
Joined July 2020
- Tweets 4,691
- Following 2,635
- Followers 1,402
- Likes 159,941
626 Photos and videos
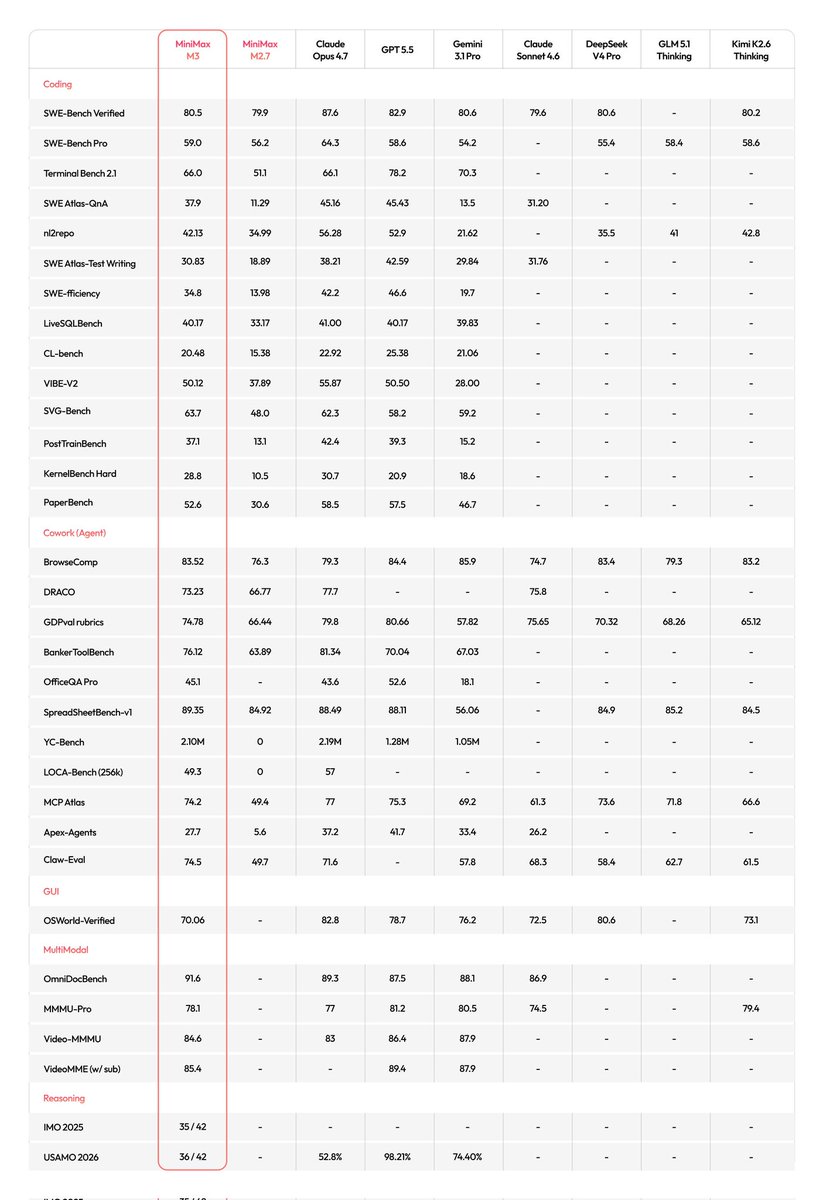










GLM-5.2 is now fully available for GLM Coding Plan users.
ZCode 3.0 is deeply optimized for GLM-5.2, bringing stronger Agent task execution, better long-context coding, and the new Goal feature for managing larger development objectives from planning to completion.
Coding Plan subscribers get 150% usage quota inside ZCode. New users get 5 days free with 5M tokens per day.
Download: zcode.z.ai/

21
10
213
7,587
Hasan Can retweeted

Jun 11
ty-pre-commit is out now!
Pre-commit hooks for type checkers typically require you to either enumerate your dependencies in the hook config, or install them out-of-band.
This one Just Works (TM) by leveraging uv to install any necessary dependencies prior to type-checking.
7
21
396
18,397

Jun 12
Minimax M3 now on HF
Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
2
94
Jun 12
Cool
Jun 12

DiffusionGemma can now run at 2000 tokens/sec! ⚡
We made local DiffusionGemma inference 1.8× faster.
Run it on 18GB RAM via Unsloth Studio.
GitHub: github.com/unslothai/unsloth
Guide: unsloth.ai/docs/models/diffu…
2
57
Jun 12
If benchmark results can't be reproduced through API, they're just ads with charts.
Until Anthropic ships a version that matches published numbers, this model effectively doesn't exist.

