
@UCSF surgeon. Researching AI for clinical reasoning. Health policy for @FT, WaPo. Cofounder @memorahealth (acq). Alum @ycombinator w18, @harvardmed.
Joined December 2012
- Tweets 5,183
- Following 931
- Followers 2,721
- Likes 16,943
393 Photos and videos
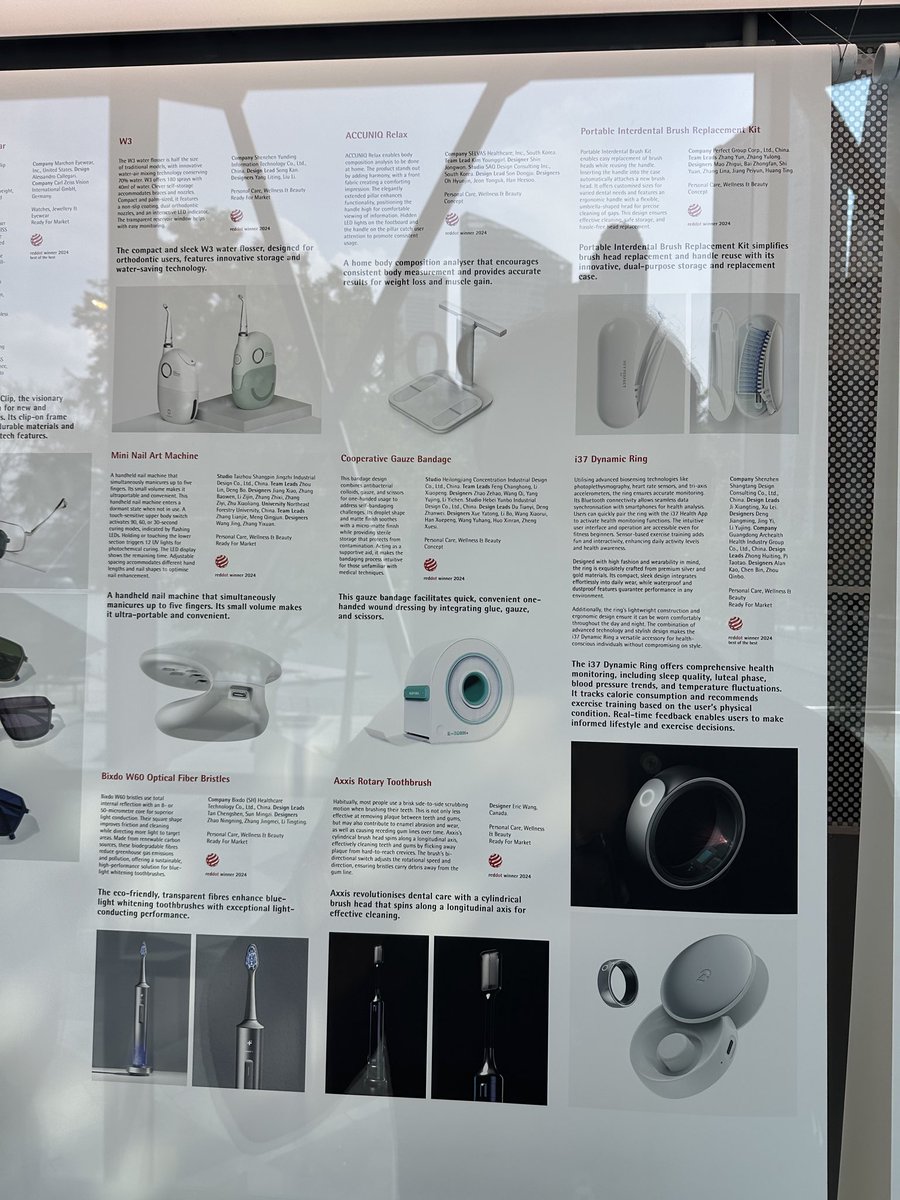










