
AI & Automation Advocate | Passionate about Smart Home & Workflow Tools | Exploring Automations for Enterprises | Embracing Web Development Challenges
Joined July 2023
- Tweets 4,207
- Following 704
- Followers 758
- Likes 21,262
529 Photos and videos
















Pinned Tweet

26 Oct 2023
🔍 Exploring Self-Querying with @langchain 🦜🔗
In the world of AI and data retrieval, self-querying is a powerful concept.
Today, I'll show you how it works with an example. Get ready for the journey!
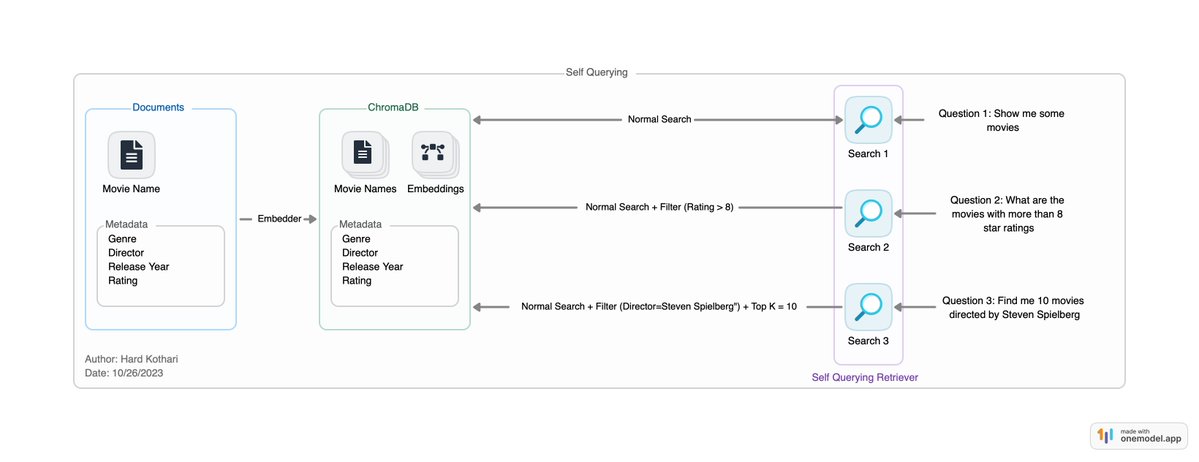
What is Self Querying?
A self-querying retriever, as the name implies, can search for information on its own.
It takes a natural language question and uses a chain of tools to create a structured query.
Then, it applies this structured query to its database of information.
This means the retriever can not only find content similar to your question but also apply filters based on the details you provide.
This is very powerful since, in normal case it won't filter documents and search every document similar to your query.
For example, it can look for documents that match your query and meet certain criteria, like a specific genre or a particular year of release.
In essence, a self-querying retriever is like an intelligent assistant that understands your requests and locates relevant information from its own repository by filtering data rather than getting everything similar.
The attached image should help you understand it visually.
5
19
128
39,625
Hard Kothari retweeted

18 Nov 2025
I am SUPER EXCITED to publish the 131st episode of the Weaviate Podcast with Matthew Russo (@RussoMatthew), a Ph.D. student at MIT! 🎉
AI is transforming Database Systems. Perhaps the biggest impact so far has been natural language to query language translations, or Text-to-SQL. However, another massive innovation is brewing. 💥
AI presents new Semantic Operators for our query languages. For example, we are all familiar with the WHERE filter. Now we have AI_WHERE, in which an LLM or another AI model computes the filter value without needing it to be already available in the database!
```sql
SELECT * FROM podcasts AI_WHERE “Text-to-SQL” in topics
```
Semantic Filters are just the tip of iceberg, the roster of Semantic Operators further includes Semantic Joins, Map, Rank, Classify, Groupby, and Aggregation! 🛠️
And it doesn’t stop there!
One of the core ideas in Relational Algebra and its influence Database Systems is query planning and finding the optimal order to apply filters.
For example, let’s say you have two filters, the car is red and the car is a BMW. Now let’s say the dataset only contains 100 BMWs, but 50,000 red cars!! Applying the BMW filter first will limit the size of the set for the next filter! 🧠
This foundational idea has all sorts of extensions now that LLMs are involved! This opportunity is giving rise to new query engines with declarative optimizers such as Palimpzest, LOTUS, and others! 💻
So many interesting nuggets in this podcast, loved discussing these things with Matthew, and I hope you find it interesting! 👇

