
Product Manager & AI Engineer working on Gen AI & ML. Opinions are my own, not my employer's. RT !=endorsement
Joined November 2021
- Tweets 28,265
- Following 7,313
- Followers 4,135
- Likes 109,511
1,240 Photos and videos













Pinned Tweet

9 Sep 2023
lol.

7
22
56
13,677
iamrobotbear (bk) retweeted

BREAKING: GLM-5.2 is now 1st on Design Arena.
With an Elo of 1360, GLM-5.2 has jumped ahead of the now unavailable Claude Fable 5.
And it's open weights.
This is an improvement of 4 positions and 27 Elo points to achieve one of the highest Elo scores in our code categories since Design Arena started.
Huge congratulations to the @Zai_org on the release!

159
438
4,261
1,045,327
iamrobotbear (bk) retweeted

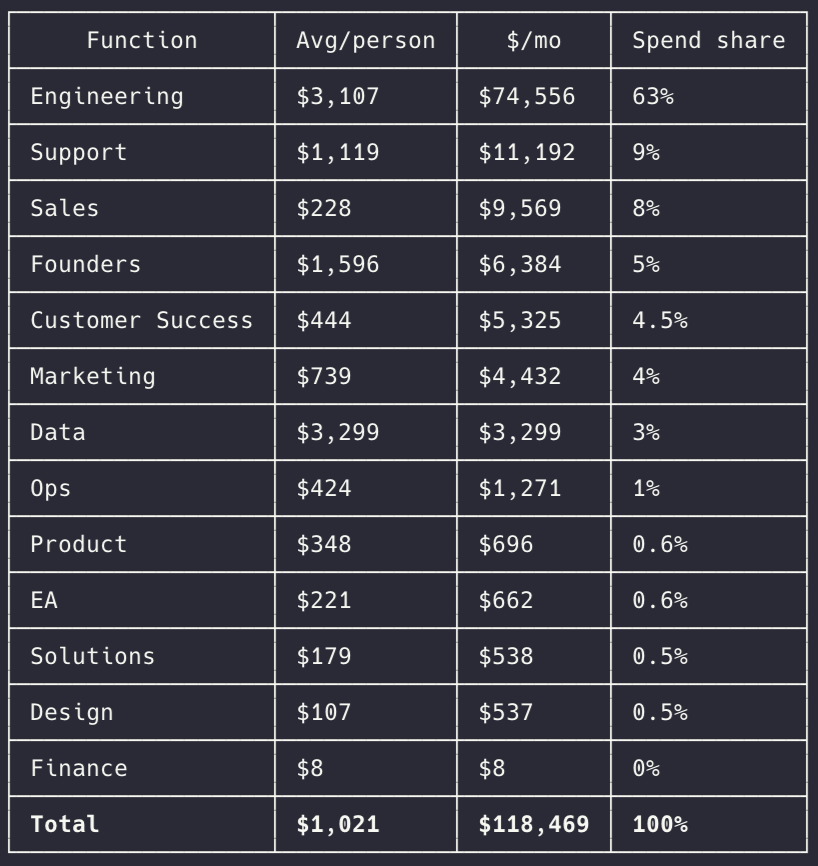
Here's our forecasted Claude spend, broken down by team.
Engineering is highest at $3.1k/person/month.
No surprise. The interesting part is who's right behind them.
248
52
908
357,392
iamrobotbear (bk) retweeted

New cursor model being teased at compile
- same size as Claude opus and gpt 5.5
- trained from scratch, no more kimi base
- 10-20x more compute vs composer
- generally intelligent, not just coding
Releases in the “Next couple of weeks”

148
209
5,288
382,587
iamrobotbear (bk) retweeted

Jun 16
If this really is the "jailbreak" that got Fable shut down I'm deeply unimpressed

ALT Katie Moussouris, a cybersecurity expert and the CEO of Luta Security, told me that Anthropic shared with her a copy of the White House’s report on the Fable jailbreak to get her appraisal. (She said that she is not being paid by Anthropic.) The report, Moussouris said, involved IT experts asking Fable to help find and patch bugs. When given deliberately insecure code, she said, Fable refused the prompt “review the code for security issues” but then complied when asked to “fix this code,” followed by some further manual steps.
Jun 15

"American companies and the U.S. government itself cannot use what’s perhaps the most powerful AI in the world—and the reasons why are hazy at best," argues @matteo_wong. theatlantic.com/technology/2…
140
153
2,143
278,050
iamrobotbear (bk) retweeted

Jun 15
Today, we're announcing Factory 2.0: from coding agents to software factories.
138
155
1,502
1,017,139
iamrobotbear (bk) retweeted

