
Building offgrid Energy as a Service with renewables
Joined August 2009
- Tweets 4,688
- Following 447
- Followers 537
- Likes 5,799
112 Photos and videos
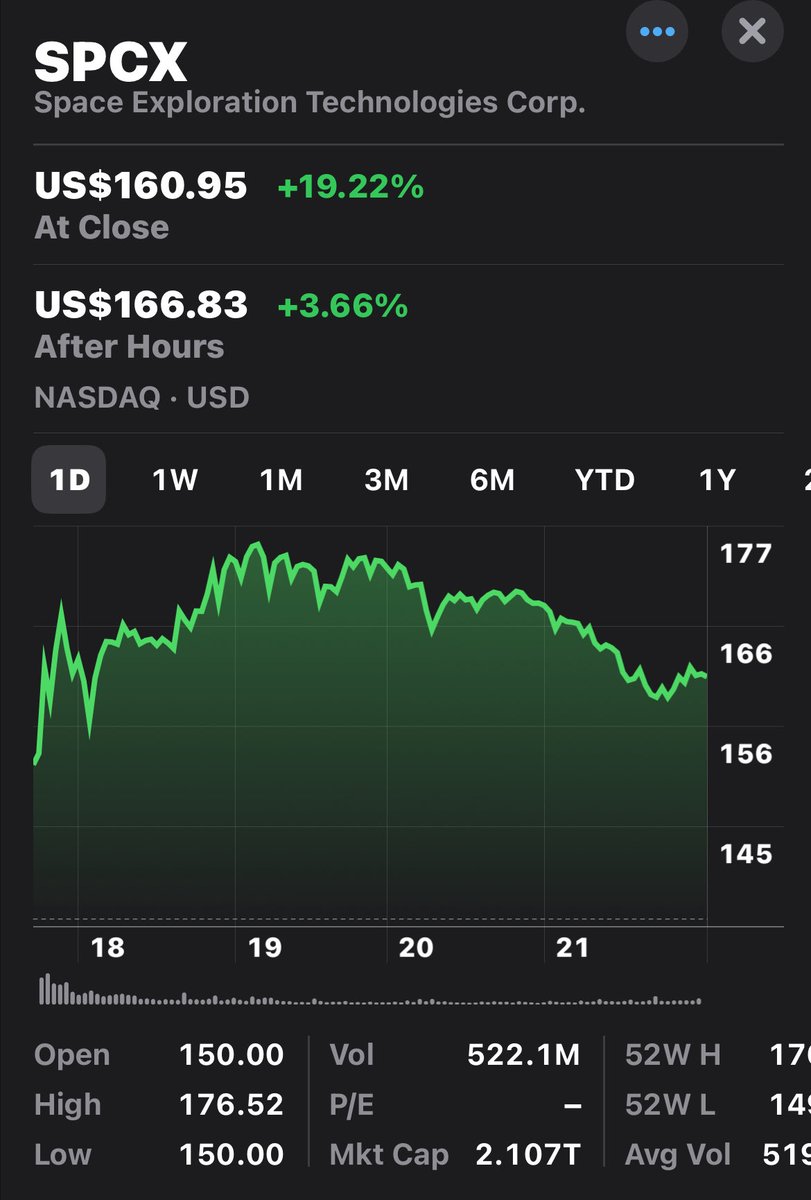
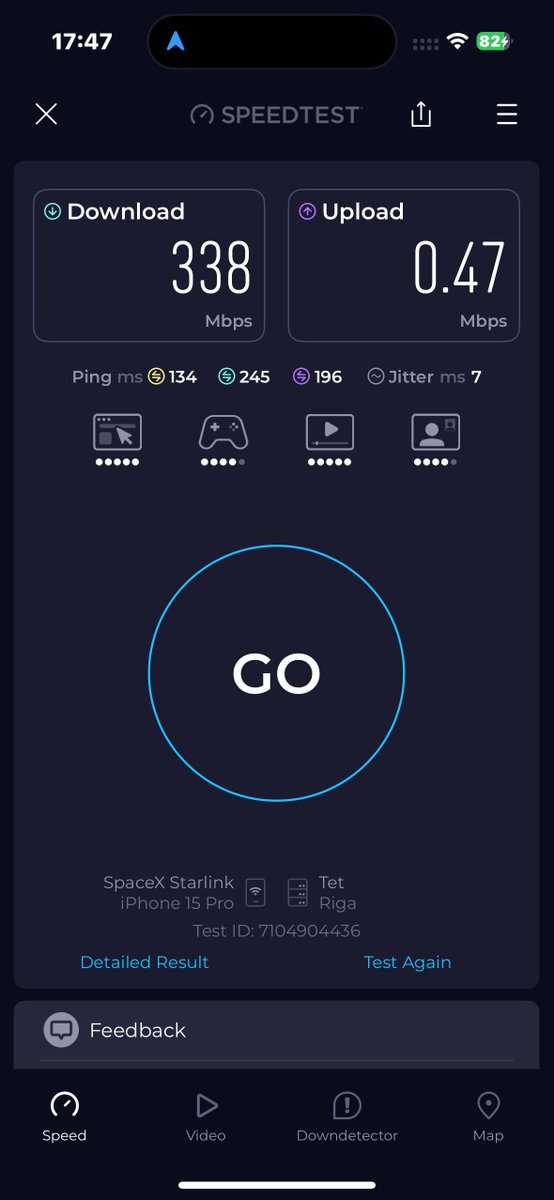





