
Joined February 2021
- Tweets 176
- Following 212
- Followers 2,386
- Likes 528
3 Photos and videos


mei retweeted

May 21
Raising $ is cool. What’s even cooler is getting to work every day with this incredible group of humans.
We like solving hard problems and building things we can be proud of. If this is you, come join us! We’re just getting started :)


19
20
281
51,077

🐋 DeepSeek V4 is now merged into SGLang main with v0.5.12.
What we shipped at launch:
🔹 ShadowRadix: native prefix caching for V4's hybrid attention
🔹 HiSparse: CPU-extended KV for sparse attention (up to 3× long-context throughput)
🔹 MTP speculative decoding with in-graph metadata preparation
🔹 W4A8 MegaMoE kernel
🔹 Flash Compressor Lightning TopK kernels
🔹 Multiple parallelism methods: Tensor Parallelism/Expert Parallelism/Context Parallelism/Data Parallelism Attention
🔹 Prefill Decode Disaggregation
🔹 Hardware: H100, H200, B200, B300, GB200, GB300, MI35X
And what we added since:
🔹 HiCache for V4 under UnifiedRadixTree
🔹 W4A4 MegaMoE kernels for faster MegaMoE
🔹 Marlin/FlashInfer MXFP4 (W4A16) MoE on Hopper
🔹 Hierarchical multi-stream overlap for small-batch decode
🔹 Optimized mHC pipeline: DeepGemm fused norm fused hc_head
🔹 Faster KV Compression V2 kernel
🔹 Fused SiLU clamp FP8 quantization kernel
🔹 Support TP16 on H100/H20
🔹 Support Multiple Detokenizers
🔹Pipeline Parallelism
🔹One docker image for all supported Nvidia hardware
Thanks to @NVIDIAAI, @AMD, @ant_oss, @alibaba_cloud, ByteDance, @iFLYTEKLab, @radixark, and @pranjalssh for the work we shipped together on V4 🙌
More in 0.5.12 👇

9
33
201
14,598


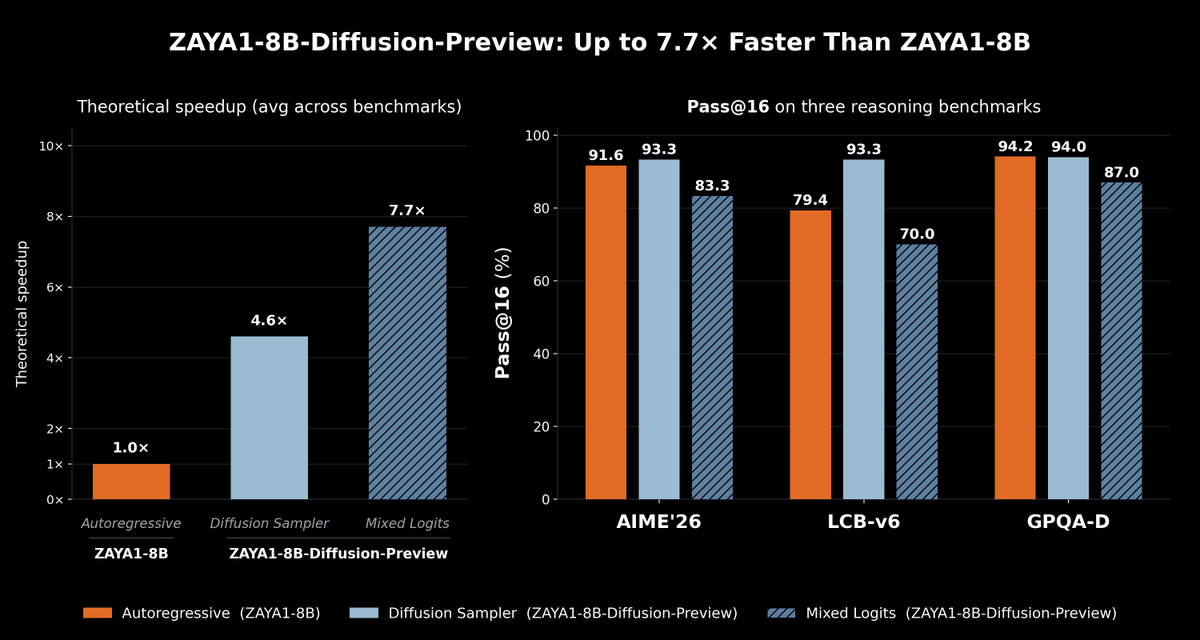
We present ZAYA1-8B-Diffusion-Preview, the first diffusion language model trained on @AMD.
Autoregressive LLMs generate one token at a time; diffusion generates a block in parallel, speeding up inference.
We show a 4.6-7.7x decoding speedup with minimal quality degradation 🧵
22
85
691
1,103,268
mei retweeted

