
OG local LLaMA shill. Sr. Solution Architect @RedHat, ex particle physicist. Born @ 347 ppm CO₂. Personal account, potentially unaligned.
Joined March 2009
- Tweets 3,622
- Following 6,792
- Followers 1,882
- Likes 110,122
71 Photos and videos



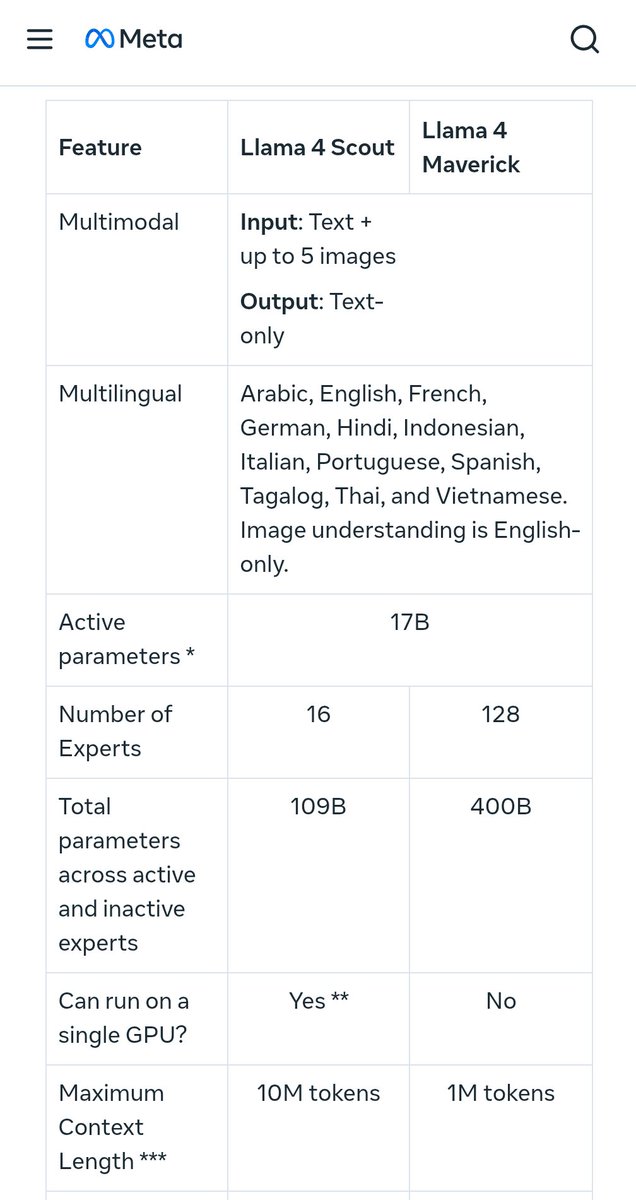







Pinned Tweet

Apr 11
Your Hermes Agent can now delegate to RLMs 🙌 Recreated the document analyzer example with the converted skill. 136 PDF pages analyzed. Best part: Auto-configures from HERMES_MODEL / HERMES_PROVIDER env vars @NousResearch @Teknium
github.com/sroecker/predict-…

8
28
329
48,221
Steffen Röcker retweeted

Jun 10
How it feels to use Claude Fable

2
31
1,085
40,418
Steffen Röcker retweeted

Jun 8
Most AI agents forget everything between conversations. Hermes Agent doesn't.
It creates reusable skills from completed tasks, persists user memory across sessions, and runs a built-in cron scheduler for autonomous workflows. Deployed on OpenShift AI with @vllm_project for GPU inference, under 10 minutes with oc apply.
Deployment manifests and UBI 9 Dockerfile: github.com/aicatalyst-team/h…
developers.redhat.com/articl…
5
29
10,050
Steffen Röcker retweeted

Jun 8
another banger from @pupposandro and the @luceboxai team
Luce Spark runs Laguna XS.2 in 14.6 GiB at ~100 tok/s on an RTX 3090, versus ~119 tok/s fully resident.
you can now run Laguna below the 16 GiB line and use it for local evals, agent traces, routing analysis, quantization, and serving experiments.
Jun 8

