
1 Oct 2025
SORA 2 RESEARCH TEAM: The 26 Brilliant Minds Behind OpenAI's Video AI Engine
A comprehensive breakdown of the researchers who built Sora 2 - their origins, education, research impact & achievements: 🧵
1. Harold Li (Liunian Harold Li) 🇨🇳🇺🇸
> PhD, UCLA (2022)
> VisualBERT (~2,000 citations), Matryoshka Query Transformer
> 7,010 total citations | Vision-language models pioneer
2. Dmytro Okhonko 🇺🇦
> MSc, Kyiv National University (2015)
> Transformers with Convolutional Context for ASR
> 1,702 citations | Former Facebook AI, multi-modal learning expert
3. Avi Verma 🇮🇳🇺🇸
> BSc, Stanford (2024)
> Young prodigy | Tesla & Meta intern
> Regeneron Science Talent Search winner
4. Eric Zhang 🇺🇸
> BSc, UC Berkeley (2018)
> Annealed Langevin Dynamics for Music Generation
> AI in music & graphics specialist
5. Ricky Wang 🇺🇸
> BSc, UC Berkeley (2020)
> Member of Technical Staff at OpenAI
> Core Sora video generation team
6. Troy Luhman 🇺🇸
> PhD, Computer Science (2022)
> High Fidelity Image Synthesis with Deep VAEs
> 1,151 citations | Generative models & diffusion expert
7. Eric Luhman 🇺🇸
> PhD, Computer Science (2022)
> Diffusion Probabilistic Model for Handwriting Generation
> Co-developed breakthrough diffusion models
8. Bram Wallace 🇺🇸
> PhD, Cornell (2023)
> Activation Regression for Continuous Domain Generalization
> Self-supervised & transfer learning specialist
9. Eric Mintun 🇺🇸
> PhD Physics, UC Santa Barbara (2018)
> Segment Anything Model (SAM) - 5,000 citations
> 13,168 total citations | Meta FAIR contributor
10. Michael Chang 🇺🇸
> PhD, MIT (2022)
> VideoCLIP, Causal Masked Multimodal Model (CM3)
> 9,522 citations | Former Google DeepMind
11. Gabriel Petersson 🇸🇪
> High school dropout
> Founded Depict.ai at 17 (YC-backed)
> Joined OpenAI without degree - pure talent!
12. Jure Zbontar 🇸🇮
> PhD, University of Ljubljana (2015)
> fastMRI Dataset & Benchmarks (~1,000 citations)
> 11,543 total citations | Former Meta FAIR
13. Daniel Geng 🇺🇸
> PhD, University of Michigan (2025)
> Visual Chirps - Audio-Driven Video Generation
> Multi-modal AI specialist, Google DeepMind intern
14. Will DePue 🇺🇸
> BSc Design/CS, University of Michigan (2015)
> Designer-engineer hybrid | runs depue. design
> OpenAI visual tools contributor
15. Alex Zhao 🇨🇳🇺🇸
> Likely Stanford or similar tier
> OpenAI researcher | Internal systems specialist
16. Cheng Lu 🇨🇳
> PhD, Tsinghua University (2023)
> VFlow, SDE Beats ODE in Diffusion-Based Image Editing
> 6,572 citations | Tsinghua ML group
17. Yufei Guo 🇨🇳
> BSc, Peking University (2020)
> 1,028 citations on neural networks
> OpenAI engineer, core Sora team
18. Pritam Damania 🇮🇳🇺🇸
> MSc, SUNY Stony Brook (2015)
> PyTorch Distributed - Accelerating Data Parallel Training
> Former Tesla | PyTorch framework contributor
19. Larry Kai 🇨🇳🇺🇸
> OpenAI researcher
> Internal Sora infrastructure contributions
20. Farzad Khorasani 🇮🇷🇺🇸
> PhD, UC Riverside (2015)
> Stallion, CuMAS for GPU optimization
> 635 citations | Former Tesla, inference optimization
21. Kenji Hata 🇯🇵🇺🇸
> MSc, Stanford (2015)
> 9,582 citations in computer vision
> Multi-modal research specialist
22. James Betker 🇺🇸
> DALL-E 3 "Improving Image Generation with Better Captions"
> GPT-4o contributions | Former Google security engineer
> Lead on DALL-E 3
23. Vladimir Chalyshev 🇷🇺
> OpenAI researcher
> Internal Sora contributions
24. Connor Holmes 🇺🇸
> PhD, Colorado School of Mines (2020)
> ZeRO , DeepSpeed-Chat RLHF Pipeline
> 1,411 citations | Former Microsoft, scaling specialist
25. Aditya Ramesh 🇮🇳🇺🇸
> DALL-E (~5,000 citations), DALL-E 2
> 28,300 total citations - HIGHEST on team!
> Inventor of DALL-E series, leads world simulation
26. Bill Peebles 🇺🇸
> PhD, UC Berkeley (2023, BAIR)
> Scalable Diffusion Models with Transformers, Sora Technical Report
> 5,735 citations | HEAD OF SORA at OpenAI
> NSF Graduate Fellow
📊 TEAM STATS:
> Combined citations: 100,000
> Countries: 10 represented
> Top institutions: UC Berkeley, MIT, Stanford, Tsinghua, Cornell