May 14
SGLang team is cracked. Respect 🫡

🌊 SGLang now supports @poolsideai's Laguna-XS.2, a 33.4B-A3B hybrid SWA MoE model purpose-built for agentic coding and long-horizon SWE work
☑️ SWE-bench Verified 68.2%; Multilingual 62.4%; Pro 44.5%; Terminal-Bench 2.0 30.1%
☑️ 131K-token context for long agent traces
☑️ Native poolside_v1 reasoning tool-call parsers (OpenAI-compatible)
☑️ BF16, FP8, and NVFP4 quantizations
👉 Cookbook: docs.sglang.io/cookbook/auto…

5
19
3,483

mei retweeted

May 11
thinking machines is using SGLang btw

May 11

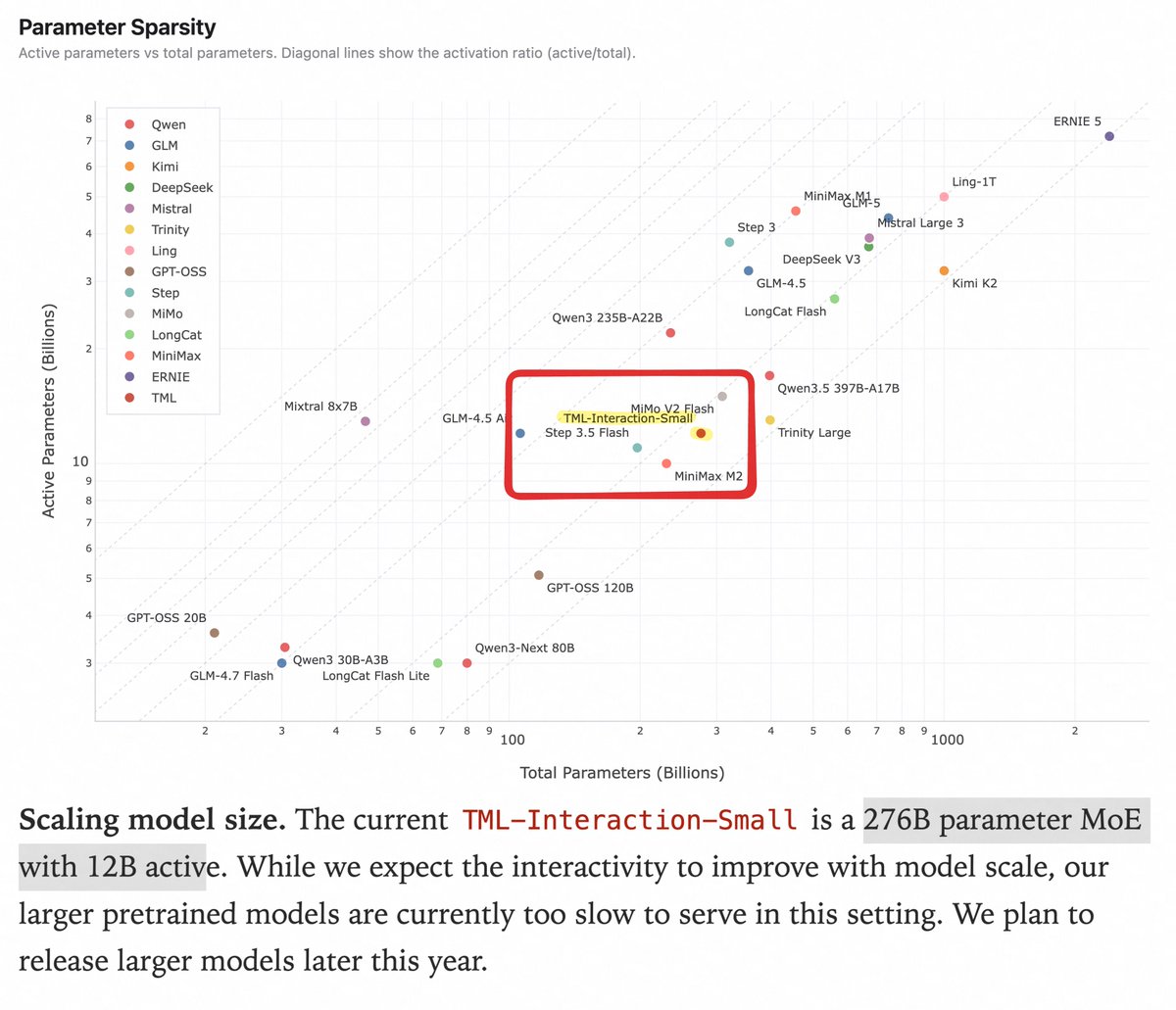
the "small" model behind this demo is a 276B total 12B active MoE (larger pretrains are cooking), sparsity ratio looks pretty standard compared to open models of the same size
6
16
334
29,075
mei retweeted

