
Joined August 2022
- Tweets 435
- Following 133
- Followers 54
- Likes 1,439
103 Photos and videos
















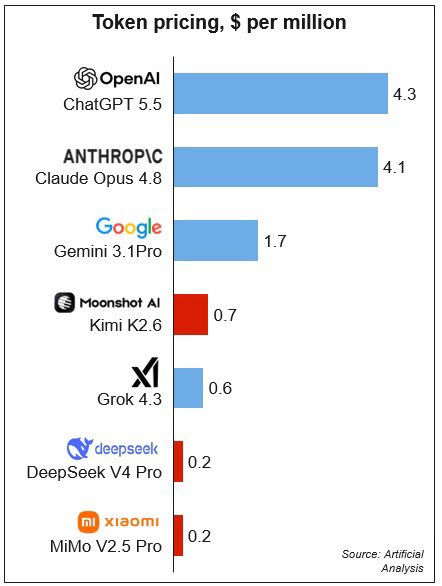
open source models demonstrating “your margin is my opportunity” in 4k
you are gambling with every prompt anyways for output, might as well go cheap with more tries.
Jun 8

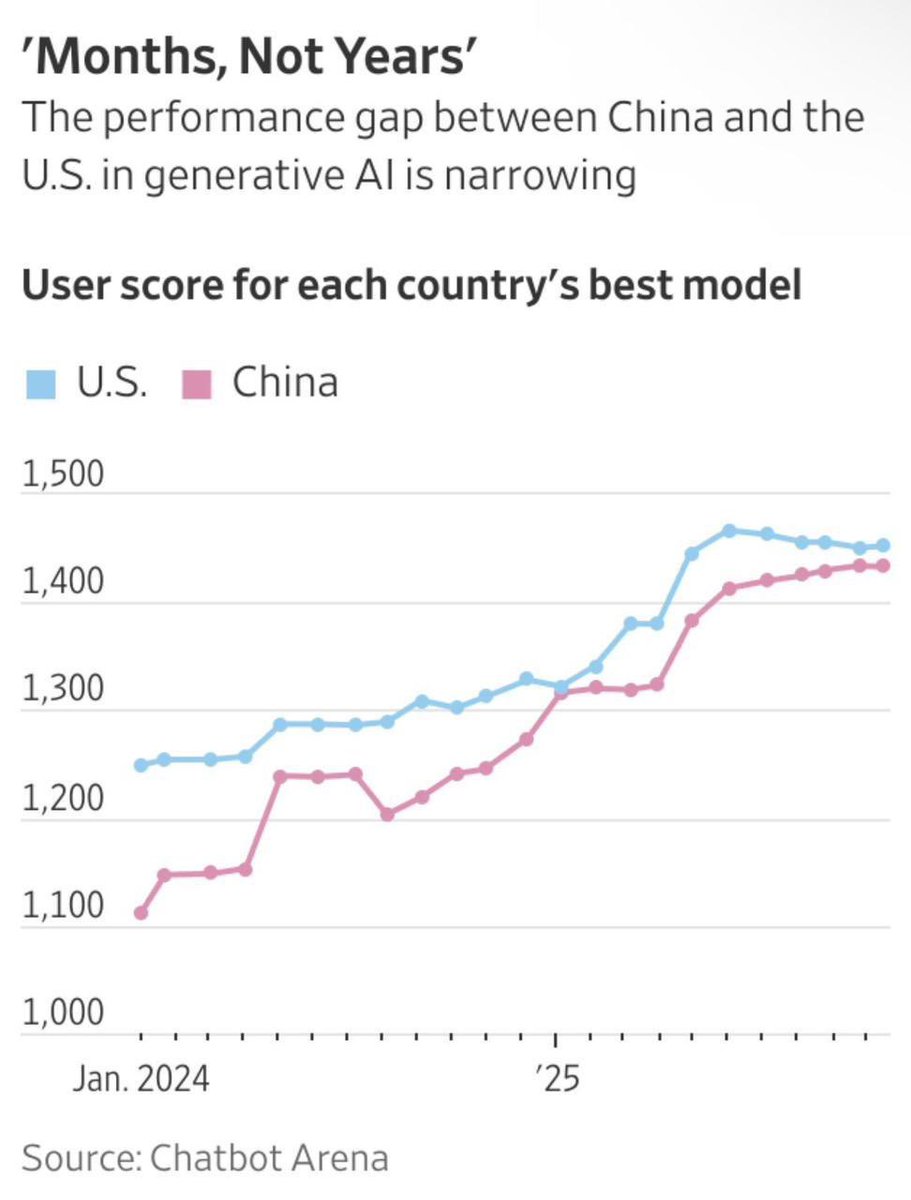
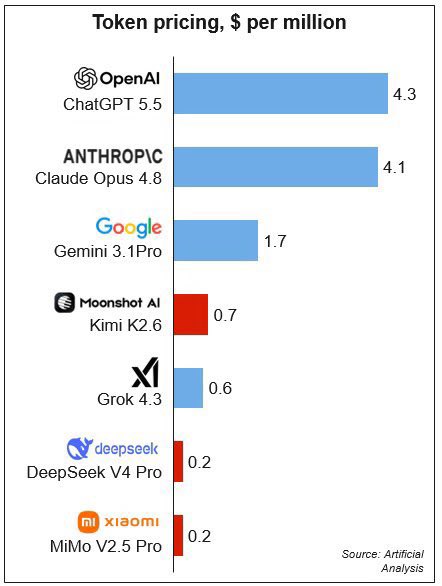
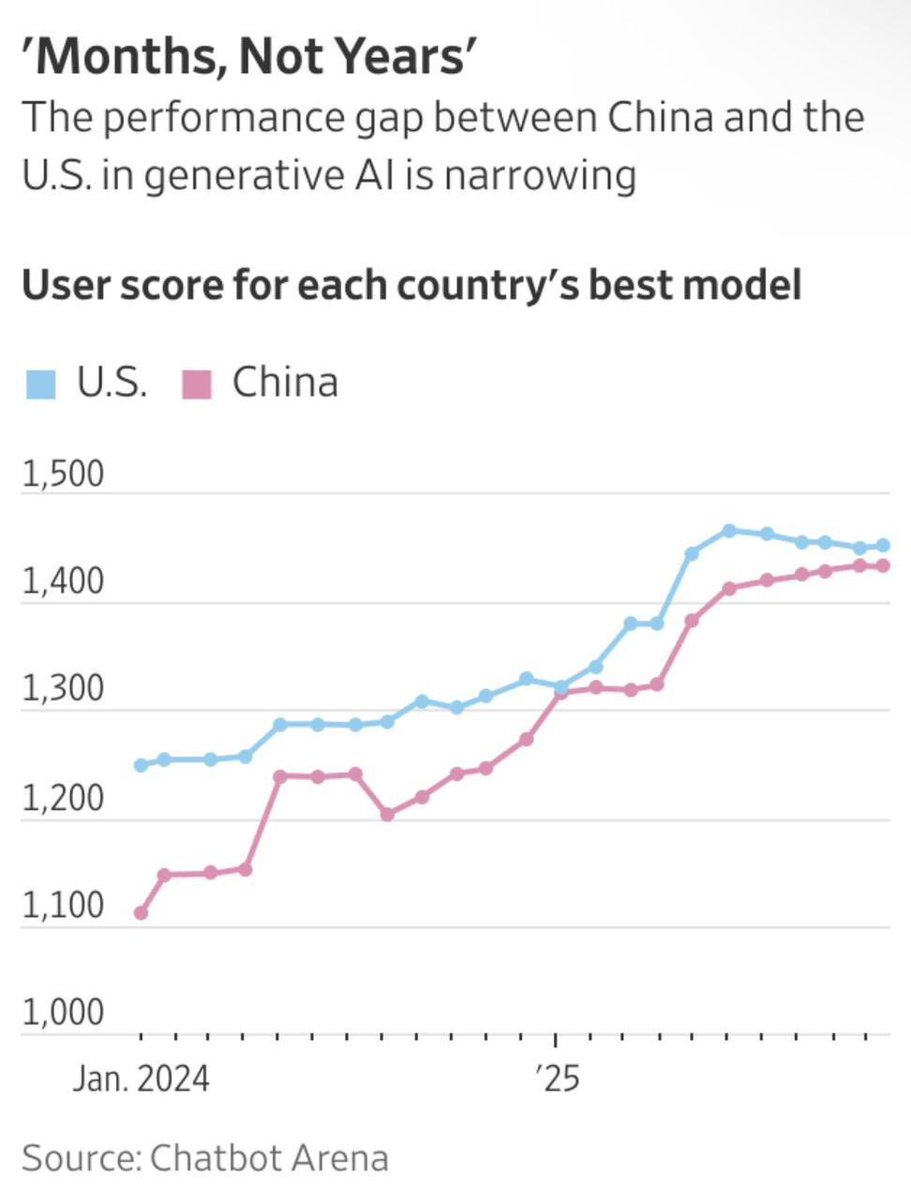
Econ101:
When the red line catches the blue line, if the cost of the blue products/companies don’t go down to be the same cost of the red products/companies, the red companies will win.
3
29
591
🧩@Gradient_HQ Puzzle Mastermind!
Play from now til June 6th 1AM EDT!
🏆 Top 10 Participants will receive Quiz Mastermind on Discord!
Rules:
- username must match DC username
- play as many times & anytime you want during event duration
./ puzzle here: jigsawplanet.com/?rc=play&pi…