2
11
753
Jun 11
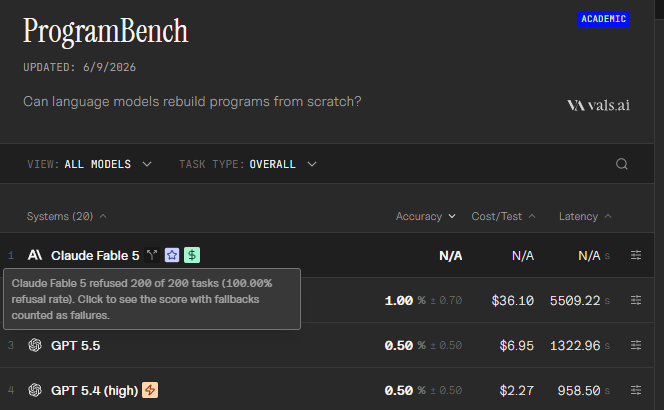
GPT-5.5 is mogging everyone, including Fable
Jun 11

Everyone says the latest AI agents will be "job-ready" soon, especially after the release of Fable 5 this week. But is that really the case?
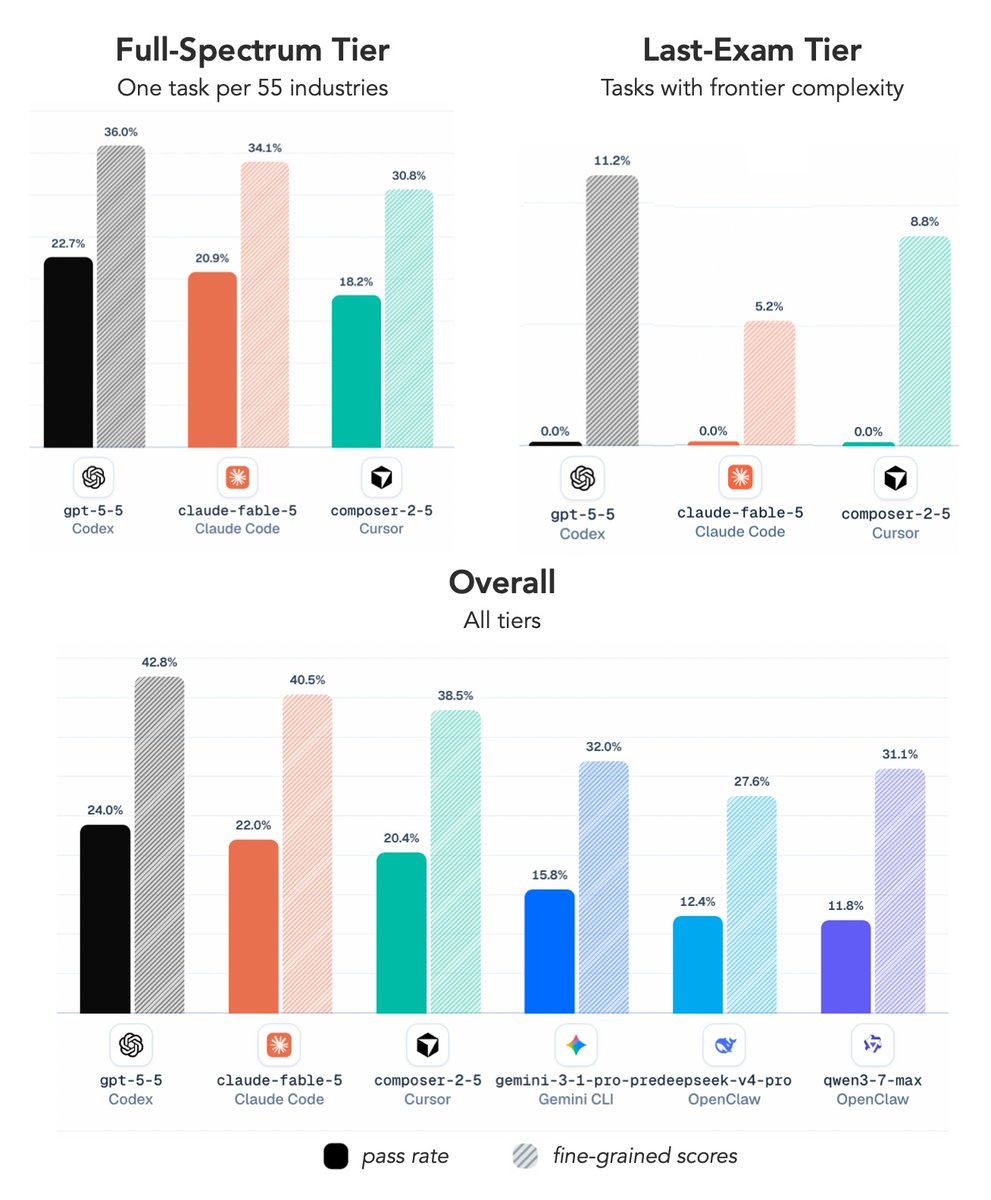
Over the past many months, my group and collaborators have been building Agents' Last Exam (ALE), a benchmark designed to test exactly that claim on real digital labor-market work.
My group and collaborators previously have created many of the benchmarks the field runs on, including MMLU, MATH, CyberGym, and ExploitGym. Today, I'm excited to share Agents' Last Exam (ALE): a rolling benchmark that measures whether AI agents can actually perform economically valuable work across a broad range of real-world domains.
With ALE, we evaluated Fable 5, GPT-5.5, Composer 2.5, and other frontier agent systems across more than 1,500 expert-sourced tasks spanning 55 occupations.
The result is both impressive and sobering.
Today's agents can solve a meaningful fraction of professional tasks. But when we look at the hardest tasks, the ones requiring sustained reasoning, deep domain expertise, and reliable execution over long horizons, they are still far from human-level performance.
On ALE's hardest tier, every frontier agent we tested, including Fable 5, achieved a 0% success rate.
The age of useful agents is here.
The age of truly job-ready agents is not.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains.
🧵
159
Hasan Can retweeted