I've been saying
Zyphra is an exceptional neolab, on all levels from moral to technical to financial. They have done what Geohot has failed to do: made AMD relevant again. They'll reap the rewards for it.
Truly, DeepSeek of the West

Today we’re announcing 15MW of AMD Instinct MI355 GPU capacity through Zyphra Cloud, our full-stack neocloud powered by @AMD.

6
11
324
22,606
mei retweeted

May 9
I’ve been consistently impressed by zephyra, and have always felt a kinship with their cause. Beautiful work across the board, and what a slate of releases this week.
Western open weights is going to have a hell of a year.
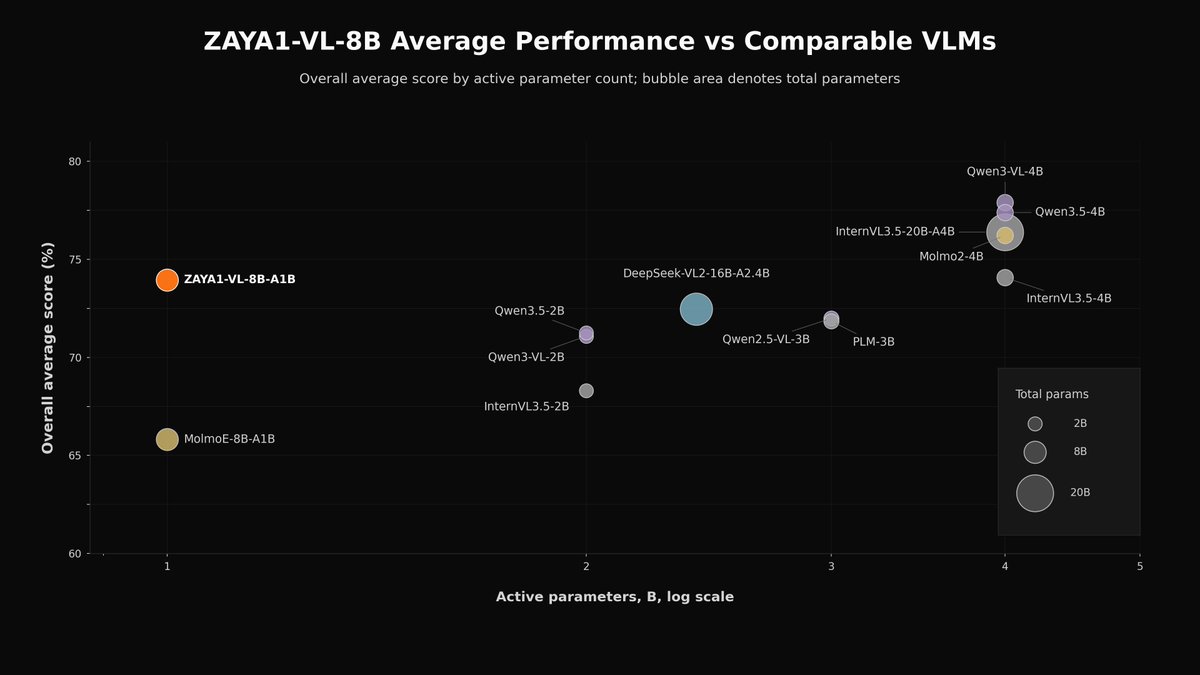
Today we're releasing ZAYA1-VL-8B, our first vision-language model.
ZAYA1-VL-8B is a 700M active / 8B total MoE built on our ZAYA1-8B base trained on @AMD. We achieve strong performance for our size resulting in leading intelligence density and inference efficiency.
2
4
64
4,338
mei retweeted
They keep going!
Today we're releasing ZAYA1-VL-8B, our first vision-language model.
ZAYA1-VL-8B is a 700M active / 8B total MoE built on our ZAYA1-8B base trained on @AMD. We achieve strong performance for our size resulting in leading intelligence density and inference efficiency.
2
5
62
5,664
mei retweeted

