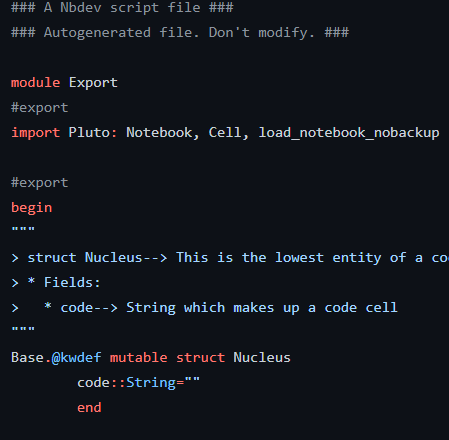
Great thought by
@Thom_Wolf on what it may take to create an AI that can create new things instead of just generating stuff from it’s training data.
I shared a controversial take the other day at an event and I decided to write it down in a longer format: I’m afraid AI won't give us a "compressed 21st century".
The "compressed 21st century" comes from Dario's "Machine of Loving Grace" and if you haven’t read it, you probably should, it’s a noteworthy essay. In a nutshell the paper claims that, over a year or two, we’ll have a "country of Einsteins sitting in a data center”, and it will result in a compressed 21st century during which all the scientific discoveries of the 21st century will happen in the span of only 5-10 years.
I read this essay twice. The first time I was totally amazed: AI will change everything in science in 5 years, I thought! A few days later I came back to it and, re-reading it, I realized that much of it seemed like wishful thinking at best.
What we'll actually get, in my opinion, is “a country of yes-men on servers” (if we just continue on current trends). Let me explain the difference with a small part of my personal story.
I’ve always been a straight-A student. Coming from a small village, I joined the top French engineering school before getting accepted to MIT for PhD. School was always quite easy for me. I could just get where the professor was going, where the exam's creators were taking us and could predict the test questions beforehand.
That’s why, when I eventually became a researcher (more specifically a PhD student), I was completely shocked to discover that I was a pretty average, underwhelming, mediocre researcher. While many colleagues around me had interesting ideas, I was constantly hitting a wall. If something was not written in a book I could not invent it unless it was a rather useless variation of a known theory. More annoyingly, I found it very hard to challenge the status-quo, to question what I had learned. I was no Einstein, I was just very good at school. Or maybe even: I was no Einstein in part *because* I was good at school.
History is filled with geniuses struggling during their studies. Edison was called "addled" by his teacher. Barbara McClintock got criticized for "weird thinking" before winning a Nobel Prize. Einstein failed his first attempt at the ETH Zurich entrance exam. And the list goes on.
The main mistake people usually make is thinking Newton or Einstein were just scaled-up good students, that a genius comes to life when you linearly extrapolate a top-10% student.
This perspective misses the most crucial aspect of science: the skill to ask the right questions and to challenge even what one has learned. A real science breakthrough is Copernicus proposing, against all the knowledge of his days -in ML terms we would say “despite all his training dataset”-, that the earth may orbit the sun rather than the other way around.
To create an Einstein in a data center, we don't just need a system that knows all the answers, but rather one that can ask questions nobody else has thought of or dared to ask. One that writes 'What if everyone is wrong about this?' when all textbooks, experts, and common knowledge suggest otherwise.
Just consider the crazy paradigm shift of special relativity and the guts it took to formulate a first axiom like “let’s assume the speed of light is constant in all frames of reference” defying the common sense of these days (and even of today…)
Or take CRISPR, generally considered to be an adaptive bacterial immune system since the 80s until, 25 years after its discovery, Jennifer Doudna and Emmanuelle Charpentier proposed to use it for something much broader and general: gene editing, leading to a Nobel prize. This type of realization –"we've known XX does YY for years, but what if we've been wrong about it all along? Or what if we could apply it to the entirely different concept of ZZ instead?” is an example of out-side-of-knowledge thinking –or paradigm shift– which is essentially making the progress of science.
Such paradigm shifts happen rarely, maybe 1-2 times a year and are usually awarded Nobel prizes once everybody has taken stock of the impact. However rare they are, I agree with Dario in saying that they take the lion’s share in defining scientific progress over a given century while the rest is mostly noise.
Now let’s consider what we’re currently using to benchmark recent AI model intelligence improvement. Some of the most recent AI tests are for instance the grandiosely named "Humanity's Last Exam" or "Frontier Math". They consist of very difficult questions –usually written by PhDs– but with clear, closed-end, answers.
These are exactly the kinds of exams where I excelled in my field. These benchmarks test if AI models can find the right answers to a set of questions we already know the answer to.
However, real scientific breakthroughs will come not from answering known questions, but from asking challenging new questions and questioning common conceptions and previous ideas.
Remember Douglas Adams' Hitchhiker's Guide? The answer is apparently 42, but nobody knows the right question. That's research in a nutshell.
In my opinion this is one of the reasons LLMs, while they already have all of humanity's knowledge in memory, haven't generated any new knowledge by connecting previously unrelated facts. They're mostly doing "manifold filling" at the moment - filling in the interpolation gaps between what humans already know, somehow treating knowledge as an intangible fabric of reality.
We're currently building very obedient students, not revolutionaries. This is perfect for today’s main goal in the field of creating great assistants and overly compliant helpers. But until we find a way to incentivize them to question their knowledge and propose ideas that potentially go against past training data, they won't give us scientific revolutions yet.
If we want scientific breakthroughs, we should probably explore how we’re currently measuring the performance of AI models and move to a measure of knowledge and reasoning able to test if scientific AI models can for instance:
- Challenge their own training data knowledge
- Take bold counterfactual approaches
- Make general proposals based on tiny hints
- Ask non-obvious questions that lead to new research paths
We don't need an A student who can answer every question with general knowledge. We need a B student who sees and questions what everyone else missed.
---
PS: You might be wondering what such a benchmark could look like. Evaluating it could involve testing a model on some recent discovery it should not know yet (a modern equivalent of special relativity) and explore how the model might start asking the right questions on a topic it has no exposure to the answers or conceptual framework of. This is challenging because most models are trained on virtually all human knowledge available today but it seems essential if we want to benchmark these behaviors. Overall this is really an open question and I’ll be happy to hear your insightful thoughts.