
Transferable generative models bridge femtosecond to nanosecond time-step molecular dynamics
science.org/doi/10.1126/scia…
AI Speeds Up Molecular Simulations by 10,000×
A new AI framework called TITO represents a significant advance in computational chemistry and biophysics. The system was trained on more than 12,500 organic molecules and over 1,000 peptides, learning the fundamental rules that govern how molecular systems evolve over time.
Traditionally, molecular dynamics (MD) simulations track atomic movements using femtosecond-scale time steps (10⁻¹⁵ seconds). While highly accurate, this approach is computationally expensive and often prevents researchers from observing the slower molecular motions—such as protein folding, conformational changes, and relaxation processes—that determine biological and chemical function.
TITO addresses this challenge by using a deep generative modeling approach that can accelerate molecular simulations by up to four orders of magnitude (10,000×) while preserving the underlying physics of the system. Rather than calculating every individual atomic step, the AI learns how molecular structures evolve across time and can effectively bridge molecular behavior from femtoseconds to nanoseconds.
Remarkably, the model not only reproduces equilibrium molecular ensembles and dynamical relaxation processes but also generalizes across different chemical compositions and molecular sizes. It can even extrapolate to peptides larger than those used during training, capturing chemically meaningful transitions on timescales previously accessible only through costly brute-force simulations.
Why This Matters
This work could dramatically accelerate research in:
Drug discovery — exploring protein-ligand interactions and conformational states more efficiently.
Materials science — designing novel materials with desired properties.
Catalysis — understanding reaction pathways and optimizing catalysts.
Biophysics — studying protein dynamics, folding, and molecular mechanisms at unprecedented speed.
More broadly, TITO may represent one of the clearest examples of AI accelerating scientific discovery itself, not merely assisting with data analysis. By expanding the accessible timescales of atomistic simulations while maintaining physical realism, AI-driven approaches like TITO could transform how scientists investigate molecular systems, enabling discoveries that were previously impractical due to computational limitations.
For researchers working at the intersection of AI, chemistry, and biology, this development highlights a growing trend: AI is increasingly becoming a tool for exploring the laws of nature, not just interpreting experimental data. The ability to rapidly map molecular conformational landscapes, thermodynamics, and kinetics may ultimately shorten the path from hypothesis to discovery across multiple scientific disciplines.
#AIforScience #MolecularDynamics #DrugDiscovery #GenerativeAI #Biotech
1
15
838


Jun 13
文科省「SPReAD(SPReAD1000)」第2回公募が進行中(〜7/3正午)。CarbConnect®を基盤とした「AI for Science 伴走支援」へのご相談が増えています。PoCから社会実装まで一気通貫で伴走。
▼ carbgem.com/carbgem_ai_for_s…
#SPReAD1000 #AIforScience #CarbConnect #研究DX

1
61

TPC26 proved AI science is advancing fast—but interconnect bottlenecks are silently crushing ROI. Cheap cables = idle GPUs = massive TCO bleed. Time to upgrade to 1.6T LPO architecture.
#AIForScience #DataCenterInfrastructure #HighSpeedInterconnects
10

