
115 Photos and videos







Sid retweeted

Jun 1
really well written blog on the emerging shift from optimization-limited to rollout-limited frontier RL. what stood out to me was the observation that as reasoning trajectories become longer and more heterogeneous GPU utilization and learner-generator synchronization increasingly dominate training efficiency. one underexplored question is whether capability jumps themselves can be detected through staleness statistics. if old trajectories suddenly become much less useful for learning that may indicate the model has discovered a qualitatively new reasoning strategy. in that sense replay-buffer value decay could become an observable signal of phase transitions in capability acquisition. if you're into async-RL/large-scale training systems this is a really worthwhile read.
Jun 1

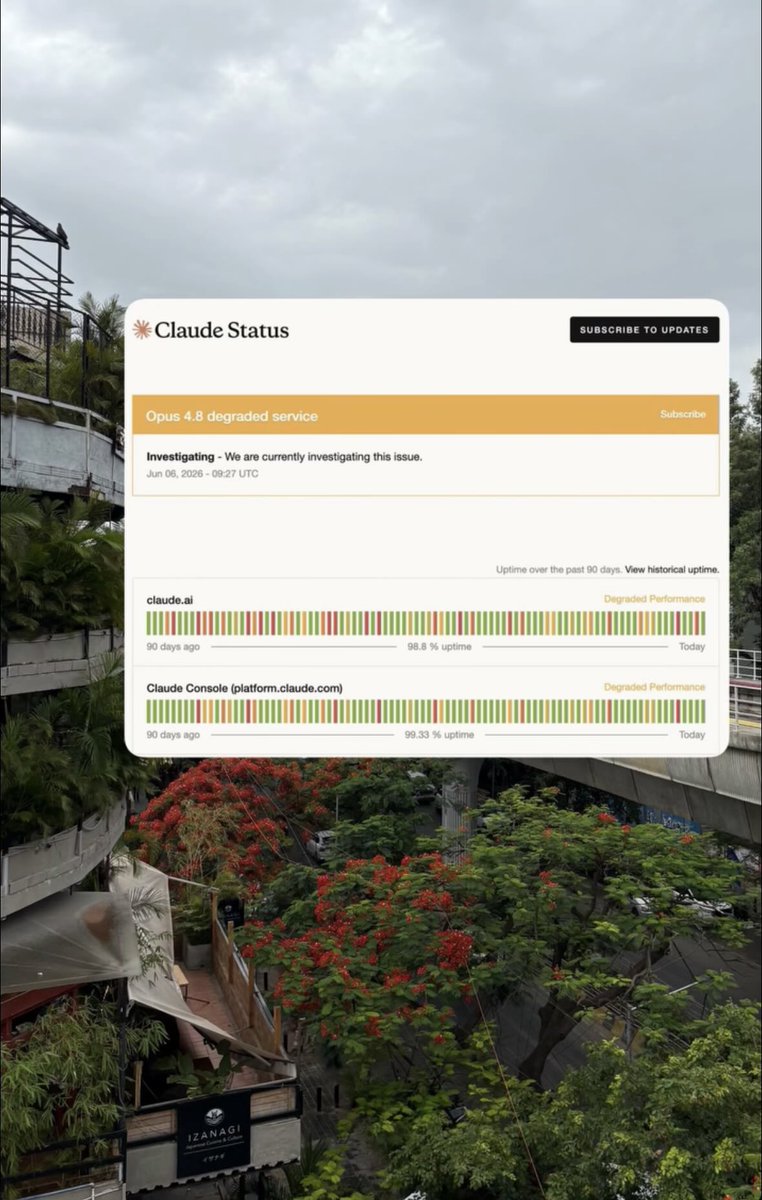
New blog! Is frontier asynchronous RL solved?
The blog covers Async RL theory and infrastructure, surveying 8 open-weight frontier labs for the algorithmic techniques and systems fixes to handle train-inference mismatch. Also answered: why do current methods still fail at high policy lag? Which methods scale with horizon and compute?

