
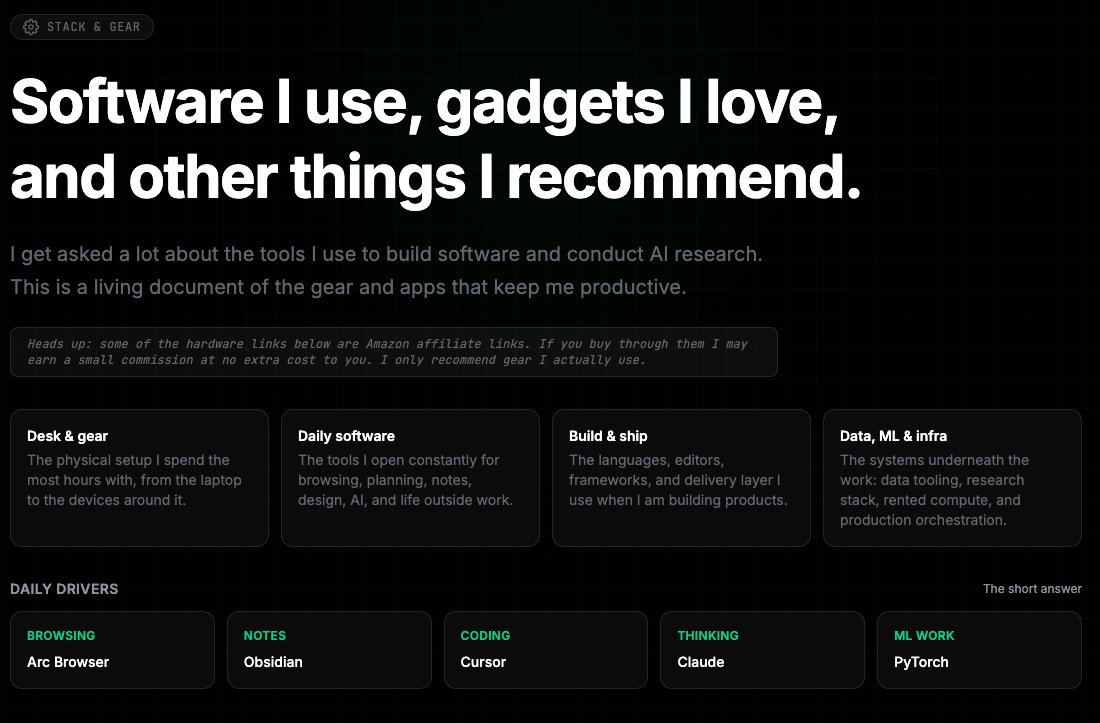
building AI @ Confidential | prev: @cursor_ai ambassador; @pytorch award winner; @deepforai @malaa_tech @oregonstate | ms & bs @oregonstate
Joined April 2023
- Tweets 2,689
- Following 967
- Followers 3,220
- Likes 20,703
458 Photos and videos










Mazen — sa/acc retweeted

Jun 13
Explaining JEPA in 10 seconds
8
54
515
23,054
Mazen — sa/acc retweeted

Jun 13
If Dario had invented the iPhone he would have spent the whole keynote talking about how it might blow up in your pocket
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
121
574
11,128
417,649
Mazen — sa/acc retweeted