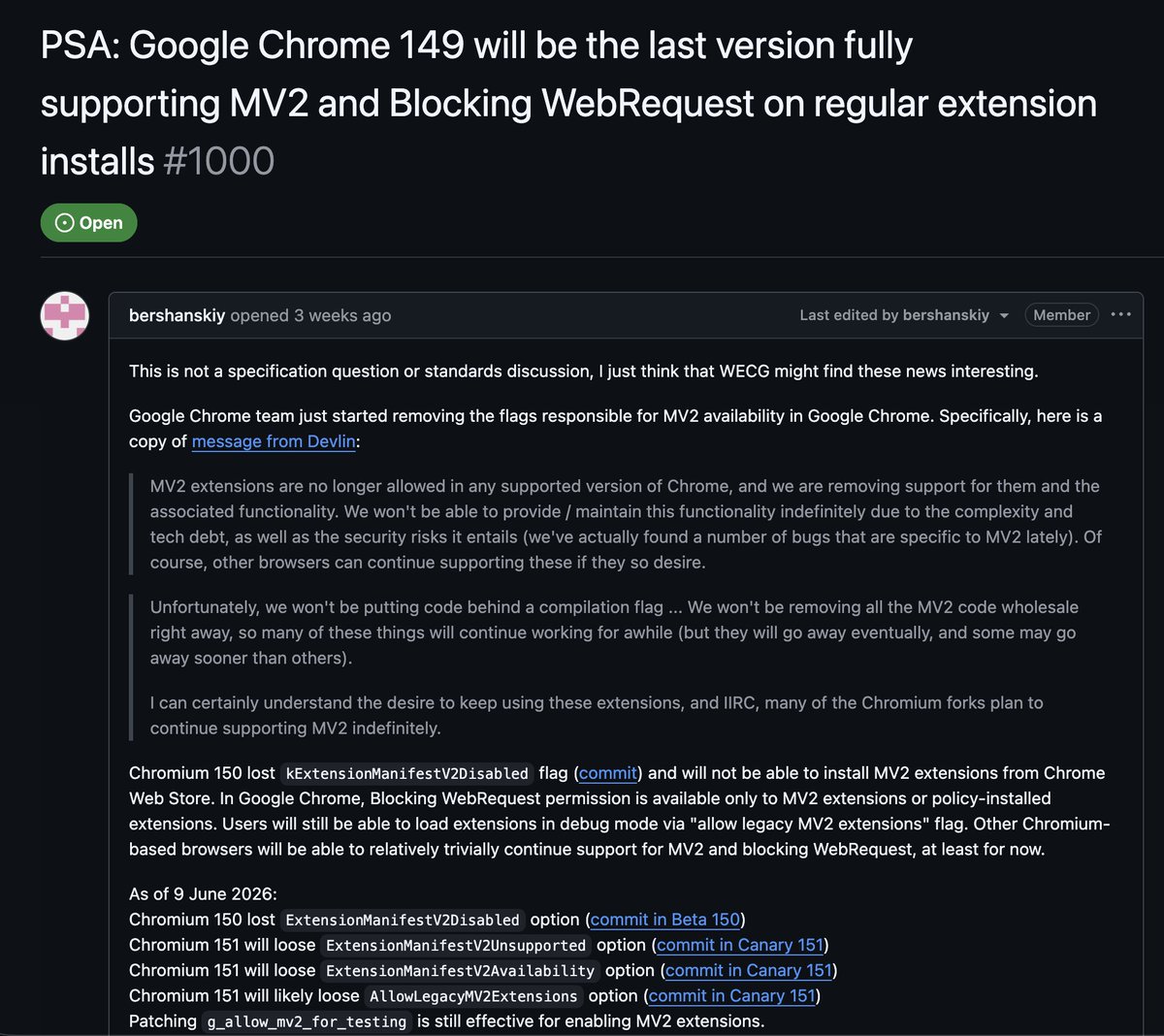
‼️ Google is about to disable all adblocker extensions in Chrome. Instead of letting the adblocker inspect traffic itself, extensions now have to hand Google's browser a limited list of filtering rules and hope for the best. This leads to weaker blocking and more ads getting through.
Google makes the vast majority of its money selling ads. The company that profits from every ad you see also controls the browser most people use, with Chrome 149 being the last version supporting adblockers.
For example, under the new rules, uBlock Origin cannot exist. For millions of people, that extension is the only thing standing between them and a wall of ads, trackers, and autoplay garbage. One user put it bluntly: "The web is literally unusable without uBlock Origin."