May 8
With this release we have rounded out our full suite of core modalities: Language, Vision, Audio, and Thought
This is the first step on our path to ubiquitous and efficient open visual understanding, and we have an exciting roadmap ahead.
Congrats to the team. Amazing work!
Today we're releasing ZAYA1-VL-8B, our first vision-language model.
ZAYA1-VL-8B is a 700M active / 8B total MoE built on our ZAYA1-8B base trained on @AMD. We achieve strong performance for our size resulting in leading intelligence density and inference efficiency.
2
4
54
4,822
mei retweeted

May 9
Amazing work from the @sgl_project and @radixark team for their work optimizing DeepSeek V4 inference on B200, B300, and the recent 4x iso-interactivity throughput improvements on GB300 by @ChengWan17! As @elonmusk said, The GB300 is the best AI computer, and software optimizations like this show its true potential!

7
36
261
35,790

May 7
4
54
4,787
mei retweeted

May 6
okay this looks like something
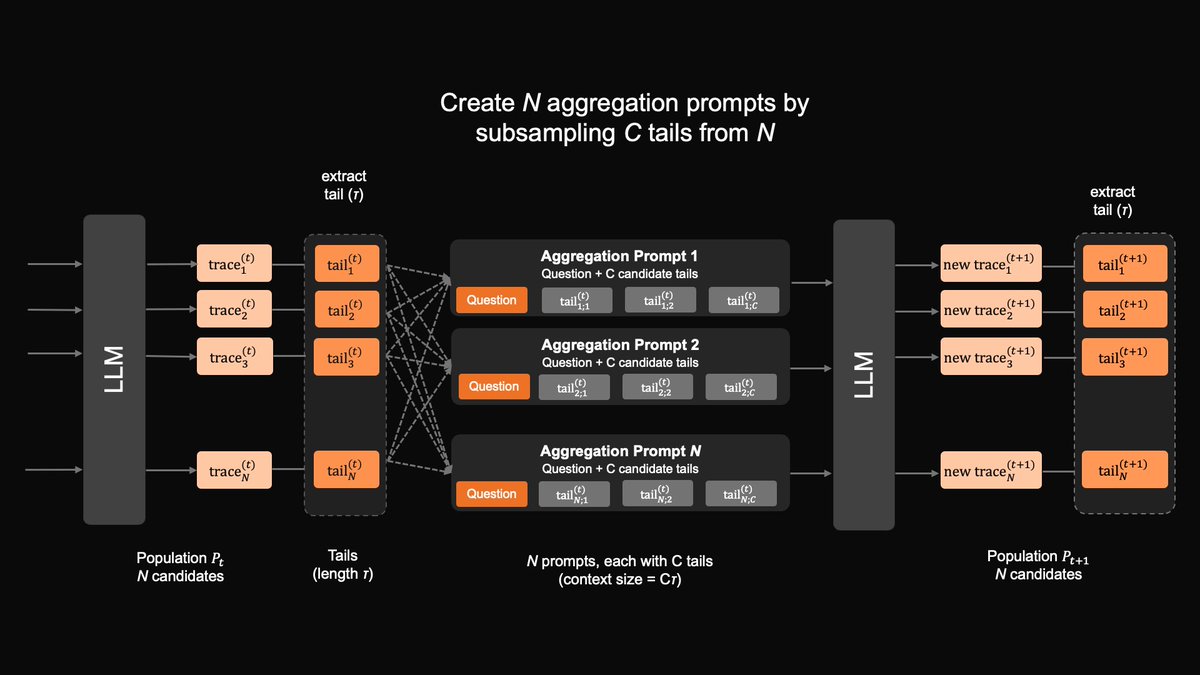
We introduce Markovian RSA: recursive candidate aggregation with bounded carryover. Each round passes only the last τ tokens of each candidate forward, so no matter how long the model reasons for, the context length always remains bounded.
1
1
33
4,635
mei retweeted

