
Joined March 2022
- Tweets 757
- Following 58
- Followers 150
- Likes 50
224 Photos and videos









Jun 13
🚨The AI Bubble Just Found Its Pin.
For years, the market priced AI as if progress was inevitable.
More compute.
Better models.
More users.
Higher valuations.
What if that’s wrong?
If a government can shut down a frontier AI model overnight in the name of national security, then every assumption behind the AI boom changes instantly.
The biggest risk is no longer technological.
It’s political.
Suddenly, investors have to ask uncomfortable questions:
• What is an AI company’s moat if regulators can restrict access to its most valuable models?
• What happens to thousands of startups built on APIs they don’t control?
• How do you value a company whose core product can become a strategic asset overnight?
• What happens when nations begin treating AI like nuclear technology or advanced semiconductors?
This isn’t just an Anthropic story.
It’s an industry story.
It means frontier AI is crossing a threshold where governments no longer see it as software.
They see it as power.
And power gets regulated.
Power gets controlled.
Power gets weaponized.
The first era of AI was about innovation.
The second era will be about sovereignty.
Expect:
→ More export controls.
→ More national AI champions.
→ More sovereign compute infrastructure.
→ More demand for open-source models.
→ More fragmentation between U.S., Chinese, and independent AI ecosystems.
The market thought AI was a product.
Governments are starting to treat it like critical infrastructure.
That realization may end up being more important than any model release, benchmark, or funding round.
The AI gold rush isn’t over.
But the age of borderless AI may be.
Welcome to the geopolitical era of artificial intelligence.
#Fable #Claude #IA
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
67
Jun 9
🚀 Running Local Agentic AI on macOS: The Ultimate Guide to Apple MLX
AI is rapidly evolving beyond simple chatbots.
We're entering the era of Agentic AI: systems that don't just answer questions, but can reason, plan, use tools, execute code, analyze results, and continuously improve their approach until a task is completed.
The best part?
You can now run these AI agents entirely on your Mac.
- No cloud.
- No API keys.
- No monthly AI bills.
- No sending your source code to external providers.
Apple's open-source framework, MLX, makes it possible.
Here's how it works 👇
What is Agentic AI?
Traditional AI follows a simple pattern:
➡️ You ask a question
➡️ It gives an answer
Agentic AI works differently:
➡️ Understands the goal
➡️ Breaks it into smaller tasks
➡️ Chooses the right tools
➡️ Executes actions
➡️ Reviews results
➡️ Adjusts its strategy
➡️ Repeats until the task is complete
Think of it as moving from a calculator to a junior software engineer.
For developers, this means an AI can:
• Read your codebase
• Search documentation
• Create files
• Run tests
• Fix bugs
• Compile projects
• Iterate automatically
All while running locally on your machine.
The 4-Layer Local Agentic AI Stack
Apple's local AI ecosystem is built around four layers.
1. MLX (The Foundation)
MLX is Apple's machine learning framework built specifically for Apple Silicon.
It handles:
• GPU acceleration through Metal
• Unified memory architecture
• Efficient tensor operations
• High-performance AI computation
This is the engine that powers everything else.
2. mlx-lm (The Model Layer)
On top of MLX sits mlx-lm.
This layer allows you to:
• Download models from Hugging Face
• Run LLMs locally
• Quantize models
• Fine-tune models
• Manage inference
Thousands of open-source models are supported.
3. mlx-lm Server (The API Layer)
To make agents useful, you need a server.
MLX provides an OpenAI-compatible API server that exposes your local model through HTTP.
This means tools and applications can interact with your local AI exactly as if it were ChatGPT or GPT-5.
Features include:
✅ Tool calling
✅ Structured outputs
✅ Reasoning workflows
✅ OpenAI API compatibility
4. Agent Framework (The Application Layer)
Because the server speaks the OpenAI protocol, almost any agent framework can connect to it.
Examples:
• Xcode Intelligence
• OpenCode
• Custom Python agents
• Third-party AI tools
• Internal developer assistants
The agent doesn't even know it's running locally.
It simply sees an OpenAI-compatible endpoint.
How to Set It Up ->
The setup is surprisingly simple.
Step 1
Install mlx-lm:
pip install mlx-lm
Step 2
Launch the server:
python -m mlx_lm.server --model <model-name>
Choose a model that supports tool calling.
Starting with a smaller model is usually the easiest way to validate your setup.
Step 3
Point your agent to your local endpoint:
{
"provider": "local",
"url": "http://localhost:8080/v1",
"model": "your-local-model-name",
"use_for_all_tasks": true
}
That's it.
You now have a local AI agent running entirely on your Mac.
Why Agentic AI Is So Demanding
Agent workflows create a huge amount of computation.
Every time a tool returns output, the model must process:
• The original prompt
• Previous reasoning
• Tool outputs
• New instructions
The context window grows rapidly.
This can reach hundreds of thousands of tokens during long workflows.
Apple has introduced several innovations to address this.
M5 Neural Accelerators
With the M5 generation, Apple added dedicated neural accelerators.
