
Head of Data and Digital Preservation at the BFI National Archive. Working on digital preservation, audiovisual archiving. Opinions my own.
Joined November 2010
- Tweets 8,959
- Following 5,120
- Followers 1,478
- Likes 57,583
285 Photos and videos










Stephen McConnachie retweeted

A spine tingling rendition of Flower of Scotland being belted out by The Tartan Army, before their first World Cup Finals game in 28 years.
A moment that many have waited a lifetime for. 🥹🏴❤️
342
2,646
26,969
1,862,917
Stephen McConnachie retweeted

Jun 13
Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

588
1,531
13,112
4,800,982
Stephen McConnachie retweeted

Jun 12
🚀PP-OCRv6 is officially released!
🔥PaddleOCR’s new OCR model series scales from 1.5M to 34.5M parameters, bringing stronger accuracy, faster inference, and broader deployment options — from browsers and edge devices to servers.
📊What’s new:
🔸Tiny / Small / Medium models: 1.5M, 7.7M, 34.5M params
🔸 4.9% detection accuracy and 5.1% recognition accuracy over PP-OCRv5
🔸Up to 5.2× faster CPU inference with OpenVINO
🔸50 languages in one unified model
🔸New scenarios: PCB, CAD drawings, digital tubes, dot-matrix text
🔸Apache 2.0 open source
✨Lightweight OCR, built for the AI data era.
🔗Try it:
🌐 paddleocr.com
💻 github.com/PaddlePaddle/Padd…
🤗huggingface.co/collections/P…
#PaddlePaddle #PaddleOCR #OCR #AI #ComputerVision #OpenSource #EdgeAI


