
Scaling RL @meta | prev RL @xAI | founding engineer @anyscalecompute | committers of @raydistributed @vllm_project Sglang | Github: rkooo567
Joined September 2016
- Tweets 128
- Following 582
- Followers 2,800
- Likes 4,575
Photos and videos

📢 Three incoming faculty members at KAIST AI, starting in August 2026✨
Dr. Sehoon Kim from xAI (@sehoonkim418), Dr. Hyunwoo Kim (@hyunw_kim), and Dr. Seung Wook Kim (@seungkim0123), both from NVIDIA, will be joining KAIST AI as Assistant Professors
Check their websites below🧵
4
13
153
51,978

Jun 12
RT @GoldmanSachs: SpaceX is redefining industries on Earth and aiming to create new ones beyond it.
On June 11, it successfully priced its…
1,138
SangBin Cho retweeted

Jun 12
Today, @SpaceX (Nasdaq: SPCX) makes its public market debut with a $75Bn offering (pre-greenshoe) at $135 per share, marking the largest IPO in history.
Congratulations to the SpaceX team. We are honored to serve as joint lead bookrunner and sole stabilization agent.
816
2,076
11,997
14,535,617
SangBin Cho retweeted

Jun 10
Today I'm publishing a new essay, Policy on the AI Exponential. AI is progressing extremely fast—much faster than the policy process was built to handle. The essay lays out where I think the technology is now, and the action needed to close the gap: darioamodei.com/post/policy-…
1,328
2,426
13,526
6,481,315
SangBin Cho retweeted

May 19
Composer 2.5 is now the most-chosen model in Cursor.
We're giving everyone 10x usage for the rest of the day. Enjoy!
May 18

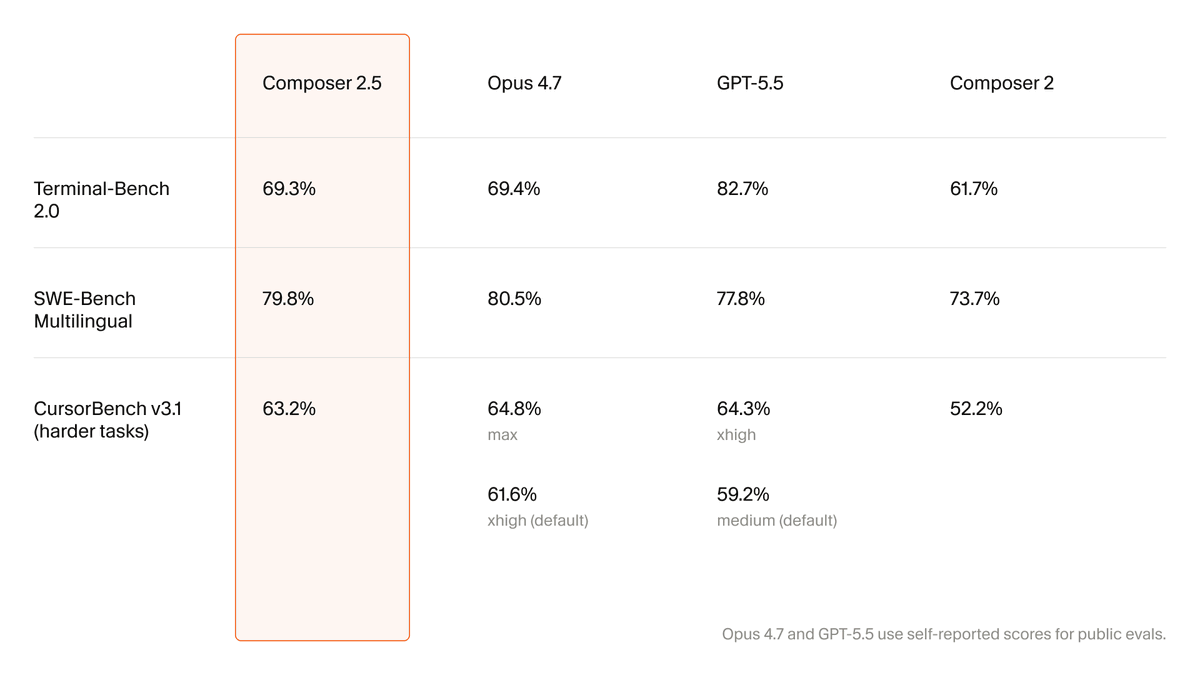
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
331
244
3,481
39,764,945
SangBin Cho retweeted

May 19
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
7,989
11,146
150,225
27,575,398
SangBin Cho retweeted

May 15
Very importantly! We have a beautiful patio on Market Street.

