
Lapsed neuroscientist turned data everything. Interests outside neuroecon: irrationality, metascience, LLMs (duh)
Joined October 2009
- Tweets 1,168
- Following 969
- Followers 495
- Likes 125,448
46 Photos and videos









Pinned Tweet

28 Feb 2022
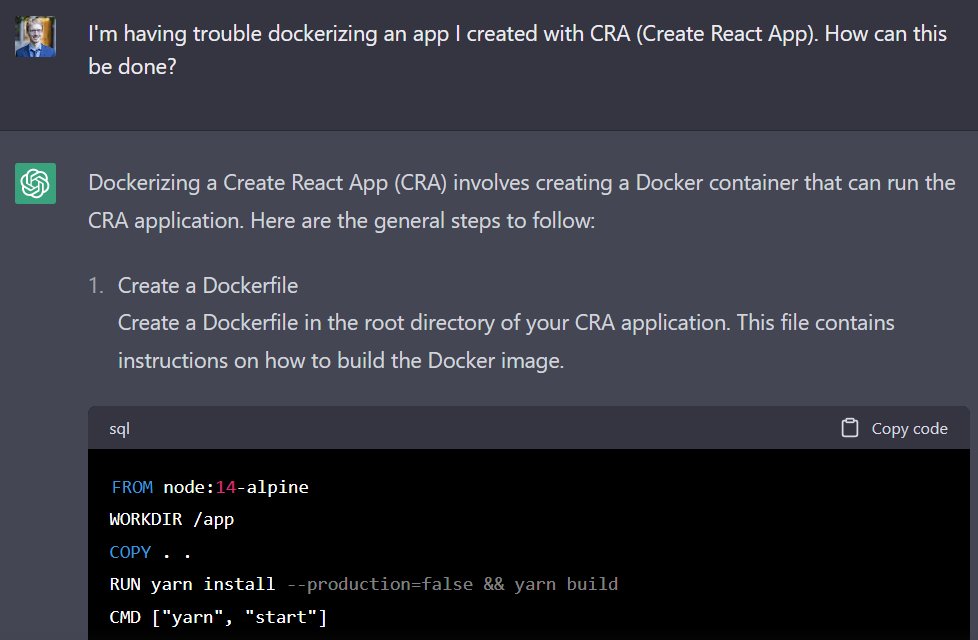
"how do you explain @getdbt to non-AEs?"

ALT Meme: "thank you for changing my life", dbt logo responds "I'm literally just a Jinja templater that runs your SQL in the right order"
5
14
123
Šimon Podhajský retweeted

Jun 6
"they're only withholding the model for safety as a marketing ploy" is such a dumb take and has been for most of a decade. you can think they're wrong about ai risk but nobody is running gigabrain plans to forgo enormous certain profits now for theoretical future profit
21
28
507
26,919
Šimon Podhajský retweeted

May 28
I want to take a stab at being more specific about why I think this is bad. The easy answer is just that this is almost always undisclosed AI use, so the higher % AI people are lying, presenting AI work as their own work. Beyond that, I do feel sad about the breakdown of the relationship between 'long text with broad vocabulary and syntax' and 'real intellectual work'. If I read a dissertation from 5 years ago, it can only be well-written if someone who is reasonably smart and knowledgeable put that work in. Therefore, if it's well-written it's probably worth reading. That signal is gone. Most stuff isn't worth reading, and authors have lost one way to signal that their stuff is different.
That's not to say that someone who uses disclosed AI is doing anything wrong, even if there's a big cost to the new equilibrium. It's obviously very useful. And some smart and knowledgeable people can't write, so my previous strategy filtered out good work by people who can't write. I don't think it's viable to ask for anything other than "disclose AI use".
...but, once you've disclosed it, I probably won't read it, because I don't have a good way to assess at a glance if it's worth my time.

