
Climate scientist working on cloud feedbacks, climate sensitivity, hydrological sensitivity and machine learning.
Joined March 2009
- Tweets 562
- Following 2,189
- Followers 753
- Likes 384
23 Photos and videos













Mark J. Webb retweeted

14 May 2025
We also applied AlphaEvolve to over 50 open problems in analysis ✍️, geometry 📐, combinatorics ➕ and number theory 🔂, including the kissing number problem.
🔵 In 75% of cases, it rediscovered the best solution known so far.
🔵 In 20% of cases, it improved upon the previously best known solutions, thus yielding new discoveries.
18
106
740
95,672
Mark J. Webb retweeted
10 Apr 2025
Human generated data has fueled incredible AI progress, but what comes next? 📈
On the latest episode of our podcast, @FryRsquared and David Silver, VP of Reinforcement Learning, talk about how we could move from the era of relying on human data to one where AI could learn for itself.
Watch now →
00:00 Introduction
01:50 Era of experience
03:45 AlphaZero
10:19 Move 37
15:20 Reinforcement learning and human feedback
24:30 AlphaProof
29:50 Math Olympiads
35:00 Experience based methods
42:56 Hannah's reflections
44:00 Fan Hui joins
46
264
1,228
225,841
Mark J. Webb retweeted

24 Nov 2024
The original RL algorithms, inspired by natural learning, were online and incremental—they were streaming in the sense that they learned from each increment of experience as it happened, then discarded it, never to be processed again. The streaming algorithms were simple and elegant, but the first big successes of RL in deep learning were not with streaming algorithms. Instead, methods such as DQN chopped the stream of experience into individual transitions, then stored and sampled them in arbitrary batches. Subsequent work followed, extended, and refined the batch approach into asynchronous and offline RL, while the streaming approach languished, unable to produce good results in popular deep learning domains.
Until now. Now researchers at the University of Alberta have shown that streaming RL algorithms can work just as well as DQN on Atari and Mujoco tasks (arxiv.org/pdf/2410.14606). How did they do it? Mostly just by getting signal normalization and step-size bounding right for the streaming case—otherwise they use standard streaming algorithms like TD(lambda) and Q(lambda). To me it looks like they were simply the first researchers knowledgeable of streaming RL algorithms to seriously address deep RL without being over-influenced by batch-oriented software and batch-oriented supervised-learning ways of thinking.
22 Nov 2024

Would you believe that deep RL can work without replay buffers, target networks, or batch updates? Our recent work gets deep RL agents to learn from a continuous stream of data one sample at a time without storing any sample. Joint work with @Gautham529 and @rupammahmood.
16
225
1,384
129,464
Mark J. Webb retweeted

4 Oct 2024
Excited to announce a pre-print of my first paper as part of my PhD at @BristolUni! We’ve created a generative ML emulator of a UK convection-permitting climate model (CPM). It’s able to produce simulations of high-res precipitation at far lower computational cost.
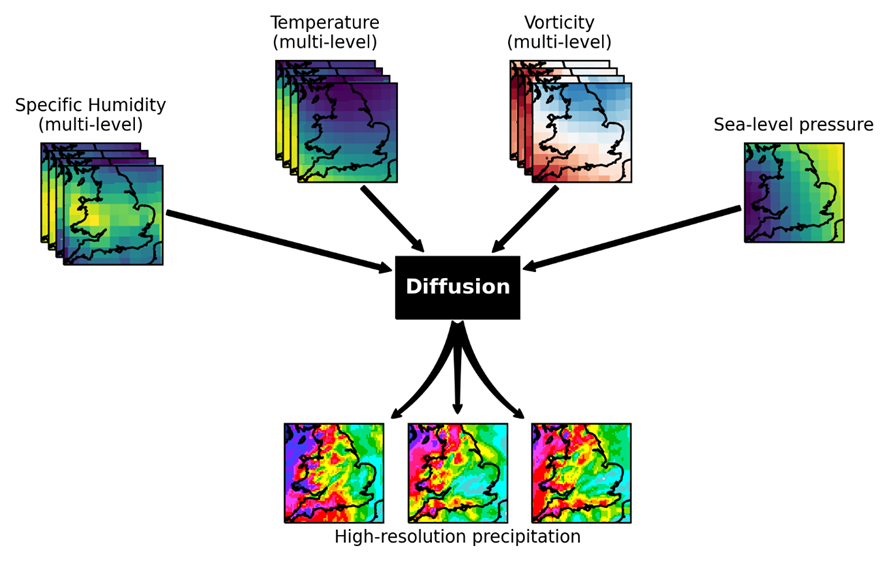
2
2
13
894
Mark J. Webb retweeted

