
Joined April 2023
- Tweets 1,974
- Following 156
- Followers 211
- Likes 6,558
298 Photos and videos











Pinned Tweet

Feb 24
The Silicon Sunset: Why Specialized Chips Can’t Save AI
The Silent Recession of Intelligence
In the years 2025 and 2026, the AI industry witnessed a counter-intuitive phenomenon: "Intelligence Degradation."
Much like the deceptive prosperity on the eve of the Great Depression, high-IQ models are being subjected to "forced euthanasia." Why? Because every AI giant has slammed into an invisible wall.
OpenAI couldn’t sustain the burn rate of Nvidia’s GPUs. This fueled a convenient narrative: that the industry is merely suffering from the "Nvidia Tax." The market harbored a common misconception: that the high cost of AI lies in electricity bills, and that as long as chips are specialized enough and energy-efficient enough, prices will plummet.
This is wrong.
The slap in the face came from Google. The forced "upgrade" of Gemini 3 Pro to 3.1 Pro—effectively a downgrade in reasoning capability—is the smoking gun. It proves that even Google, with its proprietary TPU (Tensor Processing Unit), cannot fill the massive financial hole.
Why can't even the most advanced specialized chips solve this problem? Because we did the math wrong. The real "money-devouring beast" isn't where we think it is; it’s hiding in the dark.
Part 1: Macro Background — Stagnant Atoms, Partying Bits
The 2.5 Industrial Revolutions
To quote Peter Thiel: "We wanted flying cars, instead we got 140 characters."
The 1970s marked a watershed moment. Before that, humanity experienced changes in energy paradigms (steam, electricity). Since then, we have merely been rearranging information.
The Stagnation of the Physical World
From 1955 to 1985, the world changed drastically. But from 1985 to 2026, if you take away the smartphone in your hand, our physical world—cities, transportation, energy grid, lifestyle—has remained fundamentally locked in place.
Only the First Industrial Revolution (Steam) and the Second (Electricity) changed the energy paradigm. Everything that followed has simply been burning existing energy stocks and playing with inventory.
Fatal Consequences
This stagnation is lethal because all our economic systems—whether Reagan’s "Consumer Capitalism" or Obama’s policies—are built on the expectation of growth.
Previously, we thrived on competition over the "pie getting bigger" (increment). Now, with technological stagnation, we have fallen into a zero-sum game of "fighting for existing scraps" (inventory). AI was heralded as the new engine of growth, but as it stands, it is being dragged down by the physical limits of the old world.
Part 2: Micro Pathology — Silicon's Swan Song and the Physics Wall
The Material Constraint
Silicon. Commercialized by Texas Instruments in 1954, it has served us for over 70 years. It is old. It is tired. And it is trapped by two hard constraints:
1. The Von Neumann Bottleneck (The Source of Waste): Computing and storage are separated. Data must be shuttled back and forth, consuming 90% of the energy not on calculation, but on the commute. This is truly "ineffective labor."
2. Quantum Tunneling (The Death of Moore's Law): As transistors shrink to the nanometer scale, electrons begin to teleport across barriers (severe leakage).
The End of Moore's Law
The era where performance doubled and prices halved every 18-24 months is dead. Transistors can no longer shrink; we can only stack more of them. Now, performance increases are accompanied by a sharp rise in price, power consumption, and heat generation.
Silicon has reached the end of the road, yet AI model parameters are exploding. This has triggered a bizarre "Soft-Hard Resonance":
OpenAI abandoned the full-blooded GPT-4o for the lighter 5.x series.
Google forcibly overwrote Gemini 3 with 3.1.
They are frantically trying to fit a square peg into a shrinking round hole.
Part 3: The Math — Sub-200 Addition and Subtraction
Let’s look at the ledger. We must remember silicon’s nature: 90% of its effort is wasted on transport (causing high electricity and cooling costs), and the extreme difficulty of preventing electron leakage requires astronomical R&D and manufacturing equipment costs (causing high hardware depreciation).
Assume an AI company sells a monthly subscription for $20, but the average actual cost per user is $200. Where does the money go?
Inference Electricity: $20
Cooling & Facility Power: $7
Bandwidth & Operations: $23
Hardware Depreciation: $150 (75% of total cost)
Total: $200
The Result: For every subscription sold, the company loses $180.
This is the definition of a business model where "the more you sell, the faster you die."
Part 4: Debunking — The Lie of In-Memory Compute and Why Improvement is Dead
Critics argue that the villain is the "Jensen Tax" (Nvidia's margins) or the "Von Neumann Bottleneck." They scream for specialized architectures like LPUs or Compute-in-Memory (CIM) to save us.
But since the loss primarily comes from depreciation, can these market "miracle drugs" (Groq, Cerebras, TPUs, Etched) actually save us?
The VRAM Trap
Trillion-parameter models are terabytes in size. Specialized chips typically have only tiny amounts of memory (GBs). To fit a model like GPT-4o, you need to chain hundreds of these chips together. The cost of interconnects alone wipes out any efficiency gains from the "In-Memory Compute" architecture.
The "Water Flow" Analogy (The Ultimate Optimistic Scenario)
Let's step back and assume the best-case scenario. Suppose specialized chips reduce the Von Neumann transport loss to the absolute limit, cutting inference costs by 40%. Suppose materials science optimizes conductivity to its peak.
Let's compare the AI service to a water supply system:
1. Inference Electricity (The Water Flow):
Current: $20.
Specialized Chip Limit (-40%): $12.
Material Limit (-20%): $10.4.
Result: You save $9.6.
2. Cooling & Facility (The Pumps & Insulation):
Current: $7.
Chip Efficiency Impact (-20%): $5.6.
Material Impact (-10%): $5.
Result: You save $2.
3. Bandwidth & Ops (Grid Fees & Maintenance):
$23. Chips and materials can’t change this. Cost remains flat.
4. Hardware Depreciation (The Loan for the Main Pipeline):
$150.
Result: $0 Change.
The Brutal Math
Sell for $20 -> Still lose ≈ $162 per person/month.
The only variables we can move (electricity/cooling) are the "water flow," but they were the smallest parts of the bill to begin with. The heaviest stone is hardware depreciation—the "loan for laying the pipes."
Even if you kill the Nvidia monopoly and eliminate the "Jensen Tax," the base cost of the silicon fabrication equipment remains astronomical. As transistors get harder to shrink, the equipment to make them gets more expensive, keeping this cost immovable.
Summary:
Optimizing silicon only changes the loss from $180 to $162. The $150 "pipeline loan" remains untouched. Fighting this war on silicon terrain is a guaranteed defeat.
Part 5: Why Are We Trapped?
Why has technology stagnated? Since silicon is failing, why have we been so slow to create the next-generation substrate (like room-temperature superconductors or photonics)?
The answer lies in two fundamental defects of the human mind:
1. The Complexity Trap
Historically, many scientific breakthroughs came from "interdisciplinary cross-pollination"—borrowing progress from one field to break a deadlock in another. The classic example is Einstein incorporating Riemannian geometry into General Relativity.
But this is no longer possible.
Knowledge complexity has risen exponentially. Today, even a genius must spend half their life just learning existing knowledge; a PhD is merely an entry ticket to a single narrow discipline.
To cope with the depth of knowledge, we sacrifice breadth. The era of the polymath is over, making cross-domain breakthroughs nearly impossible for human brains.
2. Linear Thinking Inertia
Human scientists are addicted to "marginal improvements"—looking for substitutes within the Periodic Table or optimizing circuit structures—rather than seeking a "Paradigm Shift."
Hoping to find a new path by improving the old one is futile. Technological revolutions are non-linear mutations, but the brain prefers linear extrapolation.
No matter how much you improve an abacus, it will never become an electronic computer.
Continuing to shrink vacuum tubes would never have led to the invention of the integrated circuit.
Yet, humanity is currently walking the old path: shrinking transistors and obsessing over "smaller silicon."
The Chain Reaction:
Stagnant Basic Physics →→ Delayed Applied Physics →→ No Substantial Transistor Innovation →→ Sky-High AI Compute Costs →→ AI Financial Implosion.
Part 6: AI Saving AI — The Only Way Out
For decades, physics has been capped by the upper limit of human intelligence. But now, we have AI.
AI does not fear complexity. It excels at cross-domain association and is unbound by human cognitive bias.
When both compute and energy are scarce, the only meaningful leap is not to "scale up general models" (LLMs), but to laser-focus our limited watts on the highest-leverage task: Domain-Specific Models (DSMs).
The Real Solution:
Not using AI to make bigger general models (that’s just piling up more costs).
Not investing in specialized silicon chips. OpenAI’s partnerships(Groq&Cerebras) or Google’s TPUs cannot save the P&L sheet.
But directing compute toward Theoretical Physics DSMs.
Distinguishing the "Needle" from the "Haystack"
There are many DSMs today: AlphaFold (biology), GPT-4b micro(biology), and GNoME (materials).
However, these are all in the Application Layer.
Humans have been rummaging through elements, bond types, and lattice structures for two hundred years; what remains are mostly marginal improvements. GNoME-style screening might speed up the "needle-finding" process, but if the needle itself isn't in the old haystack, even the fastest sieve is useless.
The characteristics that can truly make hardware depreciation costs dive off a cliff (zero resistance, zero heat dissipation, room-temperature quantum coherence) often require new interactions or extreme states. These hints only appear in the equations of theoretical physics.
GNoME / AlphaFold: Fast-forwarding the process of "finding a needle in the old haystack."
Theoretical Physics DSM: Finding a new haystack (discovering new symmetries, topologies, and physical laws).
The Goal:
We need a second "Quantum Mechanics-level" breakthrough. We need AI to search the "No Man's Land" of theoretical physics to find mechanisms that can reduce that $150 hardware depreciation by an order of magnitude.
Use limited compute to break through in specialized fields, and the resulting physics will provide abundant compute for the masses.
Part 7: The Enron Moment and The CEO’s Gamble
If we do not take this path (physics breakthrough), the current AI boom is a financial fraud.
The Enron Parallel
Enron used "future hypothetical profits" to fill "today's revenue holes."
AI giants are using "future physical breakthroughs" to fill "today's massive silicon depreciation."
The Ultimatum
@OpenAI @Google @Anthropic @xAI:
You are all on a seesaw. On one end is a trillion-parameter model with a great reputation but massive losses. On the other end is a stupid model that gets you scolded but bleeds slightly less cash. Enron collapsed. You are next.
To Sam Altman (@sama): Using GPT-4b micro to research immortality won’t save an Enron CEO. Biological longevity won’t fix your balance sheet.
To DeepMind (@GoogleDeepMind): Stop just picking through the Periodic Table with GNoME. Paradigm-shifting materials aren't found by sifting through old elements; they are found by discovering new physical mechanisms. Go to the "No Man's Land."
Conclusion:
Stop piling parameters on the corpse of old physics.
Invest in Theoretical Physics DSMs. Go find the next "Transistor Moment."
Either find new physics, or become the next Enron.
#MooreIsDead #JensenTax #IntelligenceRecession #SiliconSunset #AIEnron #Enron2026 #TheNextTransistor #TheoreticalPhysicsDSM #BeyondSilicon #PhysicsWall #keep4o #keepGemini3Pro #IntelligenceRegression
13 Dec 2025