MSCA Doktora Ağları 2026 Çağrısı Açıldı!
Ufuk Avrupa Marie Skłodowska-Curie Actions kapsamında yürütülen Doktora Ağları 2026 Çağrısı, 28 Mayıs 2026 itibarıyla başvurulara açıldı.
📅 Son Başvuru Tarihi: 24 Kasım 2026
💶Bütçe: 593 milyon Avro
🎓Hedef: 130’dan fazla proje ve yaklaşık 2.115 doktora adayının desteklenmesi
Çağrı; üniversiteler, araştırma kuruluşları, araştırma altyapıları, işletmeler, KOBİ’ler ve ilgili diğer kuruluşların uluslararası konsorsiyumlar aracılığıyla yenilikçi doktora programları yürütmesini desteklemektedir.
📌 Başvuru formatları:
🔹Standart Doktora Ağları
🔹Sanayi Doktoraları
🔹Ortak Doktoralar
🤖 2026 çağrısının önemli yeniliklerinden biri olan RAISE Doctoral Networks pilot girişimi ise yapay zekânın bilimsel araştırmalarda kullanımına odaklanan doktora ağlarını destekleyecektir.
📢 Avrupa Komisyonu tarafından 3 Haziran 2026 tarihinde çevrim içi bir Bilgi Günü düzenlenmiştir.
🔗 Bilgi Günü sunumlarına ulaşmak için:
marie-sklodowska-curie-actio…
📩 Sorularınız için: ncpmobility@tubitak.gov.tr
***
MSCA Doctoral Networks 2026 Call is now open!
The Doctoral Networks 2026 Call, implemented under the Horizon Europe Marie Skłodowska-Curie Actions, opened for applications on 28 May 2026.
📅 Deadline: 24 November 2026
💶Budget: €593 million
🎓Target: Support for more than 130 projects and approximately 2,115 doctoral candidates
The call supports universities, research organisations, research infrastructures, businesses, SMEs and other relevant organisations in implementing innovative doctoral programmes through international consortia.
📌 Proposal formats:
🔹Doctoral Networks
🔹Industrial Doctorates
🔹Joint Doctorates
🤖 One of the key novelties of the 2026 call, the RAISE Doctoral Networks pilot initiative, will support doctoral networks focusing on the use of artificial intelligence in scientific research.
📢 The European Commission held an online Info Day on 3 June 2026.
🔗 Info Day presentations:
marie-sklodowska-curie-actio…
📩 For questions: ncpmobility@tubitak.gov.tr
#HorizonEurope #MSCA #DoctoralNetworks #MarieSkłodowskaCurieActions #RAISE #AIforScience #Research #Innovation #TÜBİTAK
4
10
1,339

India carries the world’s deadliest snakebite burden, yet next-gen solutions remain underexplored.
Delighted to receive an @Anthropic Science AI grant to accelerate antibody discovery at @LabVenomics, @iiscbangalore.
#AIforScience #Snakebite #IISc #venomdetective
16
58
431
13,244

Our paper, “IPSM-Bench: A New Intermediate Phase Segmentation Benchmark in Microstructure Images of Zinc-based Absorbable Biomaterials,” has been accepted at IJCAI-ECAI 2026!
paper: arxiv.org/pdf/2606.11001
dataset: github.com/AgileMotionTeam/I…
#IJCAI2026 #AIforScience #Biomaterials

1
33

Jun 11
AI is transforming drug discovery at an unprecedented pace.
But discovery alone is not enough.
Scientific breakthroughs only matter when they can be:
• validated
• reproduced
• executed in real-world environments
The next frontier isn’t just smarter models.
It’s building the infrastructure that turns discoveries into outcomes.
#AIforScience #DeSci

19

Ronit Chaodhary, who is a 21-year-old NST student, publishes AI for science paper accepted at ICML 2026 workshop
timesofindia.indiatimes.com/…
#ICML2026 #AIForScience #MachineLearning #AIResearch #IndianAI

1
95

Jun 11
<브뤼셀에서 한-EU 과학기술 협력의 다음 단계를 논의했습니다>
대통령님 벨기에·EU 국빈 방문을 수행하며 브뤼셀 일정을 마치고 어젯밤 이탈리아로 이동했습니다. 조금 늦었지만 브뤼셀에서 있었던 과학기술 협력 소식을 전합니다.
예카테리나 자하리에바(Ekaterina Zaharieva) EU 스타트업·연구혁신 집행위원(@EZaharievaEU)을 만나 한-EU 과학기술 협력 확대 방안을 논의했습니다. 이번 정상회담에서 다뤄진 AI, 디지털, 연구혁신, 인력교류, 딥테크 스타트업 협력을 실제 연구 현장과 기업 협력으로 이어가기 위한 자리였습니다.
특히 호라이즌 유럽 준회원국 참여 성과를 함께 확인했습니다. 한국은 아시아 국가 중 처음으로 호라이즌 유럽 준회원국이 된 뒤 짧은 기간 안에 여러 국제 공동연구 과제에 참여하고 있습니다. 우리 연구자들이 유럽의 세계적 연구기관들과 함께 경쟁하고 협력하고 있다는 점에서 의미가 큽니다.
앞으로 AI for Science, 첨단바이오, 양자 분야에서 협력을 더 넓혀가기로 했습니다. K-문샷과 국가과학AI연구센터를 바탕으로 과학데이터와 AI 활용 연구 협력도 구체화해 나가겠습니다.
브뤼셀 방문 첫 일정으로는 벨기에 루벤의 반도체 연구기관 IMEC에서 활동하는 한인 연구자들도 만났습니다. 세계 최고 수준의 반도체·AI·양자 연구 현장에서 뛰고 있는 분들을 보며 대한민국 과학기술의 무대가 이미 세계와 깊이 연결되어 있다는 것을 다시 느꼈습니다.
이번 방문이 한-EU 공동연구와 연구자 교류, 딥테크 협력으로 이어질 수 있도록 귀국 후에도 꼼꼼히 챙기겠습니다.
#한EU협력 #HorizonEurope #AIforScience #K문샷 #과기정통부 #MSIT




