
11 Photos and videos








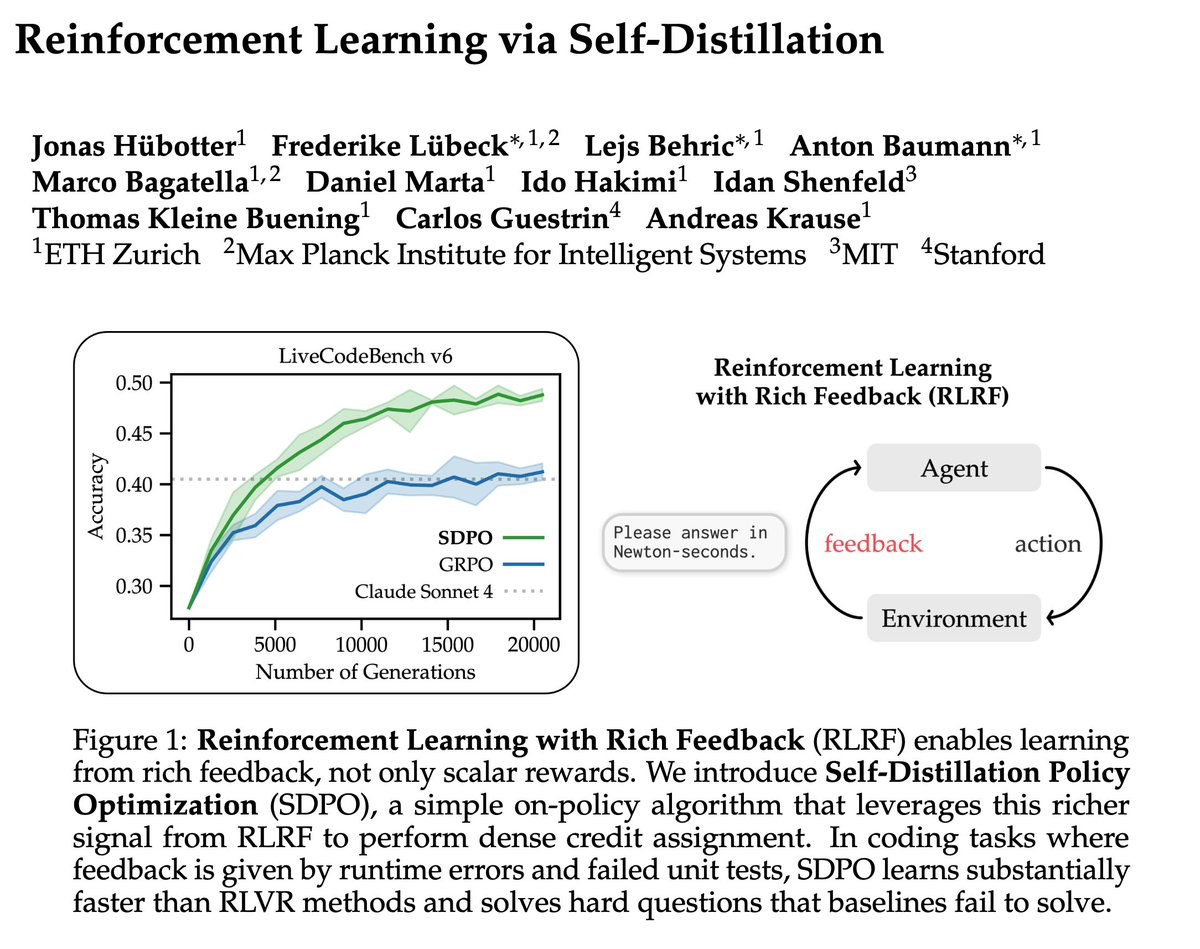
Jan 29
With SDPO, you can now do RL with natural language feedback, like error messages from coding environments or LLMs as judges. You can achieve huge gains over GRPO with scalar rewards!
Jan 29

Training LLMs with verifiable rewards uses 1bit signal per generated response. This hides why the model failed.
Today, we introduce a simple algorithm that enables the model to learn from any rich feedback!
And then turns it into dense supervision.
(1/n)
3
17
233
38,231
Carlos Guestrin retweeted