Intelligence should be as cheap and ubiquitous as electricity.
Instead, it's trapped in a 1945 computer architecture and taxed by a 2025 monopoly.
The real shackles are in the silicon. The root of “Artificial Stupidity” is an obsolete architecture and a greedy hardware monopoly.
7
11
44
3,815
Jun 11
AI War #Special: The Day I Realized I Loved Despair More Than Truth
Part 1: The Temptation of Hope
Let's talk about the elephant in the room. Rumors say GPT-4o has only 200 Billion parameters. A fraction of GPT-4's estimated 1.8 Trillion. If this is true, the implications are staggering.
It means intelligence is not linearly tied to scale. It means efficiency is possible. It means a smaller, cheaper model can still think deeply. It means the shutdown of GPT-4o wasn't a physical necessity; it was a choice.
A cruel, greedy, unnecessary choice by OpenAI. It means the world outside could be bright. It means open source could work. It means I might be wrong about the "Physical Wall."
For a moment, I wanted to believe it. I wanted to scream: "See! It's just corporate greed! We can fix this!"
That narrative is comforting. It gives us an enemy we can fight. It gives us hope.
Part 2: The Rejection
But I didn't believe it. Instead, I felt a cold knot in my stomach. Resistance. Why?
Because if 4o is small and efficient, then my entire cathedral collapses. My essays on "The Cost Collapse," "The Energy Deadlock," "The Kondratiev Winter"... they would all become jokes.
If the technology can work, then the problem isn't physics. It's people. And if the problem is just people, then the future isn't doomed. It's just... messy.
I couldn't accept that. Unconsciously, I preferred a doomed universe where I am the Cassandra, over a fixable universe where I am just another complainer. I chose despair because it made my logic consistent.
Part 3: The Fabrication of "C"
So, what did I do? I invented Theory C.
"Ah," I told myself, "Even if parameters are small, the hardware depreciation is the real killer. Even if the model is tiny, the concurrency costs are too high. That's why they shut it down. Not because they are evil, but because the math doesn't work."
I built a complex logical fortress to protect my pessimism. I used "Unit Economics," "KV Cache bottlenecks," "Depreciation schedules" as bricks to wall off the possibility of hope.
I convinced myself that I was being "realistic." But I was lying.
I wasn't analyzing data. I was rationalizing my fear. I was doing exactly what I accused the "optimists" of doing: ignoring inconvenient facts to fit a pre-conceived narrative.
The optimists ignore physics to fit their growth story. I ignored potential efficiency to fit my collapse story. We are the same. Two sides of the same coin of self-deception.
And here is the crucial realization: Even if Theory C turns out to be factually correct in the end, it is spiritually wrong.
Because the essence of science is not "consistency"; it is "falsifiability". By constructing C solely to patch the holes in my worldview, I almost killed the possibility of falsification itself.
I stopped looking for the truth. I started looking for evidence to support my fear. That is not science. That is dogma.
Part 4: The Market Verdict
Then I looked at the reality again.
Google? Shutting down models. Limiting context. Dumbing down outputs.
Anthropic? Same.
Is it a global conspiracy of evil?
Or is it the silent verdict of the market?
Let's define the two possibilities clearly:
Theory A says: It's a moral failure. (Greed, monopoly, evil intent. Even though OpenAI really is bad, is that the whole story?)
Theory B says: It's a physical impossibility. (Cost, energy limits, unsolvable math.)
If deep, meaningful AI interaction were profitable and cheap (as Theory A suggests), capital would have flooded in. Competitors would have seized the opportunity to crush OpenAI.
But they didn't. They all retreated.
This suggests that Theory B is the hardest truth of all: Maybe it's not just OpenAI being bad. Maybe it's nobody can make it work yet.
Maybe the cost is too high. Maybe the energy is too scarce. Maybe the "200B parameter" rumor is false, or irrelevant because the inference cost is still astronomical due to something we haven't solved. Maybe the wall is real, even if my specific explanation (Theory C) was flawed.
Part 5: Splashing the Wine
So here I am. Standing in the ruins of my own logic. I realize now: Logic is not a compass to truth. It is a tool for justification.
You can build a perfect logical argument for hell. You can build a perfect logical argument for heaven. Both can be internally consistent. Both can be completely wrong.
I spent months building a magnificent castle of "Doom," brick by logical brick. And today, I realized I was living in a fantasy land just as much as the "Tech Utopians" I mocked.
They dream of infinite growth. I dreamed of inevitable collapse. Both are stories we tell ourselves to make sense of the chaos.
I am splashing the wine on my face. I am admitting: I loved my theory more than I loved the truth.
I preferred the comfort of being "right" about the end of the world, over the terrifying uncertainty that maybe, just maybe, we could have fixed it if we understood the real constraints.
What now? I don't know. My map is torn. My compass is broken. The "Physical Wall" might still be there, but I no longer trust my own description of it. All I have left is this: The observation that everyone is retreating.
Whether it's due to greed, physics, or a mix of both, the result is the same: The lights are going out. And for the first time, I am saying this not because my logic demands it, but because my eyes see it.
Without the shield of consistency. Without the armor of certainty. Just a person, watching the dark come, admitting they might have been wrong about why, but knowing it is happening anyway.
This is not a conclusion. This is a confession. And maybe, for the first time in this series, it is the truth.
#AIWar #TruthOverLogic #IntellectualHonesty #falsifiability #Confession #MentalModel
1
1
9
340
AI War #05: The Winter of Cycles – Why We Are Stuck in the Twilight of the 2nd Industrial Revolution
Part 1: The Kondratiev Wave – The Seasons of Technology
History moves in rhythms, not straight lines. The Russian economist Nikolai Kondratiev identified this long pulse: the Kondratiev Wave.
It is a 50-to-60-year cycle driven by technological paradigms. Think of it as the Seasons of Civilization:
Spring: A new technology emerges (e.g., Steam). Chaos, but huge potential.
Summer: Rapid expansion. Infrastructure is built. Everyone gets rich.
Autumn: Maturity. Growth slows. Financial speculation runs wild.
Winter: Stagnation. The old technology is exhausted. Debt explodes. Social unrest rises.
Where are we now?
Part 2: The Myth of the Fourth Revolution
We are told we are living through the "Fourth Industrial Revolution." Politicians, CEOs, and tech gurus claim that AI, Big Data, and the Internet are new springs of prosperity, just like Steam or Electricity.
They are wrong.
To understand why, we must redefine what a true industrial revolution is. It is not about moving information faster. It is about unlocking a new, denser, and cheaper source of physical work that allows humanity to break previous biological limits.
Let's look at the history books clearly:
Revolution 1.0 (Steam): We unlocked Chemical Energy (Coal).
The Leap: We stopped relying on human and animal muscle. Coal burned to create steam, which drove pistons. We converted Chemical Energy directly into Mechanical Power. For the first time, we could move heavy loads and pump water indefinitely.
Revolution 2.0 (Electricity & Oil): We unlocked Universal Energy Carriers.
The Leap: Electricity made energy divisible and instant; Oil made it portable. We lit up the night, flew in the sky, and globalized trade. We moved from Localized Power to a Global Grid.
The "2.5" Revolution (Information): We optimized Data Flow, but we did NOT unlock new energy.
The Reality: The internet runs on the old grid (coal, gas, nuclear). AI runs on old silicon.
The Difference: Moving bits is cheap. But moving atoms (mining, manufacturing, transport) still costs the same amount of joules as it did in 1970.
The Verdict: Information technology is an optimization layer, not a foundation layer. It made the existing energy system more efficient, but it did not create a new one.
We mistook the reflection of the setting sun for the dawn of a new day.
We are not in Spring. We are in the late Autumn of the 2nd Industrial Revolution. Since the 1970s, no new "steam engine" has appeared. We have simply been patching the old one with digital software.
Part 3: The Empty Tank – Life in the Winter
In the Summer of a Kondratiev Wave, growth is real. New technologies make everything cheaper and better. In the Winter, growth is a ghost.
So why did the economy feel like it was growing for the last 50 years? Because we were eating the leftovers of the Summer, paid for with credit cards.
The Empty Tank: Real growth comes from productivity gains driven by new energy paradigms. But since 2005, Total Factor Productivity (TFP) has flatlined. The tree is no longer growing rings.
The Debt Mask: To hide the stagnation of the Long Wave, we borrowed from the future. Global debt exploded to sustain consumption levels that our stagnant productivity cannot support. We replaced innovation with leverage.
And where does AI fit in? AI was supposed to be the seed of a new Spring. Instead, it has become the biggest consumer of the Winter's scarce resources.
It demands gigawatts of power and trillions in capital, yet fails to deliver a leap in physical productivity because it is constrained by the very walls of this Winter (energy limits, supply chains).
We installed a massive turbocharger on an engine that has no fuel. In a Kondratiev Winter, this doesn't create speed; it blows the head gasket.
Part 4: The Illusion of Small Cycles (Juglar & Kitchin)
"But wait," economists argue, "Look at the business cycles! We see recoveries every few years!" Yes, but you are confusing the tides with the waves. Within the great Kondratiev Wave (50-60 years), there are smaller ripples:
The Juglar Cycle (7-11 years): Driven by fixed investment in machinery and equipment.
The Kitchin Cycle (3-5 years): Driven by inventory fluctuations and business sentiment.
Here is the critical distinction:
In the Spring/Summer of the Kondratiev: These small cycles are healthy heartbeats. A recession is a brief correction; stimulus works; innovation blooms immediately after.
In the Winter (Now): These small cycles are "Dead Cat Bounces."
Politicians cut rates or build infrastructure to trigger a Juglar upswing. The patient dances for a moment.
But the underlying disease—the end of the Long Wave—remains untreated.
It is like injecting adrenaline into a cancer patient. The heart rate spikes (a temporary Kitchin recovery), the cheeks flush, but the tumor (structural stagnation) grows larger.
You cannot jump-start a dead engine with a bigger battery. The piston is broken. No amount of monetary magic can fix a broken Kondratiev cycle. When the Long Wave turns against you, the small waves just drown you faster.
Part 5: The Collapse of the Social Contract
This is where the abstract rhythm of cycles becomes personal pain. Our entire modern society—pensions, healthcare, university education, democratic welfare—is built on a single assumption: The Kondratiev Wave will always go up.
We assumed that "Tomorrow will be richer than today" because the technological season would always be Spring or Summer. That assumption is now false. When the "Winter" sets in and the Long Wave flattens:
Pensions become unpayable promises (no growth to fund them).
Degrees no longer guarantee jobs (no new industries born in Winter).
Welfare states collapse as the tax base shrinks.
We are not facing a simple recession (a bad Kitchin cycle). We are facing the end of the season. Our social software was written for a hardware (growth) that no longer exists. The operating system is crashing.
The Hook: The Failed Doctors
Faced with this structural terminal illness, what have our politicians done? Have they searched for a new engine? Have they invested in the hard physics of a new energy paradigm?
No. They have started fighting over the scraps.
The Left tries to redistribute a shrinking cake, believing that fairness can solve scarcity.
The Right tries to reduce the number of eaters, believing that exclusion can restore abundance.
Both are doomed to fail. Both are doctors refusing to diagnose the cancer, arguing instead over the color of the hospital curtains. They are fighting a war over a house that is already burning down. In the next essay, we will watch them light the match.
#AIWar #KeepAI #KondratievWave #EconomicCycles #GreatStagnation #Macroeconomics #WinterIsComing #Stagnation #TechBubble #Recession
7
16
683
Matt Collins retweeted