Excited to launch Luce Spark: now a 35B MoE runs on a 16GB GPU, with no offload tax.
An A3B model fires ~8 of its 256 experts per token, but to keep it resident you pay VRAM for all 256. Spark pins the experts your traffic actually hits, offloads the rest to CPU, and decodes the whole token in one fused graph, so offload stops costing speed.
▸ Qwen3.6 35B-A3B: ~20.5 → 13.3 GiB
▸ Laguna XS.2 33B-A3B: 18.8 → 14.6 GiB
Decode holds ~100 tok/s, close to the 119 you get with every expert resident on a 24 GB card. No calibration step. It tunes itself from live traffic.
5
11
43
4,058
Steffen Röcker retweeted

Jun 5
🧠 Gemma 4 QAT checkpoints are out, and vLLM is Google's recommended way to serve them!
Open-source inference is at its best when one engine spans research and production — glad vLLM's is the recommendation for Gemma 4 QAT.
Get started 👇 huggingface.co/collections/g…
Jun 5

We just dropped Gemma 4 Quantization-Aware Training (QAT) checkpoints on Hugging Face!
All Gemma 4 model sizes and their drafters are now optimized with QAT to cut memory requirements and maximize on-device performance!
8
19
181
18,291
Steffen Röcker retweeted

Jun 2
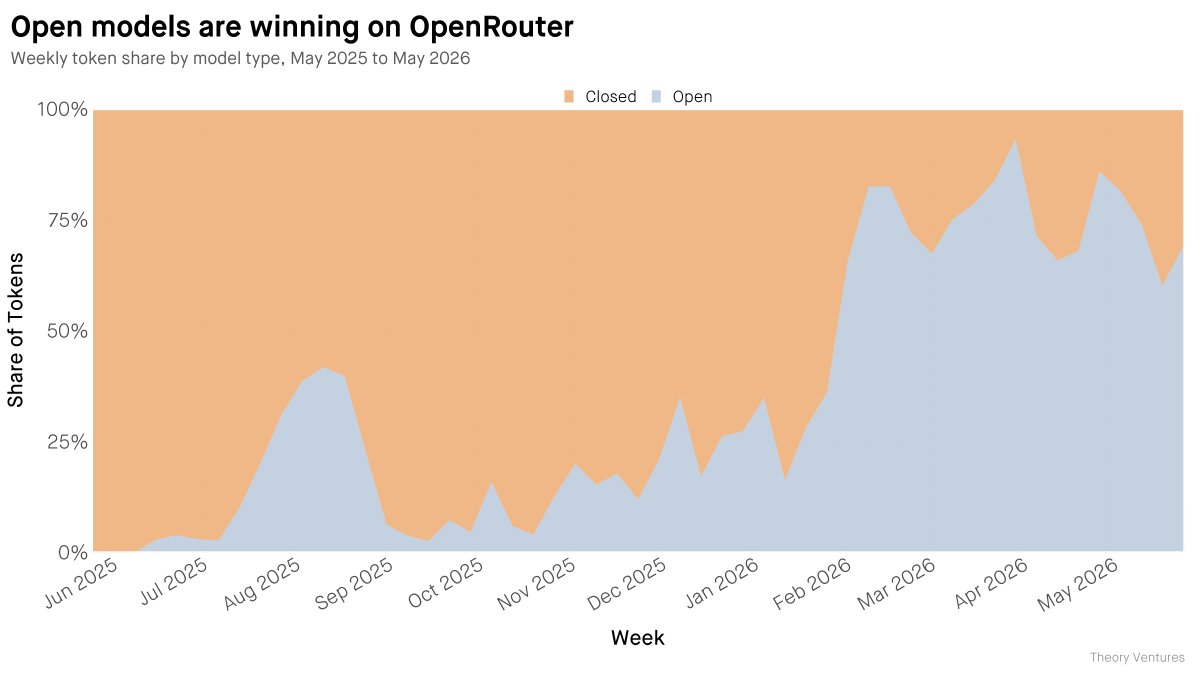
Open-weight models have overtaken closed models on OpenRouter.
69.1% of token volume now goes to open-weight models. 30.9% to closed.
Competition is a discovery procedure — and developers are discovering the value of open models.
🧵
14
36
156
31,675
Steffen Röcker retweeted
May 29
Speculators v0.5.0 just dropped with 3 big updates:
- DFlash training support. Draft all tokens in one pass via block diffusion
- Unified online/offline training powered by @vllm_project's hidden states extraction system
- Docs & tutorials overhaul for faster onboarding
vllm.ai/blog/2026-05-28-spec…
7
50
4,220
Steffen Röcker retweeted

May 28
Project Lightwell is a $5 billion investment that marks a fundamental shift in how we think about our role as open source stewards. I believe it will define the next chapter of Red Hat's engineering mission. We are applying the same discipline, upstream-always commitment, and engineering rigor across all active application layers that modern enterprise environments depend on.

