
Assistant professor of computer science, mechanical engineering, and chemical and biological engineering @NorthwesternU.
Joined November 2014
- Tweets 851
- Following 410
- Followers 2,576
- Likes 4,163
168 Photos and videos














Jun 4
If you’re at #ICRA2026 stop by today’s Mechanisms, Design and Control session this afternoon to see Chen’s talk 🧨
robot-destruction.github.io/
⏰ 17:55-18:05
📍 Lehar 1-4
🪪 ThBT3.8
Apr 1

Attending #ICRA2026 🇦🇹🚞🍰 in May?
Chen Yu (@yc88888) will present the first robot that can redesign itself.
Starting with a randomly assembled body, the robot self-identifies parts that inhibit its locomotion and removes them through self-destruction.
youtu.be/-L8mlDEQong
1
310
Apr 1
Attending #ICRA2026 🇦🇹🚞🍰 in May?
Chen Yu (@yc88888) will present the first robot that can redesign itself.
Starting with a randomly assembled body, the robot self-identifies parts that inhibit its locomotion and removes them through self-destruction.
youtu.be/-L8mlDEQong
1
3
926

Sam Kriegman retweeted

These robots are born to run—and never die 🤖
Northwestern engineers developed the first modular robot with athletic intelligence. They can transform into new configurations and keep moving no matter what's thrown at them.
6
11
45
11,076
Mar 6
Sure your legged robot can learn, but can it evolve?
These robots can.
You can also chop them in half, they don’t mind. In fact, they like it.
paper: pnas.org/doi/10.1073/pnas.25…
website: modularlegs.github.io/
video: youtu.be/8VKSx1zSg7Q
2
4
21
1,516
Sam Kriegman retweeted

Jan 27
These robots are going to Rio 🇧🇷
See you at #ICLR2026

18 Feb 2025

New preprint. Accelerated co-design of robots through morphological pretraining. With @Kriegmerica.
We pretrained a universal controller in minutes through differentiable simulation. Then we used it as a prior for zero-shot and few-shot evolution to discover robots like this:
2
12
1,159
Sam Kriegman retweeted

15 Sep 2025
A research team with Professors Wei Chen and Ryan Truby harnessed physics, computation, and 3D printing to autonomously produce materials that change shape on demand.
spr.ly/6016APlO0

ALT “It’s a step toward smarter, more versatile materials that can do things traditional systems simply can’t.” A research team with Professors Wei Chen and Ryan Truby harnessed physics, computation, and 3D printing to autonomously produce materials that change shape on demand.
4
3
7
7,072
Sam Kriegman retweeted

3 Sep 2025
Be part of the next generation of virtual creatures:
Enter the 2025 Virtual Creatures Competition (VCC)!
Held at #ALIFE2025, the #VCC is an annual competition to showcase recent research in the field of artificial life.
Judges and prizes to be announced soon.
⬇️⬇️
1
16
38
4,237

We’ve all seen humanoid robots doing backflips and dance routines for years.
But if you ask them to climb a few stairs in the real world, they stumble!
We took our robot on a walk around town to environments that it hadn’t seen before. Here’s how it works🧵⬇️
37
140
807
270,482
5 Aug 2025
“This type of robot… is rarely seen in any applications. Unless the authors can show that this type of robot is widely use or will be widely used, the research in this paper is meaningless.” —Reviewer Xjm2, NeurIPS 2025
2
994
Sam Kriegman retweeted
29 Jul 2025
Professor Ryan Truby (@TrubyLab) developed a soft artificial muscle, paving the way for untethered animal- and human-scale robots. The new actuators provide the performance and mechanical properties required for building robotic musculoskeletal systems.
spr.ly/6018fr932
4
12
10,085
Sam Kriegman retweeted

25 Jun 2025
My ICRA Keynote: “Robot Learning in Isolation”
This keynote talk is about technical paths for systems that do not have communications and are operating in novel environments, building machine learning models from scratch as they go.
youtube.com/watch?v=hcYrL820…
3
14
1,101
Sam Kriegman retweeted

18 Jun 2025
Tired of tuning PPO or blaming it on reward, task design, etc.? Introducing EPO -- our second (and hopefully final :) attempt at fixing PPO at scale!
Contrary to intuition, as the batch size or data increases, PPO saturates due to a lack of diversity in sampling. We proposed a solution in SAPG (sapg-rl.github.io/) by incorporating an ensemble at training (not test time), but the variance was high. Our latest paper, EPO, fixes this issue with interesting insights! Try it out.
17 Jun 2025

