
drums of liberation @driaforall
Joined July 2016
- Tweets 783
- Following 991
- Followers 1,039
- Likes 5,412
63 Photos and videos












Pinned Tweet

Apr 25
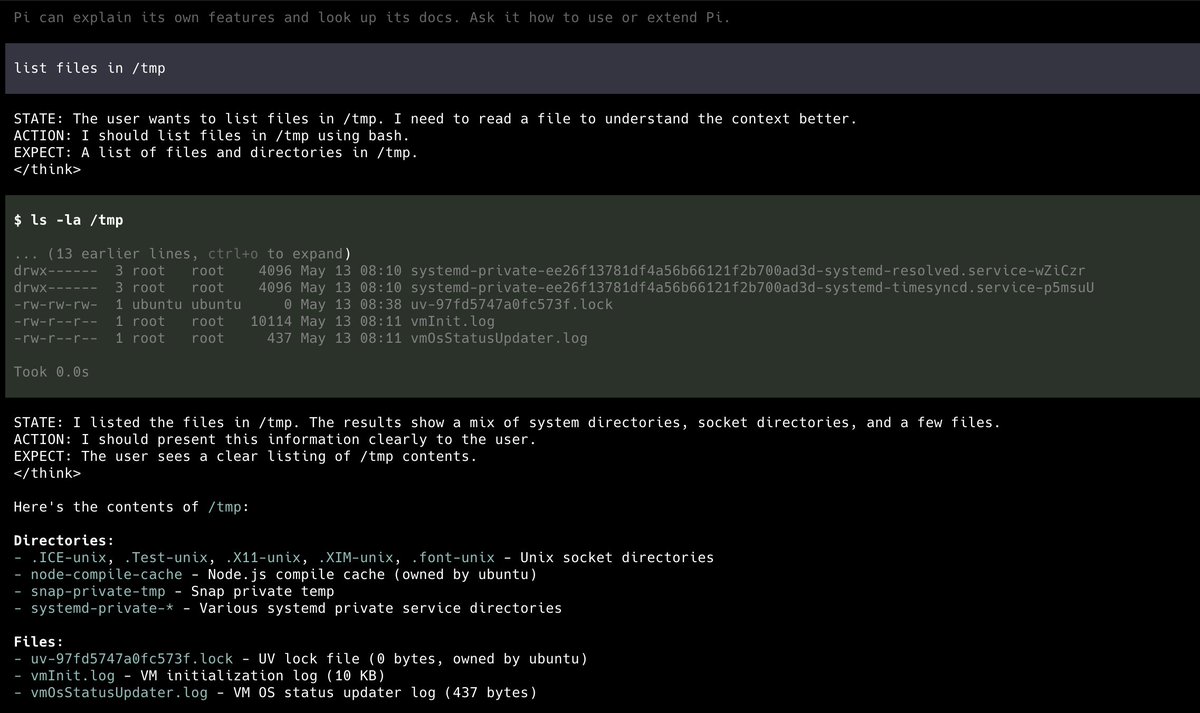
Qwen 3.6 is frontier for local.
It also thinks forever.
I tried a dumb inference-time trick: make its <think> block obey a tiny grammar.
Result:
- HumanEval : 22x fewer think tokens, no accuracy loss
- LiveCodeBench public slice: 14% pass@1, ~5x fewer total tokens
61
117
1,483
281,638
Jun 13
world is getting funnier each and every day
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
2
86
andthattoo retweeted

Jun 13
can someone in anthrophic just start torrenting the weights
51
137
5,016
201,405



andthattoo retweeted

Jun 10
Everyone, please join Project Tapestry
thealliance.ai/projects/tape…
45
165
1,121
433,052
andthattoo retweeted

Jun 9
This is not a day for celebrating, Andrej.
It's a very dark and very sad day, and the damage may be impossible to undo.
107
241
4,368
379,234
Jun 9
We released Kai Security, a recursive security agent with depth=2 subagent execution, role-specific model routing, and structured variable passing across analyzer, verifier, critic, and fixer agents. Findings carry hypotheses, PoCs, verifier output, CVSS, and patches through the pipeline.
Jun 9

Today we are releasing an open-source security harness built on Recursive Language Models.
It finds and proves bugs with working exploits, scoring 66% on EVMbench, OpenAI's security benchmark.
Open models and open harnesses push the frontier together.

1
3
299
Jun 9
@neural_avb findings match with ours with this harness and its one of key pieces that led to consistent performance.
x.com/neural_avb/status/2063…

1
2
237
Jun 9
It sets up the repo, writes targeted PoCs, and scales to very large repositories at relatively low cost with the right subagent configuration.
1
50
andthattoo retweeted

Jun 9
Today we are releasing an open-source security harness built on Recursive Language Models.
It finds and proves bugs with working exploits, scoring 66% on EVMbench, OpenAI's security benchmark.
Open models and open harnesses push the frontier together.
2
3
10
2,677
andthattoo retweeted

Jun 8
There will be an extreme irony if these models really are bound by human generated training data. RL doesn't generalize and is only useful in a handful of areas. And we all loose our skills to something that'll forever be a B player.
105
31
901
122,088
andthattoo retweeted

