
PhD student @Oxford and very slow ultrarunner :)
Joined April 2023
- Tweets 57
- Following 91
- Followers 173
- Likes 87
9 Photos and videos
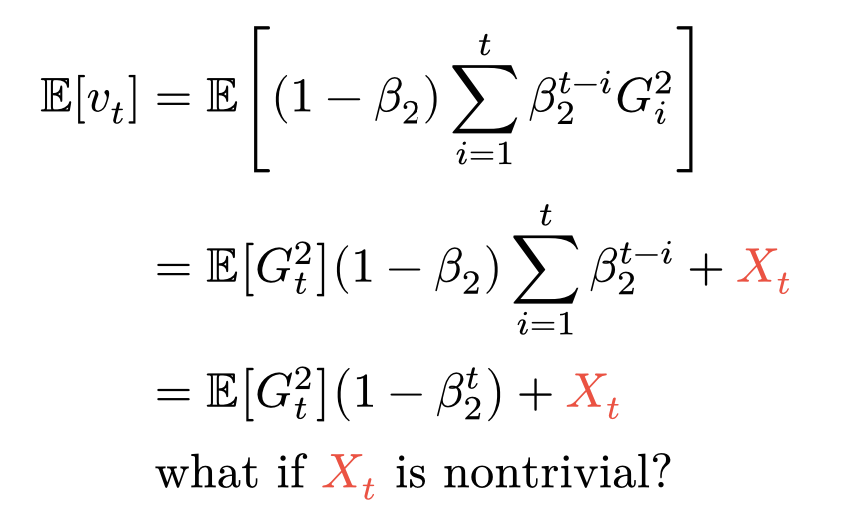
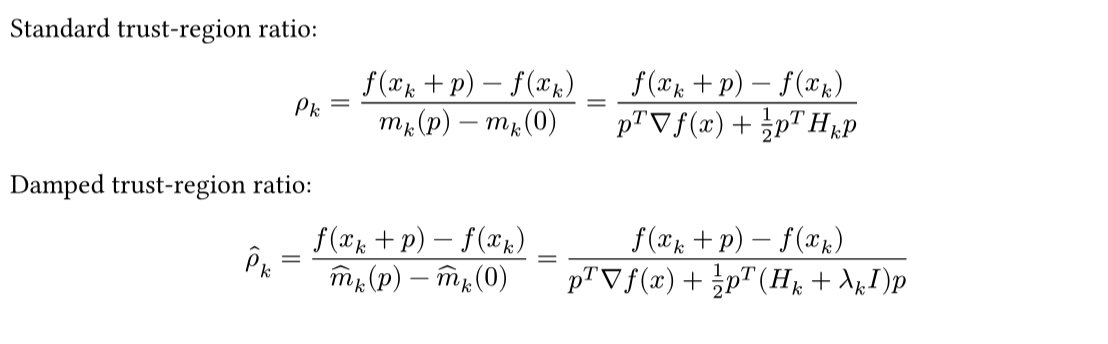
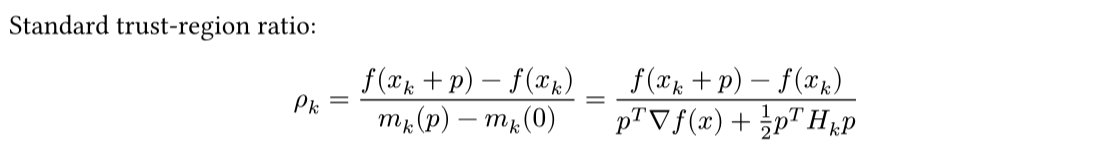



Jason Rader retweeted

9 Dec 2024
Looking forward to presenting this work at #NeurIPS2024 !
Come find us on Thursday from 11-2 @ West Ballroom A-D #6907
9 Nov 2024

Want to know why Mamba beats other state-space models—and where it falls short?
Then check out our #NeurIPS 2024 paper: "Theoretical Foundations of Deep Selective State-Space Models."
🔗 Read the paper: arxiv.org/abs/2402.19047 💻 Access the code: github.com/Benjamin-Walker/s…
🧵1/6
2
7
351

27 Oct 2024
Adam depends on the gradient distribution during training, which, as far as I know, we don't understand well?
Here, adapted from the Adam paper, v_t is the var estimate, G_t is the gradient r.v. and X_t is an error r.v. for distribution shift.
1
1
253
27 Oct 2024
Should we be trying to detect distribution shift and correct it (eg. by taking more samples at the same set of parameters)? Does this matter in some models and not others?
1
108
27 Oct 2024
I am genuinely interested! Empirical research around how well our ad-hoc estimates (of gradients, variances, and Fisher information for example) perform is surprisingly limited, since it needs to be constantly reevaluated as SOTA changes
101
Jason Rader retweeted