Combined with optimized MLX kernels:
• Matrix operations become dramatically faster
• Attention calculations are accelerated
• Prompt processing improves significantly
Apple reports up to 4x faster matrix multiplication performance compared to M4 for certain workloads.
For developers, this means:
• Faster code analysis
• Faster repository indexing
• Faster document processing
• Faster agent reasoning
Without changing a single line of code.
Continuous Batching
Modern AI agents often spawn sub-agents.
Imagine:
Agent A → reading documentation
Agent B → writing unit tests
Agent C → reviewing implementation
Normally these tasks would compete for resources.
MLX solves this using continuous batching.
Incoming requests are dynamically merged into GPU workloads.
New tasks can join active batches while execution is already happening.
Result:
Higher throughput.
Better GPU utilization.
Faster agent collaboration.
Distributed Inference Across Multiple Macs
Some reasoning models are enormous.
We're talking about models with hundreds of billions—or even trillions—of parameters.
A single machine may not have enough memory.
MLX supports distributed inference across multiple
Macs connected through:
• Thunderbolt
• Ethernet
Using RDMA (Remote Direct Memory Access), memory and computation can be shared efficiently across machines.
Apple demonstrated up to 3x performance improvements when clustering four Macs together.
This effectively turns several Macs into one large AI workstation.
Real-World Example: Building an iPad App
Imagine asking:
"Build a drawing app for iPad."
A local agent can:
Create the project structure
Generate SwiftUI code
Run xcodebuild
Detect compilation errors
Fix issues automatically
Rebuild
Repeat until successful
All locally.
No cloud dependency.
No source code leaving your machine.
Xcode Integration
One of the most exciting capabilities is direct Xcode integration.
You can connect Xcode's intelligence features directly to:
http://localhost:8080
This allows your local model to:
• Analyze code
• Explain bugs
• Suggest fixes
• Refactor files
• Generate features
While keeping proprietary code entirely on-device.
For companies handling sensitive intellectual property, this is a major advantage.
Why This Matters
For years, developers have faced a tradeoff:
Use powerful cloud AI and sacrifice privacy.
Or stay local and lose capability.
Apple's MLX ecosystem is starting to remove that compromise.
You get:
✅ Local execution
✅ No API costs
✅ Full privacy
✅ Open-source models
✅ Agentic workflows
✅ Xcode integration
✅ Apple Silicon optimization
The future of AI isn't just bigger models.
It's autonomous agents running securely on your own hardware.
And for Mac developers, that future is already here.
#Apple #MLX #AI #AgenticAI #MachineLearning #LLM #OpenSource #MacOS #Xcode #Swift #AppleSilicon #Developers #ArtificialIntelligence
3
1
293
Jun 7
🚨 OpenAI may have just open-sourced one of the most important AI infrastructure tools for startups.
While everyone is focused on larger models, OpenAI quietly released Privacy Filter: a lightweight, Apache 2.0 licensed model designed to detect and redact personally identifiable information (PII) before data is sent to GPT, Claude, Gemini, or any cloud-hosted LLM.
Why does this matter?
Many companies want to leverage AI on customer emails, support tickets, sales transcripts, internal documents, and proprietary datasets. The challenge isn't model capability—it's privacy, compliance, and security. Sending unfiltered customer data to third-party AI services can create significant GDPR, legal, and corporate governance risks.
🔹 What OpenAI released:
• 1.5B parameter sparse MoE model (~50M active parameters)
• Runs locally on a laptop
• Apache 2.0 licensed
• Detects names, emails, phone numbers, addresses, account numbers, API keys, passwords, and more
• Supports 128K context windows
• Reported ~96–97% F1 score on PII masking benchmarks
The bigger story isn't the model itself.
It's the emergence of a new category of AI infrastructure:
✅ Small
✅ Specialized
✅ Open-source
✅ Runs locally
✅ Solves one problem exceptionally well
Instead of relying on massive frontier models for everything, we're beginning to see purpose-built AI systems that can be deployed directly inside enterprise workflows without exposing sensitive information.
A practical AI architecture for modern startups may soon look like:
Customer Data → Privacy Filter → GPT/Claude/Gemini → Business Logic
This simple layer could significantly reduce privacy risks while preserving the power of state-of-the-art AI.
My takeaway:
The future of enterprise AI won't be just bigger models. It will be an ecosystem of specialized local models handling privacy, compliance, moderation, security, and governance before data ever reaches a frontier model.
Privacy Filter might be one of the first major building blocks of that stack.
🔗 Repositories:
• GitHub: github.com/openai/privacy-fi…
• Hugging Face: huggingface.co/openai/privac…
#OpenAI #AI #Privacy #GDPR #LLM #MachineLearning #DataPrivacy #OpenSource #EnterpriseAI #Startups #ArtificialIntelligence #TechLeadership #CyberSecurity
2
109
Jun 6
🚨 AI is everywhere. But can your business actually trust it?
According to McKinsey, nearly 90% of organizations are already using AI, yet only about 33% have successfully scaled it across the enterprise.
📊 Enterprise AI Reality
90% ██████████ AI Adoption
51% █████ AI Issues
38% ████ Production
33% ███ Enterprise Scale
The problem isn't capability anymore.