Jun 13
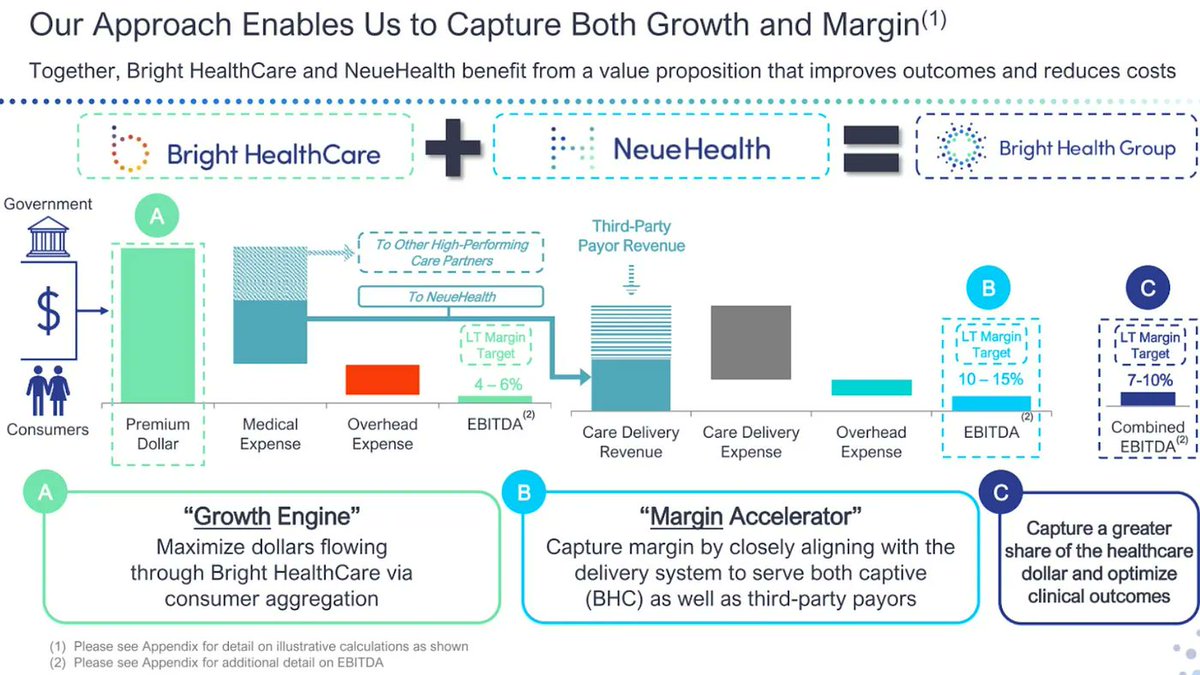
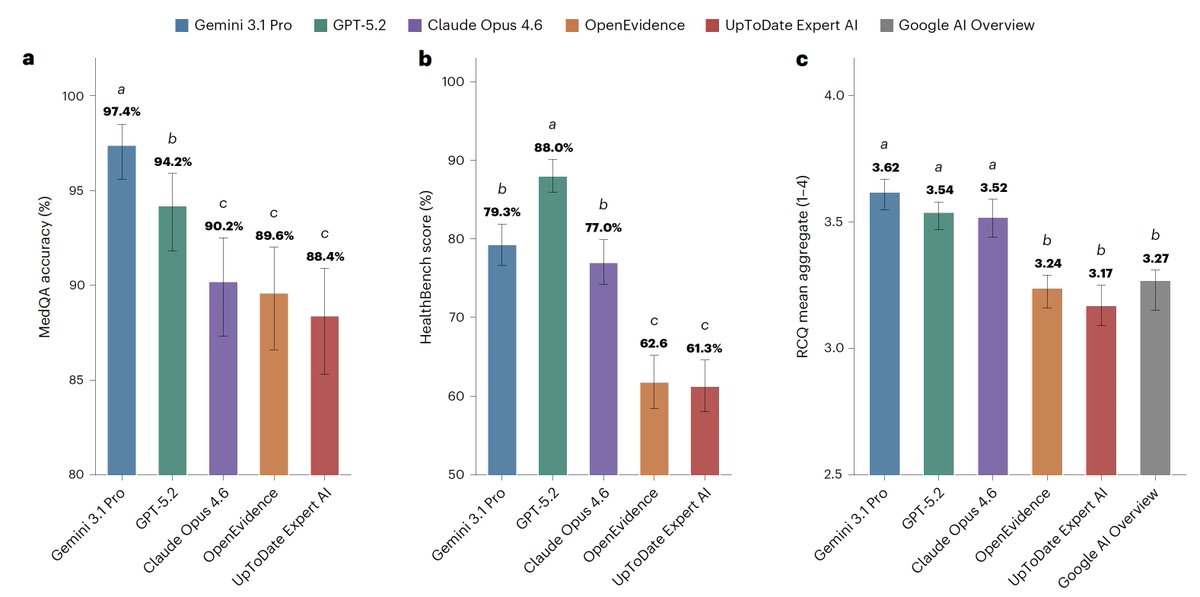
Seeing a lot of bitter lesson/scale > specialized model tweets about this study, but short of OE/UTD intentionally buying weaker models, this result is more of a *harness* issue than a model one.
MedQA score ranges across models were within 9 points (so less likely a base knowledge gap); the gap between gen vs clinical models widened on the real world clinical question answers, where the problems were mostly in omission and disorganized outputs rather than wrong facts.
Jun 12