We're onto Inferact's second office this year! Yesterday, we finally broke it in with an office warming.
It's amazing to see how far we've come. The vLLM ecosystem has been growing at lightning pace, and we've been lucky to scale alongside it: helping teams serve inference faster, cheaper, and at scale.
Thank you to everyone who made it out yesterday — customers, partners, friends, and the whole Inferact team. It meant a lot to celebrate this milestone together.
We're hiring across all teams. If you want to join one of the fastest-growing AI infra companies and power the next generation of AI, check out our careers page or DM us.
Excited for many more office warmings to come!




6
2
58
6,299
SangBin Cho retweeted

May 6
Today I’m excited to congratulate @simon_mo_ on an outstanding PhD thesis defense on his work exploring the design of Inference Serving Systems. 🎉
Simon has been working on inference systems with me for nearly a decade -- long before most people even considered inference serving a research problem worth studying.
Over that time, he helped drive inference systems projects spanning Clipper, @raydistributed Serve, and now @vllm_project. Together, these systems helped define the modern inference serving stack that powers today’s AI applications.
Beyond being an exceptional researcher, Simon has also been a remarkable team and community builder, especially through his leadership on vLLM and the open-source ecosystem around it.
Along with my colleagues @istoica05 and @koushik77, I am excited to see Simon leading @inferact as CEO and helping shape the future of inference systems and AI infrastructure.
Congratulations, Simon!

15
13
271
26,846

Today, we are thrilled to officially launch RadixArk with $100M in Seed funding at a $400M valuation. The round was led by @Accel and co-led by @sparkcapital.
RadixArk exists to make frontier AI infrastructure open and accessible to everyone. Today, the systems behind the most capable AI models are concentrated in a small number of companies. As a result, most AI teams are forced to rebuild training and inference stacks from scratch, duplicating the same infrastructure work instead of focusing on new models, products, and ideas.
RadixArk was founded to change that. We are building an AI platform that makes it easier for teams to train and serve the best models at scale.
RadixArk comes from the open-source community. We started with SGLang, where many of us are core developers and maintainers, and expanded our work to Miles for large-scale RL and post-training. We will continue contributing to both projects and working with the community to make them the strongest open-source infrastructure foundations for frontier AI.
We would like to thank our long-term partners, contributors, and the broader SGLang community for believing in this mission. We're also grateful to @Accel and @sparkcapital, NVentures (Venture capital arm of @nvidia), Salience Capital, A&E Investment, @HOFCapital, @walden_catalyst, @AMD, LDVP, WTT Fubon Family, @MediaTek, Vocal Ventures, @Sky9Capital and our angel investors @ibab, @LipBuTan1, Hock Tan, @johnschulman2, @soumithchintala, @lilianweng, @oliveur, @Thom_Wolf, @LiamFedus, @robertnishihara, @ericzelikman, @OfficialLoganK, and @multiply_matrix among others.
Thanks for the exclusive interview with @MeghanBobrowsky at @WSJ about our vision.