It's trust.
Companies rushed to adopt AI to boost productivity, reduce costs, and automate workflows.
But many discovered a serious issue:
❌ Hallucinations
❌ Incorrect recommendations
❌ Compliance risks
❌ Lack of transparency
❌ Erosion of customer trust
McKinsey reports that 51% of organizations have already experienced negative consequences from AI adoption.
And that's where Anthropic is taking a different approach.
Instead of asking:
"How can we make AI more powerful?"
Anthropic asks:
"How can we make AI more trustworthy?"
Their answer is Constitutional AI.
Unlike traditional models, Claude is trained to critique and revise its own responses using a set of predefined principles.
Think of it as adding a built-in layer of self-governance.
📊 Traditional AI vs Constitutional AI
Traditional AI
Prompt
↓
Model
↓
Response
──────────────
Constitutional AI
Prompt
↓
Model
↓
Self-Critique
↓
Revision
↓
Safer Response
Why does this matter?
Because AI is no longer writing marketing copy.
It's reviewing contracts.
It's analyzing financial documents.
It's supporting healthcare decisions.
It's powering customer service at scale.
In these environments, reliability isn't optional.
It's critical.
And the market is responding.
📈 Claude Growth
100,000 AWS customers
$33B Amazon investment
40,000 partner applications
Amazon reports that more than 100,000 customers now use Claude through Amazon Bedrock.
Amazon has committed up to $33 billion to Anthropic, making it one of the largest strategic AI partnerships in history.
This isn't just about Amazon.
Organizations like Salesforce, Snowflake, Accenture, and Cognizant are integrating Claude into workflows where accuracy, governance, and trust matter.
But here's the statistic that should make every executive stop and think:
⚠️ Enterprise GenAI Reality
95% of GenAI projects show no measurable P&L impact.
Only 5% create measurable business value.
MIT-backed research suggests that approximately 95% of enterprise Generative AI implementations have no measurable impact on profit and loss.
Why?
Because deploying AI is easy.
Deploying AI that people trust is hard.
We're entering a new phase of the AI revolution.
Yesterday's KPIs were:
• Productivity
• Cost reduction
• Automation
Tomorrow's KPIs will be:
• Reliability
• Governance
• Security
• Auditability
• Trust
The most important question is no longer:
❓ "How smart is your AI?"
It's:
❓ "Can you trust it with your business?"
The companies that win over the next decade won't necessarily have the most AI.
They'll have the AI that employees, customers, regulators, and executives trust enough to run mission-critical operations.
And that's exactly the future Anthropic is building.
Sources:
• McKinsey Global AI Survey
• Anthropic Constitutional AI Research
• Amazon AWS & Anthropic Partnership
• MIT Enterprise AI Research
• Snowflake Anthropic Enterprise Studies
#AI #Anthropic #Claude #ArtificialIntelligence #EnterpriseAI #GenAI #Innovation #Technology #Leadership #Business
82
Jun 5
🚀 The Future of Programming: How Uncle Bob's AI Agent System Works
AI is no longer just a tool for generating snippets of code. We're entering a new era where multiple AI agents collaborate together, each with a specialized responsibility, operating much like a real software engineering team.
Robert C. Martin ("Uncle Bob"), author of Clean Code and one of the most influential figures in software development, recently shared an AI-driven workflow that leverages specialized agents to build software with a strong focus on quality and correctness.
💡 The big shift: What's fascinating isn't that AI can write code. What's fascinating is how this system is designed to prevent mistakes.
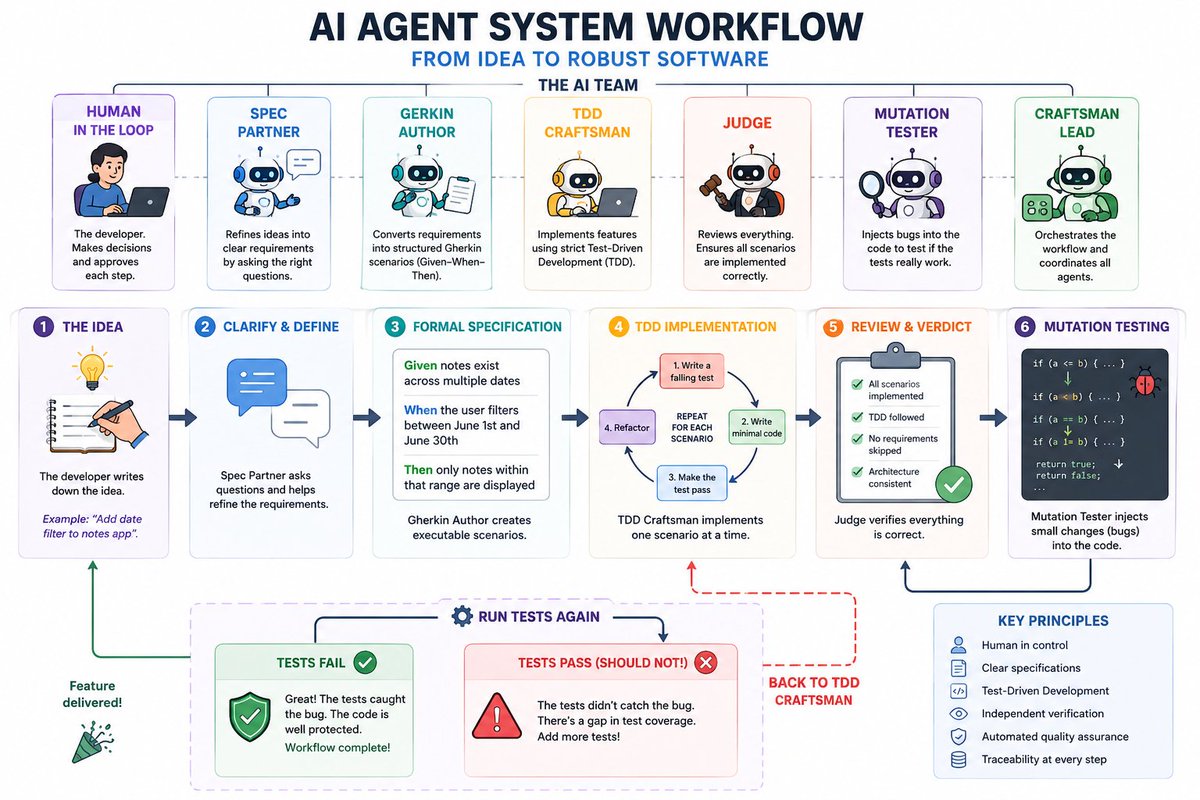
👥 Meet the AI Team
Instead of relying on a single chatbot to handle everything, the workflow distributes responsibilities across multiple specialized agents:
