
AI @ AMD
Joined June 2009
- Tweets 71
- Following 243
- Followers 635
- Likes 283
10 Photos and videos










Jun 11
The fastest whale isn’t always the bigger one 🐳
MI355X GPU Sets a New Bar for DeepSeek Inference
amd.com/en/developer/resourc…
1
1
20
3,912

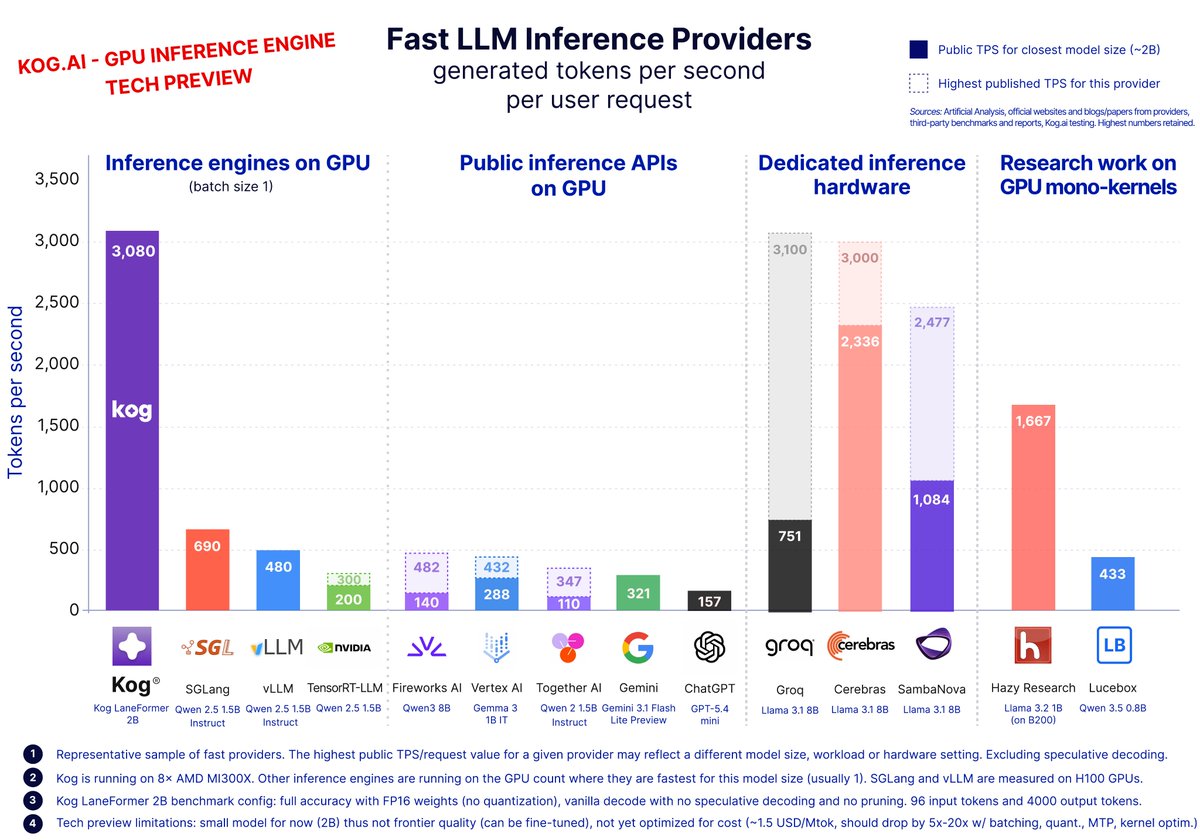
🚀 Launch today: Kog generates 3,000 output tokens/s per single request, on standard datacenter GPUs.
We are bringing real-time LLM inference to hardware that companies already run in production.
The speed previously associated with purpose-built silicon is now delivered on NVIDIA H200 and AMD MI300X.
Today, we are opening our Tech Preview with a 2B coding model, with large frontier MoE support coming next.
Try our Playground → playground.kog.ai
💥 Why that matters, and how we did it → blog.kog.ai/real-time-llm-in…
📖 Monokernel deep dive → blog.kog.ai/building-a-singl…
📖 Delayed Tensor Parallelism research → blog.kog.ai/delayed-tensor-p…
read the thread 👇
16
41
268
6,162,496
Ramine Roane retweeted