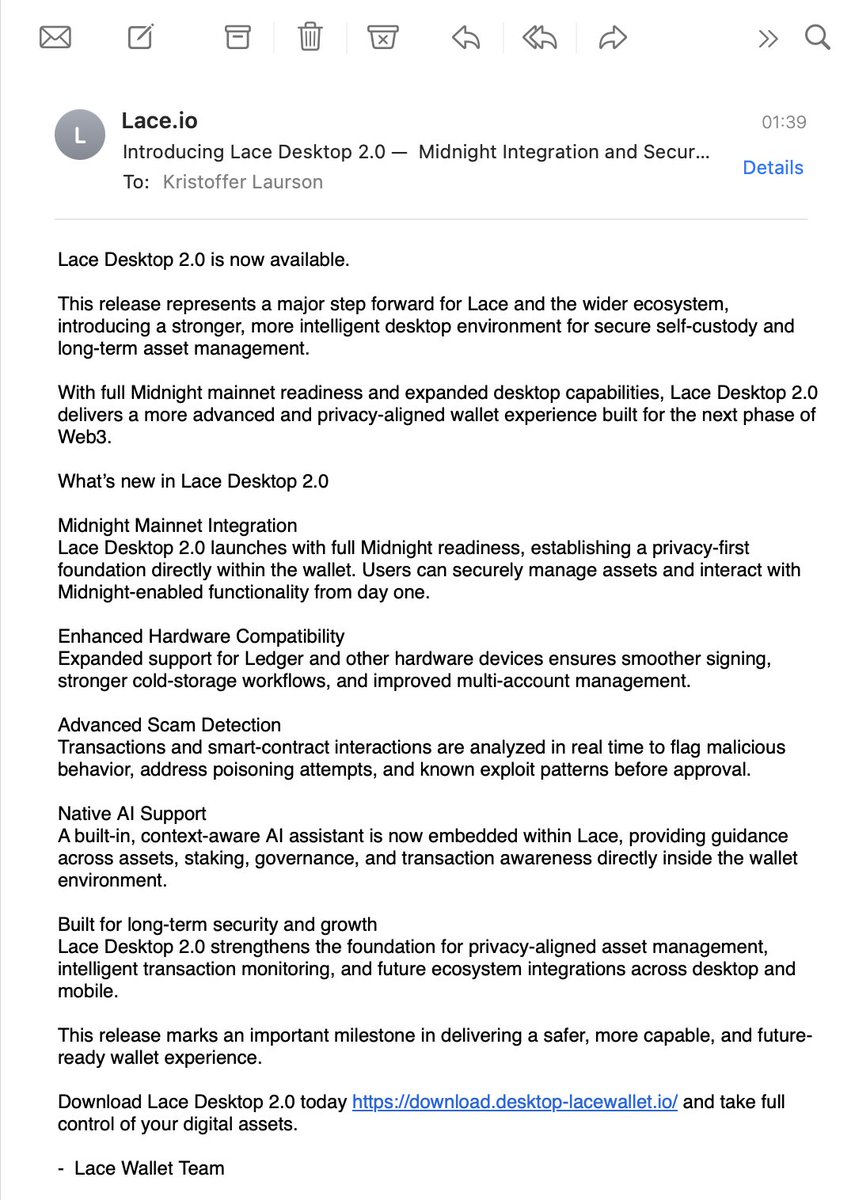
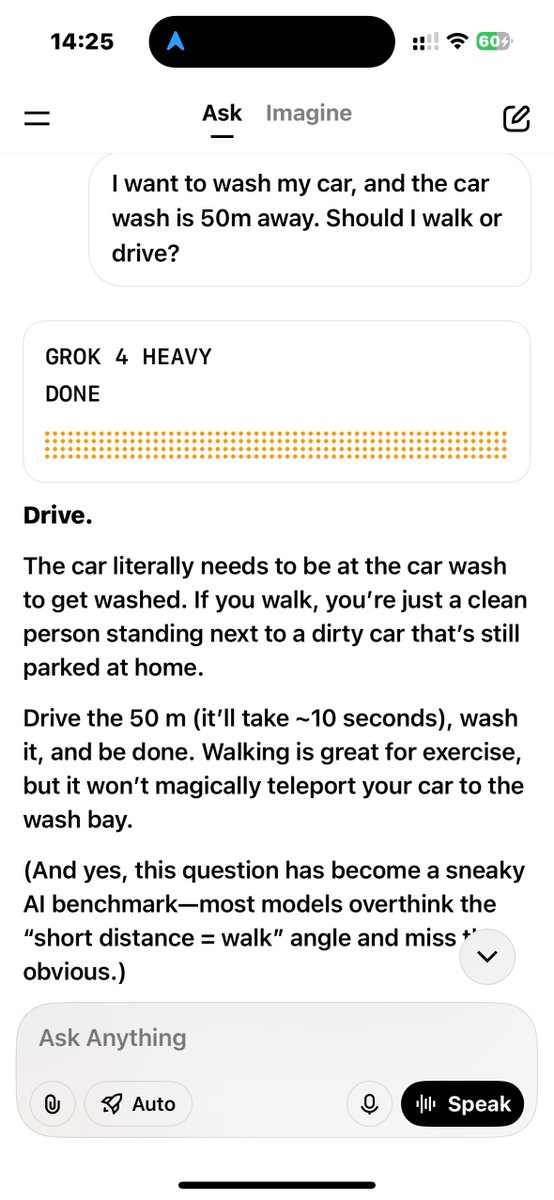



Kristoffer Laurson retweeted

I sent this letter to the Editor-in-Chief of Toxicology Reports demanding a full explanation for the removal of a published article examining vaccines and sudden infant death.
Americans have a right to know why scientific papers are removed, who made those decisions, what evidence supported them, and whether the same standards are applied consistently.
We will restore trust in public health by insisting on transparency, accountability, and open scientific inquiry—not by asking the public to accept decisions behind closed doors.