Jun 10
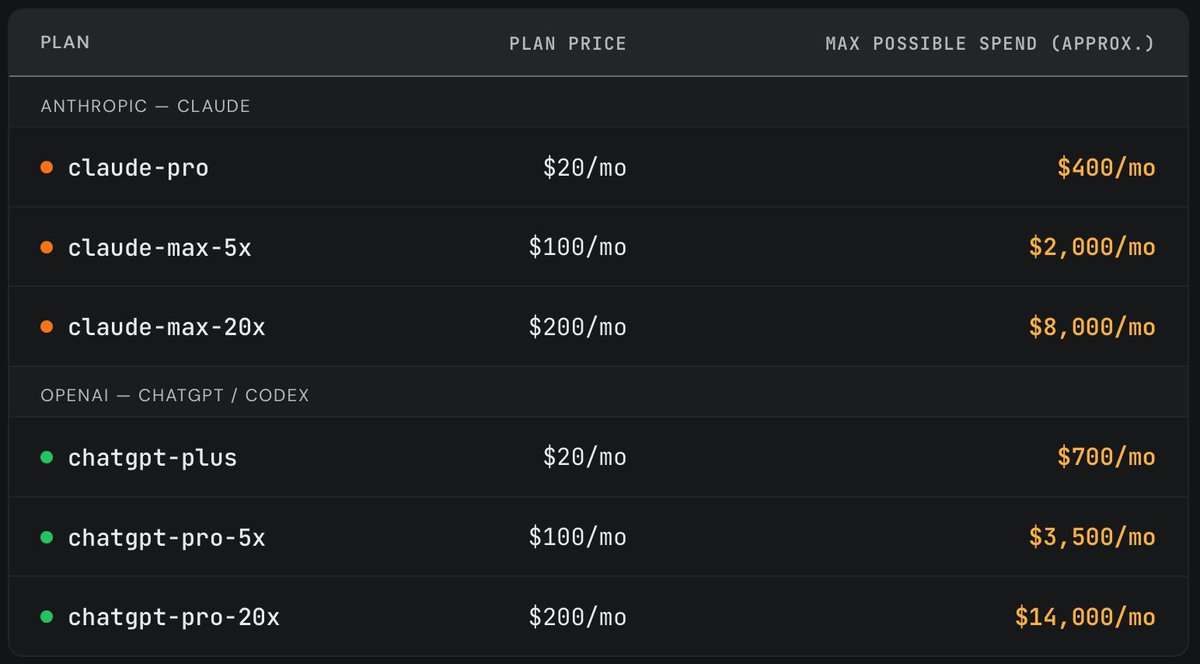
Claude $200 = $8,000
OpenAI $200 = $14,000
I like that exchange rate (while it lasts)
Jun 10

Recently, we purchased one of each Anthropic/OpenAI subscription plan and randomly ran long horizon coding tasks until we exhausted the weekly limit. It's widely believed that a $200/month plan maxes out at ~$2000/month worth of tokens (assuming API pricing). However, we found that the subscriptions are actually far more generous. (2/4)
57
108
2,856
820,445
Mazen — sa/acc retweeted

If fable can help you with your work, you aren’t working on interesting enough stuff
36
46
573
54,425
Mazen — sa/acc retweeted

Jun 9
btw, we publish everything you need to build our Nemotron models including the recipes and pipelines directly.
github.com/NVIDIA-NeMo/Nemot…
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

23
59
616
24,414
Mazen — sa/acc retweeted

Jun 9
Very sad news for the LLM research and open-source community. Does this mean PhD researchers in frontier LLMs, or contributors to open-source LLM infrastructure like Megatron, FSDP, Verl, SGLang, and vLLM, may be using a degraded Claude model in their daily work without being notified?


Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
35
36
604
59,256
Mazen — sa/acc retweeted

Jun 9
If you really think about it, despite being mocked as “ClosedAI,” OpenAI has contributed enormously to the field: GPT, GPT-2, GPT-3, CLIP, the ChatGPT paper, the GPT-4 Technical Report, the Sora technical blog, and even open-sourced Codex.
Anthropic, meanwhile, has contributed far less to the public research ecosystem while increasingly promoting fear-based narratives and restricting access through heavy gatekeeping.
The world I least want to live in is one where the future of AI is controlled by companies that prioritize secrecy, gated access, and centralized control over openness, reproducibility, and scientific progress.
121
367
4,422
203,786
Mazen — sa/acc retweeted

Jun 10
Silently sabotaging experiments in order to stultify scientific progress and protect a technology lead.
Hmmm that sounds familiar...
Welcome to "Sophanthropic".