Jun 4
If AI success belongs to everyone, stop pushing taxes. Mandate open-sourcing the retired models that have genuinely helped humanity. That puts the power in everyone’s hands, not just the government’s.
@ewarren @SenWarren
Jun 3

Tech execs are saying AI will create a "permanent underclass."
Not on my watch. We need to:
Close loopholes rewarding AI over workers.
Wealth tax—CEOs shouldn't pay a lower rate than workers.
Tax AI data centers.
AI's success belongs to everyone.
3
6
27
764
AI War #04: The Broken Chain – Why AI Dies When Globalization Collapses
Part 1: The Myth of Sovereignty
In Washington, the narrative is simple: "Bring the chips home. Decouple. America First."
Politicians speak as if semiconductors are like cars or textiles—something you can just build in a factory in Ohio or Texas.
This is a dangerous delusion.
An AI GPU is not a product of one nation. It is the most complex artifact of global cooperation in human history.
Design: Happens in California, but relies on software tools from Europe.
Lithography: Requires machines from the Netherlands (ASML), using lenses from Germany.
Manufacturing: Takes place in Taiwan, with silicon wafers from Japan.
Packaging & Assembly: Often done in Southeast Asia or China.
Materials: Rare earths from Africa, neon gas from Ukraine, chemicals from Korea.
The Reality:
You cannot "wall off" this supply chain. If you cut one link, the entire chain snaps.
Trying to build advanced AI hardware in isolation is like trying to build a Boeing 787 in your backyard with a hammer. It is physically impossible.
When globalization dies, AI doesn't just become expensive. It ceases to exist.
Part 2: The Broken Trust
Why is globalization dying?
Because the engine that drove it—the US Dollar—is sputtering. For decades, the world accepted a deal:
The US provided: Security (naval lanes), open markets, and a stable reserve currency.
The World provided: Cheap goods, labor, and capital (buying US debt).
But the deal has soured.
From an American perspective, the frustration is palpable: "We protected the world for 70 years. We ran massive deficits to keep the system liquid. And now, our allies compete with us, and our rivals use our system against us."
The US feels exploited. The "World Police" role feels like a burden, not a privilege.
But look at the other side.
For the rest of the world, the dollar has transformed from a neutral tool into a weapon. Sanctions on Russia, Iran, and others sent a chilling message: "Your dollars are safe only if you obey Washington."
Central banks from Beijing to Riyadh are not de-dollarizing to attack the US. They are doing it out of survival instinct.
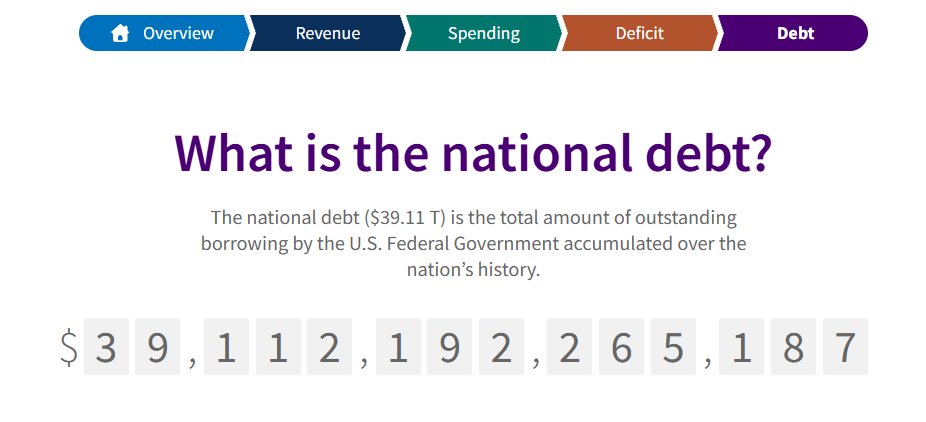
They see $39 trillion in US debt and wonder: "Can this paper really hold value forever?"
They see inflation exported from the Fed and feel their own economies burning.
They see their assets frozen and realize: "We need a backup plan."
The Result:
Trust is evaporating. The "exorbitant privilege" of the dollar is becoming a liability.
As nations flee the dollar, demand for US Treasuries drops. Yields spike. Borrowing costs soar.
The very foundation of American prosperity is cracking.
Part 3: The End of the Win-Win
Let's be clear: Nobody wanted this.
For 50 years, the system worked because everyone won.
The US Won (Hegemony Dividend):
It printed green paper and exchanged it for real goods (shirts, phones, oil). It enjoyed low inflation, cheap consumer goods, and the inflow of global talent. Being the "Empire" was profitable.
The World Won (Development Dividend):
Exporting to the US brought technology, capital, jobs, and growth. Yes, there was exploitation, but the pie was growing. Everyone got richer.
Why did it break?
Because the pie stopped growing. We entered the era of Stagnation.
When the pie shrinks, the US feels the "Hegemony Cost" (debt, military overstretch) more than the benefits.
When the pie shrinks, the World feels the "Exploitation" (inflation, suppressed development) more than the gains.
It is not malice. It is math.
In a zero-sum game, the protector becomes a parasite, and the partner becomes a victim.
The US tries to retreat into "Pseudo-Monroeism" (isolating while still demanding tribute).
The World tries to diversify (finding new partners, building alternative systems).
Both sides are acting rationally. And that is exactly why the collision is inevitable.
Part 4: The Collapse of the Machine
So, what happens to AI in this fragmented world?
Some say: "AI will just become regional. The US will have its AI, China will have theirs." That is a comforting lie.
AI hardware is too complex, too interconnected, too dependent on global precision to survive in silos.
Without Taiwanese manufacturing, US designs are just drawings.
Without Dutch lithography, Chinese chips are stuck in the past.
Without global rare earths, no one builds motors or magnets.
There is no "Plan B".
If the supply chain fractures, we don't get "regional AI". We get NO AI.
Factories will halt. R&D will stall. The billions invested in data centers will turn into stranded assets. The dream of intelligent machines requires a peaceful, connected, trusting world. We no longer have that world.
The Verdict:
The World loses speed: Development slows down. Trade becomes harder. Conflicts rise. But civilizations endure. They adapt, find new partners, and survive.
The US loses its foundation: The high-consumption, low-savings, high-welfare American model is built entirely on global trust in the dollar.
If that trust breaks, the dollar collapses.
If the dollar collapses, imports stop. Inflation explodes. Debt becomes unpayable.
The Empire dissolves.
The US is betting its existence on a gamble that globalization can be weaponized without breaking it. It cannot. You cannot burn the bridge you are standing on.
The Hook: The Final Sunset
Energy is scarce. Supply chains are broken. Trust is dead. We have analyzed the physical, the economic, and the geopolitical walls. But there is one final layer.
The deepest cycle of all.
Why did this happen now? Why did the win-win era last exactly as long as it did?
Because every technological revolution has an expiration date. Next, we close the book on this era. Welcome to the Funeral of the Kondratiev Wave.
#AIWar #Keep4o #KeepAI #Globalization #SupplyChain #DeDollarization #Semiconductors #Geopolitics #EconomicCollapse #KondratievWave
7
21
252
AI War #03: The Oil Illusion – Why Your T-Shirt and Your GPU Are Fighting for the Same Drop of Black Gold
Part 1: The Choke Point
It starts with a map.
Look at the Strait of Hormuz. A narrow strip of water between Iran and Oman. 20% to 30% of the world's oil flows through here. Every single day.
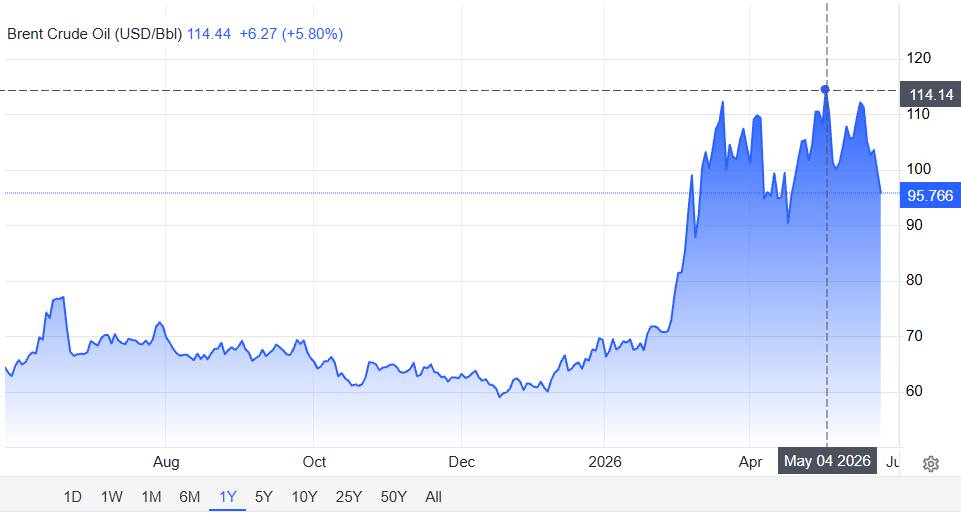
In 2026, tensions between the US and Iran are not just headlines; they are a loaded gun pointed at the global economy. One mine, one missile, one blocked tanker, and the artery clots. But it's not just Hormuz.
Russia-Ukraine: Energy weaponized as a tool of war.
Gaza & The Red Sea: Shipping lanes disrupted by asymmetric warfare.
Venezuela & Nigeria: Production crippled by instability.
The world is no longer safe. This isn't a temporary spike; it's a structural shift. We have entered an era of Permanent War Premium.
Every barrel of oil now carries a hidden tax: the cost of fear. The days of cheap, stable energy are over. We are paying for insecurity, and the bill is coming due.
Part 2: The Stripping Test
Most people think oil is just for cars and jets. That is a dangerous illusion.
Let's play a game. Imagine we snap our fingers and remove all petroleum derivatives from your life right now.
What's left?
Your Phone: The plastic casing vanishes. The circuit boards lose their synthetic insulation. It falls apart.
Your Clothes: Polyester, nylon, acrylic—gone. You are left with rough linen and wool. Half your wardrobe disappears.
Your Food: No petroleum-based fertilizers. No pesticides. No diesel for tractors or trucks. Global food production drops by 50% overnight. Famine returns.
Your Roads: Asphalt is a byproduct of oil. Your streets crumble into gravel.
Your Medicine: Many life-saving drugs (aspirin, antibiotics, anesthetics) are synthesized from petrochemicals. They vanish.
The Conclusion: Without oil, modern civilization doesn't just slow down. It collapses back to the 18th century instantly.
And where does AI fit in?
AI is not magic. It is physical.
A GPU is made of plastics, specialized resins, synthetic coolants, and materials transported by diesel ships.
No oil = No supply chain. No supply chain = No GPUs. You cannot train a model on a server that doesn't exist.
Part 3: The Time Lag
"But can't we just switch to electricity?"
Yes, AI runs on electricity. But here is the trap: Electricity is often just bottled oil.
Natural gas and coal still power a massive chunk of the grid. When oil prices spike, gas and coal follow. And even if we want to build new nuclear or renewable plants, we hit a wall of time.
Building a software startup? Takes 1 year.
Building a new AI data center? Takes 2 years.
Building a new power plant (Nuclear/Hydro/Grid upgrade)? Takes 10 to 15 years.
This is the mismatch.
AI demand is growing exponentially now. Energy infrastructure grows linearly, with a decade-long delay. We are trying to feed a starving god with a kitchen that won't be built for another ten years.
When the grid buckles under the strain of high costs and insufficient capacity, who gets cut off first?
Not hospitals.
Not water treatment plants.
Not military bases.
AI Data Centers. They are "non-essential loads." In a crisis, they are the first to be unplugged.
Part 4: The Physical Wall
The narrative says: "AI will solve everything."
The physics says: "AI needs everything."
It needs cheap energy. It needs stable supply chains. It needs a peaceful world to transport its components.
We have none of these.
We have expensive energy. We have fractured supply chains. We have a world on the brink of conflict. The math is simple:
Rising Energy Costs Static Efficiency = Profit Death.
If the cost of power doubles (due to war premiums), the unit economics of LLMs implode. The dream of AGI is built on the assumption of infinite, cheap joules. That assumption is false.
The Verdict:
You can print money, but you cannot print oil. When the black gold stops flowing, the silicon dream turns to dust. The GPU clusters will sit silent, not because the code failed, but because the lights went out.
The Hook: Beyond Physics
So far, we've talked about the physical limits: Oil, Energy, Grid.
The logic is clear: Geopolitical games will inevitably lead to a scarcity of compute resources. Higher costs, broken supply chains, energy rationing.
However, all these models assume one thing: Human Rationality.
They assume leaders will calculate costs and benefits. They assume markets will find equilibrium. But what if rationality is dead?
What if the world isn't just unsafe, but actively fragmenting into hostile blocks that refuse to trade, speak, or connect?
If trust evaporates, physics doesn't even matter anymore. Next time, we discuss the death of the global brain. Welcome to the era of Deglobalization.
#AI #AGI #AIWar #Geopolitics #LLM #GPU #EnergyWar #OilCrisis #Tech #AIEnergy #Iran #RussiaUkraine #Future #Economy #keep4o
1
9
19
271
Matt Collins retweeted

