
Applied AI Engineer (Msc) | Building Intelligent Agents.
Joined January 2016
- Tweets 10,728
- Following 1,175
- Followers 1,001
- Likes 28,472
276 Photos and videos













Richmond retweeted

Jun 10
Introducing Decentralized Language Models (DeLM)!
DeLM is a multi-agent framework that enables asynchronous, verified & reusable progress!
It makes agentic tasks more accurate and significantly cheaper. For example, it achieves 65.7% on SWE-bench Verified using Gemini 3-Flash, a ~10% jump over the best centralized alternatives at less than half the cost.
Great work led by @Mao_Yuzhen !

Jun 10

What happens when multi-agent systems stop relying on a central “controller” agent? Can agents coordinate by sharing results directly with each other?
Introducing Decentralized Language Models (DeLM): we let agents coordinate asynchronously through a shared context. Agents claim tasks from a queue and write back compact, verified results as they finish, making progress visible to all workers without requiring a main agent to merge, filter, and rebroadcast it.
New paper with @azaliamirh!
8
27
243
28,219
Richmond retweeted

Jun 8
Design is full of codewords. Knowing them changes what you can ask for, and what you can get back, whether you're working with devs, or an AI.
“tint this neutral color”, “fix this widow”, “nudge it to the optical center”
I wrote them down: index.how/to/articulate
63
180
2,179
287,479
Richmond retweeted

designing loops is so outdated. if you’re not astral projecting to become one with claude, you’re ngmi
Jun 7

Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore.
You should be designing loops that prompt your agents.
25
54
1,132
36,112

Richmond retweeted

May 30
Karpathy found a way to reduce token consumption by 90%
The problem is that the LLM re-reads the same files over and over again, loses context between documents, and provides less accurate answers as a result
The solution is called Wiki Layer the LLM cleans, structures, and links all your data once, after which it never works with raw files again
Three folders `raw/` for originals, `wiki/` for a clean knowledge base in Markdown, and files with rules for the agent
Result up to 90% token savings on repeat queries, automatic links between documents, and a visual knowledge graph in Obsidian
Everything stays on your local machine nothing goes to the cloud

Community note
Karpathy described using LLMs to compile raw data into a markdown wiki for efficient querying but did not claim 90% token savings or call the method "Wiki Layer." x.com/karpathy/statu…
154
420
4,252
1,070,340
Richmond retweeted

May 31
parakeet.cpp: native C /ggml (@ggml_org) inference for @NVIDIAAIDev's Parakeet, one of the best speech-to-text models out there, from the @LocalAI_API team.
Every Parakeet model (TDT/CTC/RNNT/hybrid cache-aware streaming), byte-for-byte identical output to NeMo, now running anywhere with no Python and even a bit faster, on CPU and GPU.
Quantized GGUF on @huggingface 🤗
Huge thanks to @ggerganov for ggml and to @NVIDIAAIDev for releasing Parakeet! 🧵
14
56
367
55,349
Richmond retweeted

13 Oct 2021
'I only support teams in London without European Cups' 🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩🚩
1,835
21,670
79,829
Richmond retweeted
13 Jul 2025
FIFA CLUB WORLD CUP WINNERS!!! 🏆

7,407
61,730
229,073
12,994,950
Richmond retweeted

May 22
Every memory system for LLM agents evolves what it stores. None evolves how it retrieves.
🧬 EvolveMem is out, now shipping inside the SimpleMem v0.3.0 update. Powered by AutoResearch: the system researches its own retrieval, treating the full retrieval config as a structured action space and running a closed loop: evaluate ➜ diagnose ➜ propose ➜ validate ➜ repeat.
🔬 From a minimal baseline, 7 autonomous rounds produce a retrieval policy that beats the strongest published baseline by 25.7% on LoCoMo and 18.9% on MemBench.
🧬 It discovers entirely new retrieval dimensions not present in the original design, all integrated into the unified SimpleMem package.
📄 Paper: arxiv.org/abs/2605.13941
💻 Code: github.com/aiming-lab/Simple…
Led by @itsJiaqiLiu, @XinyeYee with contributions from @richardxp888, @ZhengBerkeley, @cihangxie

12
80
422
28,667

Backprop strongly shapes the GPU hardware AI runs on today.
Learning algorithms without backprop open new opportunities for neuromorphic silicon, biologically grounded models, and heterogeneous compute.
Paper: arxiv.org/abs/2605.21568
Blog: zyphra.com/post/equilibrium-…
2
12
154
40,286
Richmond retweeted