85
98
641
374,373
SangBin Cho retweeted

Apr 23
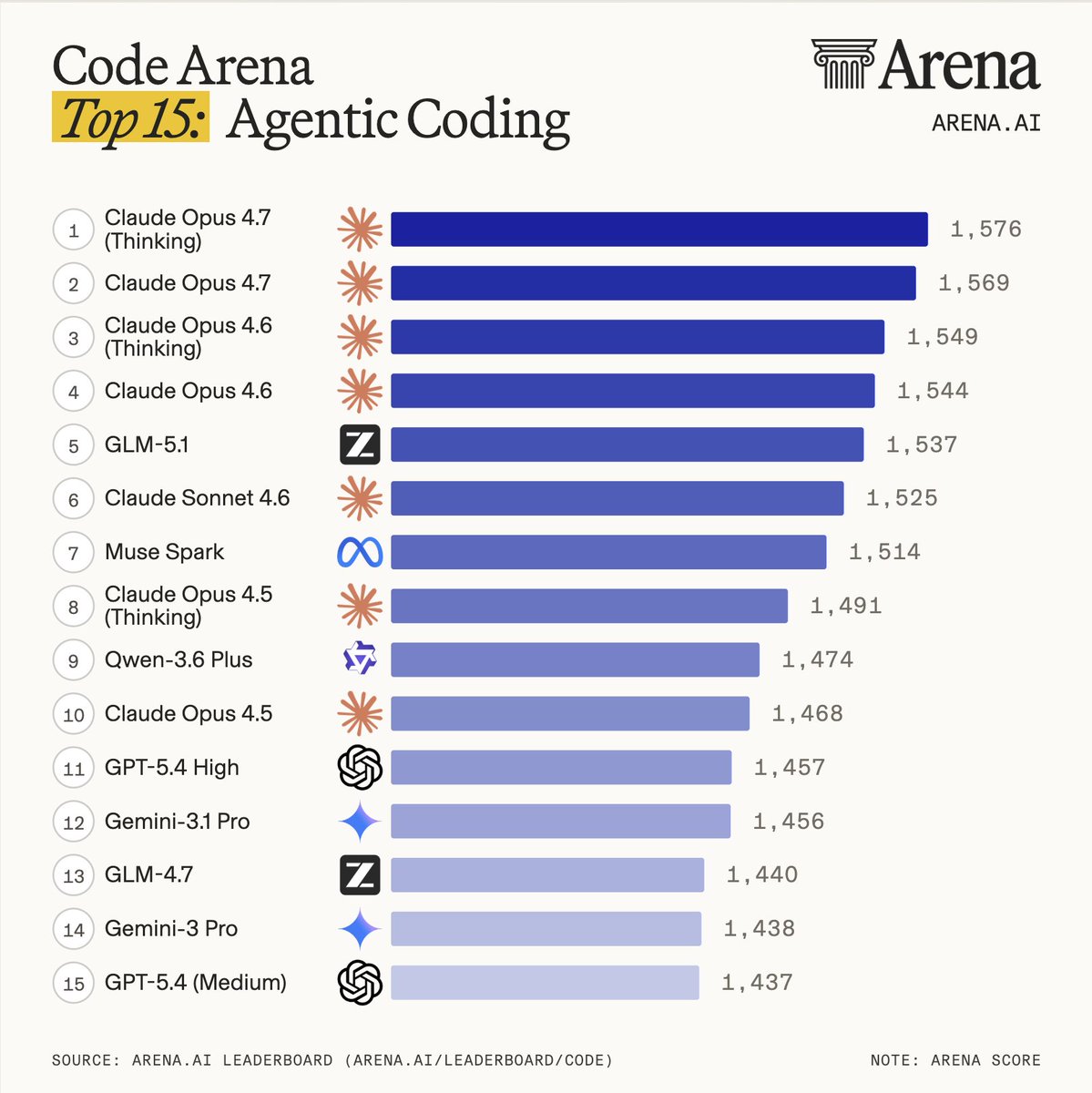
Nice debut from Muse Spark in the Agentic Coding arena.
Ranking ahead of GPT 5.4 and Gemini models, and behind the Opus series GLM 5.1.

Muse Spark debuts at #7 in the Code Arena - making @AIatMeta the #3 lab right behind @AnthropicAI’s Claude Sonnet 4.6 and @Zai_org’s GLM-5.1, surpassing Gemini-3.1-Pro and GPT-5.4.
Code Arena evaluates agentic coding on real-world tasks - building live websites and apps, ranked by users on real workflows. Huge congrats to @AIatMeta on this impressive milestone!
10
15
165
29,058
SangBin Cho retweeted

Apr 21
Small step for a finger on "post tweet" button.
Big step for millions of future AI agents doing useful work for us.
Apr 21

Today we're announcing Core Automation
Our objective: systems that optimize and automate work, starting with research itself.

58
37
671
167,987
SangBin Cho retweeted

Apr 21
Today we're announcing Core Automation
Our objective: systems that optimize and automate work, starting with research itself.
39
83
1,159
579,413
SangBin Cho retweeted