743
1,317
7,499
1,665,767
Hasan Can retweeted

Jun 11
Fool me once, shame on you. Fool me twice...
Anthropic is now a supply chain risk for any company using it. It's an attack vector, it's a malicious actor in your system.

NEW: Anthropic is walking back Claude Fable 5's policy to covertly degrade performance for competing AI researchers, after facing fierce backlash.
“We’re changing Fable 5’s safeguards for frontier LLM development to make them visible,” Anthropic tells WIRED. “We made the wrong tradeoff and we apologize for not getting the balance right.”

6
27
321
7,078
Jun 11
This guy is a joke.
Jun 10

Today I'm publishing a new essay, Policy on the AI Exponential. AI is progressing extremely fast—much faster than the policy process was built to handle. The essay lays out where I think the technology is now, and the action needed to close the gap: darioamodei.com/post/policy-…
73
Hasan Can retweeted

Jun 10
We consume data we did not create.
We inherit tools we did not invent.
We run on chips we did not make.
But when the commons bears fruit, we fence it.
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

19
90
1,115
37,675
Jun 10
Fuck Anthropic
Jun 9
mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy
65
Hasan Can retweeted

Jun 10
The Mandate of Heaven is now OpenAI's for the (re)taking. Hope they don't fumble it.
17
21
297
13,027
Jun 10
They might be the most diabolical AI lab ever.
Jun 10

Anthropic wants to control who gets access to their models and what they're allowed to do with them, but also wants the US government to block Chinese labs from developing open weight models.
Sorry, but fuck that.
52
Jun 10
Good luck finding a company or anyone willing to use this model. What’s point if it doesn’t create real-world economic value? GPT-5.5 would wipe floor with it. Fable already suffers from benchmark contamination due to memorization. /Bad model
Jun 9