3
416

5 Aug 2025
I made a video back in 2023 that goes over the history of Multimodal Deep Learning till that point. I feel these are essential reads to understand what is up with modern VLMs.
A list of research papers/topics I learned (video link in comment).
Contrastive Learning
- LSTM-CNNs
- CLIP
- ImageBind
Masked Visual LLMs
- VisualBERT
- VilBERT
Unified Architectures
- BLIP
- VL-T5
Generative LMs
- Frozen
- Flamingo
- PaLM-E

2
1
45
1,361

11 Jul 2024
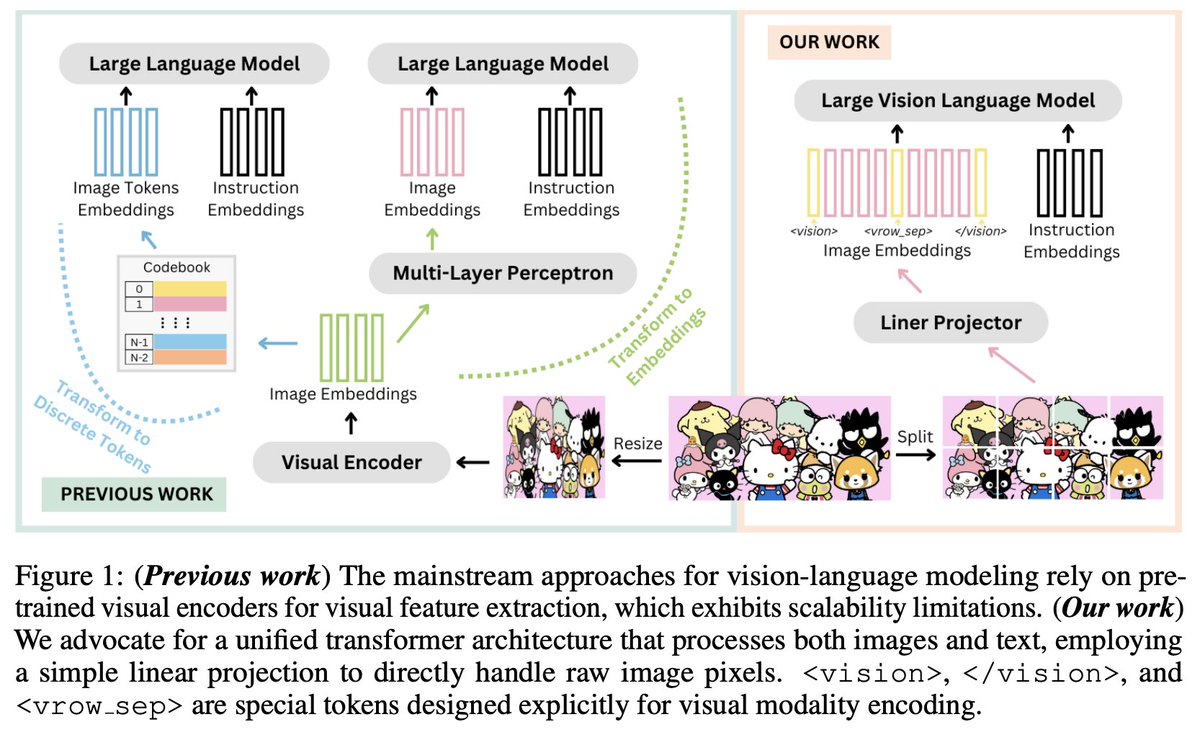
How does SOLO work? Unlike previous practice that relies on pre-trained visual encoders, we keep the image's original resolution and aspect ratio and directly apply a linear projection on the raw pixels of the image patches.
This modeling strategy draws inspiration from foundational research exemplified by VisualBERT and subsequent industry initiatives aimed at scaling, such as Fuyu.
1
2
9
731

