
Husband, Father #HealthIT #FinTech #GulfCoast #pinksocks @myligo_identity
Joined December 2008
- Tweets 18,480
- Following 5,332
- Followers 2,707
- Likes 35,082
832 Photos and videos
















Feb 4
Yesterday I drove my new car home; today I secured a $119,000 profit. A reminder that focus, patience, and consistency truly pay off when you trust the process. Grateful to my coach @CoachSelena11 for the guidance none of this was accidental. 📈
1
123
Jan 24
Man, I thank God every day I took that step of faith and trusted the process. Been seeing blessings ever since. Just got my new Truck 🚘🔥 hard work and crypto pay off! Don’t let nobody shake your vision. Big love to my @CoachSelena75


2
162
Jim St.Clair retweeted

Jan 24
50 People Joined Us to Learn and Talk About GI and Breast Cancer - Sarah Louden
@CooperHealthNJ
oncodaily.com/voices/sarah-l…
#OncoDaily #Oncology #Cancer #Health #Medicine #MedX

1
8
124
Jim St.Clair retweeted

Jan 24
👩⚕️👨⚕️ Clinicians deserve a seat at the AI table.
AI is entering exam rooms, notes, inboxes, and decisions — often faster than guidance follows.
We’re collecting real clinician experiences with AI in medicine:
✔ What actually works
✔ What doesn’t
✔ Where the risks are
⏱️ 5 minutes
🔒 Anonymous
🌍 All training levels & practice settings
📣 If you care about patient care, physician autonomy, and responsible AI — this is your moment to speak up.
👉 Take the survey:
docs.google.com/forms/d/e/1F…
🤝 Share with colleagues — collective insight beats isolated opinion.
#MedNewsWeek #PhysicianLeadership #AIethics #FutureOfCare #MedicineAndAI
4
5
6
648
Jim St.Clair retweeted

Jan 22
How are clinicians really using AI in practice? 🧠🩺📣
MedNews Week is running a short, anonymous survey to elevate real physician voices shaping the future of medicine.
Survey link:
docs.google.com/forms/d/e/1F…
Jan 22

📣How are you actually using AI in practice?📣
We’re running a very short, anonymous survey (⏱️ 5 minutes) looking at real-world AI use in medicine — from documentation to clinical decision-making.
✅ Any training level
✅ Any practice setting
✅ Whether you use AI daily, occasionally, or not at all
✅ Includes a brief clinical scenario
Your perspective matters — especially as AI tools are increasingly part of our workflows.
👉 Take the survey here: docs.google.com/forms/d/e/1F…
🙏 Please share with colleagues — broader input = better insights.
Thank you.
#AIinMedicine #DigitalHealth #AIinHealthcare #ClinicalPractice #PhysicianVoices
1
3
4
200
Jim St.Clair retweeted
Jan 22
Survey for Real-World Insights on AI Use in Medicine - @YLeyfman
oncodaily.com/voices/yan-ley…
#Cancer #OncoDaily #Oncology #MedEd #MedTwitter #MedX #MedOnc @CancerWorldmag

3
9
136

Don't miss your chance to join us on February 26 for a dynamic, one-day live virtual conference focused on translating evidence into action. Through engaging, real-world case studies and evidence-based initiatives, presenters will highlight a wide range of quality improvement and practice-based projects that have driven measurable improvements in clinical practice and patient outcomes within their institutions. View the full program and register: bit.ly/EBP2026
#MSKEBP2026 #MSKEBPCME #EvidenceBasedPractice #QualityImprovement #HealthcareInnovation @YLeyfman @JanisEnzenbach2 @kellyhaviland @nzd425 @DownerMuse @Sun_PhD

2
2
565
Jim St.Clair retweeted
Jan 23
Honored and truly grateful to be invited as a speaker at this prestigious forum at Memorial Sloan Kettering Cancer Center🌍✨
Excited to present two oral presentations focused on global oncology, translating evidence into action, and advancing efforts to combat inequities in cancer care worldwide 📊🧬🤝
Deeply thankful to my incredible mentors for their guidance, support, and belief — this work is only possible because of you 🙏💙
Looking forward to meaningful dialogue, learning from leaders across disciplines, and continuing the shared mission of improving cancer care for patients everywhere 🌎🔬 @DrArturoAI @CParkMD @MSK_DeptOfMed @MSKCME @MSKCancerCenter

Don't miss your chance to join us on February 26 for a dynamic, one-day live virtual conference focused on translating evidence into action. Through engaging, real-world case studies and evidence-based initiatives, presenters will highlight a wide range of quality improvement and practice-based projects that have driven measurable improvements in clinical practice and patient outcomes within their institutions. View the full program and register: bit.ly/EBP2026
#MSKEBP2026 #MSKEBPCME #EvidenceBasedPractice #QualityImprovement #HealthcareInnovation @YLeyfman @JanisEnzenbach2 @kellyhaviland @nzd425 @DownerMuse @Sun_PhD
2
5
374
Jim St.Clair retweeted

Don't miss the chance to connect with @VoteGiovanni and @TBC_Jessi tomorrow in Nashville at @bitcoinpark!

