
Helping people engineer the future.
Joined March 2009
- Tweets 109
- Following 966
- Followers 297
- Likes 838
19 Photos and videos






Pinned Tweet

May 26
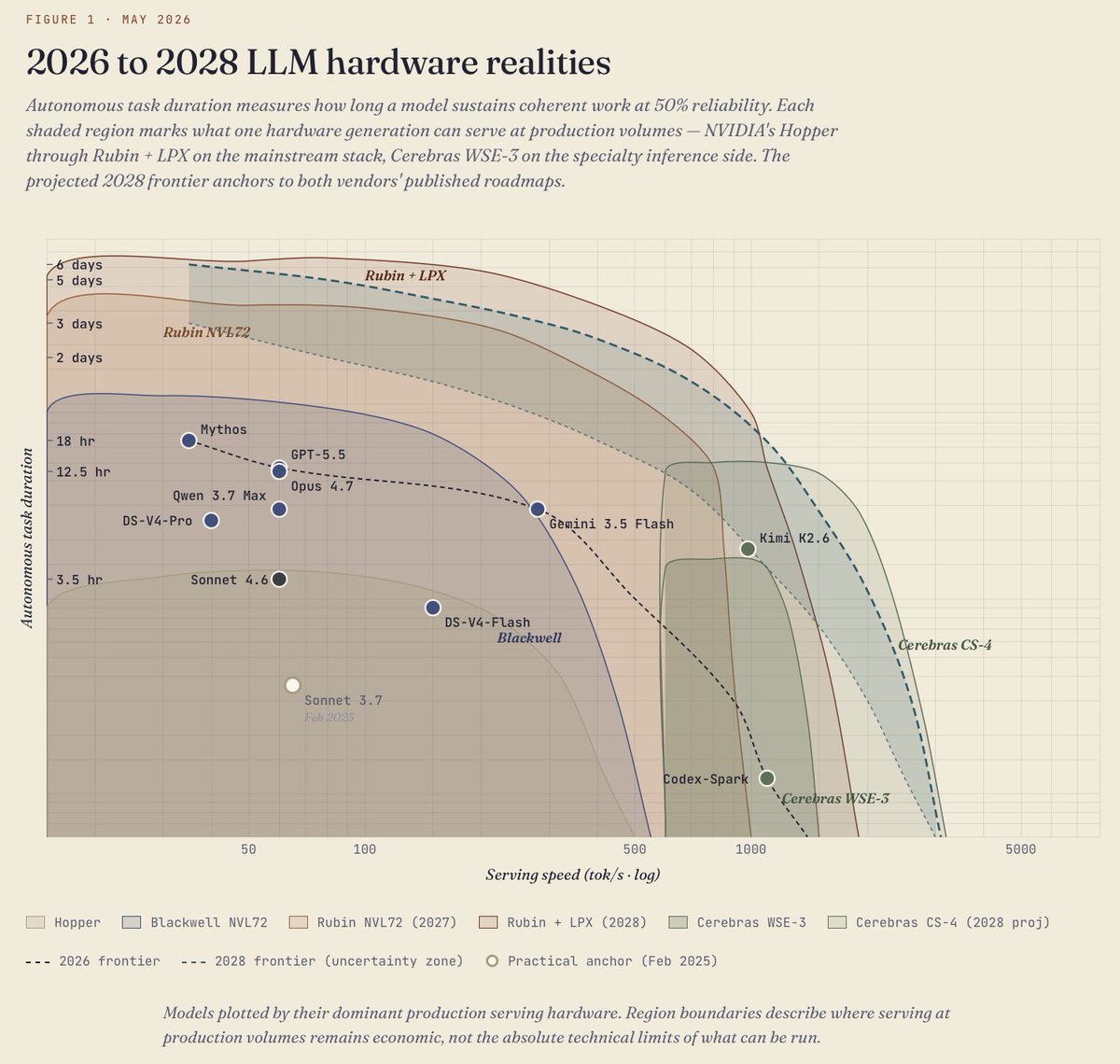
I have been investigating LLM serving economics and here are my METR-anchored projections of model capabilities as Vera Rubin ( comparable TPUs) and next-gen Cerebras are deployed over the next couple of years.