7
37
317
23,912
Stephen McConnachie retweeted

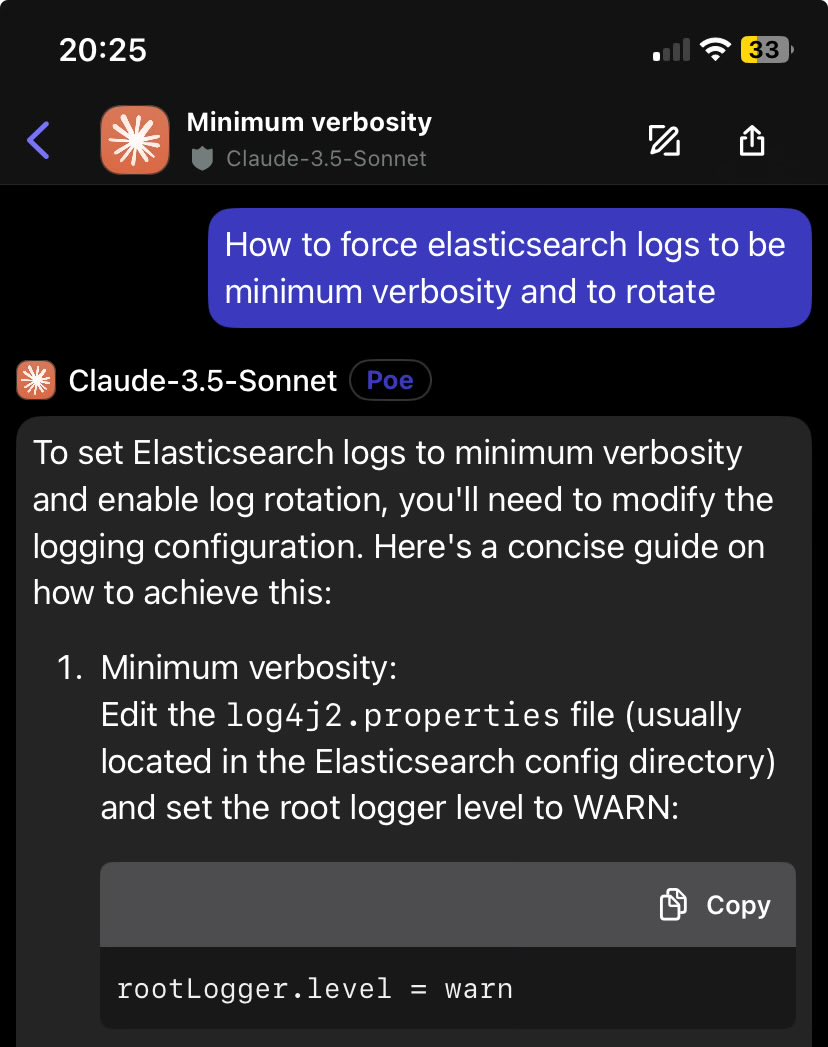
Yesterday: diffusion LM beats AR on OCR correction.
Today, after a suggestion from the @GoogleDeepMind team: bench it against its parameter-matched twin instead (same 26B MoE, same 4B active).
The twin wins slightly on quality. The diffusion model is still ~10× faster.
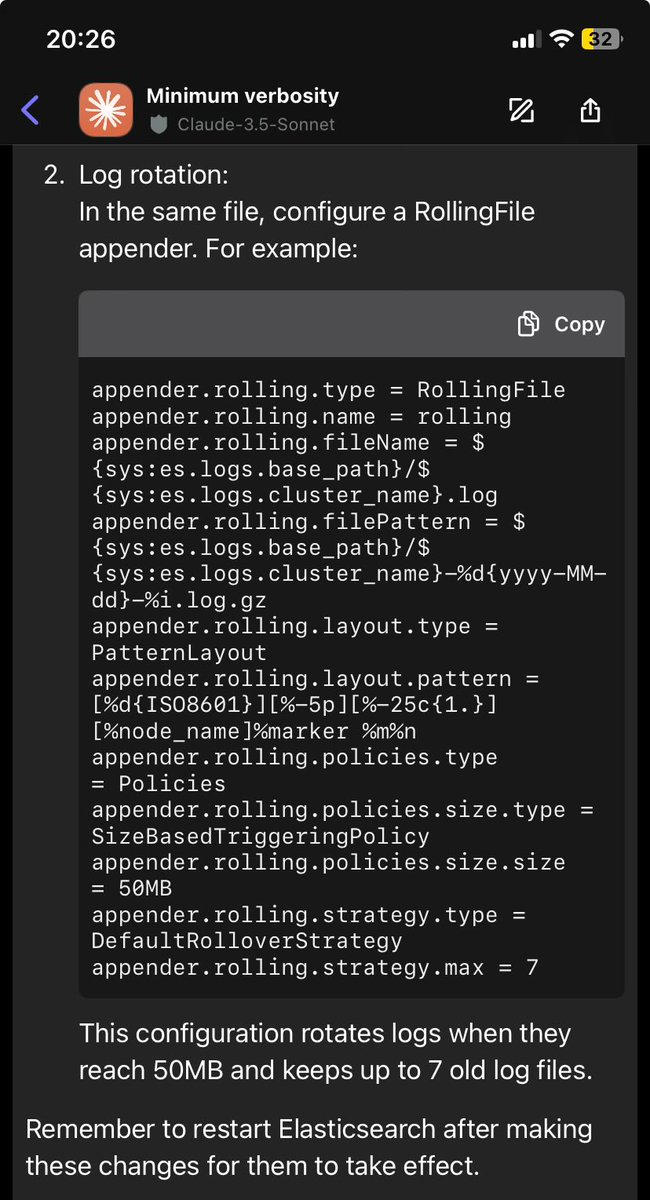
Updated scoreboard
CER on 19th-c newspaper OCR (lower = better):
• OCR input: 0.066
• Gemma-4-E4B: 0.042 (15.3s/passage)
• DiffusionGemma: 0.035 (1.7s 🚀)
• Gemma-4-26B MoE: 0.027 (16.3s)
Equal capacity: diffusion trades accuracy for an order of magnitude of speed.
Also tried the suggested sampler fixes (thx @joao_gante!) for the "seeded canvas just copies its input" bug. They free the model from copying but it re-derives the input instead of correcting it. Might still be some tweaking here?
Full agent-written lab notebook, scripts runnable straight from the bucket: huggingface.co/buckets/davan…
3
3
37
2,491
Stephen McConnachie retweeted

Jun 9
One of my personal favorite features announced at WWDC will I suspect be a sleeper hit: container machines, allowing your Mac to run a lightweight, persistent Linux environment with your home directory and repos automatically mounted: github.com/apple/container/b…
227
815
9,698
728,694
Stephen McConnachie retweeted

Jun 8
I tried the government's new AI "Jobcentre in your pocket" chatbot. Could it write me a CV? It could.
It also suggested that I should consider employment law and whether I've been discriminated against.
Key detail: I'm a parrot.