2
27
297
43,418
Sid retweeted

The open-source protein ML space just got a massive upgrade. Phenomenal work by @anindyadeeps and @try_litefold on dropping the biggest protein data collection on Hugging Face
May 27

We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
1
5
10
2,018
Check this out 👇
May 19

open sourcing Marlin-2B 🐟
a tiny VLM to extract structured information from videos
Marlin is finetuned for two questions devs want to ask in their videos: what is happening, and when?
Best open model in its weight class, competitive with Gemini-2.5-flash at only 2B params 🧵
6
446
Damn — its soo over for open ai 🫡
May 19

Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
2
261
Sid retweeted

May 18
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
136
973
7,416
575,224
Sid retweeted

May 13
🚨Excited to announce Agent-BRACE!
LLM agents in long-horizon POMDPs either blow up their context with raw history or summarize it, discarding uncertainty by collapsing belief into a point estimate. Agent-BRACE decouples the agent into belief state policy models, jointly trained via RL.
Key takeaways:
1️⃣ 🎯The belief state model produces a structured approximation of the belief distribution as a set of atomic natural-language claims with ordinal verbalized certainty labels ranging from certain to unknown. The policy conditions on this compact belief rather than the full history.
2️⃣ 📈 Outperforms strong RL baselines on long-horizon partially observable embodied language environments while maintaining a near-constant context window independent of episode length.
3️⃣ 🔄 The learned belief becomes increasingly calibrated as evidence accumulates, and epistemic belief decreases over time: the proportion of claims that the agent has the strongest level of belief in grows from 21% → 52% over an episode.
👇🧵

2
39
67
15,964
Amazing talk by @DrJimFan -- exciting times for Physical AGI!
TL;DR
VLA architecture is parameter-misallocated toward language and should be replaced by World Action Models
→ pretrained video diffusion models that jointly predict future world states and robot actions, instantiated by Dream Zero (a 14B model running real-time control at 7Hz with 2× generalization gains over VLAs, @SeonghyeonYe ).
arxiv.org/pdf/2602.15922
His central data claim is that egocentric human video is the FSD-equivalent ambient data flywheel for robotics, and EgoScale (@ruijie_zheng12) demonstrates a near-perfect log-linear scaling law (ℒ(N) = a − b log N, R² = 0.9983) between 1K and 20K hours of pretraining data and downstream dexterity performance.
arxiv.org/pdf/2602.16710
His central environment claim is that classical physics simulators will be replaced by neural simulators, and Dream Dojo (@ShenyuanGao) demonstrates this with 44K hours of human video pretraining, 10 FPS real-time interaction, and Pearson r = 0.995 policy-evaluation fidelity.
arxiv.org/pdf/2602.06949
Significant gaps in the talk:
- it does not address runtime semantics (skill installation, behavior consistency, run-update separation)
- it does not address the model-exploitation failure mode of training policies against learned simulators or learned rewards.
My running notes w/ Opus 4.7 👇
docs.google.com/document/d/e…
@NVIDIAAI

