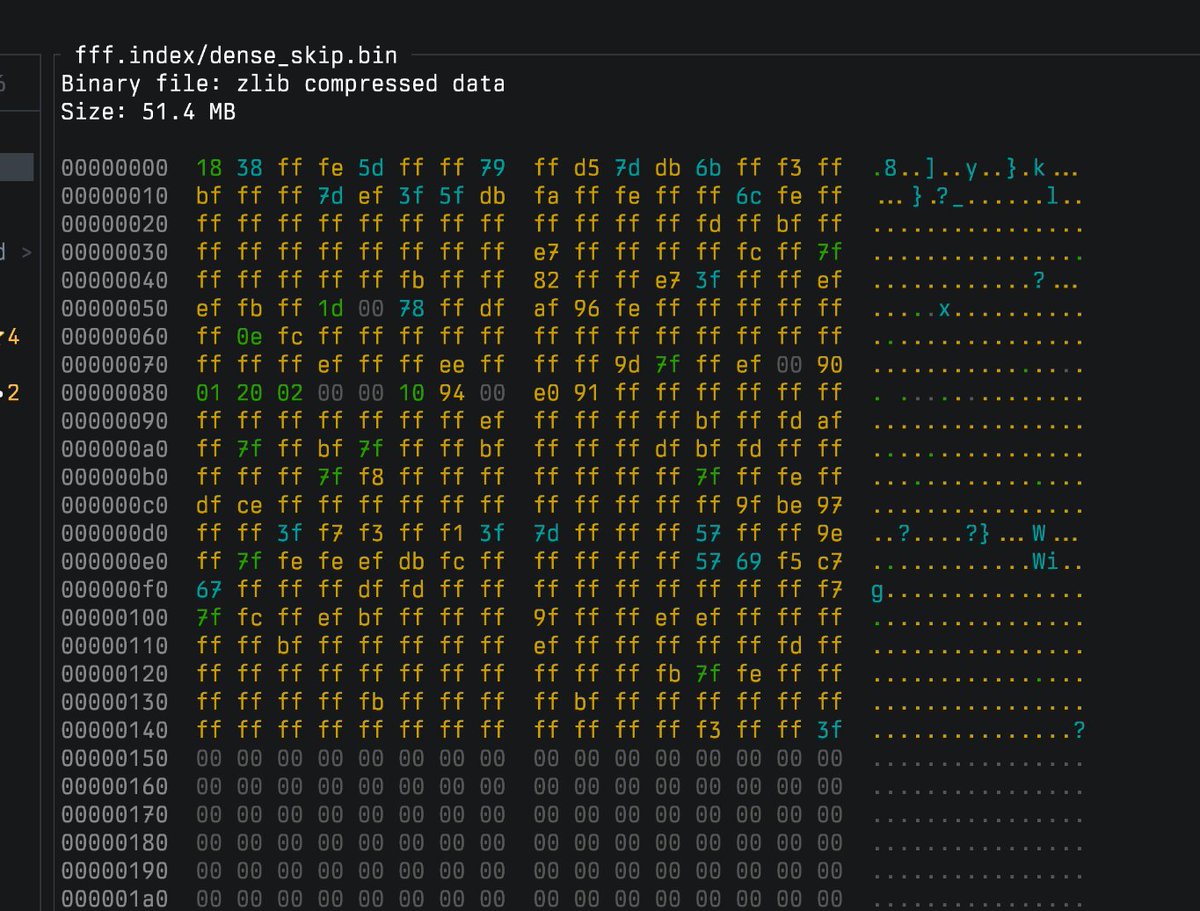
Experimenting with persisting index for fff to actually make a cli that so many people are asking about
this is about the file size we need for the whole linux kernel filetree content prefiltering index, and I think this is kinda impressive
rendered in fff neovim plugin btw
3
65
3,425
The file search engine is written in Rust, Zig and contains all the possible low level optimizations including SIMD, memory mapped caching, prefiltering and much more (even contains inline assembly in the source code)
1
1
43
8,574

Mar 30
Manticore Search 25.0.0 is out.
Highlights:
🔀 Hybrid search
🎯 KNN prefiltering
⚡ Parallel chunk merging
☁️ S3-compatible backups
📦 Simpler bundle packaging
Also includes 36 bug fixes across query execution, replication, auto-embeddings, RT tables, SQL compatibility, and more.
🧵 below
manticoresearch.com/blog/man…
1
1
4
860

Mar 27
In the next version of fff I optimized query prefiltering even further!
Now the grep on the linux kernel (92k indexed files) results in sub-16ms results on EVERY SINGLE keystroke

2
1
55
3,247

Mar 25
Hmm interesting. Yeah I think what I'm proposing might just absorb all of the work that soft blending in the final composition would have to do, and might work better by integrating that into learning.
BTW the IPE video visualization here jonbarron.info/mipnerf/ is what I'm imagining. Prefiltering a sinusoid has very nice math.
What do you have to do to make the DIT handle multi-resolution RoPE? Is just training on a mixture not enough? Do you need to communicate what frequencies are missing and what aren't? If so the IPE math provides a solution for this, which is basically just including the weight attenuation scaling in [0, 1] to the features during training. It's basically a soft mask indicating "is this frequency reliable?", though might not even be necessary because a scaled posenc already encodes scale by breaking the symmetry between each sin and cos in each posenc pair.
1
4
338

Mar 13
Some QTers now dunking on my Grok Q&A because I performed my experiment in public, rather than prefiltering your data with a private query. Cool. You go on dunking and I'll go on doing real experiments where I don't always get the result I expect.
2
47
2,961