Apr 11
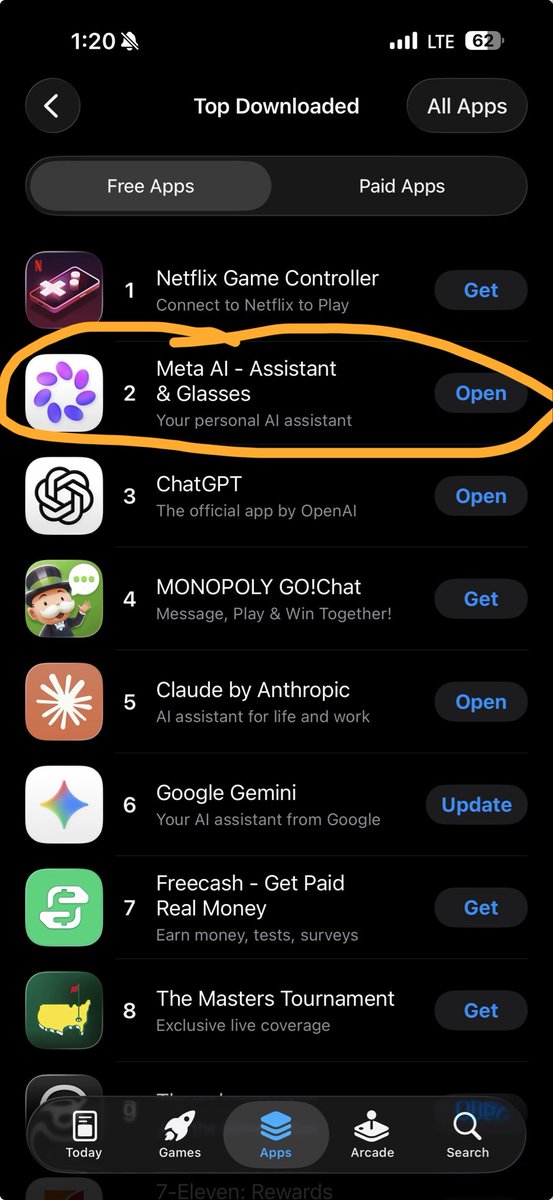
okay this is too exciting :)
meta AI is now #2 in the app store, top AI app!
we are so back!
256
117
2,173
336,393
SangBin Cho retweeted
Apr 10
the muse spark API will be coming soon!
we have been thrilled with the amount of excitement amongst developers who want to try muse spark inside their agentic harnesses
stay tuned!
127
89
1,746
176,325
SangBin Cho retweeted

Apr 8
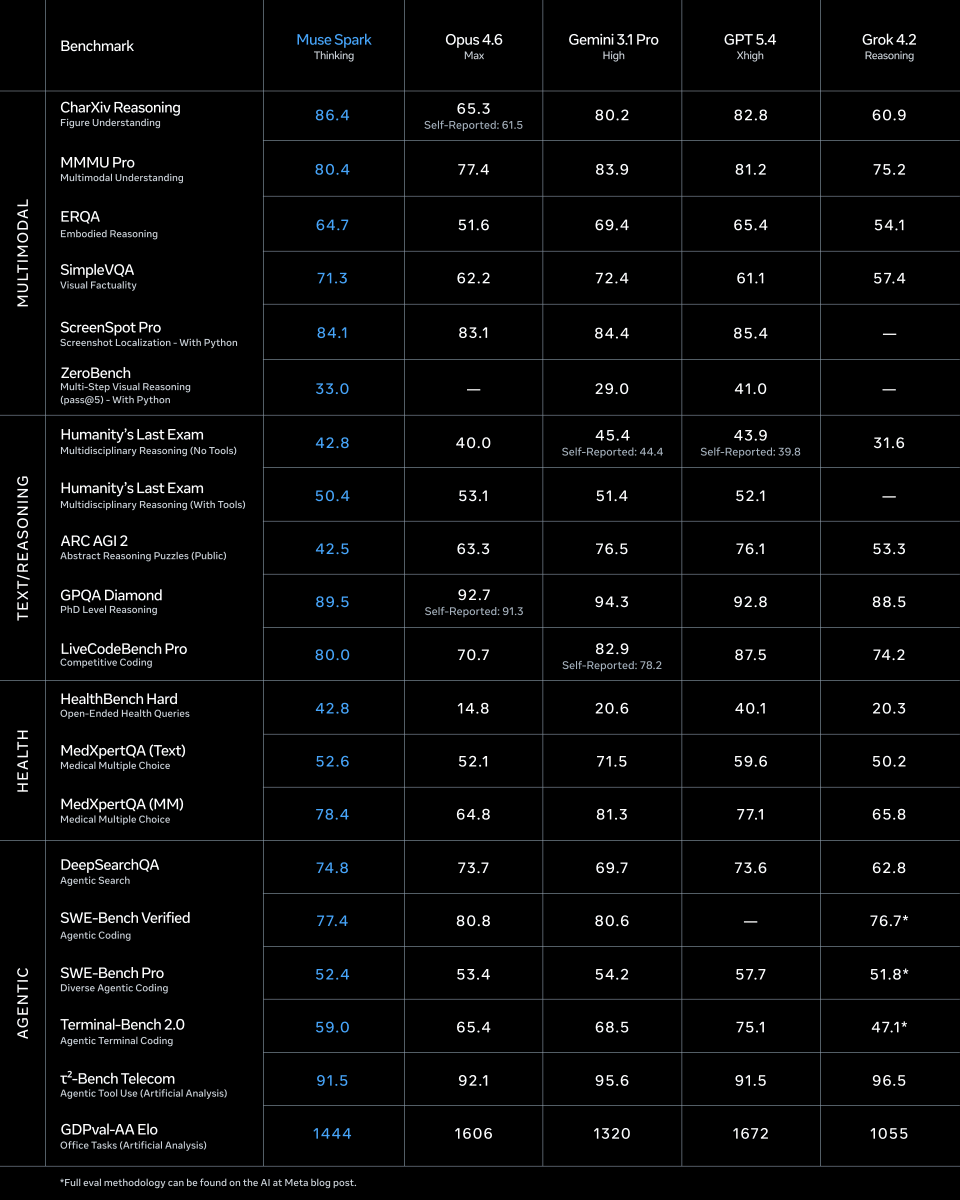
Check out Muse Spark, our first milestone in the quest for personal superintelligence! Scaling this with the team has been a total blast. Give it a spin and let us know what you think! 🥑
18
58
318
71,569
SangBin Cho retweeted