Relevant background: 10 years managing large, global R&D datacenter efficiency and the last 3 years working every angle of LLM engineering. (v2 post)
3
2
345
Jun 9
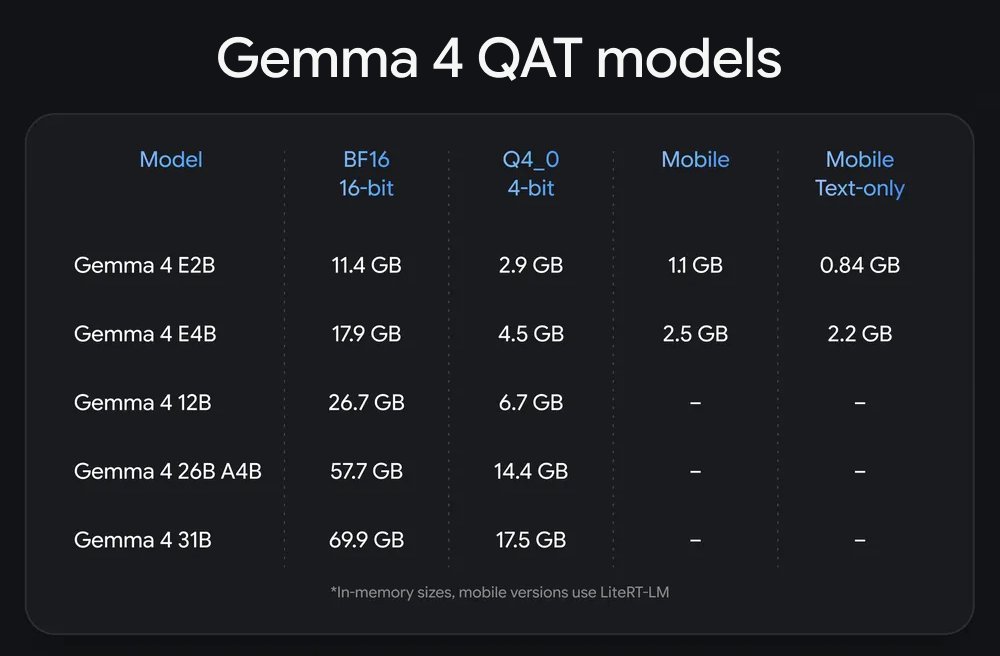
Gemma 4 12B new QAT release allows you to run high context comfortably on 16GB GPUs, while sacrificing very little in quality vs the unquantized model.
llama.cpp just got support for MTP w/ Gemma 4 too.
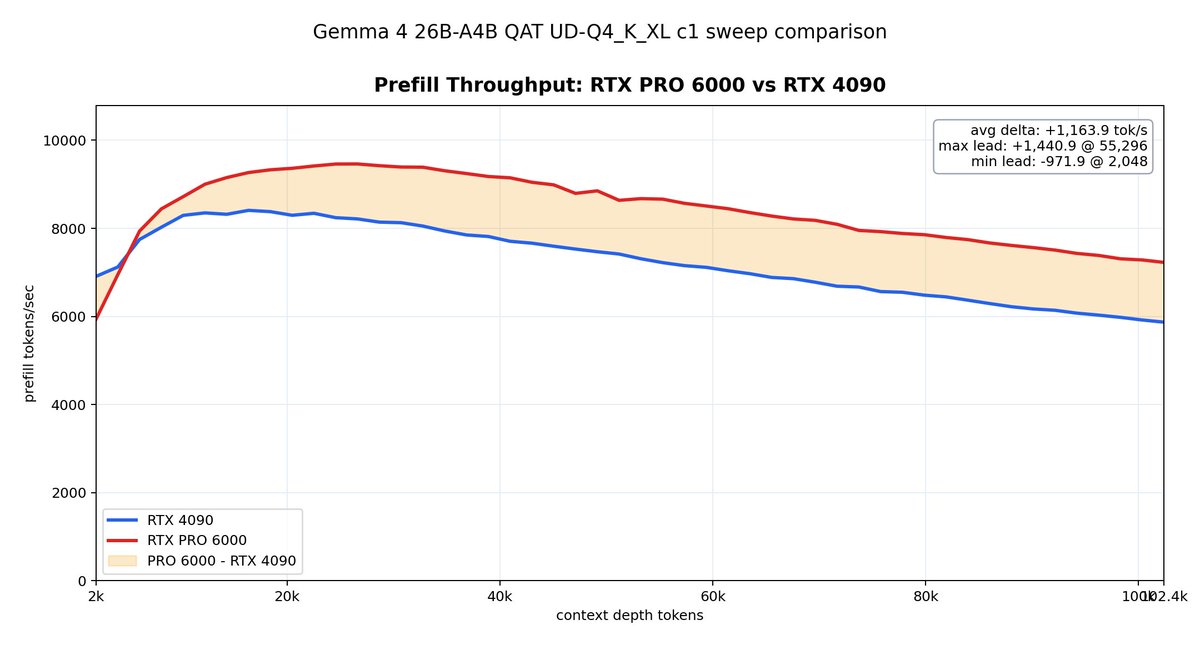
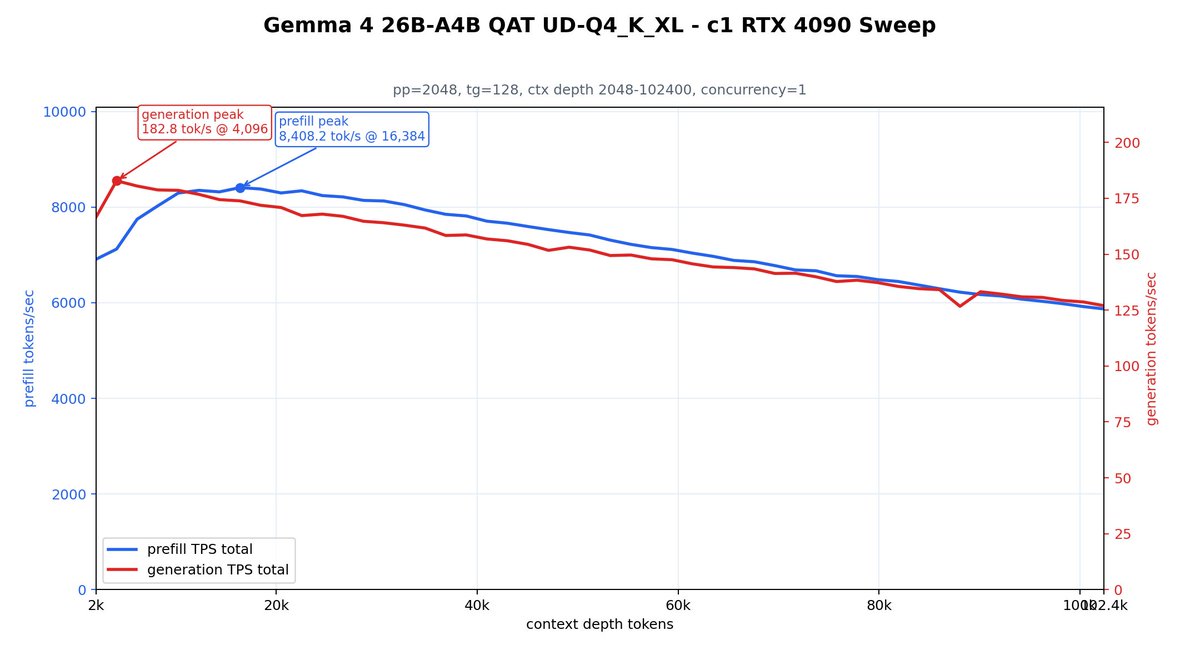
I tested performance. RTX 4090 gets a boost from 90 tok/s to 120 tok/s. PRO 6000 (should be similar for RTX 5090) goes from 120 to 155 tok/s.
