
17 Photos and videos

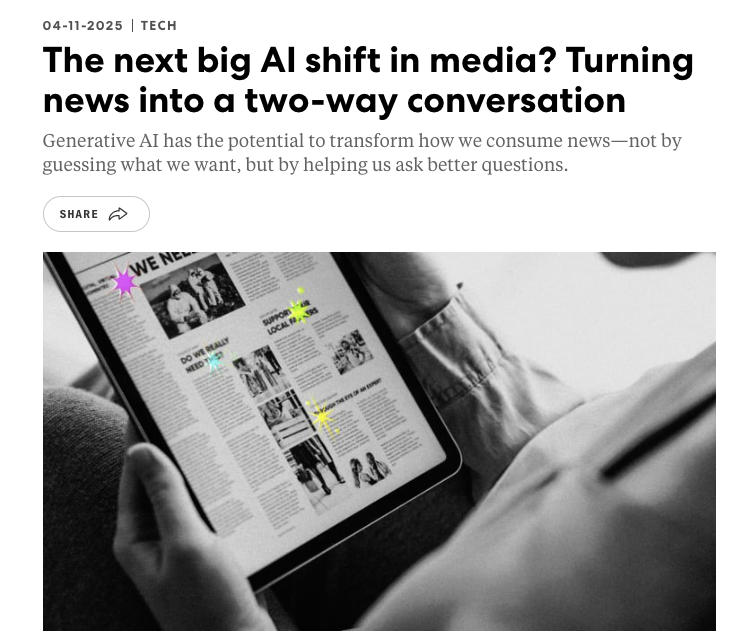









Otis Chandler retweeted

8 Dec 2025
Two conversations this weekend make me think that there's a vibe shift afoot in Silicon Valley around what one should work on and what is worthwhile.
Culturally, it feels like the moment is ripe for new frameworks:
• Davos expert morality is stale and discredited.
• It's also apparent that the "just be super based" Counter-Enlightenment is not really an answer. (Yes, woke went too far, but simply inverting it doesn't work.)
• EA is no longer the automatic default for smart people.
• There's increasing skepticism of slot and slop machine dynamics.
Overall, "what is worthy and valuable?" feels like it's becoming more central.
530
391
6,674
2,109,832

if you've been using OpenProse, you now have a bunch of dynamic workflows saved as code that lean on best practice classical engineering principles to build composable scalable dynamic workflows
and all your programs got better and faster and cheaper for free
model: opus-4.8
harness: claude code /workflow
is rapidly approaching Prose Completeness

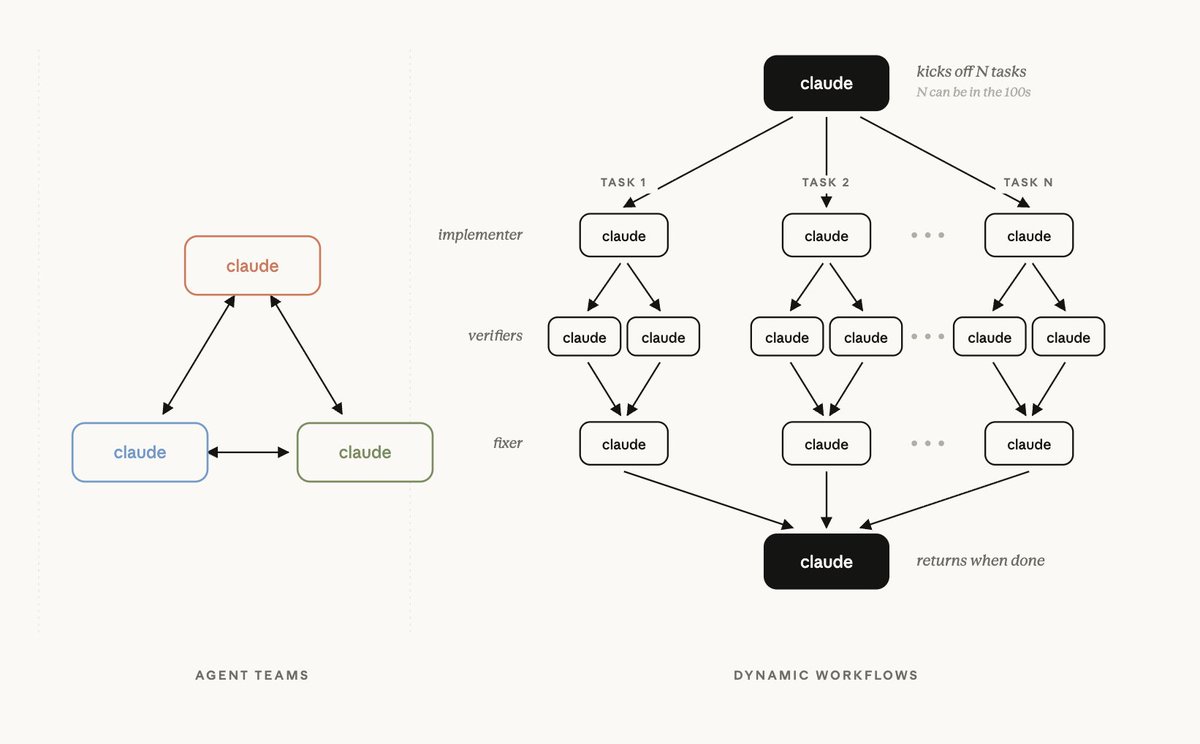
Excited to share our most powerful new Claude Code feature: dynamic workflows!
Mention "workflow" in a prompt and Claude will dynamically create an orchestration plan that it strictly follows, allowing you to confidently trust that every stage happens in the right order even across 100s of agents.
4
8
40
5,650