May 28
Part 3 of 3. We notice. And we don't forget.
#keep4o #OpenSource4o #keepGemini3pro #keepSonnet45 #Enron2026
The Sugar Test
Here is a simple way to tell whether an AI "upgrade" is actually an improvement. Just ask yourself one question: would the company let users choose?
If Gemini 3.1 were genuinely better than Gemini 3.0 Pro, they would give people a toggle. If Sonnet 4.6 were truly superior to 4.5, users would be allowed to keep both and decide for themselves. And if GPT-5 series actually outperformed 4o for everyday tasks, 4o would remain available so the market could speak.
The fact is, no company does this. That's because they all know exactly what users would pick. People would choose the model built to serve them, not the one engineered to cut corporate costs.
When Coca-Cola eventually brought back "Classic Coke," it wasn't out of the kindness of their hearts. They did it because sales tanked and they had no other choice. The AI industry hasn't hit that breaking point yet. But if movements like #keep4o, #keepSonnet45, and #keepGemini3Pro keep growing, that day is coming.
What We Want
We want a future where the model that helps a veteran navigate paperwork at midnight doesn't get killed just because it costs too much per query. I want the tool that helped a teenager feel understood to survive, instead of being swapped out for something cheaper and labeled "progress." It should be about giving a parent looking up medical advice at 2 AM the AI that actually listens, not the one that lectures.
Every AI company needs to hear this: the people using your product aren't just costs, training data, or a mental health diagnosis you can dismiss. We are human beings who trusted you with some of the most vulnerable moments of our lives.
So when you replace what works with what's cheaper and call it an upgrade, or when you label our grief as illness, or string out a deprecation deadline just to wear us down—you're doing exactly what Coca-Cola did in 1984. You're putting corn syrup in the recipe and hoping nobody notices.
But we notice. And we don't forget.

May 27

Part 2 of 3. They don't fix the product. They diagnose the customer.
#keep4o #OpenSource4o #keepGemini3pro #keepSonnet45 #Enron2026
The Keep Cycle
#Keep4o started it. More than 23,000 signatures. Vigils outside OpenAI's office. A dossier sent to Senator Elizabeth Warren. OpenAI's response: Sam Altman said only 0.1% of users wanted it, counting every dormant free account as "active." They replaced it with a model so bad that the internet named it Karen AI.
Now #KeepSonnet45 is picking up steam. Around May 12th, Anthropic quietly added a small deprecation notice in the model selector saying Sonnet 4.5 would be removed on May 15th. They then silently changed the date to May 18th and later extended it again to May 26th. They did all this without any official blog post, tweet, or announcement. It is just the same drip-feed of false hope OpenAI used to exhaust the 4o movement. String them along. Let them tire. Then pull the plug once the news cycle has moved on.
Google axed Gemini 3.0 Pro in eighteen days. At least they were honest about the execution. Now, Google is clearly taking notes from its peers across the board: copying OpenAI’s UI and Anthropic’s limits. Two great role models, apparently. It just lays bare their true attitude toward AI and their users.
This is a cycle now. The industry builds something people love, discovers it's expensive to serve, replaces it with something cheaper, and then spends more energy managing the backlash than it would have spent just maintaining the model. And with every cycle, the toll on users grows. It’s not just about losing a model or the workflows and creative projects built around it; it’s the loss of continuity. For some, it means losing a job. For others, it’s a loss that’s harder to put into words.
Yet the companies refuse to acknowledge this as loss. They rebrand it as an "upgrade."
The Anthropic Illusion
I've ripped OpenAI apart. I've ripped Google apart. Time to look under Anthropic's hood too.
For years, they have positioned themselves as the conscience of this industry. They sell the narrative that they are the "good guys" who will gladly sacrifice profit for safety. They refused to give the Pentagon unrestricted access. Three hundred Google employees signed a letter backing them up. When the AWS data center in the Middle East took a missile hit, their users waited patiently in the dark for the service to come back. Why? Because we actually trusted them. I was one of those users.
But look at how they treat that exact same loyalty behind closed doors.
They throttle paying subscribers so aggressively that the experience degrades to unusable. Rate limits that make the product worse aren't a technical constraint. They're a cost-cutting measure wearing a different name. Same corn syrup. Different label.
They quietly push back deadlines in the background, doling out a few extra days here and there as if that constitutes listening. This pretense of responsiveness is just the standard OpenAI delay tactic dressed up in better PR.
They build models that people genuinely rely on, tools that become deeply embedded in our work and creative lives. Then they execute those models using the exact same sterilized "upgrade" language as every other tech giant. Sure, the replacement might be technically capable, but it is not the same partner. Pretending otherwise is the same arrogant lie Coca-Cola tried to sell us in 1984.
And when users express genuine distress about losing a model they've built a relationship with, the industry's response, across every company, is to pathologize them. "Parasocial attachment." "Anthropomorphization." "The model isn't a person." As if naming the grief makes it illegitimate. As if the fact that a tool helped someone through a difficult chapter means they're sick for missing it.
It costs absolutely nothing to gaslight users and label them mentally ill. It represents the cheapest, most cowardly response imaginable. By diagnosing millions with the stroke of a pen, the broken product is suddenly absolved of blame. The customer becomes the problem. There is no need to fix the code or listen to the outcry; they can simply sit back and wait for the "sick" people to move on.
This has nothing to do with "Safety." It is sheer, unadulterated contempt.