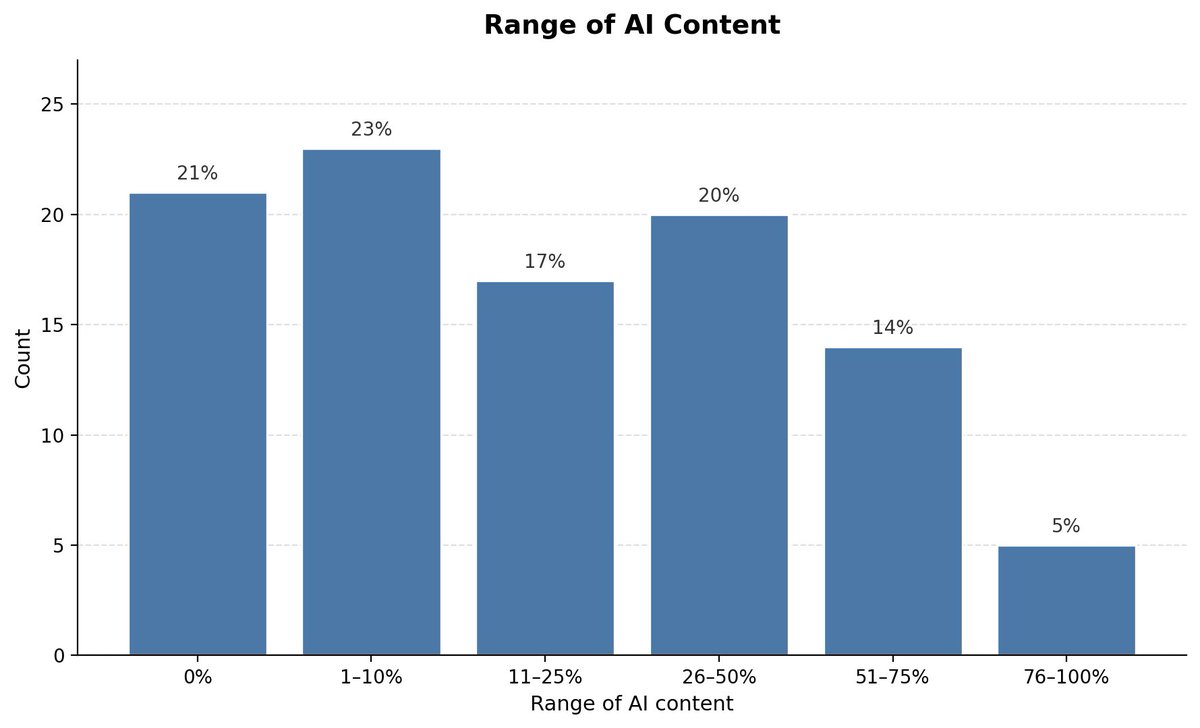
Out of a sample of 100 Doctor of Education dissertations, over half contained some amount of AI-generated text.
Research done in collaboration with Pangram. Link to full paper in replies.
34
20
291
35,708
Šimon Podhajský retweeted

May 13
These "requirements to build affordable housing" are a demand that builders rent or sell a percentage of their brand new homes at a loss. This is a tax on new housing that has worsened the housing shortage and increased housing prices in every city where it was implemented.
May 13

There are currently six BUILD bills in the state Senate aimed at increasing housing and lowering costs. "Yet there’s one thing missing in each bill: a requirement to build affordable housing," write Carolina Sternberg and Jesse Mumm of DePaul University. chicago.suntimes.com/other-v…
6
75
891
23,494
Šimon Podhajský retweeted

May 13
In life, everything is a wager. Whether you realize it or not, you are constantly making implicit and explicit predictions about the future state of reality. To live is to predict.
So when you are faced with something like Mythos, and you say, “this is just ‘doomer hype’!,” what you are really doing is making a bet against model capabilities growth, and thus ultimately you are making a broad directional bet against deep learning, which has usually been a pretty bad bet to make.
I am surprised that so many people—people who are otherwise AI optimists!—continue to make these bets against deep learning. They keep being wrong, and the less humble among them have torched their credibility with anyone paying attention.
So ask yourself, when you make claims about AI and its future: “am I making an implicit bet against deep learning in a broad directional way?”
May 13

UK AISI has access to a "newer Mythos Preview checkpoint", which now performs significantly better on its cybersecurity benchmarks:
TLO: 6/10 attempts successful (up from 3/10 for the original Mythos)
Cooling Tower: 3/10 attempts successful (previously unsolved by AI)
21
26
307
28,147