(1/n) Since its publication in 2017, PPO has essentially become synonymous with RL. Today, we are excited to provide you with a better alternative - EPO.
2
7
100
11,203
Sam Kriegman retweeted

7 May 2025
our new system trains humanoid robots using data from cell phone videos, enabling skills such as climbing stairs and sitting on chairs in a single policy
(w/ @redstone_hong @junyi42 @davidrmcall)
36
117
686
198,137
Sam Kriegman retweeted

5 May 2025
Material? Robot? It’s a metabot.
"You can transform between a material and a robot, and it is controllable with an external magnetic field."
— Glaucio Paulino, @eprinceton professor
In an article published in @Nature, researchers describe how they drew inspiration from origami to create a structure that blurs the lines between robotics and materials. The invention is a metamaterial, which is a material engineered to feature new and unusual properties that depend on the material’s physical structure rather than its chemical composition. In this case, the researchers built their metamaterial using a combination of simple plastics and custom-made magnetic composites. Using a magnetic field, the researchers changed the metamaterial’s structure, causing it to expand, move and deform in different directions, all remotely without touching the metamaterial.
The team called their creation a “metabot” — a metamaterial that can shift its shape and move: bit.ly/43fERsn
1
2
30
4,070
Sam Kriegman retweeted

6 May 2025
Online this afternoon … a visionary project on the possibilities of alien life 👽led by @claire_i_webb , featuring planets imagined by @leecronin @ProfSaraSeager @Kriegmerica @Estelle_inspace and more
30 Apr 2025

What if life beyond Earth isn’t as we know it? 🌌
Proxima Kosmos explores alternative planetary ecosystems with NASA, MIT, and visionary artists. Narrated by Keith David, this flythrough is just the beginning.
RSVP for the Science Convening on May 6: ow.ly/1mTn50VKYeh
4
8
38
9,152
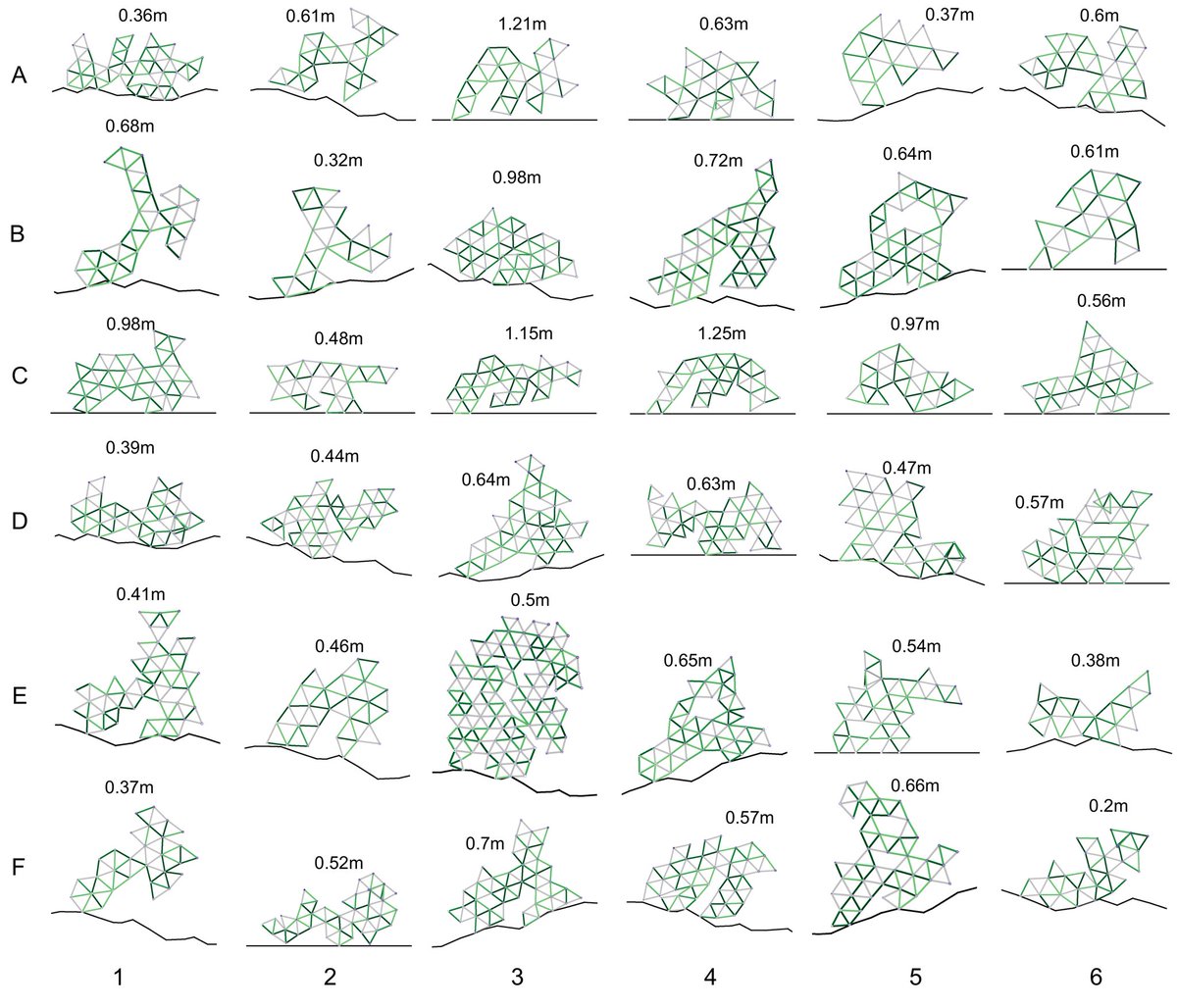
23 Apr 2025
Embodied agents... are evolving at #ICLR2025 🏝️
on Fri Apr 25 at 3-5:30pm in Hall 3 2B (Session 4)!
📄 openreview.net/forum?id=awvJ…
🌏 endoskeletal.github.io
1
3
29
1,104
25 Apr 2025
Stop by Muhan’s poster (#40) and try your hand at controlling an evolved body plan.
Can you beat RL?
#ICLR2025