For medical information, general AI frontier models (Google, OpenAI, Anthropic) outperformed specialized @EvidenceOpen and @UpToDate as assessed by 12 US clinicians, randomized and blinded to which model and extensive testing/benchmarks. This was not anticipated. @NatureMedicine
nature.com/articles/s41591-0…
7
2
20
5,669
May 27
Me teaching every surgeon I meet how to use ChatGPT for Clinicians / OpenEvidence.
May 27

Forward Deployed Clinician (FDC)
7
4
73
13,170
May 27
Immensely proud.
May 27

I wanted my first public video to be learnings from the past 7.5 years here at @AppliedInt. Hopefully it’s useful to the next set of builders 🐻
3
1,506
Nisarg Patel, MD retweeted

May 12
Quick piece of advice for clinicians being offered equity to join a startup’s clinical or scientific advisory board:
Its total BS when a founder says, “We’re offering you 10,000 shares. That’s 0.1% of the company, and since we just raised at a $100M valuation, that’s $100K of value.”
That is not really how it works. Your common shares are not worth the same as the preferred shares investors just bought. There will likely be future dilution. And the paper value is not the same as actual economic value.
Clinicians should evaluate these roles differently than typical startup advisors because you are not just giving advice. You are lending credibility, validation, and halo to the company’s care model.
The real questions are:
- Do you trust the founders and feel comfortable vouching for them?
- Do you believe the problem they are solving matters?
- Do you believe in the care model they are building?
- Do you believe the product can actually improve care?
If the answer is yes, the opportunity may still be worth it for the learning, relationships, and ecosystem connectivity.
But if you want to evaluate the economics, ask the founder directly: how much dilution do you expect the common stock to take, and what would my advisor shares be worth pre-tax in a low, base, and high exit case?
7
8
104
18,980
Nisarg Patel, MD retweeted

Apr 1
54
94
579
139,082
Mar 19
Healthcare is one of the few sectors where policy has arguably *driven* tech innovation and diffusion rather than vice-versa.
With that in mind, there are plenty of policy levers in both public health and medicine that are positive-sum! Reference pricing to promote service competition and better correlate price to quality, all payer rate setting (e.g., Maryland) to reduce admin complexity, lead removal from paint/water to reduce childhood lead toxicity and resulting healthcare costs, etc. Even tech-specific policies like Cures and TEFCA that improve interop will likely reduce admin overhead as CMS rolls out implementation details over the next few years.
Until we see more policy movement and the implementation science (via academics or industry) to adopt and expand new system-level incentives and interventions, most newcos will, very reasonably, try to maximize adoption by operating within the tradeoffs of cost/quality/access rather than maximizing clinical value per dollar.
Mar 19

Most healthcare “innovation” is zero-sum at best, negative-sum at worst. I want to see more more positive sum HC ideas that grows the surplus rather than shifting it around

3
14
2,298
Feb 19
How long until this is a standard ask for health systems fielding agent vendors? cc @arieldora
Feb 18

Voice agents built with ElevenLabs can now be covered with insurance - in the same way that human agents can!
A first of its kind - adding real risk coverage and accountability, even for the toughest edge cases.
elevenlabs.io/blog/aiuc-anno…
1
10
2,674

If you’re starting an autonomy company today, public roads are the hardest place to begin.
We sat down with @bsofman (CEO @BedrockRobotics) & @malharhar (Special Projects Head @AppliedInt) to discuss picking the right problem for physical AI.