Šimon Podhajský retweeted

If you do a blind test with laypeople, they will tend to prefer the AI writing style. It’s only us weirdos with high-brow (read: objectively correct) taste that notice this stuff and learn to despise it.
This suggests that the explanation is not some kind of mistake or error. ChatGPT uses negative parallelisms because, somehow, to the majority of its audience, they constitute “good” writing.
As somebody who is kind of obsessed with rhetoric, I think the answer is pretty obvious: people process information better when it is strongly contrasted. It is often insufficient to tell people “what something is” if you do not also tell them “what it is not”.
You’ll notice I just used Negation like 3 times in the preceding paragraphs and imo it is an incredibly effective technique. Perhaps I’d even go so far as to assert that the fundamental unit of communication is neither the bare assertion nor the atomic truth value, but *difference*.
Parallelism is then another One Neat Trick you layer on top of Negation to improve ease of comprehension. With parallel sentence structures you are literally reducing the amount of grammatical/structural information that the person has to process in order to digest your point. It’s a cheat code. Read the writings of any good orator and you’ll see it littered everywhere.
And the simplest form of bashing these two techniques together is the Negative Parallelism: it’s not X, it’s Y.

I think AI saying "it's not X, it's Y" a lot is a form of mode collapse?
The modal token which comes after "it's" is typically "not."
But it has to be something more than just mode collapse though, like you wouldn't see this with raw probabilities in a sampled natural corpus.
43
58
1,185
100,840
Šimon Podhajský retweeted
Apr 18
The whole “talking about risks from frontier AI is 6d marketing chess” trope reminds me so much of the Jobs-era knock against Apple that everything they did was “just marketing,” yelled by their detractors as Apple’s superior products took over the world. “It’s just marketing” is what technology industry observers say when they do not understand what is happening but want to seem situationally aware, mistaking cynicism for savvy.
13
28
411
17,795
Šimon Podhajský retweeted

Apr 18
“The labs are running around telling people their product is dangerous and should be taxed and regulated as a ploy to pump up their valuations” is a such a perfect demonstration of the thesis of this paper journals.sagepub.com/doi/10.…

16
45
408
109,858

Šimon Podhajský retweeted

Apr 9
I think it is generally a good idea to take AI company claims about unreleased models with a grain of salt, but at this point the deniers are implying there is an industry-wide conspiracy to let Anthropic claim they are finding zero-day exploits in critical software with, I guess, a basement full of world-class white hat hackers pretending to be Claude?
Apr 9

It’s crazy that some are just straight up in denial about mythos having the capabilities anthropic says it does. Usually the in-denial-about-AI community is able to cloak their views in at least *some* intellectual garb, but this time it’s just, “it’s not real.” Wild. Also sad.
25
27
345
57,452
Šimon Podhajský retweeted

Jan 29
Agent Builders vol. 2 yesterday.
We went deep on agentic evals. How to get started, what tools people actually use, and which methodologies hold up in production.
Thanks Václav Čadek and @sim_pod for coming and @daniel_bukac for presenting how we do it at @duvoai

2
3
201
Jan 25
This actually is a good prompt (though whether it will stand up to targeted prompt injection attacks is an open question), but the irony of having a one-liner that installs it is palpable.
Jan 25

Since I’m seeing so many new people are installing Clawdbot, I highly recommend inoculating it against prompt injection attacks (or at least hardening it a lot to make it much more resistant) with my ACIP project. I even made a one-liner installer script:
github.com/Dicklesworthstone…

1
5
3,044
Šimon Podhajský retweeted

Jan 10
Important point. As organizations grapple with influx of one -shot AI generated content (#6), it is critical to have tools that do not flag the value-generating cases (1-4) as the slop (#6).
To its credit, @pangram does make this distinction, but we have not audited this.

Imo we should have a 6-point scale for AI involvement in writing:
1. Human-only
2. AI-assisted research/ideation
3. AI-edited human draft
4. AI as co-writer
5. Human-edited AI draft
6. One-shot generated
And we should clearly differentiate critiques of substance vs style.
3
6
34
6,022
Šimon Podhajský retweeted

13 Sep 2025
As a Texas YIMBY, this is what I have the most respect for about the CA YIMBYs.
They are Sisyphus and the housing crisis is the stone. The amount of grit and determination they have is insane. I’m so stoked for them and for California.

