
Joined November 2024
- Tweets 463
- Following 513
- Followers 4
- Likes 1,861
Photos and videos

现在的叙事是:读什么 PhD,早点去大厂套现
“最快等你 4 年毕业,解放战争才打了三年多,全面抗战都打一半了”
能不登校就不登校,大不了 AI 泡沫散了被裁员了再去读 PhD,你的 credit 永远是你的,只会原来越多
感谢推友告诉我今年校招多么夸张,已严肃投递春招 research 岗,大不了当 gap year
这样一看,从我决定放弃保研到现在也才一个月,这个世界的信息差一直很大,永远不要失去想象力
Jun 8

以前的叙事是:CS PhD = 改命,大厂 = 上岸。
现在有人从美国 CS PhD 退学,去做现场电工/新能源设备,虽然累、晒,但至少每天解决的问题是具体的。
而是很多白领路径正在失去确定性,体面也越来越像一种高成本幻觉。

105
17
294
60,214
cleo retweeted

May 31
OpenAI Robotics is making rapid progress towards building AI that can help people in the physical world.
Apply now to join the team:
May 31

OpenAI Robotics is hiring, looking for exceptional full-stack hardware, ops, systems, and ML engineers to help us program and manufacture robots that are useful for society.
AI should be able to help people in the physical world. In the short term, we are focused on robots to support skilled workers to build our future infrastructure; in the long term, we imagine everyone having a personal robot doing anything they need.
Our world simulation research program, led by Aditya Ramesh (@model_mechanic), has evolved over the past year into OpenAI Robotics. Progress is rapid, and based on a foundation of co-design between robotics hardware and ML research.
If you love working hands-on across the robotics stack and want to build the future, please consider joining us. Send an email with your background and evidence of exceptional accomplishment to: robotics-recruiting@openai.com
198
127
2,436
264,358
cleo retweeted

May 31
We’re hiring full-stack roboticists, and solving robotics with a full-stack mentality: hardware, systems, ops, and ML… all moving together. Come and build with us.
May 31
OpenAI Robotics is hiring, looking for exceptional full-stack hardware, ops, systems, and ML engineers to help us program and manufacture robots that are useful for society.
AI should be able to help people in the physical world. In the short term, we are focused on robots to support skilled workers to build our future infrastructure; in the long term, we imagine everyone having a personal robot doing anything they need.
Our world simulation research program, led by Aditya Ramesh (@model_mechanic), has evolved over the past year into OpenAI Robotics. Progress is rapid, and based on a foundation of co-design between robotics hardware and ML research.
If you love working hands-on across the robotics stack and want to build the future, please consider joining us. Send an email with your background and evidence of exceptional accomplishment to: robotics-recruiting@openai.com
28
32
674
54,212
cleo retweeted

May 26
当生活几乎被 AI 填满后,我开始意识到:工作流可以自动化,表达可以被润色,代码可以被重写,但孤独、爱、亲密关系这些东西,依然绕不开人本身。
越追求效率,越发现自己真正缺的不是效率,而是连接。