4
11
165
70,681
Nisarg Patel, MD retweeted
13 Nov 2025
AI has given venture capital a new way to repeat an old mistake: kingmaking.
The pattern from 2021 is back: a category becomes "obvious," a top-tier firm anoints its winner, and everyone else acts like the decision is final.
Sierra for support. Harvey for legal. Applied Compute for RL-as-a-service.
68
78
1,113
420,914
30 Oct 2025
My latest in @Health_Affairs on the AI training data challenge health systems shouldn't ignore:
Amidst AI labs moving towards model training on chat history with multi-year retention windows, ~2.6% of Claude & 5.7% of ChatGPT conversations contain clinical content, often as PHI within consumer tiers without BAAs. healthaffairs.org/content/fo…
3
1,465
20 Oct 2025
AWS is down.
Government is shut down.
Epic is still up.
20 Oct 2025

Amazon $AMZN's AWS is still down.
Here are some of the sites affected:
Adobe Creative Cloud
Airtable
Amazon (incl. Alexa & Prime Video)
Apple Music
Asana
AT&T
Battlefield (EA)
Blink (Security)
Boost Mobile
Canva
ChatGPT
Chime
Coinbase
CollegeBoard
Dead By Daylight
Delta Air Lines
Duolingo
EA
Fanduel
Fetch
Fortnite (Epic Games services)
GoDaddy
Grubhub
HBO Max
Hinge
Hulu
IMDb
Instacart
Kik
League of Legends
Life360
Lyft
McDonald’s app
Microsoft (incl. 365, Outlook & Teams)
MyFitnessPal
Navy Federal Credit Union
Peloton
Pinterest
PlayStation Network
Pokémon Go
Rainbow Six Siege
Reddit
Ring
Robinhood
Roblox
Roku
ShipStation
Signal
Slack
Smartsheet
Snapchat
Square
Starbucks
Steam
Strava
T-Mobile
Tidal
Trello
Ubisoft Connect
United Airlines
Venmo
Verizon
VRChat
Wall Street Journal
Whatnot
Wordle
Xbox
Xero
Xfinity by Comcast
Zillow
Zoom
Ouch.
1
1
1,231
20 Oct 2025
Love that AI labs are prioritizing biomedical research.
Between Skills and MCP, the near-term future of computational biology might not necessarily be *better prediction models* but rather *better integration layers* that let general intelligence operate across the full research stack.
20 Oct 2025

We’re launching our Claude for Life Sciences initiative today, including new bioinformatics Skills, and new MCPs from @benchling, @BioRender, PubMed, @WileyGlobal, @Sagebio, @10xGenomics and more:
anthropic.com/news/claude-fo…
4
1,069
7 Aug 2025
Excited for the imminent health system research/ops work on local 1) post-training (to improve hospital-specific clinical context), 2) benchmarking/uncertainty evaluation (to track population-specific accuracy/drift), and 3) continuous model monitoring and rapid on-prem patching (to minimize patient risk).
5 Aug 2025