Introducing Project Lightwell from @IBM and Red Hat: a $5 billion, AI-powered, 20,000 engineer-strong, first-of-its-kind force to identify and fix open source vulnerabilities at scale.
Read about our commitment to the future of open source in the AI era. red.ht/4nV9iwW

2
7
16
1,563

the trick is not to do native tool calling instead do code gen in a RLM style REPL
May 27

The local-model crowd has been right that you can run serious models on a laptop. The catch nobody mentions: tool selection breaks there first.
qwen3.5 on an M4 MacBook, 100 tools wired in, picks the right tool 8% of the time. Same model, same laptop, ranking gateway in front: 77%.
Local OSS didn't need a bigger model to become viable for agents. It needed the catalog ranked before the model sees it.
This one's for the people like @ivanfioravanti pushing local hard. cc @rstagi_
1
2
43
2,374
Steffen Röcker retweeted
May 27
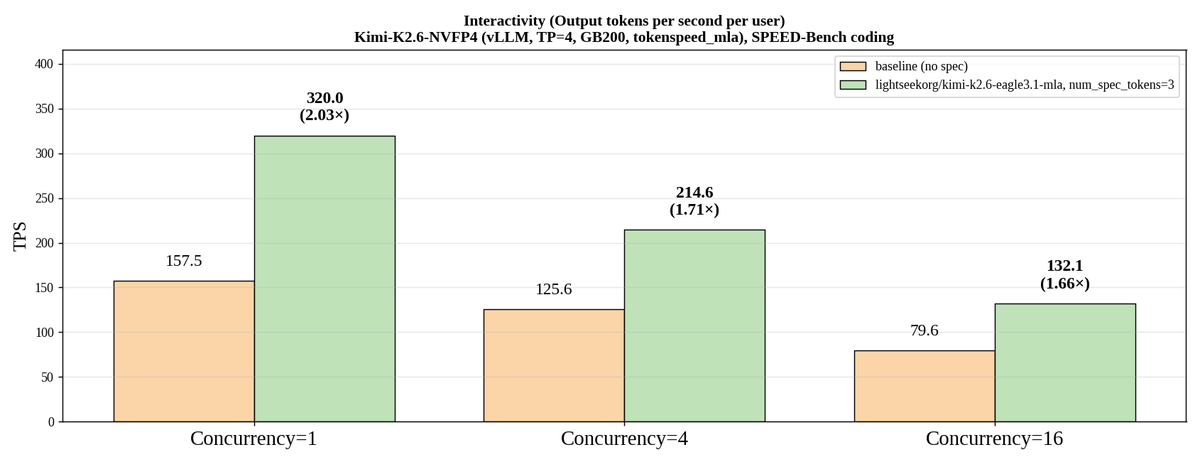
EAGLE 3.1 is out. The team identified attention drift as the root cause of acceptance-length degradation at deeper speculation steps.
Fix: FC normalization post-norm hidden-state feedback. Result: 2x longer acceptance length in long-context workloads, 2.03x per-user throughput on Kimi K2.6.
Already in @vllm_project nightly. Native support lands in the next release v0.22.0. Open source draft model available now.
May 26

🎉Thrilled to announce EAGLE 3.1 - the next evolution of speculative decoding from @EagleCorp, developed by @hongyangzh, @dogacel0, and the EAGLE team in collaboration with vLLM @vllm_project and TorchSpec @lightseekorg!
💡EAGLE 3.1 introduces a new FC normalization post-normalization hidden-state feedback architecture that significantly improves long-context robustness, acceptance length, and serving stability across real-world inference environments.
Shoutout to @NVIDIA who has been instrumental in the large-scale training, benchmarking, and inference validation of EAGLE 3.1 to help bring this next step in inference acceleration to production environments.
For EAGLE 3.1, the EAGLE team identified attention drift as a key bottleneck behind deeper-step acceptance-length degradation in speculative decoding.
✨What's new:
• Up to 2× longer acceptance length in long-context
• Stronger long-context chat-template robustness
• More stable serving across diverse prompts or environments
• Native vLLM support
• TorchSpec training support
• Open-source Kimi K2.6 EAGLE 3.1 draft model
🔗 Blog: vllm.ai/blog/2026-05-26-eagl…

