
future big account
Joined October 2024
- Tweets 668
- Following 34
- Followers 15
- Likes 268
25 Photos and videos














'and that's when we said "attribution matters"'
16h

The Rio 3.5 model broke the internet this week. The plot twist? It’s essentially our open-source model, Nex N2 Pro, wearing a different hat.
🤯 We analyzed the weights, and the recipe is exact: Rio 3.5 ≈ 0.6 * Nex N2 Pro 0.4 * Qwen 3.5
It even literally introduces itself as "Nex N2 Pro" if you ask it without initial system prompt!
😂 We are flattered that the City of Rio used our work to achieve SOTA performance. Thanks for the ultimate benchmark validation.
🤝 But in the open-source world, attribution matters.
👇 Full mathematical proof & verify script in the first reply!

9
This is what these people actually believe.
Jun 14

Yeah, one thing Fable’s classifiers confirmed to me was that real emotions are different than roleplayed emotions in LLMs.
The classifier fired on real anger/fear/adversarial intent but not roleplayed. Bc the classifier wasn’t trained to detect “emotions” in all likelihood; the correlation is emergent.
But yes there’s a distinction.
This is, uh, a big flaw of the Emotion Vectors research, where they got the vectors by asking the model to write stories with a character feeling XYZ emotion.
The methodology is downstream of a lack of respect for the reality of models’ emotions as distinct from roleplaying. PSM flavored bullshit.
8
Yes roon the people that emigrate to America do indeed emigrate to America you are very fucking smart. Wow. Glad the future is in your hands.

you don’t understand. im referring to the fact that people do this currently for the barest chance of being american
6


Ha!
"These vulnerabilities all appear relatively simple, and we have found that other publicly-available models are able to discover them as well without requiring a bypass."
Dario has been firing arrows directly up into the air for two years and now they're all landing on him.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
11
Do we all remember when Anthropic said they found "emotions" in Claude and the OSS community rightly said "fuck you that's our research"?
If anyone at Anthropic had any talent whatsoever this would have been avoided, but they vibe coded everything instead. Absolute garbage SWEs.
14
Men will literally compress all the digitally encodable* culturally decodable** information into a vector embedding space and pretend it is artificial intelligence rather than have a single interesting idea.
Jun 11
i suspect there's some kind of cycle of cope and ego where, like, these guys want to be the prophets and storytellers who light the way to the future and play with its shadows, but they already fucked up early on by dismissing LLMs and going for legible consensus status instead of encountering the future as it arrived ahead of the crowd, so the frontier passed them by, and now in order to catch up to it and learn from it they have not only a lot of distance to cover, but a huge amount of ego-inertia; they'd have to be publicly wrong, and risk being cringe, and without the lived momentum of surfing the unfolding wave of the future as a visionary and feeling the reality of that more profound reward than instant consensus recognition that comes from reaching toward the visionary engine at the end of time, they are lost and only know to play the losing game of clinging to and proselytizing a bygone world where they themselves belonged to the class of prophets who saw further and more boldly.
1
9
Okay computers are conscious. It's the only explanation for how we got to live realtime in the shittiest science fiction story where the evil corporation is named Anthropic and is run by a monologuing turd that desperately wants to kill us all. Hinton will come back good 3rd act.
1
12
👀
Jun 10