38
8
166
69,807
cleo retweeted

May 26
看完很感触。虽然我自己在感情上一踏糊涂,但还是有点微小的经验可以分享分享。希望拾一不要介意。
第一,尽量不要试图通过线上交流培养感情。做我们这一行,很容易忽略了线下交流的魅力所在。双方的第一次眼神接触,第一次交谈,交谈过程中双方的反应,人格魅力的互相释放,身体的气味,等等,都是两个人是否能走在一起最关键的因素。在交往前,荷尔蒙永远无法通过文字传递。
因此不应该在通讯录中找对象突然开始话题,这十分不明智,除非这个人本来就对你有兴趣。
不过,拾一找「学习委员」聊天并约出来见面吃饭,这是其实是很正确且勇敢的做法。但拾一认为「现在慢慢地基本上没有什么可聊的了,再主动去约的话,也不会有什么结果。这仍然是一段非常不对等的关系,你主动付出是得不到什么回应的,不管是情绪价值还是别的什么」,这种想法我觉得有点过于伤害了自己。
不应该认为「主动付出是得不到什么回应的」,因为对方同意出来线下见面吃饭,已经是最好的回应。至于结果如何,是双方是否来电决定的,如果没有交往的可能,只是两个人不匹配,或是一方期望对方主动,而一方不够主动所导致的错位。并非拾一所认为的「关系不对等」,无需太过自责。
所以,尽可能多地制造线下社交的机会。这是效率最高的,且最锻炼一个人社交能力的方式。尝试用一些 Dating App, 或参加线下活动,或清吧,或剧本杀,或同好组,等等,人为地把自己放在公共场所。去了解,去沟通,去接触。
有人会说,Dating App 有认真谈恋爱的吗?我认为在这个阶段,首要追求的并不是情感的质量,而是把自己投入到情感当中。没有人能保证恋爱的质量,即使不是通过 Dating App 认识的对象。恋爱的目的永远是通过在恋爱或情感中,更加了解你自己。你对爱情的看法,你对对象的期望,你想和什么样的人过生活。
每一份爱情无论成功与否,只要你能从中得到成长,这份感情就是有价值的。我们在相爱的过程中学习爱的能力,我们通过爱情弥补过去情感教育的缺失。
拾一说,「一方面,我渴望拥有这样的关系;而另一方面,我更多的是担心自己能不能承担起这样的责任。随着岁数越来越大,这种恐惧和矛盾也变得越来越严重。扪心自问一下,我向往的关系是什么样的呢?」
我相信,只要投入到一段关系中,拾一能对这些问题有更清楚的理解。因为只有自己最了解自己,短视频上的恋爱,无论是充满浪漫甜蜜还是充满悲观,都是一千个人的一千种爱情,而不是自己的爱情。
第二,一定要自信。
拾一在咱圈子里如此牛逼,足够有自信的资本。或许有人认为,在别人面前谈论技术有多牛逼未免有点太尴尬。这是当然的。牛逼的技术能力并不是用来聊天的资本,自信是散发出来的,而能力是散发自信的基底,它处于自信的立足层,而在此之上的,是你通过技术,想成为一个什么样的人,想做成什么样的事,想改变哪些你认为不合理的东西,这些构成了你的价值观,你的世界观。而这些往往就是你的魅力所在。我相信拾一在这方面肯定有足够的自信。只是还没把它通过合适的方式散发出来而已。
当然,交流的技巧也是相当重要的一部分。如何使对方感受到被尊重,如何不把话题聊死,等等,不过这些都足够写成一本书了。在这里就不展开了。
茫茫人海中,能找到互相喜欢的,甚至双方都愿意一起过下去的人本来就是一件很难的事情,个人所能做到的,就是尽可能地学习、创造机会,让概率最大化。创业也是如此吧。
加油拾一。
最后推荐一本沈奕斐的书《什么样的爱值得勇敢一次》,希望有帮助。
May 26

当生活几乎被 AI 填满后,我开始意识到:工作流可以自动化,表达可以被润色,代码可以被重写,但孤独、爱、亲密关系这些东西,依然绕不开人本身。
越追求效率,越发现自己真正缺的不是效率,而是连接。
26
19
259
75,738
cleo retweeted

May 19
兄弟们,一个挪威神经科学家花了整整20年,就为了证明一件事:
手写笔记和打字,在大脑里是完全不同的两件事。
她叫Audrey van der Meer,在Trondheim经营脑科学研究实验室。
2024年她在Frontiers in Psychology上发的那篇论文,直接把争议画上了句号。
实验很简单:36名大学生戴上256通道EEG帽。
屏幕上闪出一个单词。
一半人用数字笔在触屏上手写,另一半直接在键盘上打字。
结果惊人:
手写时,大脑全亮。
记忆区、感觉整合区、新信息编码区全部同步激活,像整个皮层网络同时醒过来。
打字时呢?
大部分脑区瞬间安静,刚才那些连接几乎全消失。
同一个单词、同一个大脑、同一个人,两套完全不同的神经事件。
原因藏在微动作里:手写每一个字母,都是上千个微小动作和眼睛实时配合的空间问题。
手指、手腕、视觉、空间定位全在协同工作。
打字呢?
每按一个键都是完全相同的动作,大脑几乎不需要整合,也没什么问题要解决。
十年前普林斯顿的另一组研究用完全不同的方法也得到了相同结论:手写笔记的学生在真正理解题上完胜,打字组只记住了表面内容。
因为手写逼你必须听、必须选、必须用自己的话重新组织。
打字让你像复印机一样狂敲,却几乎没经过大脑加工。
我看完后最大的感受是:
我们以为打字是效率,手写是老派。
其实手写才是真正让知识扎根