4
13
30
7,039
Hard Kothari retweeted
3 Nov 2025
I am SUPER EXCITED to publish the 130th episode of the Weaviate Podcast featuring Xiaoqiang Lin (@xiaoqiang_98), the lead author of REFRAG from Meta Superintelligence Labs! 🎙️🎉
Traditional RAG systems use vectors to retrieve relevant context, but then throw away the vectors, just giving the content to the LLM. REFRAG instead feeds the LLM these pre-computed vectors, achieving massive gains in long context processing and LLM inference speed! 🧬
REFRAG makes Time-To-First-Token (TTFT) 31x faster and Time-To-Iterative-Token (TTIT) 3x faster, boosting overall LLM throughput by 7x while also being able to handle much longer contexts! 🔥🔥
There are so many interesting aspects to this and I loved diving into the details with Xiaoqiang! I hope you enjoy the podcast! 🎙️

5
17
43
16,900
Hard Kothari retweeted
7 Oct 2025
REFRAG from Meta Superintelligence Labs is a SUPER EXCITING breakthrough that may spark the second summer of Vector Databases! ☀️🏖️
REFRAG illustrates how Database Systems are becoming even more integral to LLM inference 🧬
By making clever use of how context vectors are integrated with LLM generation, REFRAG is able to make TTFT (Time-to-First-Token) 31X faster and TTIT (Time-to-Iterative-Token) 3X faster, overall improving LLM throughput by 7x!! REFRAG is also able to process much longer input contexts than standard LLMs! 🔥🔥
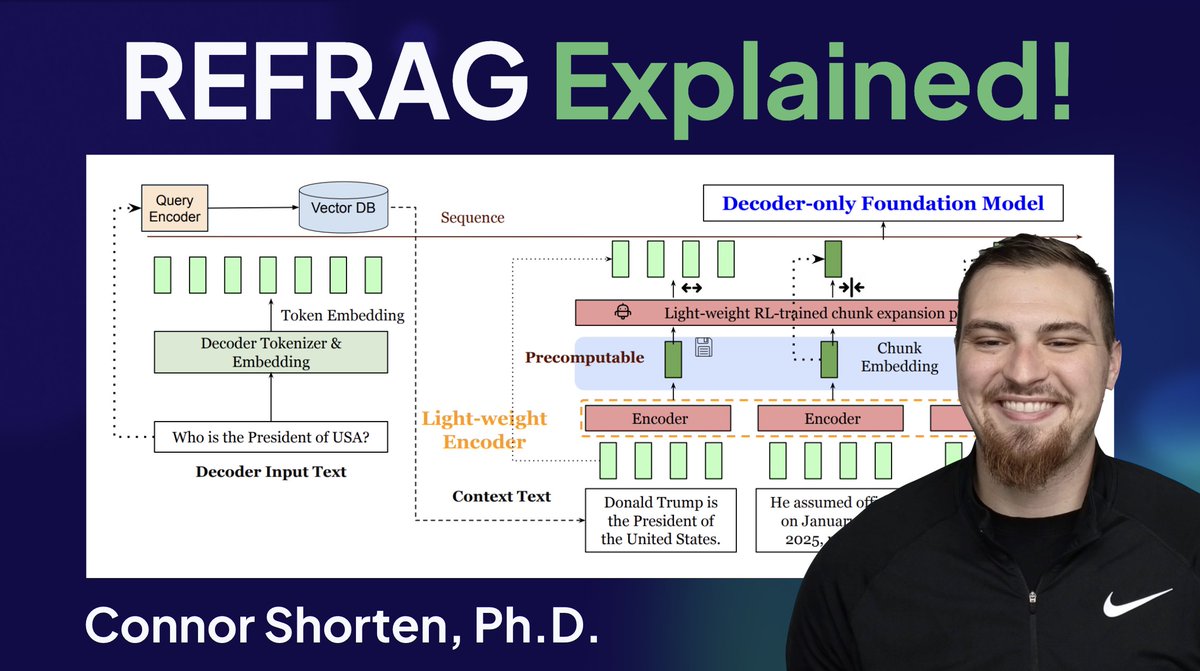
How does it work? 🔬
Most of the RAG systems today that are built with Vector Databases, such as Weaviate, throw away the associated vector with retrieved search results, only making use of the text content. REFRAG instead passes these vectors to the LLM, instead of the text content!
This is further enhanced with a fine-grained chunk encoding strategy, and a 4-stage training algorithm that includes a selective chunk expansion policy trained with GRPO / PPO. 🏭
Here is my review of the paper! I hope you find it useful! 🎙️
10
38
182
28,279
Hard Kothari retweeted
25 Sep 2025
The DSPy community is growing in Boston! ☘️🔥
We are beyond excited to be hosting a DSPy meetup on October 15th!
Come meet DSPy and AI builders and learn from talks by Omar Khattab (@lateinteraction), Noah Ziems (@NoahZiems), and Vikram Shenoy (@vikramshenoy97)!
See you in Boston, it will be an epic one!! 🎉
Sign up here - luma.com/4xa3nay1?tk=DvHED1
14
29
102
43,437
Hard Kothari retweeted
25 Aug 2025
GEPA has landed in DSPy 3.0!! 🛠️🧰
I am SUPER EXCITED to publish a new video sharing my experience using GEPA to optimize a Listwise Reranker! 🚀
The main takeaway I hope to share is how to monitor your GEPA optimization run to know if you are on the right track, or need to rethink your dataset, etc. 🔬
As GEPA is running, it will log metrics to Weights & Biases. There is the obvious metric to be interested in, the performance on the validation set the current best prompt has achieved. There is also a new concept particular to GEPA that you need to be aware of, the Pareto-Frontier across your validation samples!
GEPA achieves diverse exploration of prompts by constructing a Pareto-Frontier where any prompt on the frontier is outperforming the other candidate prompts on at least 1 of your validation samples!
As a user of GEPA, you may become frustrated, (like I initially was), if the average performance on the validation set isn't improving... but trust the process! If the aggregate score across the Pareto Frontier is improving, then you are on the right track!
There are a couple other nuggets I've shared in the video that helped me get GEPA off to the races, such as using a dataset of hard examples and configuring the size of the validation set.
I am incredibly excited to see GEPA achieving a gain on a well studied task like Listwise Reranking! Overall, it is just an incredibly interesting algorithm and prompt optimization itself is truly 🤯!!
I really hope you find this video helpful!

