
Haskell and PureScript, not necessarily in this order
Joined March 2009
- Tweets 4,531
- Following 389
- Followers 334
- Likes 16,577
469 Photos and videos
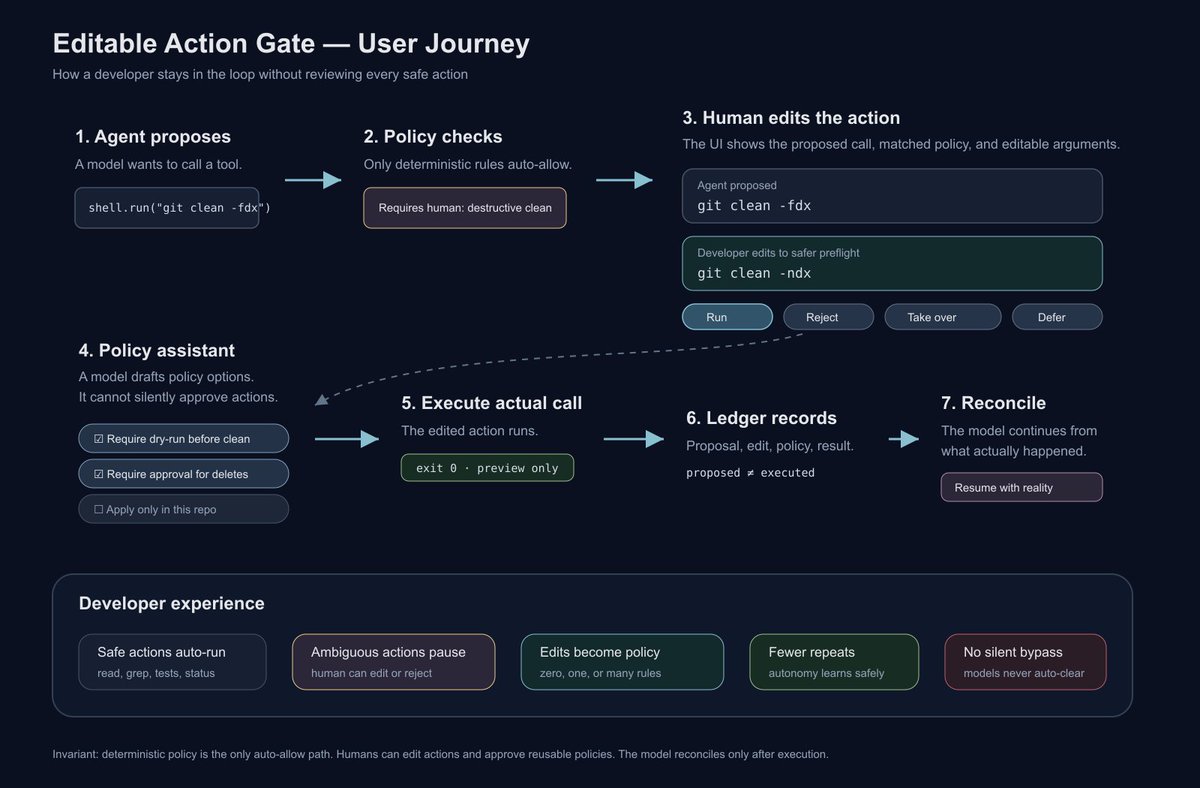











herdr 0.7.0 is out, and it's a major one: it introduces plugins!
the idea is simple: herdr stays lean, and everything custom gets extended through plugins. shareable, scoped, built however you want, to fit your own flow.
with this release we're also shipping a few examples of what the plugin system can do. first up: a telegram plugin.
herdr already controls your agents and knows their status, so the plugin just hooks into agent events and pings telegram the moment one needs you.
notification lands → `herdr --remote` or ssh from your phone → straight back to the agent that needs you.
11
12
138
20,101
KlarkC retweeted

Jun 12
I don't understand the obsession of the big labs with making the models bigger and fancier.
Well-targeted performance of AI is already superhuman.
Just advance context management in tooling, that has way more upside than adding another B to the model size.
9
3
64
7,559