18 May 2024
📝 Top Papers in Computer Vision, NLP, Speech, Multimodal AI, Core ML, RecSys, & Graph ML
🔗 papers.aman.ai
👉🏼 I’ve put together a summary of key papers in #AI and segregated them into (i) need-to-know and (ii) good-to-know.
🔹 Vision
- Image Classification (CNN architectures such as AlexNet, VGGNet, InceptionNet, ResNet to Transformer architectures such as ViT, DeiT, BEiT, MAE)
- Object Detection (YOLO v1-v8, Fast/er R-CNN, Mask R-CNN, CenterNet, Pix2Seq, DETR, Detic, Focal Loss)
- Semantic/Instance Segmentation (U-Net, Mask R-CNN, Segment Anything)
- NeRF (InstantNeRF, BlockNeRF)
- SSL Contrastive Learning (SimCLR, MoCo, DINO v1 & v2)
🔹 NLP
- Transformers (original paper)
- Semantic Representation Encoders (BERT and its variants: RoBERTa, DistillBERT, ELECTRA, XLNet, MPNet, ALBERT)
- Autoregressive Decoders (GPT-n, Llama 1/2/3, Alpaca, Vicuna)
- Augmented LMs (RAG, Toolformer, HuggingGPT, Gorilla)
- Supervised Fine-tuning (Instruction tuning/FLAN, LIMA, LESS)
- LLM Alignment (RLHF/InstructGPT, PPO, DPO, KTO, GPO, IPO, sDPO, ICDPO)
- Encoder Decoder Architectures (T0, T5, BART)
- Machine Translation (M2M-100, NLLB-200)
- Contrastive Learning (SNCSE, InfoNCE, Sentence-BERT)
- Prompting (CoT, Auto-CoT, Self-Consistency, ToT, GoT, ReAct, APE, ART)
- PEFT (Prefix-tuning, Adapters, LoRA, LLaMA-Adapter v1 and v2, QLoRA, QA-LoRA, DoRA, NOLA)
🔹 Speech
- SSL Pre-Training (WavLM, AudioMAE, HuBERT)
- Automatic Speech Recognition/Keyword Spotting (GMM-HMM, DNN-HMM, all-neural architectures such as LAS/Whisper, streaming architectures such as RNN-T/Transformer-T)
- Speaker Identification (i/d/x-vectors, GE2E loss, AAM loss)
- Text-to-Speech (HiFi-GAN, Tacotron v1 and v2, Voicebox)
- Text-to-Audio/Music (MusicGen, AudioGen)
🔹 Multimodal
- SSL Pre-Training (ViLT, MLIM, UNiTER, LXMERT, VisualBERT, Data2Vec v1 and v2, I-Code, VL-BEIT, ImageBind)
- V L Prompting (Flamingo, Frozen, InstructBLIP)
- Text-to-Image (DALL-E 1/2/3, Imagen, Latent Diffusion, Make-A-Scene, Make-a-Video)
- Translation (SeamlessM4T)
- Contrastive Learning (InfoNCE, CLIP, CLAP, AudioCLIP)
🔹 Core ML
- Training Regularizer (Dropout)
- Training/Inference Efficiency (ZeRO, ZeRO-Infinity, FlashAttention, FlashAttention-2)
- Training Stability (Batch/Layer/Group/Instance Norm, Residual/Skip Connections)
- Explainable AI (Guided Backprop, Grad-CAM, CAV, Influence functions, Representer points, TracIn)
🔹 RecSys
- ML-based Collaborative Filtering (Factorization Machines)
- DL-based Algorithms (Collaborative Deep Learning, Wide & Deep, DNNs for YouTube Recommendations, Product-based DNNs, NCF, Deep & Cross v1 and v2, DeepFM, Deep Interest Network, Behavior Sequence Transformer)
🔹 Graph ML
- Factorization-based Algorithms LLE (LLE, LAP, HOPE)
- Random Walk-based Algorithms (Node2vec)
- Deep Learning-based Algorithms (SDNE, GraphSAGE, EGNN, GCN, GAT)
#ArtificialIntelligence