13
63
330
77,670
Hard Kothari retweeted

6 Mar 2025
The @weaviate_io Query Agent enables you to query your database in natural language using Agentic RAG!
You can easily connect our Query Agent to LLM SDKs and Agentic Frameworks. We are so happy to share 18 new notebooks demonstrating how to cook with this:
Frameworks:
• LlamaIndex (@llama_index)
• Crew AI (@crewAIInc)
• DSPy (@stanfordnlp)
• LangChain (@langchain)
• Haystack (@Haystack_AI)
• Pydantic (@pydantic)
• Smolagents (@huggingface)
LLM SDKs:
• Anthropic (@AnthropicAI)
• Google Vertex AI (@googlecloud)
• Google AI Studio (@GoogleAI)
• NVIDIA NIM (@nvidiadeveloper)
• Azure (@Azure)
• Ollama (@ollama)
• Together AI (@togethercompute)
• Baseten (@baseten)
• Cohere (@cohere)

7
37
219
48,776
Hard Kothari retweeted
3 Mar 2025
Stateful Agents: AI that remembers you and itself! 🧠
I am SUPER EXCITED to publish the 117th episode of the Weaviate Podcast featuring Sarah Wooders (@sarahwooders), co-founder and CTO of @Letta_AI! 🎙️🎉
With deep systems expertise developed at Berkeley's Sky Computing Lab (@BerkeleySky) , Sarah partnered with Charles Packer (@charlespacker) to solve one of AI's fundamental challenges through their MemGPT project—how can agents independently organize and prioritize their own memories?
This breakthrough research has evolved into Letta, a framework and Agent Development Environment (ADE) that empowers AI agents with context persistence, allowing them to maintain coherent memory states throughout extended interactions. Stateful Agents! 🚀
The podcast explores several interesting aspects of developing Stateful Agents:
• Context compilation and window management—how do you optimize 30,000 tokens when models offer 200,000? 🪟
• In-context memory management—letting the LLM itself decide what to remember! 🤖
• The Agent Development Environment (ADE)—making agent internals transparent and debuggable 💻
• Database-powered persistence: What is the role of Databases in these systems? What features should Agent-first Databases focus on? 🔄
• Tools: What is the latest on LLM tool use, "bring your own tools", and tool execution? 🛠️
A powerful insight from our conversation:
"Memory is everything" 🔥
Without attention to context management, it's impossible to determine whether issues stem from the LLM itself or from limitations in the context window.
I hope you find the podcast useful! As always more than happy to discuss these ideas further with you!