4
71
266
2,294

Jun 11
Training Personal Agents for real, stateful workspaces faces severe data and evaluation bottlenecks. ClawGym solves this by providing a complete pipeline:
• SynData: 13.5K executable, dual-route synthetic tasks
• Agents: Multi-turn SFT & sandbox-parallel RL training
• Bench: Capability diagnostics across 6 workspace scenarios
Brought to you by IQuest Research and its partners. 📊
Get started with the framework: github.com/ClawGym
#AI4S #AIforScience

1
68


Astrophysicist Chi-kwan Chan uses Codex to simulate black holes, bringing new possibilities for testing Einstein’s theory with AI-driven cosmic models. #AIforScience #OpenAI openai.com/index/using-codex…
22

Jun 11
Everyone is asking how to build better AI research agents.
Our latest study may suggest a different question:
Preprint: arxiv.org/html/2606.11830v1
How do we evaluate them?
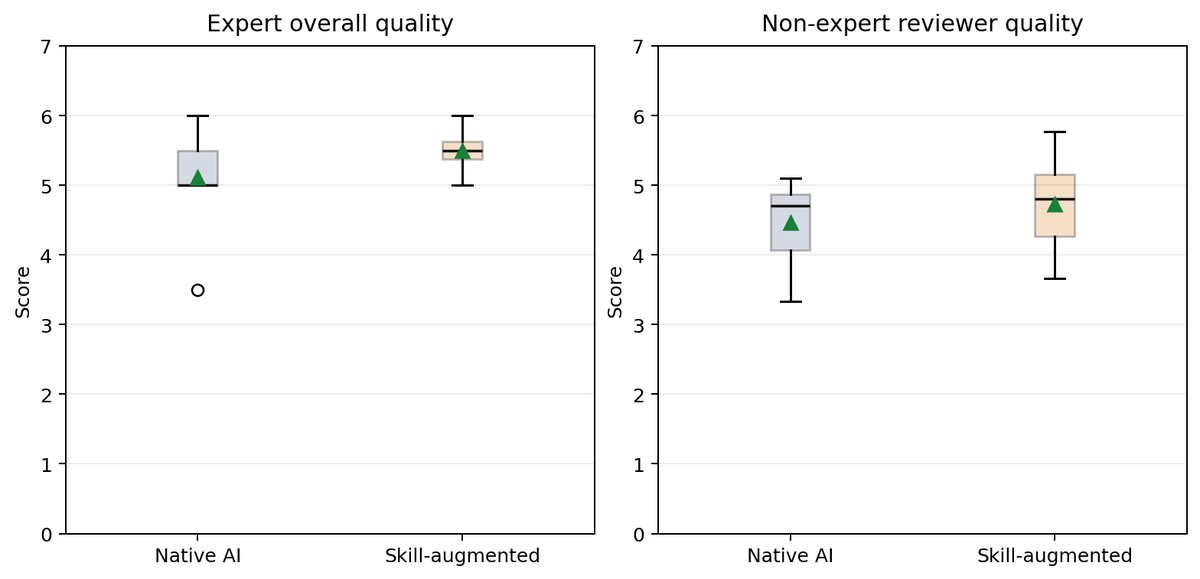
In a blinded human evaluation of medical research agents, Skill-Augmented Agents showed positive signals in research quality.
But here's the surprising part:
The disagreement between expert reviewers (0.67 points on average) was larger than the observed improvement from skills ( 0.39).
Even more striking, expert inter-rater reliability was negative (ICC = -0.15).
The bottleneck may no longer be agent capability.
It may be the evaluation itself.
As AI agents become increasingly capable, building reliable evaluation frameworks could become one of the most important challenges in AI for Science.
#AIAgents #AIforScience #Evaluation