1
6
353

5 Apr 2024
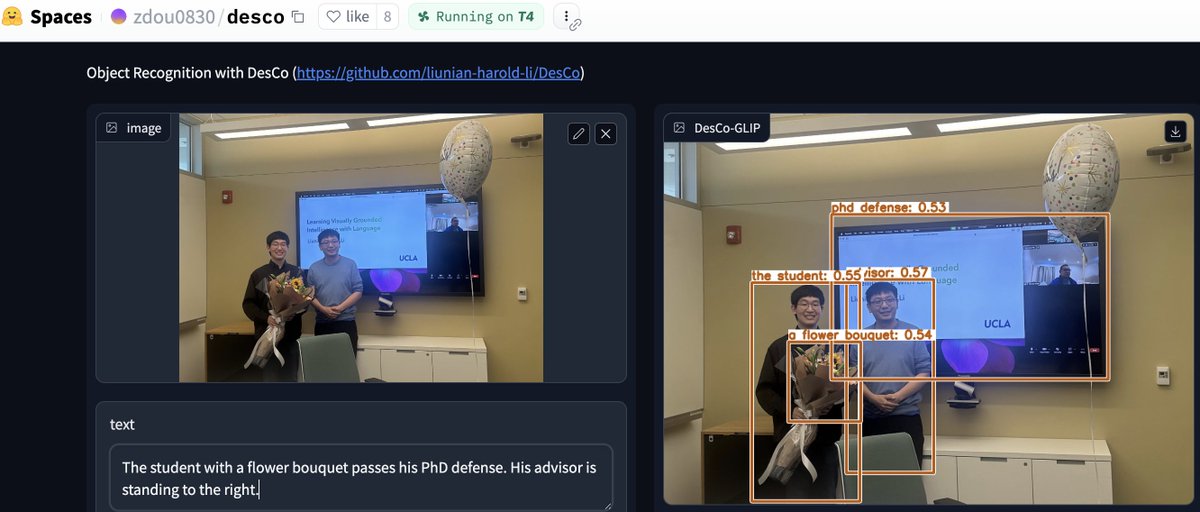
Harold guided me step by step when I was an undergrad and just started research. He was so nice to share his valuable research experience to junior students and introduced so many chances to help me grow up 🚀.
He also taught me a lot about how to do solid research and think of impactful ideas. It's my great honor to work with him on bunch of successful projects, VisualBERT, GD-VCR and GeoMLAMA! ❤️
Words can't fully express how grateful I am to you! Too many memories flood my mind. Anyway, hope everything goes well in the future and look forward to your next journey! @LiLiunian
5 Apr 2024

📢Please join me in congratulating Harold Li @LiLiunian for passing his Ph.D. defense today🎉 Harold has accomplished remarkable work and has been a pioneer in vision-language foundation models. 🧵 1/
1
25
3,683

5 Apr 2024
The journey started in 2019, when Harold developed one of the first V&L models, VisualBERT, trained on image captions. By allowing token/visual embeddings to interact in Transformer, visualBERT captures intricate associations between text and image 5/
12 Aug 2019

hot off the press -- VisualBert: A simple and performant baseline for vision and language. Language image region proposals -> stack of Transformers pretrain on captions = SOTA or near on 4 V&L problems. arxiv.org/abs/1908.03557 @LiLiunian Cho-Jui Hsieh Da Yin @kaiwei_chang
1
1
7
778