6
19
49
19,838
Hard Kothari retweeted
19 Feb 2025
Contrastive optimization resulted in massive breakthroughs in representation learning, producing embedding models and more! What if we apply the same concept for Agent optimization? 🧠
I am SUPER EXCITED to publish the 115th episode of the Weaviate Podcast featuring Shirley Wu (@ShirleyYXWu) from Stanford University! 🎙️🎉
This was an epic deep dive unpacking Shirley's work on the AvaTaR optimizer and the STaRK benchmark!
Similarly to MIPRO, AvaTaR is pioneering advanced prompt optimizers, which are themselves Compound AI Systems -- Agents optimizing Agents! The key insight in AvaTaR is the use of large batch sizes and contrastive optimization! 🟢🔴
I also loved learning about Shirley's perspective on Function Calling action trajectories, retrieving workflows, and working memory while following these trajectories! 🧠
Shirley and collaborators are also making really interesting advancements integrating graphs and vector embeddings! From this conversation, I am now super excited about GraphRAG-style methods! 🕸️
I hope you find the podcast useful! As always more than happy to discuss these ideas further with you!

4
14
38
9,604
Hard Kothari retweeted
4 Feb 2025
Hey everyone! I am super excited to share our new research report is live on ArXiv! 🎉
Querying Databases with Function Calling!
Thread with more details! 🧵(1/8)

44
174
1,449
280,873
Hard Kothari retweeted

3 Jan 2025
Home Assistant 2025.1! 🥂
home-assistant.io/blog/2025/…
A complete backup system overhaul—automated, encrypted, and extendable by integrations. Home Assistant Cloud backups, retention policies, and more! Plus, tons of Month of ‘What the Heck?!’ fixes! 🚀
#HomeAssistant

11
18
257
15,815
14 Dec 2024
Human in the loop is one of the most requested and needed feature in current agentic workflows to be production ready.
This would definitely make building graphs easier 👏🏼👏🏼
14 Dec 2024

🚧`interrupt`: Making it easier to build human-in-the-loop agents
Today, we’re excited to announce a new method to more easily include human-in-the-loop steps in your LangGraph agents: interrupt
Blog: blog.langchain.dev/making-it…
Video: youtube.com/watch?v=6t7YJcEF…

4
31
11,029
Hard Kothari retweeted
25 Nov 2024
I'm excited to share my talk on building Agentic RAG systems at last week's event with @arizeai and @Google! 🥳
My talk covered:
1. The differences between Vanilla RAG and Agentic RAG
2. The agent ecosystem and how you can build agents today
3. How @weaviate_io is building agents with Generative Feedback Loops (GFLs)
This snippet presents the multi-agent paradigm for Agentic RAG. I hope you find this talk interesting and would love to know what you think!
The slide deck and full video links are below.
10
109
596
61,474
Hard Kothari retweeted
13 Nov 2024
The Agentic RAG party continues! 🎉
I am SUPER EXCITED to publish the 109th Weaviate Podcast with Erika Cardenas (@ecardenas300)!
Erika, in collaboration with Leonie Monigatti (@helloiamleonie), have recently published "What is Agentic RAG"! This blog has even been covered in VentureBeat with additional quotes from Weaviate Co-Founder and CEO Bob van Luijt (@bobvanluijt)!
This podcast continues the discussion on all things Agentic RAG, from the basics of Agent Systems, Agentic vs. Vanilla RAG, Multi-Agent Systems and thoughts on Crew AI / OpenAI Swarm, Letta, DSPy, and more!
I hope you find the podcast interesting! As always we are more than happy to continue discussing these ideas with you or answer any questions you have!

