
Assistant Professor @sbucompsc @stonybrooku. Prev. @UMIACS @CLIPUMD @RiceCompSci @merl_news @MITIBMLab. EECS Rising Star'23. Former drummer. 🇨🇷
Joined February 2018
- Tweets 220
- Following 538
- Followers 359
- Likes 2,876
12 Photos and videos









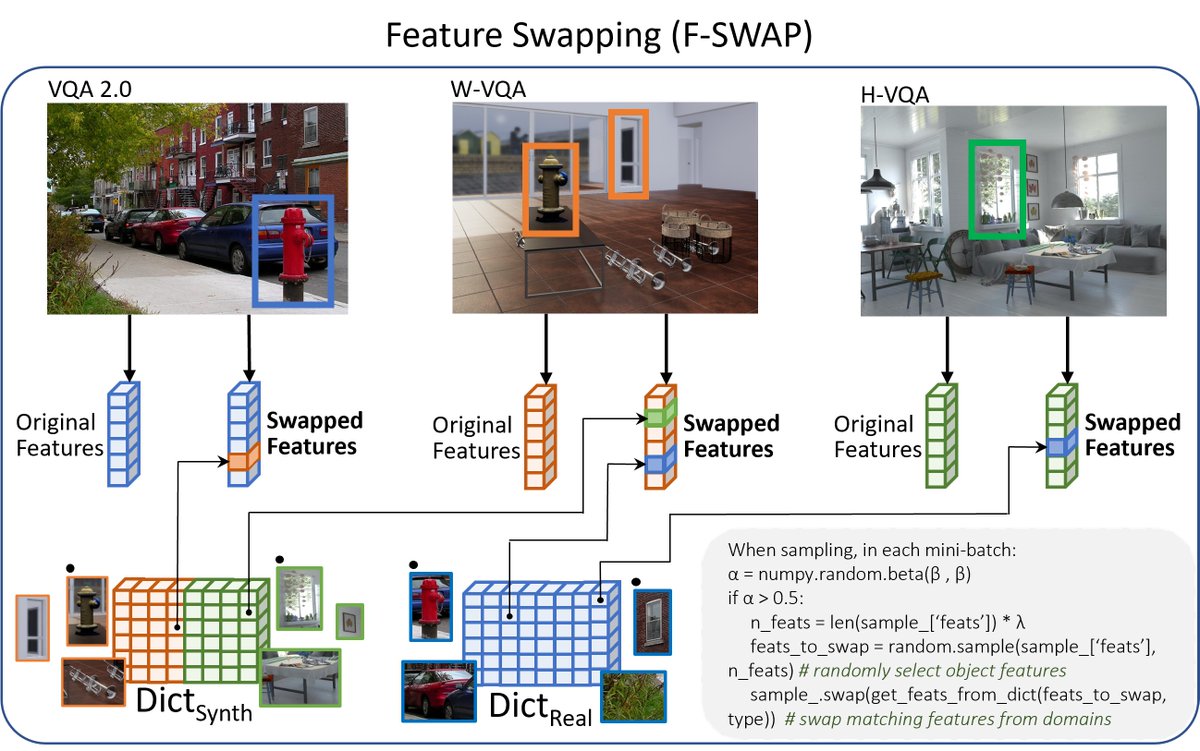


Our group had a blast at #CVPR this year!
We had multiple workshop presentations on our ongoing work on egocentric perception (@JeffriMurrugarr), spatial and semantic understanding (Kathakoli Sengupta), and VLM-SSM vision-encoders (Shang-Jui Ray Kuo).
(1/n)



2
1
8
437
... reconnect with old friends (Moayed Haji Ali @moayedhajiali, who took the last picture video 🎶); and perform a few songs at the reception on Saturday night with an incredible group of talented musicians!
Hope to see y'all at the next conference!! -- paolacascante.com/lab/

1
2
261
I also had the privilege to work with my good friend, the amazing Abby Stylianou (@abby621), on this year's Doctoral Consortium; had my advisor, Vicente Ordónez-Román (@bluevincent), meet my students; reconnect with...
(2/n)


2
76
Paola Cascante-Bonilla retweeted

Jun 6
It was a privilege to work with my good friend, Paola Cascante-Bonilla, on this year's @CVPR Doctoral Consortium, again with support from the @NSF. What a remarkable group of graduating students (not all of whom are photographed here) -- you can see the list of recipients at docs.google.com/spreadsheets…