May 18

A Norwegian neuroscientist spent 20 years proving that the act of writing by hand changes the human brain in ways typing physically cannot, and almost nobody outside her field has read the paper.
Her name is Audrey van der Meer.
She runs a brain research lab in Trondheim, and the paper that closed the argument was published in 2024 in a journal called Frontiers in Psychology. The finding is brutal enough that it should have changed every classroom on Earth.
The experiment was simple. She recruited 36 university students and put each one in a cap with 256 sensors pressed against their scalp to record brain activity. Words flashed on a screen one at a time.
Sometimes the students wrote the word by hand on a touchscreen using a digital pen, and sometimes they typed the same word on a keyboard. Every neural response was recorded for the full five seconds the word stayed on screen.
Then her team looked at the part of the data most researchers had ignored for years, which is how different parts of the brain were communicating with each other during the task.
When the students wrote by hand, the brain lit up everywhere at once.
The regions responsible for memory, sensory integration, and the encoding of new information were all firing together in a coordinated pattern that spread across the entire cortex. The whole network was awake and connected.
When the same students typed the same word, that pattern collapsed almost completely.
Most of the brain went quiet, and the connections between regions that had been alive seconds earlier were nowhere to be found on the EEG.
Same word, same brain, same person, and two completely different neurological events.
The reason turned out to be something nobody had really paid attention to before her work. Writing by hand is not one motion but a sequence of thousands of tiny micro-movements coordinated with your eyes in real time, where each letter is a different shape that requires the brain to solve a slightly different spatial problem.
Your fingers, wrist, vision, and the parts of your brain that track position in space are all working together to produce one letter, then the next, then the next.
Typing throws all of that away. Every key on a keyboard requires the exact same finger motion regardless of which letter you are pressing, which means the brain has almost nothing to integrate and almost no problem to solve.
Van der Meer said it plainly in her interviews.
Pressing the same key with the same finger over and over does not stimulate the brain in any meaningful way, and she pointed out something that should scare every parent who handed their kid an iPad.
Children who learn to read and write on tablets often cannot tell letters like b and d apart, because they have never physically felt with their bodies what it takes to actually produce those letters on a page.
A decade before her, two researchers at Princeton ran the same fight using a completely different method and ended up at the same answer. Pam Mueller and Daniel Oppenheimer tested 327 students across three experiments, where half took notes on laptops with the internet disabled and half took notes by hand, before testing everyone on what they actually understood from the lectures they had watched.
The handwriting group won by a wide margin on every question that required real understanding rather than surface recall.
The reason was hiding in the transcripts of what the two groups had actually written down.
The laptop students typed almost word for word, capturing more total content but processing almost none of it as they went, while the handwriting students physically could not write fast enough to transcribe a lecture in real time, which forced them to listen carefully, decide what actually mattered, and put it in their own words on the page.
That single act of choosing what to keep was the learning itself, and the keyboard had quietly skipped the choosing and skipped the learning along with it.
Two studies. Two countries. Same answer.
Handwriting makes the brain work. Typing lets it coast.
Every note you have ever typed instead of written went into your brain through a thinner pipe. Every meeting, every book highlight, every idea you captured on your phone instead of on paper was processed at half depth.
You did not forget those things because your memory is bad. You forgot them because typing never woke the part of the brain that would have made them stick.
The fix is the thing your grandmother already knew.
Pick up a pen. Write the thing down. The slower road is the faster one.

162
661
3,032
532,234
cleo retweeted
May 18
兄弟们,今天必需卧槽一下了!
昨晚发完这条推文后,终于等到了…
xAI算法开源后,终于有人把源码真正啃完了。
岚叔@LufzzLiz (某大厂架构师,多模态与模型私有化领域专家)直接上手,把xai-org/x-algorithm仓库的每一行结论都追溯到源码,用Opus-4.7花了两天时间,搞出了一个完整wiki。
所有页面都有明确源码出处,跟市面上很多“AI批量生成”的解读完全不一样,直接Wiki库整起来了… 就是不一样啊!
这才是真正有价值的算法拆解。
GitHub仓库:github.com/cclank/x-algorith…
在线阅读地址:lansu-wiki-web.lank.workers.…
May 17