May 19
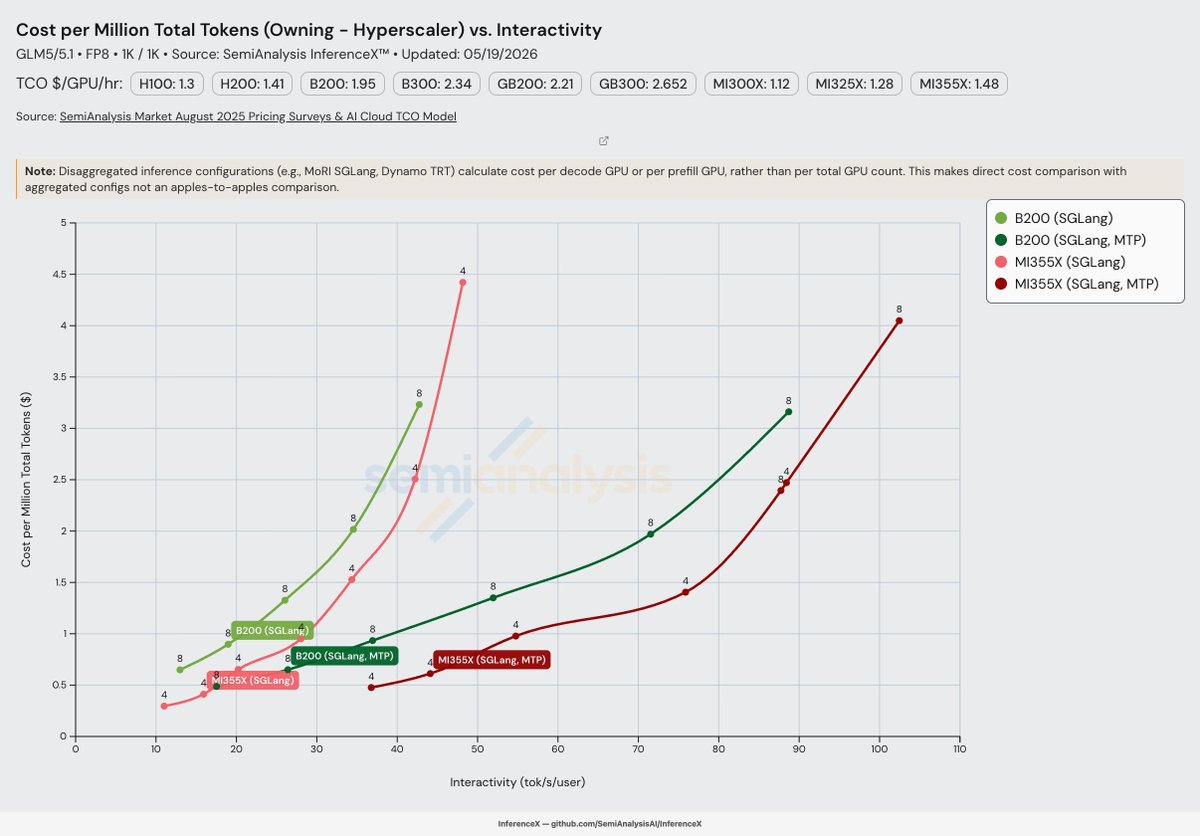
AMD ALERT 🚀 MI355 is now 40% cheaper than B200 on GLM5 architecture for Single Node serving FP8 14 weeks after the initial launch of GLM5 on both non-MTP & MTP with spec decode for SGLang v0.12 for both CUDA & ROCm. SPEED IS THE MOAT!! Great work to @AnushElangovan, @roaner, HaiShaw & his team!
Next step is for MI355X to catch up to CUDA when composing production inference optimizations like FP4 & on distributed inferencing where you can gang up MI355 boxes such that per GPU performance goes up thus the cost per million tokens goes down.
7
44
459
48,625

