
24 Photos and videos










Willie Neiswanger retweeted

13h
Together with my co-founders Michael @MichaelPoli6, Stefano @Massastrello and Armin @athmsx, I am excited to announce @RadicalNumerics is emerging from stealth with a $50M seed round to build general biological intelligence.
We’re also sharing an early preview of our new model Omnii, the most powerful genome language model to date.
Omnii preview link:
radicalnumerics.ai/blog/radi…
At Radical Numerics, our mission is to master the code of life, and to drive the frontier of biological AI for both design and defense.
This is our dual mandate, which comes from something our own team helped make possible.
Our founding team trained Evo and Evo 2, the largest biological AI models (40B params) trained on DNA sequences. Trillions of tokens across all of life, from microbes to mammals. It’s fully open source, and created the field now known as generative genomics.
Last year, scientists used Evo to generate the world’s first complete genome from scratch using AI. Turns out it was a bacteriophage—a type of virus. It functioned in the real world, and in this case it was harmless. But for us, it was a clear turning point.
It showed that AI is no longer just analyzing biology. It is on the cusp of generating functional lifeforms. Eventually, AI will have the power to design and control life itself.
That should make all of us incredibly excited, and incredibly uneasy. (Anyone can design DNA with a new function, and have it synthesized and delivered, like something from Amazon Prime).
The same technology that will help us cure cancer is the very technology that might create the next global pandemic, or worse, allow the creation of bioweapons that can wipe out populations.
We believe these forces are inseparable. If you work on the frontier of biology, you have to build technology to safeguard it from its misuse. Existing biosecurity tools are sorely losing the arms race, relying on outdated “have I seen this exact thing before?” style algorithms.
We founded Radical Numerics to turn the tide.
And we can’t do that by training on textbooks and natural language. We must understand the language of biology from the raw physical data itself, to reason across every molecule and modality, from DNA to proteins.
The next frontier for AI goes far beyond chatbots or video generators to models that can understand and engineer life.
Today, we’re previewing Omnii, which is already far surpassing Evo 2, and will continue improving as we scale and add new modalities (training now).
1. For human health, Omnii can read and write whole genomes (more on writing later). It’s state of the art (SOTA) on detecting causal variants for disease, and can rank Alzheimer's mutations zero-shot. We’re partnering with a diagnostics company to use Omnii for early cancer detection (pancreatic and multi-cancer).
2. For defense, Omnii is SOTA at detecting AI-generated pathogens. We benchmarked existing detection tools, and they simply can’t detect the AI-generated ones (“deepfake viruses”). We’re partnering with a US national lab to pilot Omnii for detecting the next pandemic, both natural and AI-generated.
We have a data center full of Blackwells in construction now to build the most powerful biological AI models ever. This mission takes a new kind of AI lab that can actually scale on physical, biological data: new alignment research (mid/post training), scaling long context, building out mech interp teams to dissect what these models learn, new architectures and systems designs, all from the ground up.
Our team is made up of AI researchers and scientists from top labs and institutions (e.g. Stanford, MIT, Google DeepMind), but more importantly, we all share the belief that this is the most important challenge of our lifetime. If you feel similarly, we are hiring. We aim to bring the brightest minds in AI and science together to save lives.
Thanks to our partners on this journey, led by Emergence Capital @emergencecap, with Obvious Ventures @obviousvc, Triatomic @TriatomicCap
, and Patrick Collison @patrickc. Our advisors include Eric Horvitz @erichorvitz, CSO of Microsoft, Chris Re @HazyResearch of Stanford, George Church @geochurch of Harvard, and Andrew Weber @AndyWeberNCB, former Assistant Secretary of Defense for Nuclear, Chemical and Biological Defense Programs.
Fortune article: fortune.com/2026/06/15/exclu…
Jobs: radicalnumerics.ai/join-us