3
4
60
4,806
Steffen Röcker retweeted

May 19
🚀 Organizing the Efficient Qwen Competition @icmlconf !
Goal: Minimize LLM inference latency for a single GPU without breaking model quality.
Prizes: $3K / $2K / $1K present at ICML 2026, Seoul
Getting Started - adaptfm.gitlab.io/call-for-c…
Leaderboard - d1krc5fcnf73gi.cloudfront.ne…
6
16
144
10,736
Steffen Röcker retweeted

May 20
What hardware actually powers open-source AI?
Not benchmarks.
Not vendor marketing.
Real-world community usage.
We’re launching @huggingface Hardware:
→ trending GPUs & CPUs
→ VRAM distribution
→ inference hardware trends
→ what the OSS AI ecosystem really runs on

41
71
415
80,954
Steffen Röcker retweeted

May 19
Weight-only quantization powers local LLMs like llama.cpp or Ollama. But SOTA quantized accuracy requires complex kernels that are notoriously hard to implement.
Can we get SOTA accuracy and keep things simple? Our new GSQ (Gumbel-Softmax Quantization) method says yes. 🧵
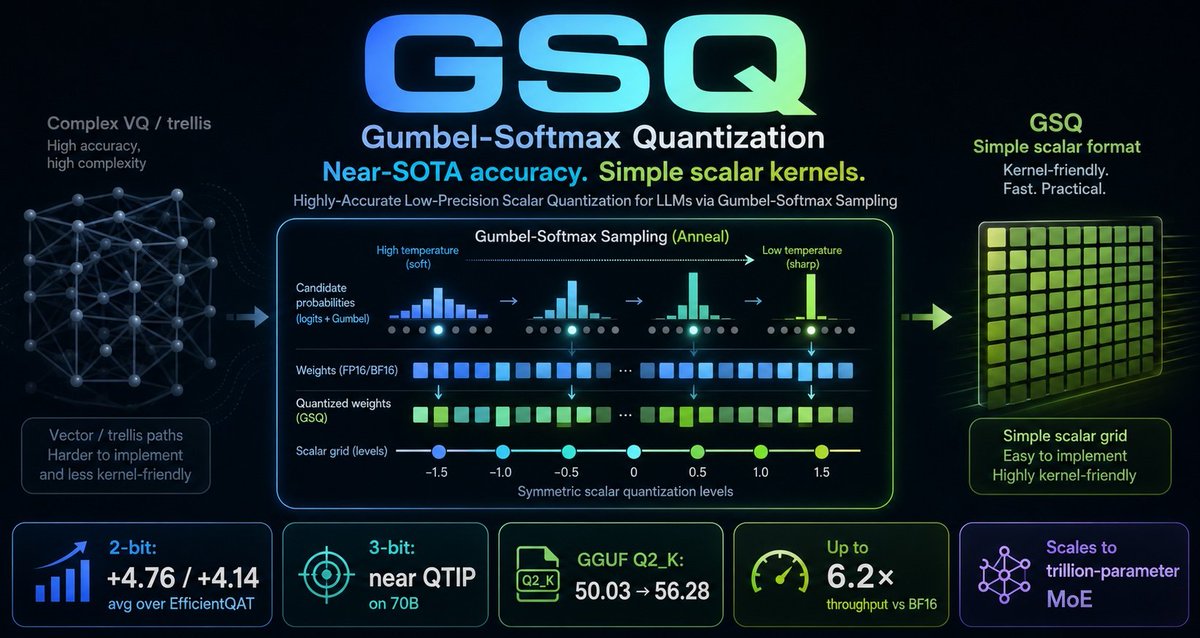
1
11
51
6,184
Steffen Röcker retweeted