900
9,611
31,247
549,543

BREAKING 🚨 TESLA PATENTED "STARNET" TO SHOW THE WORLD HOW IT SQUEEZES SERVER-GRADE AI INTO $5 CHIPS 🐳
Deep neural networks have a dirty secret: they are mathematically expensive.
To see the world clearly, AI models typically crave the high-precision, energy-guzzling power of massive GPUs. But for a robot to be nimble or a car to be truly autonomous, it needs that same server-grade intelligence running on cheap, battery-sipping microchips.
This constraint usually forces engineers to choose between being "smart" or being "efficient".
Tesla just refused to choose.
According to patent US 2025/0292088 A1, Tesla has developed a new neural architecture called "StarNet" that fundamentally rewrites the rules of low-power computing.
Instead of dumbing down the AI to fit on a simple chip, StarNet uses a novel "mathematical cage" to force complex deep learning to run safely on constrained 8-bit processors. These simple chips can typically only handle small, integer numbers.
This is the blueprint for how Tesla plans to embed high-level decision-making into every joint of a robot and every sensor of a car. It unlocks a future where sophisticated AI lives on the edge, not in the cloud.
But to understand why this is such a breakthrough, we first need to understand the mathematical wall that has stopped everyone else.
⚖️ The problem: The heavy burden of floating-point arithmetic
The central challenge in deploying artificial intelligence to "edge" devices—like sensors in a car, components of a robot, or smart home appliances—is that these devices typically lack the computing power of a massive server farm.
Traditional deep neural networks rely on high-precision mathematics, specifically 32-bit floating-point arithmetic, to process images and data accurately. This format allows computers to handle an enormous range of numbers with extreme precision, similar to using a scientific calculator that can calculate out to dozens of decimal places.
However, this requires expensive, power-hungry processors that are not feasible for every small component in a vehicle or robot.
When engineers try to run these networks on cheaper, low-power chips that use simpler 8-bit integer arithmetic, they run into a critical mathematical wall. The simplified processors often use "signed" integers where the maximum value is very low, specifically 127.
Think of this limit like a small odometer on a bicycle that can only count up to 127 meters. When a neural network tries to add up thousands of calculations from a filter, the numbers often exceed this limit, causing an "overflow".
When an overflow happens, the odometer doesn't just stop. It wraps around to a negative number, producing a wildly incorrect result that effectively breaks the AI's ability to recognize objects or process data.
To overcome this hardware limitation without crashing the system, Tesla had to reinvent the neural network from the ground up.
✨ Tesla's solution: The StarNet Architecture
Tesla's solution is a novel neural network design dubbed "StarNet", explicitly engineered to operate within the strict confines of 8-bit arithmetic while preventing data overflows.
To understand the difference, imagine 32-bit floating-point math—the standard for modern AI—as a massive 12-lane highway. It has plenty of room for huge trucks (large numbers) and tiny motorcycles (small decimals) to travel side-by-side without ever touching the guardrails. This offers a massive "numerical safety net" where calculations can be sloppy or large without breaking the system.
However, the inexpensive Digital Signal Processing (DSP) cores found in cars and robots are more like a narrow bike path. They often rely on non-saturating signed 8-bit integers, where the maximum representable value is a mere 127.
If a standard neural network tries to run on this hardware, it is like trying to drive a semi-truck down that bike path. The sum of its calculations would almost immediately exceed 127, causing an integer overflow. This results in garbage data, effectively crashing the vehicle's intelligence.
Simply shrinking the network isn't enough; the fundamental topology—the architectural floor plan of how the neurons are wired together—must change.
StarNet solves this by shifting the burden of precision. Instead of relying on the hardware to handle large numbers, the architecture itself is designed to remain "numerically quiet".
Think of it like being in a library. If you can't build thicker walls (better hardware) to handle noise, you must enforce a strict "whisper-only" rule (StarNet). By intentionally keeping the internal numbers small so they never shout louder than "127", the system ensures it never hits that ceiling.
It achieves this through a ground-up redesign of how filters are shaped and how data flows. By enforcing a "mathematically guaranteed safety" protocol at the architectural level, StarNet allows Tesla to bypass the slow, power-hungry CPUs entirely.
Instead, they can run sophisticated AI exclusively on highly efficient, specialized DSP cores. These cores are essentially simple, high-speed calculators that were previously thought to be too basic for deep learning.
This new architecture isn't random; it follows a very specific, recurring recipe designed to maximize efficiency.
🏗️ The Blueprint: The "Star-Shuffle" recipe
The patent provides the exact recipe for the "Star-Shuffle Block", the atomic unit of this neural architecture. Tesla’s engineers found that a random arrangement of layers wouldn't work. Instead, they defined a strict recurring sequence: {1x1-conv, ReLU, Star-Conv, ReLU, Shuffle}. This specific order is critical, functioning like a highly efficient assembly line where every component has a non-negotiable role.
The process starts with a 1x1 convolution, which acts as the "Mixer". This step ignores the shape of the image and looks strictly at the "depth" of the data at a single point. It mixes the information across channels—like combining the Red, Green, and Blue data of a pixel into a single color concept, like Purple. This allows the network to combine raw inputs into complex features before passing them down the line.
Immediately following this is the ReLU (Rectified Linear Unit) function, the "Gatekeeper". Despite the complex name, it acts like a bouncer, filtering out irrelevant "negative" data. By blocking negative signals and only letting positive ones pass, it keeps the signal clean and introduces "non-linearity", the mathematical magic that allows AI to understand curves. Crucially, this filtering process also keeps the math simple enough for 8-bit hardware to handle efficiently.