I promise this will be the best 20 min you spend today! Robotics: Endgame, the sequel to my last year's Sequoia AI Ascent talk, "Physical Turing Test". I laid out the roadmap for solving Physical AGI as a simple parallel to the LLM success story. Be a good scientist, copy homework ;)
And stay till the end, more easter eggs and predictions for your polymarket!
00:30 DGX-1 origin story at OpenAI, I was there in 2016 signing with Jensen and Elon. Heading to the Computer History Museum!
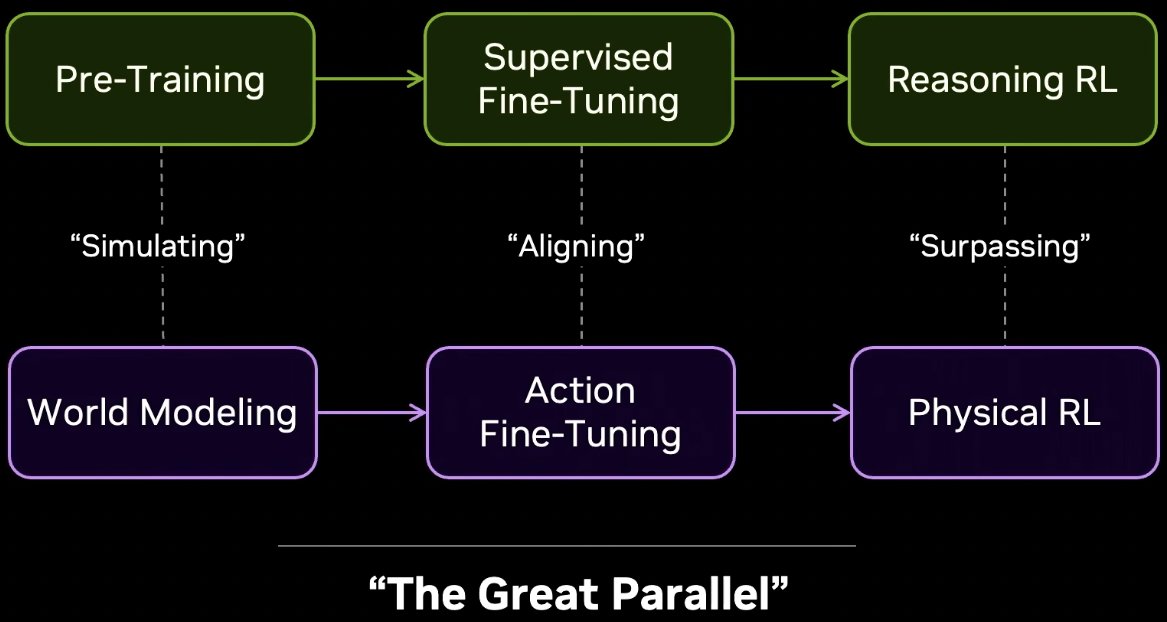
01:42 The Great Parallel
03:31 Robotics, the Endgame
03:39 Why VLAs fall short
04:32 Video world models as the 2nd pretraining paradigm
06:09 World Action Models (WAM)
07:46 Strategies for robot data collection and the FSD equivalent to physical data flywheel for robot manipulation
11:06 EgoScale and the Dexterity Scaling Law we discovered recently
14:00 Physical RL: bridging the last mile
15:39 DreamDojo: an end-to-end neural physics engine for scaling RL in silico
17:00 Civilizational Technology Tree and my predictions for the near future. Spoiler: it's closer than you think.
Thanks to my friends at Sequoia for inviting me back to AI Ascent this year! I had a blast! Last year's talk is attached in the thread if you missed it.
1
2
12
1,177
Notes on Robotics' End Game: Nvidia's Jim Fan!
- @sidgraph and Opus 4.7
youtu.be/3Y8aq_ofEVs?si=aWEN…
TL;DR
Vision-Language-Action architecture is parameter-misallocated toward language and should be replaced by World Action Models
→ pretrained video diffusion models that jointly predict future world states and robot actions, instantiated by Dream Zero (a 14B model running real-time control at 7Hz with 2× generalization gains over VLAs).
His central data claim is that egocentric human video is the FSD-equivalent ambient data flywheel for robotics, and EgoScale demonstrates a near-perfect log-linear scaling law (ℒ(N) = a − b log N, R² = 0.9983) between 1K and 20K hours of pretraining data and downstream dexterity performance.
His central environment claim is that classical physics simulators will be replaced by neural simulators, and Dream Dojo demonstrates this with 44K hours of human video pretraining, 10 FPS real-time interaction, and Pearson r = 0.995 policy-evaluation fidelity.
The framework is strongest on data (genuinely empirically grounded), partial on architecture (Dream Zero shows the substrate works but is GPT-2-stage, not GPT-3-stage), and weakest on the predictive claims about timeline and the "VLA is dead" rhetorical framing.
Three significant gaps in the talk: it does not address runtime semantics (skill installation, behavior consistency, run-update separation), it does not address safety, and it does not address the model-exploitation failure mode of training policies against learned simulators or learned rewards.