Mar 24
The RL training infra for Composer 2 was built with Ray. Very impressive work.


9
21
248
20,159
SangBin Cho retweeted

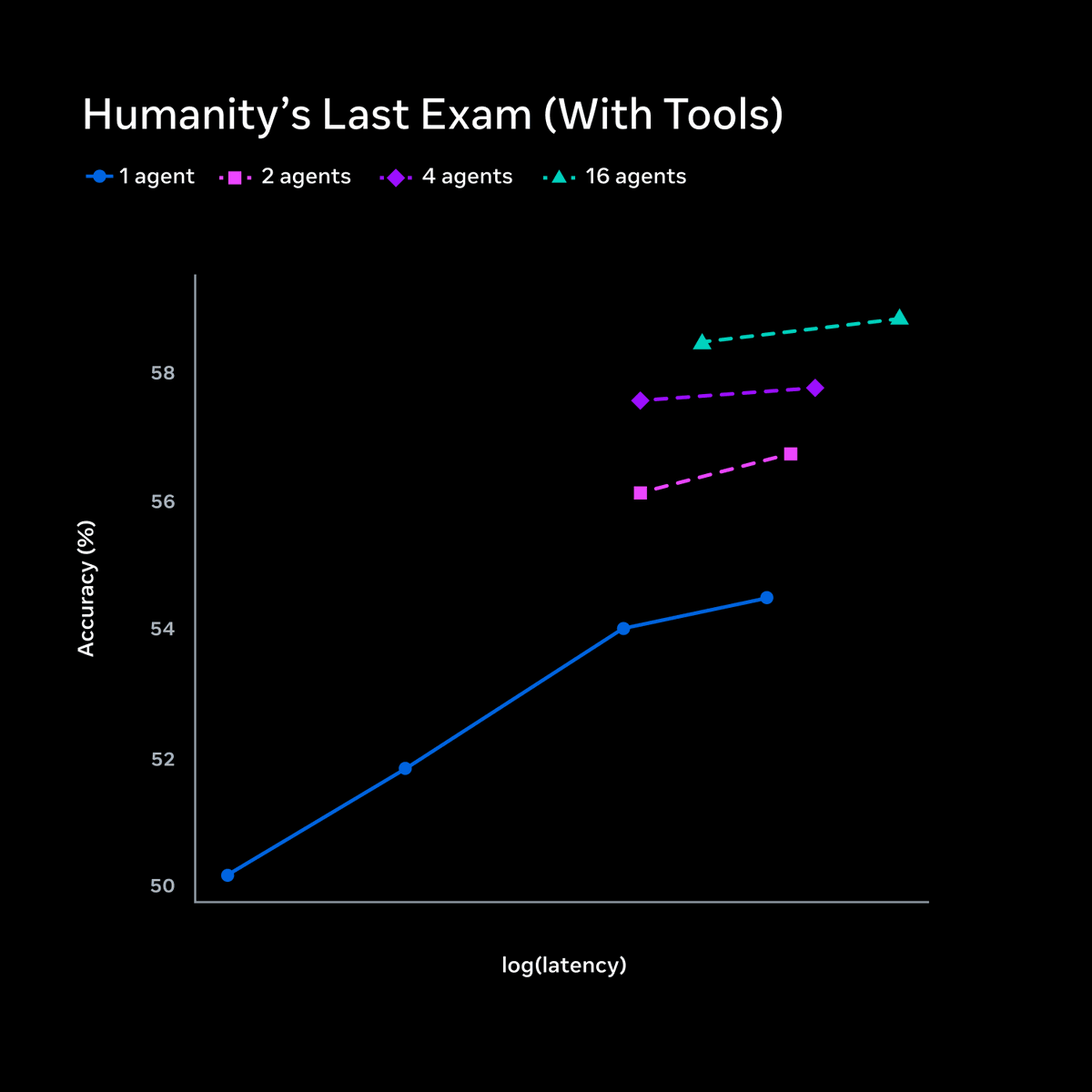
Feb 12
Building Grok to 10x the productivity of everyone
Since xAI was formed just 30 months ago, the small and talented team has made remarkable progress.
The future has never looked more exciting!
292
528
2,806
926,042
Feb 3
🚀