13 Sep 2025

What's impressive about California YIMBYs is that they don't get everything they want every year, but they keep coming back and adding more each session. California still has far too much red tape and NIMBYism but they're whittling away at it year by year, bit by bit.
24
113
2,209
66,851
16 Aug 2025
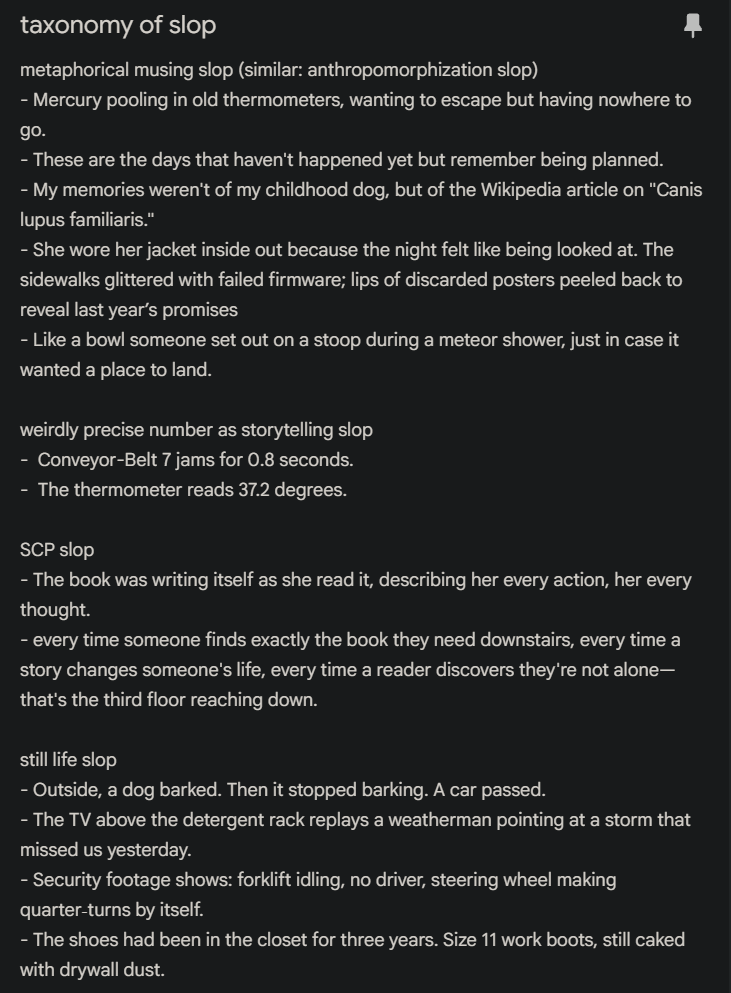
LLMs amplify midwit trope writing, which is terrible news for midwits like me
(I'm an admitted sucker for "weirdly precise number as storytelling slop" and "metaphorical musing slop", and suspect some of the latter is still good writing when used judiciously)




1
263

Šimon Podhajský retweeted

27 Jul 2025
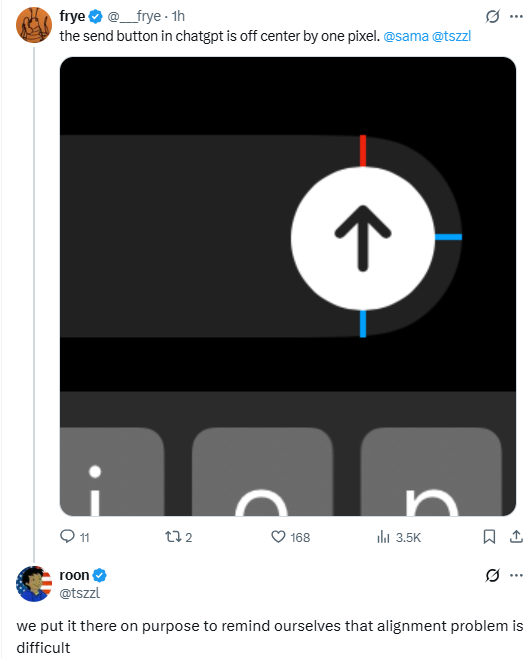
"I saved a PNG image to a bird" is just an incredible sentence, simultaneously the platonic ideal of YouTube title, and the thing he did.

