
Data reliability delivered. #datadowntime montecarlodata.com
Joined May 2020
- Tweets 1,885
- Following 419
- Followers 1,573
- Likes 1,716
543 Photos and videos













Excited to share how Anthropic's data team has automated 95% of business analytics queries with Claude. Blog post covers how we approach evals, ablations, and online validation!
Jun 3

How do we automate business analytics with Claude?
New blog post covering our best practices for skills, data foundations, and evaluations when building agents to perform data analysis:
claude.com/blog/how-anthropi…
59
120
2,998
878,923
Monte Carlo retweeted

11 Aug 2025
@montecarlodata Launches @salesforce Integrations for AI-Ready Customer Data
martech360.com/tech-analytic…
#AIobservability #businessworkflows #CRMData #CustomerDataPlatforms #customerprofiles #GoToMarketoperations #martech360 #MonteCarlo
2
3
313

12 Aug 2025
We're excited to be a Launch Partner for the @AtlanHQ App Framework - a new way to build apps on Atlan’s Metadata Lakehouse using APIs, secure runtimes & marketplace distribution. 🚀
Catch the launch at #AtlanActivate: atlan.com/activate/?utm_medi…
2
234
Monte Carlo retweeted

16 Jun 2025
Data downtime holding you back? 📉 Tune in as Data Cloud Now's Ryan Green and @montecarlodata's Tim Osborn discuss minimizing data downtime with AI-driven data observability. Essential for reliable AI & trusted decision-making at scale! bit.ly/3SWJzFE

2
6
1,614
Monte Carlo retweeted
30 May 2025
Sending a huge thank you to our Black Diamond partners at #SnowflakeSummit: @Accenture, @awscloud, @capitalone, @Cognizant, @Deloitte, @EYnews, @hex_tech, @Informatica, @Infosys, @LTIMindtreeOFCL, @montecarlodata.
Don't miss out on all the latest and greatest in data, apps, and AI: snowflake.com/en/summit/?utm…

4
19
2,413
Monte Carlo retweeted

4 Jun 2025
AI-readiness doesn’t have to be buzzword. Learn how you can get AI-ready with @montecarlodata industry-first observability agents, solutions that allow organizations to monitor and troubleshoot data quality issues with the click of a button.
👉montecarlodata.com/product/o…

1
1
3
442
Monte Carlo retweeted

11 Jun 2025
Congratulations to team Monte Carlo for getting named 2025 Databricks Data Governance Partner of the Year!
It was great to meet @montecarlodata CEO, Barr Moses, @BM_DataDowntime during @databricks #DataAISummit today. @Jas_MonteCarlo, I missed you! Safe travels!
_______________
Monte Carlo created the data AI observability category to help enterprises drive mission critical business initiatives with trusted data AI

1
8
354
Monte Carlo retweeted

20 May 2025
Raise a glass with us at @Snowflake Summit 🍸
Thinking about what’s next for data and AI? This is where your peers will be 👀 Join Atrium, @montecarlodata, and ThoughtSpot on 6/3 for a rooftop happy hour with drinks, food, and real talk with industry pros.
RSVP here: bit.ly/45i7AhG
#snowflakesummit #thoughtspot #Networking

2
2
271
Monte Carlo retweeted

20 May 2025
Data observability specialist @montecarlodata launched #Observability Agents, a set of #GenAI-powered agents, and unveiled agents for monitoring data and troubleshooting anomalies.
Analysis from @StewartLBond and @KevinPetrieTech.
bit.ly/4dtR7sT
2
2
279
Monte Carlo retweeted

21 May 2025
Transformation & Governance: Tools for data modeling, observability, and lineage.
• @dbt_labs – Transformation layer for the modern stack
• @AtlanHQ – Active metadata platform
• @montecarlodata – End-to-end data observability
[🧵 4/7]
1
3
5
135
Monte Carlo retweeted