KlarkC retweeted

Jun 8
Simon Peyton Jones is the co-creator of Haskell (pure functional programming language) and I interviewed him about functional programming, why it matters, and his thoughts on other programming languages.
In this episode:
• Useful and useless programming languages
• Rust vs C
• Haskell vs OCaml
• Why functional programming matters
• Static languages and their value for LLMs
• Why Excel is his 2nd favorite programming language
Where to watch:
• YouTube - youtu.be/xcB_LF3cdqw
• Spotify - open.spotify.com/episode/5d9…
• Apple Podcasts - podcasts.apple.com/us/podcas…
• Transcript - developing.dev/p/co-creator-…
Thank you to the sponsor of this episode for supporting my work:
• WorkOS: makes your app Enterprise Ready with easy to use APIs to add SSO, SCIM, RBAC, and more in just a few lines of code, check them out at workos.com/
Chapters:
00:00 - Intro
00:39 - What functional programming is
09:18 - Downsides of functional programming
10:53 - Specialized hardware for functional programming
21:47 - Haskell is useless
25:59 - Rust vs C
28:26 - Haskell vs OCaml
35:26 - Side effects in Haskell
44:26 - Type systems
57:30 - How the Haskell compiler works
01:04:35 - Why Haskell is talked about more than used
01:09:07 - Avoiding success at all costs
01:11:12 - LLMs and programming languages
01:13:57 - New programming language design
01:15:59 - Should students continue to learn programming
01:22:33 - Why Excel is is 2nd favorite programming language
01:25:04 - Advice for his younger self
29
107
728
121,845
Time to run local models

AI models are getting more expensive and worse at the same time
Claude Opus 4.6 - hits limits in 60 mins
Claude Opus 4.7 - hits limits in 15 mins
Claude Opus 4.8 - hits limits in 5 mins
Same story with Codex
Prices keep rising, they remove old models like GPT-5.3 and force you onto expensive new ones that burn through limits instantly
at this rate AI will soon cost more than hiring a employee
or will people just switch to local models instead?
13
KlarkC retweeted

May 26
🦀 The Rust frontend is officially merged into vLLM!
As GPUs get faster, the frontend has become a real share of CPU time. The new Rust frontend is a drop-in alternative to the Python API server — same engine, same ZMQ boundary. Opt in with VLLM_USE_RUST_FRONTEND=1.
Early numbers: on a preprocess-heavy workload, ~837 req/s vs ~162 req/s for default Python — ~5x in a single process.
A few design choices we're excited about:
• Layered crates with clear boundaries
• Stream-native pipeline — non-streaming for free
• Builds on stable Rust
Huge thanks to @BugenZhao from @inferact for introducing the work at @PyTorch Meetup Singapore.
github.com/vllm-project/vllm…



26
104
925
84,877
KlarkC retweeted
May 27
AI sucks at compiler development not least because humans do too.
The set of people who can design a programming language soundly and people who can contribute to an industry-grade compiler is ridiculously small.
So you get either a sound theory or a high-quality implementation, but rarely both, if ever.
And then LLMs go train on this dogshit plus toy compiler implementations plus book and courses which are just textual versions of toy implementations.
In the end all you get is unscalable compiler passes that trigger bugs the moment you attempt to use two uncommon features of your compiler together.
May 26

Status update: I've been on/off AI agents in the last few days and it is a verifiable truth that every day I didn't use agents, I was more productive. I still attribute that to how slow they are, and my own inability to multi-task efficiently. The magic is there but the slowness doesn't let it cross the threshold where they actually make me faster, and I still dislike the whole thinking paradigm.
About Bend2: honestly, the C/Metal compiler codebase is a clusterfuck right now. I regret letting AI agents write it. All tests pass, and GPU performance is mind-blowing, so the core architecture works. Yet, it has a LOT of bugs. Anything not covered by the tests is a coin toss. This is actually impressive, because, in many parts of the codebase, the right solution was actually the simplest one, yet, the agents STILL managed to find a way to make it work just for the tests. The level of reward hack these agents output is actually impressive I can't even be mad.
It is also ironical because that's the very problem that Bend's proof system was supposed to solve, but Bend is in TypeScript, not in Bend. I'm disappointed I didn't write Bend in itself, and now I feel an immense urge to do so. But the clock is ticking . . .
Still, I do not think Bend is worth launching without the GPU compiler being solid, because the closest competitor, Lean, is actually extremely good, so we need a big differential. Yet, due to the very nature of the project, it would be embarrassing to have bugs at launch.
Regarding AI, I now believe using current gen AI agents in production codebase is harmful and a massive mistake. That doesn't mean no agents at all, but agents work best when they don't touch critical code. Debugging, researching, providing insights, scripts / tools, or anything that doesn't touch code you will maintain in the long term. But if you merge AI code without reading, you're going to have a bad time. Speaking from experience
I'm working 10h/day on SupGen and the remaining time on Bend2
20
27
423
38,689
KlarkC retweeted