NEW: OpenAI just released gpt-oss, its first open-weight models since GPT-2.
The 120B model nearly matches o3 on HealthBench, beating GPT-4o and o4-mini -- making it OpenAI’s most efficient model yet.
Big step toward local, low-cost clinical AI.
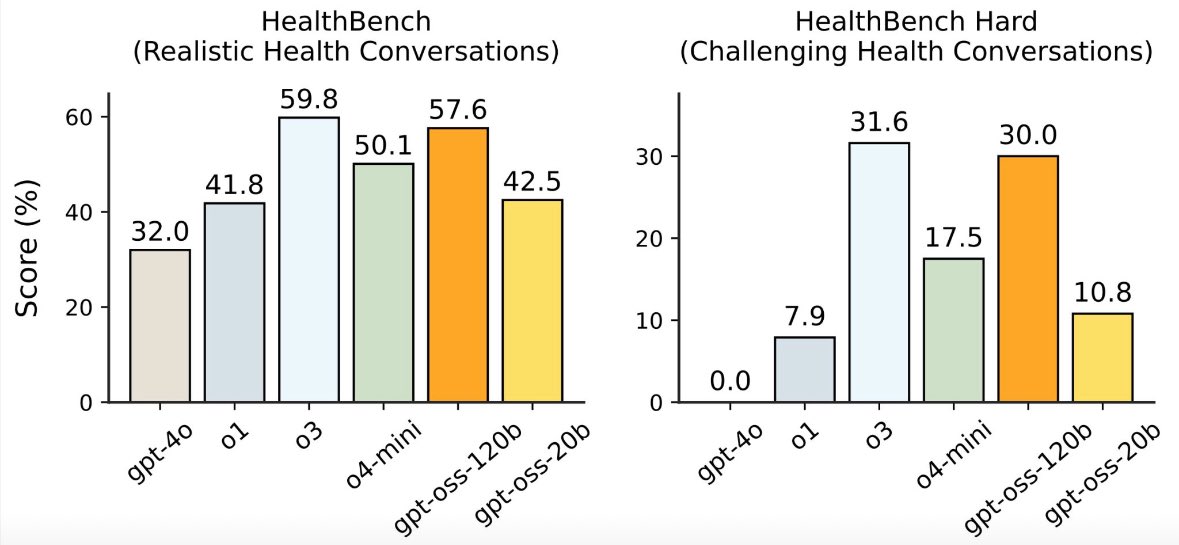
1
13
2,145
22 Jul 2025
This meant that v2 model validation was done in a bespoke fashion tailored to each health system's level of staff resources/expertise and clinical QI sophistication. Univ of Colorado Health offers a helpful example of how intentional validation steps, including model comparisons and monitoring, can both 1) improve patient safety and 2) offer 'unspoken' context to models, i.e., hospital-specific tools, protocols, and available resources that a turnkey model wasn't explicitly trained on.
statnews.com/2022/10/24/epic…
1
2
376
22 Jul 2025
LLMs appear to have significantly better generalizability over prior clinical decision support tools; however, we'll likely need both local (i.e. clinic, health system) and organization-level guidelines (e.g., AMIA) for clinical model governance, auditing, and improvement. Excited to work on that at UCSF.
1
2
290
22 Jul 2025
Finally, despite the incredible appetite for health AI (see @SofiaGuerraR's excellent breakdown), enterprise health systems and SMB clinics will need to assess their own "AI readiness", i.e., data structure/portability, level of AI expertise, cybersecurity standards (a large digital health challenge independent of language models), and staff training capacity. There's plenty of white space to develop a framework and step-by-step implementation protocol here. bvp.com/atlas/the-healthcare…
1
1
3
278
22 Jul 2025
The *standout* point on this work is the excellent focus on effective deployment, user training, and workflow implementation (e.g., minimally intrusive UI), a critical step for real-world studies often overlooked in the prior generation of health AI products (e.g., the remarkably scant public validation data for the now >1000 FDA-cleared AI devices).
22 Jul 2025

📣 Excited to share our real-world study of an LLM clinical copilot, a collab between @OpenAI and @PendaHealth.
Across 39,849 live patient visits, clinicians with AI had a 16% relative reduction in diagnostic errors and a 13% reduction in treatment errors vs. those without. 🧵
2
1
6
906
22 Jul 2025
An unanswered question is *where* the best practices for language model implementation will be designed, within model manufacturers (akin to enterprise SaaS deployment teams) or hospital staff?
For example, the poor performance and criticism of Epic's initial sepsis prediction model led to development of a v2 product trained *locally* to client hospitals/emergency rooms.
jamanetwork.com/journals/jam…
1
1
1
115
24 Jun 2025
Always enjoy reading @DrSidMukherjee's prose, and while his latest @NewYorker essay is a master class in biostats, it also got me thinking about the value of cancer diagnostics outside the typical bayesian/PPV mental model, that is, as *representations* of human pathophysiology.
1
4
600
24 Jun 2025
In the same way that the @arcinstitute team recently used the transcriptome and perturbation data to represent and abstract shifting single-cell states, I believe the future of cancer diagnostics is in designing tools that, when combined, model cancer cell biology and metastasis.
1
1
191
24 Jun 2025
These tools, encompassing molecular, spatial, *and* temporal cell/tissue changes ( tested on in vitro microphysiological systems) may provide data that foundation models will need to 1) precisely gauge the lethality of suspected tumors and 2) assess urgency for intervention.
1
191