May 13
We released experimental MTP Qwen3.6 Unsloth GGUFs!
Qwen3.6 27B MTP now runs at 140 tokens/s. Qwen3.6 35B-A3B MTP gets 220 tokens/s generation on a single GPU.
Qwen3.6 27B and 35B-A3B have >1.4x speed-up over the original GGUFs without any change in accuracy.
Guide GGUFs Benchmarks: unsloth.ai/docs/models/qwen3…
In terms of average speedup, we see a 1.4x for dense models at draft tokens = 2 and for the MoE around 1.15 to 1.2x.
We do not recommend more than 2 draft tokens because the acceptance rate drops precipitously from 83% to 50% with 4 draft tokens, and the forward passes for MTP become less beneficial.
Use `--spec-type mtp --spec-draft-n-max 2`
Thanks to Aman for github.com/ggml-org/llama.cp…!
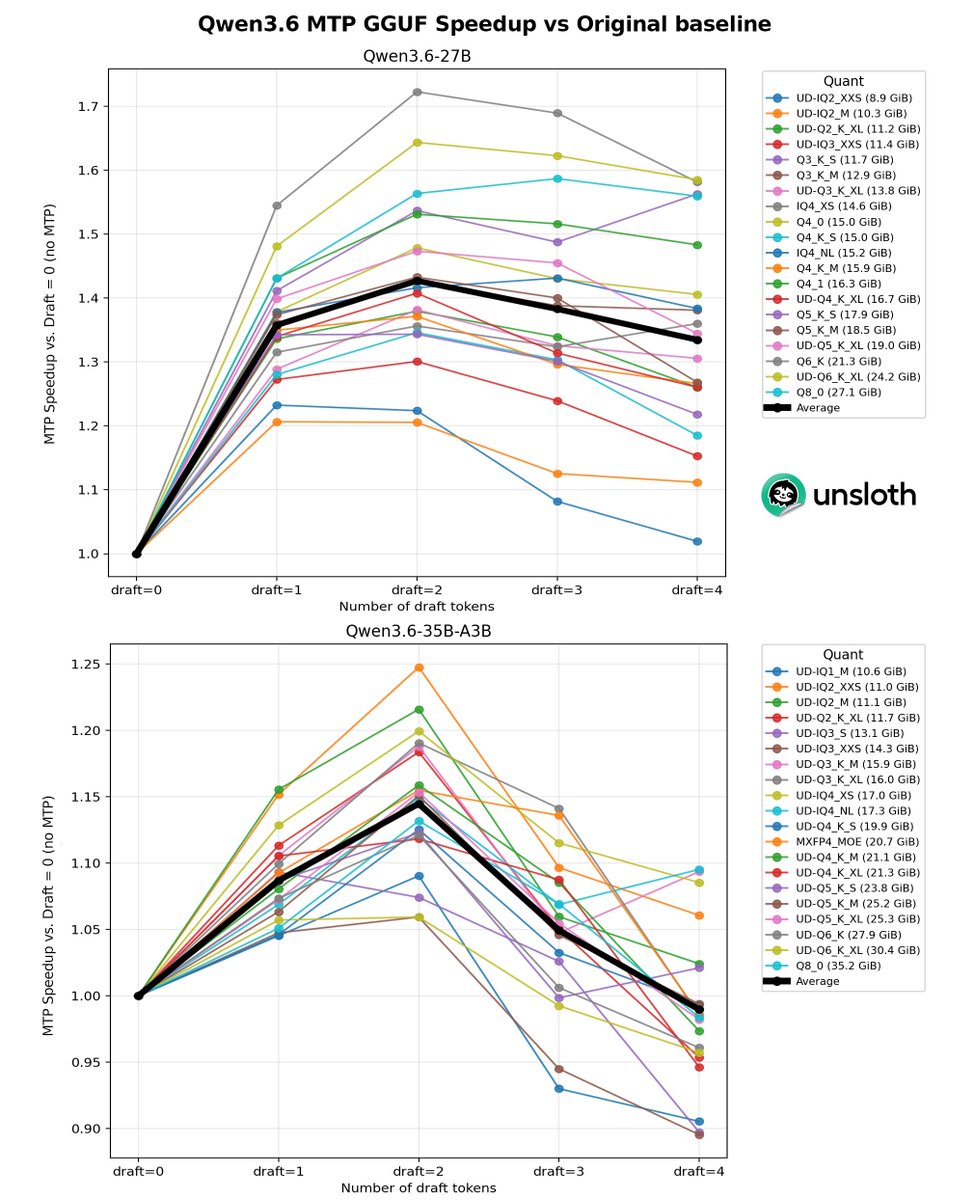
60
117
785
123,742
Steffen Röcker retweeted