May 6
new model! strong <1B active MoE
led data and posttraining for this release. cca goat @rishiiyer01 and the pretraining squad cooked
x.com/ZyphraAI/status/205210…
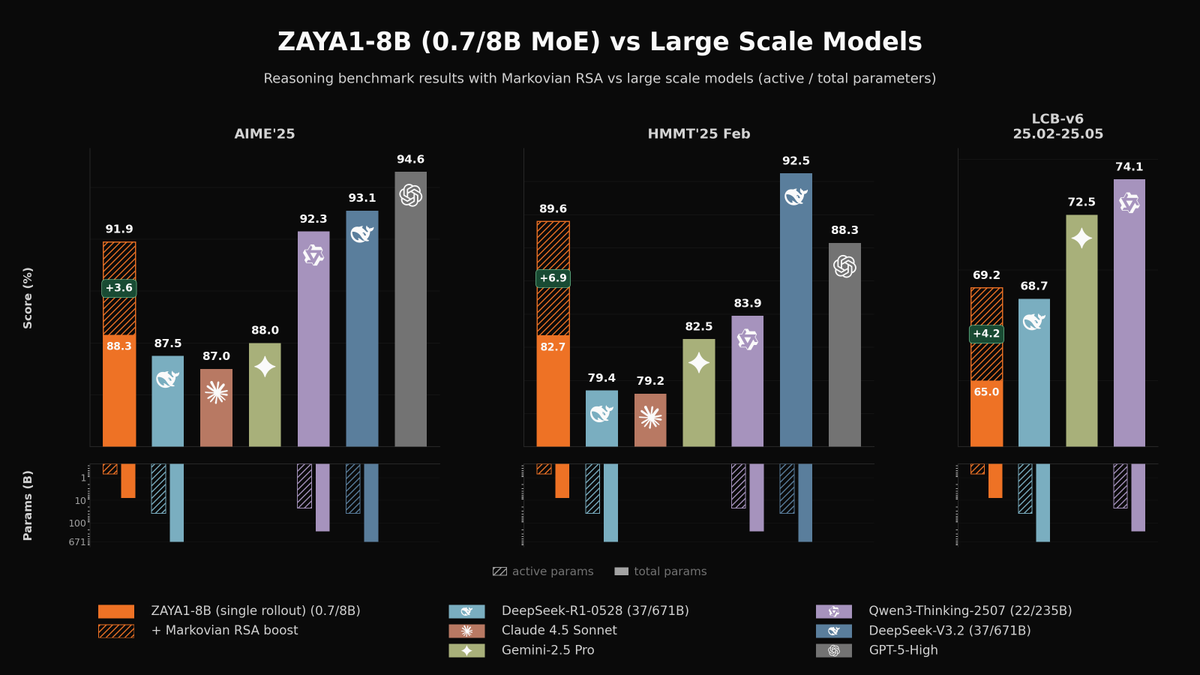
Today we're releasing ZAYA1-8B, a reasoning MoE trained on @AMD and optimized for intelligence density.
With <1B active params, it outperforms open-weight models many times its size on math and reasoning, closing in on DeepSeek-V3.2 and GPT-5-High with test-time compute. 🧵
8
12
75
5,886
mei retweeted
May 6
Incredible work from the entire Zyphra team for this one! We never expected that our small ZAYA1 would be able to compete (at least in math) with the frontier giants. Our post-training and pre-training stacks are strong.
More general thoughts on the ZAYA release, a 🧵
Today we're releasing ZAYA1-8B, a reasoning MoE trained on @AMD and optimized for intelligence density.
With <1B active params, it outperforms open-weight models many times its size on math and reasoning, closing in on DeepSeek-V3.2 and GPT-5-High with test-time compute. 🧵
9
8
86
6,350
May 7
RT @gm8xx8: Zyphra remains one of my favorite teams in the game because the releases all point in the same direction: capable AI that is ch…
3
mei retweeted

May 6
what a release jesus
Today we're releasing ZAYA1-8B, a reasoning MoE trained on @AMD and optimized for intelligence density.
With <1B active params, it outperforms open-weight models many times its size on math and reasoning, closing in on DeepSeek-V3.2 and GPT-5-High with test-time compute. 🧵
8
34
941
161,271

not many Western open-source labs are willing to take real research risks, but @ZyphraAI is one of the few that does
great release, interesting new arch, strong rl. Missing a bit of agentic but strong potential imo
I feel like the folks at @ZyphraAI are massively underrated
Today we're releasing ZAYA1-8B, a reasoning MoE trained on @AMD and optimized for intelligence density.
With <1B active params, it outperforms open-weight models many times its size on math and reasoning, closing in on DeepSeek-V3.2 and GPT-5-High with test-time compute. 🧵
8
12
207
28,810