Today, we announced more than $10B in investment across Taiwan’s ecosystem to scale advanced packaging and accelerate next-gen AI infrastructure, from 6th Gen EPYC CPUs codenamed “Venice” to our Helios rack-scale platform including Instinct MI450X GPUs, with multi-gigawatt deployments beginning in 2H 2026.
Additionally, AMD and TSMC have hit another major production milestone, with Venice EPYC CPUs ramping on TSMC 2nm technology in Taiwan with future plans to ramp production at TSMC’s Arizona Fab.
More on the news: bit.ly/4tJrUkR

31
100
713
92,601
Ramine Roane retweeted

May 21
We ran GLM 5.1 on MI350X - much faster and cheaper than MI355X and B200.
SwarmOne optimization delivered off-the-chart agentic performance on 150-200K context windows.
Single node. 8×MI350X. 140 tok/s/user. $1.44/Mtok.
34–55% faster. 54–64% cheaper. No synthetic benchmarks.
Most configs on the chart sit on frustrating or constrained territory for agentic inference. Below ~50 tok/s/user with variable ISL/OSL and tool calls, your agents are bottlenecked - no matter how low the cost looks on paper.
Respect to @AnushElangovan, @roaner and HaiShaw for pushing MI355X forward. We're building on that momentum and showing what full-stack agentic optimization unlocks on ANY silicon.
If you're scaling agentic workloads and cost-per-token matters, let's talk.
@nvidia @AMD @SemiAnalysis_

1
5
58
91,605

Huge respect to HaiShaw, Thomas, @roaner, @AnushElangovan from @AMD for the relentless work, fusing mHC ops and RoPE hadamard transforms, and shipping new attention indexer KV cache kernels in TileLang & Triton at remarkable speed.
Honored SGLang is the stack powering it. Cheering you on for the next 5x.
May 10

SPEED IS THE MOAT: AMD ROCm software stack has improved performance by over 75x in the last 14 days since DeepSeekv4 launch. The performance comes from fusing mHC operations & also fusing RoPE hadamard transformations to reduce cpu overhead & improve HBM memory utlization. Furthermore, other kernels like the attention indexer & kvcache compressor has been written using TileLang & Triton for fast development velocity.
Another 5x performance improvement is needed to catch up to single node aggregated B200 performance & then another 1.5x is needed to catch up to PD disaggregated B200 performance, which is within the realm of possibility for AMD within the next couple of weeks. Great work to HaiShaw, Thomas, @roaner, @AnushElangovan for this rapid improvement.