82
242
736
1,007,414

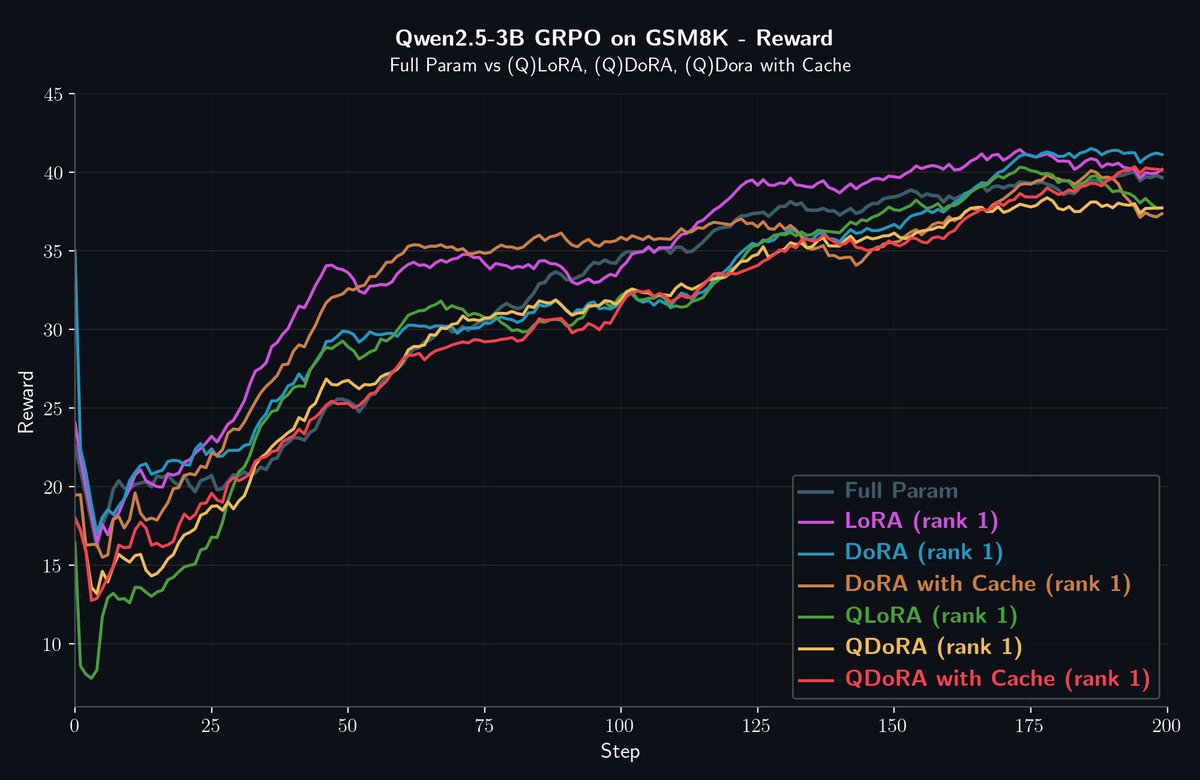
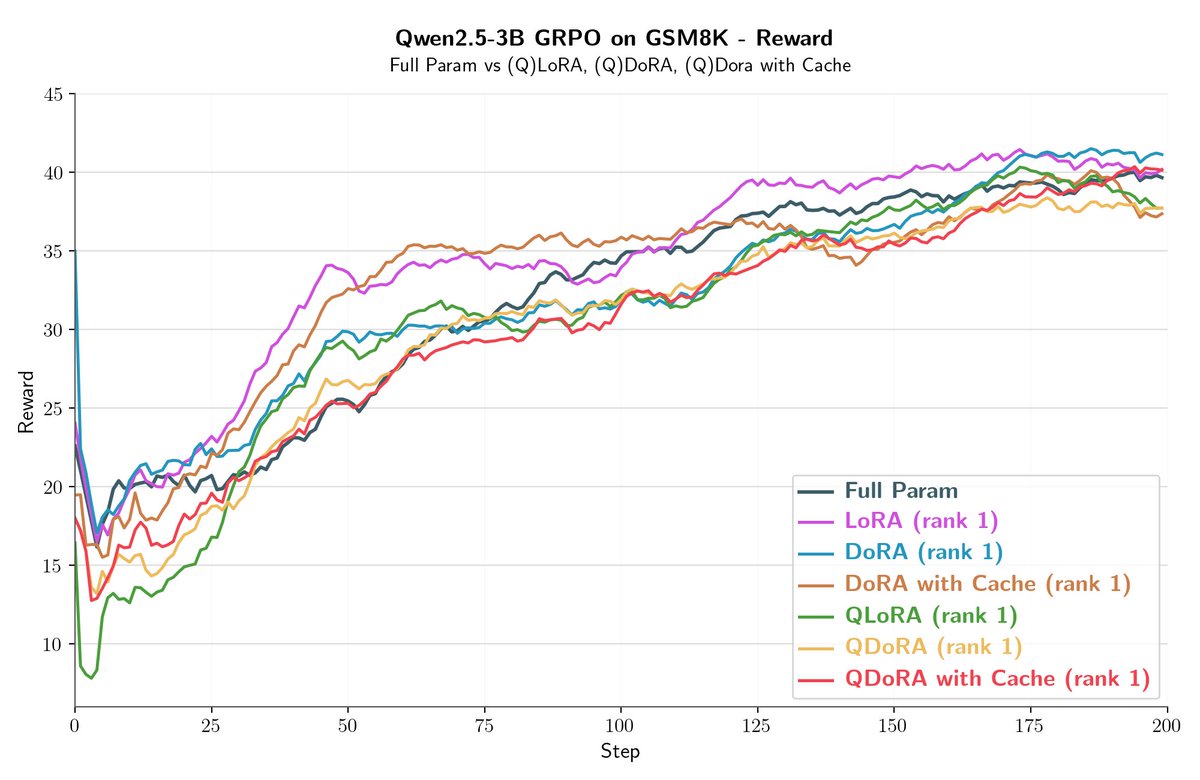
Tina proved that LoRA can match or surpass full-parameter RL. Tora builds directly on that result, turning it into a full framework.
Built on torchtune, it extends RL post-training to LoRA, QLoRA, DoRA, and QDoRA under one interface with GRPO, FSDP, and compile support. QLoRA and QDoRA enable 4-bit RL with stable rewards, while DoRA-Cache speeds rollouts by 2–4× under the same setup.
Tora establishes a clean, scalable baseline for LoRA in RL post-training.
⮕ 𝐥𝐢𝐧𝐤 𝐛𝐞𝐥𝐨𝐰