Jan 26
I don't think people have realized how crazy the results are from this new TTT RL paper from Stanford/Nvidia.
Training an open source model, they
- beat Deepmind AlphaEvolve, discovered new upper bound for Erdos's minimum overlap problem
- Developed new A100 GPU kernels 2x faster than the best human kernel
- Outperformed the best AI coding attempt and human attempt on AtCoder
The idea of Test Time Training is to train a model *while* it's iteratively trying to solve a task. Combining this with RL like they do in this paper opens up the floodgates of possibilities for continual learning
Authors: @mertyuksekgonul @LeoXinhaoLee @JedMcCaleb @xiaolonw @jankautz @YejinChoinka @james_y_zou @guestrin @sun_yu_

45
198
1,763
111,214
Jan 27
By specializing the model to each hard task using a simple entropic objective and RL, TTT-Discover writes new high-performing GPU kernels and improves open mathematical bounds.
8
1,513
Jan 22
Relational Transformers provide zero shot predictions for complex databases!
30 Oct 2025

Transformers are great for sequences, but most business-critical predictions (e.g. product sales, customer churn, ad CTR, in-hospital mortality) rely on highly-structured relational data where signal is scattered across rows, columns, linked tables and time.
Excited to finally share what I have been working on over the last year: a Foundation Model architecture which brings the power of Transformers to relational domains, enabling large-scale pretraining and zero-shot generalization in enterprise settings. 🧵1/n

ALT Title and abstract of the paper.
7
37
5,402
Jan 13
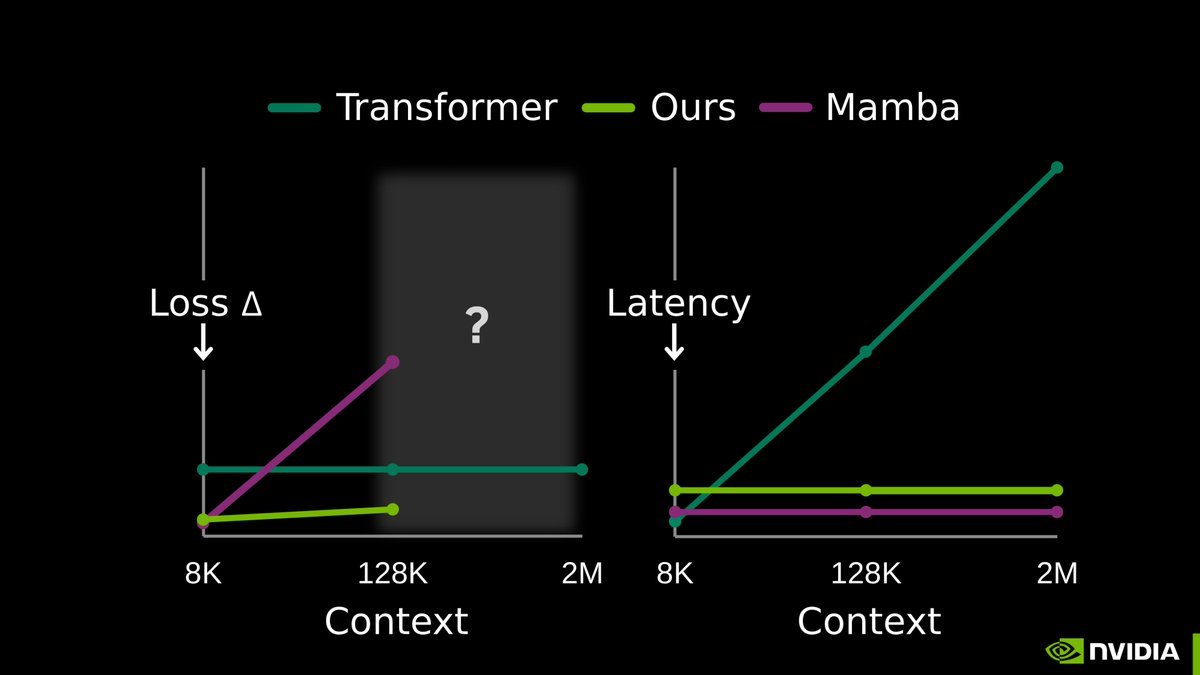
TTT-E2E compresses the context simply through end-to-end test-time training — outperforms the loss of transformers with full attention, and achieves constant-time latency per token.
Jan 12