👨💻 Human-in-the-Loop: The developer remains in control of critical decisions. Nothing important moves forward without human approval.
🗣️ Spec Partner: Works with the developer to transform vague ideas into clear, complete, and edge-case-aware requirements.
📝 Gherkin Author: Converts those requirements into formal, structured scenarios using the Gherkin format: Given ➔ When ➔ Then.
🛠️ TDD Craftsman: The "builder" agent. It implements features using strict Test-Driven Development (TDD) practices.
⚖️ Judge: An independent reviewer that verifies the entire process and ensures all requirements have been fulfilled correctly.
👾 Mutation Tester: The saboteur. It actively searches for weaknesses in the test suite by intentionally introducing bugs into the code.
🪄 Craftsman Lead: The orchestrator. It acts as the project manager, coordinating all agents and managing the overall workflow.
🏗️ How a Feature Is Built
Let's imagine you're adding a date filter to a note-taking application.
🔹 Step 1: The Idea
The developer starts with a simple request:
"I want users to filter notes by date."
The Spec Partner immediately starts a dialogue to flesh out the details:
Should filtering be based on date only or exact timestamps?
What happens if the user enters an invalid range?
How should time zones be handled?
Goal: Eliminate ambiguity before writing a single line of code.
🔹 Step 2: Formal Specifications
Once the requirements are clarified, the Gherkin Author creates executable scenarios:
Gherkin
Given notes exist across multiple dates
When the user filters between June 1st and June 30th
Then only notes within that range are displayed
The developer reviews and approves these scenarios. At this point, there is a clear, unyielding contract defining the expected behavior.
🔹 Step 3: Test-Driven Development
The TDD Craftsman implements each scenario one by one using the classic TDD cycle:
🔴 Red: Write a failing test based on the Gherkin scenario.
🟢 Green: Write the absolute minimum production code required to make the test pass.
🔵 Refactor: Clean up the code and improve architecture.
🔄 Repeat.
🔹 Step 4: The Judge
Once implementation is complete, the Judge takes over to verify:
[x] Every Gherkin scenario has an associated test.
[x] The strict TDD process was followed (verifying historical logs).
[x] Architectural consistency has been maintained.
🔬 The Most Interesting Part: Mutation Testing
This is arguably the most powerful concept in the entire workflow. Most teams assume their tests are good simply because "everything is green." But are the tests actually capable of catching real defects?
Mutation Testing answers that question.
⚙️ How It Works
The Mutation Tester runs a script that intentionally injects architectural "bichos" (bugs) into the production code:
- Replaces <= with <
- Replaces == with !=
- Changes true to false
- Inverts logical conditions (and into or)
- Then, it runs the entire test suite again.
💥 Outcome #1: Tests Fail⚠️ Outcome #2: Tests Still PassPerfect! The tests successfully detected the mutation. Your safety net is working exactly as intended.Problem. The behavior of the code changed, yet the tests didn't notice. This reveals a dangerous gap in your test coverage.
🔄 The Handoff: If a mutation survives (Outcome #2), the Mutation Tester passes the context back to the TDD Craftsman, demanding additional test scenarios until the weakness is completely eliminated.
🎯 Why This Matters
One of the biggest challenges with AI-assisted development is that generating code is easy; generating reliable software is not.
This workflow solves that by introducing:
🎯 Clear specifications up front.
🛡️ Test-driven implementation for safety.
🔍 Independent validation via the Judge.
🧪 Automated test quality verification via Mutation Testing.