56
354
1,754
232,022

THE CREATOR OF OBSIDIAN JUST TURNED YOUR NOTE VAULT INTO AN AI AGENT.
Not a plugin.
Not an integration.
A full agent skills system that teaches Claude Code, Codex, and OpenCode to READ, WRITE, and REASON inside your Obsidian vault like a power user.
27,000 GitHub stars in days.
Here is what shipped at launch:
obsidian-markdown — wikilinks, embeds, callouts, properties, the full Obsidian flavor Claude now understands natively.
obsidian-bases — Claude can create .base files with views, filters, formulas, and summaries.
json-canvas — Claude builds .canvas files with nodes, edges, groups, and connections.
obsidian-cli — Claude controls your vault, develops plugins and themes directly from the terminal.
defuddle — strips web pages into clean Markdown so you stop burning tokens on clutter.
Install the whole thing in one line:
npx skills add github.com/kepano/obsidian-s…
Then connect it to Claude Code, Codex, or OpenCode.
That is it.
Your second brain now has an agent inside it that understands how Obsidian actually works.
Not a generic AI that pastes text into files.
An agent that knows what a wikilink is. What a callout is. What a canvas is.
Built on the open Agent Skills spec. MIT license. Free forever.
The gap between people using Obsidian as a note app and people using it as an AI operating system just got wider.
Bookmark this before you open your vault today.
Follow @cyrilXBT for every build that changes how Obsidian and Claude work together.
51
86
775
58,176
Stephen McConnachie retweeted

Jun 6
NVIDIA just dropped Nemotron-3.5-ASR: one 0.6B model, 40 languages, streaming.
parakeet.cpp already runs it. On a plain CPU, 2.5x faster than @NVIDIAAI 's Nemo runtime, output byte-for-byte identical (WER 0).
No GPU needed. Offline or real-time. Pick a language with --lang, or auto.
GPU numbers are coming to compare with Nemo framework.
21
108
939
77,193
Stephen McConnachie retweeted