LLM memory is considered one of the hardest problems in AI.
All we have today are endless hacks and workarounds. But the root solution has always been right in front of us.
Next-token prediction is already an effective compressor. We don’t need a radical new architecture. The missing piece is to continue training the model at test-time, using context as training data.
Our full release of End-to-End Test-Time Training (TTT-E2E) with @NVIDIAAI, @AsteraInstitute, and @StanfordAILab is now available.
Blog: nvda.ws/4syfyMN
Arxiv: arxiv.org/abs/2512.23675
This has been over a year in the making with @arnuvtandon and an incredible team.
1
5
796
30 Oct 2025
The Relational Transformer (RT) provides strong zero-shot predictions from relational data, e.g., databases.
30 Oct 2025
Transformers are great for sequences, but most business-critical predictions (e.g. product sales, customer churn, ad CTR, in-hospital mortality) rely on highly-structured relational data where signal is scattered across rows, columns, linked tables and time.
Excited to finally share what I have been working on over the last year: a Foundation Model architecture which brings the power of Transformers to relational domains, enabling large-scale pretraining and zero-shot generalization in enterprise settings. 🧵1/n
ALT Title and abstract of the paper.
1
12
1,714
29 Apr 2025
SAIL Postdoctoral Fellows is an awesome opportunity to collaborate with the amazing faculty and students in the Stanford AI Lab!
29 Apr 2025

SAIL is still accepting applications for the SAIL Postdoctoral Fellowships! This is an opportunity to work with our wonderful professors and community. Applications received by the end of April 30 will receive full consideration: ai.stanford.edu/postdoctoral…
1
1
7
1,438
18 Apr 2025
The SAIL Postdoctoral Fellowship is a fantastic opportunity for recent PhDs to do their most innovative and impactful AI research, while being part of a highly collaborative and welcoming environment at Stanford.
18 Apr 2025
Stanford AI Lab (SAIL) is excited to announce new SAIL Postdoctoral Fellowships! We are looking for outstanding candidates excited to advance the frontiers of AI with our professors and vibrant community. Applications received by the end of April 30 will receive full consideration: ai.stanford.edu/postdoctoral…
2
1,456
17 Apr 2025
We are super excited to empower developers to focus on their goal of building innovative AI applications; we’ll take care of safety and security! What an awesome ride with Bo Li @uiuc_aisecure, @sanmikoyejo, @dawnsongtweets and the whole @VirtueAI_co team!
15 Apr 2025

We’ve raised $30M in Seed Series A funding led by @lightspeedvp and Walden Catalyst Ventures, with participation from Prosperity7 Ventures, Factory, Osage University Partners (OUP), Lip-Bu Tan, Chris Re, and more.
Virtue AI is the first unified platform for securing AI across red teaming, guardrails, and agents. We’re proud to already support forward-thinking companies like @Uber , @glean, and several frontier labs.
This investment will help us continue improving our platform, scale agentic workflows, build out integrated enterprise use cases, and grow our team.
Grateful to our customers, our team, and our investors for the support.
3
16
2,817
Carlos Guestrin retweeted