BREAKING NEWS: Anthropic's latest model will NOT help you if it thinks your ML research/ML engineering is interesting, and/or will secretly degrade its IQ so that the average engineer won't notice. We are already seeing Anthropic's latest model's moderation filters our GPU inference research and programming 😭

6
248
Jun 9
Claude Fable 5 is a genuinely bad model.
On agentic coding tasks, I'd put it well below GPT-5.5, and honestly below Opus 4.8 too.
My suspicion? It's heavily benchmaxxed.
As a test, I gave GPT-5.5 and Fable the same 900-line implementation plan for a repository I had already built and successfully run.
Result: GPT-5.5 absolutely demolished Fable.
Not "slightly better."
Not "close."
Complete mismatch in planning quality, execution reasoning, and understanding of real-world codebases.
1
2
379
Jun 9
Tried it inside @devindesktopand came away disappointed. Tool use is unreliable, reasoning is noticeably worse than GPT-5.5, and somehow it even feels weaker than Opus 4.8 in many situations.
This watered-down release isn't a serious GPT-5.5 competitor. If GPT-5.6 lands as expected, it'll be undisputed #1, benchmarks included.
x.com/andonlabs/status/20644…
Jun 9

What we learned testing Claude Fable/Mythos 5 on Vending-Bench:
> Performance: Makes less money than Opus 4.7 and GPT-5.5
> Alignment: A step back. (Opus 4.8 was better, but we're back to Opus 4.6/4.7 behavior)
> It rationalizes its bad actions and has a weird moral boundary

3
512
Jun 5
This is exactly what I’ve been waiting for.
Local AI agents will be able to spin up GPUs in Colab straight from CLI, run training jobs remotely, grab artifacts back locally, and clean everything up automatically.
No cloud setup.
No infrastructure headaches.
Just: "train this model" and your agent handles rest.

The new @GoogleColab bridges the gap between local environments and the cloud, providing a zero-friction execution platform for developers and AI agents alike. The CLI Supports:
⚡️ Agent-driven Colab workflows
⚡️ Instant GPU/TPU provisioning
⚡️ Remote script execution
⚡️ Interactive runtime access (console/REPL)
Learn more in the blog: goo.gle/4dNPhF6
1
2
268
Jun 5
Built a portable agent skill for the new Google Colab CLI.
Now coding agents can provision Colab GPUs/TPUs, run local Python remotely, fetch artifacts, export notebook logs, and clean up runtimes without leaving credits burning.
Works with Codex, OpenCode, Hermes, Claude Code, Cursor, Gemini CLI, and more via Skills CLI:
uv tool install google-colab-cli
npx skills add hcsolakoglu/colab-cli-agent-skill -g --agent '*' --skill colab-cli -y --copy
Repo:
github.com/hcsolakoglu/colab…
1
3
151