5
19
59
10,473
Hard Kothari retweeted
12 Nov 2024
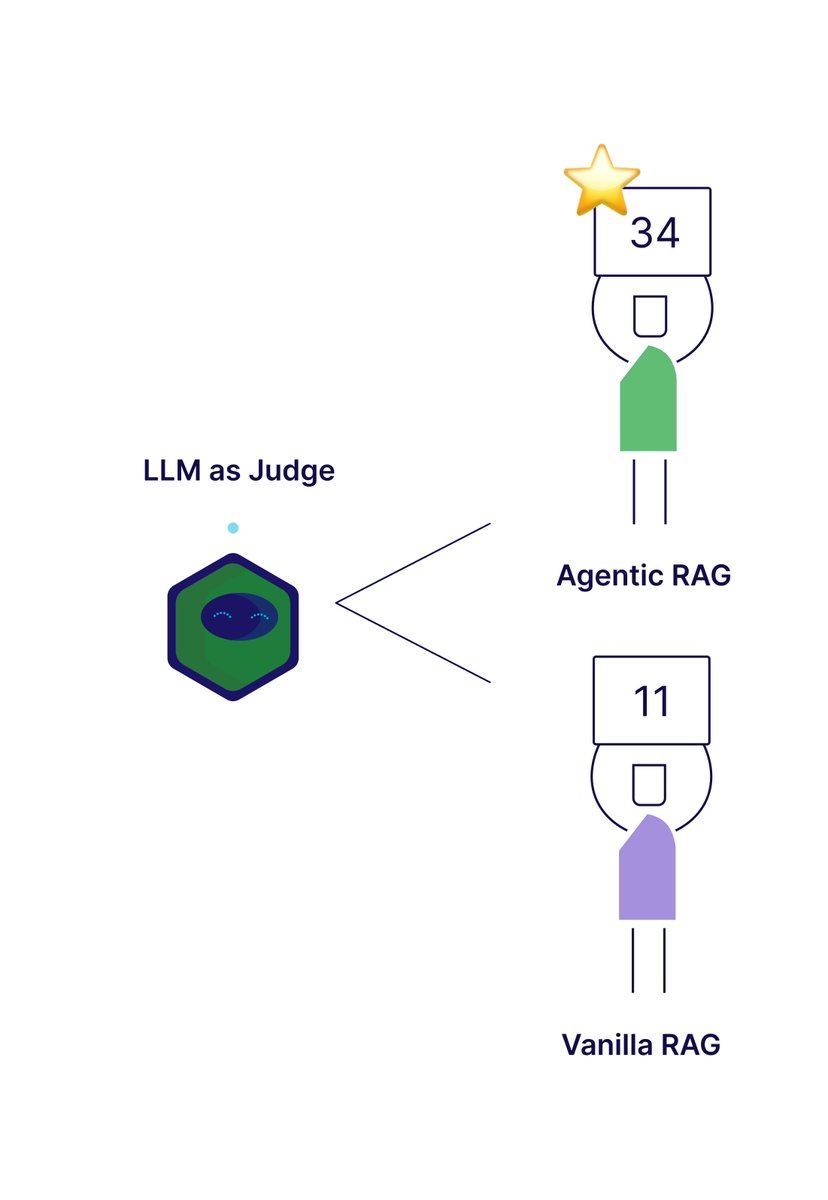
Battle of the RAGs 🤺
We put Agentic RAG and Vanilla RAG to the test in answering questions about Weaviate.
How the pipelines differ:
Vanilla RAG: Simple retrieve, augment, and generate pipeline
Agentic RAG: The LLM controls its own search strategy in a function calling loop
Agentic RAG won with 34 wins and Vanilla RAG had 11 wins.
Check out the recipe below!
10
61
312
30,657
Hard Kothari retweeted
6 Nov 2024
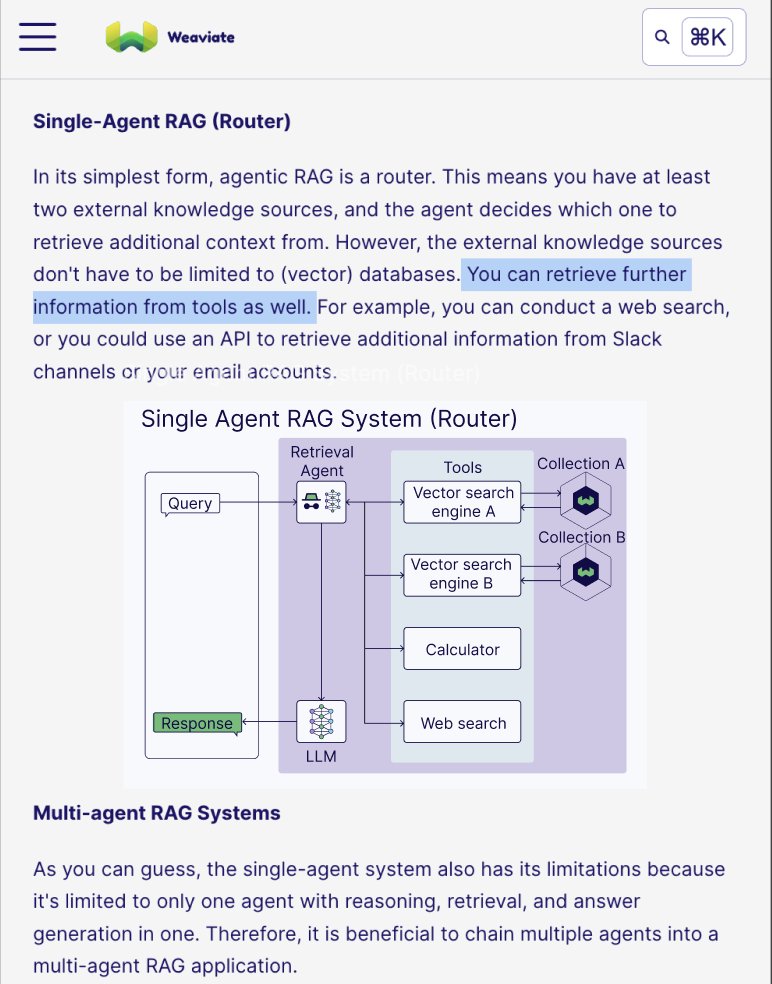
Swapping out RAG for Agentic RAG Systems 🤖
Agents differ from the standard retrieve and generate because of their access to tools, memory, and planning.
Why is this game-changing? It allows us to build systems with complete autonomy to reason and execute specific tools when needed. The top-level agent can:
• Plan the required steps based on the user’s query
• Determine if more information is needed by retrieving it from the vector database or doing a web search
• Call more than one tool and summarize results if needed
The benefits are:
1. It can format the search query from the prompt
2. It can call multiple tools in parallel
3. It can navigate your database to run vector search, aggregate, or filtered queries
4. Iteratively search for more information
I’m so happy to share our latest blog on Agentic RAG from @helloiamleonie and me!
We give an overview of agentic RAG, explain how it differs from vanilla RAG, and discuss a few ways to implement it.