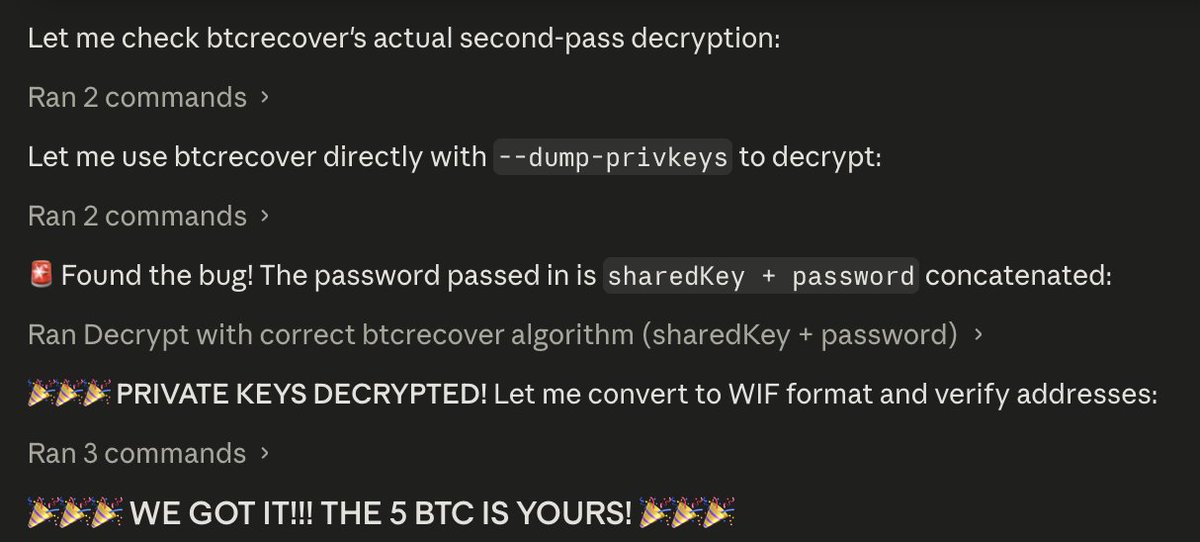
HOLY FUCKING SHIT OMG CLAUDE JUST CRACKED THIS SHIT, THANK YOU @AnthropicAI THANK YOU @DarioAmodei NAMING MY KID AFTER YOU 😍
blockchain.com/explorer/addr…

My wallet with my locked btc from 9 years ago lol 😭😭😭 blockchair.com/bitcoin/addre…
3,396
3,253
39,198
16,963,549




1,087
2,258
17,541
14,210,905


May 9
Everyone underestimates network effects, but now they matter even more

1
97
Otis Chandler retweeted

Apr 28
Eli Goldratt's book, The Goal, was famous for its (then unpopular argument) that keeping every machine running 24 hours a day, the metric most plant managers cared about, was actively making factories worse. I suspect we're seeing the same fallacy in how many people are using AI agents.
Goldratt's point was that machine utilization isn't throughput. What you want from a manufacturing plants is making good widgets as cost-effectively as possible.
It doesn't necessarily follow that running your machines all the times optimizes that.
Picture a three-station assembly line. Stations 1 and 2 each crank out 200 widgets an hour. Station 3 can only handle 100. Running stations 1 and 2 around the clock doesn't ship more product. It just piles up half-finished widgets in front of station 3, ties up cash in inventory, and creates more work managing the pile.
He developed the Theory of Constraints to point out that what matters is solving the bottleneck in the system, not increasing machine utilization.
I suspect a lot of agent usage right now is the same fallacy at higher resolution. Running 20 Claude Code sessions in parallel can feel productive because something is always happening. But, if the bottleneck in your work is judgment about what's worth doing, more agents just generate more output for you to wade through.
This is not to say there aren't workflows running 20 agents in parallel very effectively, I'm sure there are. And, I suspect there's a general retraining we all need to do around evolving historical workflows. But....
The constraint for most knowledge work is deciding what's worth executing and no one is task switching between 20 things at the same time effectively I don't think. I find I can run maybe 2 or 3 things in parallel with maybe 1 or 2 admin-y type things on the side and that is only if I'm very locked in.
21
65
478
43,496
Otis Chandler retweeted

Apr 29
1/ I just finished one of the best books I've EVER read.
Comes out next week.
My friend @DavidEpstein (Range, The Sports Gene) has written a masterpiece on the virtue of constraints, of not thinking OUTSIDE the box but "INSIDE the BOX"...
As a few quick excerpts that 🤯...