docs.google.com/document/d/e…
13
419
Amazing talk by @DrJimFan -- exciting times for Physical AGI!
TL;DR
VLA architecture is parameter-misallocated toward language and should be replaced by World Action Models
→ pretrained video diffusion models that jointly predict future world states and robot actions, instantiated by Dream Zero (a 14B model running real-time control at 7Hz with 2× generalization gains over VLAs, @SeonghyeonYe ).
arxiv.org/pdf/2602.15922
His central data claim is that egocentric human video is the FSD-equivalent ambient data flywheel for robotics, and EgoScale (@ruijie_zheng12) demonstrates a near-perfect log-linear scaling law (ℒ(N) = a − b log N, R² = 0.9983) between 1K and 20K hours of pretraining data and downstream dexterity performance.
arxiv.org/pdf/2602.16710
His central environment claim is that classical physics simulators will be replaced by neural simulators, and Dream Dojo (@ShenyuanGao) demonstrates this with 44K hours of human video pretraining, 10 FPS real-time interaction, and Pearson r = 0.995 policy-evaluation fidelity.
arxiv.org/pdf/2602.06949
Significant gaps in the talk:
- it does not address runtime semantics (skill installation, behavior consistency, run-update separation)
- it does not address the model-exploitation failure mode of training policies against learned simulators or learned rewards.
My running notes w/ Opus 4.7 👇
docs.google.com/document/d/e…
@NVIDIAAI
I promise this will be the best 20 min you spend today! Robotics: Endgame, the sequel to my last year's Sequoia AI Ascent talk, "Physical Turing Test". I laid out the roadmap for solving Physical AGI as a simple parallel to the LLM success story. Be a good scientist, copy homework ;)
And stay till the end, more easter eggs and predictions for your polymarket!
00:30 DGX-1 origin story at OpenAI, I was there in 2016 signing with Jensen and Elon. Heading to the Computer History Museum!
01:42 The Great Parallel
03:31 Robotics, the Endgame
03:39 Why VLAs fall short
04:32 Video world models as the 2nd pretraining paradigm
06:09 World Action Models (WAM)
07:46 Strategies for robot data collection and the FSD equivalent to physical data flywheel for robot manipulation
11:06 EgoScale and the Dexterity Scaling Law we discovered recently
14:00 Physical RL: bridging the last mile
15:39 DreamDojo: an end-to-end neural physics engine for scaling RL in silico
17:00 Civilizational Technology Tree and my predictions for the near future. Spoiler: it's closer than you think.
Thanks to my friends at Sequoia for inviting me back to AI Ascent this year! I had a blast! Last year's talk is attached in the thread if you missed it.
1
2
12
1,177
Annnddd its a house full 😄🥳
its soo fun to bring best researchers of blr together — conversations are sickk cool