2
5
19
3,412
Paola Cascante-Bonilla retweeted

Apr 3
Apr 3

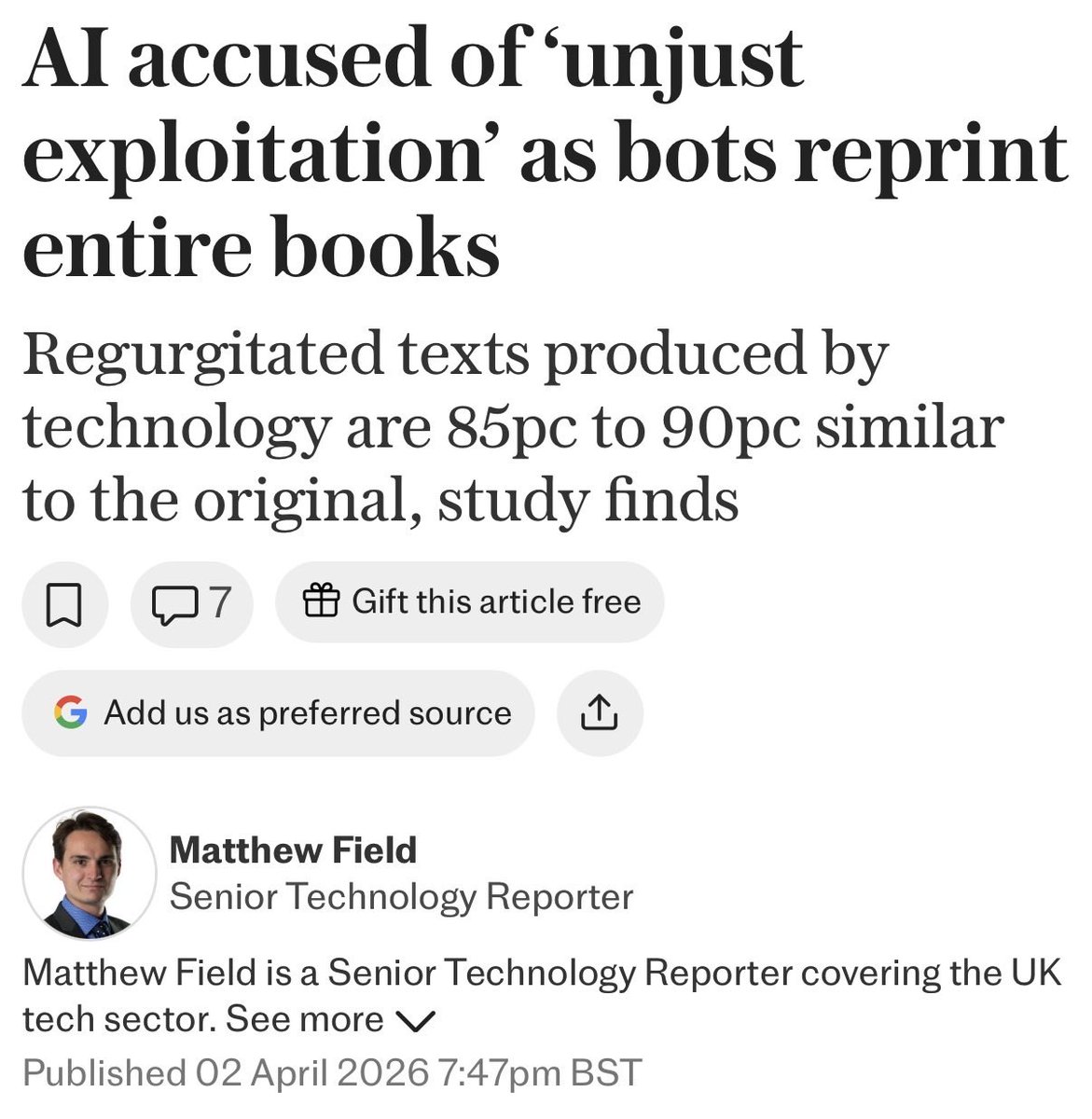
New evidence that LLMs memorise huge chunks of works they are trained on.
Great to see this important paper hitting the mainstream press.
telegraph.co.uk/business/202…
2
16
1,193

🎓Still thinking about applying to the #CVPR2026 Doctoral Consortium?
The submission deadline is April 13, 2026.
If you are a PhD student nearing graduation, this is a great opportunity to network, receive mentorship, and present your work at CVPR.
cvpr.thecvf.com/Conferences/…