17 Apr 2025
This might be the biggest news we’ve shared all year—and I’m so freakin’ excited about it.
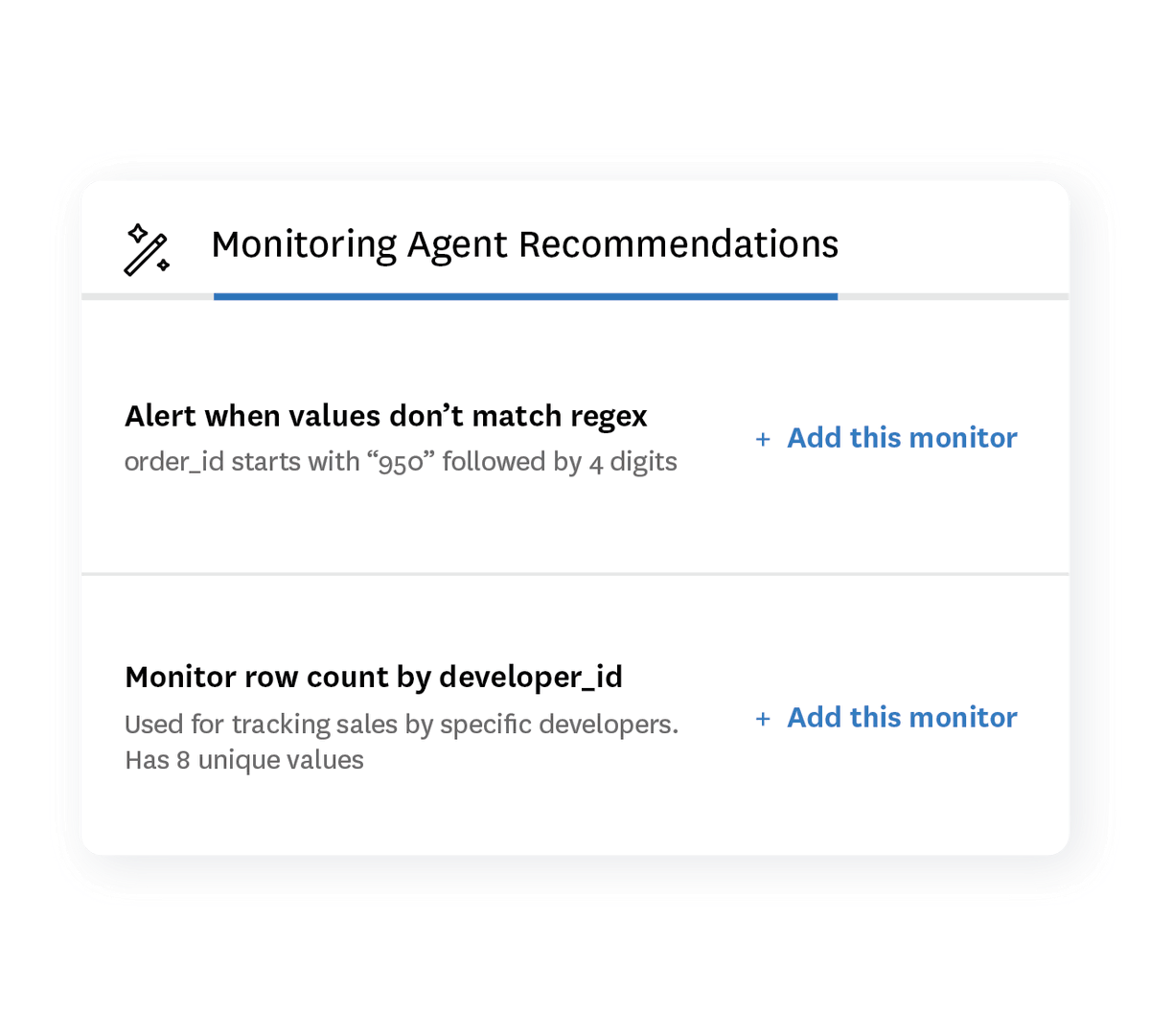
Monte Carlo just announced our first-ever Observability Agents to accelerate reliability workflows for enterprise teams—beginning with our Monitoring and Troubleshooting Agents to drastically accelerate monitor creation and incident resolution.
You may have seen automated monitor suggestions before, but not like this.
This is the first AI agent that makes recommendations based on:
- a data profile AND
- Metadata for the larger contextual meaning AND
- Query logs to understand how the data is used.
The result is more sophisticated, helpful suggestions—and a 60% acceptance rate.
But don’t take my word for it. You can take a demo or a self-guided tour of our Monitoring Agent today.
Please check this one out and let me know what you think: lnkd.in/gSDPaAQ2
2
3
643
Monte Carlo retweeted