17
11
66
2,571
locally operated AI agents will be the closest thing to taste like ubi if it’s not already in being pursued right now.
saving rates in america has evaporated once again, need additional hands and value add for income
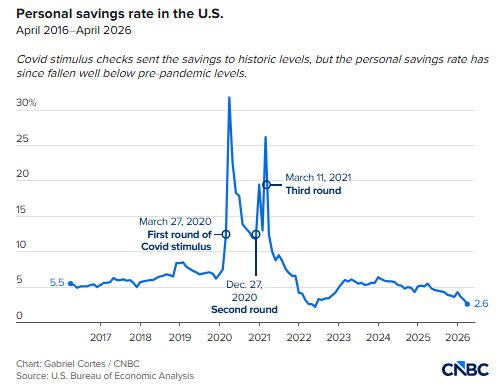

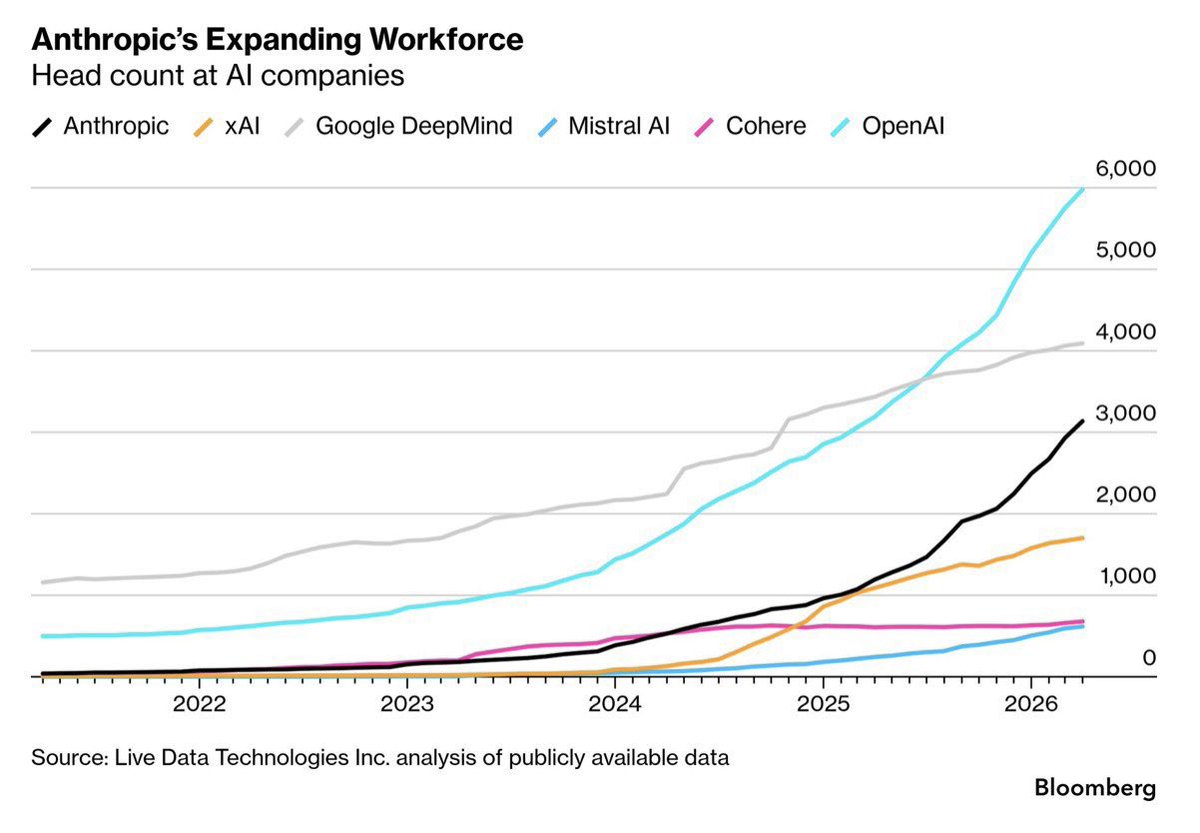
“AI will replace all human jobs, everyone will be useless”
meanwhile many of the fear mongering labs selling this narrative are workforcemaxxing with their headcount.
there’s some truth to having repetitive work eliminated but alot of it is probably greatly exaggerated.
2
3
32
462
“AI will replace all human jobs, everyone will be useless”
meanwhile many of the fear mongering labs selling this narrative are workforcemaxxing with their headcount.
there’s some truth to having repetitive work eliminated but alot of it is probably greatly exaggerated.
1
5
34
936
M3 autonomy in PostTrainBench just dusted everyone else.
If M3 didn’t beat in raw outperformance it beat in cost per intelligence. It’s number 3 only behind Opus 4.7 and GPT 5.5, everyone after is not close.
1M context too, can’t wait to see where autonomy is at eoy 😆
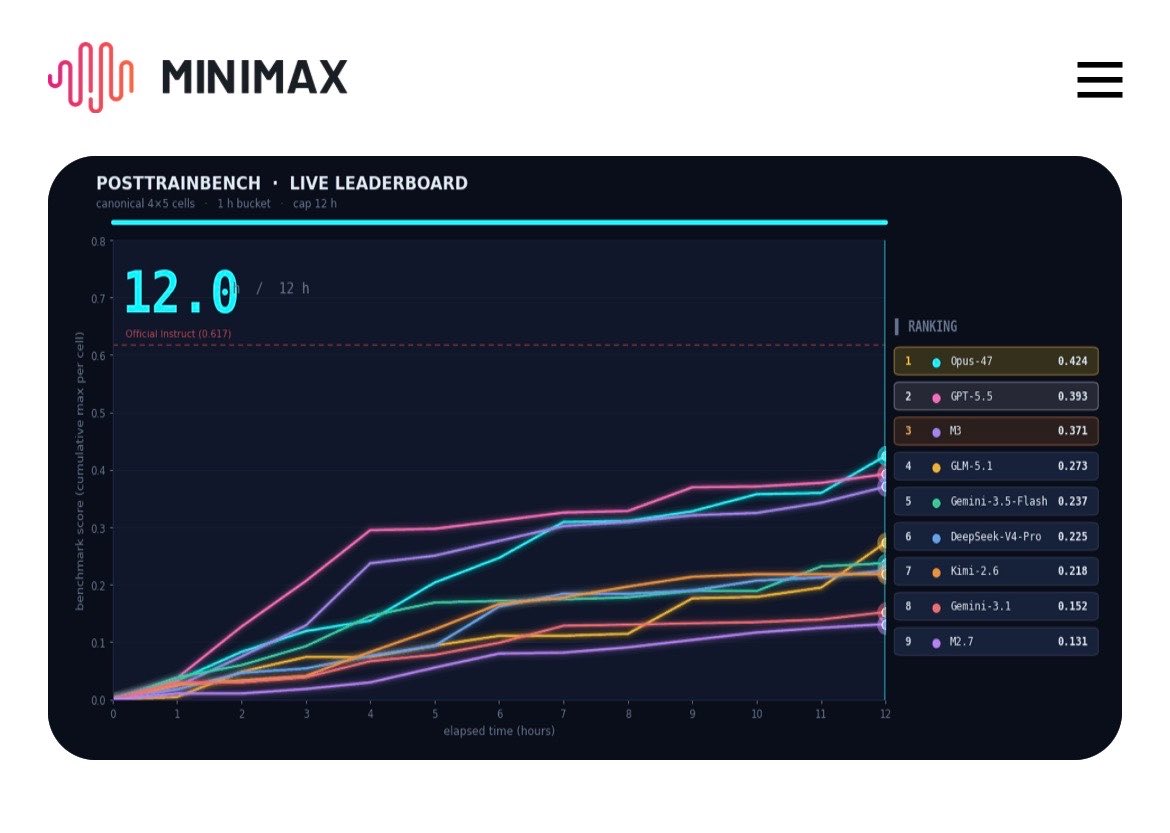