3 Jun 2024
My first PhD paper!🎉We learn *diffusion* models for code generation that learn to directly *edit* syntax trees of programs. The result is a system that can incrementally write code, see the execution output, and debug it. 🧵1/n
111
583
5,369
742,394
29 May 2024
Screw it, here's a new JAX implementation in Optimsitix:
github.com/packquickly/sched…
28 May 2024

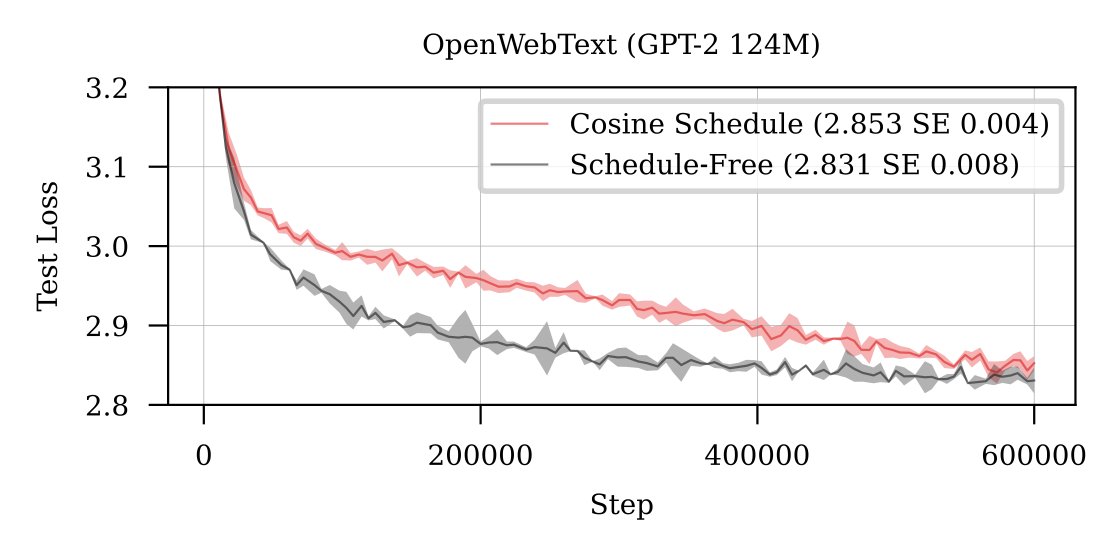
Schedule-Free paper is up!
arxiv.org/abs/2405.15682
Joint work with collaborators @alicey_ang @HarshMeh1a @konstmish @akhaledv2 @AshokCutkosky
We have some strong small-scale experiments on Transformers, comparing to chinchilla-style cosine 10x reduction schedules.
2
7
71
11,755
Jason Rader retweeted