17 Apr 2025
Monte Carlo Brings AI Agents Into the Data Observability Fold ow.ly/TQ0Y50VCHWo

2
2
210
17 Apr 2025
Monitoring & troubleshooting just got even easier.
Introducing the world's first-ever Observability Agents, the Monitoring Agent & Troubleshooting Agent, designed to help data AI teams find and fix issues faster with AI-driven detection and resolution. montecarlodata.com/blog-mont…
1
2
148
Monte Carlo retweeted

16 Apr 2025
Bad data used to be a nuisance.
Now? It’s a liability.
In the AI era, one broken pipeline can cost millions—or worse, make the wrong decision at scale.
Bar Moses (CEO @MonteCarloData) lays it out:
✅Mission-critical data needs constant oversight
✅Focus on high-impact pipelines, not one-size-fits-all
✅Detection isn’t enough — fix issues fast
AI depends on trustworthy data. Garbage in, chaos out.
Your data stack can’t afford to fly blind.
1
2
3
200
Monte Carlo retweeted
16 Apr 2025
🚗 Most companies treat data like a car they build and immediately drive 120mph — only to realize the door flies off mid-ride.
Bar Moses, CEO of Monte Carlo, breaks down why data & AI observability is the missing layer—and how Monte Carlo helps teams actually trust their data.
🎯 From dashboards to generative AI apps, data teams are building products that run on reliability.
Monte Carlo ensures they don’t crash.
#DataQuality #AIObservability @montecarlodata
2
4
204
11 Apr 2025
Don't miss @BM_DataDowntime and @hugobowne on the High Signal podcast chatting about why most companies aren't actually AI-ready... and what they can do to fix that. #AIready #data
Full episode here: high-signal.delphina.ai/epis…
1
1
109
Monte Carlo retweeted
10 Apr 2025
I don't care how big your context window is.
While it’s true that running a single complex action on a model with a large context window would lead to a more favorable output than a smaller model all other things being equal, that assumes that you actually need to run that complex action as a single task.
The reality is, twenty smaller models running in parallel and outputting a smaller number of tokens will almost always be faster than a single large model running on all the data all at once.
And I’ll do you one better—small models can even improve the performance of your AI agents too.
Strategies like horizontal task splitting minimize the number of input tokens, output tokens, and model size required to complete an operation—reducing runtime, maintaining (or even reducing) costs, and delivering more deterministic responses for their respective tasks.
The secret? Curating the right high quality data to make it work.

2
6
360
Monte Carlo retweeted
19 Mar 2025
Data and AI are no longer two separate technologies.
It’s time we stopped treating them that way.
That’s why I’m ecstatic to announce that Monte Carlo will be extending our partnership with Databricks to bring our vision for data AI observability to the Databricks’ Data Intelligence Platform.
Databricks SVP of Product Adam Conway says it well:
“We’re incredibly excited to see Monte Carlo expanding their data AI observability capabilities to support unstructured data pipelines in Databricks' Data Intelligence Platform. This collaboration empowers our customers to gain deeper insights and trust in their AI-driven workloads, accelerating innovation with reliable, high-quality data.”
If you're a Databricks customer, you can expect:
- Coverage for structured and unstructured data pipelines
- AI-powered alerts and detection
- Lineage tracking to identify incident impact
- And root cause within AI agents
The first step to adopting any new technology is trust. If you can't trust the technology, you can't depend on it. End-to-end data AI observability is no longer a nice-to-have; it's essential for the reliable operation of AI agents and applications.
This partnership is the next big step to get us there.
Link to the full announcement: montecarlodata.com/blog-mont…

1
2
7
463
10 Apr 2025
Is your data AI-ready?
Check out @lgavish on @DataScienceDojo talking about how to build scalable and reliable AI! 🚀youtube.com/watch?v=pNVLfcRW…
#DataScience #DataAnalytics #DataEngineering
1
1
107

At #HumanX, women in leadership were pushing the bigger conversations about AI.
@montecarlodata | @CredoAI | @honeybook | @LatticeHQ | @Get_Writer | @nylas | @TrustVanta | @veseyventures | @2ndTimeFounders
2
4
25
6,717