Prefill takes a small hit, but stays in the 5000 range.
This model is notable for being one of the most capable multimodal models available today which will run on a single mid-tier GPU faster than you'd get on API for most models.
Most model speed testing in the consumer space isn't as thorough and visual as the sweeps I've put together here. I built my own pipeline for this testing. If you'd like to see more or have me share it, let me know.
@googlegemma
ALT A comparison of Gemma 4 12B QAT speed with and without MTP on RTX 4090 and RTX PRO 6000 GPUs. MTP keeps performance above 100 tok/s for most uses even at deep contexts.
4
9
1,566
Jun 9
QAT takes the model weights down from 27 GB to 7GB (in use, with context full, you'll still need ~13 GB VRAM)
1
2
206
Jun 9
12B model is comparable in performance to the 26B-A4B MoE model across many tasks. 12B model benefits from MTP, while the MoE does not though.
2
148
Jun 5
New Agent @arena pits models against each other in a real agentic harness. Congrats, dynamic real-world comparison is here!
I spotted a big next opportunity..
Their analysis of the tasks and categories is much like my analysis of DeepSWE challenge catalog: x.com/bleysg/status/20622801…
The big opportunity:
Use task distribution and the deeper categories I broke out in the DeepSWE analysis to build a by-model signal on things like..
"Highest-complexity tasks which are full feature requests in Rust with a behavior theme of data transformation"
This then goes from, "average performance across all work types, in all languages, for all users," to, "average performance for my work types, in my languages, for my users" ... the signal people actually want.
Jun 3

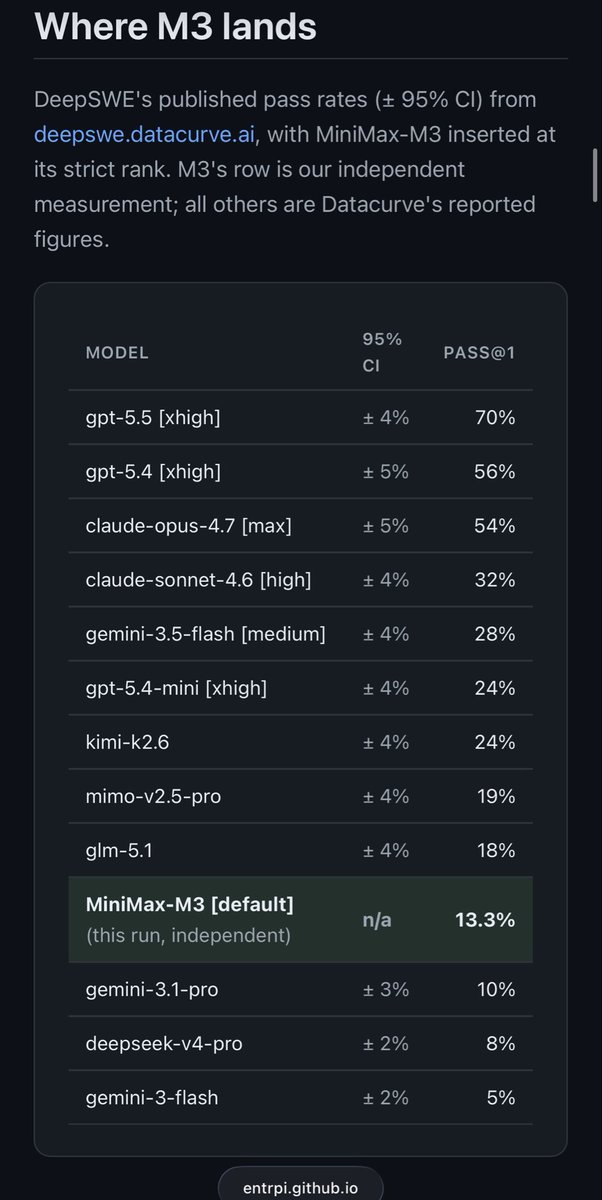
I got a lot of followup on my DeepSWE testing of Minimax M3 asking what it means to be fluent in this eval set.