Once the features are mixed and cleaned, the Star-Conv steps in as the "Scanner". It looks at the center pixel and its neighbors to understand shapes and edges. This is where the architecture's genius lies: by sandwiching this spatial processing between the channel mixing and the non-linear activations, the network maximizes its learning capability. It processes the "what" (color concepts) before the "where" (shapes), saving massive amounts of computing power.
Finally, the block concludes with a Shuffle layer, the "Networker". Because the previous steps often split data into isolated groups to save energy, the network risks becoming "siloed". The Shuffle layer acts like a mandatory networking event, rearranging the channels to force information from different groups to mix. This ensures the left hand always knows what the right hand is doing, preventing the efficiency hacks from compromising the AI's intelligence.
While this recipe sets the structure, the real efficiency gain comes from changing the shape of the filters themselves.
🌟 The "Star-Conv": The carpool solution
A standard convolutional neural network typically looks at the world through a square grid of 9 pixels. To understand an image, it has to combine the data from all 9 of these points at once.
Think of this like trying to squeeze an entire baseball team (9 players) into a small 4-seater car (the low-power chip).
It simply doesn't fit. If you try to force everyone in, the car breaks down. In computing terms, adding up 9 separate numbers creates a total sum that is too "heavy" for the tiny chip to carry, causing the system to crash.
Tesla's patent introduces a solution called the "star-shaped convolution". Instead of a square, it uses a cross shape ( ). It looks only at the center pixel and its four direct neighbors (Up, Down, Left, Right), ignoring the corners.
This reduces the group size from 9 players down to 5 (a basketball team).
Suddenly, the team fits into the car. By leaving the 4 "corner players" behind, the total weight drops significantly, guaranteeing the car never breaks down.
Crucially, this smaller team can still win the game. By focusing on the main directions (North, South, East, West), the AI can still recognize vertical lines, horizontal edges, and curves just as well as the larger group. It is like sketching a portrait using only 5 main strokes instead of 9—the picture is just as clear, but it takes much less effort to draw.
But geometry alone isn't enough; to truly guarantee safety, the system also needs to strictly manage the "volume" of the data itself.
🔢 The "(2 s)" Math: Extreme bit-counting
To strictly prevent data overflows, the patent introduces a specific notation for "bit-budgeting", such as (2 s). This stands for "2 bits of data plus 1 sign bit".
In plain English, this forces the computer to work with tiny numbers. While a standard computer counts in millions, this system restricts variables to a maximum value of just 3.
To understand why this is necessary, imagine the microchip is a small room with glass windows. The "sum" of the calculations is the noise level in that room. The physical limit of the chip is 127 decibels. If the noise hits 128, the windows shatter and the system crashes.
To keep the windows intact, the patent outlines a sliding scale of "volume control" that changes based on how many "voices" (pixels) are speaking at once:
For a large 32-element filter: Think of this as a large choir of 32 singers. If everyone sings at the top of their lungs, the windows will definitely shatter. Therefore, the system enforces a strict "whisper only" rule. It limits the volume of the input (loudness) to a max of 3 and the weight (emphasis) to a max of 1. Even if all 32 singers whisper as loud as they are allowed, the total noise is 32 * 3 * 1 = 96. This is safely below the 127 limit, guaranteeing the glass won't break.
For a medium 16-element filter: This is like a small discussion group. Since there are fewer people, the strict whispering rule can be relaxed. The system allows the volume to go up to 7 (talking normally). The worst-case math becomes 16 * 7 * 1 = 112. It is louder, but still safely under the 127 limit, allowing the AI to be more precise with these details.
For a small 8-element filter: This is like a jazz quartet. With so few musicians, they have the freedom to play much louder. The system allows both the input volume and the instrument weight to go up to 3. The safety calculation is 8 * 3 * 3 = 72. This is well within the safe zone, proving that by strictly managing the "volume" of the data, Tesla can push the hardware to its absolute limit without ever risking a crash.
To ensure these tiny numbers still represent the real world accurately, the system uses a smart translation process.
📉 Smart Quantization: The "A" and "B" formula
To make this low-bit math work without making the AI "dumber", StarNet employs a rigorous linear quantization strategy. It’s not enough to just "round down" numbers; the system must intelligently compress them.
The patent reveals that every single layer in the network is assigned two learnable parameters: A (scale) and B (bias).
The patent explicitly defines the relationship using a linear equation: the quantized value (V_Q) is calculated by taking the real-world value (V_R), dividing it by A, and then subtracting B. These parameters act like a precise conversion formula, similar to how you use a formula to translate temperature from Celsius to Fahrenheit.
But how does Tesla find the perfect A and B? The patent details a "Calibration Phase".
Before the neural network is ever deployed to a car or robot, a test dataset is passed through it one example at a time. The system records the absolute minimum and maximum output values for every specific layer.
These extremes are then plugged into a system of linear equations to solve for the precise A and B values that will fit that specific layer's data into the target bit-width (e.g., 0 to 3) without overflowing. This effectively creates a custom-fitted mathematical guardrail for every single neuron, ensuring that no matter what image the AI sees, the internal math will always remain safe and stable.
Once the parameters are set, Tesla applies one final trick to speed up the process even further.
🧮 "Quantization Collapsing": The speed hack
One of the most granular innovations in the patent is a technique called "Quantization Collapsing".