Our new President, @voteGiovanni, and Executive Director, @TBC_Jessi, are heading to NEMS in Nashville, hosted by @bitcoinpark_!
Giovanni and Jessi want to connect with you! If you don't think they're serious about it, we're calling your bluff. Here are their contacts, just for you:
Giovanni@texasblockchaincouncil.org
Jessi@texasblockchaincouncil.org
Set up your meeting ASAP!

1
6
442

Take a peek behind the scenes in this blog post from the Tutorial Chairs of AAAI-26 👀
blog.aaai.org/report-from-th…

1
5
1,000
Jim St.Clair retweeted

Jan 14
"We analysed 40,000 public social media posts on LinkedIn and Facebook, all in English, comparing what the same accounts were publishing a few years ago with what they post today. The short story: most people have stopped writing their own posts. Roughly 9 out of 10 posts we analysed from late 2024 onwards were generated largely or entirely by AI."
By @mariusdrag and Media and Journalism Research Center @MedJournResCen
Welcome to Slopfest 3000.
147
724
3,372
695,491
Jim St.Clair retweeted

Jan 11
Here is a short video that condenses my hour-long talk on MyTerms at Indiana University: youtube.com/watch?v=O2B76mKY… Does a pretty good job.
15
6
696
Jim St.Clair retweeted

Jan 9
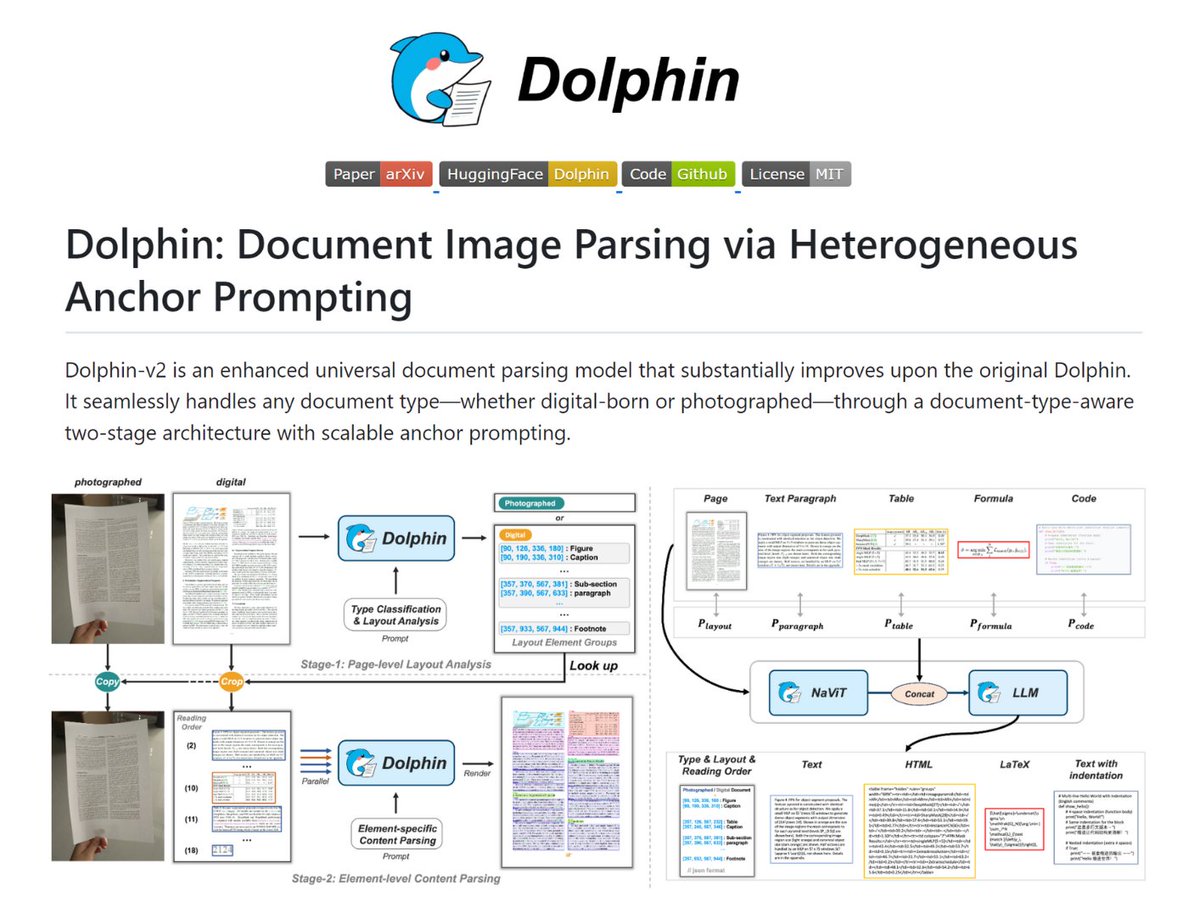
If you need structured Markdown/JSON from document images and PDFs, here is a useful tool – Dolphin
It works with multi-page PDFs, vLLM, TensorRT-LLM, HF.
- Dolphin detects whether a doc is scanned or digital
- Recovers layout reading order
- Parses text, tables, formulas, code with different strategies
- Runs element parsing in parallel when possible
Moreover, Dolphin scales from a lightweight 0.3B model to a 3B version and shows a big jump in quality (up to 89.8 on OmniDocBench)
5
32
182
10,418
Jim St.Clair retweeted