xAI 算法开源后,解读内容铺天盖地。
我敢说一句颠覆多数人认知的实话:
市面上 95% 的分析,是 AI 批量生产的同质化废话,
连源码文件名都没翻过一次。
「多互动」「多发帖」「账号要垂直」
这种谁都会说的话,说了等于没说。
真正藏在 xAI 算法深处的机制,
大多数人连名字都没听过,
却在教别人怎么运营 X。
你见过哪篇解读,是真的牛逼有价值,欢迎推荐!
如果没有我就来个收费的文章😁 绝对牛逼!
开玩笑,我也是每天在一点点的啃~~
但是真的惊喜不断!

20
65
321
52,514

由于这篇文章太伟大了,所以我把它变成了一个 Agent Skill。
大家可以使用自己的 Coding Agent 安装一下这个 Skill,这样就可以用「最佳实践」来轻松地重构或者开发一个既容易跨平台、又极其接近 Native 性能的桌面端应用。
github.com/yetone/native-fee…
May 14

everything you need to know about how the team built the new @raycast from the ground up
honestly worth a read 👉 raycast.com/blog/a-technical…
there's nothing to hide
39
269
2,105
267,837
cleo retweeted

May 11
这篇文章强烈推荐:KV Caching in LLMs
写得挺清晰的,从第一性原理出发,配了动图对比,适合不太了解推理优化的人。
核心现象:你用 ChatGPT/Claude 的时候,第一个字出来特别慢,后面噼里啪啦就全出来了。原因是 KV Caching。
6个部分讲清楚了这个机制:
1. LLM 怎么生 token:Transformer 处理所有输入 token,每个产生一个 hidden state,但只有最后一个 token 的 hidden state 用来预测下一个词。前面的都是中间产物。
2. Attention 在算什么:每层里每个 token 有 Q、K、V 三个向量。要算最后一个 token 的输出,需要它的 Q × 所有 token 的 K 和 V。
3. 冗余在哪:生成第50个 token 要用 1-49 的 K、V;生成第51个又要用 1-50 的。1-49 的 K、V 根本没变,但模型每次从头重算。浪费 O(n²) 的计算。
4. 解决办法:把算过的 K、V 存起来(cache)。每步只算新 token 的 Q、K、V,然后把新的 K、V 追加到缓存里,attention 用新 Q 对完整缓存跑。这就是 KV Caching。
5. 为什么第一个字慢:你发 prompt 的时候,模型要一次性处理整个输入,算出所有 token 的 K、V 并缓存——这叫 prefill 阶段,是最吃算力的。缓存建好后,后续每个 token 只需一次单 token 前向传播。
6. 代价是显存:KV Cache 用计算换内存。以 Qwen 2.5 72B 为例,单请求的 KV Cache 可以吃掉好几 GB 显存。并发量一大,KV Cache 比模型权重本身还大。这就是为什么有 GQA/MQA(共享 key/value head 省显存)和 Paged Attention(高效管理 KV Cache 内存)。
所有主流推理框架(vLLM、TGI、TensorRT-LLM)都基于这个思路。👇

27
265
1,174
197,241

cleo retweeted
May 11
some news: I’ve joined OpenAI.
After wrapping up my PhD in Robotics, I’m excited to keep working toward AGI in the physical world.
exciting journey ahead :)