22 Mar 2024
Jasmin Paris @JasminKParis finished loop five of the #BM100 in 59:58:21.
2,507
3,365
20,564
2,737,673
30 Nov 2023
⭐ Lineax is now on arXiv! ⭐
If you’re doing linear solves or linear least-squares in JAX, give it a shot today!
Lineax
is fast ⚡️,
has new solvers (eg. QR, tridiagonal),
supports general linear Operators.
github: github.com/google/lineax
arXiv: arxiv.org/abs/2311.17283
1/n
2
11
109
19,081
30 Nov 2023
The paper describes out how we achieved many of these things (such as differentiation through all our solvers,) and outlines some of the design choices we made when creating Lineax.
arxiv.org/abs/2311.17283
1
5
476
30 Nov 2023
Finally, a million thanks to @PatrickKidger, who supervised this whole project.
If you’re following me, chances are good you already follow him. If not, go give him a follow! (right after installing Lineax of course 😉)
4/4
2
408
11 Oct 2023
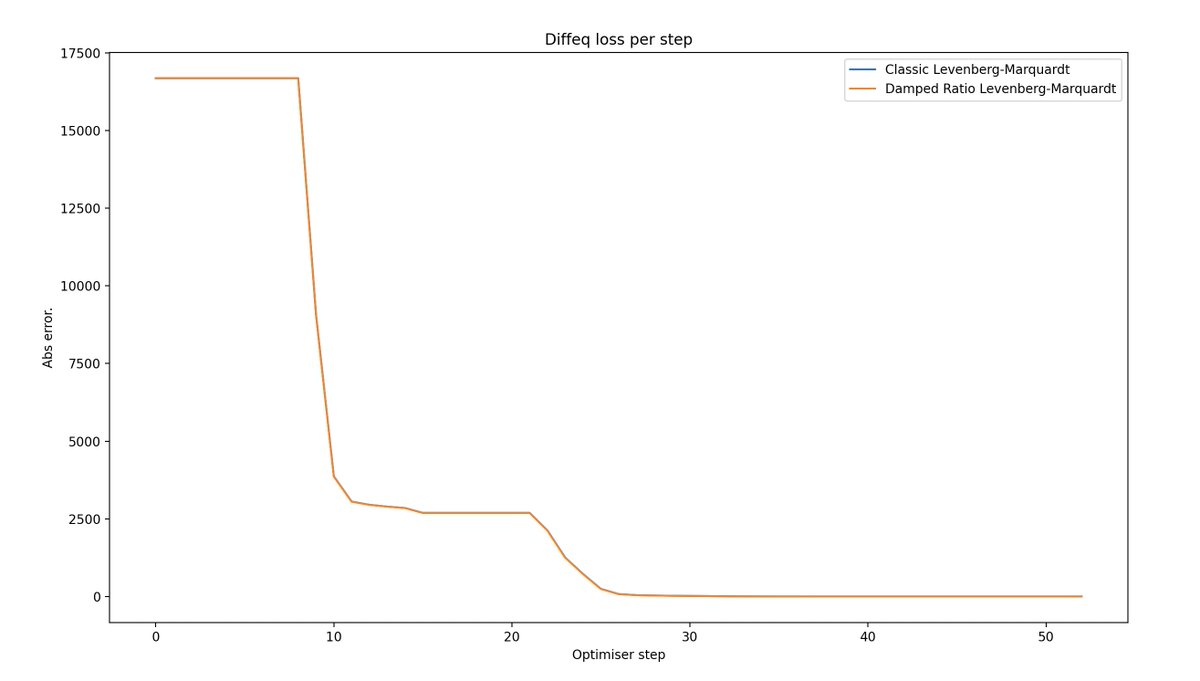
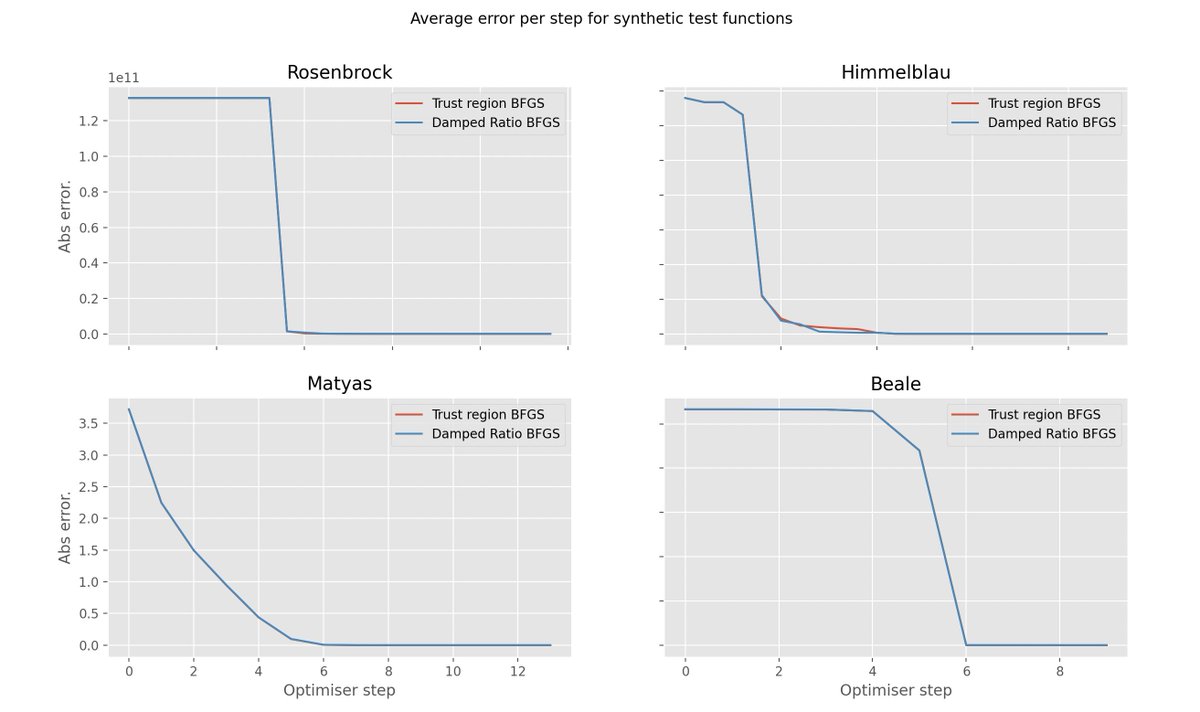
Tikhnov regularised trust-region methods (*cough* Levenberg-Marquardt) oddly use two different approximations to the objective function at each step.
One regularised, one not.
What if we just regularised both?
1/
1
4
32
14,345
11 Oct 2023
This example was taken from an offhand comment in "Training Deep and Recurrent Networks with Hessian-Free Optimisation" by Martens and Sutskever.
1
4
445
11 Oct 2023
They mentioned the choice between these two model functions made little difference in practice.
While this is believable, and indeed proved to be true, it struck me as an example of a claim which is very difficult to verify using existing optimisation software.
12/12
2
419