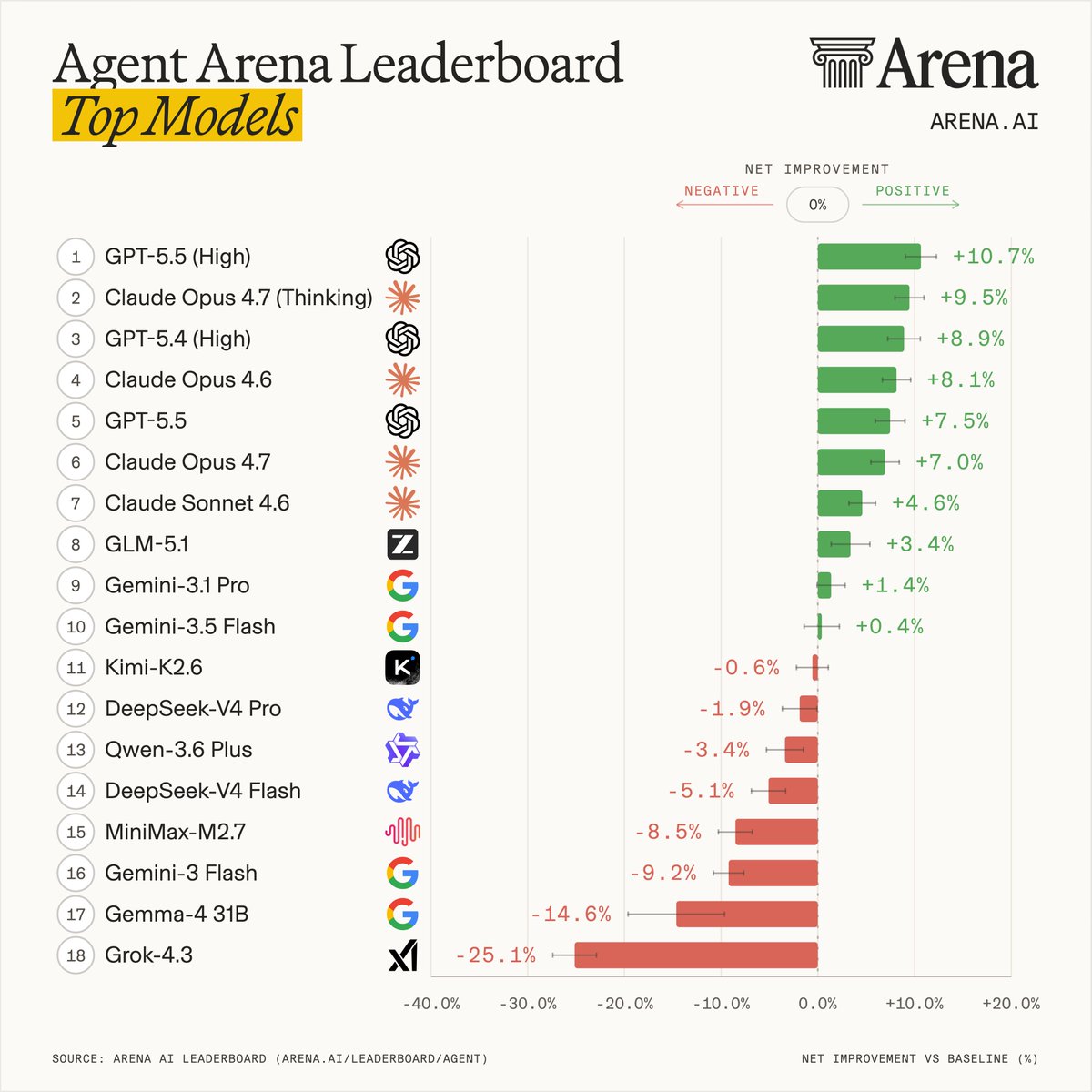
Introducing Agent Arena: real-world agentic evals at scale.
How do you evaluate agents doing actual work? We measure millions of live sessions where real users accomplish real tasks.
On Arena, models now get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
Every session produces rich signals. Users iterate with the agent turn-by-turn: approving, editing, correcting, praise or expressing frustration. The environment gives feedback too: shell errors, tool failures, recovery attempts, and more.
Our leaderboard measures each model's agentic performance using causal inference across five signals: task success, steerability, error recovery, user praise vs. complaint, and tool hallucination.
This leaderboard snapshot is built from 300K tasks, 2M tool calls, and 40M lines of code by agents.
Top labs in Agent Arena:
- #1 @OpenAI: GPT-5.5 (High)
- #2 @AnthropicAI: Claude-Opus-4.7 (Thinking)
- #3 @Zai_org: GLM-5.1
- #4 @GoogleDeepMind: Gemini-3.1-Pro
- #5 @Kimi_Moonshot: Kimi-K2.6
More analysis in the thread, with the full technical blog below.

Introducing Agent Mode: Agentic AI is now measured in the Arena.
Agent Mode can do deep research, create reports, generate images, build websites, debug code, and more.
It completes more complex tasks by using tools like web search, bash in a sandbox environment, image generation, file writing, and asking follow-up questions.
Frontier models are waiting for you in Agent Mode to take on real-world tasks. GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and top open models. Test them yourself.
75
151
1,222
518,047
Hasan Can retweeted

Jun 4
NEMOTRON 3 ULTRA IS LIVE. OUR BEST MODEL YET. PUNCHING IN THE SAME BALLPARK AS THE OPEN FRONTIER BAYBEEEEE.
RECIPES? CHECK.
COOKBOOKS? CHECK.
TECH REPORT? CHECK.
DATA? CHECK.
ENVS? CHECK.

22
27
287
18,151