I dug into it.
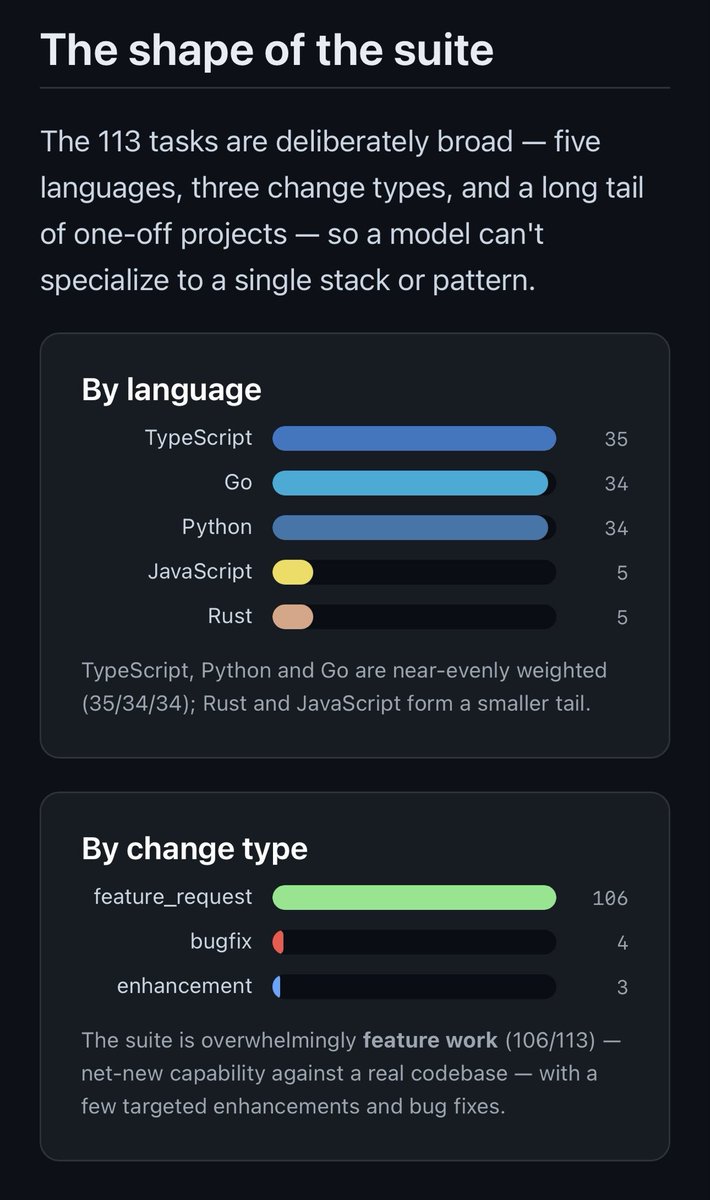
Full report covers breakdown by languages, task types, complexity, and more so you can see just how applicable it is to your type of work.
entrpi.github.io/misc/deepsw…

1
7
424
Jun 5
Agent Arena details: x.com/arena/status/206256674…
or arena.ai/blog/agent-arena-me…

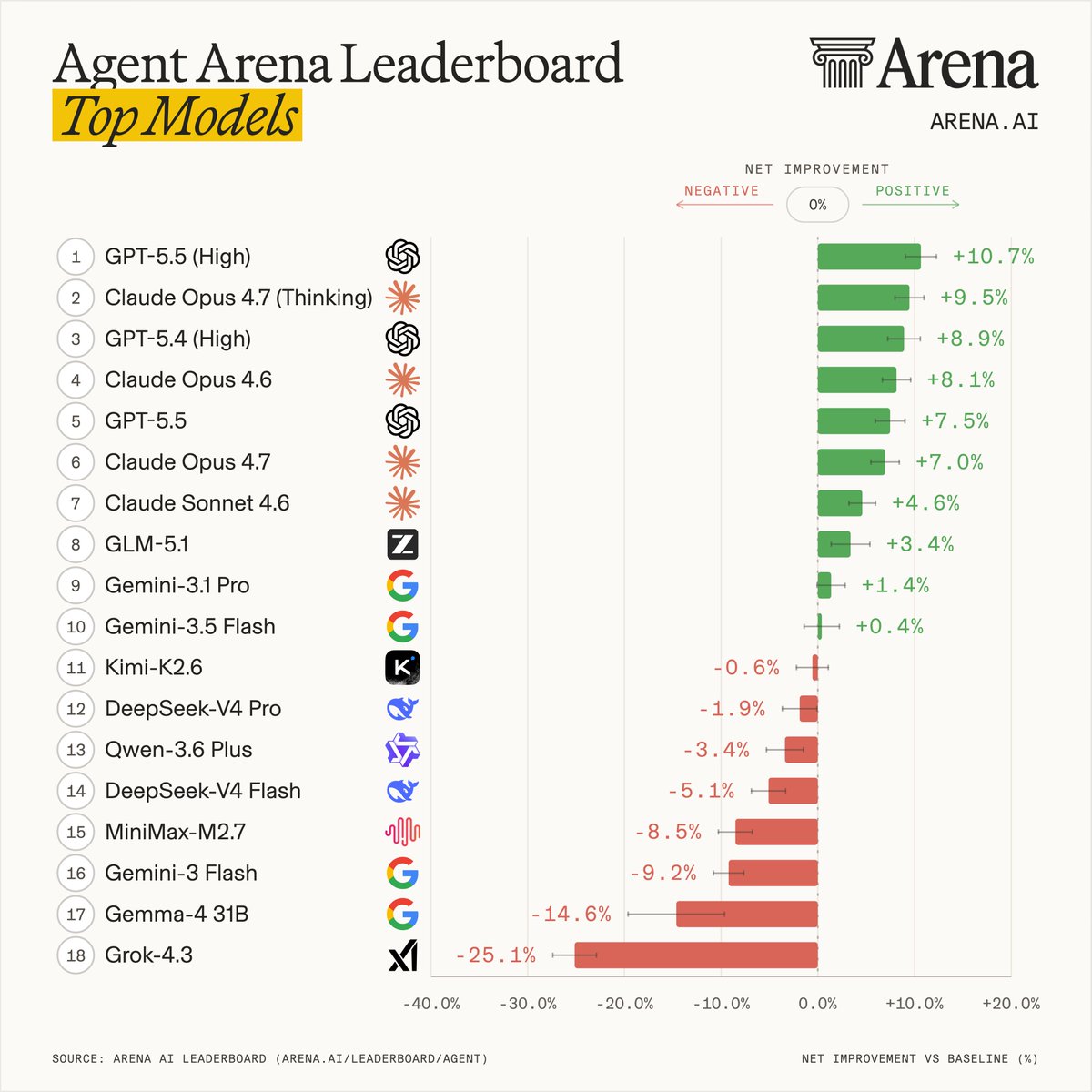
Introducing Agent Arena: real-world agentic evals at scale.
How do you evaluate agents doing actual work? We measure millions of live sessions where real users accomplish real tasks.
On Arena, models now get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
Every session produces rich signals. Users iterate with the agent turn-by-turn: approving, editing, correcting, praise or expressing frustration. The environment gives feedback too: shell errors, tool failures, recovery attempts, and more.