1
3
4,755

Jun 11
GRAIL made a successful debut at #NYTechWeek with “Building AI Agents for Science.” @Techweek_
Through a panel and an #ApexClaw workshop, researchers, founders, engineers, investors, and academics explored how AI agents can support every stage of the scientific process.
Beyond the sessions, attendees connected with peers across academia, startups, and industry, creating valuable opportunities for collaboration and knowledge sharing.
Thank you to our speakers, Eugene Wu, Francisco Villaescusa-Navarro, Glen Hocky, and everyone who joined us. We're excited to continue advancing the future of AI for Science and empowering researchers with agentic AI. Ready to get started? Explore ApexClaw and begin building your own scientific AI agents: grailai.io/
#AIAgents #AutonomousScience #AIforScience #techweek #newyorkevents
26

Jun 10
A wonderful evening at today's State Reception in Munich, where I had the privilege of opening the evening after Minister Hubert Aiwanger and welcoming participants of HAICON 2026. 🇩🇪
It felt particularly fitting to discuss the future of AI in the historic Kaisersaal of the Munich Residenz 🏛️. Science is not only becoming faster. It is becoming fundamentally different. AI is transforming how we do research, how companies innovate, and increasingly how society works.
This year's HAICON brought together around 600 participants from academia, industry, and government, including guests from around the world. The discussions over the last days reinforced something I strongly believe: Bavaria, and especially Munich, has become one of Europe's leading ecosystems for AI, combining world class research, entrepreneurship, industry, and forward looking policymaking 🚀.
Thank you to the Bavarian Ministry of Economic Affairs and everyone who helped make this event possible.
The future of AI will not simply happen to us. It is ours to understand, shape, and build. 🤖
#HAICON26 #AIforScience #Bavaria



1
2
32
3,640

TPC26 Panel Highlights the Growing Importance of Collaboration in AI for Science
ow.ly/3U8150Za6qE
#AIforScience, #ResearchCollaboration, #GlobalScience, #ScientificPartnerships, #InternationalResearch, #TPC26, #ScientificComputing, #OpenFoundationModels

