
Housing and media researcher, advocate, designer, builder, writer; possibilist. Contributor writer @Sightline. #MovableDwelling
Joined February 2009
- Tweets 51,278
- Following 4,838
- Followers 4,938
- Likes 39,197
6,820 Photos and videos










Pinned Tweet

Mar 30
new micro-essay: "You Must Change Your Feed" — how and why to take back your Facebook feed from the algorithm, and find what you actually want to want. Plus related life tips from #Rumi and #Rilke. Latest in my #Possibilist newsletter:
possibilist.tmccormick.org/p…
1
191
Tim McCormick retweeted

Seventy years apart in San Francisco

25
51
901
566,544
Tim McCormick retweeted

Apr 2
Haha I vibe code products with twitter :D
10
4
704
160,518
Tim McCormick retweeted
Apr 3
pleased to discover that what I've been developing lately for research/writing is in many ways fairly close to that of #AndrejKarpathy — legend, inventor and term-coiner of #VibeCoding! [my prototype system: #Toposcope]
x.com/i/status/2039805659525…
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1
121
Tim McCormick retweeted
Mar 30
new micro-essay: "You Must Change Your Feed" — how and why to take back your Facebook feed from the algorithm, and find what you actually want to want. Plus related life tips from #Rumi and #Rilke. Latest in my #Possibilist newsletter:
possibilist.tmccormick.org/p…
1
191
16 Dec 2025
new post: Halfway Homegoing — travels across the US and Canada since August
[in my Possibilist newsletter, Dec 16th]. An update from four months on the road possibilist.tmccormick.org/p…. #HalfwayHomecoming #OCanada


2
2
453
Mar 30
new micro-essay: "You Must Change Your Feed" — how and why to take back your Facebook feed from the algorithm, and find what you actually want to want. Plus related life tips from #Rumi and #Rilke. Latest in my #Possibilist newsletter:
possibilist.tmccormick.org/p…
1
191
Tim McCormick retweeted
Mar 9
however, as a rhetorical/advocacy/political matter, seems like "You/we need to use careful #GeneralEquilibrium analyses" needs some branding, messaging, naming help! What are, what might be keen terms, strategies for promoting such 🤔? Eg #BigPicture, holistic, "community-level"?
1
57
Tim McCormick retweeted
Mar 7
the case here & in @_brianpotter's #TheOriginsOfEfficiency, I find insufficient. Industrialization *has*
worked, large-scale: eg Sears #KitHomes, Levitt, Soviet #Plattenbau, Singapore’s HDB, Japanese housing, Sweden #MillionProgramme, #MovableDwelling; what worked, how now?
1
1
917
Tim McCormick retweeted
Mar 5
this dream of the '90s is alive in Portland: Rose City Coffee Co. went 24-hr this fall while I was away, as if to my prayers. Literally the owner described goal as bringing back what she'd loved as teen in 90's PDX (like me): opb.org/article/2025/12/12/t….
x.com/i/status/2029371232546…


Mar 5

Before COVID-19, every US city had at least one dumpy, Bohemian coffee shop that was in an old house full of rooms like this. For the price (~$1) of the worst cup of coffee you've ever had, you and your friends could just hang out there all night, vibing out.

1
8
446
Mar 2
plenty of foreground political issues are fairly senseless from a policy standpoint, but have powerful logic for cultural, political-symbolic reasons. Eg #SaulAlinsky's #RulesForRadicals, Rule 12: Pick the target, freeze it, personalize it, and polarize it
x.com/i/status/2028563575334…