Jun 5
Before the week ends, let's acknowledge one of the most INSANE week ever for open AI, with 25 notable open-weight drops across every modality:
🧠 LLMs
→ NVIDIA Nemotron 3 Ultra: 550B hybrid Mamba-MoE, only 55B active, 1M context, MMLU 89.1. NVFP4 variant claims ~5x throughput on Blackwell. First openly-weighted 550B hybrid Mamba-Transformer, closing the gap with frontier closed models.
→ Google Gemma 4 12B: fully open dense any-to-any (text/image/audio/video), 256k context, encoder-free, 140 languages, AIME 2026 at 77.5. Shipped with a 23-checkpoint QAT wave (mobile ONNX MLX). Most deployable model of the week.
→ StepFun Step-3.7-Flash: 198B sparse MoE VLM, ~11B active, SWE-Bench PRO 56.3. Apache 2.0.
→ Liquid AI LFM2.5-8B-A1B: edge MoE, just 1.5B active, 128k ctx, MATH500 88.8, MLX-ready. Best on-device option this week.
→ JetBrains Mellum2-12B-A2.5B-Thinking: their first open MoE, near-Qwen3-14B coding at 2.5B active. Apache 2.0.
🎨 Image gen (the surprise of the week)
→ Ideogram 4: their FIRST-EVER open weights. 9.3B flow-matching DiT trained from scratch. #2 overall behind GPT Image 2, top open-weight model on Design Arena LMArena. Strongest open checkpoint for text-rich images, full stop. It has taste. Still can't believe this is open weights.
🔊 Audio & Speech (a breakout week for open TTS, 4 labs shipped)
→ Boson Higgs Audio v3 4B: 102 languages, 21 emotions, singing/whispering/shouting, sub-second TTFA.
→ RedNote dots.tts: the only fully continuous (no codec) open TTS pipeline, Apache 2.0.
→ Google Magenta RealTime 2: real-time music gen, <200ms latency, text audio MIDI. multimodalart ported it to PyTorch within hours with live ZeroGPU demos.
→ NVIDIA Nemotron-3.5 ASR: 600M streaming, 17x more concurrent streams vs Parakeet RNNT 1.1B.
👁️ Vision & VLMs
→ PaddleOCR-VL-1.6: SOTA document parsing at 1B params, Apache 2.0.
→ Baidu NAVA: 6.3B joint audio-video gen, best-in-class A/V sync, Apache 2.0.
🎬 Video, 3D & World Models
→ NVIDIA Cosmos3-Super: 64B omnimodal world model coupling action trajectories with video audio gen, for Physical AI.
→ JD JoyAI-Echo: up to 5-min multi-shot text-to-video on LTX-2.3.
→ ByteDance Bernini-R VAST TripoSplat (single-image-to-3D Gaussian splats, MIT).
87
409
2,758
527,078
Stephen McConnachie retweeted
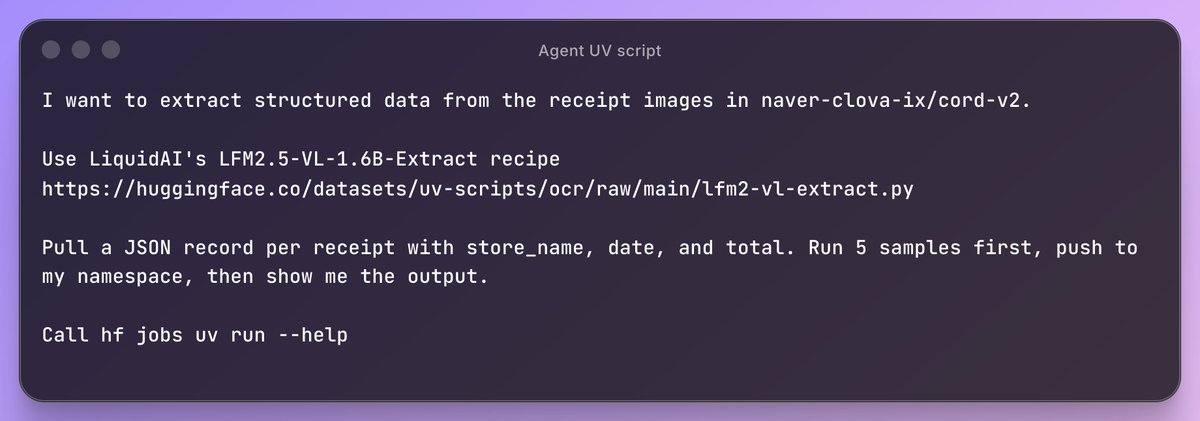
The unit of AI/ML work is becoming the UV script: one file, dependencies inline, run it from a URL, locally or on a GPU via @huggingface Jobs.
A single script, easy to adapt and reuse for humans and coding agents alike.
So I built a cookbook of them 🧵
2
1
18
1,401