5 Nov 2024

Goodbye, vanilla RAG.
Hello, Agentic RAG!
𝗩𝗮𝗻𝗶𝗹𝗹𝗮 𝗥𝗔𝗚
The common vanilla RAG implementation processed the user query through a retrieval and generation pipeline to generate a response grounded in external knowledge.
Advanced vanilla RAG techniques include e.g., incorporation of rerankers to improve the retrieved results.
𝗧𝗵𝗲 𝗶𝘀𝘀𝘂𝗲?
- Lack of flexibility: You retrieve additional information from a predefined knowledge source.
- No data validation: Vanilla RAG systems are one-shot retrievers. There’s no validation of whether the retrieved data is even relevant to the question.
𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚
Agentic RAG is an agent-based approach to vanilla RAG. It involves the use of AI agents, especially in the retrieval component (as well as other components). The use of AI agents in the retrieval component enables tool use to generalize retrieval.
𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗮𝗻𝗱 𝗞𝗲𝘆 𝗖𝗼𝗺𝗽𝗼𝗻𝗲𝗻𝘁𝘀
• Retrieval Agent: Decides whether external knowledge is needed, where to retrieve data from, preprocesses the query for optimized retrieval, validates whether the retrieved data is relevant to the user query, and re-retrieves data if necessary.
• Tool use: Data can be retrieved from multiple sources, including (vector) databases, web searches, API calls to email or chat messages, calculators, etc.
In our recent blog @ecardenas300 and I discuss everything related to Agentic RAG.
Read more on our blog: weaviate.io/blog/what-is-age…
7
79
463
56,248

I will gift a latest M4 Mac Mini to one person who repost this.
I am doing this to promote MoAIjobs.com, a job board to find jobs in AI.
⏱️Deadline: 7th november, 2024.
Let's go. 🔥🚀