8 Dec 2023
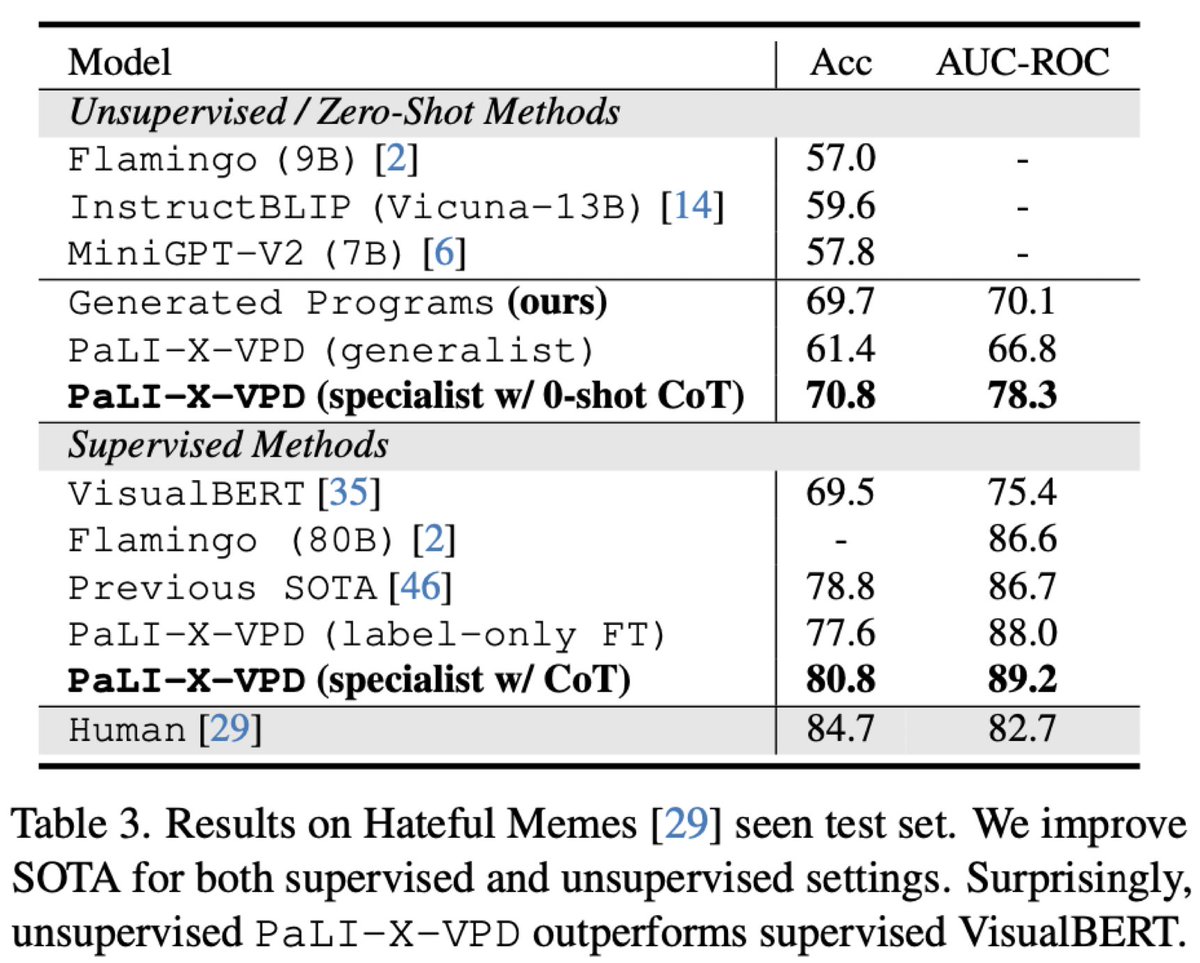
VPD can also be used for adaptation to downstream tasks. We apply VPD on Hateful Memes detection.
PaLI-X-VPD set the new superhuman SOTA. Notably, our unsupervised PaLI-X-VPD even outperforms supervised VisualBERT!
(6/n)
1
4
256
13 Oct 2023
Congrats to @LiLiunian for winning Google PhD Fellowship! 🎉🥳🎊 Harold led pioneering efforts in vision-language research, including developing notable models such as VisualBERT, CLIP, and recently introduced Desco. He will be on the market this year! @uclanlp @UCLAengineering

In 2009, Google created the PhD Fellowship Program to recognize and support outstanding graduate students pursuing exceptional research in computer science and related fields. Today, we congratulate the recipients of the 2023 Google PhD Fellowship! goo.gle/3PYfLXl
4
6
89
20,596

9 Sep 2023
Anyone got a lead on a good embedding model that can embed both images and text into the same space, so you can search for "dog" and get back images most likely to contain a dog?
It looks like VisualBERT is one, what are others?
22
20
243
104,379

13 Mar 2023
Lots of good #visualizations of the recent SOTA models!
#ai #generativeai #chatgpt #transformers #reinforcementlearning #GAN #diffusion #bert #visualbert #dalle #dalle2 #knowlegegraph #kg #responsibleai
1
1
261

15 Dec 2022
multi-modal models🗨️:
• vilt
• clip
• donut
• trOCR
• flava
• x-clip
• clipSeg
• lxmert
• owl-ViT
• perceiver
• groupViT
• data2Vec
• layoutXLM
• visualBERT
• layoutLMV2
• layoutLMV3
• chinese-CLIP
• vision text dual encoder
• vision/speech encoder-decoder

2
10
35

8 May 2022
これは試してみたい!
VisualBERTでもそうですが,言語モデルへの入力をテキスト→画像に変えてうまく行くのは何とも不思議ですね
そして日本語T5モデルをせっせと大量に提供している言語処理屋さんがなぜ日鉄ソリューションズにいらっしゃるのかは最大の謎
qiita.com/sonoisa/items/618e…
41
270