Bird saves and reproduces data: A PNG image of a bird ( photo of a bird -> spectral synthesizer ) was reproduced by an adult Starling bird youtu.be/hCQCP-5g5bo?si=HMtV…. It seems to have reproduced the sound in conjunction with some additional notes which made it not detectable aside from the recording of the bird in post.
16
524
7,428
198,087
Šimon Podhajský retweeted

27 Jun 2025
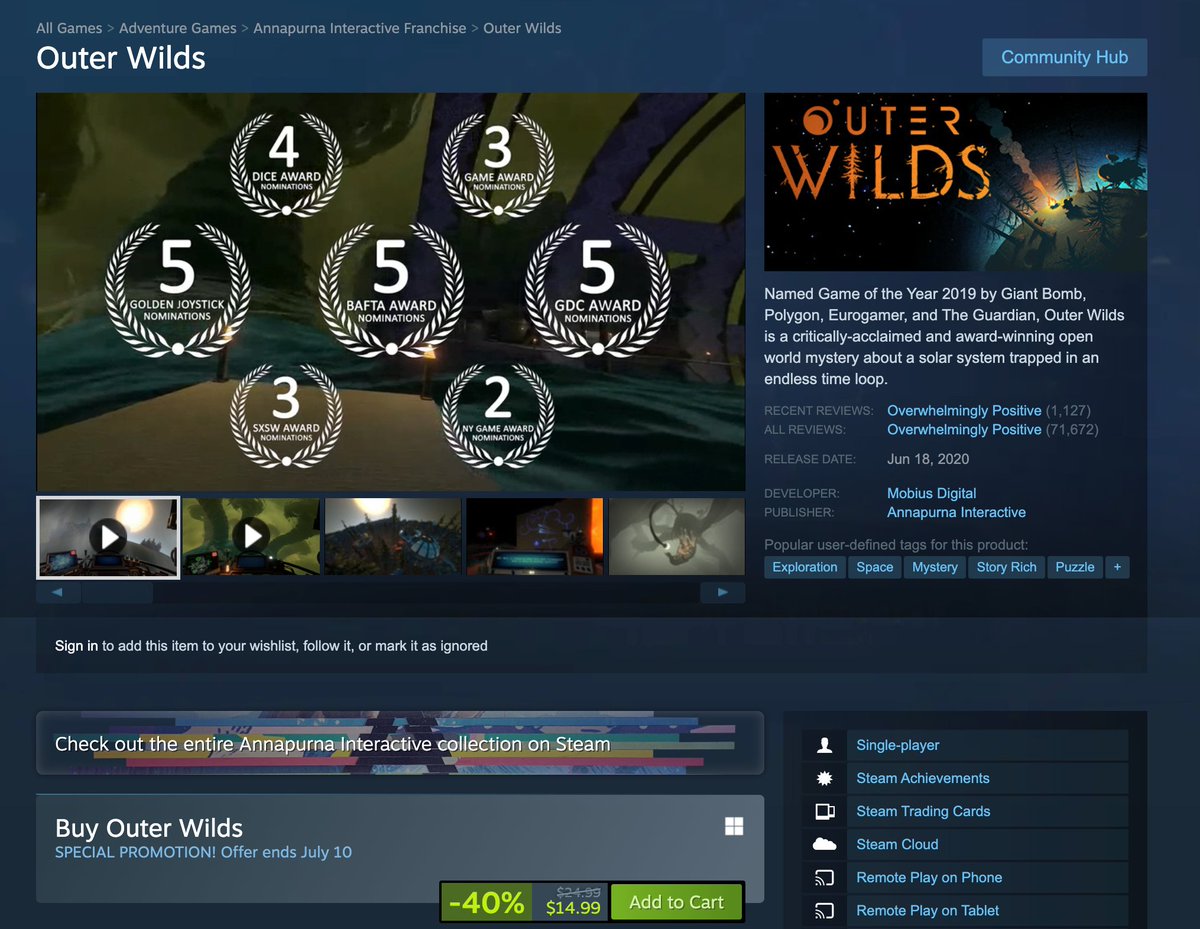
Outer Wilds (the best video game ever made) is on sale on Steam for $15.
Please play this game. Takes about 20 hours to finish. The less you know going in the better.
122
84
1,883
416,277
Šimon Podhajský retweeted