Our leaderboard measures each model's agentic performance using causal inference across five signals: task success, steerability, error recovery, user praise vs. complaint, and tool hallucination.
This leaderboard snapshot is built from 300K tasks, 2M tool calls, and 40M lines of code by agents.
Top labs in Agent Arena:
- #1 @OpenAI: GPT-5.5 (High)
- #2 @AnthropicAI: Claude-Opus-4.7 (Thinking)
- #3 @Zai_org: GLM-5.1
- #4 @GoogleDeepMind: Gemini-3.1-Pro
- #5 @Kimi_Moonshot: Kimi-K2.6
More analysis in the thread, with the full technical blog below.
1
172
Jun 3
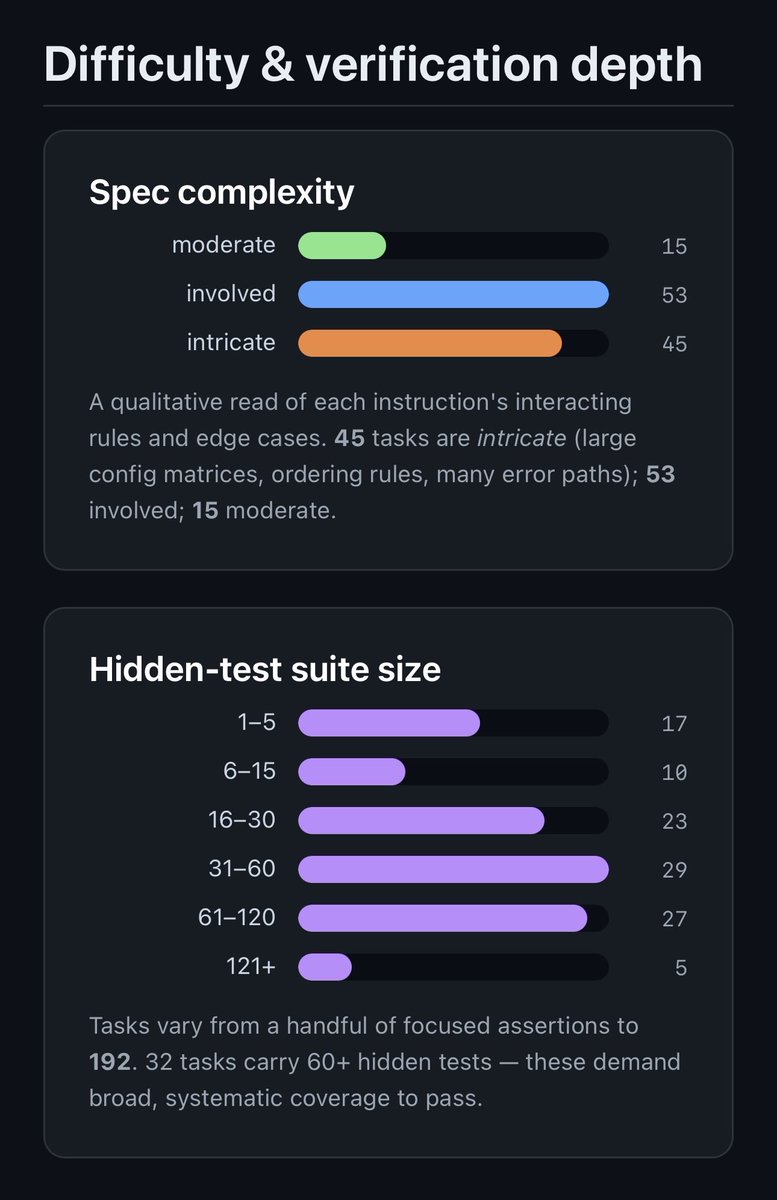
I got a lot of followup on my DeepSWE testing of Minimax M3 asking what it means to be fluent in this eval set.