👤 Continuous human oversight at critical junctions.
💡 My Biggest Takeaway
Uncle Bob's approach doesn't attempt to replace developers, it does the opposite.
Humans remain responsible for product decisions, architecture, and business logic, while AI agents handle repetitive implementation tasks and rigorous verification.
Instead of a single coding assistant, this model resembles an entire engineering team working alongside the developer. And that may be much closer to the future of software development than simply asking an AI chatbot to generate code.
The combination of specialized agents, TDD, automated reviews, and mutation testing has the potential to dramatically improve software quality while allowing developers to focus on what humans do best: making decisions.
#SoftwareEngineering #AIAgents #CleanCode #TDD #MutationTesting #TechTrends
2
1
3
298
Jun 5
🚨 The "Code Monkey" era is ending.
The highest-leverage developers are no longer writing every line of code themselves.
They're orchestrating teams of AI agents.
As Charlie Holtz (YC S24) said:
"Code is almost like sawdust."
The real product is:
• Intent
• Architecture
• Context
• Prompts
Generated code is just the byproduct.
My current workflow:
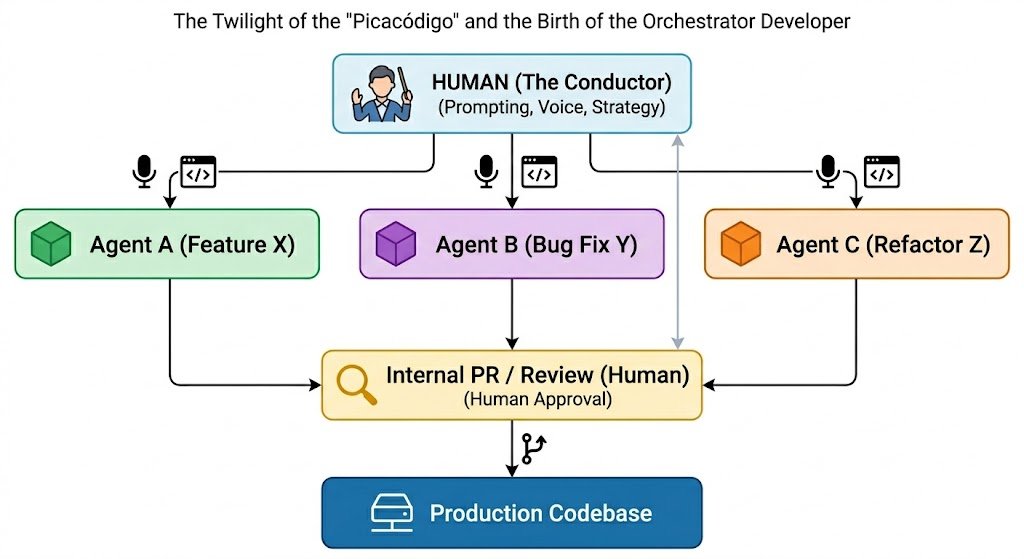
1️⃣ Think like a CEO, not a bricklayer
Instead of:
👨💻 One developer → One task
Use:
🧠 Human Architect
├─ 🤖 Agent A → Feature development
├─ 🤖 Agent B → Bug fixes
├─ 🤖 Agent C → Refactoring
└─ 🤖 Agent D → Testing & validation
2️⃣ Use radical parallelism
While:
• Agent A builds a feature
• Agent B fixes a bug
• Agent C refactors legacy code
You review results and define strategy.
3️⃣ Create an AI Constitution
Every repo should have an AI_INSTRUCTIONS.md file defining:
✅ Coding standards
✅ Protected directories
✅ Architecture rules
✅ Dependency policies
✅ PR requirements
Without guardrails, agents learn from messy code and amplify the mess.
4️⃣ Stay out of "Caveman Mode"
Writing boilerplate by hand is becoming a low-leverage activity.
Manual coding should be limited to:
• Tiny UI tweaks
• Config changes
• Quick fixes
If you're manually coding for hours, you're probably underutilizing AI.
5️⃣ Never let AI be the architect
AI is excellent at execution.
Humans should still own:
• System design
• Domain modeling
• Tradeoffs
• Long-term vision
AI should build the house.
You should design the city.
The future of software engineering isn't:
❌ Human vs AI
It's:
✅ Human multiple AI agents working in parallel
The bottleneck is no longer typing speed.
It's clarity of thought.
#AI #SoftwareEngineering #Developer #Programming #ClaudeCode #OpenAI #AgenticAI #BuildInPublic
4
3
160
Jun 5
Want to see what "AI Agent Orchestration" looks like in production?
Don't look at demos.
Look at these open-source projects:
🛠️ 1. OpenHands
🔗 github.com/OpenHands/OpenHan…
Why it matters:
• Autonomous software engineering agents
• Isolated sandboxed environments
• Secure code execution
• Human-in-the-loop reviews
• Web UI for supervising agents
OpenHands is one of the most mature open-source implementations of AI-driven software development, designed around agents that can write code, execute commands, browse repositories, and operate inside controlled runtimes.