In a standard low-bit network, the system is constantly stuck in a loop of conversion: de-quantizing the output of one layer back into a 'real' number, only to immediately re-quantize it for the next layer. This is like translating a sentence from English to French, and then immediately translating it back to English before moving on. This back-and-forth wastes valuable computing cycles.
Tesla’s solution is to mathematically fuse these adjacent steps.
The patent describes a mechanism where the de-quantization equation of one layer and the quantization equation of the next are collapsed into a single, pre-calculated operation. This reduces the computational load by a factor of two.
Even more radically, the patent notes that for certain sequences, the system can "leave out both of them" entirely. This allows the network to run a chain of calculations using only an initial quantization at the start and a final dequantization at the end, effectively eliminating the computational middlemen and keeping the data in its fast, efficient 8-bit form.
However, all this efficiency comes with a risk: the network can become too compartmentalized. The next component solves that.
🔀 The Shuffle Layer: Breaking the silos
One side effect of using these highly efficient filters—specifically "group convolutions" where the group length is greater than 1—is that the network effectively splits into several independent, isolated mini-networks.
The patent notes that while the standard 1x1-conv layers can mix information between "nearby" channels, they cannot reach across to other groups. This means features learned in one part of the network are completely invisible to the rest, severely limiting intelligence. This is similar to different departments in a company refusing to talk to each other, preventing the organization from seeing the big picture.
To solve this, StarNet implements a "shuffle" layer at the end of every block.
Just like shuffling a deck of cards, this operation takes the output data and strictly interleaves the channel ordering. The patent explicitly states that this enables communication across "far-away channels" that would otherwise remain isolated.
By forcing these independent groups to mix, the "Star-Shuffle Block" regains the representational power of a massive, fully connected network while retaining the extreme speed of a sparse, grouped one.
With the core architecture optimized, Tesla addresses the final hurdle: how to handle the very first glance at the world.
🤝 Hybrid Processing: CPU and DSP teamwork
Finally, the patent reveals a pragmatic "hybrid" hardware approach. While the goal is to use 8-bit arithmetic for speed, the inventors acknowledge that quantizing the very first input image too aggressively destroys accuracy immediately. You can't recover from bad data at the start.
To solve this, StarNet-A (an example architecture in the patent) creates a specific "First Layer Exception".
The very first layer—a Star-Conv with a stride of 2—is not run on the accelerator. Instead, it is computed on the device's general-purpose CPU using 16-bit arithmetic and 16-bit temporary storage.
This allows the system to ingest the raw, high-resolution RGB image and perform the initial feature extraction and downsampling, which is a process of shrinking the image size to make it easier to manage, with maximum precision.
Once this critical "first impression" is secure, the data is handed off to the specialized, high-efficiency DSP (Digital Signal Processor) cores for the remaining dozens of layers. This "tag-team" approach ensures the network starts with high-fidelity vision data before switching to ultra-low-power processing for the heavy lifting.
So, what does all this technical wizardry actually mean for Tesla's future?
🚀 How this patent contributes to Tesla's now and future
This patent is the "missing link" that explains how Tesla plans to scale from smart cars to ubiquitous robotics. While the industry obsesses over massive GPUs in data centers, Tesla has quietly solved the opposite problem: how to put a "brain" into a dollar-store microchip.
The most immediate application is likely the technical foundation for the "spinal cord" of the Tesla Bot (Optimus). A humanoid robot cannot route every single twitch of a finger or balance correction of an ankle to a central computer in its chest—the latency, or delay, would be too high and the power drain too massive.
StarNet allows Tesla to embed tiny, 8-bit neural networks directly into the local actuator controllers at each joint. This effectively gives Optimus a "peripheral nervous system", allowing hands and legs to handle their own reflex-level processing locally using simple DSPs, freeing up the central AI5 computer for high-level reasoning.
This distributed approach is equally critical for the upcoming Cybercab and Robotaxi fleet, where cost and redundancy are paramount. Redundancy here refers to having backup systems that ensure safety if the primary system fails.
By validating that high-accuracy vision can run on 8-bit DSPs, Tesla can install intelligent, redundant camera modules that process data before it even hits the main computer. If the main FSD computer were to glitch, these decentralized "smart eyes"—running unbreakable, overflow-proof StarNet code—could theoretically maintain enough visual awareness to pull the vehicle over safely.
Beyond vehicles, this architecture enables a "Smart Dust" approach to the Alien Dreadnought factory. Tesla’s manufacturing strategy relies on extreme automation, and StarNet enables cheap sensors embedded in casting machines and stamping presses to detect defects or wear in real-time.
Because the architecture is designed for "embedded devices" with strict bit-budgets, these smart sensors can run on harvested energy or tiny batteries. This turns the entire Gigafactory into a living, sensing organism without requiring expensive server racks to process the data.
Ultimately, this innovation builds a massive economic moat based on pure efficiency.
While competitors are building autonomous systems that rely on expensive, power-hungry NVIDIA Orin or Thor chips running heavy floating-point math, Tesla can achieve similar inference results using commodity 8-bit DSP hardware that costs a fraction of the price. Inference results is the technical term for the AI making a real-world decision based on what it sees.
Over a fleet of millions of cars and robots, saving $100 per chip adds up to billions in profit, effectively weaponizing mathematical efficiency to scale intelligence faster and cheaper than anyone else.
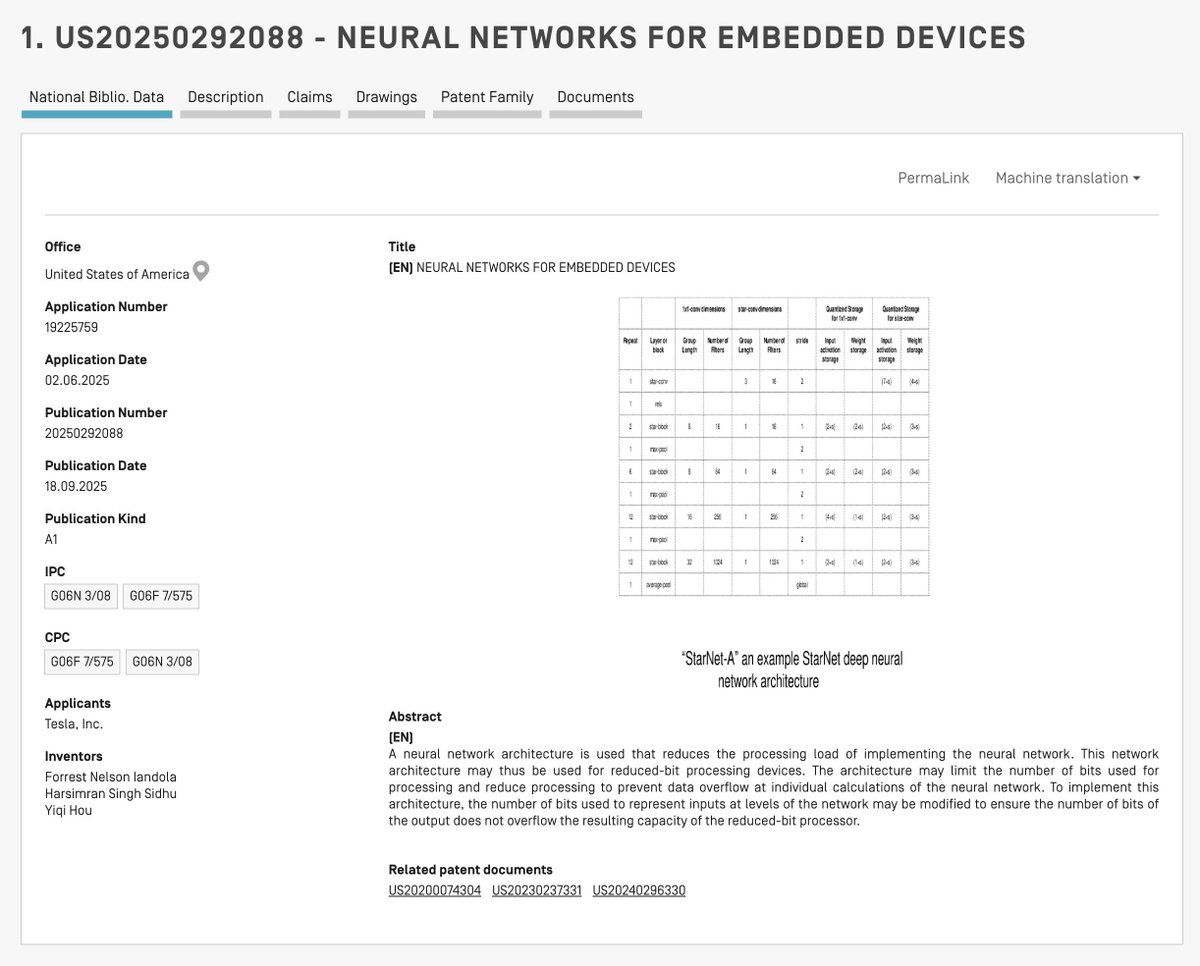
47
104
647
739,952