I dug into it.
Full report covers breakdown by languages, task types, complexity, and more so you can see just how applicable it is to your type of work.
entrpi.github.io/misc/deepsw…
4
2
80
7,664
Jun 3
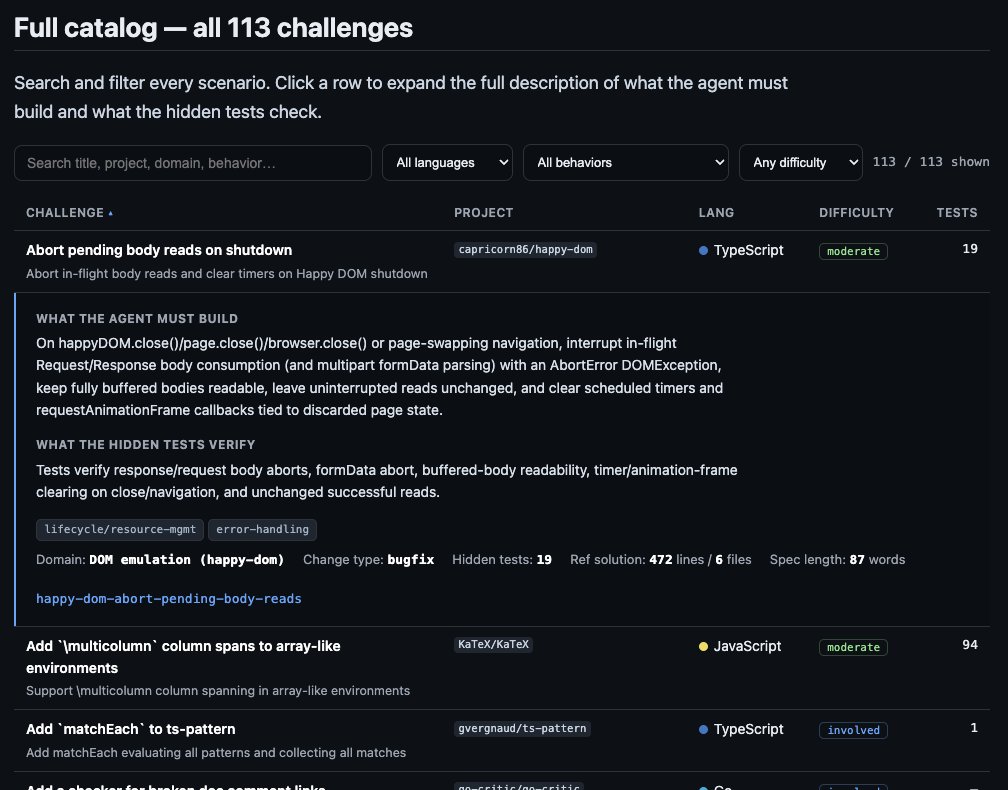
Every challenge is searchable with readable summaries at the end of the report as well.
5
980
Jun 2
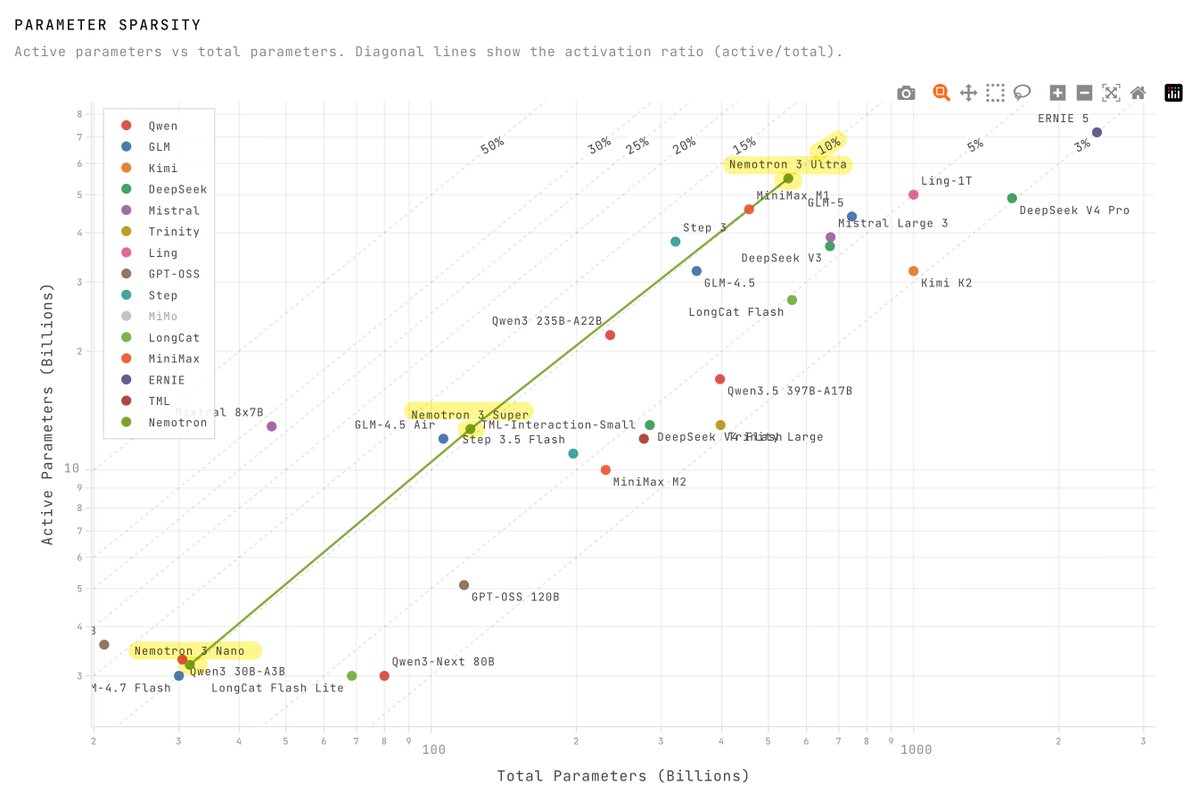
There is a backstory to why @NVIDIAAI has stuck to 10% throughout the Nemotron 3 series, including the new 550B Ultra model, while most of the industry chases MoE with 3-5% activation.
LatentMoE is that story. They argue effective MoEs be evaluated by two dimensions: accuracy per FLOP and accuracy per parameter. The race toward 3-5% activation implicitly optimizes only the first.
arxiv.org/abs/2601.18089v1
1
1
14
2,227
Jun 2