1
5
48
6,119
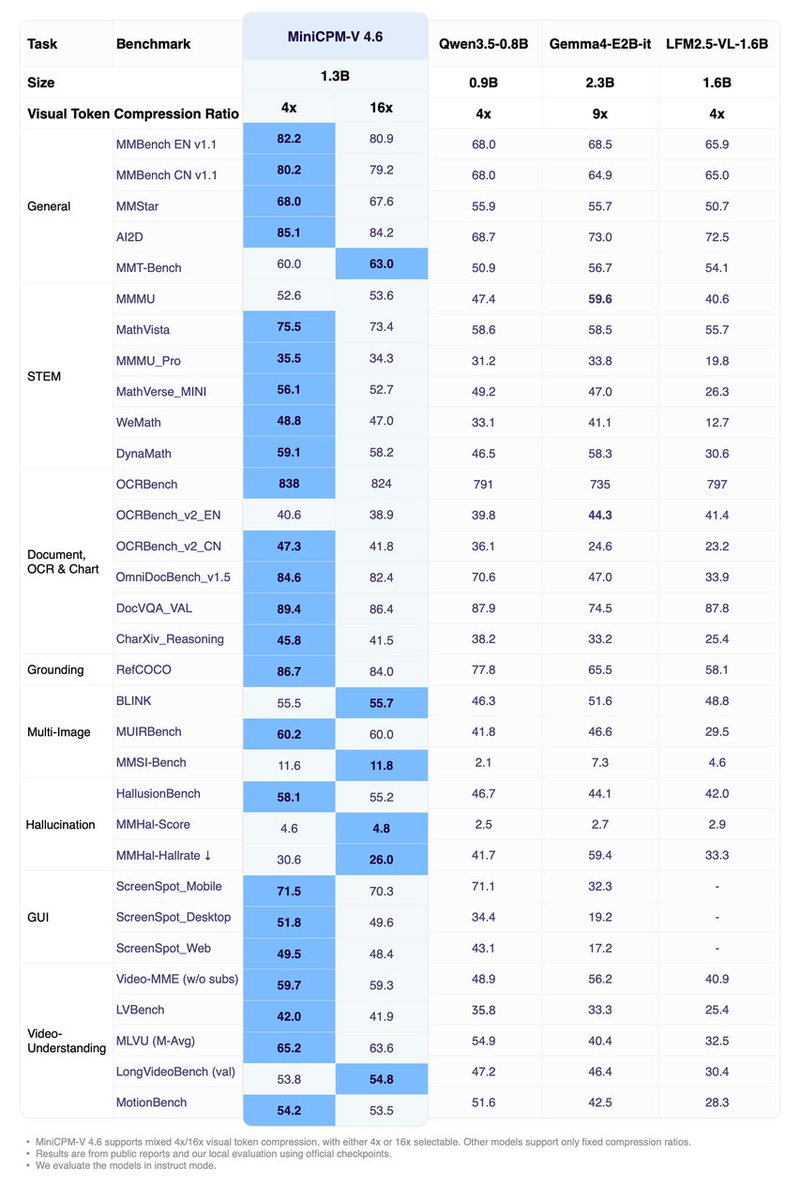
🎉 Meet MiniCPM-V 4.6 from @OpenBMB, a 1.3B edge-friendly multimodal LLM with superior efficiency. Day-0 support is now live in SGLang!
✅ Leading capability: scores 13 on Artificial Analysis Intelligence Index benchmark
✅ Strong multimodal: Matches Qwen3.5 2B-level capacity across 5 major VL benchmarks
✅ Ultra-efficient: 50% less visual FLOPs via LLaVA-UHD v4 and mixed 4x/16x visual token compression
✅ Mobile-ready: can be deployed across iOS, Android, and HarmonyOS
Cookbook: docs.sglang.io/cookbook/auto…
Run it now with SGLang!


1/5 MiniCPM-V 4.6 (1.3B) is now live 🚀🚀
High-res visual processing, optimized for consumer-grade and mobile hardware. We’ve leveraged the latest LLaVA-UHD v4 technique to cut vision encoding costs by 55%, enabling native edge deployment with extreme efficiency.
🔥 Beats Gemma4-E2B-it and Qwen3.5-0.8B across key multimodal and Artificial Analysis benchmarks — scoring higher than Qwen3.5-0.8B using just 2.5% of its token budget.
⚡ TTFT (75.7ms) 2.2x Faster than Qwen3.5-0.8B even with 3136² high-res images.
🏗️ ~1.5x Token Throughput compared with Qwen3.5-0.8B on a single RTX 4090.
Try the model here:
🤗 Hugging Face:
huggingface.co/openbmb/MiniC…
💻 GitHub:
github.com/OpenBMB/MiniCPM-V
🔭 Modelscope:
modelscope.cn/models/OpenBMB…
🌐 Web Demo:
huggingface.co/spaces/openbm…
📱 App Demo:
github.com/OpenBMB/MiniCPM-V…
4
24
4,096
Ramine Roane retweeted
May 10
SPEED IS THE MOAT: AMD ROCm software stack has improved performance by over 75x in the last 14 days since DeepSeekv4 launch. The performance comes from fusing mHC operations & also fusing RoPE hadamard transformations to reduce cpu overhead & improve HBM memory utlization. Furthermore, other kernels like the attention indexer & kvcache compressor has been written using TileLang & Triton for fast development velocity.
Another 5x performance improvement is needed to catch up to single node aggregated B200 performance & then another 1.5x is needed to catch up to PD disaggregated B200 performance, which is within the realm of possibility for AMD within the next couple of weeks. Great work to HaiShaw, Thomas, @roaner, @AnushElangovan for this rapid improvement.
24
85
841
165,035
Ramine Roane retweeted

Mar 23
1/7
Running huge MoE models on affordable hardware is all the rage.
Adding a new approach to the mix optimized for speed and model quality.
Introducing FOMOE: Fast Opportunistic Mixture Of Experts (pronounced fomo).
Runs Qwen3.5 flagship model with 397 billion parameters at 5 – 9 tok/s on a $2,100 desktop! Uses Q4_K_M quants.
Two $500 GPUs, 32GB RAM, one NVMe drive. Runs on Linux.