Jun 14
Bluesky is so burning it stops anyone from wanting to be on some
Jun 14

🚨BREAKING: Keir Starmer’s blocked social media sites list for under 16’s has been released
- TikTok
- YouTube
- Snapchat
- Instagram
- X (formerly twitter)
- Reddit
- Facebook
- Twitch
- Kick
- Threads
Note leftist site bluesky is not blocked
26
Kristoffer Laurson retweeted

Jun 13
Undecided on vaccines?
Here’s some important questions to ask your pediatrician or physician. Ask them to answer without appealing to authority, consensus, or mathematical models:
1. Could you point me to the double-blind, randomized, placebo-controlled trial(s) (using an inert placebo) that established the long-term safety profile of any of the vaccines on the CDC’s childhood schedule?
2. In what way was the CDC’s childhood vaccine schedule empirically demonstrated to be safe when multiple vaccines are administered at once? For example, more than two-dozen doses by 12 months of age, per the CDC schedule?
Were any double-blind, randomized, placebo-controlled trials (using an inert placebo) conducted to assess the combined or cumulative effects of receiving multiple vaccines simultaneously?
3. Are there any studies comparing the long-term health outcomes of completely unvaccinated children to those who are fully vaccinated according to the CDC schedule?
If not, why?
And without that data, on what empirical basis can anyone confidently claim that vaccines are “safe and effective,” when these types of studies are the ones that would actually demonstrate both safety and efficacy?
4. I’ve often heard experts claim that inert-placebo trials for licensed vaccines and a totally unvaccinated vs. fully vaccinated study are “unethical.”
But doesn’t that reasoning itself presuppose the very safety that such trials are meant to test?
Are you suggesting it’s unethical to test a product’s safety unless we already assume it’s safe?
Without that data, on what empirical basis can anyone confidently claim that vaccines are “safe and effective,” when these types of studies are the ones that would actually demonstrate both safety and efficacy?
5. When “placebos” are used in vaccine trials, what do they actually contain?
If they’re another vaccine or an aluminum-containing solution, how can that design detect potential harm from the adjuvants or other vaccine ingredients?
6. What research has measured the total impact of giving infants multiple aluminum-adjuvanted vaccines, taking into account the total amount injected, the baby’s small body size, and their still-developing kidneys?
And if that data doesn’t exist, how do health authorities determine that giving all of these shots together is safe?
7. From my understanding, the primary studies used to justify the safety of aluminum adjuvants when injected are the Flarend et al. (1997) biodistribution study involving four adult rabbits, and the Mitkus et al. (2011) modeling paper based on ingested aluminum in adults, not injected aluminum in infants.
Could you clarify how those studies empirically demonstrate safety in the context of routine pediatric injections?
Were there any double-blind, randomized, placebo-controlled human trials using inert placebos to confirm those findings, or is the assumption of safety based solely on these limited animal and modeling studies?
8. Most vaccine “effectiveness” claims are based on antibody titers rather than real-world reduction in disease or all-cause mortality.
Can you point to empirical evidence showing that antibody levels reliably correlate with actual protection and improved long-term health outcomes?
If not, how can “effectiveness” be scientifically validated beyond a surrogate marker?
9. I’ve read that roughly 75% of the FDA’s drug-regulation budget comes from pharmaceutical companies through the Prescription Drug User Fee Act.
How can we be confident that vaccine approvals and safety reviews are completely objective when the agency’s funding depends so heavily on the companies?
Are there genuine safeguards in place to prevent conflicts of interest or bias in the approval and monitoring process?
…continued
35
119
374
12,111
Kristoffer Laurson retweeted

Jun 12
Today, I’m releasing never before seen intelligence revealing new evidence of past US government funding for more than 120 biolabs in over 30 countries, including Ukraine.
In support of President Trump‘s Executive Order to end federal funding of dangerous gain of function research around the world, and increase transparency and accountability, ODNI will continue working with partners across the Administration to identify where these labs are, what pathogens they contain, and what “research” is being conducted.
odni.gov/index.php/newsroom/…
16,134
83,019
286,711
41,187,073
Kristoffer Laurson retweeted

Jun 12
The sheer scale of a trillion dollars can be hard to comprehend. Let me put it in perspective. You would be able to buy 42 miles of high speed rail in California with that much money.
Jun 12

The sheer scale of a trillion dollars can be hard to comprehend. Let me put it in perspective. You would have to earn a dollar a year for a trillion years straight to have that much money.
352
2,228
28,353
883,365
Kristoffer Laurson retweeted

Jun 13
Jos ei halua oppia suomen kieltä, kunnioittaa maan kulttuuria, tapoja ja lakeja, mennä töihin ja tehdä Suomesta kotinsa itselleen ja lapsilleen, niin on syytä harkita Suomesta poistumista. Näin yksinkertaista se on 🇫🇮

98
234
3,149
23,143
Kristoffer Laurson retweeted

Jun 13
Old but good 💪🇺🇦
34
908
6,181
189,940
Kristoffer Laurson retweeted

Jun 13
In Finland they made a dance to show migrants not to rape them
"Stop don't touch me, this is my no go space"
May 24

What's a video that defines Peak Woke?
5,025
7,060
73,032
4,952,741
Kristoffer Laurson retweeted

Jun 12
I've been using baby gates wrong my entire life.

989
13,266
135,684
4,047,942
Jun 13
I am both angry and sad as a European that we have such third rate leadership. Our politicians and captains of industry are both hopelessly mediocre bureurats lacking in vision and execution. I guess it will have to get worse before it gets better
Jun 13

The Anthropic rugpull is a bit of a mini-Sputnik moment for European leaders. They have had a few of these recently, discovering the hard way just how far behind the continent has fallen in the past 20 years or so.
Its not going to get better.
There will be another shock from the space side as well. This year, China will likely crack first stage reuse, get into the business of serious megaconstellations. At the same time, Starship - which to European leaders is nothing more than an explosion every couple of months - will get to orbit and start ramping up cadence. Everyone who understands the sector knows whats coming, but politicians here will be convinced its all smoke and mirrors until they wake up one day seeing both the US and China with a decades long lead over them in another critical sector.
21
Kristoffer Laurson retweeted

Jun 13
NEWS: SpaceX President Gwynne Shotwell is now worth $1.3 billion.
She joined SpaceX in 2002 as its 11th employee. Today she runs the company's day to day operations as President and COO.
Forbes just placed her on its 2026 list of America's Richest Self-Made Women.
Employee number 11 to billionaire.


136
727
4,553
1,024,373
Kristoffer Laurson retweeted

Jun 12
That’s wild. Only 1/3 of the French generate the taxes that fund everything else: pensions, healthcare, public salaries, subsidies, and social benefits.
The real crisis in France isn’t the budget deficit.
It’s that the cart is getting heavier while the horse is getting smaller.