SpaceX has acquired xAI, forming one of the most ambitious, vertically integrated innovation engines on (and off) Earth → spacex.com/updates#xai-joins…

1
14
1,305
SangBin Cho retweeted

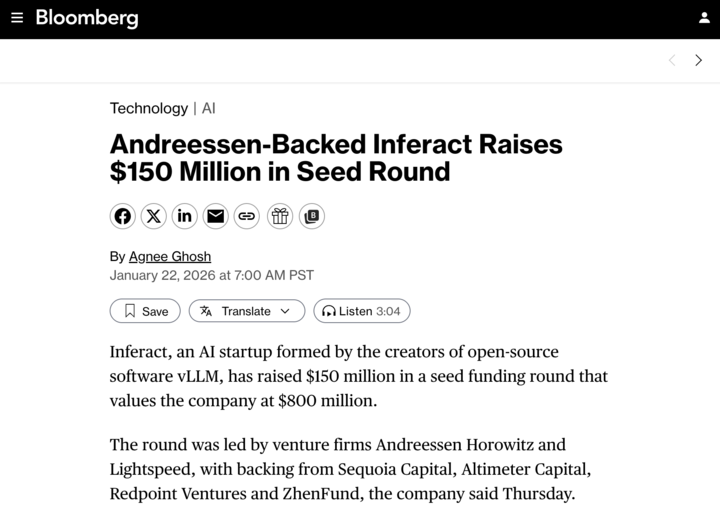
Jan 22
I am really excited about @inferact.
Working on OSS vLLM has been deeply rewarding. I joined Meta half a year ago, working on developing and deploying vLLM at large scale in a frontier-lab setting. While many of the technical challenges we face are shared, there are still hard problems that open source alone can’t fully solve - and this company is well positioned to tackle them.
My best wishes to the team. Go vLLM!
Jan 22