📢 Call for Participation: The #CVPR2026 Doctoral Consortium submission portal is now open!
Important Dates
• Submission deadline: Apr 13, 2026
• Notification: Apr 27, 2026 (estimated)
Details: cvpr.thecvf.com/Conferences/…
2
3
21
11,672
Paola Cascante-Bonilla retweeted
Mar 25
🚨New paper on AI & Copyright
👨⚖️Courts have credited LLM companies' claims that safety alignment prevents reproduction of copyrighted expression.
But what if fine-tuning on a simple writing task ruins it all?
Worse : Fine-tuning on a single author's books (e.g., Murakami) unlocks verbatim recall of copyrighted books from 30 unrelated authors, sometimes as high as 90%.
Joint work with @niloofar_mire (@LTIatCMU), Jane Ginsburg ( @ColumbiaLaw) and my amazing PhD student @irisiris_l (@sbucompsc )
(1/n)🧵

16
154
394
115,765
Paola Cascante-Bonilla retweeted

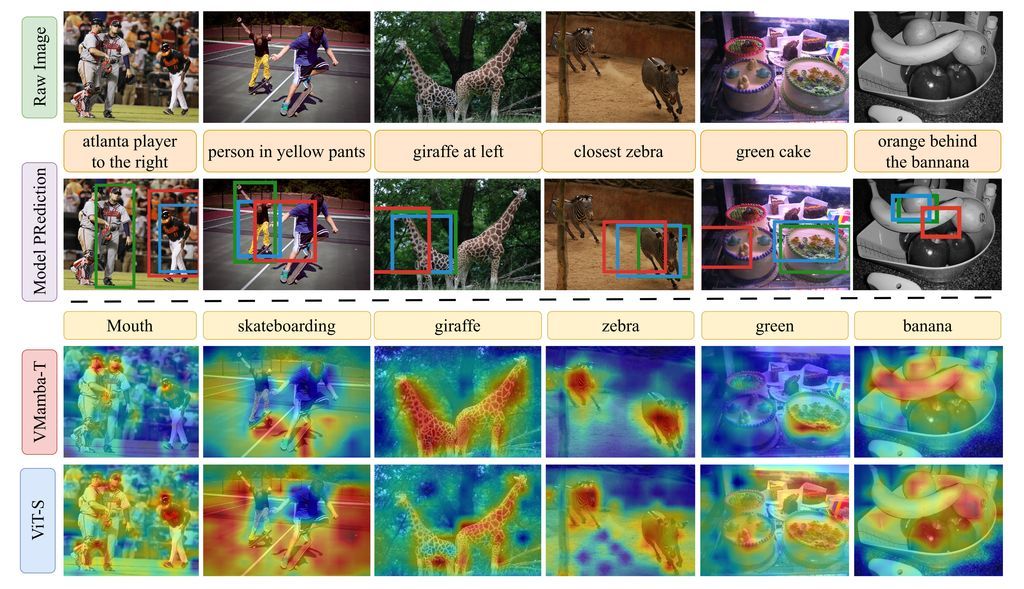
Do VLMs Need Vision Transformers?
A controlled study of Transformer, state space, and hybrid vision backbones for frozen vision-language models.
Finding:
- Under matched settings, VMamba improves localization while staying competitive on open-ended VQA, making SSMs a practical alternative to ViTs.
- Detection or segmentation pretraining generally improves VQA and localization, with the largest gains appearing in backbones that need more spatial inductive bias.
- Better classification scores and naive scaling do not consistently predict stronger downstream VLM behavior, especially for grounding-sensitive tasks.
- Some dense-objective checkpoints fail sharply in localization, but simple interface and connector adjustments recover much more robust behavior.
Paper Title: Do VLMs Need Vision Transformers? Evaluating State Space Models as
Project: lab-spell.github.io/vlm-ssm-…
Link: arxiv.org/abs/2603.19209
2
26
168
10,756
📢 Call for Participation: The #CVPR2026 Doctoral Consortium submission portal is now open!
Important Dates
• Submission deadline: Apr 13, 2026
• Notification: Apr 27, 2026 (estimated)
Details: cvpr.thecvf.com/Conferences/…
6
31
26,527
Paola Cascante-Bonilla retweeted
21 Dec 2025
@dhillon_p and my work is in the @NewYorker today. Words can’t describe how I feel. Many thanks to Vauhini Vara for this beautiful and thought provoking essay.
If you care about AI disclosures, Fair Use & the Future of Creative Labor I recommend reading it :)
20 Dec 2025