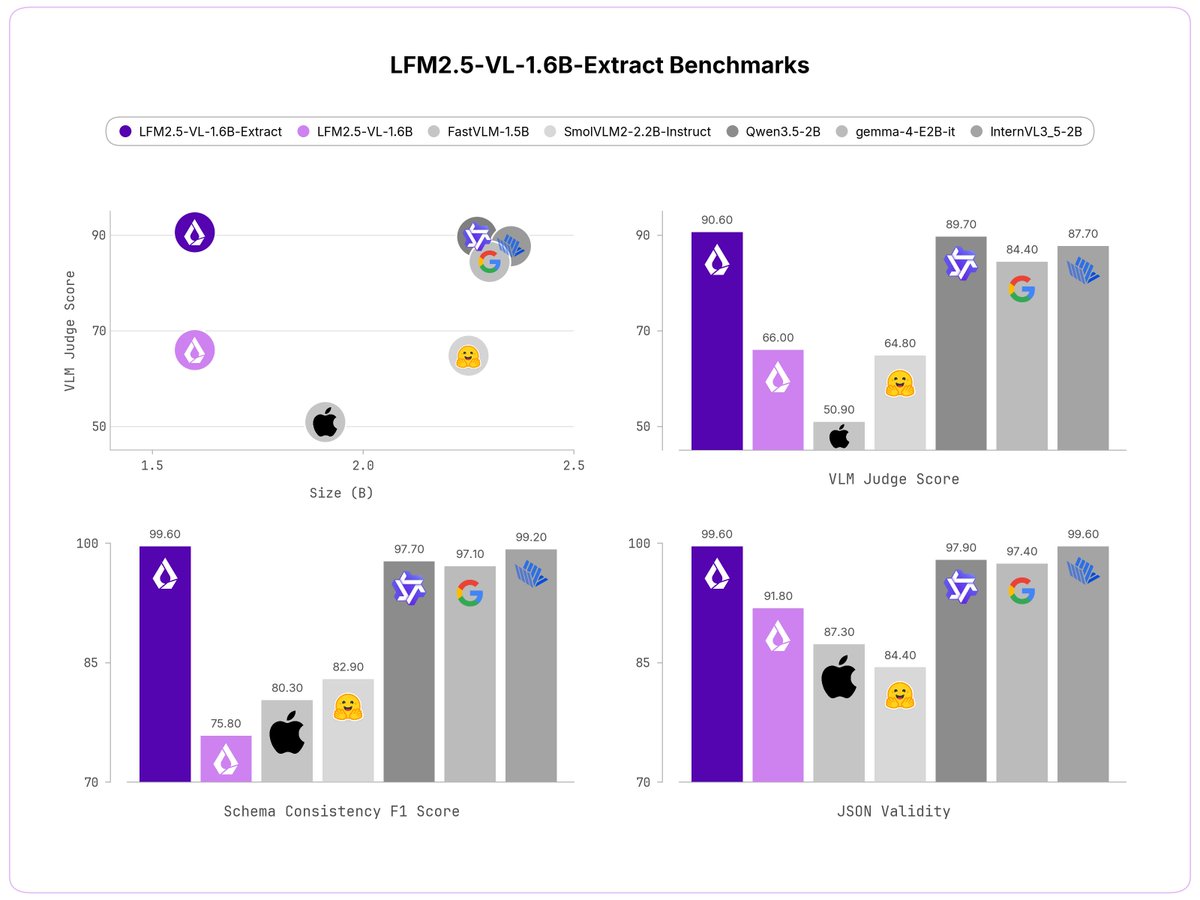
Introducing LFM2.5-VL-1.6B-Extract and LFM2.5-VL-450M-Extract: Vision-language models that return structured JSON, not free-form text.
Pass in an image and a list of fields. Get back a clean JSON object.
> Two sizes: 1.6B parameters and 450M
> open-weight
> run on any device SoC
🧵
38
150
1,200
94,594
Stephen McConnachie retweeted