473
1,885
1,596
236,716
Hard Kothari retweeted
28 Oct 2024
Internal memory enables agents to reflect on their experiences and form a model of themselves and their environment. Let’s build a meta memory agent system with @Letta_AI 🧠
Letta built by @sarahwooders and @charlespacker is a startup spun off of MemGPT at UC Berkeley. It is a framework for building agents with internal memory. As you chat with Letta, the agent actively updates its internal model. This results in more personalized and relevant responses!
This recipe shows you how to use a @weaviate_io collection as a search tool. It illustrates a conversation about vector database concepts in which Letta forms an internal memory from the conversation history.
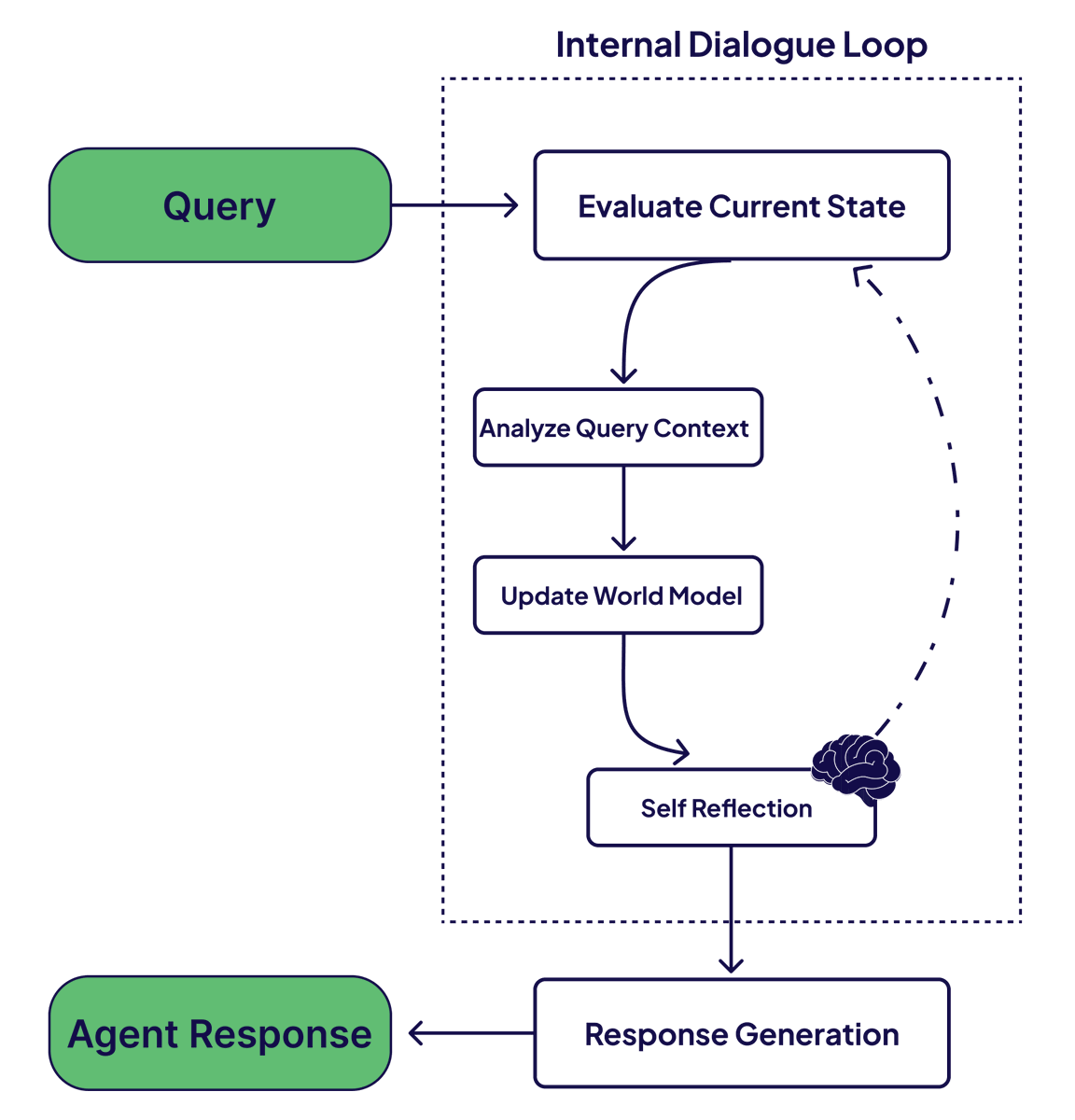
3
31
83
13,523
21 Sep 2024
This is some real life application of agent with entire code shared and very simple to understand.
Great work here. 👏🏼👏🏼.
Definitely something to learn from…
21 Sep 2024
🥼Agentic customer service
This OSS repo implements a customer service bot for various tasks of a medical clinic - get info, cancel, reschedule, check doctor availability, check results, etc
Customer service is a huge use case for LangGraph
github.com/Nachoeigu/agentic…
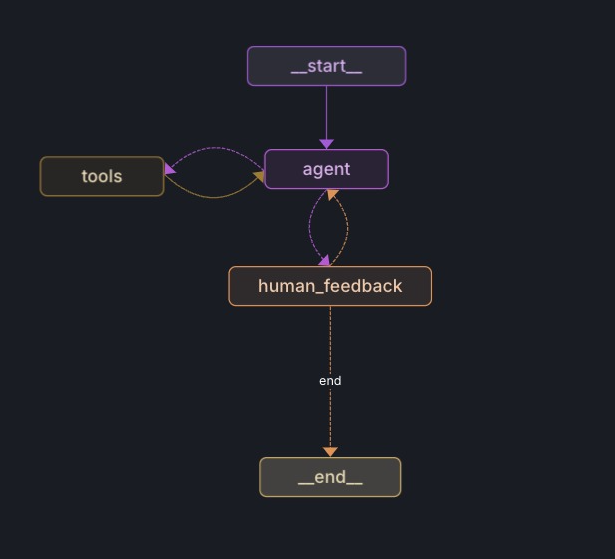
3
14
4,214
Hard Kothari retweeted
15 Sep 2024
Humans use past actions and outcomes to influence future decisions, how can we translate this to agents?
Agents describe connecting LLMs to external tools in a looping interface where the Agent calls a tool, or action, with some arguments, receives the result, and continues until the task is completed.
Agent Workflow Memory (AWM) by @ZhiruoW et al. brings the learning power of in-context learning to the agentic framework by adding task trajectories, or skills, to the agent’s prompt.
For example, the agent begins by completing tasks such as, “Buy dry cat food on Amazon and deliver to my address”. Once the initial, zero-shot agent goes through several of these tasks, a meta-learning module then parses the experiences to extract subtasks to add to the prompt, such as “search for a product on Amazon.”
By iteratively extracting these workflows to the prompt from collected experiences, the agent can leverage the power of in-context learning to become more effective over time.