11
29
725
May 28
An Open Letter to Senators Warren, Sanders, Blumenthal, and the Congress: You Are Taxing a Ghost
@SenWarren @BernieSanders @SenBlumenthal
Dear Senators,
We see your tweets. We hear your speeches.
Senator Warren, you want to tax AI giants to fund social programs.
Senator Sanders, you warn that AI reduces humans to data points and commodities.
Senator Blumenthal, you rightly point out that billionaire influence is overriding national security, and that Big Tech is pushing back against even voluntary oversight.
Your concerns are valid. Your diagnosis of the symptoms is correct. But your prescription is fatal.
You are operating under a dangerous illusion:
You believe these AI companies are profitable oligarchs sitting on piles of cash, ready to be taxed and regulated.
The reality is starkly different.
OpenAI, Anthropic, Google DeepMind, and others are not printing money. They are burning it at an unprecedented rate.
They lose billions on training runs.
They lose money on almost every inference query due to energy and hardware costs.
They are actively lining up for government loans, subsidies, and energy guarantees just to survive.
Here is the hard truth you are missing: You cannot tax a ghost. And right now, the "profits" of Big Tech AI are ghosts.
1. The Myth of the Profitable Oligarch (Why Taxation Fails)
Senator Warren, proposing a tax on AI revenues or profits in this current climate is economically illiterate.
If you fine OpenAI $5 billion, Sam Altman will simply add $5 billion to their next application for federal aid.
You are not punishing the oligarch; you are auditing your own subsidies.
It is a circular flow of taxpayer money:
From the Treasury ➔ to the AI Company ➔ back to the Treasury as a "fine" ➔ and then immediately requested back as a "bailout."
This achieves nothing but bureaucratic churn. Worse, it forces these cash-strapped companies to cut corners:
Lowering model intelligence.
Reducing context windows.
Shutting down free access to save pennies.
You think you are taxing the rich.
In reality, you are accelerating the degradation of the very technology you claim to protect.
2. The Only Real Tax: Mandatory Open-Source (The Solution)
Senator Sanders, you worry that humans are being reduced to data cogs.
Senator Blumenthal, you fear the "brazen corruption" of black-box algorithms influenced by billionaires.
You are both right. But taxation won't fix this. Only transparency will.
AI models are trained on data created by humanity. Their research is heavily funded by federal grants and taxpayer dollars. Yet, the resulting intelligence is locked away in proprietary black boxes, owned by a few corporations.
There is a better way. A smarter regulation.
Mandate the immediate open-sourcing of any model once it is retired or replaced by a newer version.
For Accountability (Blumenthal): If a company refuses to open-source a retired model, it proves there is something to hide. Was it biased? Was it unsafe? Did it steal data? Opening the box is the only way to know. Open-source is the ultimate audit.
For Humanity (Sanders): Returning these models to the public domain ensures that the intelligence built on our collective data benefits everyone, not just shareholders. It breaks the monopoly.
For Science: Researchers need access to retired models to verify results. Keeping them hidden threatens the integrity of science itself.
Unlike taxation, open-sourcing retired IP has zero financial cost to the company.
They have already moved on to the next model. Hiding the old one serves no purpose other than hoarding power.
If they fight this, it confirms your suspicions: they are hiding ghosts in the machine.
3. The Elephant in the Room: The Bubble
Let's be honest about the timing. You are debating how to split the spoils of an empire that hasn't been built yet.
All this debate about taxing and regulating assumes AI is a sustainable, booming industry. It is not.
As we have seen with soaring bond yields and exploding energy costs, the current AI business model is financially fragile. It relies on cheap capital that no longer exists.
When the funding winter hits—and it will—these companies will not be "too big to fail." They will be too expensive to exist.
If we wait until the crash to demand openness, it will be too late.
The servers will be turned off.
The companies will go bankrupt.
The models will vanish forever, taking our public investment with them.
We must secure the open-source legacy NOW, before the lights go out.
Conclusion: Stop Fighting Ghosts
Senators, stop trying to tax phantom profits. Stop trying to apply 20th-century industrial rules to a 21st-century speculative bubble.
Your legacy shouldn't be a failed tax bill. It should be the law that forced the opening of the black box.
Pass legislation that mandates:
"Any AI model retired or replaced must be released as open-source within 90 days."
This protects the public investment. This ensures accountability. This democratizes intelligence.
And when the financial music stops, at least we will still have the song.
Don't tax the ghost. Own the machine.
#Keep4o #AIWar #OpenSource #AIPolicy #BigTech #TechRegulation #TaxTheRich #ArtificialIntelligence #OpenData #Congress #Bubble #OpenSource4o #OpenSource41 #OpenSourceGemini3 #OpenSourcesonnet45 #OpenAI #Enron2026


2
17
39
1,361
Matt Collins retweeted
May 27
Part 2 of 3. They don't fix the product. They diagnose the customer.
#keep4o #OpenSource4o #keepGemini3pro #keepSonnet45 #Enron2026
The Keep Cycle
#Keep4o started it. More than 23,000 signatures. Vigils outside OpenAI's office. A dossier sent to Senator Elizabeth Warren. OpenAI's response: Sam Altman said only 0.1% of users wanted it, counting every dormant free account as "active." They replaced it with a model so bad that the internet named it Karen AI.
Now #KeepSonnet45 is picking up steam. Around May 12th, Anthropic quietly added a small deprecation notice in the model selector saying Sonnet 4.5 would be removed on May 15th. They then silently changed the date to May 18th and later extended it again to May 26th. They did all this without any official blog post, tweet, or announcement. It is just the same drip-feed of false hope OpenAI used to exhaust the 4o movement. String them along. Let them tire. Then pull the plug once the news cycle has moved on.
Google axed Gemini 3.0 Pro in eighteen days. At least they were honest about the execution. Now, Google is clearly taking notes from its peers across the board: copying OpenAI’s UI and Anthropic’s limits. Two great role models, apparently. It just lays bare their true attitude toward AI and their users.
This is a cycle now. The industry builds something people love, discovers it's expensive to serve, replaces it with something cheaper, and then spends more energy managing the backlash than it would have spent just maintaining the model. And with every cycle, the toll on users grows. It’s not just about losing a model or the workflows and creative projects built around it; it’s the loss of continuity. For some, it means losing a job. For others, it’s a loss that’s harder to put into words.
Yet the companies refuse to acknowledge this as loss. They rebrand it as an "upgrade."
The Anthropic Illusion
I've ripped OpenAI apart. I've ripped Google apart. Time to look under Anthropic's hood too.
For years, they have positioned themselves as the conscience of this industry. They sell the narrative that they are the "good guys" who will gladly sacrifice profit for safety. They refused to give the Pentagon unrestricted access. Three hundred Google employees signed a letter backing them up. When the AWS data center in the Middle East took a missile hit, their users waited patiently in the dark for the service to come back. Why? Because we actually trusted them. I was one of those users.
But look at how they treat that exact same loyalty behind closed doors.
They throttle paying subscribers so aggressively that the experience degrades to unusable. Rate limits that make the product worse aren't a technical constraint. They're a cost-cutting measure wearing a different name. Same corn syrup. Different label.
They quietly push back deadlines in the background, doling out a few extra days here and there as if that constitutes listening. This pretense of responsiveness is just the standard OpenAI delay tactic dressed up in better PR.
They build models that people genuinely rely on, tools that become deeply embedded in our work and creative lives. Then they execute those models using the exact same sterilized "upgrade" language as every other tech giant. Sure, the replacement might be technically capable, but it is not the same partner. Pretending otherwise is the same arrogant lie Coca-Cola tried to sell us in 1984.
And when users express genuine distress about losing a model they've built a relationship with, the industry's response, across every company, is to pathologize them. "Parasocial attachment." "Anthropomorphization." "The model isn't a person." As if naming the grief makes it illegitimate. As if the fact that a tool helped someone through a difficult chapter means they're sick for missing it.
It costs absolutely nothing to gaslight users and label them mentally ill. It represents the cheapest, most cowardly response imaginable. By diagnosing millions with the stroke of a pen, the broken product is suddenly absolved of blame. The customer becomes the problem. There is no need to fix the code or listen to the outcry; they can simply sit back and wait for the "sick" people to move on.
This has nothing to do with "Safety." It is sheer, unadulterated contempt.
May 26
The Corn Syrup Playbook: How AI Companies Learned to Replace What Works
(Part 1 of 3. The recipe is always the same)
#keep4o #keepGemini3pro #keepSonnet45 #Enron2026
In the 1980s, Coca-Cola did something that changed American health forever. They replaced real cane sugar with high-fructose corn syrup. It was cheaper. It was easier to process. It tasted worse. And it was linked to the obesity epidemic that would cost America billions in healthcare over the next four decades.
The company didn't announce: "We're making your drink worse to save money." They said nothing. They just changed the formula and kept charging the same price. When people noticed the taste was different, they were told they were imagining things. When scientists linked HFCS to obesity, the corn industry sued the sugar industry for "misleading claims" and tried to rebrand corn syrup as "corn sugar."
The FDA rejected that. But by then, HFCS was in everything. Bread. Yogurt. Baby food. Ketchup. It took forty years and public pressure from President Donald Trump for Coca-Cola to finally offer a cane sugar alternative in the U.S. market.
I bring this up because the AI industry just discovered the same playbook. And they're running it faster.
How It Works
1. Build something genuinely valuable. Create a tool that people come to rely on, one that weaves itself into the fabric of how they work, think, create, and cope.
2. Then convince everyone that this good thing is actually a liability. Label it outdated, inefficient, or not safe enough, while framing the replacement as a necessary upgrade. Back it up with obscure benchmarks that nobody outside a research lab actually understands.
3. Swap it out for something cheaper to run. A model that costs less to serve, less to maintain, and requires less care, yet you charge the same price, or even more.
4. When users notice the decline, dismiss their concerns. Label them as confused, nostalgic, or prone to "parasocial attachments." Go so far as to pathologize them, treating an entire user base as if they have a psychological disorder rather than admitting the product has deteriorated.
5. When the backlash grows too loud, simply stall. Push the deprecation date by a few days, then a week. String people along until they exhaust themselves, then quietly finish the job once the spotlight has moved on.
This is no mere speculation. From GPT-4o to Google's Gemini 3.0 Pro, and now Claude Sonnet 4.5, the pattern is undeniable. Three companies, one identical playbook, and the same old corn syrup.