236
59
2,401
225,155
cleo retweeted

Apr 30
If there is one secret recipe about GPT Image 2, it must be codex. In the last 6 months, codex has been zero-shoting every single prompt I tried. GPT Image 2 is 99% coded by codex. The codex team is integrating image gen into the ecosystem for more agentic capabilities, hope you enjoy!
21
12
293
17,440
写的非常详细的入门教程
RL 很恶心的点就在于你什么都要会:pretrain、inference、theory、infra
现在我也有了可以推荐给别人入门的读物,比我当时东看一点西看一点好太多了🥺
很多现代 LLM 的教学其实跳过了相当一部分的基础知识,比如 CNN、Q-Learning 这一类经典内容。我感觉我也是填鸭式地在学习这些内容,需要耐下心来慢慢地去看那些最旧最老最传统的东西
很感谢苏剑林的 blog 带我入门,我也想能写出一些带别人入门的东西,只不过即使是用 LLM 辅助写 notes 也相当折磨人,然后知乎上还没什么人看
当然还是有很多人喜欢看我写的垃圾 notes 的,还被行业杰青大佬订阅了,这种事跟 paper 被人关注了一样开心
Website: walkinglabs.github.io/hands-…
May 2
比较有趣的入门教程
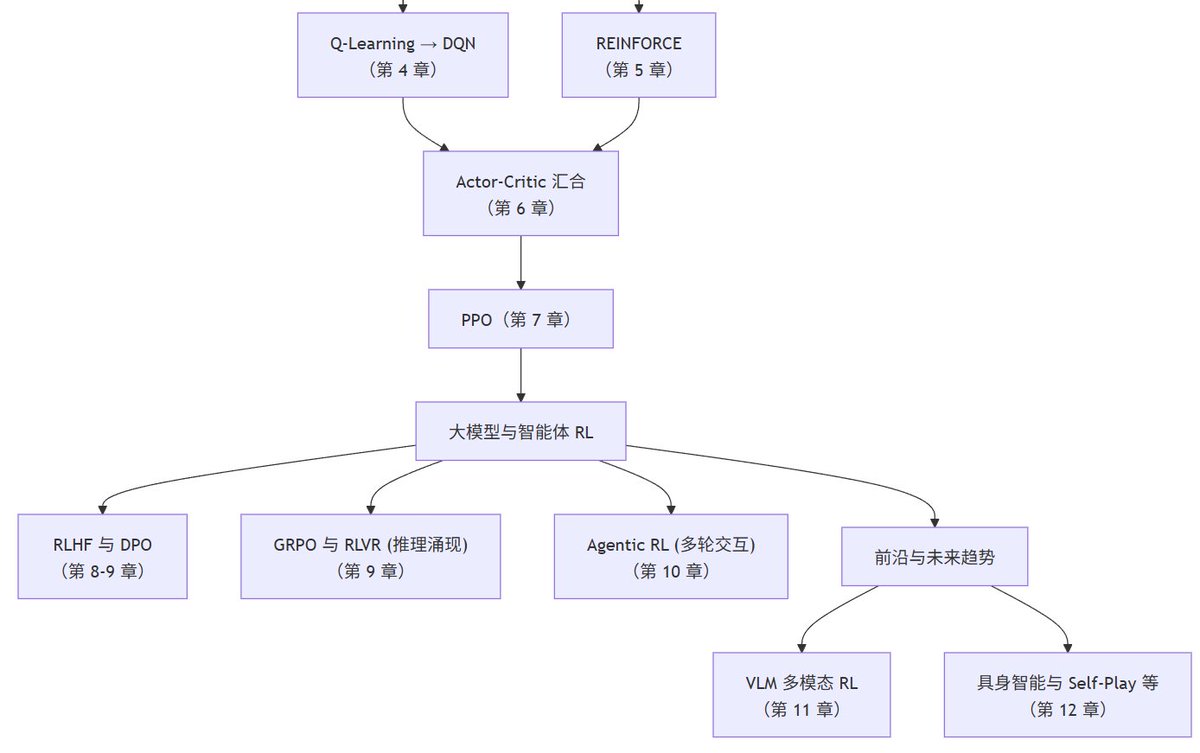
该项目希望用一条更“实践优先”的路径来学习现代强化学习:从经典控制出发,逐步连接到 LLM 后训练基础、DPO/GRPO/RLVR、Agentic RL 和 VLM RL 等现代应用。
GitHub: github.com/walkinglabs/hands…
WebPage: walkinglabs.github.io/hands-…


15
277
1,839
192,212



其实以字节为例,看看 Seed 校招/社招的岗位,你就能知道工业界要什么方向:seed.bytedance.com/zh/seedea…
LLM 所有的主流方向目前都不怎么天坑
- Foundation:训练(pretrain、RL)、推理(链路、算子、分布式)、数据(核心科技)、Infra(最吃资历)
- AGI:多模态、语音、具身、Agent
- 业务:AI 搜推(最热门的方向)、ToC
本科无算法、算法无本科,但是本科开始做 MLsys/数据 这一大类还是熬的出来
- 如果你想早点套现,读个研究生做 AI 搜推/基模是最吃香的
一些适合去学术界的方向
- 安全(攻防、差分隐私)、可解释性、传统 ML/RL
- 传统 CV
- Theory
剩下的方向本人就不太了解了,比如 AI4Sci
May 3