People often dismiss A.I.-generated literature because they read books to access someone else’s consciousness. But what if they can’t tell the difference? newyorkermag.visitlink.me/GV…
1
3
20
1,785
Paola Cascante-Bonilla retweeted
21 Oct 2025
🚨New paper on AI and copyright
Several authors have sued LLM companies for allegedly using their books without permission for model training.
👩⚖️Courts, however, require empirical evidence of harm (e.g., market dilution). Our new pre-registered study addresses exactly this gap.
Joint work with Profs @dhillon_p (@umsi) & Jane Ginsburg ( @ColumbiaLaw)
(1/n)🧵

9
170
515
107,092
Paola Cascante-Bonilla retweeted

7 Oct 2025
Privacy protection is vital — but blanket masking can cripple model performance.
Our COLM 2025 paper introduces FiG-Priv, a fine-grained privacy protection framework that masks only high-risk content, keeping useful details for blind & low-vision users.
📄 arxiv.org/abs/2508.09245

ALT We show the impact of masking private objects in images taken by BLV users across levels: (a) all private information exposed, (b) the entire object masked, (c) all finegrained detected text masked, (d) only high-risk PII masked. We show the outputs of a VLM (Caption and Question/Answer) based on the image, along with the risk score for each case.
2
1
2
331
Paola Cascante-Bonilla retweeted

23 Sep 2025
Thanks @arankomatsuzaki, @ManuelFaysse, and @_akhaliq for reposting our work! We extended matryoshka to multi-vector embedding and were glad to see that the popular concept, test-time scaling in LLM, also works in retrieval.
Work done with @AIatMeta & @vislang!
23 Sep 2025

Meta Superintelligence Labs presents MetaEmbed: Scalable multimodal retrieval
• Flexible late interaction via Meta Tokens
• Test-time scaling: trade off retrieval accuracy vs efficiency
• SOTA on MMEB ViDoRe, robust up to 32B models
• Matryoshka training → coarse-to-fine multi-vector embeddings

3
5
28
10,160
Paola Cascante-Bonilla retweeted
15 Jul 2025
Honored to get the outstanding position paper award at @icmlconf :) Come attend my talk and poster tomorrow on human centered considerations for a safer and better future of work
I will be recruiting PhD students at @stonybrooku @sbucompsc coming fall. Please get in touch.

7 May 2025

Very excited for a new #ICML2025 position paper accepted as oral w @mbodhisattwa & @TuhinChakr! 😎
What are the longitudinal harms of AI development?
We use economic theories to highlight AI’s intertemporal impacts on livelihoods & its role in deepening labor-market inequality.

16
16
122
12,130
Paola Cascante-Bonilla retweeted

20 Jul 2025
#ICCV2025 is deeply committed to promoting diversity, equity, and inclusion within our community. As part of this commitment, travel support is available to help broaden participation.
Applications will be reviewed on a rolling basis until August 20, 2025 (anywhere on Earth).

3
13
53
10,769
Paola Cascante-Bonilla retweeted
8 Jul 2025
Now accepted to @COLM_conf 🤩 Super excited for Montreal 🇨🇦🍁
This also marks my third successful collaboration with my good friend @PhilippeLaban
21 Apr 2025

Unlike math/code, writing lacks verifiable rewards. So all we get is slop. To solve this we train reward models on expert edits that beat SOTA #LLMs largely on a new Writing Quality benchmark. We also reduce #AI slop by using our RMs at test time boosting alignment with experts.


3
6
83
4,537

8 Jul 2025
Beyond Blanket Masking: Examining Granularity for Privacy Protection in Images Captured by Blind and Low Vision Users -now accepted to #COLM
Last June, Jeffri Murrugarra presented a short version at LXAI and VizWiz Workshops @ CVPR'25
More info soon; see you all in Montreal!✨
2
3
10
774
8 Jul 2025
We introduce a multi-agent collaboration system that produces fine-grained information and privacy risk scores to enable usability and utility while preserving privacy.
Kudos to all amazing collaborators: Haoran Niu, Suzanne Barber, @haldaume3, @Triiiiiista!
1
1
55
8 Jul 2025
Full paper, code and webpage will be available soon~! 🦙✨
1
48