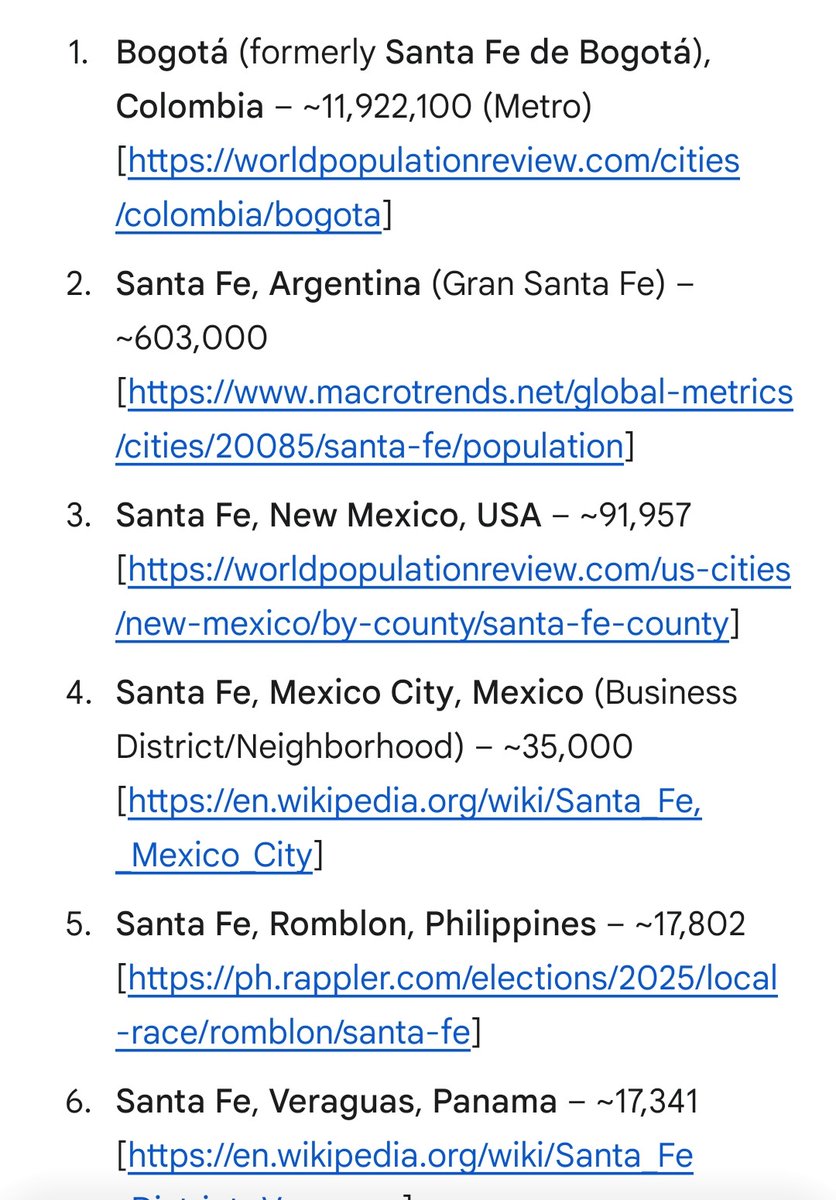
Singling out data centers over water use is bizarre. California’s data centers *combined* use ~2,300 acre-feet of water per year, that’s ~.006% of all CA water use and <1% of the water use by all golf courses in the state.
3
128
Tim McCormick retweeted
Mar 1
"Here, in an atmosphere of private opulence and public squalor, the private goods have full sway.
—#JohnKennethGalbraith. #TheAffluentSociety (1958). archive.org/details/affluent…
x.com/i/status/2028176457307…
Mar 1

In San Francisco, we have 30 freestanding toilets that are available for free public use.
They cost the city $14M last year, and recorded 750,000 visits, ~$19 per visit.

Community note
The $14.1M funded the Pit Stop program (60 toilets at 30 sites), including staff and needle disposal. Their 2026 budget has already been cut to $5.7M, including $4M in rollover funds from last year.
The 750K visits were also for the last 9 months, not for the entire year.
sfstandard.com/2025/04/07/pub…
1
1
1
865
Tim McCormick retweeted

Feb 25
"Dignified Technology" is the framework that I came up with to guide how I build creative tools, including an AI writing tool that won't write for you:
• Framework overview
• Applying "Dignified Technology" to Hermes
• @claudeai Agent Skill for auditing your own product
4
3
50
5,772
Feb 22
"Until more permanent housing comes online, cities may have little choice but to treat RVs not as an anomaly, but as part of the housing landscape". Why not consider #MovableDwelling permanently part of the landscape, given unique fitnesses & advantages?"
x.com/i/status/2024935226229…
Was happy to join Kate Rogers @CNBC to discuss RV homelessness in the Bay Area. The story is offers an inside look into some RV residents and efforts in SJ and SF to move ppl into housing. cnbc.com/2026/02/20/how-rvs-…
1
3
155
Feb 21
"There is after all only one Nature, and…even in our human zone of it, the cheerful zone of reason and freedom of choice, still there are traces, in the passions, of bleak and irresistible Necessity."
— #Goethe, in his advertisement for novel #ElectiveAffinities (1809)