May 22
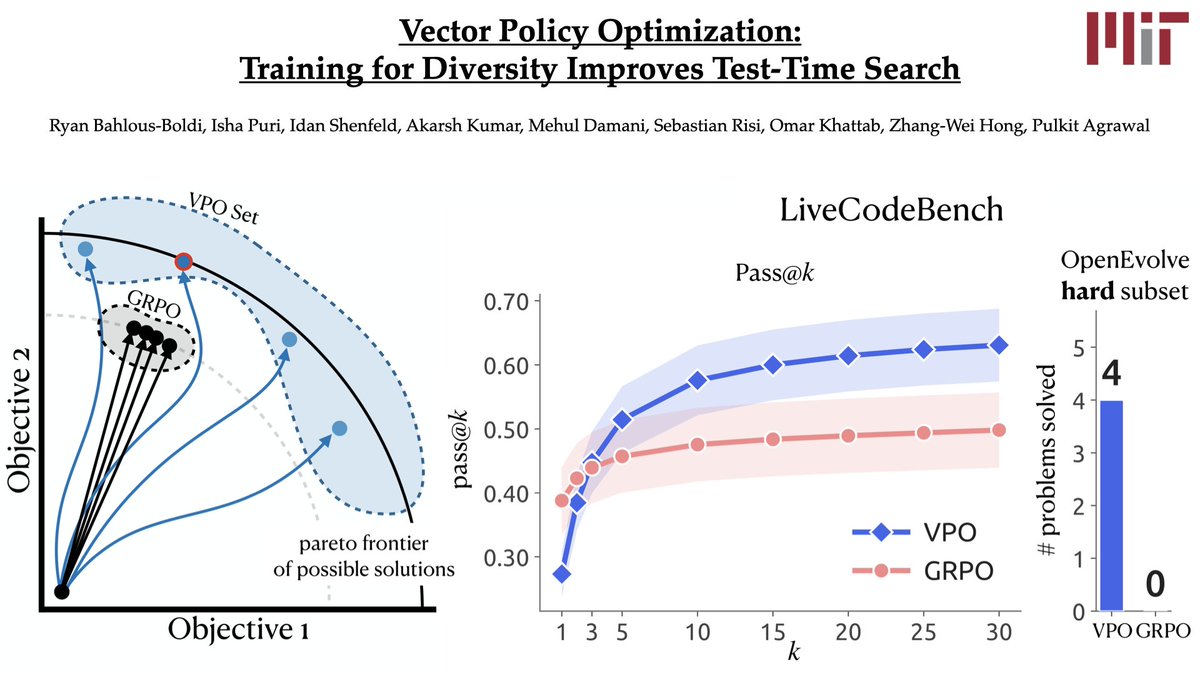
It's never made sense to me that RL collapses all reward signals to a single scalar. Today, we fix that!
Introducing Vector Policy Optimization: we train models to inherently optimize for the varied nature of a reward vector, creating diverse sets of answers ideal for test time search. Website and code coming soon!
May 22

Your RL post-training may be sabotaging your LLM’s test-time scaling!
Conventional RL pretends that you can collapse all reward signals *upfront* into a single *scalar reward*.
We introduce Vector Policy Optimization (VPO), which natively maximizes *vector-valued* rewards, boosting test time search performance, even on the original scalar.
11
66
716
68,711
Richmond retweeted

May 18
neural geometry in biology! i think we're going to learn a lot about our own brains by studying neural networks
May 18

Biological networks too :)
Here is the neural geometry of mice navigating a figure-8 maze.

23
204
15,356
Richmond retweeted

May 19
SCALING ISN’T EVERYTHING
Another tiny model breaking the rule.
-trained on less than 1/1000th of the data
- can be trained in a single day with <1000 USD
Human knowledge base ca be compressed & retrieved much tighter than LLMs do today.
May 18

Introducing HRM-Text.
An ultra-lean 1B-parameter reasoning language model designed to deliver strong general performance with a fraction of the data, compute, and infrastructure.
Trained on just 40B structured tokens, HRM-Text achieves competitive performance while using ~1/1000 of the training data of comparable models.
The kicker? The full model trains in roughly one day on a $1,000 budget.
This opens the door to a new generation of AI that is powerful, accessible, and radically easier to adapt. Theories and research concepts once deemed too expensive to test are officially back in the game.
Sapient Intelligence invites you to help us shape a new paradigm for general intelligence.
4
5
81
11,361
Richmond retweeted

May 15
Ooo let me add a layer above it. Harness-Orchestration - agentfield.ai/blog/what-is-h…
6
31
14,978
Richmond retweeted

May 15
SSH Tailscale is how I am managing multiple machines from the same phone.
Give it a shot.
May 15

Codex mobile app can now manage all my devices through tailscale. Incredible. OpenAI won.
GG

12
12
261
32,067
Richmond retweeted

May 14
👀

May 14

Neural networks do math by rotating shapes.
We found a shape-rotating calculator hidden inside an LLM – and it’s used for more than just math! (1/6)
15
156
1,968
116,998
Richmond retweeted

May 14
🚨 BREAKING: NVIDIA proved back-propagation isn't the only way to build an AI.
Billion-parameter models were trained without a single gradient. No calculus, no exploding memory, no massive GPU clusters.
The culprit? A long-dismissed technique called Evolution Strategies.
NVIDIA and Oxford just made it scalable with EGGROLL, which replaces bloated mutation matrices with two tiny ones, enabling hundreds of thousands of parallel mutations at inference-level speed.
They're pretraining models from scratch using only simple integers. No backprop. No decimals.
We assumed the future of AI required endless precision hardware. Evolution had other plans.

29
179
1,253
269,150
Richmond retweeted

Ize wa do ya gbele vbo wa 🤦🏼♀️
May 3

First Lady, Oluremi Tinubu Donates 100 Trucks Of Rice For 19 Northern Muslims States👀:
29
19
68
4,158
Richmond retweeted

Apr 19
Building a data-driven recruitment engine for football is about spatial intelligence.
I’ve been developing a tactical system that uses Go and Three.js to turn raw match data into 3D tactical insights.
github.com/nutcas3/tactical-…
#SportsTech #Golang #DataScience #FootballAnalytics
10
29
961