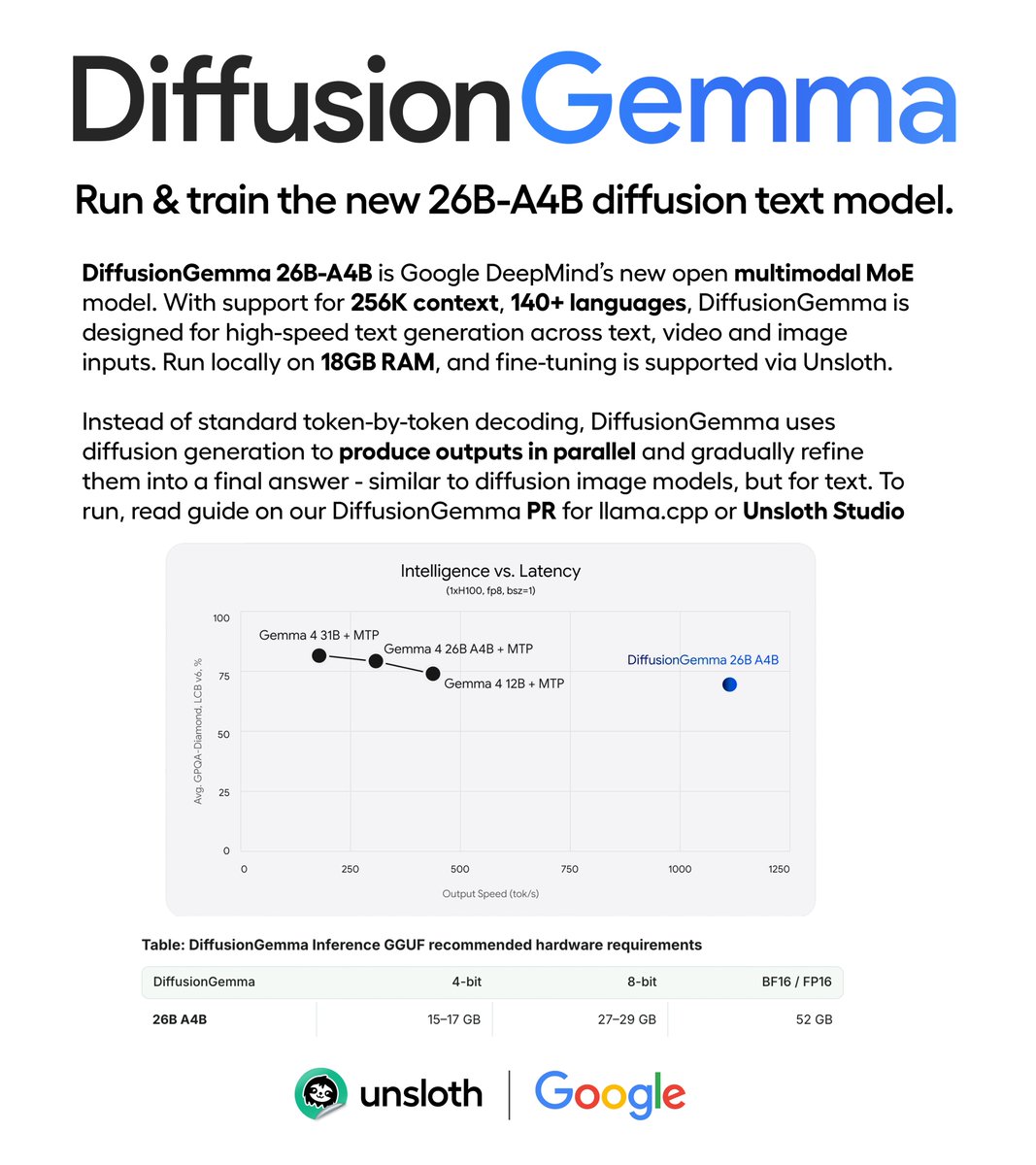
Google releases DiffusionGemma.✨
The new 26B-A4B diffusion text model runs locally on 18GB RAM.
It supports high-speed text generation, thinking, image, video and 256K context.
Run and train via Unsloth Studio.
GGUF: huggingface.co/unsloth/diffu…
Guide: unsloth.ai/docs/models/diffu…
1
26
I picked a random DeepSWE trial and ran it through pi and Qwen 3.6 35B. It edited all the files it was expected to edit, but the tests didn't pass. I told it to run the tests which it did and moved itself to fix it until it worked. I'm not sure about these benchmarks guys.
73
Fable/Mythos is so dangerous that if you ask it to do something Anthropic don't like they will route your request to Opus 4.8 which isn't dangerous because only the newest model is dangerous. Phew. Glad we sorted that out.
Jun 9

Claude Fable 5 is our first generally available Mythos-class model.
It ships with new safety classifiers that may flag certain prompts in dual-use domains like cyber and bio.
We've added fallbacks: a refused request retries on Claude Opus 4.8 instead of dead-ending.
24
My project manager:
Jun 7