60
Feb 17
"I'm out for presidents to represent me/…
I'm out for dead presidents to represent me…"
For #PresidentsDay: Nas, "The World Is Yours," on Illmatic, 1994, a greatest-ever rap track, video; & model intertextual work, referencing eg Scarface 1932 and 1983
m.youtube.com/watch?v=e5PnuI…



80
Tim McCormick retweeted

Feb 14
Crazy that Mike Davis used this same facade as the cover of City of Quarts 30 years ago

5
42
354
15,828
Tim McCormick retweeted

There’s a window in LA’s Metropolitan Detention Center through which people held hostage by ICE can wave at protestors outside. It’s haunting
589
2,358
19,667
168,504
Feb 13
the antifascist message of "You Can't Go Home Again", title phrase of 1940 #ThomasWolfe novel: "atavistic yearnings [for] the dark ancestral cave…One saw traces of it everywhere…many disguises, many labels. Hitler, Mussolini, Stalin…America had it too"
archive.org/details/youcantg…


64
Tim McCormick retweeted

Feb 9
🚨 Holy shit… Stanford just published the most uncomfortable paper on LLM reasoning I’ve read in a long time.
This isn’t a flashy new model or a leaderboard win. It’s a systematic teardown of how and why large language models keep failing at reasoning even when benchmarks say they’re doing great.
The paper does one very smart thing upfront: it introduces a clean taxonomy instead of more anecdotes. The authors split reasoning into non-embodied and embodied.
Non-embodied reasoning is what most benchmarks test and it’s further divided into informal reasoning (intuition, social judgment, commonsense heuristics) and formal reasoning (logic, math, code, symbolic manipulation).
Embodied reasoning is where models must reason about the physical world, space, causality, and action under real constraints.
Across all three, the same failure patterns keep showing up.
> First are fundamental failures baked into current architectures. Models generate answers that look coherent but collapse under light logical pressure. They shortcut, pattern-match, or hallucinate steps instead of executing a consistent reasoning process.
> Second are application-specific failures. A model that looks strong on math benchmarks can quietly fall apart in scientific reasoning, planning, or multi-step decision making. Performance does not transfer nearly as well as leaderboards imply.
> Third are robustness failures. Tiny changes in wording, ordering, or context can flip an answer entirely. The reasoning wasn’t stable to begin with; it just happened to work for that phrasing.
One of the most disturbing findings is how often models produce unfaithful reasoning. They give the correct final answer while providing explanations that are logically wrong, incomplete, or fabricated.
This is worse than being wrong, because it trains users to trust explanations that don’t correspond to the actual decision process.
Embodied reasoning is where things really fall apart. LLMs systematically fail at physical commonsense, spatial reasoning, and basic physics because they have no grounded experience.
Even in text-only settings, as soon as a task implicitly depends on real-world dynamics, failures become predictable and repeatable.
The authors don’t just criticize. They outline mitigation paths: inference-time scaling, analogical memory, external verification, and evaluations that deliberately inject known failure cases instead of optimizing for leaderboard performance.
But they’re very clear that none of these are silver bullets yet.
The takeaway isn’t that LLMs can’t reason.
It’s more uncomfortable than that.
LLMs reason just enough to sound convincing, but not enough to be reliable.
And unless we start measuring how models fail not just how often they succeed we’ll keep deploying systems that pass benchmarks, fail silently in production, and explain themselves with total confidence while doing the wrong thing.
That’s the real warning shot in this paper.
Paper: Large Language Model Reasoning Failures


265
1,396
6,884
967,492
Feb 10
my #MobileBookshelf, brought into cafe to take a #shelfie: current, recent, prospective (print) reading—vs ebook which mostly now by text-to-speech is how I read, incl many of these—new refreshed selection from library in exile/storage. photos.app.goo.gl/EtXVkSM7zQ…
#LibraryShelfie ⛵

1
74
Tim McCormick retweeted
Feb 6
or to build more broadly on that point, what might be the best, synoptic, metric for 'scoring' the social value of a housing unit/opportunity created? that'd take into account how soon it occurs, total costs and benefits to all parties? upon this rock…
x.com/i/status/2019586600049…

What's the NPV of the social cost of delay?
1
99