May 11
appreciate the comprehensive write-up from @_EldarKurtic, @mgoin_, @RedHat_AI on TurboQuant. data on H100 with native FP8 Tensor Cores looks right for what was tested. few things to add from the non-H100 side, where most of my testing lives:
May 11

TurboQuant has drawn a lot of attention recently, but the accompanying evals didn't tell the full story.
So we ran what I believe is the first comprehensive study of TurboQuant: where it helps, where it falls short, and how it impacts accuracy, latency, and throughput.
Findings:
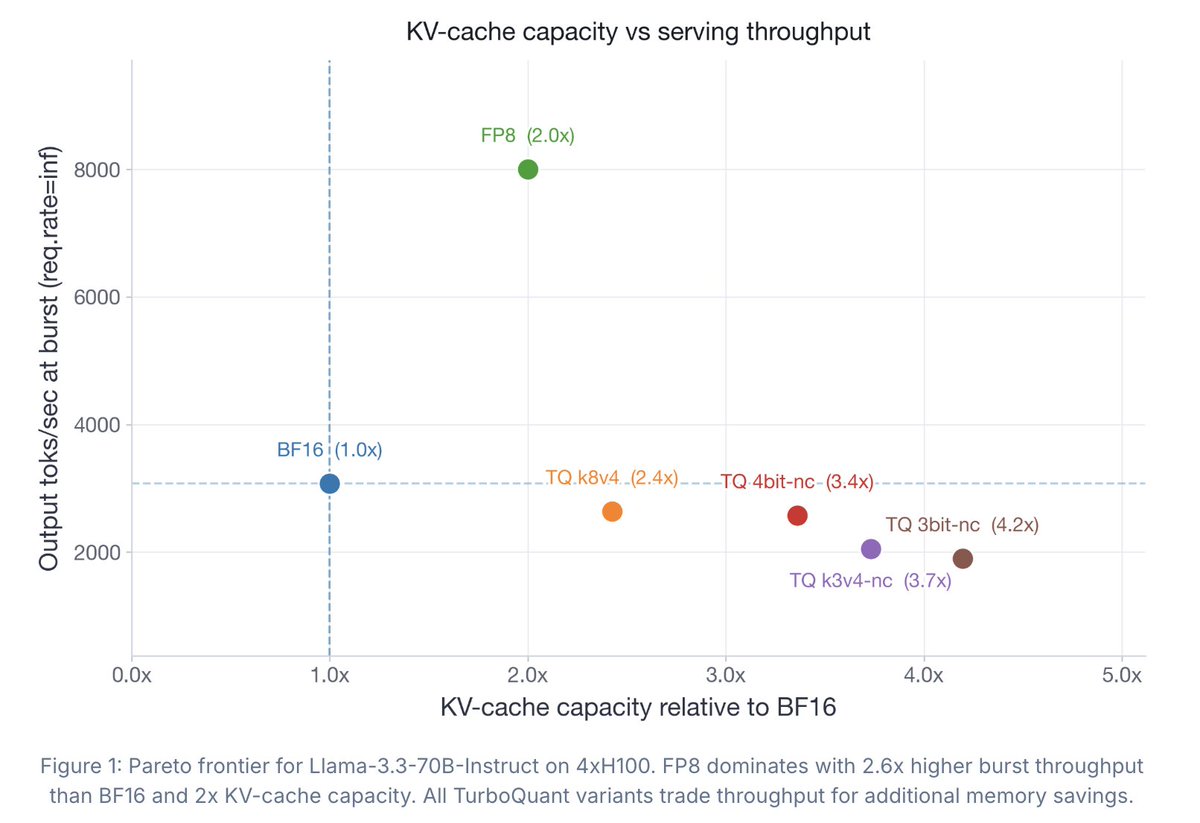
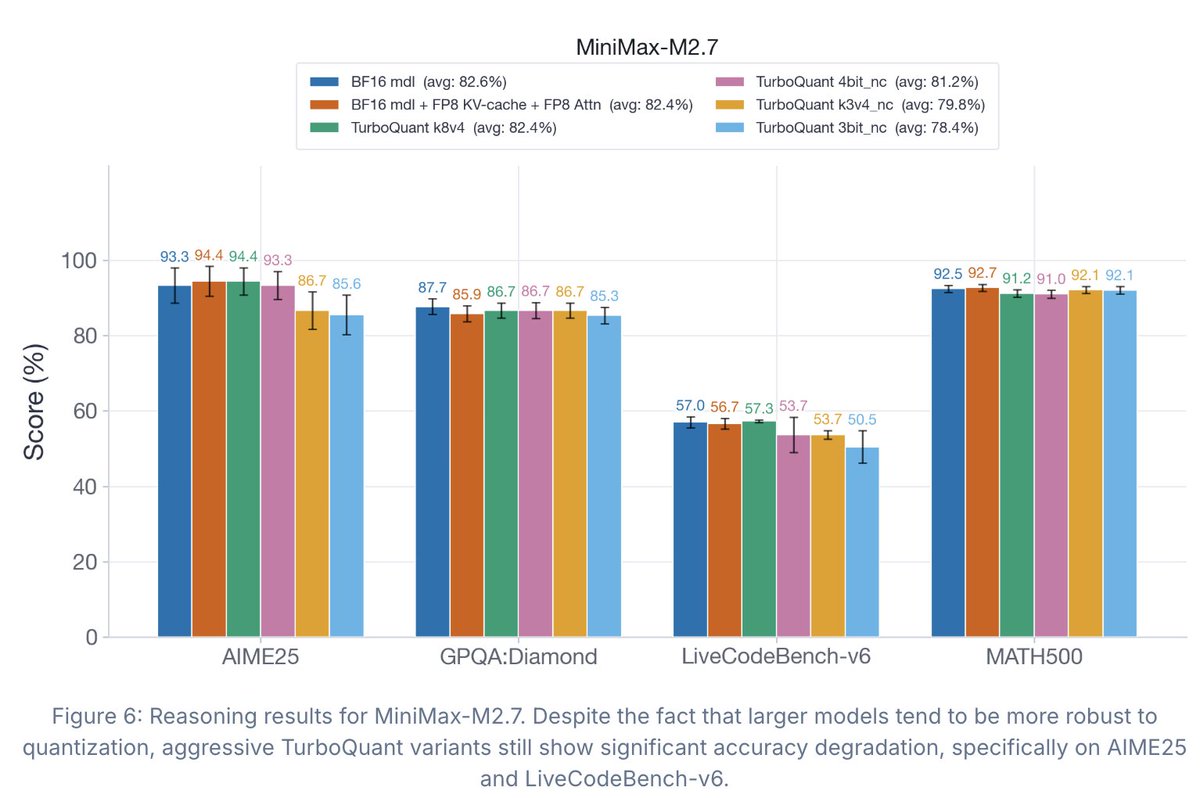
1
1
15
1,984
Steffen Röcker retweeted