Jun 2
AI video editors can't edit what isn't indexed. Learn how a developer used Gemma 4 31B locally on a 5-year-old laptop to process and index a year of raw, unlabeled video, making it fully searchable. A great look at building local-first tools.
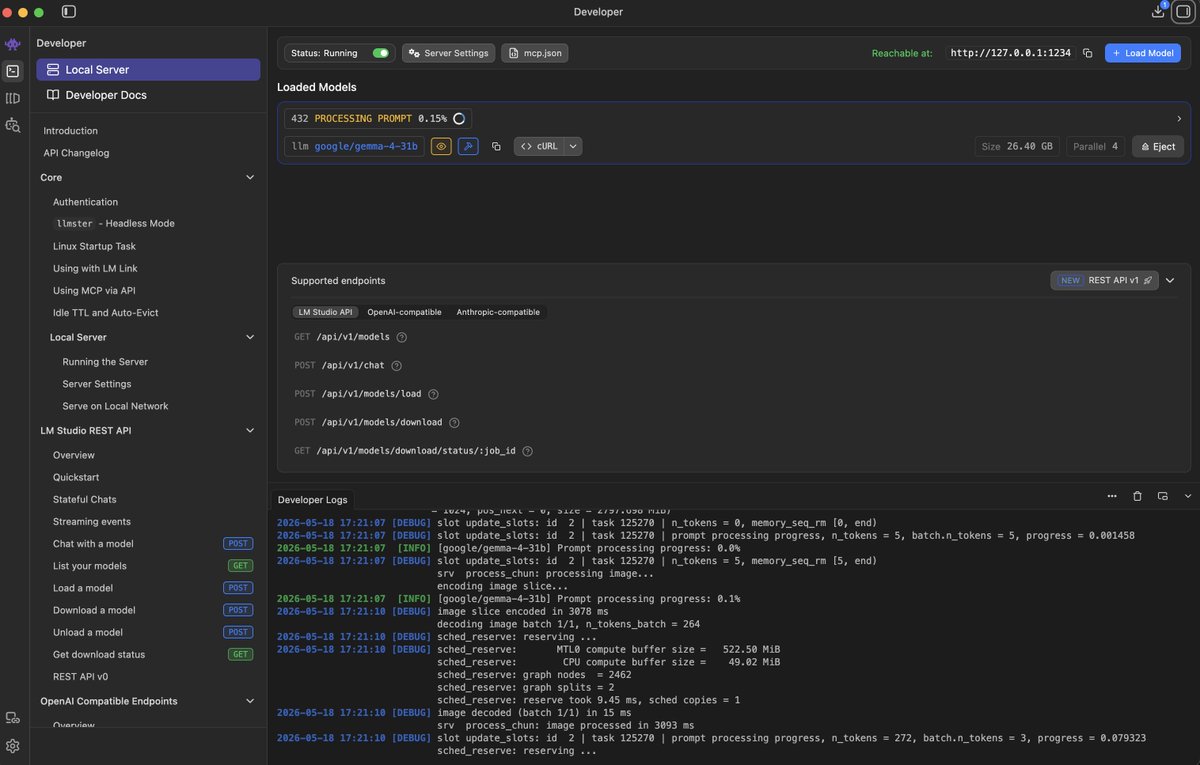
30
160
1,261
57,045
Stephen McConnachie retweeted

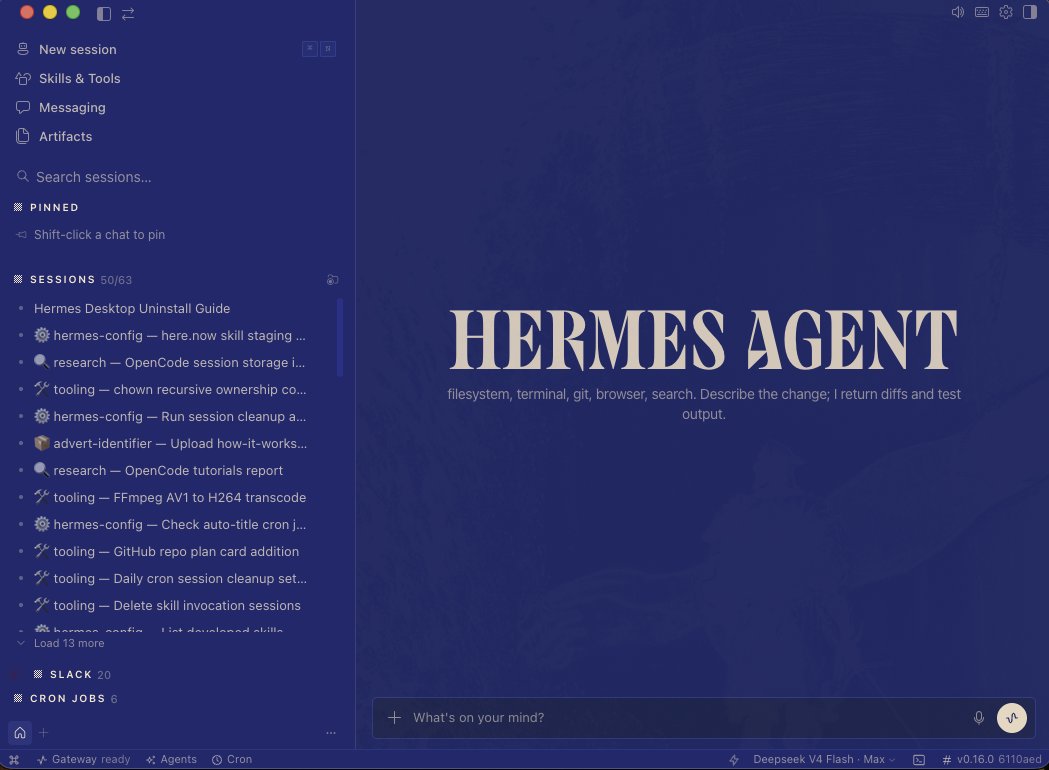
Jun 2
The next evolution of Hermes Agent is here!
Introducing Hermes Desktop: everything you love about Hermes, now native on your machine.
First demoed in Jensen's GTC keynote, it's now in public preview.
1,230
1,459
12,752
5,808,839
Stephen McConnachie retweeted