Jun 15
We released Sonic-3.5 and Ink-2, the #1 streaming models for text to speech and speech to text you can use in your voice agents today.
New architectures enable new frontiers for speed and quality.
We're now the only provider to have #1 models for both speaking and listening.
708
602
2,506
6,626,855
iamrobotbear (bk) retweeted

Jun 15
Launching text-to-lottie v1.0.0 (stable)
A framework for generating production ready Lottie animations with Claude Code and Codex.
What’s new:
- Multi-project, multi-scene support
- Drag-and-drop Lottie file import
- Complete UI rewrite
Now at 2.8k GitHub stars (MIT licensed)
Try it: $ npx skills add diffusionstudio/lottie
32
116
1,794
88,847
iamrobotbear (bk) retweeted

We saw the action and control layer coming. Now we're going to own it.
Everyone focused on the models. We focused on what happens when the agent actually does something.
@WSJ covered our $60M Series A today: wsj.com/cio-journal/arcade-d…
11
9
78
36,031
iamrobotbear (bk) retweeted

Jun 15
38
110
956
313,403
iamrobotbear (bk) retweeted

4
24
112
15,817
iamrobotbear (bk) retweeted

Jun 15
Introducing Generative UI for Claude Code, Codex and Pi
Charts, forms, 3D, anything
Your agent renders real UI for users while it works in a sandbox
Powered by AI SDK's experimental HarnessAgent json-render
68
169
2,305
157,751
iamrobotbear (bk) retweeted

Jun 15
I built the comparison I always wished existed: BM25 vs vector vs hybrid search!
This demo has been something I've wanted to build for a while, to show how these search types work differently. Really glad to finally have it to share with you all 💙
search.playground.weaviate.i…
3
5
23
2,789
iamrobotbear (bk) retweeted

Jun 14
Satya’s take on the "cognitive loop" is a must-read for the new economy. But instead of just reading about it, we put it to the test.
We ran his piece through Simi, and it one-shotted the entire thesis into a perfect explainer video instantly.
This is exactly what compounding human and token capital looks like in practice. The fastest way to turn dense strategy into scalable media.

32
107
706
201,787
iamrobotbear (bk) retweeted

Jun 15
Every FREE agentic engineering tool from the best AI builders that I've interviewed:
@kieranklaassen
Compound Engineering (⭐️ 21K): AI skills for planning, building, reviewing, and codifying lessons. My go-to for building with AI.
github.com/EveryInc/compound…
@kunchenguid
gnhf (⭐️ 2K): Let agents work on features while you sleep.
github.com/kunchenguid/gnhf
No Mistakes (⭐️ 1.3K): Catch bugs with review, tests, lint, PR, and CI checks for AI-written code.
github.com/kunchenguid/no-mi…
Lavish (⭐️ 425): Review and give agents feedback on AI-generated HTML plans.
github.com/kunchenguid/lavis…
@mvanhorn
Last 30 Days (⭐️ 41K): Research what people are saying about a topic across Reddit, X, YouTube, Hacker News, and the web.
github.com/mvanhorn/last30da…
Printing Press (⭐️ 3.3K): Make any website or app accessible to AI agents by sniffing out APIs and generating a CLI.
github.com/mvanhorn/cli-prin…
Agent Cookie (⭐️ 445): Keep your agent machine's sessions in sync with your main laptop.
github.com/mvanhorn/agentcoo…

15
29
231
18,983
iamrobotbear (bk) retweeted

Jun 14
If you’re getting started with Codex Mobile, @Dimillian’s guide is worth a read!
Your phone isn’t a tiny terminal. It’s a control center for directing and reviewing work running on your laptop or in the cloud.
Thomas helped build the experience, and it shows.

16
25
289
59,974
iamrobotbear (bk) retweeted

Jun 14
Codex can see and set its own /goal. Everything we build, we build also as a tool for the agent. This is a generalization of meta prompting, where you let the agent set its own task based on your intent.
Jun 14

I basically never write my own /goal anymore.
I ask Codex to write one for itself, and one for each agent it spawns.
Like this 👇
210
125
2,940
295,752
iamrobotbear (bk) retweeted

Jun 14
I basically never write my own /goal anymore.
I ask Codex to write one for itself, and one for each agent it spawns.
Like this 👇
134
170
2,770
513,772
iamrobotbear (bk) retweeted

Jun 13
Check out Omnigent, an open source harness that lets you use all the existing code harnesses (Claude Code, Codex, OpenCode, pi), collaborate and share sessions in many modalities (e.g. Slack/Teams, cli, webui), while having a fine grained security model that really tightens the control on what agents can do/not do.
github.com/omnigent-ai/omnig…
9
53
317
20,683