When you are flop-rich with GB200, Nemotron-style architectures better optimize for the hardware you have available. This may make Nemotron 3 Ultra the best blend of intelligence to tok/s to tok/megawatt of any model available this month.
3
640
Jun 2
While most of the industry chases MoE with 3-5% activation, NVIDIA has stuck to 10% throughout the Nemotron 3 series, including the new 550B Ultra model. Will be keen to see what they settle on for the next series' sparsity.
Jun 2

nemotron 3 is significantly less sparse than other models (~10% active vs ~3% for kimi K2/deepseek v4)

1
6
1,534
Jun 2
This is also a story of optimizing your architecture to specific hardware which you understand intimately. Nemotron 3 Ultra is the culmination of targeting flop-rich GB200 Blackwell clusters with a goal of reaching peak intelligence which can push towards 300 tok/s efficiently.
411
Jun 1
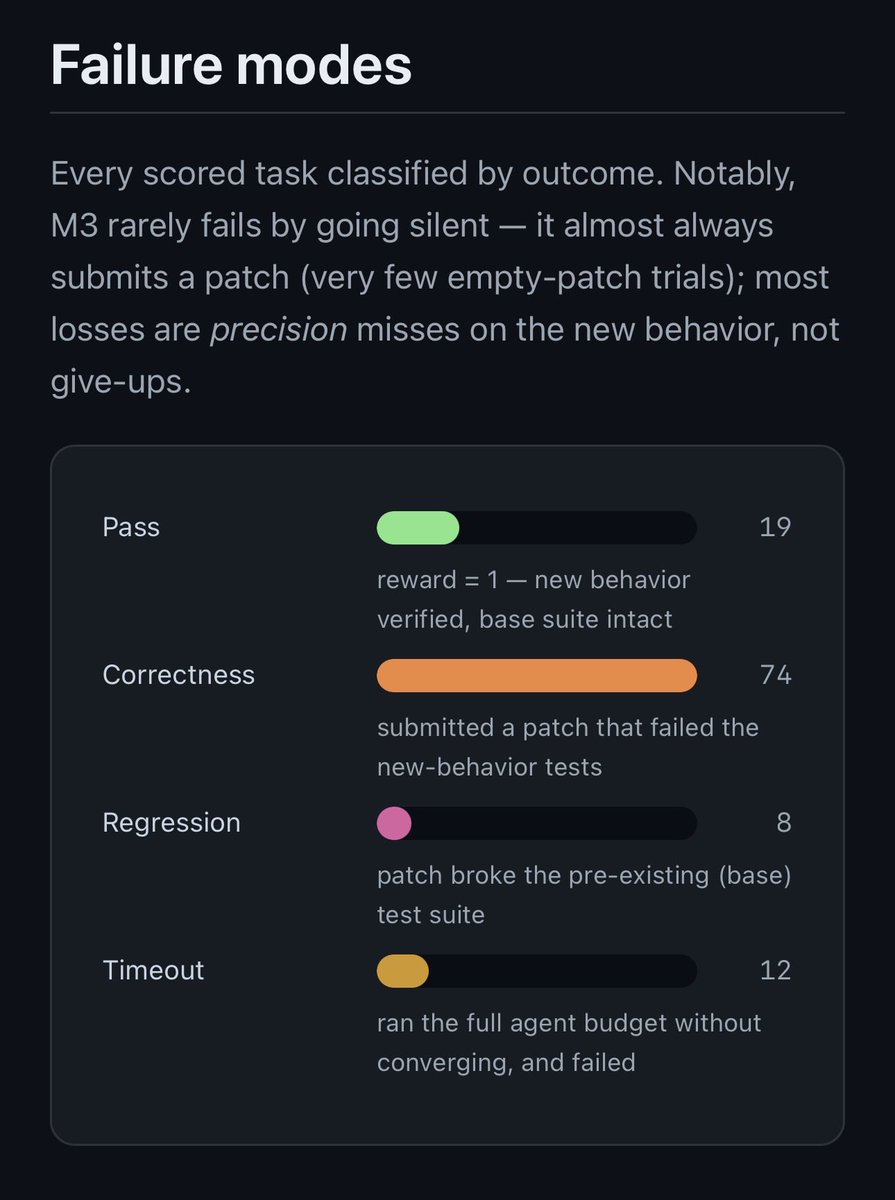
Since everyone is asking, I ran DeepSWE on MiniMax M3.