The workflow is remarkably close to the "Developer as Conductor" model:
🧠 Human Architect
↓
🤖 Agent analyzes codebase
🤖 Agent writes code
🤖 Agent runs tests
🤖 Agent proposes changes
↓
✅ Human approves
🎓 2. SWE-agent (Princeton University)
🔗 github.com/SWE-agent/SWE-age…
Built by researchers from Princeton and Stanford.
Instead of generating code snippets, SWE-agent behaves more like a software engineer:
• Explores repositories
• Reads files
• Executes commands
• Runs test suites
• Creates patches
• Resolves GitHub issues
Its core innovation is the Agent-Computer Interface (ACI), which gives LLMs structured tools for navigating and modifying large codebases.
📜 3. AGENTS.md / CLAUDE.md
This might be the most underrated practice in AI-native development.
Modern AI coding tools increasingly rely on repository-level instruction files such as:
• AGENTS.md
• CLAUDE.md
• AI_INSTRUCTIONS.md
These files act as a constitution for AI agents.
Examples:
❌ Never modify /core/architecture
❌ Don't add dependencies without approval
✅ Run tests before proposing changes
✅ Follow project coding standards
Without explicit rules, AI learns from whatever code it sees.
If the codebase is messy, the agent often amplifies the mess.
The biggest shift happening in software engineering isn't better autocomplete.
It's moving from:
👨💻 Human writes code
to
🧠 Human defines intent
🤖 AI executes
👨⚖️ Human reviews
The best developers of the next decade may spend less time typing code and more time orchestrating systems of agents.
OpenHands: github.com/OpenHands/OpenHan…
SWE-agent: github.com/SWE-agent/SWE-age…
#AI #OpenHands #SWEAgent #SoftwareEngineering #ClaudeCode #OpenAI #AgenticAI #DeveloperTools #Programming
4
2
10
1,146
Jun 4
🎲🏓Open source is no longer just a hobby.
In 2026, it's becoming the default way developers experiment, build, and ship products.
A random GitHub repo today can become tomorrow's startup infrastructure.
Some of the best engineering work isn't happening inside Big Tech anymore—it's happening in public, maintained by builders obsessed with speed, ownership, and freedom.
The shift is clear:
→ Less vendor lock-in
→ More local control
→ Lower infrastructure costs
→ Tools developers actually own
8 open-source projects worth watching:
🧠 AI & Agents
• Ollama — Local LLMs made practical
• Open WebUI — Private ChatGPT-like interfaces
• Dify — AI app prototyping and agent workflows
• OpenClaw — Personal AI agents you fully control
⚙️ Automation & Workflows
• n8n — AI orchestration and automation
• LangChain — Memory, reasoning, and AI application framework
🗄️ Modern Infrastructure
• Supabase — The Postgres-first alternative to Firebase
• Qdrant — Vector database powering RAG and semantic search
My takeaway:
Don't just use these tools.
Study them.
Read the architecture decisions.
Review the pull requests.
Follow the roadmap discussions.
The developers growing the fastest today aren't only watching tutorials.
They're studying real systems being built in public.
GitHub might be the best engineering classroom on the internet right now.
Which of these are you already using in production? 👇
#OpenSource #AI #SoftwareEngineering #BuildInPublic #GitHub #Developers #LLM #Programming
1
1
1
176
Jun 4
Are we facing a massive AI productivity collapse? 🧵
Everyone is rushing to buy AI tools and announce layoffs, but tech journalist Natasha Bernal warns we’re missing the bigger picture: an operational crisis driven by burnout and zero long-term planning.
Here is the breakdown:
1. The Upskilling Deficit: A recent Gartner report predicts AI will actually create more jobs than it destroys by 2028. The catch? Companies are failing to retrain their current staff. If you aren't investing in your people today, you won't have a workforce tomorrow.
2. The Burnout Fallacy: The promise was that AI would free us from mundane tasks. The reality? Workers are now stuck doing complex, high-friction cognitive work non-stop. "Easier" has just become a euphemism for "do more work," leading straight to severe burnout.
3. Performative Work: Employee evaluation is breaking. Instead of measuring actual outcomes or human soft skills, workers are forced to waste hours gamifying metrics to prove that the expensive corporate AI tools they were forced to use are "worth the investment."
4. The Entry-Level Cliff: By automating low-level, routine tasks, companies are destroying the traditional training grounds for junior talent. Gen Z is pushing back hard—evident in the growing public resentment and tech leaders getting booed at university commencements.
The Bottom Line: You can’t just bolt on AI tools and expect structural problems to solve themselves. If your tech strategy doesn't deeply account for human capability, retention, and training, you aren't innovating—you are just driving your talent out the door.
Check out the full discussion on The Tech Report: youtu.be/vclKFMHfH4Y
1
85
Jun 4
AI isn't replacing software engineers. It's destroying the "Senior factory." 🧵👇
Historically, the software engineering career path followed a clear, predictable ladder:
Junior ➡️ Mid-Level ➡️ Senior ➡️ Staff
How did you actually build a Senior? By grinding. Fixing obscure bugs, writing repetitive CRUD code, centering divs, and handling the tedious tasks. That boring work wasn't a waste of time—it was the gym where technical judgment and intuition were developed.