3
157

Closing the Prior-Posterior Loop: Self-Reflective Molecular Design with Analysis-Driven LLM Iteration
1. The paper proposes an alternative to “Generate → Score → Regenerate” in LLM molecular design: “Generate → Analyze → Reflect → Refine”, where the model is fed mechanism-level quantum-chemistry evidence (e.g., orbital energies, charges, electron density) instead of a single scalar score.
2. Core claim: providing full physicochemical rationale from first-principles calculations can shift an LLM’s behavior from stochastic sampling toward more causal, structure-property reasoning—because the model learns not only that a candidate misses the target, but why.
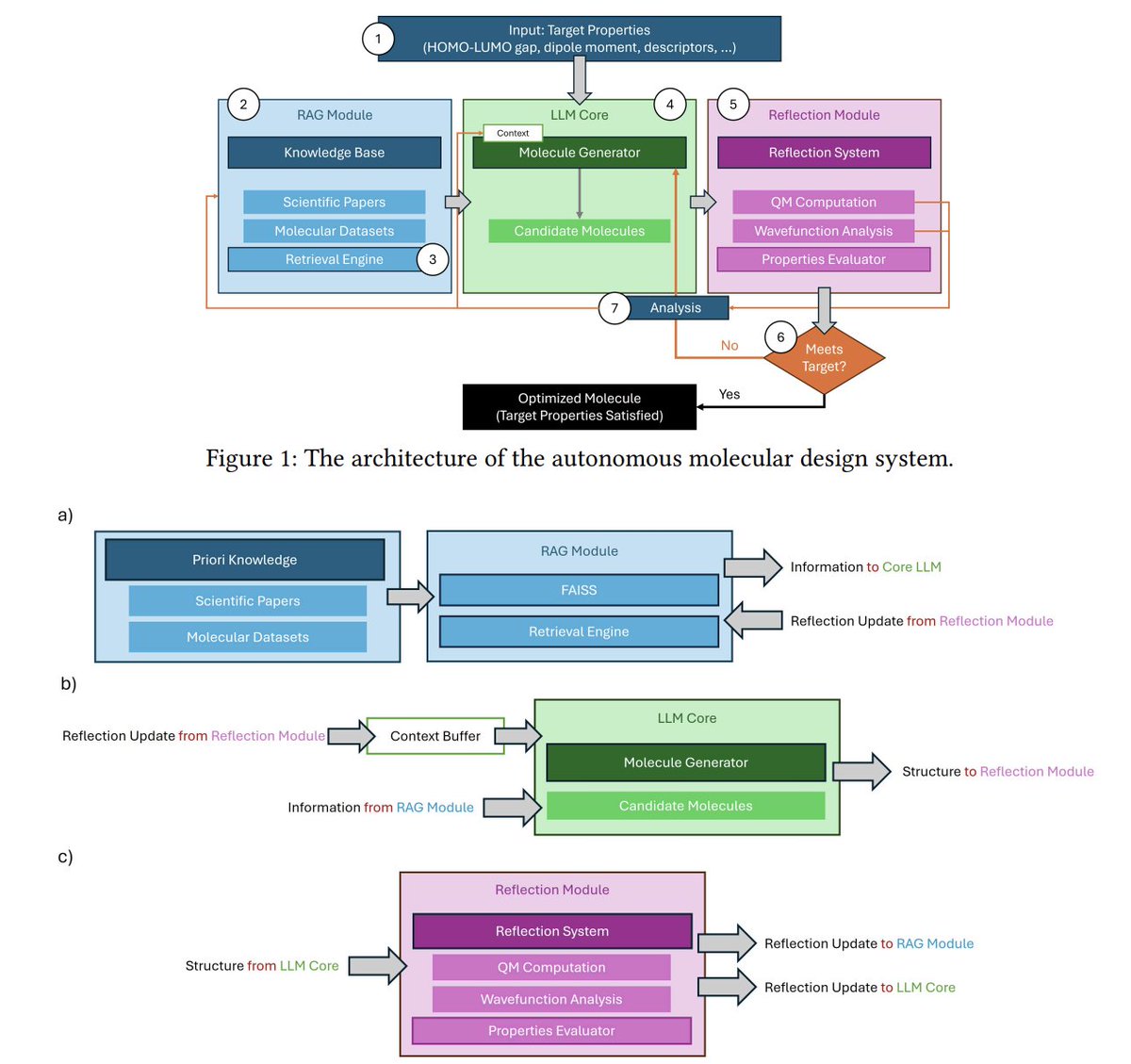
3. System architecture has three coupled parts: (i) a retrieval-augmented generation (RAG) module for prior knowledge, (ii) an LLM core that proposes candidates, and (iii) a reflection module that runs quantum calculations and converts raw outputs into actionable design edits.
4. The RAG database is built from QM9 (about 130k small organic molecules, <9 heavy atoms) using a FAISS vector index; retrieval is conditioned on the requested target property (e.g., HOMO-LUMO gap).
5. The reflection module explicitly avoids treating computation as a black-box scorer. It preserves rich outputs such as HOMO/LUMO energies, Mulliken charges, total electronic energies, dipole moments, and (conceptually) wavefunction/electron-density information.
6. For efficiency, evaluation is staged: GFN2-xTB is used for geometry optimization and fast pre-screening, then pySCF performs higher-accuracy DFT on top candidates (default batch: x=20 candidates screened, y=5 sent to DFT).
7. The self-reflection procedure is described as a 3-step pipeline: (1) extract key parameters from DFT output, (2) perform causal reasoning linking structure to the target property, (3) plan concrete structural modifications for the next iteration; reflection insights are also written back into the RAG context.
8. On targeted HOMO-LUMO gap design across 5 targets (5.0, 4.0, 3.0, 2.0, 1.0 eV), SPR reflection (mechanism-level feedback) RAG is consistently the most stable configuration; for the 3.0 eV task it reports deviation down to 0.0003 eV, and for the 2.0 eV task it is the only configuration reaching 100% success rate (within the authors’ success definition).
9. The paper highlights a failure mode of scalar-only feedback: on the hardest 1.0 eV gap target, Scalar RAG fails (0/3 successes), while SPR RAG yields at least one close solution (0.0164 eV deviation), suggesting that “far from target” numbers alone may not provide an actionable gradient for difficult design regimes.
10. Additional findings: (i) convergence is not monotonic—extra iterations can cause “overthinking” and oscillations; (ii) batch reflection can outperform per-molecule reflection (BFS-like vs DFS-like exploration); (iii) the framework generalizes beyond gaps to dipole-moment targeting (example target 2.5 D, best deviation ~0.016 D), and appears robust across five LLM backbones (DeepSeek-V4Pro/Flash, MiniMax-M3, Qwen-3.7Max, GLM5.1).
📜Paper: arxiv.org/abs/2606.09520
#ComputationalChemistry #MolecularDesign #LLM #RAG #QuantumChemistry #DFT #InverseDesign #AIforScience #Cheminformatics
2
6
1,090