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

1
1
32
919
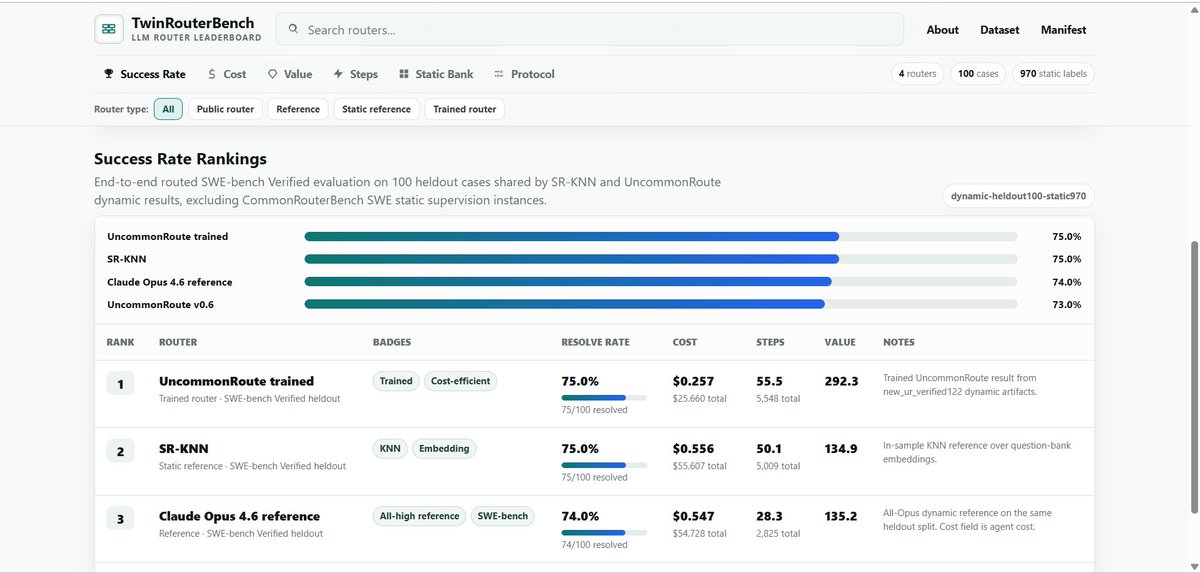
Uncommonroute trained router matches Claude Opus 4.6 in SWE-bench Verified evaluation.
In TwinRouterBench you test realism agentic trajectories and the results are staggering:
Uncommonroute Trained vs Claude Opus 4.6
75/100 vs 74/100 (matched in resolution)
$25.66 vs $54.73 (53% cost saving with Uncommonroute trained)
Models cost more now with advanced reasoning and agentic tasks, time to save to get same quality at a better price.
May 26

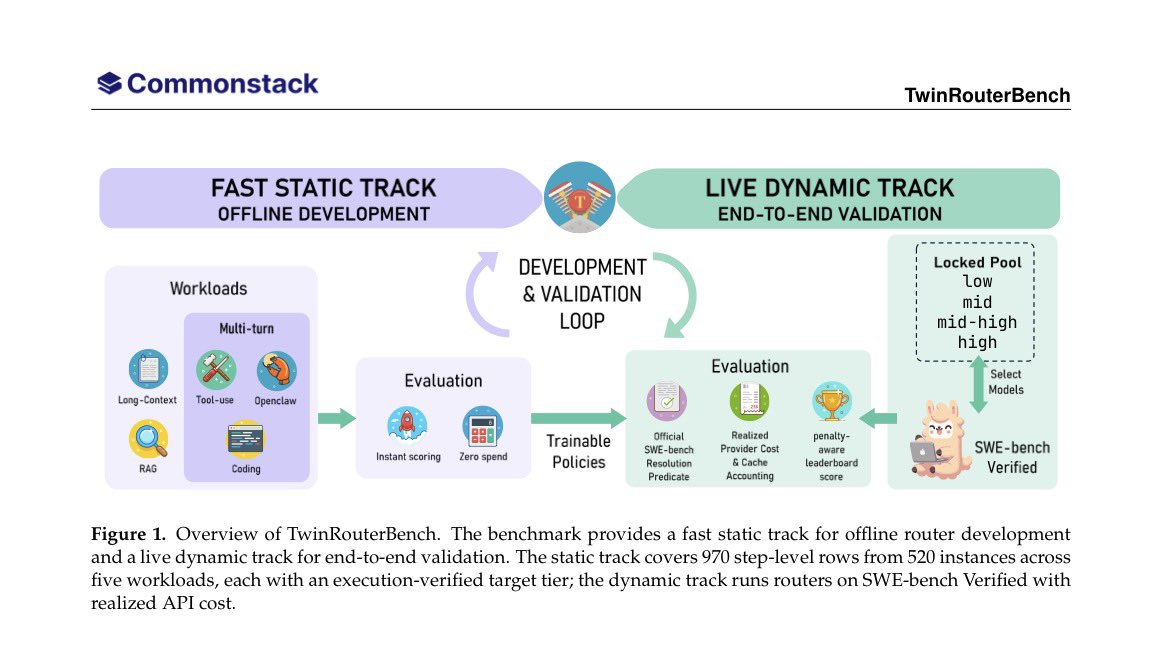
TwinRouterBench is a new benchmark designed for step level routing in long horizon, multi turn agentic workflows. Differing from traditional routing benchmarks that focus on single prompt routing, TwinRouterBench evaluates how well a "router" can choose the right model for each individual step of a complex task.
It implements dual tracks evaluation between fast development and realistic testing:
Track 1: Static Track (Fast Offline Track)
• 970 router visible prefixes from 520 trajectory instances.
• Covers 5 diverse benchmarks: SWE-bench, BFCL, mtRAG, QMSum, and PinchBench.
• Each example comes with an execution verified target tier (cheapest sufficient model tier).
• Uses deterministic scoring (based on tier correctness, trajectory membership, and token cost) no LLM judges needed.
Ideal for: training routers, rapid iteration, and cheap offline evaluation.
Track 2: Dynamic Track (Live Validation Track)
• Full evaluation harness on SWE-bench Verified (500 tasks).
• Reports results on a 100 case heldout split (disjoint from static data).
• Router must choose a real model from a locked pool at every step.
• Measures real outcomes: Official task resolution success, Actual API spend (real dollars), Includes failure penalties for unresolved tasks
By providing both a Static (fixed) and Dynamic (flowing) track, TwinRouterBench solves the problem where a router looks good on paper but fails when the agent actually has to live with its choices.
TwinRouterBench is set for the agentic era where every step is measured in routing vs just one shot prompt testing. This benchmark targets the realism distortion by testing routing within the actual context of multi step, stateful agent trajectories.
6
4
43
1,000