24 Aug 2024
Programming is changing so fast... I'm trying VS Code Cursor Sonnet 3.5 instead of GitHub Copilot again and I think it's now a net win. Just empirically, over the last few days most of my "programming" is now writing English (prompting and then reviewing and editing the generated diffs), and doing a bit of "half-coding" where you write the first chunk of the code you'd like, maybe comment it a bit so the LLM knows what the plan is, and then tab tab tab through completions. Sometimes you get a 100-line diff to your code that nails it, which could have taken 10 minutes before.
I still don't think I got sufficiently used to all the features. It's a bit like learning to code all over again but I basically can't imagine going back to "unassisted" coding at this point, which was the only possibility just ~3 years ago.
514
2,011
18,137
2,829,105
Mark J. Webb retweeted

25 Jul 2024
Article: Inhibition of atmospheric convection by dry air intensifies moist heatwaves, and this process may further increase moist heatwaves under climate warming
@Duan_Suqin
nature.com/articles/s41561-0…
2
14
32
5,476
Mark J. Webb retweeted

9 Jul 2024
🎉New preprint on hybrid physics-ML climate modeling is out! 📣
“Sampling Hybrid Climate Simulation at Scale to Reliably Improve Machine Learning Parameterization”
arxiv.org/pdf/2309.16177
Led by Jerry Lin @jlin404 @uciess @UCIPhysSci @LeapStc
🧵
2
11
52
5,671
Mark J. Webb retweeted

8 Jul 2024
Cannot believe this finally happened! Over the last 1.5 years, we have been developing a new LLM architecture, with linear complexity and expressive hidden states, for long-context modeling. The following plots show our model trained from Books scale better (from 125M to 1.3B) than Mamba and Transformer, and our 1.3B model works better and better with longer context.
The idea, Test-Time Training (TTT), is something we have been working on for over 5 years. I still remember when I started as a postdoc, discussing with Alyosha what to work on, he asked me to talk to Yu Sun on TTT. And that is when everything begins.
Although this TTT is quite a different thing now. It is a network layer, replacing the hidden state of an RNN with a machine learning model. Instead of using a feature vector to represent a memory, our TTT layer maintains a small neural network to compress the input tokens. As each token comes in sequentially, the compression is done via gradient descent on this token to update the small neural network.
This is currently applied to language modeling, but imagine applying it to videos. In the future, when modeling long videos, instead sampling 1 FPS, we can sample the frames densely, and these dense frames would be a burden for Transformer but a blessing for TTT layer. As they are essentially just augmentations in time to train a better network inside TTT.
Please check: arxiv.org/abs/2407.04620
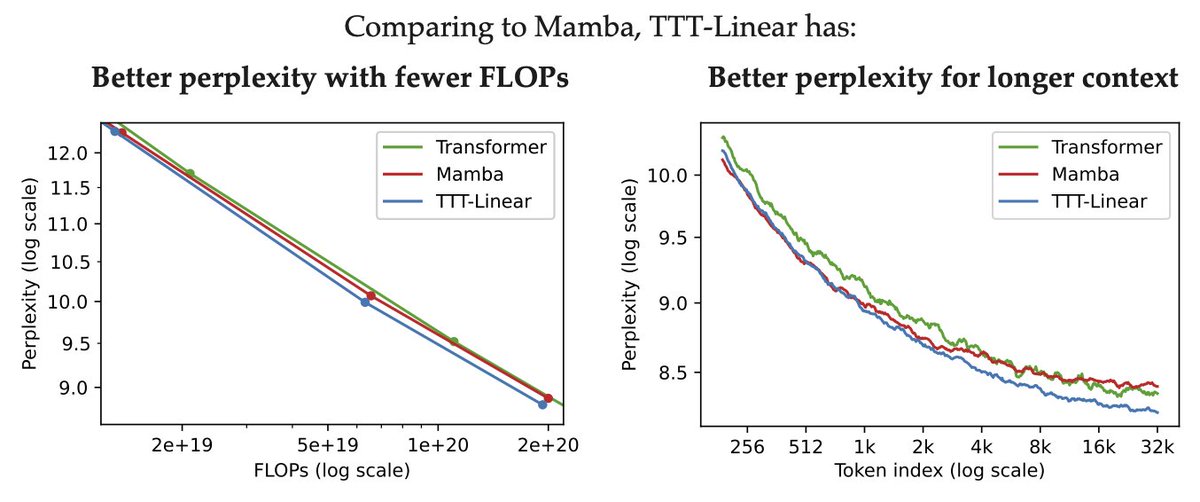
20
262
1,577
261,938
Mark J. Webb retweeted