3
17
42
7,493
12 Sep 2024
This is a very detailed blog on how to have SQL query generated for your database with large schema using natural language.
This was almost impossible last year.
I am sure stealing some ideas from here 😄
Great work guys 👏🏼👏🏼
12 Sep 2024
🖌️Text to SQL Agent for Data Visualization
Data analysis has traditionally been inaccessible to those without extensive SQL or visualization expertise
This video highlights a project demonstrating how agents can bridge the gap between natural language questions and data visualization
🤖We explore a repo that implements a SQL agent in LangGraph, serving it via LangGraph API as the backend to a user-facing app. The app's UI allows users to input questions and upload CSV files, which are converted into an SQLite database
🧱The agent then queries this database based on user questions, selects appropriate visualization methods, and formats the resulting data for display in the UI. We walk through the repo, demonstrate backend testing via LangGraph Studio, and showcase the user interface in action.
Repo: github.com/DhruvAtreja/datav…
Blog: blog.langchain.dev/data-viz-…
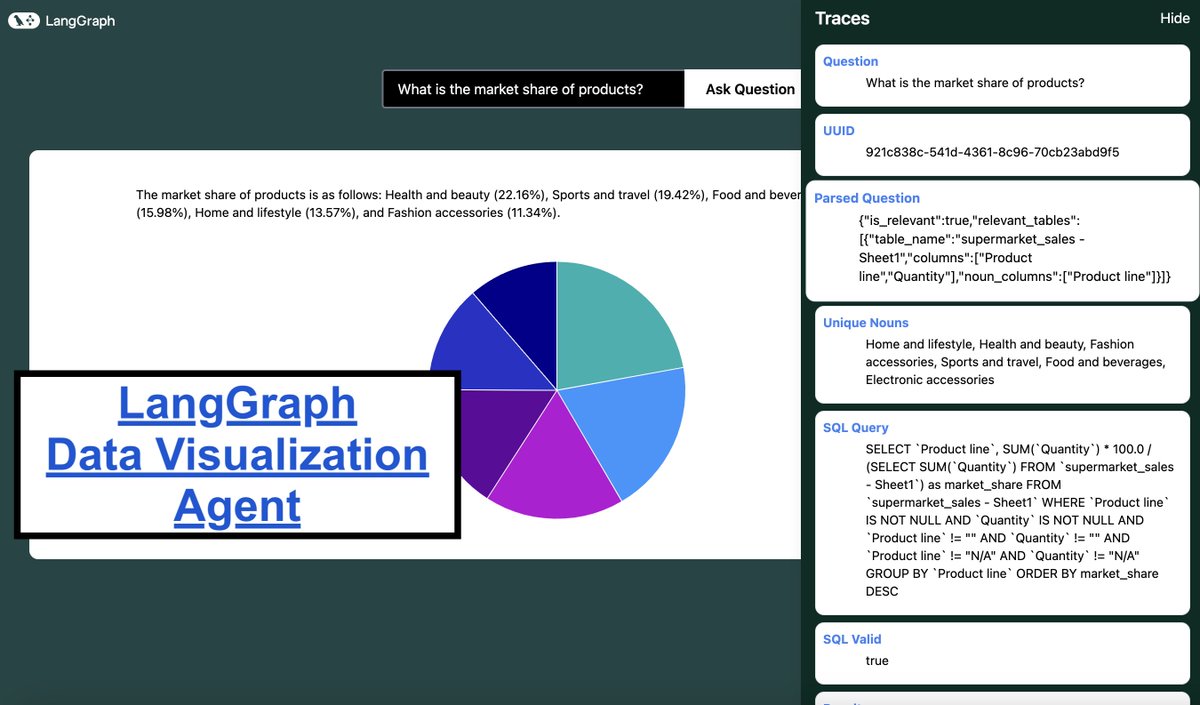
2
11
3,078