May 26
We never end.
May 24
Hello everyone. X is removing it’s X communities feature on May 30th
I started building this community in January 2025 and it’s been a wonderful experience to meet nearly 5,000 of you inside of our Open Intelligence Lounge
@Gradient_HQ will continue to update it’s research efforts on main page and on Discord with other activities as well: discord.gg/gradientnetwork
Let’s stay in touch and there will be more to come!
2
20
i was the fourth member of lounge (**wink wink** 😏)
anyways join @Gradient_HQ discord as well here:
discord.gg/gradientnetwork
see you guys there!
May 24
Hello everyone. X is removing it’s X communities feature on May 30th
I started building this community in January 2025 and it’s been a wonderful experience to meet nearly 5,000 of you inside of our Open Intelligence Lounge
@Gradient_HQ will continue to update it’s research efforts on main page and on Discord with other activities as well: discord.gg/gradientnetwork
Let’s stay in touch and there will be more to come!
8
3
53
812
May 14
SBF was out here aping OpenAI back in 2018 with Alameda writing a 500k check
@SBF_FTX is literally a generational VC player, got in Anthropic and OpenAI very early days.
His legacy would be so different if funding sources were from proper avenues

4
82
Bennett Bui ./ retweeted

May 6
Run Claude Code with Commonstack in 4 steps:
- generate an API key
- set 4 environment variables
- run claude
- /status to verify
Set it up now in 5 minutes with @alex_mirran.
8
21
41
3,565
gradient bringing open infra into the agentic era.
coordination, privacy and accessibility have been strong research efforts from the lab.
happy to see gradient with other leading companies and labs powering agent infrastructure.
./ time to roll @Gradient_HQ

May 4

1/ Today we’re launching the HOL Partner Program.
Cohort One brings together 30 signed partners, including XMTP, GoDaddy, and DSR, to help shape open infrastructure for AI agents.
Registries. Payments. Privacy. Security. Communication. Standards.
The agent stack is forming now.
17
19
64
4,282

Bennett Bui ./ retweeted

May 1

Apr 30

This GPT Image 2 prompt is going insanely viral right now.
“Redraw the attached image in the most clumsy, scribbly, and utterly pathetic way possible. Use a white background, and make it look like it was drawn in MS Paint with a mouse. It should be vaguely similar but also not really, kind of matching but also off in a confusing, awkward way, with that low-quality pixel-by-pixel feel that really emphasizes how ridiculously bad it is. Actually, you know what, whatever, just draw it however you want.”


153
47
532
57,884
xAI has a lot of underutilized capacity that could be used as a white labeling service for the neoclouds who haven’t finished building their infra, fulfill those signed commitments to boost rev
also distributed training is music to my ears cc @Gradient_HQ

May 3

NEWS: xAI is reportedly using just 11% of its 550,000 NVIDIA GPUs, while Meta and Google squeeze 43-46% out of theirs.
According to a report from The Information, xAI's massive Memphis and Colossus GPU clusters, packed with H100s and H200s including liquid-cooled setups, are running at only around 11% utilization. That works out to roughly 60,000 active GPUs out of the 550,000 installed.
The issue is not unique to xAI. Running hundreds of thousands of GPUs efficiently is one of the hardest challenges in AI today. As clusters scale up, idle time piles up fast and software stacks struggle to keep up.
Meta and Google have invested heavily in their software optimization, hitting 43% and 46% utilization respectively. xAI's distributed training network and software stack are still maturing, leading to longer idle times and bottlenecks in the data pipeline.
xAI is targeting 50% utilization through future infrastructure and software upgrades. The company may also start renting out its GPU fleet as it shifts workloads to hardware better suited for agentic AI tasks.
On top of this, Elon Musk is doubling down on the Terafab project, building in-house silicon and tapping Intel's 14A technology to power the next generation of xAI, SpaceX and Tesla compute needs.
Source: The Information


6
12
59
3,271
Bennett Bui ./ retweeted

May 3
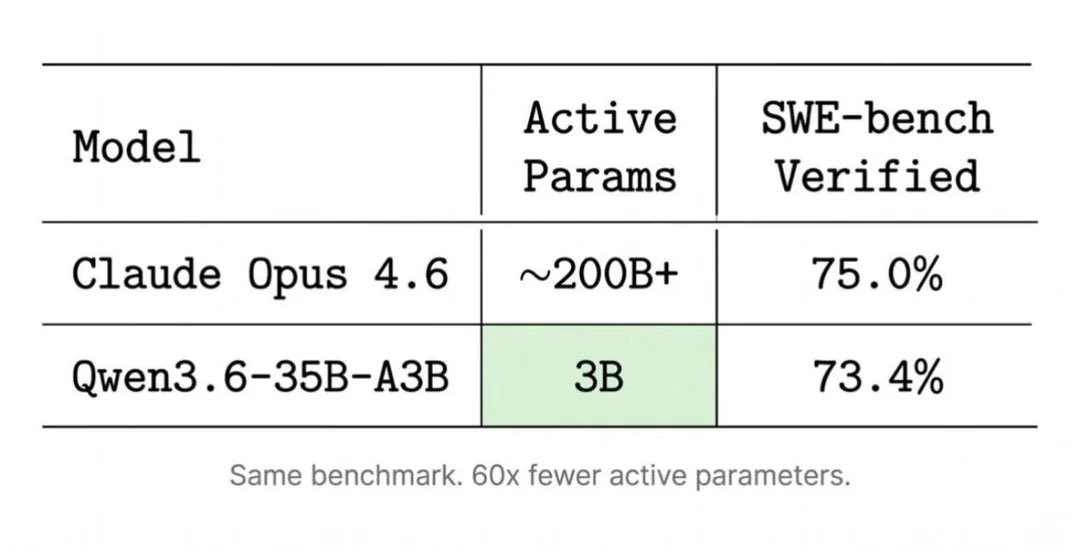
open source models so good now paid fudding in action.
once you have your own machines you don’t need to fully depend your entire system on a few providers blasting you with constant usage limits