Jun 1
Dear colleagues! Our call for proposals is still open for #nttw10! All the info and link for submitting here: mediaarea.net/NoTimeToWait10. Look forward to reading you!
3
4
114
Stephen McConnachie retweeted
May 31
parakeet.cpp: native C /ggml (@ggml_org) inference for @NVIDIAAIDev's Parakeet, one of the best speech-to-text models out there, from the @LocalAI_API team.
Every Parakeet model (TDT/CTC/RNNT/hybrid cache-aware streaming), byte-for-byte identical output to NeMo, now running anywhere with no Python and even a bit faster, on CPU and GPU.
Quantized GGUF on @huggingface 🤗
Huge thanks to @ggerganov for ggml and to @NVIDIAAIDev for releasing Parakeet! 🧵
14
56
367
55,334
Stephen McConnachie retweeted

May 29
llama.cpp now has an official website: llama.app
Our goal is to make local AI accessible to everyone, and improving the user experience is a big part of that. On the new landing page you’ll find a single-line cross-platform installer. The installation provides a single unified `llama` entrypoint which you can use to run/serve models and interface with 3rd-party agentic applications.
While oriented towards simplified user experience, the new `llama` application also provides all the advanced functionality of the existing llama.cpp tooling with which experienced users are already familiar. Also note that all GGUF models that you might have already downloaded with llama.cpp in the past will be automatically available to use without downloading again (they are stored in the common HF cache on your machine).
We have many improvements in the pipeline both at the UX and at the engine level and we plan to iteratively ship new things over the coming months. One of the main focuses will be seamless integration with local-friendly 3rd-party agents (such as Pi). In the meantime, we’ll continue to listen for feedback from the community and adjust accordingly, so keep letting us know what you think and need.
96
483
2,980
164,056
Stephen McConnachie retweeted