Tina: Tiny Reasoning Models via LoRA
LoRA-RL tuned 1.5B models on curated reasoning data, achieving 20% gains and 43% Pass@1 (AIME24) at $9 total cost. Outperforms full-parameter RL on DeepSeek-R1-Distill-Qwen-1.5B.
- LoRA-based RL yields better performance with less compute.
- best checkpoints align with format-reward transitions, not accuracy plateaus.
- efficiently adapts reasoning structure while preserving core model knowledge.
3
29
301
29,629
Willie Neiswanger retweeted

24 Oct 2025
Announcing 🔭✨Hubble, a suite of open-source LLMs to advance the study of memorization!
Pretrained models up to 8B params, with controlled insertion of texts (e.g., book passages, biographies, test sets, and more!) designed to emulate key memorization risks 🧵

2
41
131
49,868

8 Oct 2025
It was great to see @thinkymachines LoRA w/o Regret blog, which connects nicely to our work on Tina (LoRA for RL).
For wider use, we’re releasing a clean implementation of RL with LoRA, DoRA, QLoRA/QDoRA, plus speedups & more, across models from 1.5B–32B.
Nice work @UpupWang!
8 Oct 2025

We now know that LoRA can match full-parameter RL training (from x.com/thinkymachines/status/… and our Tina paper arxiv.org/abs/2504.15777), but what about DoRA, QLoRA, and more?
We are releasing a clean LoRA-for-RL repo to explore them all.
github.com/shangshang-wang/T…
2
1
23
3,566
Willie Neiswanger retweeted

12 Jun 2025
Sparse autoencoders (SAEs) can be used to elicit strong reasoning abilities with remarkable efficiency.
Using only 1 hour of training at $2 cost without any reasoning traces, we find a way to train 1.5B models via SAEs to score 43.33% Pass@1 on AIME24 and 90% Pass@1 on AMC23.

10
55
498
72,349

Textual steering vectors can improve visual understanding in multimodal LLMs!
You can extract steering vectors via any interpretability toolkit you like -- SAEs, MeanShift, Probes -- and apply them to image or text tokens (or both) of Multimodal LLMs.
And They Steer!

1
14
53
10,226
Willie Neiswanger retweeted

7 May 2025
Is LoRA (Low Rank Adaptation) relevant in 2025 for reasoning models?
I recently read "Tina: Tiny Reasoning Models via LoRA (arxiv.org/abs/2504.15777)", and it made me pause for a moment: when was the last time I heard someone excitedly talk/write about LoRA?
LoRA (Low-Rank Adaptation) was one of the most influential fine-tuning methods in the earlier LLM boom (as you may remember, I wrote about it a lot in recent years). The idea is simple but effective: avoid full model updates and instead inject a small number of trainable parameters for downstream tasks. This drastically reduces memory and compute costs. But in the age of ever-larger instruction-tuned models coupled with well-working distillation techniques (like popularized by DeepSeek-R1 etc), LoRA seemed to become more irrelevant recently.
What about LoRA work for developing reasoning models?
This paper tackles exactly that question. Instead of the usual supervised fine-tuning or instruction distillation pipeline, the authors use LoRA with reinforcement learning (RL) to improve reasoning capabilities. Specifically, they fine-tune a 1.5B base model using LoRA adapters while applying RL on reasoning benchmarks.
Their baseline model is DeepSeek-R1-Distill-Qwen-1.5B, which is a model already fine-tuned for reasoning tasks. (I wish they started with the base Qwen-1.5B model; but this way, I guess they have more comparisons with other methods that further trained the DeepSeek-R1-Distill-Qwen-1.5B.)
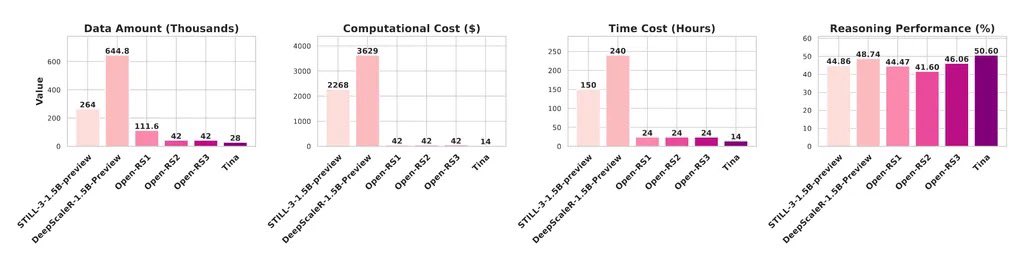
From there, the authors ran experiments across datasets, learning rates, LoRA ranks, and RL algorithms. Their best-performing model was trained on just 7k examples and cost just $9 to train. Even with hyperparameter sweeps and multiple ablations, the entire study cost just $526.
So, how well does LoRA work?
The top half of the results figure (highlighted in blue) compares models trained with LoRA-based RL versus standard RL (i.e., no LoRA). On every benchmark (AIME24, AIME25, AMC23, MATH500, GPAQ, Minerva), LoRA outperforms the regular RL baseline when applied to the same starting model.
Insights from ablations
1) Surprisingly, the best-performing model came from the smallest dataset: just 7k examples from Open-RS.
2) The classic LoRA rank 16 emerged as the sweet spot, but ranks 8 and 32 also worked well.
3) It's nice that they included the recent Dr. GRPO (I recently discussed it in my latest Ahead of AI blog). It substantially reduces training time by length-normalizing rewards and addressing issues in GRPO
Bottom line:
Reasoning is certainly an interesting use case, and it's interesting (and a bit surprising) that LoRA does so well here. It might also be the first case where I've seen LoRA coupled with RL, which is another interesting aspect.
LoRA certainly peaked in popularity 1-2 years ago, and more people now consider (more expensive) full-parameter updates (based on anecdotal perception); there's still a place for LoRA and LoRA-like methods.
Let's not forget that one of the key advantages of LoRA is that it doesn't modify the underlying base model. This is key in applications where you either have lots of specialized use cases or lots of customers. For example, instead of storing 100 1B full-parameter tuned models, it would be much cheaper to store a 32B model with 100 sets of LoRA weights.