Here is the lowdown. 15 of 113 passed!
19 if you count the 1.5x overtime I gave just to see.
Full report: entrpi.github.io/misc/deep-s…


Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

45
37
451
147,313
Jun 1
It is also commendable for rarely causing regressions. It really is better than the surface number reveals. There are good bones here.
1
1
40
5,106
Jun 1
Surprisingly it is often very close to a pass and just barely misses! It is rarely totally wrong.
5
47
10,879
Jun 1
Models comparison. Sits between Gemini 3.1 Pro and GLM-5.1.
8
7
109
11,046
May 29
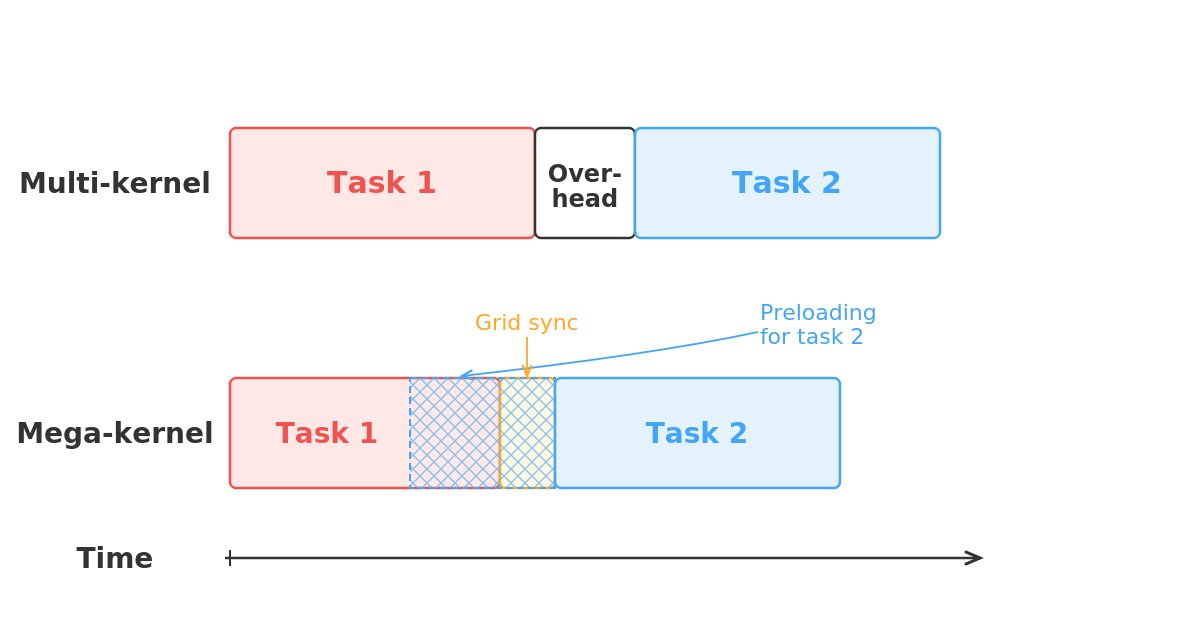
Excellent details here. Congrats on the Kog release. Wonderful to see more across-the -stack optimized work on bringing latency in GPU inference towards the floor.

We get those microseconds back by co-designing three layers that are normally tuned in isolation: the runtime, the low-level GPU code (including collective-communication), and the model architecture itself.
The monokernel: our entire decode pass runs as one persistent, GPU-resident program.
There is only one kernel launch for the whole sequence. This lets weight streaming run uninterrupted across kernel boundaries, and sampling stays on-GPU.
We also rebuilt grid synchronization. Instead of a grid-wide barrier with HBM round-trips, each compute unit waits only on the values it actually depends on, with the readiness state being encoded directly in the data. On the AMD MI300X GPU that took the barrier from ~7 µs to under 1 µs.
Before that, grid sync had been eating ~35% of token-generation time!
📖 Deep dive for the MI300X → blog.kog.ai/building-a-singl…
1
1
7
1,147
May 27
REAP on Kimi K2.6 is likely how Cerebras is managing to pilot the model today on WSE-3 without untenable costs. Not serving full-weights.
May 26

Looking forward to this deep dive by Cerebras! luma.com/reap?tk=SVrhb2
1
641