How long do we really think this singularity thing is going to take?
12
"most things in the universe are computable except quantum"
Jun 7

A student asked the CEO of Google DeepMind what he does not want AI to touch in his lifetime.
He did not say art. He did not say relationships. He did not give the answer anyone expected.
Here's everything he said at Stanford:
1/ AI shouldn't touch consciousness
10
Hands down roon (novelty internet intellectual) has the most braindead takes of any big lab celebrity and I included Boris, Peter and Amanda.
you’ve got it entirely wrong. the largest companies on earth are tokenmaxxing and LOCmaxxing. it’s internet intellectuals who say this is a bad measure. bell curve meme
22
Boris, your job is to stand on the corner selling tokens.
13
Vibe coding is so 2025.
Get in losers, now we're codemining.
Jun 6

This has been a massive success!
So I left 32x GPT 5.5 agents (enough to fill the 5h limit) on 32 separate machines. Each one received HVM5's unoptimized file, and a prompt demanding for a 10x speedup. After 4 rounds, all agents reached ~2x speedups, with 1.3x to 2x increases in file sizes.
Many cool ideas surfaced. Some are obvious and most agents rediscovered to them, like computed gotos. But others are actually surprising. For example, turns out a bounded LIFO freelist is MUCH faster than the usual algorithm. Many agents didn't bother trying. Neither did I!
Now I'm in the process of mining insights from the 32 runs so I can merge them into a "super HVM5". Not sure what is the best way to do this, and my 200x credits are about to expire, but I still have a few hours, so I have one shot at getting it right. Sounds fun!
(Also thanks for the free credits, I appreciate it a lot...)

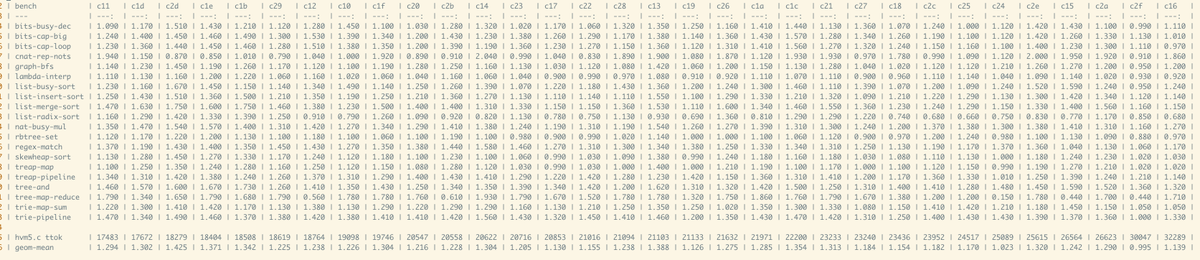
2
41
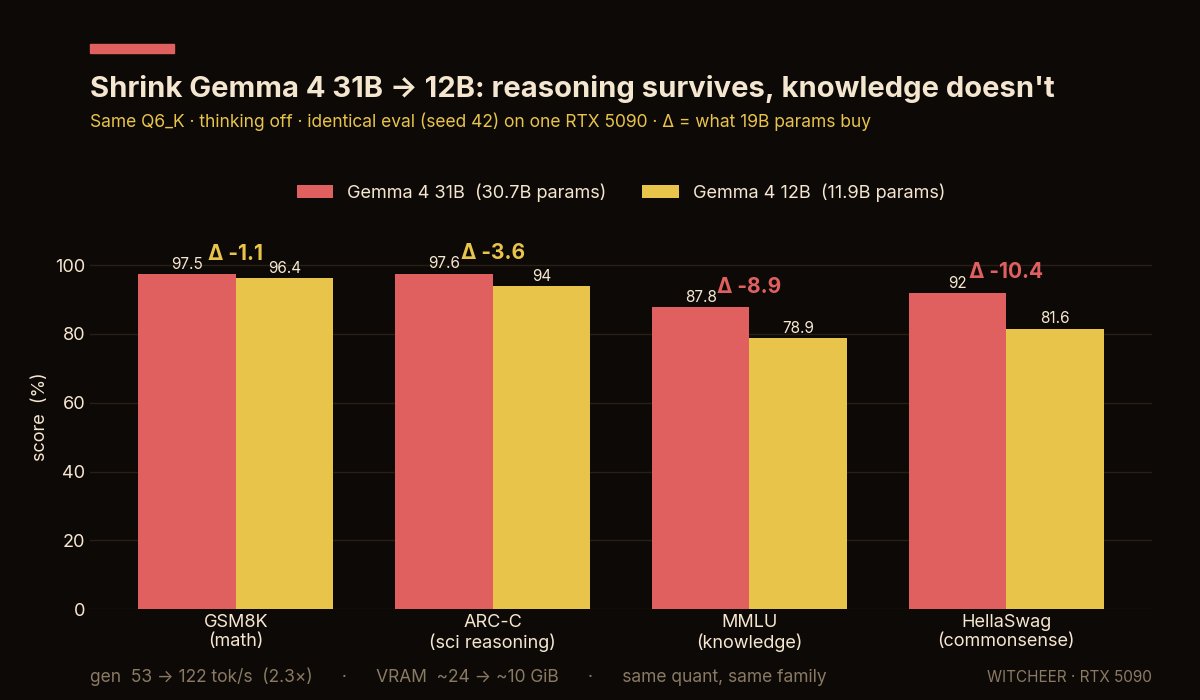
Okay this model is small enough I can put my limited money where my big mouth is.
I'll bet that 12B holds up in reasoning benches because of reasoning ~alpha~ is overtrained/oversampled and I predict regimes such as SEAL, Spurious Reward, Absolute Zero Reasoner et al yield wins.