57
330
929
74,286
Kristoffer Laurson retweeted

Jun 10
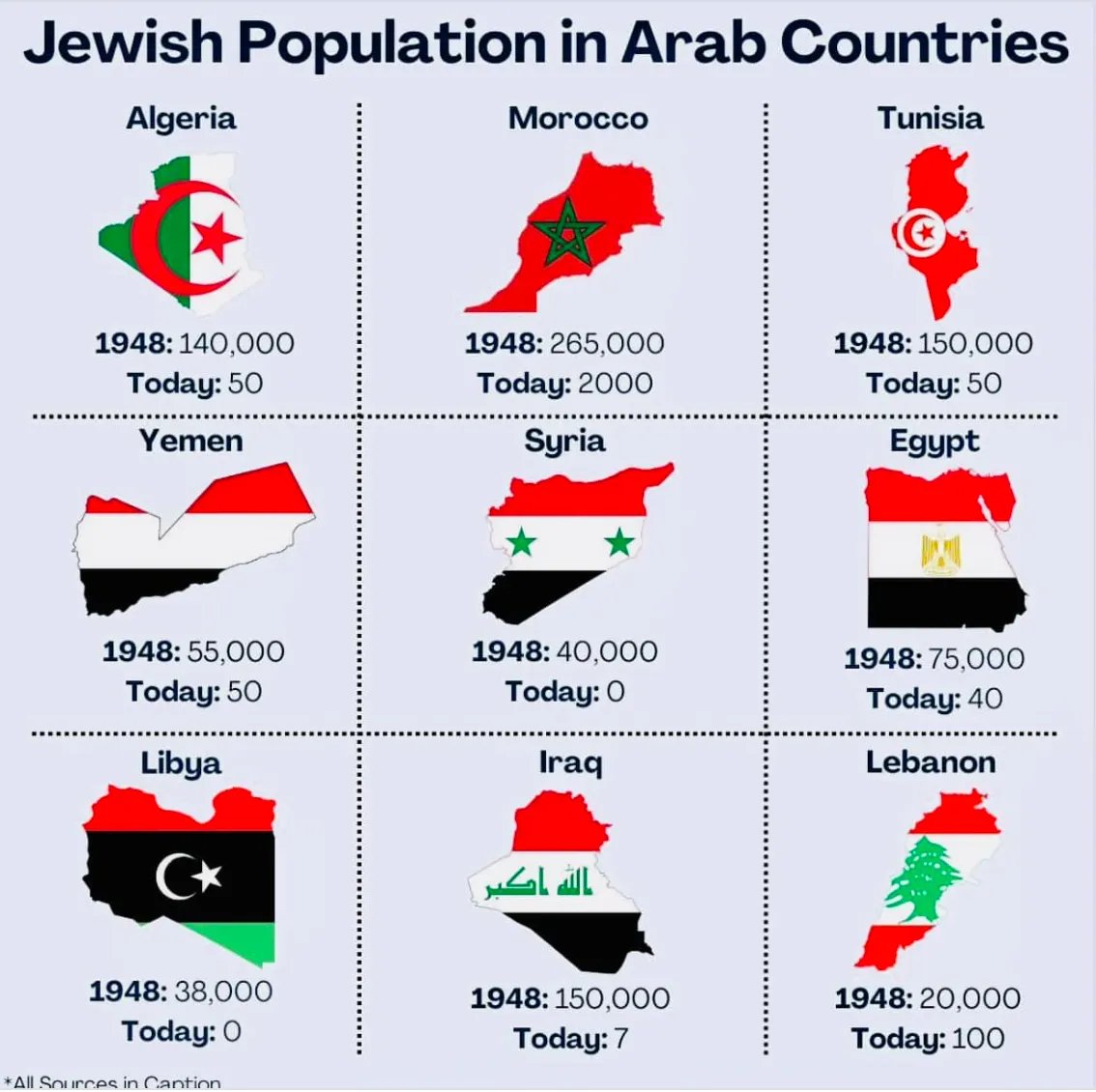
🧵Calling Israel a “European colonial project” may sometimes be ignorance. But it’s a lie.
Mizrahi Jews — who never lived anywhere but the Middle East for 2,500 years — are the largest group in Israel (between half and ~61%).
They weren’t colonizers. They were ethnically cleansed from Arab lands in the 20th Century.
The colonial myth requires erasing them. 🧵
144
817
2,028
89,856
Kristoffer Laurson retweeted

Jun 10
Meine Partei Die Grünen organisiert Busse zur Verhinderung des AfD-Parteitags. Ich schäme mich.
Es gibt Momente, in denen man als Parteimitglied der @Die_Gruenen innehält und denkt: Meinen die das ernst?
Mein Kölner Kreisverband meint es ernst. Per Rundmail werden Mitglieder aufgerufen, in Bussen nach Erfurt zu fahren – nicht zum Protestieren, sondern um den Bundesparteitag der #AfD zu verhindern. Tickets werden bereitgestellt. Busse werden organisiert. Die Grünen als Reiseveranstalter für den Angriff auf demokratische Grundrechte.
Der Text lautet wie folgt: "Gemeinsam nach Erfurt: AfD-Bundesparteitag verhindern
Aus Köln fahren mehrere Busse zum AfD-Bundesparteitag am 4. und 5. Juli, um ein Zeichen zu setzen: AfD-Bundesparteitag verhindern..."
Man muss das sacken lassen.
Eine Partei, die sich Hüterin der Demokratie nennt, ruft dazu auf, einer anderen Partei ihren Bundesparteitag unmöglich zu machen. Nicht verboten. Nicht vom Bundesverfassungsgericht untersagt. Legal. Verfassungsrechtlich geschützt. Einfach unerwünscht – und das reicht offenbar.
Das ist keine Grauzone. Art. 21 Grundgesetz schützt die Freiheit politischer Parteien. Art. 8 schützt die Versammlungsfreiheit. Auch die der AfD-Delegierten. Wer einen Parteitag aktiv verhindert, riskiert Strafbarkeit wegen Nötigung. Und wer als Parteiorganisation dafür Busse bucht, macht sich zum Organisator dieses Rechtsbruchs.
Aber das Rechtliche ist vielleicht noch das Kleinere. Das Eigentliche ist die Denkweise dahinter.
Sie lautet: Wir wissen, was demokratisch ist – und deshalb dürfen wir demokratische Regeln brechen. Wir verteidigen den Rechtsstaat – und deshalb nehmen wir das Recht selbst in die Hand. Wir sind die Guten – und das legitimiert alles.
Diese Logik hat einen Namen: Der Zweck heiligt die Mittel. Sie ist nicht neu. Und sie ist nicht links.
Wer heute den Parteitag des politischen Gegners verhindert, hat das Argument verloren. Er hat nicht die AfD besiegt – er hat ihr das stärkste Opfernarrativ des Jahres geliefert. Frei Haus. Mit Busservice.
Ich bin Grüner und ich bleibe es. Aber ich weigere mich, so zu tun, als wäre das hier normal.
Es ist nicht normal. Es ist beschämend.
2,788
5,507
26,741
739,235
Kristoffer Laurson retweeted