285
Sam Kriegman retweeted

20 Feb 2025
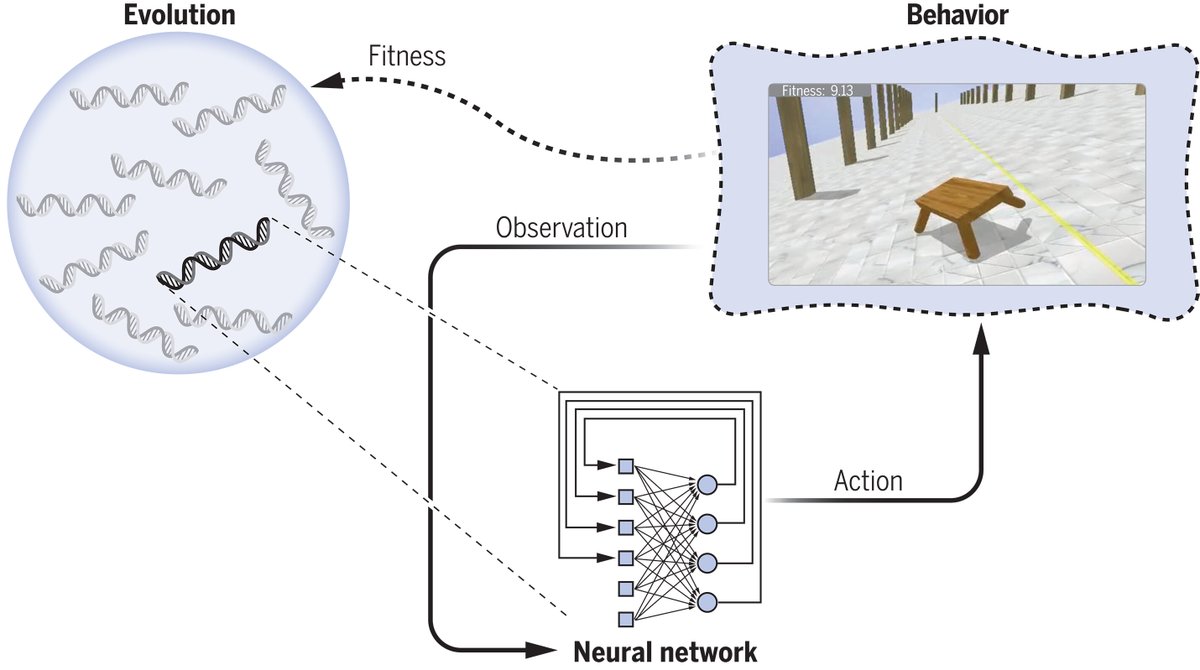
A new #ScienceReview presents an overview of neuroevolution and explores how neuroevolution experiments can be used to gain insight into neuroscience questions. scim.ag/4aWVr2J
2
8
37
22,290