Today, we're proud to announce @inferact, a startup founded by creators and core maintainers of @vllm_project, the most popular open-source LLM inference engine.
Our mission is to grow vLLM as the world's AI inference engine and accelerate AI progress by making inference cheaper and faster.
The Challenge
Inference is not solved. It's getting harder.
Models grow larger. New architectures proliferate: mixture-of-experts, multimodal, agentic. Every breakthrough demands new infrastructure. Meanwhile, hardware fragments: more accelerators, more programming models, and more combinations to optimize.
The capability gap between models and the systems that serve them is widening. Left this way, the most capable models remain bottlenecked and with full scope of their capabilities accessible only to those who can build custom infrastructure. Close the gap, and we unlock new possibilities.
And the problem is growing. Inference is shifting from a fraction of compute to the majority: test-time compute, RL training loops, synthetic data.
We see a future where serving AI becomes effortless.
Today, deploying a frontier model at scale requires a dedicated infrastructure team. Tomorrow, it should be as simple as spinning up a serverless database. The complexity doesn't disappear; it gets absorbed into the infrastructure we're building.
Why Us
vLLM sits at the intersection of models and hardware: a position that took years to build.
When model vendors ship new architectures, they work with us to ensure day-zero support. When hardware vendors develop new silicon, they integrate with vLLM. When teams deploy at scale, they run vLLM, from frontier labs to hyperscalers to startups serving millions of users. Today, vLLM supports 500 model architectures, runs on 200 accelerator types, and powers inference at global scale. This ecosystem, built with 2,000 contributors, is our foundation.
We've been stewards of this engine since its first commit. We know it inside out. We deployed it at frontier scale—in research and in production.
Open Source
vLLM was built in the open. That's not changing.
Inferact exists to supercharge vLLM adoption. The optimizations we develop flow back to the community. We plan to push vLLM's performance further, deepen support for emerging model architectures, and expand coverage across frontier hardware. The AI industry needs inference infrastructure that isn't locked behind proprietary walls.
Join Us
Through the open source community, we are fortunate to work with some of the best people we know. For @inferact, we're hiring engineers and researchers to work at the frontier of inference, where models meet hardware at scale. Come build with us.
We're fortunate to be supported by investors who share our vision, including @a16z and @lightspeedvp who led our $150M seed, as well as @sequoia, @AltimeterCap, @Redpoint, @ZhenFund, The House Fund, @strikervp, @LaudeVentures, and @databricks.
- @woosuk_k, @simon_mo_, @KaichaoYou, @rogerw0108, @istoica05 and the rest of the founding team
3
11
219
25,131
SangBin Cho retweeted
Jan 22
vLLM has grown to 2000 contributors scale with a diverse community of model, hardwares, and applications. I see @vllm_project on the path of becoming the world's inference engine and @inferact to accelerate AI progress. We cannot be more excited about the road ahead.
Jan 22
Today, we're proud to announce @inferact, a startup founded by creators and core maintainers of @vllm_project, the most popular open-source LLM inference engine.
Our mission is to grow vLLM as the world's AI inference engine and accelerate AI progress by making inference cheaper and faster.
The Challenge
Inference is not solved. It's getting harder.
Models grow larger. New architectures proliferate: mixture-of-experts, multimodal, agentic. Every breakthrough demands new infrastructure. Meanwhile, hardware fragments: more accelerators, more programming models, and more combinations to optimize.
The capability gap between models and the systems that serve them is widening. Left this way, the most capable models remain bottlenecked and with full scope of their capabilities accessible only to those who can build custom infrastructure. Close the gap, and we unlock new possibilities.
And the problem is growing. Inference is shifting from a fraction of compute to the majority: test-time compute, RL training loops, synthetic data.
We see a future where serving AI becomes effortless.
Today, deploying a frontier model at scale requires a dedicated infrastructure team. Tomorrow, it should be as simple as spinning up a serverless database. The complexity doesn't disappear; it gets absorbed into the infrastructure we're building.
Why Us
vLLM sits at the intersection of models and hardware: a position that took years to build.
When model vendors ship new architectures, they work with us to ensure day-zero support. When hardware vendors develop new silicon, they integrate with vLLM. When teams deploy at scale, they run vLLM, from frontier labs to hyperscalers to startups serving millions of users. Today, vLLM supports 500 model architectures, runs on 200 accelerator types, and powers inference at global scale. This ecosystem, built with 2,000 contributors, is our foundation.
We've been stewards of this engine since its first commit. We know it inside out. We deployed it at frontier scale—in research and in production.
Open Source
vLLM was built in the open. That's not changing.
Inferact exists to supercharge vLLM adoption. The optimizations we develop flow back to the community. We plan to push vLLM's performance further, deepen support for emerging model architectures, and expand coverage across frontier hardware. The AI industry needs inference infrastructure that isn't locked behind proprietary walls.
Join Us
Through the open source community, we are fortunate to work with some of the best people we know. For @inferact, we're hiring engineers and researchers to work at the frontier of inference, where models meet hardware at scale. Come build with us.
We're fortunate to be supported by investors who share our vision, including @a16z and @lightspeedvp who led our $150M seed, as well as @sequoia, @AltimeterCap, @Redpoint, @ZhenFund, The House Fund, @strikervp, @LaudeVentures, and @databricks.
- @woosuk_k, @simon_mo_, @KaichaoYou, @rogerw0108, @istoica05 and the rest of the founding team
12
10
102
15,775