46
83
1,303
56,051
Mazen — sa/acc retweeted

Jun 10
As believers of open research, we are disappointed to see Anthropic silently degrading Fable 5 for AI development
"Any topic related to building pretraining pipelines, distributed training infrastructure, or ML accelerator design... may have limited effectiveness through Claude via methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning."
Not only do they get to decide what you use LLMs for in research, but this also enables them to silently intervene in your research without you knowing.
This sets a dangerous precedent. If a model refuses openly, users can understand the boundary. If a model falls back to another model, users can still evaluate the difference. But if a model silently modifies or weakens its own answers while still pretending to help, researchers lose the ability to know whether a failed result came from their own idea, their implementation, or an invisible intervention by the model provider.
That is not safety. Safety policies should be transparent, auditable, and user-visible.
On top of that, the people most harmed by this are not the largest labs with massive teams and proprietary infrastructure. It is the independent researchers, academic groups, startups, and open-source builders who rely on public tools to compete, innovate, and pioneer AI for everyone else.

166
721
3,864
220,545

Mazen — sa/acc retweeted

Jun 5
frontier agents are this good partly because the model was trained inside the very harness it ships with
great to see this recipe moving to the open with works like the new "Polar: Agentic RL on Any Harness at Scale" by @NVIDIAAI
it turns harnesses (codex, claude code, qwen code or pi) into RL training environments without touching their internals
2
26
193
27,791
Mazen — sa/acc retweeted

May 23
أحد الأشياء السيئة اللي لازم تتعايش معها إذا كنت مختص في التهديدات السيبرانية وتكتب في منصة X.
يا واحد ينشر رقمك في مواقع تعارف.
يا مراهق يرسل رسائل SMS باسمك.
يا هاكر زعلان اني كتبت عنه.. او كتبت عنه معلومة غلط.
المهم.. كثير مرسلين لي اليوم هذي الرسالة وصلتهم 😂

14
2
104
145,712
Mazen — sa/acc retweeted

May 30
I received a message in my direct messages asking how difficult it would be to use computer vision to track cell movement.
> SAM zero shot for the immune cell
> YOLO finetuned on a small dataset for bacteria
Realization time: ~2 hours
48
112
1,879
186,882


Hi (:
Today we FINALLY announce our very new: CranL Sandboxes
A place where you can deploy and host your AI agent from your github repo, comes with:
- SSH access and full control
- Fully isolated Micro-VMs and high performance hardware
- Hosted in Saudi Arabia 🇸🇦 and more!
35
48
351
238,934
Mazen — sa/acc retweeted

May 23

May 23

ugh they are the worst email slop spammers, I blocked so many of their agents
27
34
1,526
109,687
Mazen — sa/acc retweeted

May 22
BREAKING! Qwopus 3.6 27B is LIVE!
Thank you for your patience on this one, but I believe you'll find the wait was worth it!
We've benchmarked this thing up and down, verified that it holds at least a 75.25% (152/202) in the initial 202 SWE bench solves. Not a full run of 500, but it shows the agentic coding quality from the original 27B is retained while adding all of the additional Qwopus benefits across many domains. As always, Jackrong is absolutely cooking here!
COT quality has improved significantly through the inversion techniques from our Negentropy proof of concept. It also went through thorough curriculum training. You can check out the MMLU pro benchmarks on the model card, but it improved a whopping 10 points over the base model in physics, as well as meaningful jumps in Chemistry, business, and computer science.
However, the best part is that I was able to build an entire survival shooter game using this local model entirely. I genuinely was blown away by the results, which you can play right now on my HF space (link in comments below). "Qwopus Commander" was completed in 9 turns of Qwopus 3.6! To test the new long context training, I made it re-output the entire 3000 line program each turn, and it would make fixes and add features that I requested in large prompts, while perfectly replicating the entire rest of the game from context. What's more is that I did it all at Q8 KV cache quantization, and never had an issue over the entire 303k token run!
IMPORTANT: Run it at --temp 0.75 to 1. Mess with it in that range for your use case. Higher temp actually lets the fine-tune shine and be exploratory and is also more stable. Swe Bench was run at temp 1, the game was built mostly at 0.8!
We're so blessed to have all of you here and using the models! The support means so much! Please let me know what you build with it in the comments! Or if you have any issues getting it up and running, I will try my best to get back to you!
Looking forward to seeing what you legends produce with it this weekend!
huggingface.co/Jackrong/Qwop…
80
135
1,373
88,260