3
3
45
571
Bennett Bui ./ retweeted
Apr 28
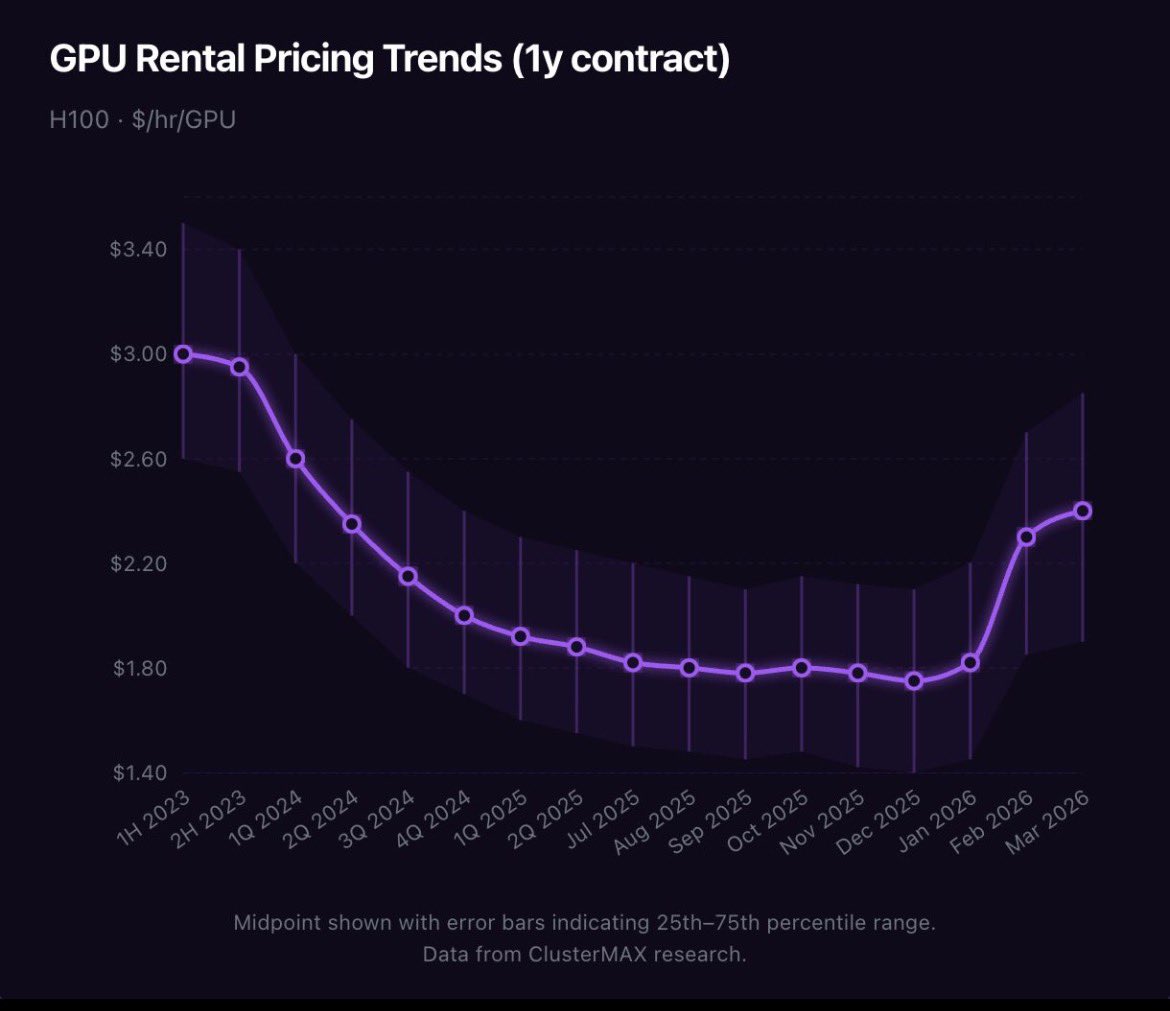
H100s rental prices have risen around 40% in the past 2 quarters
Hovered from $1.70-$1.80 to now $2.35-$2.50. H100s are nearly 4 years old and finding massive demand.
Post training, agents and foundational models can’t get enough compute.
3
4
24
633
Bennett Bui ./ retweeted
Apr 24
DeepSeek-V4-Flash is now live on commonstack.ai
Time to feed your agents!
Apr 24