11 Apr 2022
We found that all of these models are very poor overall: FLAVA, CLIP, UNITER, ViLLA, VinVL, VisualBERT, ViLT, LXMERT, ViLBERT, UniT, VSE , and VSRN. Can your model do better?
3/5
1
6

25 Mar 2022
Hugging Face (@huggingface) Transformer library also brings SSL models to computer vision.
It includes:
1. Vision Transformer by @GoogleAI
2. VisualBERT by @UCLA @allen_ai
3. DeIT by @MetaAI
1/2

1
12
45

24 Mar 2022
VisualBERT is a simple and performant Transformer-based baseline for vision and language. It reuses self-attention to align elements of input text & regions in the input image. It's pre-trained with masked language modeling and sentence-image prediction.
paperswithcode.com/method/vi…
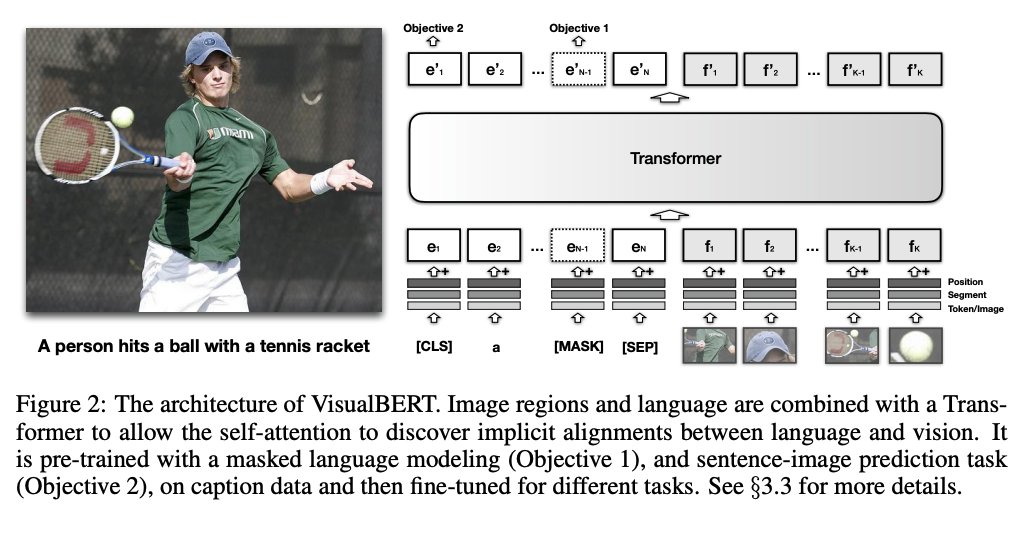
1
3
12

31 Jan 2022
🔥💫 Happy to have contributed ViLT (vision-and-language Transformer) in this release! It makes VQA painless, for the first time 😅. Most models have a complex CNN-based pipeline (like LXMERT, VisualBERT, etc.). ViLT on the other hand just adds text embeddings to an existing ViT!
31 Jan 2022

Try out VQA, which can combine vision and language effortlessly, in the Space below:
huggingface.co/spaces/nielsr…
1
8
64

22 Dec 2021
視覚と言語に関する記述は、特に気に入ってる。この領域でのTransformerベースの事前学習モデルの変遷(VideoBERT、ViLBERT、VisualBERT、Unicoder-VL、LXMERT、VL-BERT、UNITER、OSCAR、Pixel-BERT、VILLA、ERNIE-ViL、MiniVLM、VinVL、ViLT、Uniffied VLP、VL-T5、E2E-VLP、CLIP、DALL-E)など。
10
10
17 Nov 2021
related papers: bit.ly/3FlYSyF
VisualBERT: bit.ly/visualBERT (also the version in Huggingface🤗: bit.ly/huggingface-visualber…)
PLBART: bit.ly/PLBert (PLBART-large released recently)
1
1
17 Nov 2021
I gave a tutorial on Transferable Representation Learning in NLP at #ODSCWest. The talk summarizes our recent research on cross-lingual transfer, Vision&Langauge pre-training (VisualBERT), Programming&Natural Languages pre-training (PLBART) See slides: bit.ly/3wQNt7b
1
3
25
5 Nov 2021
Models that can be readily applied to computer vision tasks:
- Vision Transformer created by @GoogleAI
- VisualBERT created by @UCLA
- DeIT created by @facebookai
To use them in your project: huggingface.co/transformers/
3/3
10