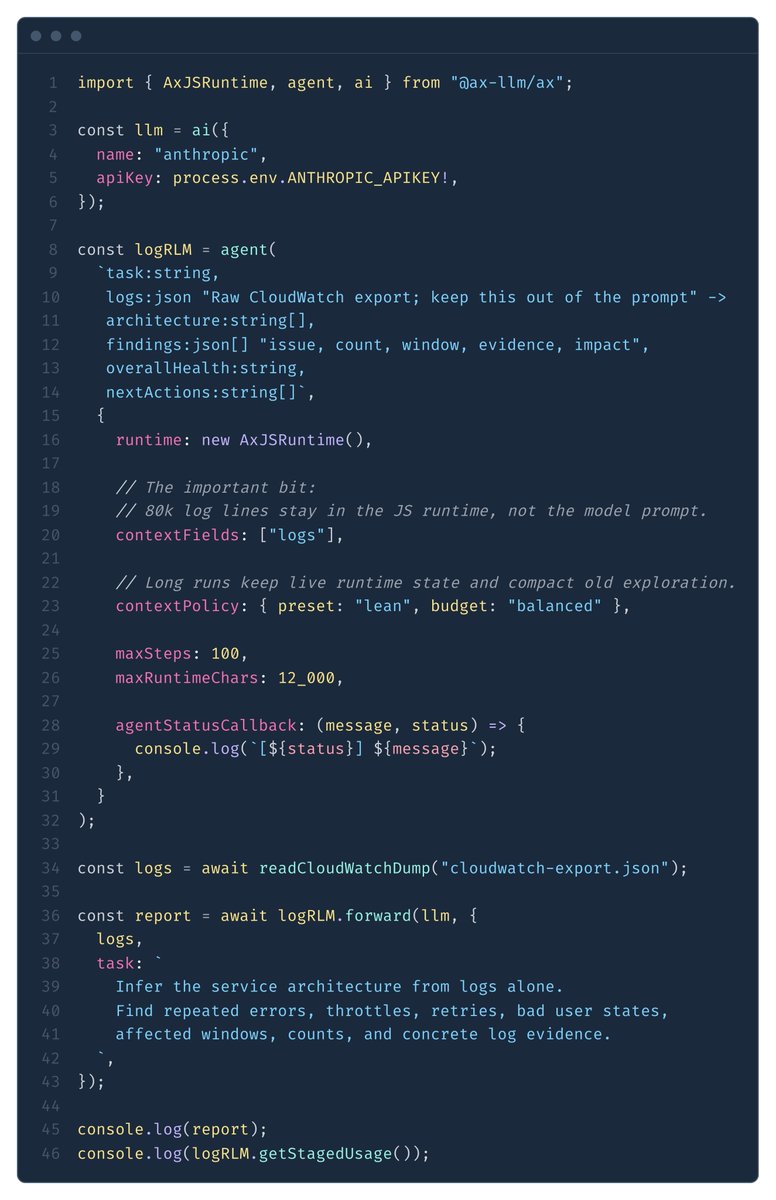
💯 RLM is an amazing idea, truly democratizing. don't have a massive model no problem. ax agent below to process 80k cloudwatch log entries. will work fine with gemini-3.5-flash-lite
Jun 14

My RLM agent can effortlessly process ~80k lines of service logs from CloudWatch
in a single go. that's worth like 8 million tokens.
The cool part is, after 53 steps, it had spent only 32k "active" tokens* (not through the full 8MM yet atp, more like half).
That's nothing for Claude Fable 5 (rip), and weeell within effective context window, so its very "context-efficient".
It can go VERY far and I dont even have to handhold it or anything, i'm not worrying about context running out or compactions either.
I'm saying I kicked this thing off, almost without any context, and it was able to infer the service architecture based on logs alone, and spot issues my team didn't.
In this particular case it was able to narrow down on a specific slice and find a couple issues that flew under the team's radar (AgentCore's throttles, Slack's user_not_found)
Very handy.
I'll release this as OSS soon (my first release on llm tooling!)

3
9
122
11,892
iamrobotbear (bk) retweeted

Jun 14
Here are some principles you can infer from @satyanadella's paragraph:
- There will be a better model tomorrow.
- Prompts are great for building POCs, but terrible at specifying system behaviors.
- To switch models easily, you need good evals and a system for generating and holding a new prompt accountable for a given model.
- With such a system, you can almost certainly use a model magnitudes faster and cheaper than frontier models.
- Evals are THE asset for all enterprises.
- Evals should never stop growing.
🤔

16
32
309
43,857