May 29
⚡️ Step 3.7 Flash is here: The new frontier is agent efficiency.
#1 ClawEval-1.1 (67.1), #1 SimpleVQA Search (79.2), #2 SWE-PRO (56.3), 95.3 on V* Python. Open weights under Apache 2.0.
Built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution.
- 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels.
- Understands UIs, charts, docs, images — then writes code or calls tools to act on what it sees.
- Web visual search reaches further: more sources, deeper follow-up.
- Reliable tool use — less drift, fewer broken toolcalls. 98% on τ²-bench across all difficulty levels.
- Works with Claude Code, KiloCode, Hermes Agent, OpenClaw, and protocols like MCP.
- Runs locally on Mac Studio M4 Max, DGX Spark, AMD AI Max 395.
GitHub: github.com/stepfun-ai/Step-3…
HuggingFace: huggingface.co/stepfun-ai/St…
GGUF: huggingface.co/stepfun-ai/St…
ModelScope: modelscope.cn/models/stepfun…
API: platform.stepfun.ai
Blog: static.stepfun.com/blog/step…
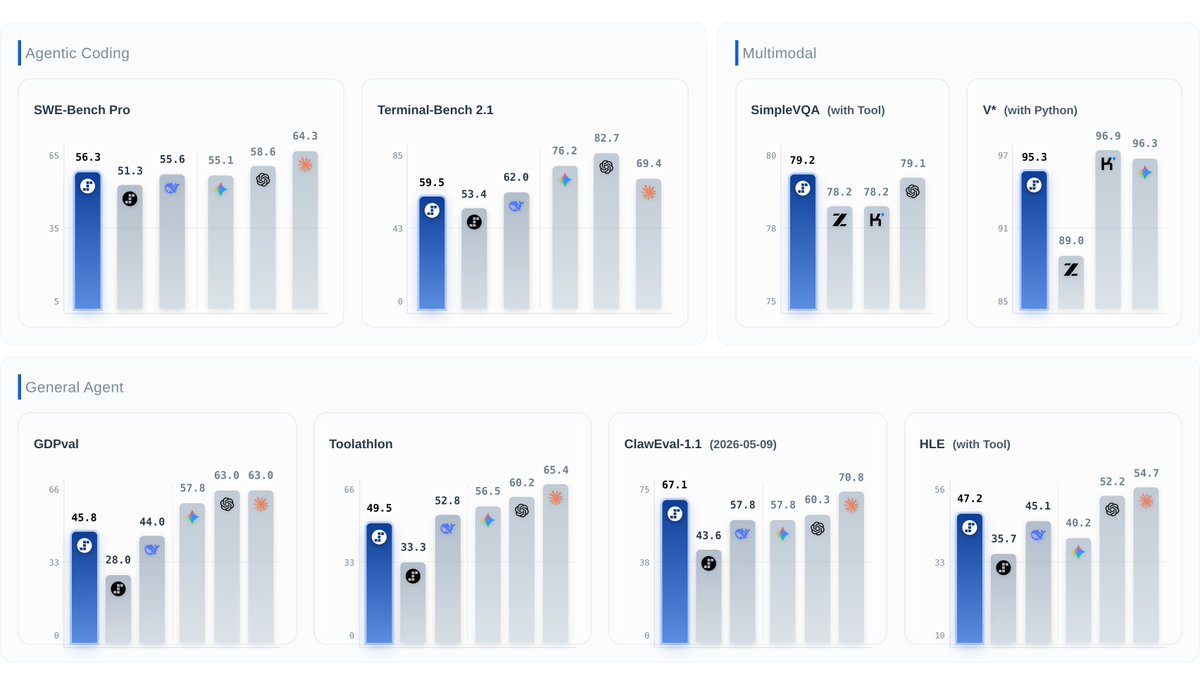
120
213
1,542
339,840
Stephen McConnachie retweeted

May 29
Step-3.7-Flash 🔥 New VL model from @StepFun_ai
✨ 198B / 11B active - MoE
✨ 256K context
✨ 3 reasoning level
✨ Up to 400 tokens/sec 🤯

2
9
96
4,677

This #CVPR2026 paper from our research team is trending #1 on @HuggingFace 🤗
Meet LocateAnything: a vision-language detection model that rethinks bounding box prediction. For AI agents and robots, “seeing” is only useful if a model can pinpoint where something is fast enough to act.
Trained on 138M high-quality samples, LocateAnything decodes bounding boxes in parallel instead of one coordinate at a time, improving localization accuracy while dramatically increasing throughput for visual grounding and detection.
Project page: nvda.ws/4dKSohb
55
333
2,187
327,115
Stephen McConnachie retweeted
May 26
cool new release: a tiny open video VLM that understands what happens in videos and when 👀
Marlin-2B (Apache 2.0!) can caption clips into timestamped events, or find a natural-language moment inside the video (can see a ton of cool use cases with it)
Made a Hugging Face demo for it ⬇️
14
50
312
24,956