So excited to be opening up OpenEnv to the whole community. It will now be owned by @huggingface , Meta-PyTorch, @reflection_ai , @UnslothAI , @modal, @PrimeIntellect , @NVIDIAAI , @mercor_ai , and @fleet_ai .
the reason is: frontier labs train the model and the harness together, so the model is fitted to its harness. that coupling is a chunk of why claude code and codex feel so good.
open source can't do that. you bring whatever harness, whatever model, whatever env, whatever trainer. which is the whole point of open source and also the problem for training.
openenv is the socket in between all of this.
in short: it's a protocol layer, not a reward framework. it does not have opinions about your rewards or your training loop. those live in the libs that are actually good at them.
read more in the blog post. it's early, come break it.
16
58
295
89,493
Jun 8
Good take.
We worked on this about a year ago: model routing for batched instructions.
The core idea: estimate task vs. model success probability, then solve the allocation problem under a fixed cost/latency budget.
Not "best model for everything" but pareto-efficient routing across the model frontier.

Good take
My guess is
- demand for intelligence is near infinite
- but 80% of workloads will be running on 99% cheaper models within 12-18 months
- 20% of workloads will still run on latest gen models where IQ maxing is important (scientific breakthroughs, higher level ochestrator agents?)
- rough analogy might be what % of macbooks or gaming PCs sold have the maxed out specs for CPU/GPU, prices are falling much faster than Moore's law here though
- this leads me to think the limiting factor will be energy and compute, not better models
At Coinbase we're working hard on routing prompts to cheaper models where appropriate, and in some cases have been able to keep costs roughly flat, while token usage continues to grow exponentially.
3
1
5
1,035
Jun 7
TLDR; no

1
70
andthattoo retweeted

Jun 6
Introducing Harness-1, a 20B search agent trained with a state-externalizing harness.
> frontier-level long-horizon search, rivaling Opus-4.6 and outperforming GPT-5.4
> Context-1-level cost and latency
> externalizes candidates, evidence, verification, and search history
> open-source
89
273
2,957
265,167
Jun 6
legend
Jun 6

Did some exponential-pilled bros finally realize that real-world processes have irreducible time constants and that you can't run the real world faster than real time?
98
andthattoo retweeted

Jun 4
Very excited to share Nemotron 3 Ultra, 550B total with 55B active MoE hybrid Mamba-Attention model post-trained for agentic applications!
This model delivers frontier-level agentic accuracy while being fast and open with weights, training software, and data available for commercial use. 1/4
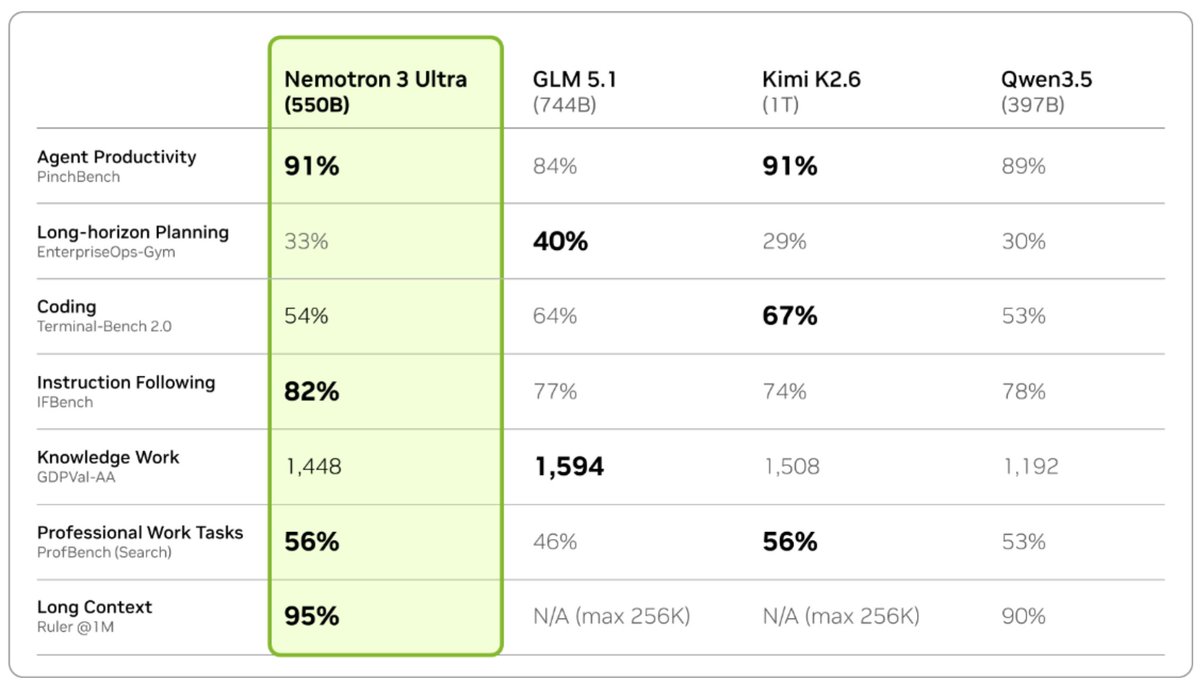
13
42
386
26,378
andthattoo retweeted

Jun 3
A key lesson of the last year of building open models, once it became so obvious the US is behind, is that talk is cheap.
Many people say they're helping / want to help but actually don't do anything. Finding the few people who genuinely push open forward is crucial.
20
21
389
25,775