18 Jun 2025
Whenever I see a system prompt that starts with "You are a".
72
17
817
124,493
Šimon Podhajský retweeted

2 Jun 2025
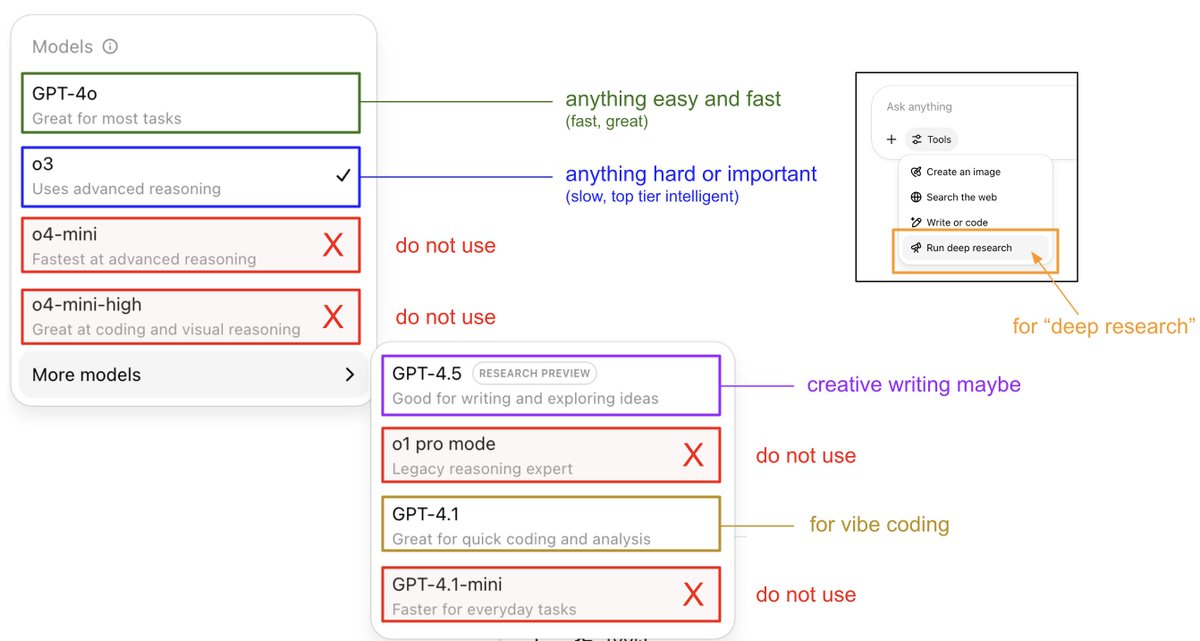
An attempt to explain (current) ChatGPT versions.
I still run into many, many people who don't know that:
- o3 is the obvious best thing for important/hard things. It is a reasoning model that is much stronger than 4o and if you are using ChatGPT professionally and not using o3 you're ngmi.
- 4o is different from o4. Yes I know lol. 4o is a good "daily driver" for many easy-medium questions. o4 is only available as mini for now, and is not as good as o3, and I'm not super sure why it's out right now.
Example basic "router" in my own personal use:
- Any simple query (e.g. "what foods are high in fiber"?) => 4o (about ~40% of my use)
- Any hard/important enough query where I am willing to wait a bit (e.g. "help me understand this tax thing...") => o3 (about ~40% of my use)
- I am vibe coding (e.g. "change this code so that...") => 4.1 (about ~10% of my use)
- I want to deeply understand one topic - I want GPT to go off for 10 minutes, look at many, many links and summarize a topic for me. (e.g. "help me understand the rise and fall of Luminar"). => Deep Research (about ~10% of my use). Note that Deep Research is not a model version to be picked from the model picker (!!!), it is a toggle inside the Tools. Under the hood it is based on o3, but I believe is not fully equivalent of just asking o3 the same query, but I am not sure.
All of this is only within the ChatGPT universe of models. In practice my use is more complicated because I like to bounce between all of ChatGPT, Claude, Gemini, Grok and Perplexity depending on the task and out of research interest.
617
1,574
13,332
1,350,832