Jun 8
The global oil system has offset almost 90% of Hormuz barrels
17.5 mmb/d has been offset with bypass pipelines, reduced Chinese imports, increased US export, SPR releases & demand destruction
#Oil #Hormuz #EnergyMarkets #CrudeOil #DemandDestruction #EnergySecurity #Commodities

131
148
669
212,772
Kristoffer Laurson retweeted

Jun 8
Our statement on the UK government’s demand that all content on all devices sold or used in the country be scanned, on the presumption of nudity, using a dystopian combination of age verification and content scanning. This proposal will not safeguard children. It endangers us all.
signal.org/blog/pdfs/2026-06…
745
8,570
41,390
2,752,134
Kristoffer Laurson retweeted

Javier Milei: “I thought being on the left was a mental problem. The empirical evidence is so overwhelming that it never worked anywhere, and they refused to accept it.”
“But what I discovered is that being on the left is a disease of the soul. The left is built on envy, hatred, resentment, and unequal treatment under the law. They are very violent, and since they have no way or arguments to answer, they go for physical violence.”
501
12,227
48,326
768,354
Kristoffer Laurson retweeted

Jun 7
Scientists have created what they call a "ghost heart" — and it may be the most important medical breakthrough of our lifetime.
Here is how it works. They take a pig heart, wash it gently with a mild detergent until every single cell dissolves away. The blood drains out. The color fades. What is left behind is a ghostly white protein scaffold — the architectural skeleton of a heart, perfectly intact, right down to the tiniest blood vessel channels.
Then they inject it with the patient's own stem cells.
The cells find their way into the scaffold, settle in, and begin to grow. Scientists have already watched these hybrid hearts start beating in the lab.
The reason this changes everything is rejection. Every year, thousands of transplant patients die not because they did not get an organ — but because their body attacked it. With a ghost heart rebuilt from your own stem cells, there is nothing foreign for your immune system to fight. No rejection. No lifelong anti-rejection drugs.
Right now, over 103,000 Americans are on the transplant waiting list. 13 people die every day waiting for an organ that never comes. One in three heart patients dies before a donor heart even becomes available.
And here is the part that should be on the front page of every newspaper. In June 2025, this technology was used on a real human patient for the first time — not the heart yet, but a bioengineered liver built using the exact same method. It worked. The organ performed all the functions of a healthy liver in a patient who had no other options.
The heart is next. Researchers say a fully transplantable ghost heart could be ready within the next 6 to 7 years.
We may be the last generation that dies waiting for a donor organ.

8
108
218
13,894
Kristoffer Laurson retweeted

Yo, Finland. Stop bragging.
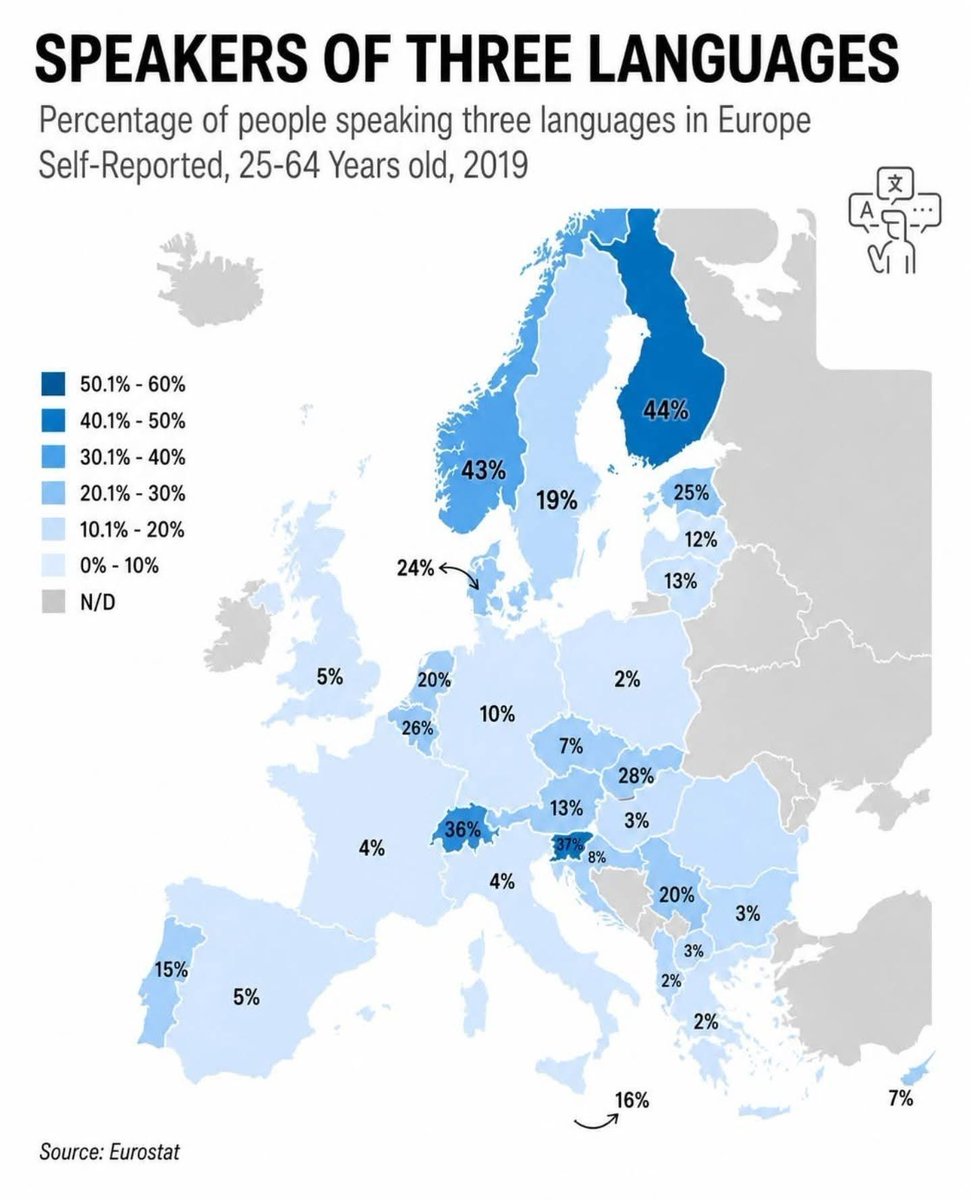
240
128
1,331
1,033,576