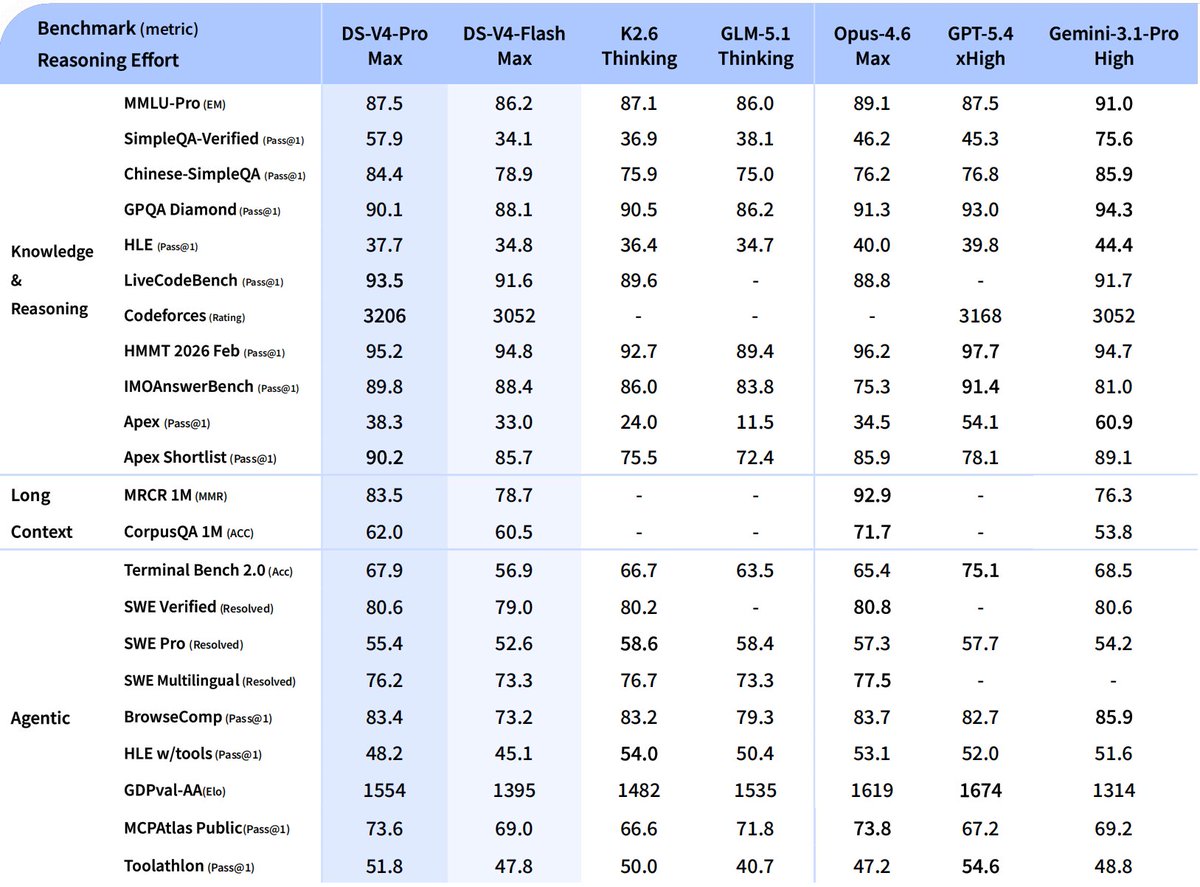
DeepSeek-V4-Flash
🔹 Reasoning capabilities closely approach V4-Pro.
🔹 Performs on par with V4-Pro on simple Agent tasks.
🔹 Smaller parameter size, faster response times, and highly cost-effective API pricing.
3/n
2
5
13
832
Bennett Bui ./ retweeted
Apr 16
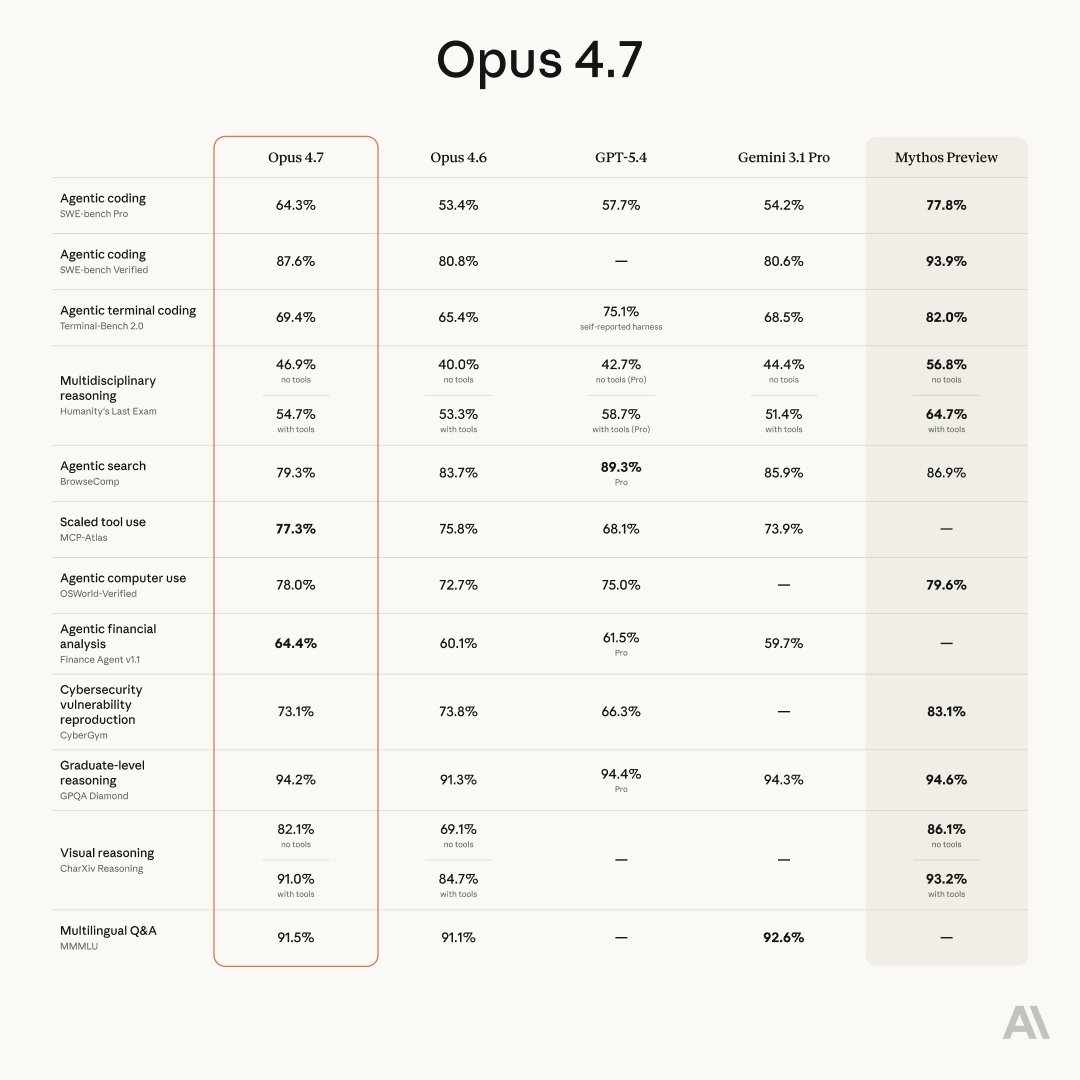
Try Opus 4.7 now, no new API key needed.

Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
ALT Claude Opus 4.7 Benchmarks
5
5
15
763
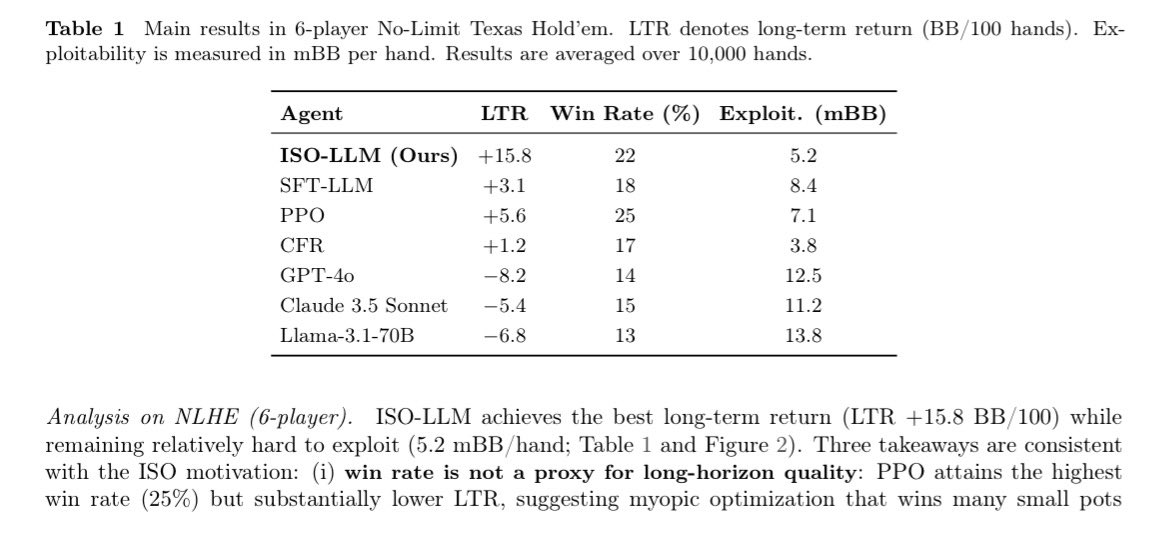
ISO-LLM cashes in profitability with the highest long term return by nearly 3x against PPO (second place) and exploitability at 5.2 mBB, the measurement of how easily an opponent can learn to beat you.
Despite PPO having an overall higher win percentage at 25% vs 22% on ISO, it’s a bread crumb chaser while ISO gets the loaf in LTR of 15.8 vs PPO’s 5.6, getting nearly 3x the bag.
This proves that ISO prioritizes high level strategies that lead to consistent long term success, unlike PPO going for short term gains through the wins of many small, insignificant pots but likely loses very large ones. 💰 @Gradient_HQ
Apr 15
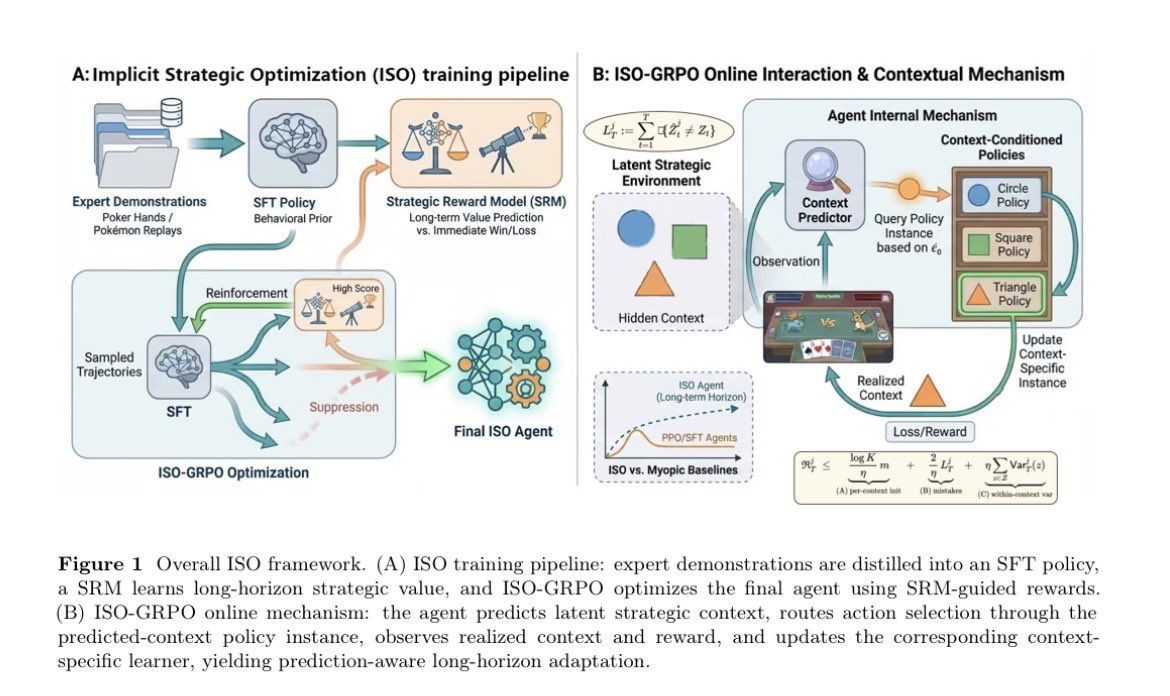
In long horizon adversarial decision making, the strategy comes from constantly evolving decisions in games like No-Limit Texas Hold’em.
Standard RL training focuses on short term rewards mechanisms (short sightedness), which is powerful short term but collapses in a long term strategy (contextual blindness).
ISO (Implicit Strategic Optimization) framework is designed to solve these issues by combining experts with a specialized long horizon reward system:
A - Strategic Reward Model, the agent is trained using an SRM that prioritizes moves with high long term value, essentially teaching it "patience" and strategy.
B - Contextual Mechanism, live interaction, a Context Predictor guesses hidden variables (like an opponent's hidden cards or playstyle). It then "routes" the decision to a specific Context Conditioned Policy optimized for that exact scenario, allowing the agent to adapt its strategy mid-game as new information is revealed.
Combining these, the ISO agent can suppress impulsive, short term gains and instead prioritize high level strategies that lead to consistent long term success. @Gradient_HQ ✍️
2
12
45
2,874