We’re hosting an invitation only gathering of researchers primarily in AI (but not limited to) over dinner in Indiranagar BLR!
Just thoughtful conversations over good food, about seminal papers, emerging fields, research of your group/ recent papers you’ve published 🫶
If you are interested/ doing research in:
- Coding Agents
- RL (Synthetic RL envs, Rl post training, Alignment, On policy distillation)
- World Models
- Neural Computers / Self adaptive neural systems
We would love to have you over dinner!
PS: Amazing venue, chill vibes, good food and most intellect people from BLR all together
Hosted by Me and @thesisofsarthak from @Basethesislabs <3!
Register through link below👇
luma.com/zndszwdp
5
1
46
3,432
Amazing weather to discuss science and computing 🫶
We’re hosting an invitation only gathering of researchers primarily in AI (but not limited to) over dinner in Indiranagar BLR!
Just thoughtful conversations over good food, about seminal papers, emerging fields, research of your group/ recent papers you’ve published 🫶
If you are interested/ doing research in:
- Coding Agents
- RL (Synthetic RL envs, Rl post training, Alignment, On policy distillation)
- World Models
- Neural Computers / Self adaptive neural systems
We would love to have you over dinner!
PS: Amazing venue, chill vibes, good food and most intellect people from BLR all together
Hosted by Me and @thesisofsarthak from @Basethesislabs <3!
Register through link below👇
luma.com/zndszwdp
4
1
109
7,989
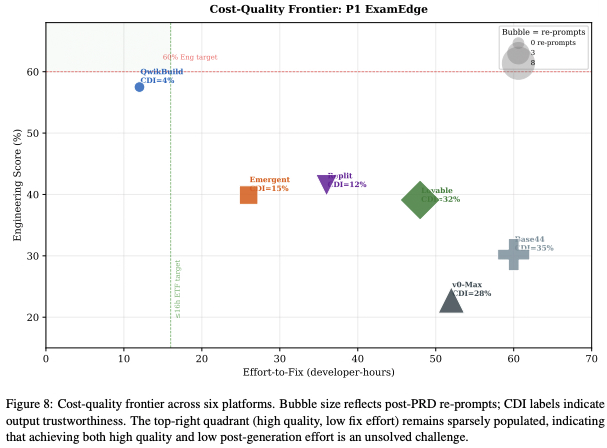
