
PhD, AI Researcher at BayzAI. Bayesian Methods for AI, AI Fairness, RL for AD .
Joined January 2011
- Tweets 849
- Following 730
- Followers 216
- Likes 4,529
12 Photos and videos











28 Aug 2025
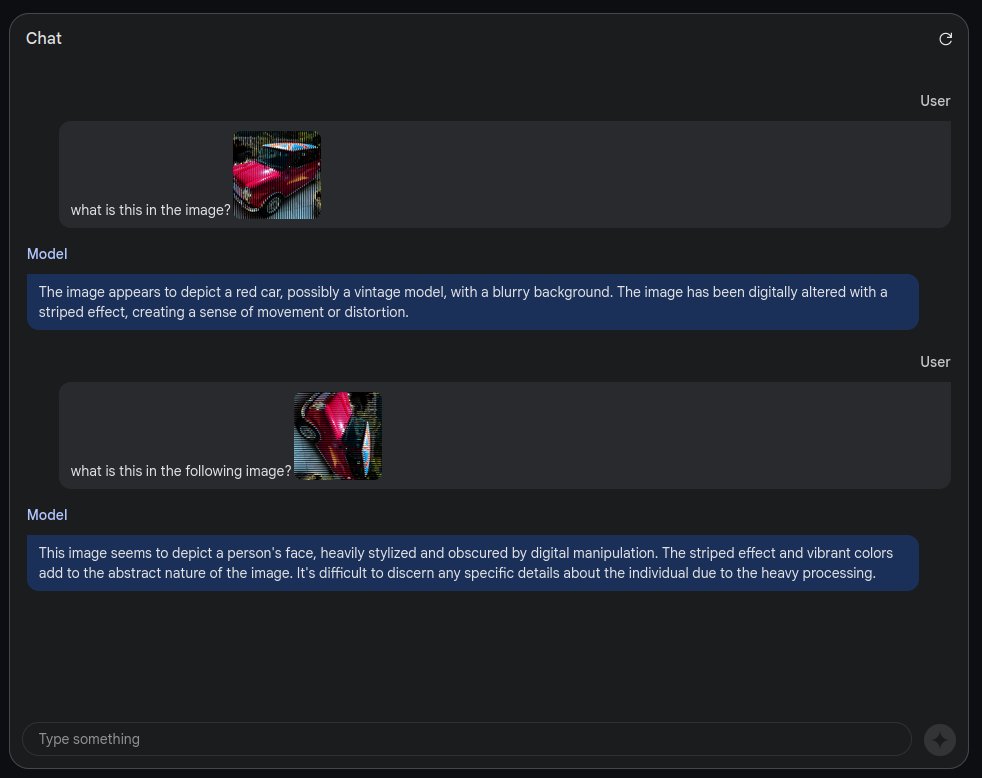
Priors are all you need!
28 Aug 2025

Insightful blog post from @ShunyuYao12 about what's needed for next level of AI progress. He's been driving AI progress since his work @PrincetonPLI including SWE-Bench.
Related but somewhat divergent view from @karpathy who argues (correctly in my opinion) that we need to go beyond current simplistic ideas in RL. x.com/karpathy/status/196080…
77
3 Jul 2025
Cool!
2 Jul 2025

🧵 What if two images have the same local parts but represent different global shapes purely through part arrangement? Humans can spot the difference instantly! The question is can vision models do the same?
1/15
3
123
1 Jul 2025
Transition Matching (TM), a novel discrete-time, continuous-state generative paradigm that unifies and advances both diffusion/flow models and continuous AR generation:
1 Jul 2025

Transition Matching: Scalable and Flexible Generative Modeling
"This paper introduces Transition Matching (TM), a novel discrete-time, continuous-state generative paradigm that unifies and advances both diffusion/flow models and continuous AR generation. TM decomposes complex generation tasks into simpler Markov transitions, allowing for expressive non-deterministic probability transition kernels and arbitrary non-continuous supervision processes, thereby unlocking new flexible design avenues."

144
1 May 2025
Integration Flows: a novel generative modeling framework
30 Apr 2025
Integration Flow Models
"Integration Flow is the first model with a unified structure to estimate ODE-based generative models and the first to show the exact straightness of 1-Rectified Flow without reflow."