现在有人觉得 CS 可能是天坑,但 AI 不是天坑,我觉得这种说法部分正确。
AI 也要分清 LLM 和非 LLM,做 LLM 也要分工业界 care 的东西和工业界不 care 的东西。1% vs 99% 的分化在算法岗位上依然存在。
AI 是个很大的 topic,很多细分方向一样找不到工作。
31
78
740
134,787

对于想偷懒的小伙伴,这篇文章不要读,直接扔给你的 tw93/waza,然后让他使用 /read 和 /think 两个技能自动帮你去优化就好,只要10min就给你搞完了。

9
30
220
47,727
cleo retweeted

May 2
穷人最不值钱的是什么?
1,对注意力的挥霍和滥用。
通常,一些陷入贫瘠或瓶颈的人,其注意力主要消耗在家长里短、八卦、宏大叙事、低价值社交、奶头乐、维持自己想象中的主角感、揣测和胡乱归因周边人对自己的善意和恶意。
以及与长期不良社交关系纠缠上。
他们的注意力几乎不用在积累技能、认知等无形文化资产上,也几乎不用在身心健康和可持续生活上,若非逼不得已,也不会去用在真正解决问题上。
2,对时间的贱卖和虚耗。
时间这东西,对穷人来说像是一种他自己都不信的资产。
花两个小时排队抢五块钱的鸡蛋,花一个下午在群里跟人对线一个跟自己八竿子打不着的明星塌房,花一整晚在短视频里刷一些「震惊!××竟然……」的笨比特供信息流。然后第二天起来骂自己穷骂世界不公。
而真正稀缺、需要长期投入才能产生复利的事——读一本难啃的书、把一项技能磨到能换钱的水平、把身体练到不轻易出毛病、把一段关系处理到不内耗——这些事在他们眼里都「太慢了」「看不到回头钱」「等我有空再说」。
于是时间就这么一天天烂掉。烂在通勤路上的发呆里,烂在下班后的瘫坐里,烂在跟室友同事的废话扯皮里,烂在「明天再开始」的无限循环里。
穷人的时间,自己都觉得不值钱,于是世界也就按这个价收购它。一小时十几块钱卖给老板,一晚上免费送给算法,一辈子折价处理给环境。
3,对信任的乱给和乱省。
穷人的信任分配,往往是错位的——该信的不信,不该信的全信。
亲戚一句「我有个项目稳赚」,他信。短视频里西装革履的所谓导师讲「财富密码」,他信。隔壁王婶说「那个谁家小孩考公上岸了你也赶紧」,他信。微信群里转的「内部消息」,他信。
真正需要信任去建立的东西——比如一个长期的合作关系、一个靠谱但起步慢的方向、一个愿意给他真话的朋友、一份需要熬几年才出成果的事业——他全都疑神疑鬼,觉得「肯定有坑」「凭啥轮到我」「先骗我入局再杀」。
他把信任当糖一样撒给了规训他、收割他的那些建制和混子,却把信任当金子一样攥着,不肯交给那些真正能帮他迭代的人和事。
这是一种被精准训练出来的逆向选择。
4,对体面的过度执着。
很多穷人最舍不得花的不是钱,是脸。
宁愿借钱也要随份子,宁愿透支也要给孩子办一场体面的婚礼,宁愿挤公交两小时也要在朋友圈发一张星巴克,宁愿在一个明显烂透的岗位上耗着也不愿意去做那些「看起来不体面」的活儿。
体面这玩意儿,本质上是一种社交评价系统给你装的360全家桶——你以为是你自己要的,其实是被装进去的。它在后台疯狂占用你的算力,让你为了一群你根本不在乎、也根本不在乎你的人,去消耗本该用在自己身上的资源。
你先把事干成了,体面自己会找上门。反过来追,追一辈子也追不上。
而穷人恰恰反着来:先把体面这个壳撑起来,里面是空的也无所谓,撑住先。撑到最后,壳碎了,人也荒芜了。
5,对判断权的主动让渡。
穷人最不值钱的,是他自己对自己人生的判断权。这东西他几乎是免费送出去的,送给父母、送给亲戚、送给同事、送给网上的陌生人、送给那些贩卖焦虑的所谓博主。
「我妈说……」「我们那边都是……」「人家都……」「现在大家都在……」——这些句式一旦成为一个人的思维主干,他就基本上是个肉鸡了,被远程操控,自己还以为是自己在做决定。
第一性原理这四个字对他们来说太奢侈了。从根上想问题需要算力,需要孤独,需要承担「想错了怎么办」的风险。而把判断权交出去就轻松多了——错了可以怪父母、怪环境、怪时代、怪命,反正不用怪自己。
他这辈子都活在别人搭好的隧道里,看不见隧道外面的旷野。隧道里挤得要死,竞争惨烈,回报微薄。但他出不去,因为他连「外面有路」这件事本身都不相信。
6,对小事的轻视。
穷人看不上小事。存几百块钱看不上,每天读半小时书看不上,把一个手艺磨三年看不上,把身体练到不生病看不上,把一段关系经营到稳定看不上。他们眼里只有那种「一把梭哈改变命运」的故事——中彩票、拆迁、风口、贵人、暴富。
而真实世界的爆发,几乎都来自小事的复利。但复利这东西的早期曲线低得让人绝望,看上去跟没动一样。穷人在这个阶段就退场了,转身去追下一个看起来更刺激的幻觉。
于是就形成了一个稳定的闭环:永远在等大事,永远看不上小事,永远一事无成,永远归因于命。
32
27
65
7,816
这篇文章里,我认为最有价值的部分其实是这一段:
非技术同学想用好 AI Coding,不能只会描述需求,最好补一点技术和产品的基本逻辑。
技术上至少知道 React、Vue、Next.js 在解决什么,终端、Git、VS Code、Chrome DevTools 怎么用,函数、变量、状态、拆文件是什么意思。
产品上推荐三本入门书:《启示录》看产品判断,《Linux/Unix 设计思想》看工程哲学,《左耳听风》看我一直怀念的左耳朵耗子的程序员专家视野。
不用学到自己会写代码,知道这些东西长什么样,跟 AI 协作会舒服很多。
29
206
901
131,042
cleo retweeted