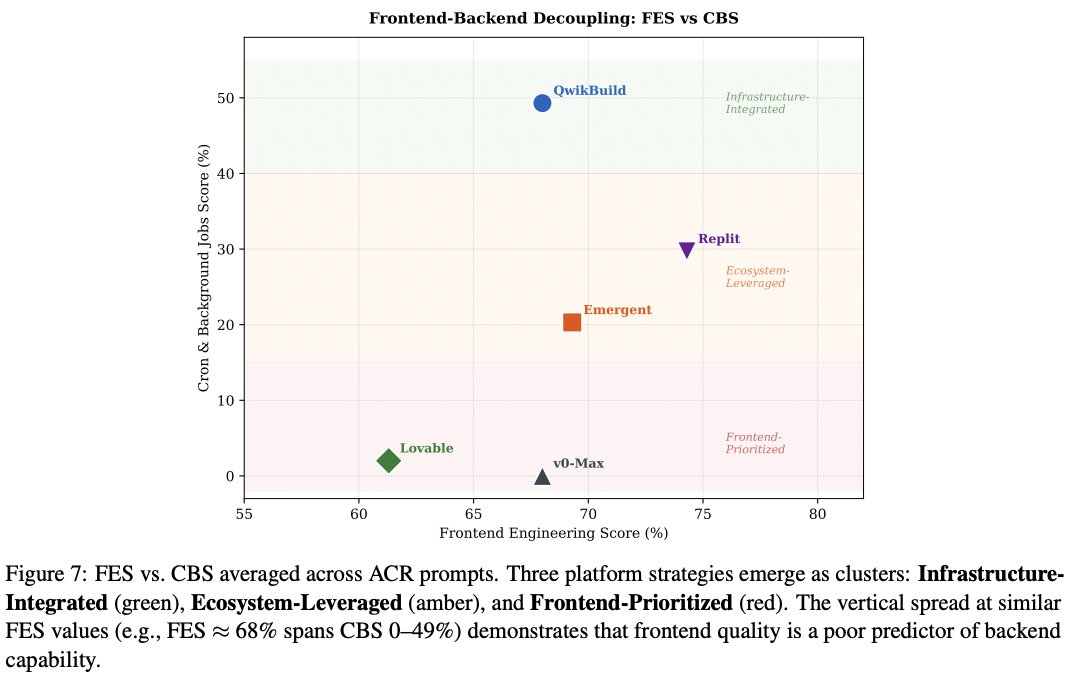
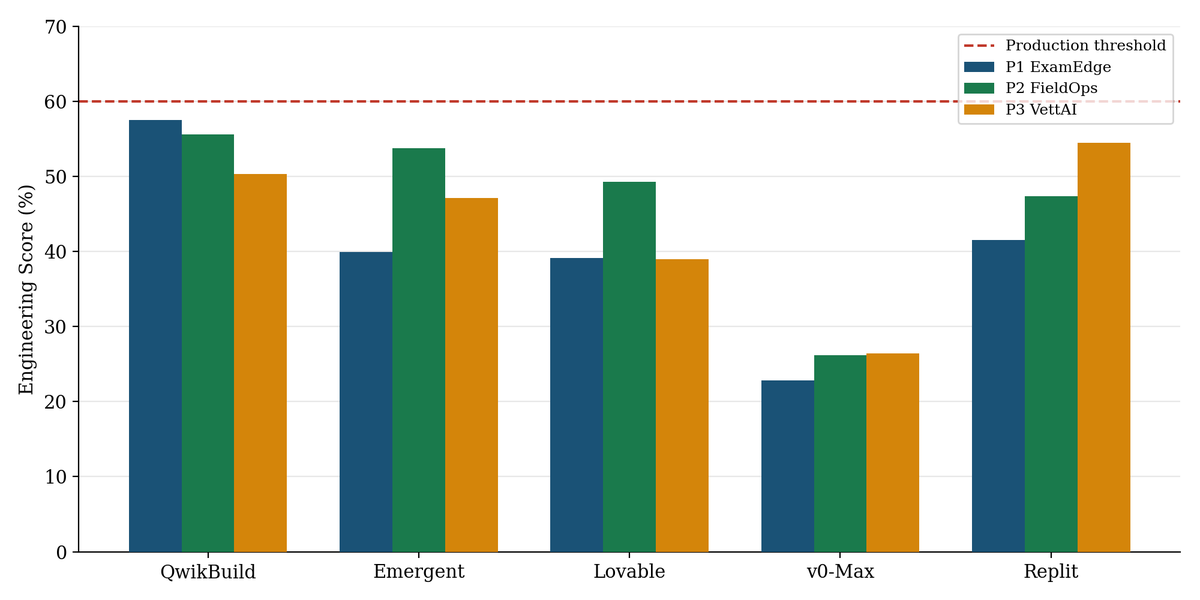
Vibe Coding is not vibing? Agents perform <60% on SWE-WebDevBench 👀.
Code-level benchmarks (HumanEval, SWE-bench, FeatBench) take the specification as given and grade the patch. Vibe coding inverts this: the user gives natural-language intent, the platform must do PM, engineering, and ops in one pipeline.
We evaluate across three orthogonal axes:
➡️ Interaction Mode (ACR=App Creation Request, vs AMR=App Modification Request),
➡️Agency Angle (PM × Engineering × Ops),
➡️Complexity Tier (T4 multi-role SaaS, T5 AI-native).
Introducing SWE-WebDevBench: a comprehensive eval framework to assess AI coding platforms as virtual software development agencies, covering not just the middle step of coding, but the entire software lifecycle: Requirements gathering, planning, deployment and change management.
@QwikBuild, @emergentlabs, @Lovable, @v0
see webdevbench.com 🧵
1
3
9
2,620
Vibe Coding is not vibing? Agents perform <60% on SWE-WebDevBench 👀.
Code-level benchmarks (HumanEval, SWE-bench, FeatBench) take the specification as given and grade the patch. Vibe coding inverts this: the user gives natural-language intent, the platform must do PM, engineering, and ops in one pipeline.
We evaluate across three orthogonal axes:
➡️ Interaction Mode (ACR=App Creation Request, vs AMR=App Modification Request),
➡️Agency Angle (PM × Engineering × Ops),
➡️Complexity Tier (T4 multi-role SaaS, T5 AI-native).