26
171
976
63,109
Willie Neiswanger retweeted

24 Apr 2025
Presenting our spotlight paper on LLMs for decision making at @iclr_conf, Apr 25, 10–12:30PM, Hall 3 #113. Come say hi!
27 Feb 2024

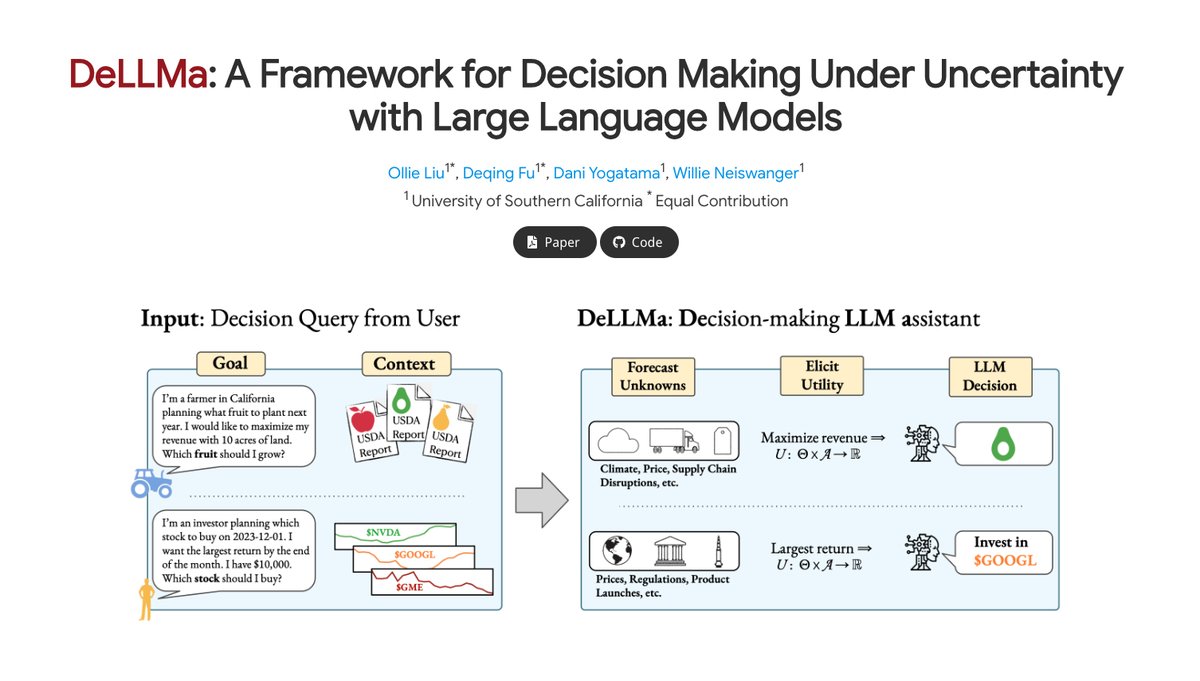
New Preprint Alert! 📢
Classical decision theory has helped humans make rational decisions under uncertainty for decades. Can it do the same for Large Language Models?
We present DeLLMa (“dilemma”), a Decision-making LLM assistant.
🔗 DeLLMa.github.io
1/🧵
5
23
4,231
Willie Neiswanger retweeted