Jan 10
A tornado watch has been issued for parts of Louisiana and Mississippi until 4 AM CST
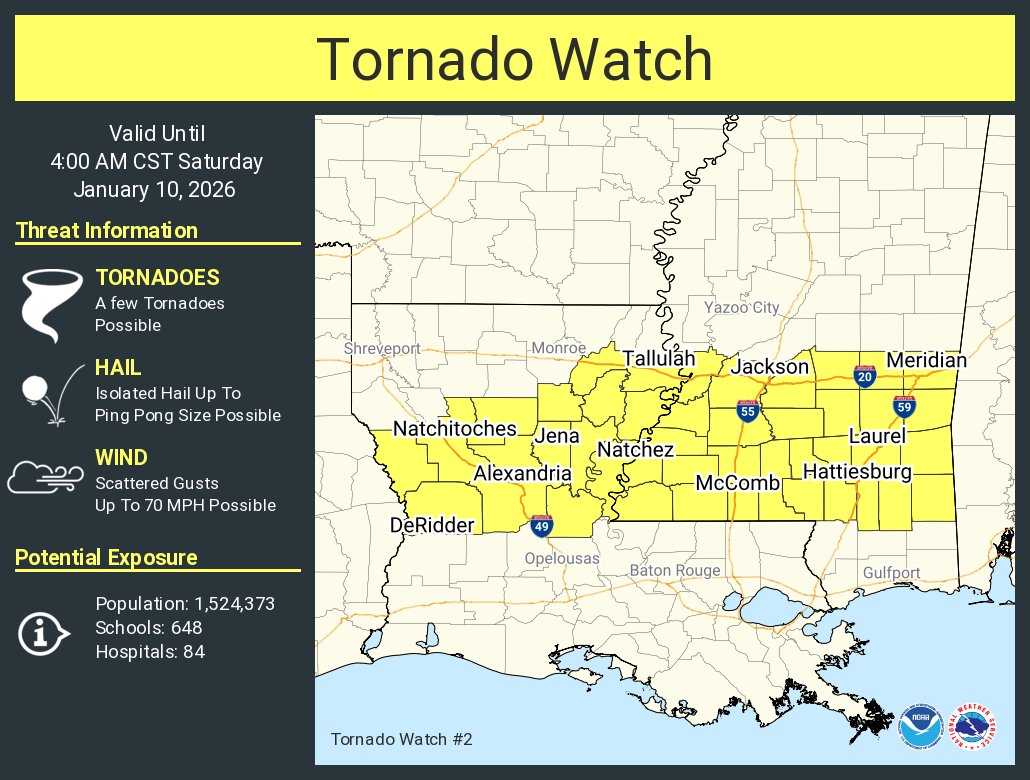
ALT This graphic displays Tornado Watch watch number 2 plotted on a map. The watch is in effect until 4:00 AM CST. The watch includes parts of Louisiana and Mississippi. The threats associated with this watch are a few tornadoes possible, isolated hail up to ping pong size possible and scattered gusts up to 70 mph possible. There are 1,524,373 people in the watch along with 648 schools and 84 hospitals.
1
14
37
16,974

the winner of health ai will look like:
“i understand you better than your doctor,
i notice patterns you can’t see,
i tell you why things matter,
i help you act today,
i make it feel worth doing tomorrow.”
biggest market on earth. infinite edge cases.
133
121
2,044
122,857
Jim St.Clair retweeted

Jan 7
The IGCS PRIME Researchship (Postdoctoral Research for Innovative Methods in Epidemiology) is a two-year fully virtual postdoctoral opportunity designed to develop future leaders in gynecologic oncology research.
Offered in collaboration with Drs. Alexander Melamed and J. Alejandro Rauh-Hain, PRIME provides intensive mentorship, advanced training in statistical methods for observational oncology data, and the opportunity to produce high-impact, peer-reviewed research—with only one fellow selected every two years.
📅 Apply by January 30
igcs.org/prime-researchship/