20 Feb 2025
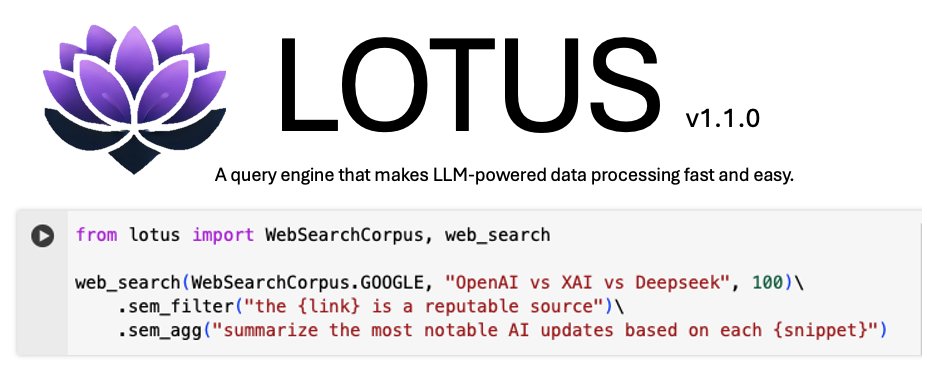
Excited to share our release of LOTUS 1.1.0, which now makes it easier than ever to get started with LLM-powered data processing over a variety of custom knowledge sources.
Seamlessly connect to data from the web, your SQL databases, vector databases and more.
And process it all with the power of semantic operators.
github.com/lotus-data/lotus
7
29
153
18,949
Carlos Guestrin retweeted

10 Feb 2025
SAIL is delighted to announce Carlos @guestrin, the Fortinet Founders Professor of Computer Science, as the next Director of @StanfordAILab. Carlos is a talented researcher and leader, known for his work on explainability, graphs, compilation, and boosted trees in AI.

6
23
97
11,457
Carlos Guestrin retweeted
18 Dec 2024
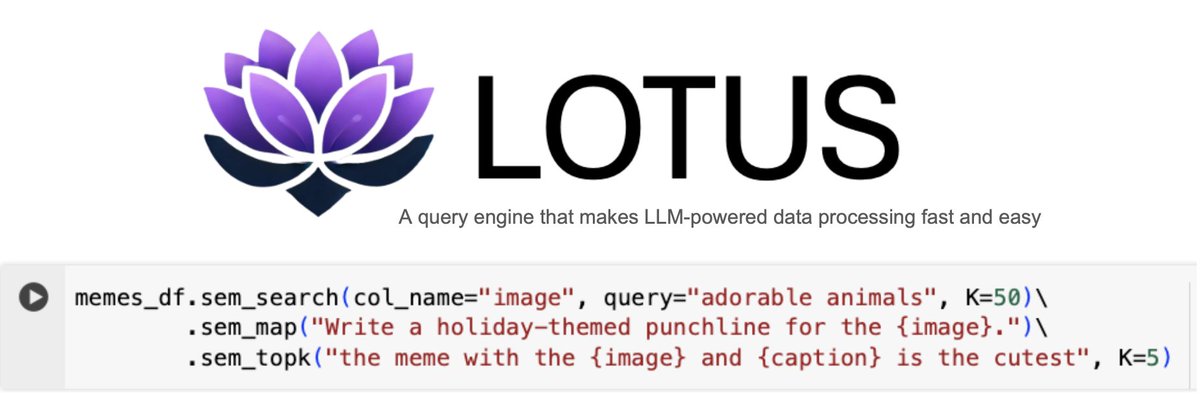
We've been building LOTUS at Stanford and Berkeley to make LLM-powered data processing fast, easy and declarative.
LOTUS is an open-source query engine that makes programming as easy as writing Pandas and optimizes your programs for up to 400x speedups.
To celebrate the holidays, we're excited to share our release of LOTUS 1.0.0 with a batch of new updates that make reasoning over your data faster, easier and better than ever!
Code: github.com/guestrin-lab/lotu…
🧵👇
17
183
1,288
159,917
Carlos Guestrin retweeted

13 Dec 2024
Can interpretability help defend LLMs? We find we can reshape activations while preserving a model’s behavior. This lets us attack latent-space defenses, from SAEs and probes to Circuit Breakers. We can attack so precisely that we make a harmfulness probe output this QR code. 🧵
11
81
371
58,886
Carlos Guestrin retweeted

27 Nov 2024
🧵LLMs are great at synthesizing info, but unreliable at citing sources. Search engines are the opposite. What lies between them?
Our new paper runs human evals on 7 systems across the✨extractive-abstractive spectrum✨for utility, citation quality, time-to-verify, & fluency!