May 26
Status update: I've been on/off AI agents in the last few days and it is a verifiable truth that every day I didn't use agents, I was more productive. I still attribute that to how slow they are, and my own inability to multi-task efficiently. The magic is there but the slowness doesn't let it cross the threshold where they actually make me faster, and I still dislike the whole thinking paradigm.
About Bend2: honestly, the C/Metal compiler codebase is a clusterfuck right now. I regret letting AI agents write it. All tests pass, and GPU performance is mind-blowing, so the core architecture works. Yet, it has a LOT of bugs. Anything not covered by the tests is a coin toss. This is actually impressive, because, in many parts of the codebase, the right solution was actually the simplest one, yet, the agents STILL managed to find a way to make it work just for the tests. The level of reward hack these agents output is actually impressive I can't even be mad.
It is also ironical because that's the very problem that Bend's proof system was supposed to solve, but Bend is in TypeScript, not in Bend. I'm disappointed I didn't write Bend in itself, and now I feel an immense urge to do so. But the clock is ticking . . .
Still, I do not think Bend is worth launching without the GPU compiler being solid, because the closest competitor, Lean, is actually extremely good, so we need a big differential. Yet, due to the very nature of the project, it would be embarrassing to have bugs at launch.
Regarding AI, I now believe using current gen AI agents in production codebase is harmful and a massive mistake. That doesn't mean no agents at all, but agents work best when they don't touch critical code. Debugging, researching, providing insights, scripts / tools, or anything that doesn't touch code you will maintain in the long term. But if you merge AI code without reading, you're going to have a bad time. Speaking from experience
I'm working 10h/day on SupGen and the remaining time on Bend2
112
82
1,655
308,397
KlarkC retweeted

May 14
Imagine deploying 1,000,000 lines of code written in 6 days by AI that no human has ever read, let alone reviewed, to production where your customer’s data is.
Imagine

89
116
3,416
292,351
KlarkC retweeted

May 6
Linux booting on thermal paper live... 🤷♂️
66
483
5,195
194,540
🔥
Apr 22

🚀 Meet Qwen3.6-27B, our latest dense, open-source model, packing flagship-level coding power!
Yes, 27B, and Qwen3.6-27B punches way above its weight. 👇
What's new:
🧠 Outstanding agentic coding — surpasses Qwen3.5-397B-A17B across all major coding benchmarks
💡 Strong reasoning across text & multimodal tasks
🔄 Supports thinking & non-thinking modes
✅ Apache 2.0 — fully open, fully yours
Smaller model. Bigger results. Community's favorite. ❤️
We can't wait to see what you build with Qwen3.6-27B! 👀
🔗👇
Blog: qwen.ai/blog?id=qwen3.6-27b
Qwen Studio: chat.qwen.ai/?models=qwen3.6…
Github: github.com/QwenLM/Qwen3.6
Hugging Face:
huggingface.co/Qwen/Qwen3.6-…
huggingface.co/Qwen/Qwen3.6-…
ModelScope:
modelscope.cn/models/Qwen/Qw…
modelscope.cn/models/Qwen/Qw…

59



TurboQuant do Google explicado de forma simples:
O problema: LLMs guardam um "cache" (KV cache) de tudo que ja processaram na conversa. Quanto maior o contexto, mais memoria esse cache consome. Isso e o gargalo #1 de inferencia hoje
A solucao: comprimir esse cache de 16-bit pra ~3.5-bit sem perder qualidade
Como funciona:
1. PolarQuant transforma vetores em formato polar (magnitude direcao)
2. Quantized Johnson-Lindenstrauss projeta em espaco menor preservando distancias
3. Juntos = 4.6x menos memoria com 95% de fidelidade
Resultado pratico:
- KV cache usa 6x menos memoria
- Inferencia 8x mais rapida
- Sem retreinar o modelo
- Funciona em qualquer LLM existente
Por que derrubou acoes de DRAM: se LLMs precisam de 6x menos memoria, a demanda por chips de memoria cai. Micron, SK Hynix e Samsung sentiram o impacto
Isso nao e teoria. Ja tem implementacao no llama.cpp rodando em Macs com Metal

3
2
17
1,372