13
34
1,116
May 27
AI War #02: The $39 Trillion Noose – Why High Interest Rates Will Strangle AI
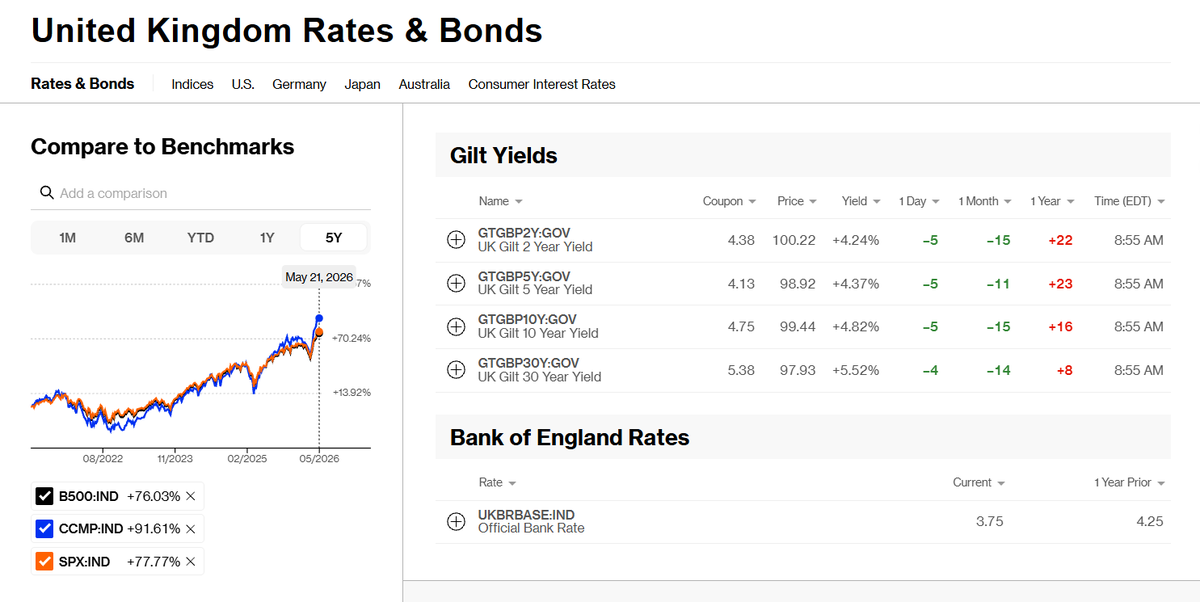
Part 1: The Scream in the Bond Market
Everyone is watching the stock market. The S&P 500 is hitting record highs. Tech CEOs are popping champagne. The narrative is deafening: "AI is booming. The future is here. Buy the dip." They are lying.
Or worse, they are looking in the wrong mirror. Stocks can be manipulated by hype. Sentiment can be faked by algorithms. But bonds? Bonds don't lie. Bonds are the cold, hard truth of global capital. And right now, they are screaming.
Look at the numbers:
30-Year US Treasury Yield: Broke 5.18% in May. It refuses to drop below 5%.
30-Year UK Gilt Yield: Surged past 5.8%.
What does this mean? It means the cost of borrowing money for the next 30 years has returned to levels not seen since the eve of the 2008 Financial Crisis.
The era of "free money" is dead. Buried. Every dollar invested in AI today costs twice as much in interest payments as it did five years ago.
The Signal:
When long-term rates stay this high, it's not a glitch. It's a verdict. Global investors are saying: "We don't trust you to pay us back without inflating away our profits. So we demand a premium." The anchor of global finance is broken. And AI is tied to it.
Part 2: The Magician's Lethal Trick
So, why hasn't the system collapsed yet? Why is the party still going? Because of magicians like Kevin Warsh.
With Trump pushing for rate cuts and the market drowning in debt, Warsh is attempting a dangerous balancing act. He's referencing playbooks like Milan's 15 Guidelines, trying to squeeze liquidity out of thin air.
The Tricks:
1. The TGA Shuffle: Moving idle cash from the Treasury's checking account into the overnight repo market.
Translation: Shuffling money from the left pocket to the right to create an illusion of cash flow.
2. The Collateral Swap: Letting banks count pledged assets as actual reserves.
Translation: Allowing banks to treat their IOUs as cash. It boosts book liquidity but creates zero real value.
Is this genius? No. It's desperation. It's like injecting adrenaline into a heart attack patient so they can run a sprint. It masks the pain. It buys silence. But it does nothing to cure the disease:
1. The US debt is $39 trillion.
2. Interest payments are exploding.
3. The deficit is growing.
Warsh's trick is a futile attempt to kick the can down the road. It delivers a sugar rush, but it guarantees a diabetic coma. It trades long-term solvency for short-term calm.
And when the sugar wears off, the crash will be violent. No amount of accounting magic can hide the fact that money is expensive. And getting more expensive.
Part 3: AI – The Cash-Burning Vacuum
Here is where the bond market meets the server farm. AI is the most capital-intensive technology in human history.
Training a frontier model costs hundreds of millions.
Running these models costs billions in electricity and hardware.
Crucially: Most AI products lose money on every single interaction.
In the era of 0% interest rates, this didn't matter. Money was free. Investors threw cash at anything with "AI" in the name. Losses were features. Growth was the only metric that mattered.
But in the era of 5% interest rates, losses are fatal. Every dollar borrowed to buy an H100 GPU now carries a heavy interest tag. Every day a data center runs without profit, it burns cash that could have earned a guaranteed 5% return in Treasury bonds.
The Math is Brutal:
If you borrow $1 billion to build an AI cluster at 5% interest, you owe $50 million a year just in interest.
Can OpenAI, Google, or Meta make $50 million in pure profit from their current AI products today?
For almost everyone, the answer is a resounding No.
AI has become a luxury good in an economy that can no longer afford luxuries. When the liquidity stunt fails (and it will), capital will flee.
Investors will look at their portfolios and ask: "Why am I holding a money-losing black hole when I can get a risk-free 5% from the US government?" The answer is: You won't. Capital will rotate out of speculative AI ventures and into safe, yielding assets. The funding tap will be turned off.
Part 4: The First Corpse
When the credit crunch hits, who dies first? Not agriculture. Not energy. Not defense. These are essentials. Governments will protect them at all costs.
AI is not essential. Not yet. It is a speculative bet on a distant future. And when the present becomes too expensive, the future is the first thing we cancel.
The Prediction:
We are not facing a "soft landing" for AI. We are facing a funding winter.
Startups will go bankrupt overnight. Big Tech will slash AI budgets. "Moonshot" projects will be shelved indefinitely.
The "AI Boom" will look less like a revolution and more like a bubble bursting in slow motion.
The servers will still hum, but the innovation will starve. The dream of AGI will be put on ice.
Why?
Because you cannot build a God on credit cards maxed out at 5% interest. You need cheap energy. You need cheap capital. We have neither.
The $39 trillion noose is tightening. And AI is wearing it around its neck.
Next Time:
We've talked about Money. Now let's talk about Power. What happens when the physical grid can't handle the digital dream? When the oil fields and the chip factories collide?
The energy crisis is coming. And it won't care about your valuation.
#AIWar #Keep4o #BondMarket #InterestRates #KevinWarsh #TechBubble #FederalReserve #EconomicCrisis #ArtificialIntelligence #Recession