1
21
66
14,261
Carlos Guestrin retweeted
18 Jul 2024
Super excited to share our work on LOTUS, a query engine for reasoning over large corpuses of data with LLMs!
Joint work w/ the amazing @sid_jha1, @matei_zaharia & @guestrin
Read the paper: arxiv.org/abs/2407.11418
Try out the code: github.com/stanford-futureda…
🧵👇
8
30
185
33,550
Carlos Guestrin retweeted

12 Nov 2024
Prior work has used LLMs to simulate survey responses, yet their ability to match the distribution of views remains uncertain.
Our new paper [arxiv.org/pdf/2411.05403] introduces a benchmark to evaluate how distributionally aligned LLMs are with human opinions.
🧵

4
36
156
28,133
Carlos Guestrin retweeted

29 Oct 2024
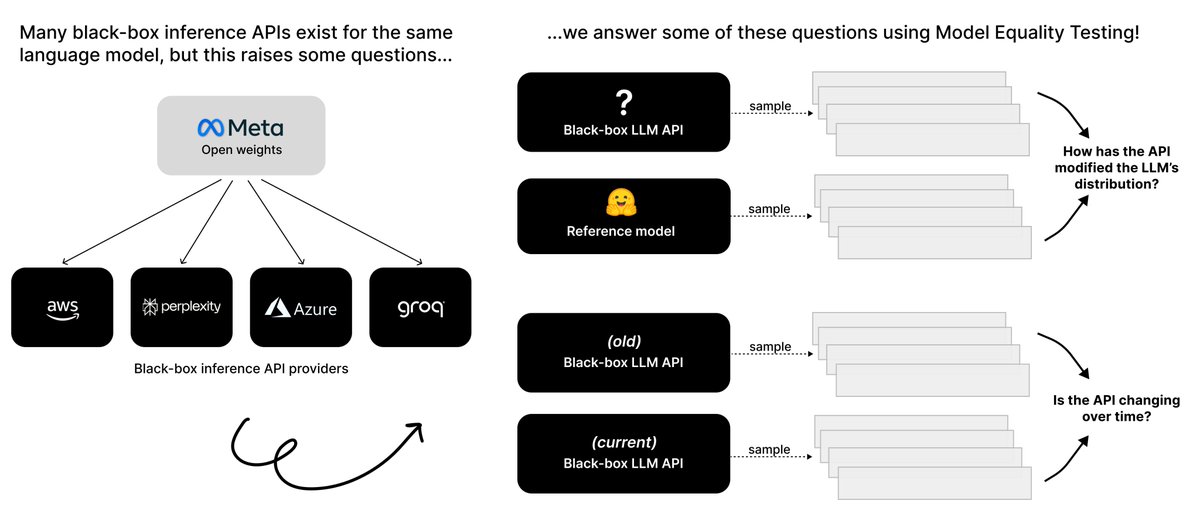
Many providers offer inference APIs for the same models: for example, there were over nine Llama-3 8B APIs in Summer 2024. Do all of these APIs serve the same completion distribution as the original model?