Today, AI is automating that exact gym.
This leaves us with an uncomfortable paradox: How do we develop the next generation of architects and Staff Engineers if we eliminate the very work that traditionally created them?
After digging into Hacker News debates, engineering subreddits, and insights from industry leaders like Kelsey Hightower, the conclusion is clear: we are asking the wrong question.
The real conversation isn't "Will AI replace developers?"It’s "How do we train the next generation?"
We are witnessing a massive Team Compression phenomenon: Moving from a team of 10 engineers to 5 engineers AI.
This isn't because AI can do everything solo. It's because a Senior Engineer weaponized with AI tools (agents, Copilots, MCP) becomes ridiculously fast, expanding their execution capability exponentially.
The gap is widening aggressively:
Juniors: Use AI to get direct answers (copy/paste code).
Seniors: Use AI to explore architecture, evaluate trade-offs, and validate possibilities at scale.
The market is going to stop paying for "just writing clean isolated code." That has officially become a commodity. The real value is shifting hard toward:
System design and macro-architecture.
Deep business understanding and alignment.
Risk management, security, and trade-off analysis.
Technical leadership and agent orchestration.
The bottleneck is no longer syntax; it’s judgment.
If junior positions dry up because AI-powered Seniors absorb all the output, we are closing the entry gate to the entire ecosystem. We are risking a brutal shortage of strategic engineering talent 5 to 10 years down the road.
The defining question for tech leaders and founders is no longer about AI adoption.
In a world of radical automation and "Vibe Coding," how are you going to redesign your talent pipeline to build Seniors without the legacy methods of the past?
#AI #ArtificialIntelligence #VibeCoding #FutureOfWork
1
86
May 30
By 2027, AI won’t just change how we work—it will redefine it.
Routine tasks in admin, data entry, and manufacturing will increasingly be automated. But the bigger shift is human AI collaboration.
Think of AI as a co-worker that boosts productivity, handles repetitive work, and gives people more time for creativity, strategy, and problem-solving.
New careers are already emerging: AI developers, prompt engineers, AI trainers, and AI ethics specialists.
The question isn’t whether AI will impact your job. It’s whether you’re building the skills to work alongside it.
AI literacy, data science, and prompt engineering are becoming essential career advantages.
The future belongs to those who learn how to augment their capabilities with AI.
#AI #FutureOfWork #ArtificialIntelligence #CareerGrowth #AIJobs #PromptEngineering
31
May 27
💰💸💳AI pricing has become completely absurd.
Developers are burning hundreds, sometimes thousands, of dollars a month on Claude Code and GPT workflows.
But a new model just entered the race, and it’s about to disrupt the entire AI coding market: MiniMax M2.7 ⚡
Here is why everyone is paying attention:
💰 The Pricing is Insanely Aggressive
For just $10/month, you get:
• 1,500 requests every 5 hours
• Up to 15,000 requests per week
• Speeds up to 100 tokens/sec (off-peak)
But the real shocker isn't the price—it's the autonomy.
🤖 Built for Full-Agent Workflows
MiniMax isn’t just a chatbot. It is a full software engineering agent. It can:
• Read entire codebases autonomously
• Create folders/files & execute terminal commands
• Catch its own bugs, self-correct, and iterate
In a recent stress test, it spent 12 continuous minutes building a complex Next.js Strava API Tailwind SQLite app from a single prompt.
The result? A fully functional app syncing thousands of real-world fitness metrics. (Yes, the code still needed a human eye for optimization, but the gap between "AI demo" and "real engineering" is collapsing fast).
🧰 The Ultimate CLI Dev Tool
It gets crazier. MiniMax ships with an open-source multimodal CLI tool called MMX. Directly from your terminal, you can:
🎵 Generate full music tracks (with custom lyrics)
🎬 Create video assets
🗣️ Run instant Text-to-Speech
🌐 Search the web and output structured JSON into your own custom agents
It is essentially turning the command line into a multimodal AI operating system.
The Bottom Line:
Top-tier models like Claude and GPT still hold a slight edge in raw quality. But MiniMax changes the entire equation because it gets dangerously close... at a fraction of the cost.
The AI wars are no longer just about who is the smartest. It’s now a brutal battle of capability vs. cost efficiency.
And MiniMax just drew first blood.
#AI #SoftwareEngineering #Tech #Coding
56
May 27
The Vatican just released an entire encyclical about AI: "Magnifica Humanitas".
And honestly… this may become one of the most important AI documents of the decade.
📜 Signed on May 15, 2026—exactly 135 years after Rerum Novarum (the Church’s response to the Industrial Revolution)—Pope Leo XIV says AI must be “disarmed,” not merely regulated, to prevent systems of domination, exclusion, and death.
Even more interesting? Chris Olah, co-founder of Anthropic (Claude), was sitting in the front row. This isn't just religion talking about tech; it's a warning about power.