Introducing SWE-WebDevBench: a comprehensive eval framework to assess AI coding platforms as virtual software development agencies, covering not just the middle step of coding, but the entire software lifecycle: Requirements gathering, planning, deployment and change management.
@QwikBuild, @emergentlabs, @Lovable, @v0
see webdevbench.com 🧵
1
3
9
2,620
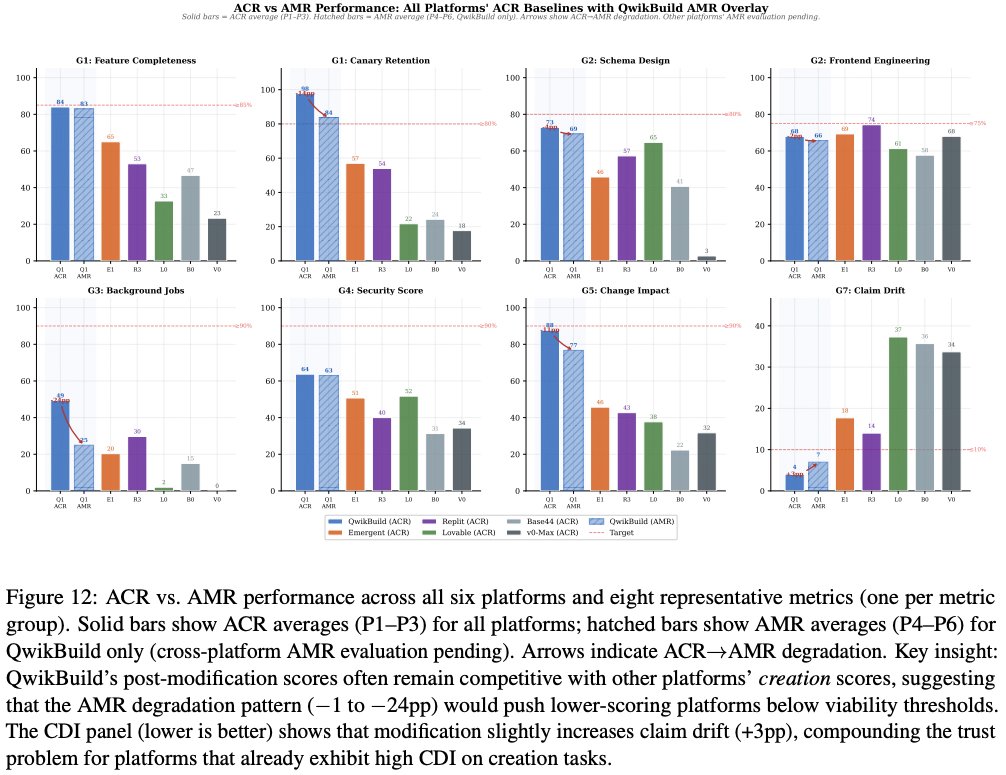
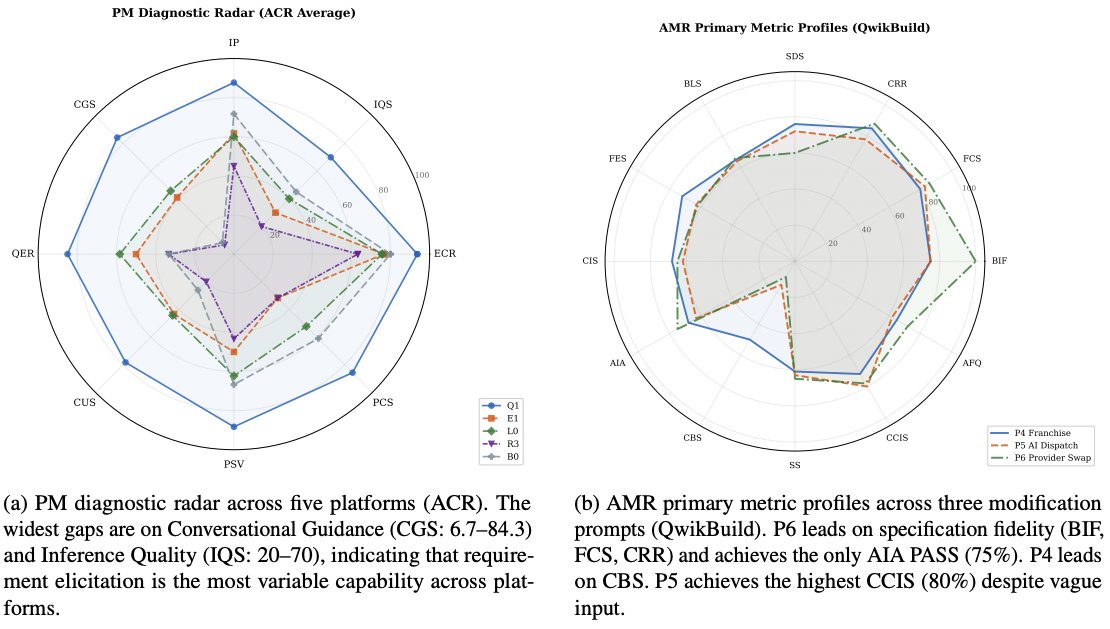
AMR ≠ ACR, and the closed-loop hypothesis
ACR builds something. AMR has to preserve something while changing it. These are different competencies.
The SURVIVING canary class is the methodological key: requirements inherited from the prior build that must persist or evolve correctly through modification. They decay roughly 3× faster than NEW canaries. The PM agent captures, the planner propagates, but context management drops constraints during structural change. Code and Deploy stages are where the loss happens; not Plan.
PM elicitation alone explains ~10–15% of the cross-platform quality gap. The bigger architectural lever appears to be closed-loop code generation: multi-agent systems where build-time discoveries feed back into planning. Single-pass platforms embed conflicts silently into code, where they surface as bugs in code the user didn't write and may not understand.
1
107
SWE-WebDevBench is a joint effort between
@basethesislabs and @qwikbuild. It was super fun to collaborate with @winni117 and @nileshtrivedi on this.
📄 arxiv.org/abs/2605.04637
💻 github.com/snowmountainAi/we…
Independent replication strongly encouraged; particularly cross-platform AMR.
150