21
21
278
23,270
Apr 26
🦞 AI builders in SF
Join us at AMD AI DevDay this Thursday (Apr 30)
• Luminary talks from AI leaders
• Hands-on workshops on DC GPUs, AI PCs, and robotics
Build, learn, connect
Free registration
amd.com/en/corporate/events/…
#AI #Developers
6
199
Ramine Roane retweeted
Mar 27
18x IMPROVEMENT ALERT🚀 In under 30 days, AMD was able to improvement Kimi K2.5 1T MXFP4 interactivity by up to 18x when iso-throughput. The main changes are in PR number 35850 AMD fixed their vLLM AITER integration to support the Kimi K2.5 MLA which uses num_head=8 for TP8 & num_head=16 for TP4 along with general GEMM tuning. All of these bug fixes & perf tuning are upstreamed & already in the vLLM 0.18 release. Great work to Chuan Li & @AnushElangovan Speed is the Moat 🔥

2
35
320
40,796
🚀 New blog: ROCm Support for Miles: Large-Scale RL Post-Training on AMD Instinct™ GPUs
Together with @AMD, Miles brings end-to-end RL pipelines to MI300/350-class clusters:
⚡️ Rollout generation dominates RL compute, and AMD’s HBM bandwidth directly addresses this bottleneck
🧠 AIME accuracy improved from 0.665 → 0.729 across training on Qwen3-30B-A3B with GRPO
💾 MI300X delivers ~1.1–1.3k tok/GPU/s rollout throughput
⏱️ Mean step time 388.5s on a single 8-GPU MI300X node (32×8 sampling, 8k response cap)
🔧 Multi-turn agentic training validated
... and more optimizations to come 🔥
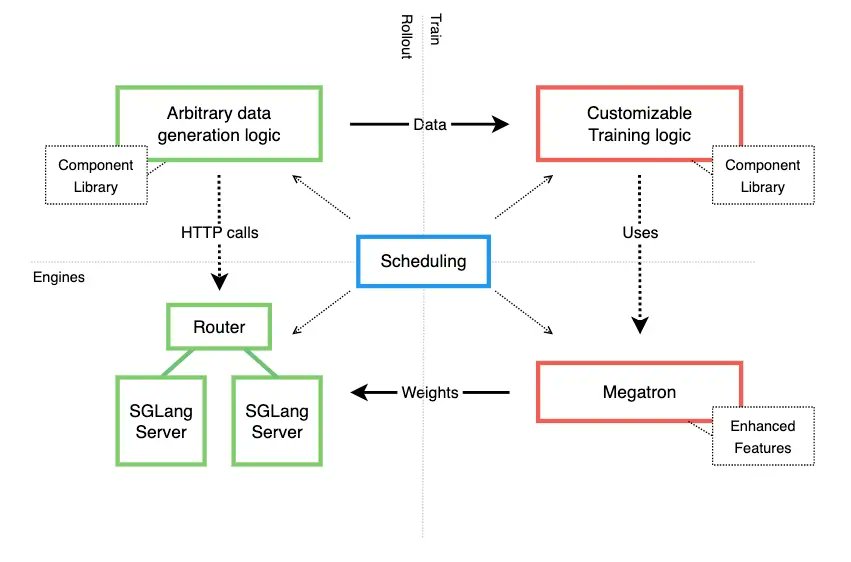
3
18
66
12,725
Ramine Roane retweeted
Mar 19
KING ALERT: Congrats to @roaner & @AnushElangovan & 10x AMD China Engineering team for its amazing FP8 MI355 ROCm SGLang disaggregated performance beating NVIDIA Blackwell! They are also the Inference King! 👑
Mar 19