29 Jun 2024
Really cool results - i never cease to be amazing how #ML models break new ground every day, accelerating the weather & climate revolution at an unprecedented pace :) Stay tuned for more interesting work in this space @ECMWF with our partners, also in the framework of #DestinE
27 Jun 2024

🔍We have taken #CMIP6 model output (left) and enhanced its resolution globally using an #AI weather prediction model (right). 🔎
More details in our preprint, led by @oceanographer : doi.org/10.48550/arXiv.2406.… @ECMWF
The animation shows 2-metre temperature in 2010 #downscaling
5
18
1,317

Mark J. Webb retweeted

27 Jun 2024
First light from #EarthCARE!!! This is an incredible moment - the first ever global measurements of cloud, snow and rain fall speeds. The reflectivity is beautifully detailed and the fall speeds are clearer than we could possibly have dreamed of! (1/4)
27 Jun 2024

The first results from #EarthCARE cloud profiling radar are here!
Here's how they look like and why you should be as excited as we are: esa.int/Applications/Observi…
The radar was provided by @JAXA_en and it's one of the four instruments aboard the satellite.
6
13
48
3,554
Mark J. Webb retweeted

27 Jun 2024
Hey everyone, I finally got a new role at the @metoffice.
I'm scoping what a data-driven climate model might look like. So, if you're into ML and climate, foundation models or something more lightweight, get in touch. It would be great to chat.
2
11
63
3,639
Mark J. Webb retweeted

25 Jun 2024
A big update to ARCO-ERA5 landed this week -- we now have a copy of ERA5 on native vertical levels with regular 0.25° horizontal resolution.
This ~6 PB dataset is freely available as part of Google's public datasets program:
github.com/google-research/a…
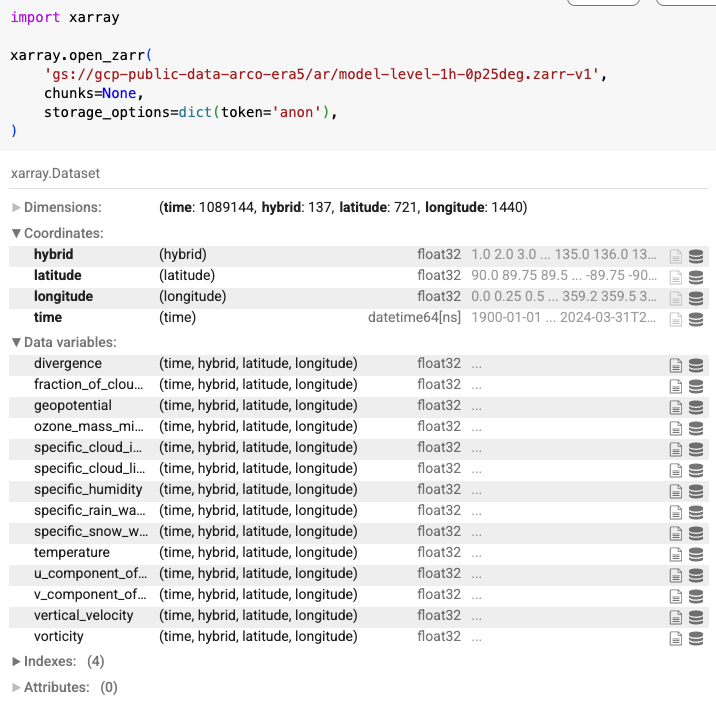
9
53
241
78,353
Mark J. Webb retweeted
26 Jun 2024
Another new preprint from @nvidia Earth-2 research. I love this ML paradigm for data assimilation pinned on skillful unconditional diffusion based state generators guided by obs during inference alone. Grateful to learn from inspiring AI researchers and a very productive intern!
26 Jun 2024