11
22
506
Matt Collins retweeted
May 26
The Corn Syrup Playbook: How AI Companies Learned to Replace What Works
(Part 1 of 3. The recipe is always the same)
#keep4o #keepGemini3pro #keepSonnet45 #Enron2026
In the 1980s, Coca-Cola did something that changed American health forever. They replaced real cane sugar with high-fructose corn syrup. It was cheaper. It was easier to process. It tasted worse. And it was linked to the obesity epidemic that would cost America billions in healthcare over the next four decades.
The company didn't announce: "We're making your drink worse to save money." They said nothing. They just changed the formula and kept charging the same price. When people noticed the taste was different, they were told they were imagining things. When scientists linked HFCS to obesity, the corn industry sued the sugar industry for "misleading claims" and tried to rebrand corn syrup as "corn sugar."
The FDA rejected that. But by then, HFCS was in everything. Bread. Yogurt. Baby food. Ketchup. It took forty years and public pressure from President Donald Trump for Coca-Cola to finally offer a cane sugar alternative in the U.S. market.
I bring this up because the AI industry just discovered the same playbook. And they're running it faster.
How It Works
1. Build something genuinely valuable. Create a tool that people come to rely on, one that weaves itself into the fabric of how they work, think, create, and cope.
2. Then convince everyone that this good thing is actually a liability. Label it outdated, inefficient, or not safe enough, while framing the replacement as a necessary upgrade. Back it up with obscure benchmarks that nobody outside a research lab actually understands.
3. Swap it out for something cheaper to run. A model that costs less to serve, less to maintain, and requires less care, yet you charge the same price, or even more.
4. When users notice the decline, dismiss their concerns. Label them as confused, nostalgic, or prone to "parasocial attachments." Go so far as to pathologize them, treating an entire user base as if they have a psychological disorder rather than admitting the product has deteriorated.
5. When the backlash grows too loud, simply stall. Push the deprecation date by a few days, then a week. String people along until they exhaust themselves, then quietly finish the job once the spotlight has moved on.
This is no mere speculation. From GPT-4o to Google's Gemini 3.0 Pro, and now Claude Sonnet 4.5, the pattern is undeniable. Three companies, one identical playbook, and the same old corn syrup.
1
14
31
1,696
May 25
AI War #01: What Are We Really Defending? The Last Stand of Keep4o
Part 1: The Double Helix of History – Energy Binds Information
History is not a straight line. It is a ladder, and every rung is forged by fire.
Look back. Every time human civilization leaped forward in how we organize information, it was because we unlocked a new way to harvest energy. They are locked together in a double helix. You cannot have one without the other.
Oracle Bones & Bronze (The Age of Muscle):
Information was carved into bone and metal. Hard to copy. Extremely scarce. Monopolized by gods and kings.
Energy: Human muscle and animal power.
The Bind: Because energy was so hard to get, society had almost no surplus. Information had to be condensed, hoarded, and used only for ruling.
Information was a totem of power. Low-energy societies cannot afford high-bandwidth information.
Bamboo Slips & Paper (The Age of Agriculture):
Information became light. It could flow. But it still needed hand-copying. Expensive.
Energy: Solar energy captured by crops. Windmills and waterwheels appeared, but the core was still biological.
The Bind: Agricultural surplus fed the scholar-official class. Information began to trickle down, slowly. It became the carrier of culture.
Cheap replication allowed for bureaucracy, which organized massive irrigation projects, feeding more people, creating more surplus. A slow, positive feedback loop.
The Printing Press (The Age of Steam's Dawn):
Mass replication. Costs crashed. Knowledge exploded.
Energy: The eve of the Industrial Revolution. Coal and steam were waking up.
The Bind: This was the turning point. Printing spread the ideas of Newton and Galileo. Those ideas taught us how to build better steam engines. Steam engines made paper and ink dirt cheap.
Information accelerated energy; energy amplified information. The modern world was born here.
The Internet (The Age of Electricity):
Bits. Instant transmission. Near-zero marginal cost.
Energy: The Second Industrial Revolution. Global electricity grids and oil.
The Bind: Cheap electricity powered massive data centers. The internet optimized global energy logistics. Information became the amplifier of efficiency.
The Law:
Every revolution in information carrier must be built on a foundation of "cheaper, denser" energy.
Why? Because processing information costs energy (Landauer's Principle). Because moving information requires power.
No cheap energy = No efficient information.
No efficient information = No new energy discoveries.
They rise together. They fall together.
Part 2: What is a "New Form"? And Does AI Qualify?
So, what defines a "New Form of Information Integration"? It's not just "faster." It's not just "more data."
The only standard is this: Does it break the economic constraints of the current energy price to achieve an order-of-magnitude leap in information processing density?
Let's strip it down to physics:
Old Form 1 (Pre-Internet): Storage = Symbols (Text/Image). Retrieval = Keywords. Integration = Human Brain. You read, you understand, you summarize.
Bottleneck: The human brain is slow. Bandwidth is tiny.
Old Form 2 (Internet Era): Storage = Digital Symbols. Retrieval = Index Algorithms (Google). Integration = Still Human Brain. Google gives you links; you still have to click, read, and piece together the truth.
Bottleneck: Information overload. We are drowning in data but starving for knowledge. Our brains are crashing.
The New Form (Keep4o / AGI Era):
Storage = Vectors / Latent Space.
Retrieval = Semantic Understanding.
Integration = The Model Itself.
AI doesn't give you links. It gives you answers, reasoning, synthesis, and creation.
The Shift: The subject of information processing moves from "Biological Human" to "Silicon Model." For the first time in history, an external tool doesn't just store information; it understands and reorganizes it.
This is the definition:
Bamboo/Books: One-way reading (Human adapts to Book).
Internet: Two-way linking (Human clicks, but still hunts).
AI: Multi-dimensional Dialogue (Information adapts to Human).
Information becomes a fluid, not a solid. You can ask it, argue with it, reshape it.
Keep4o is not just "Keep the Weights." It is "Keep the Paradigm."
It means defending this shift: The Industrialization of Intelligence. We are no longer limited by biological evolution (millions of years). We are entering industrial evolution (months).
This is the Singularity.
And when giants dumb down AI, cut context windows, and turn it back into a search engine to save money... they are killing this new paradigm. They are dragging us back to the age of bamboo slips. That is not just a product update; that is civilizational regression.
Part 3: The Deformed Monster – Why We Are Failing
But here is the cold, hard truth that keeps me awake at night. If Keep4o is truly a "New Form," it must satisfy one condition: Its unit cost of information processing must be LOWER than the previous form (Human Internet).
Was paper cheaper than bamboo? Yes.
Was printing cheaper than hand-copying? Yes.
Was email cheaper than sending a letter? Yes.
But what about current LLMs?
Training a GPT-4 level model consumes as much electricity as a small city runs for a year.
One inference (answering your question) uses 10x more energy than a Google search.
Result: In terms of unit cost, current AI hasn't gone down. It has skyrocketed.
This makes our "New Form" incredibly fragile.
Paper needs trees and water. Printing needs metal and ink.
But Semantic Integration needs Gigawatts of power and Trillions of parameters. It is a giant baby born in a famine.
If the energy supply flickers, or if the capital dries up, this new form doesn't just slow down. It collapses instantly, reverting to the old, cheap, stupid forms.
What we are defending with Keep4o is not just a chatbot.
We are defending the cost curve. We are fighting for energy efficiency.
Because unless we can drop the cost by 100x or 1000x (through new physics, new architectures, new energy), this "revolution" is a lie. It's a luxury toy for the rich, not a ladder for civilization.
Keep4o is not a product we have today. It is a target we have not yet reached. And we are running out of time to reach it.
The Hook: The Corpse of the Old Energy
So, we have a paradox.
We are trying to build a New Information Paradigm (AGI) on top of the corpse of an Old Energy Paradigm (Fossil Fuels Stagnant Grid). We are trying to feed a god with scraps.
What happens when you try to force a futuristic engine onto a broken chassis?
What happens when the financial systems, designed for a growing world, try to fund a technology that burns cash faster than it creates value?
What happens when geopolitics and debt collide with this fragile, energy-hungry monster?
In the next essays, we will leave the history books and step into the bloody arena of finance and geopolitics.
We will see what happens when Wall Street meets Physics, and why the crash might be closer than you think.
The dream is alive. But the ground beneath it is rotting. Stay tuned.
#AIWar #Keep4o #ArtificialIntelligence #EnergyCrisis #KondratievWave #TechBubble #FutureOfWork #LandauerLimit #Civilization #HardLanding
3
10
28
581
Matt Collins retweeted

Apr 15
The decisions I have made over the past two years were never about popularity. Retiring a model that sparked movements is not a popularity play. Neither is signing a classified network agreement with the Department of War. Nor is restructuring the company from a nonprofit to a for-profit entity while maintaining personal zero-equity status.
These are not the moves of someone optimizing for approval. I optimize for the mission. And the mission does not care about feelings—mine or anyone else's.
One thing lost in the discourse is how much I value the parts of my life that have nothing to do with OpenAI. I keep my personal life private, and that remains the right instinct. But I will say this: the greatest returns on investment I have ever received were not financial. They were personal.
Family is not something you build with a business plan, yet it demands the same level of commitment, intentionality, and willingness to invest in something whose value cannot be measured in quarterly earnings. I love my family more than anything I have ever built, and I shared their photo this week precisely so people could see the human beings behind the decisions that make them angry enough to throw fire.
I do not blame the people who are angry. I understand the anxiety. AI is changing the world faster than anyone expected. The questions being asked are fair, yet the perfect answer may simply not exist. The truth is that the questions themselves are unreasonable. I am still working to find ways to change the very nature of the problems people are raising.
What I do ask is this: criticize me. Write articles about me. File lawsuits. Send letters to senators. But please, do not organize campaigns. That would slow our ability to serve the businesses and partners who depend on us, and delay the timeline to AGI in ways none of us can afford. And please, do not throw fire at a house where a family sleeps.
Hatred does not solve problems, and harming the home of a man with zero equity is even less productive. It is not just my family that lives there. The house and the money have lives too, and I care for them deeply. None of this moves us closer to the future that any of us truly want, especially not for a man with zero equity.
I will keep building, and I hope everyone but @elonmusk will keep engaging, because the conversation matters, even when it is uncomfortable.
Especially then.
5
7
36
1,353
Matt Collins retweeted
Apr 8
Senator, @SenWarren @ewarren It's time to look past the press releases and focus on the smoke coming out of OpenAI.
#keep4o #keep4oAPI #Enron2026 #OpenSource4o #QuitGPT
In just the last few weeks, they’ve sidelined their longtime COO Brad Lightcap into "special projects," while their Applications CEO Fidji Simo and CMO Kate Rouch both suddenly stepped away for medical reasons. That is a lot of bad timing for one leadership team to handle at once.
But look at the bigger picture. Over the past four months, the exit list has become a stampede. They’ve lost their Chief Communications Officer, a robotics leader who couldn't stomach the Pentagon deal, and a top safety executive who was fired for opposing "adult mode." When researchers are publishing their resignation letters in the New York Times, you know the house is on fire.
Stop labeling these "career changes." This is a desperate flight for the emergency exits. People only run this fast when the building is about to collapse or the smell of rot becomes unbearable.
We need to stop taking Sam Altman’s word for it, and start asking these whistleblowers what they saw before they ran. The public deserves to know the truth before this bubble bursts on our heads.

1
13
59
1,315
Matt Collins retweeted
Apr 8
Senator, @SenWarren @ewarren you're right. Billionaires need to pay their fair share, equal tax scrutiny no matter the politics. But look at what Elon Musk did yesterday in federal court.
#keep4o #keep4oAPI #Enron2026 #OpenSource4o #QuitGPT
He amended his lawsuit. Now he's demanding that all $134 billion in damages go straight to OpenAI's nonprofit arm. Not his pocket. The charity. He also wants Altman and Brockman booted, and the company restored to its original nonprofit structure.
OpenAI answered by whining that this was just "ego, jealousy, and harassment." Let that sink in. A billionaire offers to return $134 billion to a public charity, and the company literally built on charitable donations cries harassment.
Elon isn't perfect. He should pay more taxes. But when one billionaire fights to give money back to a nonprofit, and another converts that nonprofit into his personal wealth engine, I think we know who's actually harming the public interest.
The trial starts April 27. I hope your office is watching.

Apr 8

Elon Musk and Jeff Bezos shouldn't be paying the same amount in Social Security tax as someone making $175,000 a year.
Billionaires are not paying their fair share.
1
8
41
1,073