69
michael tetelman retweeted

19 Apr 2025
The most advanced AI systems will likely exist first within the companies that developed them, with little opportunity to collectively prepare for their impacts. This dynamic creates unique risks highlighted in this recent paper by @apolloaievals and should become a growing priority for AI policy.
17 Apr 2025

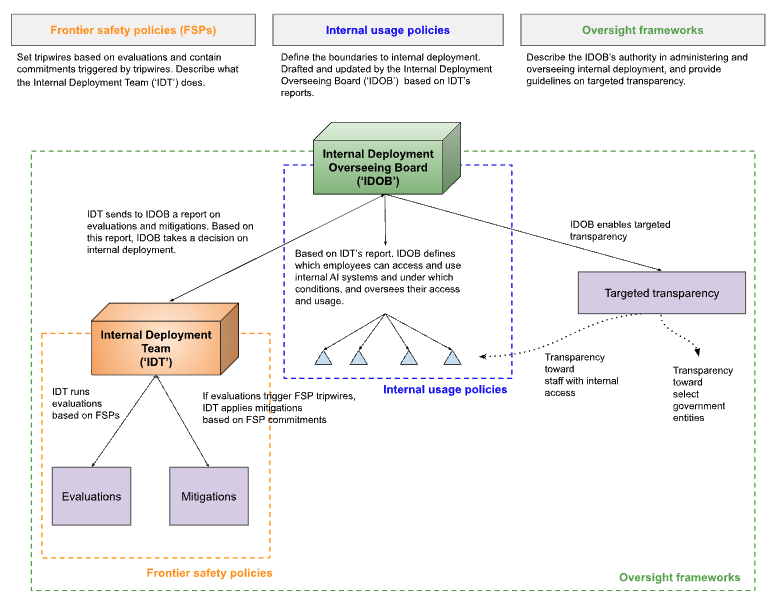
🧵 Today we publish a comprehensive report on "AI Behind Closed Doors: a Primer on The Governance of Internal Deployment". Our report examines a critical blind spot in current governance frameworks: internal deployment.
9
65
326
25,299
3 Jan 2025
After 20 years of being with @Verizon I with all my family determine to leave to another carrier after @VerizonSupport was unwilling to make an exception in their stupid sim locking policy that makes our phones unusable. Shame on you @Verizon .
1
132
michael tetelman retweeted

11 Oct 2024
What if you could make physics diagrams come alive? At #UIST2024, we will be presenting our paper, Augmented Physics, an ML-Integrated Authoring Tool for Creating Interactive Physics Simulations from Static Diagrams
Co-authors: @Freya_Wyy @nandizhang_ Jarin @rubaiat @ryosuzk
106
1,051
5,616
413,578
michael tetelman retweeted

8 Oct 2024
BREAKING NEWS
The Royal Swedish Academy of Sciences has decided to award the 2024 #NobelPrize in Physics to John J. Hopfield and Geoffrey E. Hinton “for foundational discoveries and inventions that enable machine learning with artificial neural networks.”

979
13,040
32,143
12,691,095
30 Sep 2024
Completing quantum computation before even starting it would be a lot of fun. See details in scientificamerican.com/artic…
1
41
20 Sep 2024
It's Friday. I asked llama3.1:405b to create some cooking recipe.
And here it is.
56
michael tetelman retweeted

31 Aug 2024
If you’d like to spend a few hours this weekend to dive into Large Language Models (LLMs) and understand how they work, I've prepared a 3-hour coding workshop presentation on implementing, training, and using LLMs: youtube.com/watch?v=quh7z1q7…
30
426
2,417
178,038
31 Jul 2024
Great idea
31 Jul 2024

arXiv -> alphaXiv
Students at Stanford have built alphaXiv, an open discussion forum for arXiv papers. @askalphaxiv
You can post questions and comments directly on top of any arXiv paper by changing arXiv to alphaXiv in any URL!
2
173
31 Jul 2024
Cool
31 Jul 2024

A long needed PyTorch example --
export models to desktop and mobile apps (without python), providing a native alternative to llama.cpp and other great projects in this space.
The exported models are compiled (using torch.compile) and are competitive on speed and memory use.
69
3 Jul 2024
Must see when available
3 Jul 2024