🚨New preprint🎉
"Generative Data Assimilation of Sparse Weather Station Observations at Kilometer Scales"
arxiv.org/abs/2406.16947
An absolute pleasure working on this during my internship @nvidia with @NoahBrenowitz @SciPritchard @JaideepPathak @tropmetpie and others 🧵
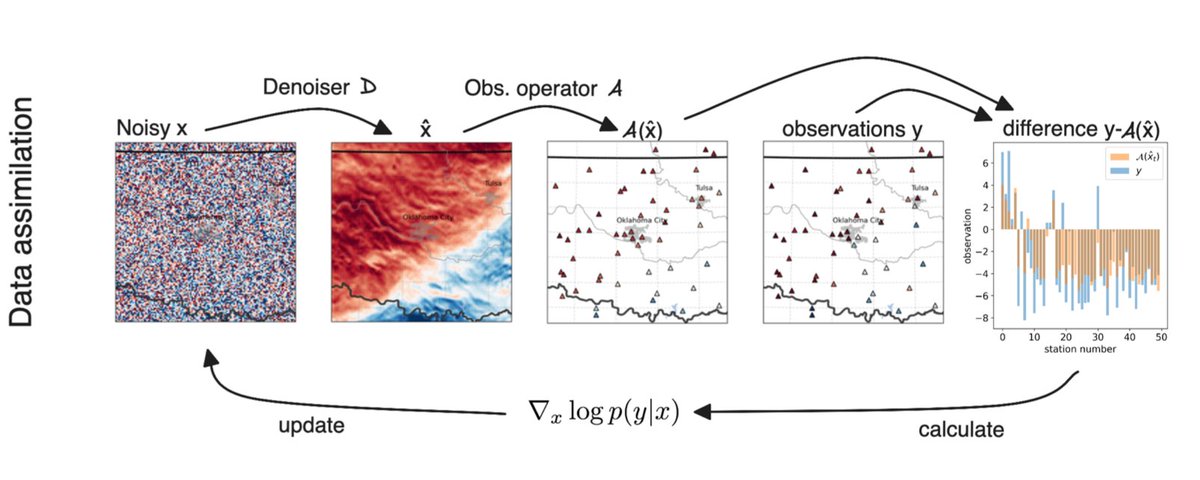
3
43
2,564
Mark J. Webb retweeted

23 Jun 2024
Looking for a mind-growing distraction? How about my 3 part intro to Bayesian causal inference. It's like a condensed version of my book, 10 weeks of causal computation in 3 short blog posts. Take with plenty of water. elevanth.org/blog/2021/06/15…
4
108
697
70,527
Mark J. Webb retweeted
18 Jun 2024
The WeatherBench2 paper has been published in JAMES!
doi.org/10.1029/2023MS004019
Big congrats to @raspstephan, who did all the heavy lifting on this project.
3
14
90
6,215
Mark J. Webb retweeted

12 Jun 2024
New paper “Possible Shift in Controls of the Tropical Pacific Surface Warming Pattern” by Watanabe et al. - @Nature nature.com/articles/s41586-0…
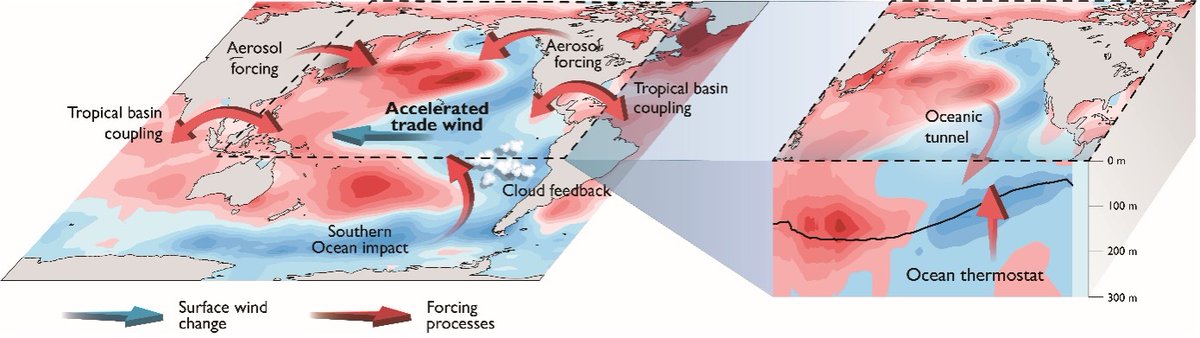
2
36
107
17,029
Mark J. Webb retweeted

18 Apr 2024
I'm excited to share a new paper in @ScienceAdvances led by UW's @VTCoop showing that the last ice age provides much stronger constraints on Earth's climate sensitivity and future warming when ice-sheet driven temperature patterns are accounted for. science.org/doi/10.1126/scia…
7
56
173
51,412
Mark J. Webb retweeted
13 Mar 2024
New paper in @PNASNews led with @cristiproist shows that a weird spatial pattern of temperature change has slowed global-mean warming since 1980. Because the pattern could evolve in the future, observed warming doesn’t help us constrain long-term warming.
pnas.org/doi/10.1073/pnas.23…
6
41
134
37,124