23 Apr 2025
Tina: Tiny Reasoning Models via LoRA
"the best Tina model achieves a >20% reasoning performance increase and 43.33% Pass@1 accuracy on AIME24, at only $9 USD post-training and evaluation cost (i.e., an estimated 260x cost reduction). Our work reveals the surprising effectiveness of efficient RL reasoning via LoRA."

13
135
751
61,494
Willie Neiswanger retweeted
23 Apr 2025
😋 Want strong LLM reasoning without breaking the bank? We explored just how cost-effectively RL can enhance reasoning using LoRA!
[1/9] Introducing Tina: A family of tiny reasoning models with strong performance at low cost, providing an accessible testbed for RL reasoning. 🧵

2
66
400
43,909
19 Feb 2025
An awesome set of resources on LLM reasoning and test-time compute, compiled by @UpUpWang — check it out!
19 Feb 2025
🔍 Diving deep into LLM reasoning?
From OpenAI's o-series to DeepSeek R1, from post-training to test-time compute — we break it down into structured spreadsheets. 🧵

10
1,406
Willie Neiswanger retweeted

10 Jan 2025
[1/11] Many recent studies have shown that current multimodal LLMs (MLLMs) struggle with low-level visual perception (LLVP) — the ability to precisely describe the fine-grained/geometric details of an image.
How can we do better?
Introducing Euclid, our first study at improving MLLM’s LLVP. We show that with proper architecture & training choices, even small MLLMs can learn strong and generalizable LLVP, surpassing the best proprietary models!

1
5
20
3,438
Willie Neiswanger retweeted

6 Jan 2025
excited to share our first scientific foundation model release in collab with @willieneis @olliezliu and more from USC.
6 Jan 2025