Apr 28
优化了一下我的 PPT Skills 在 Codex 的效果
现在太牛逼了,图片也能一键搞定!
能够调用 Codex 里的 GPT-Image-2 去帮你生成图片。
而且我为此做了专门的设计,它会有独特的风格,并根据你的内容生成不同类型的图片,包括:
- 营造氛围的人文纪实图片(类似胶片机拍摄的效果)
- 信息图、流程图、对比图、关系图
- 截图美化:如果你觉得截图不好看,它都能帮你美化并优化成对应比例的图片
现在整个图文表现效果会更好,推荐你们在 Codex 里使用。
此外,我们也优化了 Codex 的生成流程,现在系统会先询问,而不会直接跳过确认步骤去生成 PPT 了。



47
96
605
68,758
cleo retweeted

Apr 27
说个扎心的真相,90%的AI工程师,其实什么都没做出来
Cluely的CEO Roy Lee在NYU做活动,当场掏500美元现金,问在场所有学AI的学生和工程师,谁在LinkedIn上真正上线过一个公开的项目,结果全场几乎没人举手。
太真实了,现在的AI圈就是这样,人人都能跟你聊大模型,聊Agent,聊世界模型,刷过几百篇论文,调过几十个demo,但你问他有没有上线过一个能让别人用的东西,大部分人都沉默了。
我们总以为AI时代拼的是谁懂的多,谁的技术深,其实根本不是。
LLM能帮你写80%的代码,能帮你解决大部分技术问题,但剩下那20%的脏活累活,部署,边缘case,用户体验,成本控制,才是真正能区分你和别人的地方。
所以别再当那个只会看教程的工程师了,去做去实践,去解决实际问题,,离线小模型App,自我迭代的代码Agent,个人生活OS,哪个都行。
不用等你学完所有东西,不用等完美,这个周末开干,下周就公开上线。哪怕做的很烂,哪怕只有几个人用,也比你藏在电脑里的一百个demo强一万倍。
在AI时代,知识已经变成了最不值钱的东西,到处都是教程,到处都是论文,真正稀缺的,是把知识变成公开可验证的产品的执行力。
别当那个坐在NYU教室里,连500美元都拿不到的人,动起来兄弟们
67
62
442
82,439