In our new paper, ✨Model Equality Testing: Which Model is This API Serving?✨, we formalize this question as a two-sample distribution testing problem: the user collects samples for their task from the API and a reference distribution, and conducts a statistical test to see if the two distributions are the same.
We design tests which show nontrivial power in detecting when models have been quantized, watermarked, or finetuned! (🧵 1/5)
7
33
169
46,045
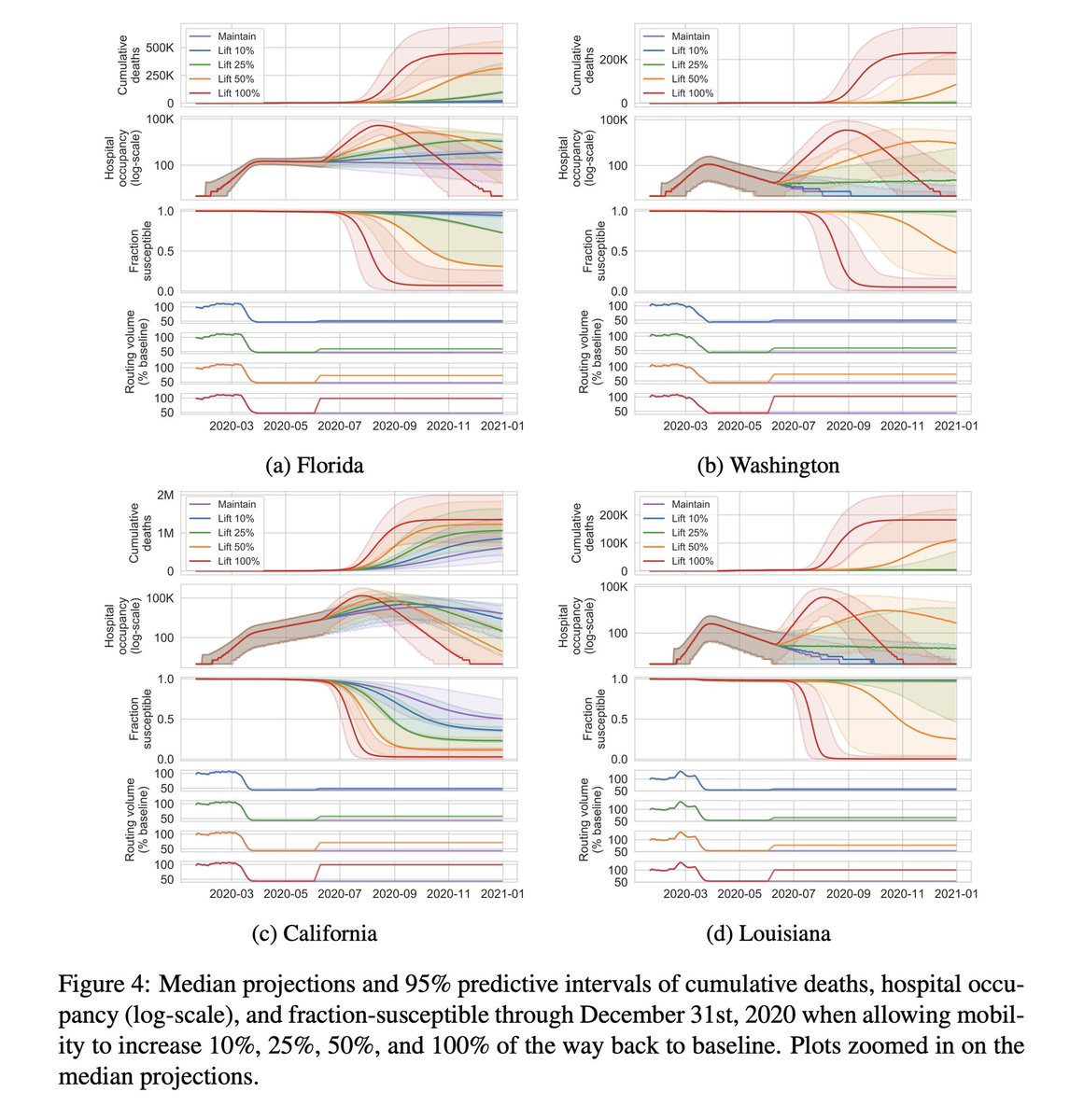
11 May 2020
Our recent work combines Maps data with hospitalization and death records to model the COVID-19 transmission rates., finding that for many states increasing mobility will lead to a significant increase in cases.
11 May 2020

Mobility trends provide a leading indicator of changes in SARS-CoV-2 transmission medrxiv.org/cgi/content/shor… #medRxiv
6
6
33





9 Dec 2017
.@vega_vis is an awesome tool to develop visualization projects! x.com/jeffrey_heer/status/93…
9 Dec 2017

Congrats Carlos and the Apple/Turi team! Exciting machine learning tools, with @vega_vis visualization built in :) x.com/guestrin/status/939267…
3
20