May 11
For more details and results check the full blog at vllm.ai/blog/turboquant .
This is joint work with @mgoin_ and Alexandre Marques from @RedHat_AI and @vllm_project .
1
2
18
1,435
Steffen Röcker retweeted
May 11
TurboQuant has drawn a lot of attention recently, but the accompanying evals didn't tell the full story.
So we ran what I believe is the first comprehensive study of TurboQuant: where it helps, where it falls short, and how it impacts accuracy, latency, and throughput.
Findings:
11
52
322
80,548
Steffen Röcker retweeted

May 8
I think @antirez ds4.c is important! I wrote down my thoughts on why I built pi-ds4 and why we need to focus our local model efforts stronger than we do currently. lucumr.pocoo.org/2026/5/8/lo…
15
50
375
30,568



Welcome to DS4, a specialized inference engine for DeepSeek v4 Flash. github.com/antirez/ds4
This project would have been impossible without the existence of llama.cpp and GGML and the work of @ggerganov and all the other contributors. Thanks!
47
218
1,493
197,431
Steffen Röcker retweeted

May 7
>new AMD Instinct MI350P GPU
>CDNA 4
>PCIe Gen 5 x16
>144GB HBM3E 4TB/s
>native MXFP6 and MXFP4 support


Don’t just scale AI. Scale ROI.
AMD Instinct MI350P PCIe cards deliver 144 GB of HBM3E memory and up to 2299 teraFLOPS (at MXFP4) in a drop-in, air-cooled card built for standard servers.
That’s how you scale AI at maximum ROI without redesigning your data center.
Interested in drop-in AMD Instinct MI350P PCIe cards? See the specs at the link: bit.ly/4exiAg2

17
13
372
38,854