3
8
435
Jim St.Clair retweeted

Jan 6
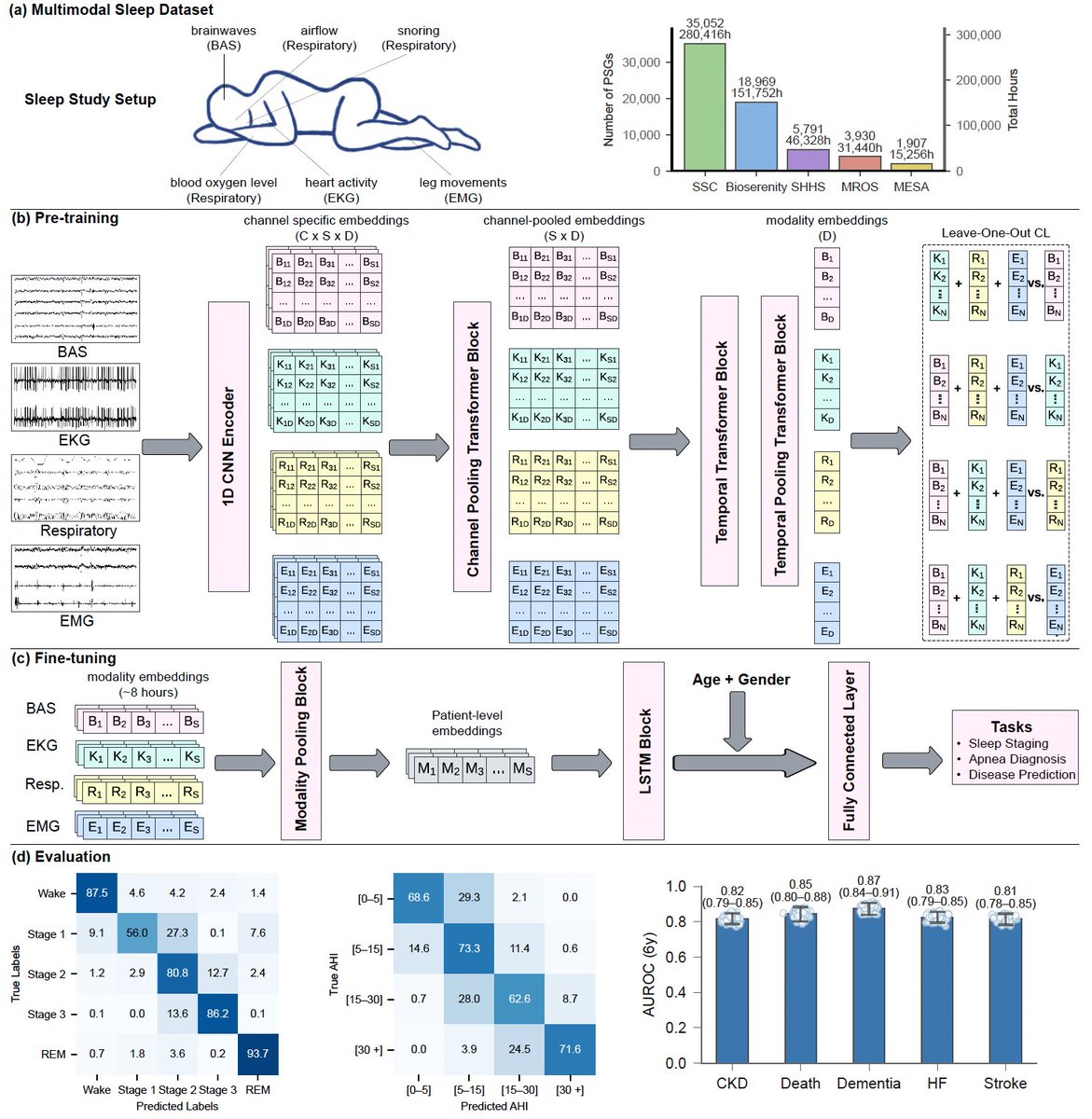
Today in @NatureMedicine we report that AI can predict 130 diseases from 1 night of sleep🛌
We trained a foundation model (#SleepFM) on 585K hours of sleep recordings from 65K people—brain, heart, muscle & breathing signals combined.
AI learns the language of sleep🧵

272
2,064
10,955
915,418
Jim St.Clair retweeted

Jan 2
Pete Golding just became an Ole Miss legend.
He took over a hurting fan base and has them on a full‑blown Cinderella run.
One of the most down‑to‑earth, easy‑to‑root‑for coaches in the country.
America is pulling for him.

272
624
13,968
223,091