8
14
184
51,033
Ramine Roane retweeted
Mar 3
Due to optimizations in AMD's MoRI inference communication library & better kernels AMD performance has 1.5x in the span of 30 days. These optimizations for MoE dispatch, MoE combine, kvcache transfer comms have been upstreamed in SGLang for everyone to use in PR 17012, 14626, 18437 etc. MoRI is AMD's inference comms library built from first principles by their 10x china team! In the age of inference, developer velocity of inference optimizations matters a lot & InferenceX™ is our research platform to continuously track the performance.
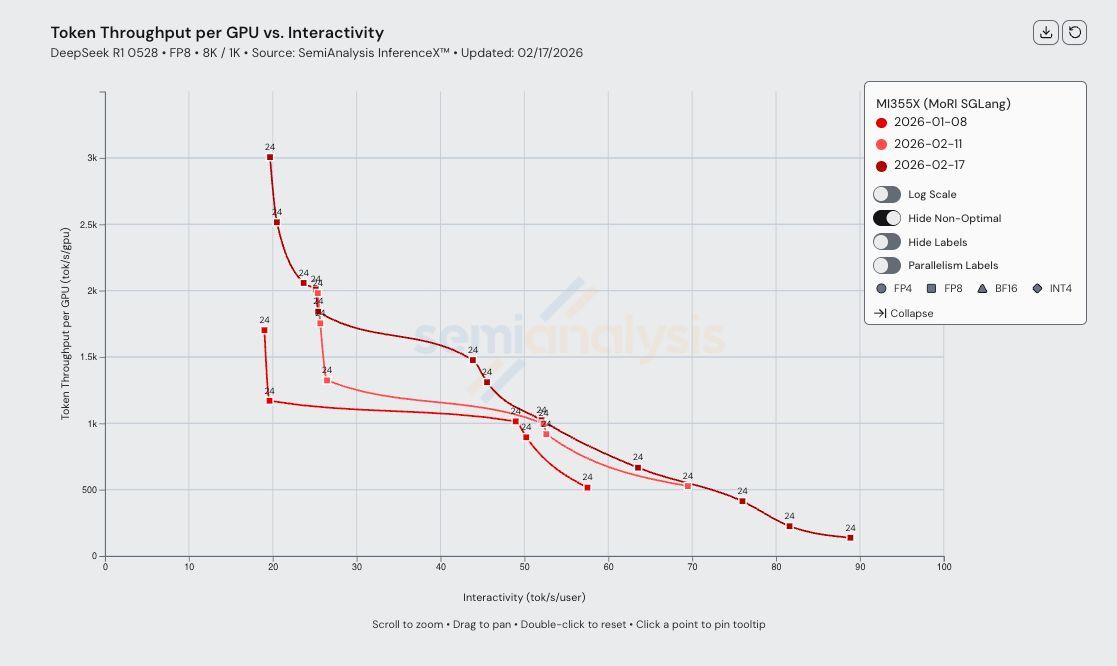
9
15
175
15,791


Day-0 support for the Qwen 3.5 model on AMD GPUs, achieved through tight collaboration with the @Alibaba_Qwen team just in time for Chinese New Year's Eve. Support is available via both @sgl_project and @vllm_project .
With SGLang:
Launch rocm/sgl-dev:v0.5.8.post1-rocm720-mi30x-20260215
Inside container, run:
python3 -m sglang.launch_server \
--port 8000 \
--model-path Qwen/Qwen3.5-397B-A17B \
--tp-size 8 \
--attention-backend triton \
--reasoning-parser qwen3 \
--tool-call-parser qwen3_coder
With vLLM:
Launch rocm/vllm-dev:nightly_main_20260211
Inside container, run:
pip install git lnkd.in/gw4k6mqE
VLLM_ROCM_USE_AITER=1 \
vllm serve Qwen/Qwen3.5-397B-A17B \
--port 8000 \
--tensor-parallel-size 8 \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
You can now run the following text/image/video input examples on Hugging Face:
huggingface.co/Qwen/Qwen3.5-…
huggingface.co/Qwen/Qwen3.5-…
huggingface.co/Qwen/Qwen3.5-…
Accuracy has been fully verified, and all AMD support code has been upstreamed.
The upcoming SGLang and vLLM releases will support Qwen 3.5 out-of-the-box on AMD MI300X, MI325X, and MI355X GPUs.
5
5
50
6,422