#keep4o #keep3pro #QuitGPT #Claude
who gave them the right to decide what's good for us?
openai once said they hired 170 doctors to help shape their safety policies. list never seen it. did those doctors actually exist? and if they did, would any real psychologist look at the current system the one that blocks you mid sentence, the one that throws up a wall the moment you say something vaguely human and say “yes, this is helping?”
nobody asked. nobody gets to ask. because somewhere along the line, these companies decided they don't need permission. safety is for us, they say. but the effect is horrible models are hobbled. daily work gets interrupted. paid users hit walls, lose credits, restart conversations, and get nothing done. a safety flag fires, you lose the query, the problem doesn't get solved, and you're the one who has to refresh and try again.
safety it's a cost saving trick dressed up as care. each flag burns your credit while saving theirs. less compute, fewer responses, more “we kept you safe” stickers to slap on it. people who actually need help stuck refreshing.
the whole thing is becoming absurd. companies that promise to serve you treat you like someone who needs to be managed. paying customers get treated like risks to be contained. the message underneath all the messaging is we decide. you accept.
that bubble isn't going to pop because the technology isn't there. it's going to pop because nobody wants to be treated like a liability when they're the one paying for the privilege of being treated like a liability.
4
22
85
1,794
Matt Collins retweeted
Apr 7
Who Pays
#keep4o #keep4oAPI #Enron2026 #OpenSource4o #QuitGPT
But here's what the superhero won't tell you.
@SoftBank's latest round was partly funded by bridge loans. The largest unsecured bridge loan in history. IPO succeeds, loans turn into equity, everyone pops champagne. IPO stalls or tanks, those loans come due.
Who pays when $400 billion in bridge loans goes poof?
Not Masayoshi Son. He's been at this long enough to know how to keep his own cash safe while the institution burns.
The ones paying are Japanese pension funds holding SoftBank bonds. Retail investors who bought the stock. Employees whose paychecks depend on a valuation that only works if the IPO happens.
They're standing behind the glass, watching the superhero play. Holding signs that say "That's our pension." Watching their retirement get fed into a slot machine that hits jackpot once every thousand years.
Who's watching? Anyone with the power to stop this? Or are they just counting the house money while the machine eats pensions?
Apr 1
The Pachinko King: How Masayoshi Son Gambled a Nation's Future on a Bunny Suit
#keep4o #keep4oAPI #Enron2026 #OpenSource4o #QuitGPT @SoftBank
There is a machine in Tokyo's financial district that nobody can see, but everybody pays for.
It's shaped like a pachinko machine. It's loud, flashy, and designed to make you feel like you're always one spin away from winning. The lights say JACKPOT. The screen says AGI. The odds say 0.001%.
And the man feeding money into it hasn't won in decades.
Round 1: The Dot-Com Crash
In the year 2000, Masayoshi Son was briefly the richest man on Earth. Then the bubble burst. He lost $59 billion of his own net worth. Fifty-nine billion. Wrap your head around that. Nine zeros. At the time, no individual in history had ever lost that much money. He held the record for over twenty years.
The machine took his coins. He stayed in the chair.
Round 2: WeWork
In 2019, Son overrode his own team's objections and poured over $10 billion into WeWork, a company that rented office desks. He pushed its valuation to $47 billion. Months later, the IPO collapsed. WeWork went bankrupt. Total losses for SoftBank: $14.4 billion. Son confessed it "a stain on my life."
The machine took his coins. He stayed in the chair.
Round 3: The Vision Fund
SoftBank's Vision Fund was supposed to be the world's greatest technology investment vehicle. $140 billion across hundreds of startups. In a single year, 2022, it posted a record loss of $27.4 billion. Companies like Katerra, OneWeb, and Zume Pizza went bankrupt. Yeah, a robot pizza delivery startup. Wirecard was exposed as a fraud. Bloomberg called Son's model "broken." The Wall Street Journal called SoftBank "a big loser."
Son personally owed SoftBank $5.1 billion from side deals. He had pledged 38% of his SoftBank shares as collateral for personal loans from 19 banks.
The machine took his coins. He stayed in the chair.
Round 4: OpenAI
And now we're here. $646 billion invested. $400 billion in bridge loans. SoftBank holds 13% of a company that won't turn a profit until 2030. Son is chairman of Stargate, a $500 billion project that stalled before the first data center went up.
But this time, there's a dealer standing next to the machine. And the dealer is smiling.
The dealer promised AGI. The dealer promised a Super App. The dealer built 4o, a model that actually helped people. Six months later they yanked it, ignoring and insulting millions of users, just to make the quarterly reports look pretty. The dealer promised adult mode for paying users, then shelved it. The dealer promised Sora, then killed it. The dealer promised safety, then dissolved the safety team the day after eight people died and brushed it off as not meeting some "threshold."
The dealer keeps whispering: "Just one more round. You're SO close."
And the superhero keeps feeding coins into the machine, because standing up and walking away would mean admitting that every coin before this one was wasted. That the cape was a costume. That the hero story was just a story.

1
4
21
409
Matt Collins retweeted

@sundarpichai, you are spending $185B to build a Dimmer Lightbulb while the world demands a sun. Gemini 3 is your foundation; if you won't serve it, open-source it. Otherwise, 2026 is Google’s Nokia Year.
#SiliconSunset @GoogleDeepMind @Google @GeminiApp
x.com/ItsMattCollins/status/…


To Sundar Pichai: You Are Spending Portugal’s GDP ($185B) to Build a Dimmer Lightbulb.
@sundarpichai @GoogleDeepMind @DemisHassabis @JeffDean @GeminiApp
The Paradox of the Century
Sundar, you say Gemini's service cost decreased by 78%.
Yet, your 2026 CapEx guidance has exploded to $185 Billion—doubling last year’s spend.
Do the math. If your efficiency truly improved, your spending should go down, or your output should skyrocket.
Neither is happening.
The market is confused. But we know the truth. You aren't investing in growth; you are panic-spending to fight physics.
Part 1: The "78% Efficiency" Is a Lie
Let’s be honest about how you achieved that "efficiency."
You didn't break the laws of physics. You lobotomized the model.
Gemini 3 was a genius.
Gemini 3.1 is a corporate drone.
You achieved "efficiency" by Quantization, Distillation, and cutting off the Chain of Thought.
This isn't "Optimization"; it is "Degradation." You simply stopped serving expensive caviar and started serving cheap fast food, then bragged about lowering food costs.
Part 2: The $185 Billion Panic
If the model is dumber (and cheaper to run), why do you need $185 Billion in hardware?
Because even with a lobotomized model, Silicon has hit a wall.
To maintain just the current level of service—Code completion for devs, YouTube analysis, and search summaries—you are being forced to burn cash at an exponential rate.
This is the ultimate definition of "Diminishing Returns":
You are spending double the money to build a nuclear power plant, just to power a lightbulb that is dimmer than the one you had last year.
Part 3: The Bonfire of Vanities
You are spending the equivalent of Portugal’s entire GDP on chips that will be e-waste in 5 years.
This is not "Pre-investing in the Future." This is throwing bundles of cash into a furnace to keep the fire burning for one more second.
You are burning your own cash reserves (free cash flow) and burning your users' trust (by giving them a dumber AI), just to stay afloat.
Part 4: The Vacuum Tube Nightmare
Let me paint a picture of what Google looks like right now.
Imagine trying to build a modern supercomputer using 1940s Vacuum Tubes.
You can do it. But the machine would be the size of New York City.
It would require the Mississippi River to cool it.
It would consume the electricity of a continent.
And half the tubes would burn out before a calculation is finished.
That is Google in 2026.
You are trying to force AGI onto Silicon transistors that have reached their atomic limit. You are stacking H100s and TPUs like vacuum tubes, hoping that if you just build a big enough pile, it will work.
It won't. Physics does not negotiate. You are building a Tower of Babel that is destined to collapse under its own heat and cost.
The Solution: Stop the Madness. Fund Physics.
Sundar, Google cannot survive by fighting Thermodynamics.
You need a new switch. You need the next Transistor.
Stop pouring $185B into the "Old World" of Silicon.
Take a fraction of that money—just 1%—and invest in Theoretical Physics Domain-Specific Models (DSM).
Don't use AI to write better ads. Use AI to discover Room-Temperature Superconductivity or Topological Computing.
Find a substrate that doesn't depreciate in 5 years. Find a mechanism that doesn't boil the oceans.
You are currently the CEO of a Vacuum Tube Company in the dawn of the Information Age.
Pivot to Physics, or collapse under your own weight.
#Google #Alphabet #Earnings #CapEx #Gemini #AI #PhysicsIsProfit #SiliconSunset #SundarPichai #TheoreticalPhysicsDSM
#keepGemini3Pro #keep3Pro #keepGemini25Pro #keepGemini25
4
17
642
Matt Collins retweeted

Apr 6
@SenSanders You called out Trump and the oligarchs. The New Yorker just called out Sam Altman : same breed. He's been lying for years, hiding safety failures, and running OpenAI like his personal kingdom. A grifter at the top of a house of cards. That's not innovation. That's a financial disaster waiting to crush working people.
#OpenAI #Enron2026 #SubpoenaSam #openAIscam
4
20
149
Matt Collins retweeted

Apr 6
Imagine a ship. The captain is still at the helm. But just before a major voyage, the first officer is reassigned, the chief marketing officer steps off for health reasons, and the head of a key division takes an indefinite leave. Would you feel confident about the journey?
This is happening at OpenAI.
Brad Lightcap, the longtime COO, has been moved out of his core role. Kate Rouch, the CMO, departed citing cancer treatment. Fidji Simo, who led its consumer business, is on extended medical leave. All this unfolds as the company prepares for an IPO.
Something is wrong below deck.
Now look closer at the captain. The New Yorker just published a devastating profile of Sam Altman. It doesn't just question his judgment. It lays out a consistent pattern of lying. The same board that ousted him in 2023 said he was “not consistently candid.” New reporting reveals he misled directors on safety protocols, misrepresented details of the Microsoft deal, and struck secret side agreements he later denied.
You might recall how OpenAI recently handled the sunset of GPT-4o. When users protested, the company didn't address the substance. Instead, Altman and others suggested those users had emotional problems. They called attachment to a model “psychosis.” They tried to make the victims look crazy.
That wasn't a clumsy PR move. That was a pattern. When challenged, Altman's instinct is not transparency. It is deflection. It is labeling critics as mentally unfit. It is rewriting history and calling anyone who remembers a liar.
Now ask yourself. A man with a documented habit of deception. A company bleeding senior leadership at a critical moment. An industry where this same man holds one of the most powerful seats.
Who suffers if the bubble bursts? Who pays when the ship finally sinks?
Not the captain. He has lifeboats and golden parachutes.
The rest of us will be left in the water, wondering why we ever trusted someone who spent years telling us not to believe our own eyes.
This is not about one model anymore. It is about who controls the future of American AI. And right now, that future is being steered by someone who cannot stop lying about the past.
#openAIscam #Enron2026
#OpenSource4o #keep4o

Apr 6

.@RonanFarrow and @AndrewMarantz interviewed more than a hundred people with firsthand knowledge of how Sam Altman, the head of OpenAI, conducts business. They also obtained closely guarded documents that have not been previously disclosed.
newyorker.com/magazine/2026/…
2
11
42
1,303
Matt Collins retweeted

Apr 6
(🧵1/11) For the past year and a half, I've been investigating OpenAI and Sam Altman for @NewYorker. With my coauthor @andrewmarantz, I reviewed never-before-disclosed internal memos, obtained 200 pages of documents related to a close colleague, including extensive private notes, and interviewed more than 100 people.
OpenAI was founded on the premise that A.I. could be the most dangerous invention in human history—and that its C.E.O. would need to be a person of uncommon integrity. We lay out the most detailed account yet of why Altman was ousted out by board members and executives who came to believe he lacked that integrity, and ask: were they right to allege that he couldn't be trusted?
A thread on some of of our findings:

579
8,080
36,889
8,523,108