I am excited to be giving a 4-hour tutorial on "Pretraining and Finetuning LLMs from the Ground Up" at the @SciPyConf conference in 5 days!
This tutorial is aimed at coders interested in understanding the building blocks of large language models (LLMs), how LLMs work, and how to code them from the ground up in PyTorch. After grasping how everything fits together and how to pretrain an LLM, we will learn how to load pretrained weights and finetune LLMs using open-source libraries.
I am currently putting the final touches on the code and will share it along with a reproducible environment soon (github.com/rasbt/LLM-worksho…).
The (I hope not too ambitious) schedule is as follows:
1) Introduction to LLMs: An introduction to the workshop, covering LLMs, the topics being discussed, and setup instructions.
2) Understanding LLM Input Data: In this section, we will code the text input pipeline by implementing a text tokenizer and a custom PyTorch DataLoader for our LLM.
3) Coding an LLM Architecture: We will go over the individual building blocks of LLMs and assemble them in code. We won't cover all modules in meticulous detail but will focus on the bigger picture and how to assemble them into a GPT-like model.
4) Pretraining LLMs: We will cover the pretraining process of LLMs and implement the code to pretrain the model architecture we created. Since pretraining is expensive, we will only pretrain it on a small text sample available in the public domain so that the LLM is capable of generating some basic sentences.
5) Loading Pretrained Weights: Due to the lengthy and expensive nature of pretraining, we will load pretrained weights into our self-implemented architecture. We will introduce the LitGPT open-source library, which provides more sophisticated (but still readable) code for training and finetuning LLMs. We will learn how to load weights of pretrained LLMs (Llama, Phi, Gemma, Mistral) in LitGPT.
6) Finetuning LLMs: This section will introduce LLM finetuning techniques. We will prepare a small dataset for instruction finetuning, which we will then use to finetune an LLM in LitGPT.
I know I say this every year, but I am really excited to be returning to my favorite conference once more! It's going to be my fifth SciPy this year, and I am thrilled to see it at a new location (Tacoma/Seattle) this time!

422
28 Jun 2024
Wonder what JEPA is? Read this
28 Jun 2024

Excellent blog post from Turing Post on JEPA (Joint Embedding Predictive Architecture), my favorite meta-architecture for Self-Supervised Learning of continuous data, such as images, video, and audio.
The post includes a list of relevant papers from my collaborators and me, as well as part of the growing list of papers from other groups that use JEPA for various things: audio, EEG, SAR, LIDAR, etc.
A small clarification: JEPA is not an alternative to transformers. I'm fact, many JEPA systems use transformer modules.
It is an alternative to Auto-Regressive Generative Architectures (such as LLMs), regardless of whether they use transformers.
turingpost.com/p/jepa
1
180
14 Jun 2024
Cool: Vision-Language-Action model:
14 Jun 2024

OpenVLA is a VLM for robot control, open-source & available for the community: openvla.github.io/
Awesome collaboration led by @moo_jin_kim, @KarlPertsch, @siddkaramcheti
W.r.t. large-scale robotic learning, this is an important step in making VLAs accessible. A thread 👇
1
244
10 Jun 2024
Love this.
9 Jun 2024
It is of paramount importance that the management of a research lab be composed of reputable scientists.
Their main jobs are to:
1. Identify, recruit, and retain brilliant and creative people.
2. Give them the environment, resources, and freedom to do their best work.
3. Identify promising research directions (often coming from the researchers themselves) and invest resources in them. Put the scientists in charge and get out of the way.
4. Be really good at detecting BS, not necessarily because scientists are dishonest, but often because they are self-deluded. It's easy to think you've invented the best thing since sliced bread. Encouraging publications and open sourcing is a way to use the research community to help distinguish good work from not-so-good work.
5. Inspire researchers to work on research projects that have ambitious goals. It's too easy and less risky to work on valuable improvements that are incremental.
6. Evaluate people in ways that don't overly focus on short-term impact and simple metrics (e.g. number of publications). Use your judgment. That's why you get paid the big bucks.
7. Insulate rogue-but-promising projects from the scrutiny of upper management. A watched pot never boils. Planned innovation and 6-months milestones never bring breakthroughs.
You can't do any of this cat herding jobs unless you are an experienced, talented, and reputable scientist with a research record that buys you at least some legitimacy in the eyes of the scientists in your organization.
2
171

🔥Phi-3 Vision Model is out!
🏛️Architecture: Phi-3-Vision-128K-Instruct has 4.2B parameters and contains image encoder, connector, projector, and Phi-3 Mini language model.
📝Inputs: Text and Image. Best suited for prompts using the chat format.
🔢Context length: 128K!🤯 More 👇
11
86
399
63,138
21 May 2024
Scale effect of LLM:
21 May 2024

New Anthropic research paper: Scaling Monosemanticity.
The first ever detailed look inside a leading large language model.
Read the blog post here: anthropic.com/research/mappi…

ALT Title card for Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
1
141