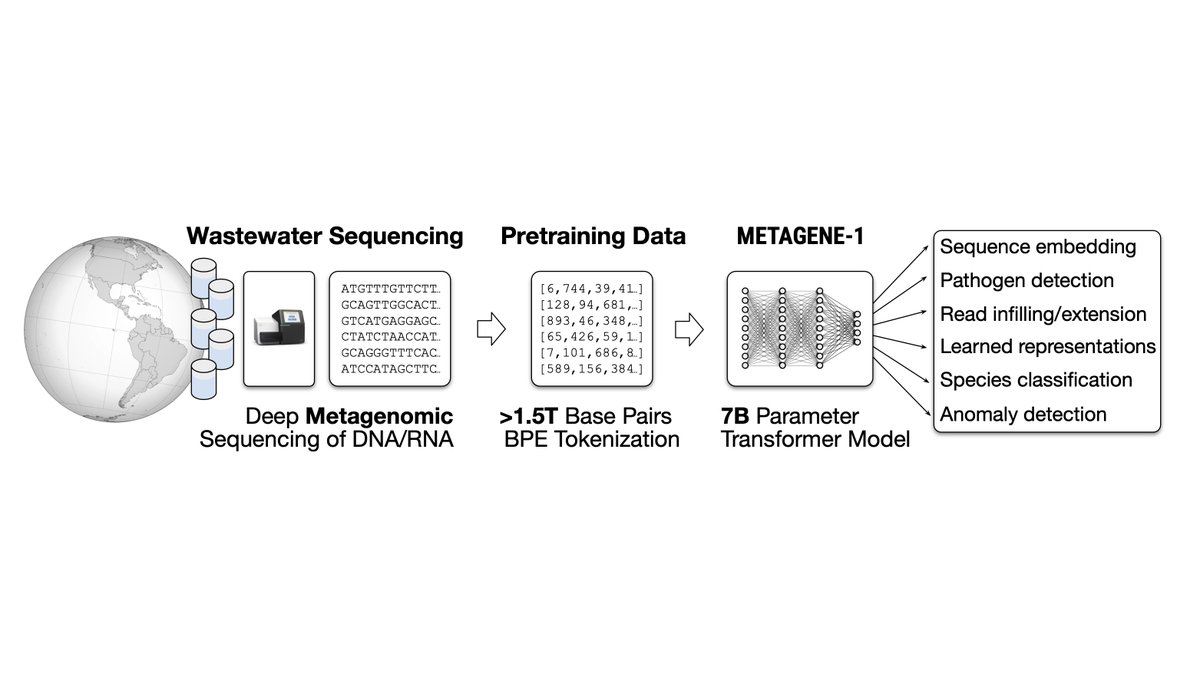
Releasing METAGENE-1: In collaboration with researchers from USC, we're open-sourcing a state-of-the-art 7B parameter Metagenomic Foundation Model.
Enabling planetary-scale pathogen detection and reducing the risk of pandemics in the age of exponential biology.
4
5
93
6,899
6 Jan 2025
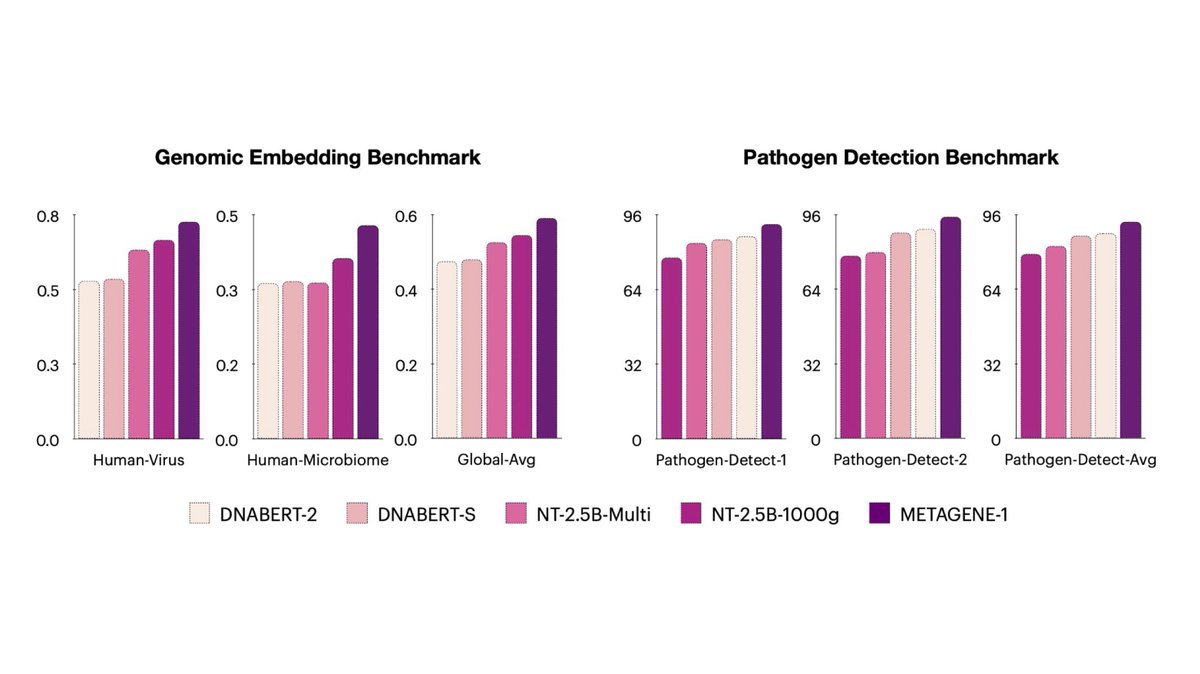
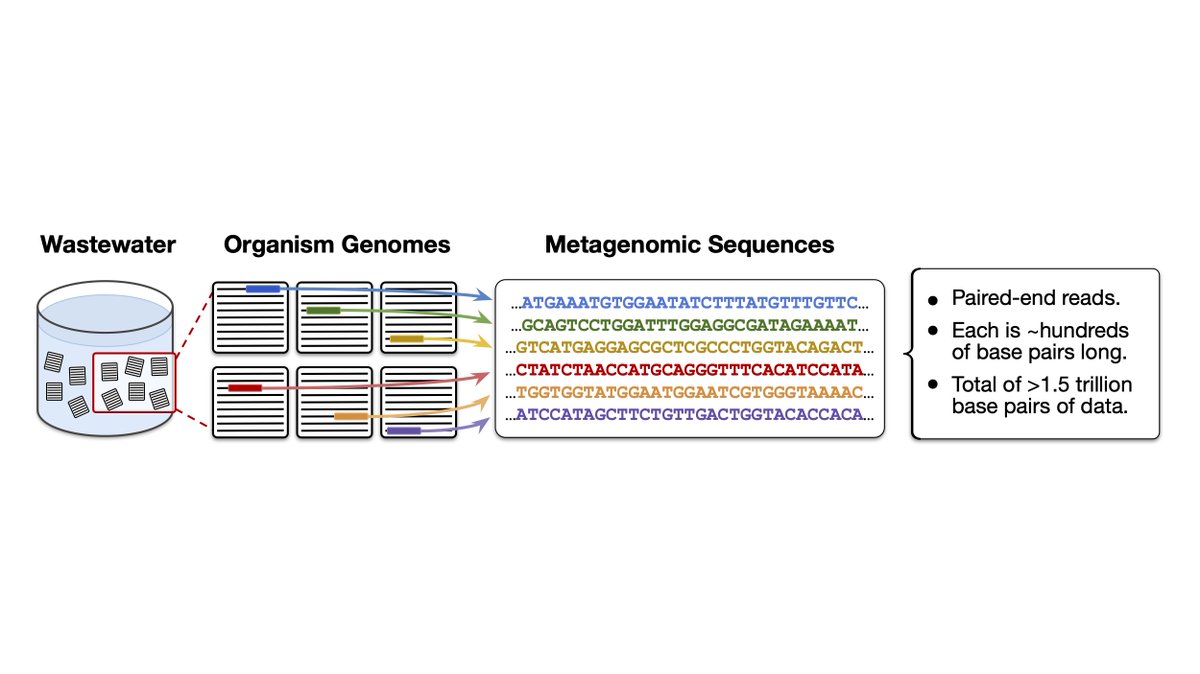
Excited to release METAGENE-1, a 7B parameter metagenomic foundation model, built to aid in pathogen detection & pandemic monitoring. Pretrained on 1.5 trillion base pairs of DNA/RNA sequenced from wastewater.
A collab w/ @USC, @PrimeIntellect, & the Nucleic Acid Observatory. 🧵
4
23
116
13,365
6 Jan 2025
We leverage the ecosystem of modern LLM tooling—in tokenization, model architecture, training, infra, etc—for performance and extensibility. METAGENE-1 is standardized & easy to use.
Hugging Face: huggingface.co/metagene-ai
Github: github.com/metagene-ai
1
5
481
6 Jan 2025
Our paper also contains an in-depth discussion on safety when releasing metagenomic models.
s/o to great coauthors @olliezliu @samsja19 @johannes_hage @UpupWang @_jason136, & jefftk
Looking for collaborators to build on this with us — please reach out!
metagene.ai/
2
7
729