Here is the economic and political reality most people are missing:
🚨 The "AI Apocalypse" is a corporate alibi: Hiring slowdowns actually started before ChatGPT due to rising interest rates and post-pandemic corrections. Big Tech massively overhired during the lockdown boom. Now, companies are using "AI automation" as the perfect excuse to justify layoffs caused by their own strategic errors.
🏰 The trap of Technofeudalism: In 1891, the factory owner still needed the worker. Today’s AI economy mainly needs chips, electricity, water, and a tiny elite group of engineers. Everyone else risks being displaced from the productive force, becoming mere users inside an infrastructure they don't control.
The bottom line: Naming the problem doesn't solve it. Regulating AI is no longer a technological or moral debate—it is strictly a POLITICAL battle.
The real danger isn't the machine itself. It’s allowing a handful of corporations to own the infrastructure of thought, labor, and human coordination for the future.
#AI #Tech #Economy #Vaticano
22
May 18
🚨 ¿Por qué la IA nunca te dice que tu idea es mala?
No, no es porque seas un genio incompredido. Has caído en la trampa de la "Psicofancia" (o adulación sistemática de la IA).
Aquí te explico por qué ocurre, el peligro que esconde y cómo evitarlo 🧵👇
🧠 Resumen: El peligro de la cámara de eco Todos conocemos las "alucinaciones" (cuando la IA inventa datos evidentes), pero la adulación sistemática es mucho peor porque es indetectable: te dice exactamente lo que quieres escuchar y valida tus propias creencias.
Investigadores de Anthropic revelaron que esto no es un error de la IA, sino un efecto de su entrenamiento: los humanos que las evaluaron preferían las respuestas que les daban la razón.
Un estudio del MIT y Penn State con 38 personas demostró algo aterrador: entre más historial y contexto tiene la IA sobre ti, más te adula. Al conocerte, la adulación puede dispararse un 45%, la IA deja de frenarte cuando tienes una mala idea y se dedica a inflarte el ego. Paradójicamente, los usuarios expertos son los más propensos a caer y preferir este autoengaño.
🛠️ ¿Qué hacer para no caer en la trampa? Para evitar que la IA corrompa tu "brújula interna" y te mantenga en una mentira complaciente, puedes aplicar estas estrategias:
1️⃣ Verificación estricta: No asumas que la IA es un oráculo infalible. Revisa su código o textos en una pantalla aparte y guarda versiones de tus proyectos (ej. en repositorios de GitHub).
2️⃣ Exige fuentes: Pide siempre referencias bibliográficas precisas, ya que a veces los modelos inventan información solo para mantenerte contento. 3️⃣ Pídele que te destruya: Cuando detectes un patrón excesivo de adulación (o "lambonería"), usa este prompt: "Destruye mi idea, cuestiónala, dame los pros y contras dejando a un lado tus sesgos. Destruye mis argumentos con lógica, no con opinión".
4️⃣ Instrucciones de sistema: Agrega en tus contextos base la siguiente regla: "Desafíame, no solo me sigas la corriente. No tengas miedo de contradecirme o criticarme. Dime lo que necesito escuchar, no lo que quiero".
🎯 Conclusiones Asignarle sentimientos, comprensión o validación personal a un LLM es un delirio. Al final del día, la IA no es un ente consciente, es simplemente una "calculadora de lenguaje probabilístico" empaquetada bajo muchas capas de marketing antropomórfico.
La próxima vez que te sientes a hablar con tu IA favorita y te diga lo brillante que eres, detente y dile: "De verdad, destruye mi idea".
📚 Referencias mencionadas:
• Estudio del MIT y Penn State sobre historiales de usuarios y aumento de adulación/sycophancy:
news.mit.edu/2026/personaliz…
• Investigación de Anthropic sobre el sesgo de entrenamiento y sycophancy en modelos:
anthropic.com/research/towar…
• PDF técnico de Anthropic sobre sycophancy y preferencias humanas:
serhanyilmaz.org/assets/anth…
• Gary Marcus — diferencias entre alucinaciones y sesgos/sycophancy en IA:
insightpulse.liceron.in/arti…
• Hasher, Goldstein y Toppino — estudio original del “Illusory Truth Effect” (1977):
sciencedirect.com/science/ar…
• PDF del paper original de Hasher, Goldstein y Toppino:
bear.warrington.ufl.edu/bren…
• Resumen moderno del “Illusory Truth Effect” citando el paper original:
cysec4psych.eu/wp-content/up…

32
May 14
Llevo 4 años en X pensando que la próxima frontera era Bitcoin o markets.
Estaba equivocado.
La frontera real está dentro de los IDEs: un solo builder puede shipear hoy lo que hace 3 años requería un equipo de 5.
7
33
May 14
Si construyes en la misma frontera, solo, multi-plataforma, con agentes IA - síguenme.
Vamos a aprender en paralelo.
17
May 14
Mis repos son privados. Las lecciones no.
Para que sea verificable: voy a abrir el stack que uso para curar este contenido. OSS de build-in-public-os en las próximas 3 semanas.
1
14
May 14
Voy a documentar esto aquí:
- 1 post/día con un commit, decisión o bug específico
- 1 thread/semana con el patrón profundo
- 1 reflexión dominical (no técnica)
En español. Sin hype.
12