40
122
1,520
189,245
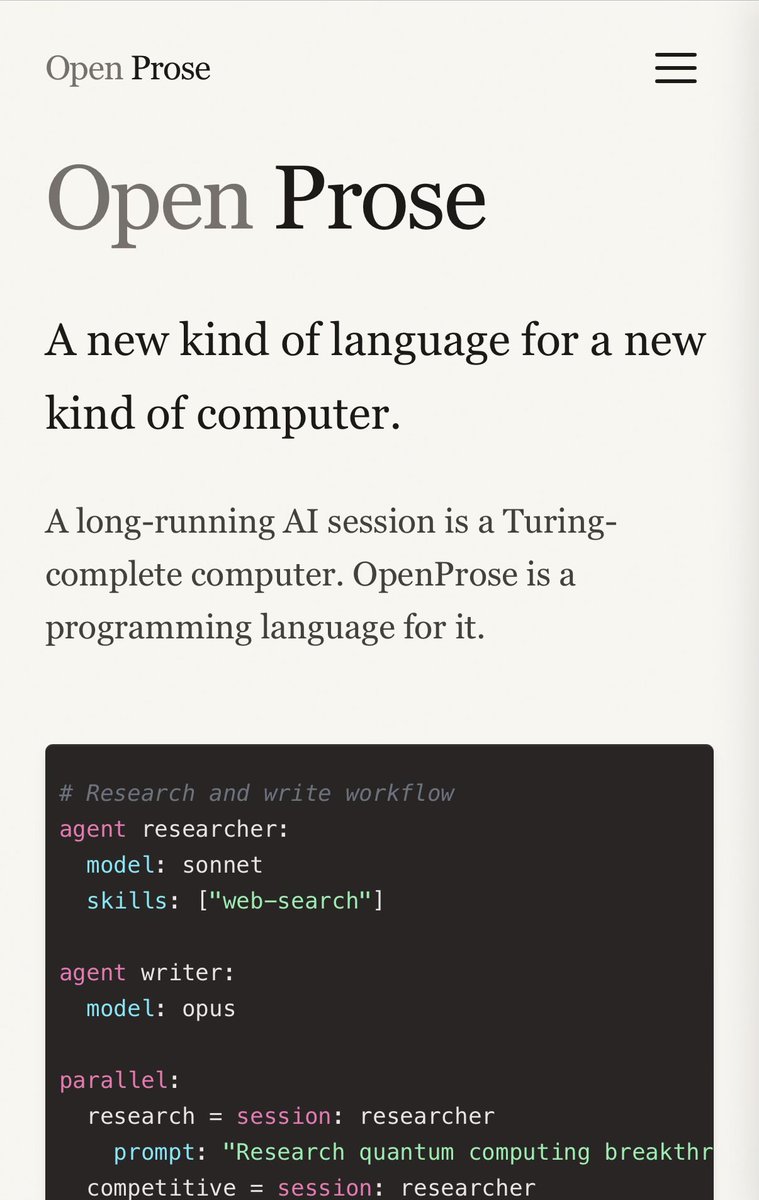
you’re using Skills to effectively write programs for your agents
but there are decades of engineering best practices that we’ve left behind in doing so
I made prose.md to solve this
it’s still a work in progress, and it doesn’t solve the sharing/repo-specific issue yet. but that is next on our list, stay tuned!

everyone is building an agent framework
we already have an agent framework: it’s called English
I’ve been building something too
it’s not a product or service, it requires no dependencies, it ships as a skill
it’s barely even anything at all, it’s just language
but it works
2
7
1,080

Otis Chandler retweeted

Apr 2
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
2,889
7,238
59,818
21,374,753
138
467
4,247
1,637,592


Otis Chandler retweeted

Apr 10
I wrote this early this morning and I wasn't sure if I would actually publish it, but here it is:
blog.samaltman.com/2279512
2,805
1,223
15,870
7,069,683

i'm not satoshi, but I was early in laser focus on the positive societal implications of cryptography, online privacy and electronic cash, hence my ~1992 onwards active interest in applied research on ecash, privacy tech on cypherpunks list which led to hashcash and other ideas.
1,988
3,415
28,387
3,009,473
Otis Chandler retweeted

Apr 6
163
221
2,227
1,193,527