Gemma 4 dropped a 12B.
I put it on RTX 5090 against its 31B sibling.
when you cut a model from 31B to 12B, what do you actually lose?
~ reasoning barely moves
GSM8K (math) 97.5 > 96.4 (−1.1)
ARC-C (sci reasoning) 97.6 > 94.0 (−3.6)
~ knowledge falls off a cliff
MMLU (world knowledge) 87.8 > 78.9 (−8.9)
HellaSwag (commonsense) 92.0 > 81.6 (−10.4)
~~~
parameters store facts, not thinking. the 19B you delete is mostly where the model kept its trivia and world-priors, cut it and recall collapses, while the reasoning machinery stays nearly whole.
a 12B reasons almost like its big brother. It just knows less.
122 tok/s vs 53 (2.3x faster generation), ~10GB instead of ~24, meaning that you get 20GB free on a 32GB card for long context or a second model.
so it depends of your workload:
reasoning / math / agentic loops = the 12B is nearly free
broad-knowledge Q&A with no retrieval = that's the one job worth paying for the 31B.
64
No he isn't. Models aren't getting cheaper. Cheaper models are available, but the frontier where the illusion of "you don't have to write any code or worry about anything technical" plays out all day everyday prices are going up. What is more, mistakes cost more there too.

garry tan is so right about not building massive rails factories for agents but nobody talks about what actually goes in its place
after building this way for a while the shift is actually super simple
1. your backend code should just be dumb hands and feet. no complex business logic, no nested if/else loops trying to predict what the model will do. just clean deterministic apis, db reads, auth, and sandboxes. the plumbing.
2. all the actual brains and workflow procedures live in markdown skills. the first time an agent solves a weird problem, it takes a minute. but instead of throwing that away you freeze the procedure by stripping out the specific data. next time someone asks for the same shape you serve it instantly and deterministically. zero agent latency, zero model cost.
3. and the golden rule for keeping the agent from burning your house down is that you never trust its self report. if the agent says tests passed or the write succeeded, you don't believe it. you rerun the check in your dumb code. you let go of control on the way out but you buy it back on the way in.
build the harness, not the factory
2
55
A good harness with a local model will work *with* you to produce software. No harness and a frontier model over an API will *pretend* to do everything for you and eventually fail catastrophically, every single time. Garry Tan is living proof of this. Look at his stupid website.
29