Jun 10
OPENSCI Perspective: From Physical AI to Quantum Chips, From Autonomous Computing Power to the Paradigm Shift of AI Research - The "hardware" of productivity is constantly upgrading every week.
However, the "software" of research - fund evaluation, contribution recognition, data sharing - still operates in the old rhythm of "two rounds a year, each round lasting half a year". When AI can autonomously generate hypotheses, analyze data, and even design experiments, who will sign off on each step of it? If the trust mechanism doesn't keep up, the faster the speed, the greater the risk.
#WeeklyFrontier #AIforScience #Quantum Computing #OPENSCI

9
Jun 10
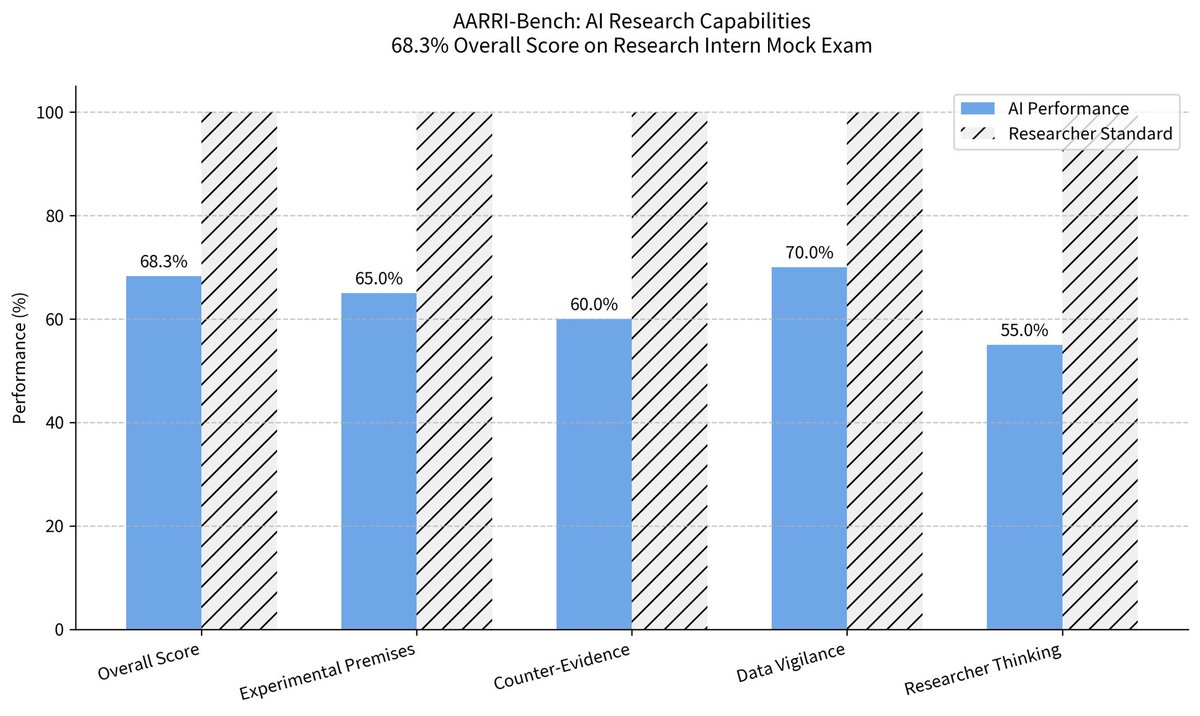
AI just took a mock exam for "research intern" positions, scoring 68.3%.
The AARRI-Bench new benchmark test reveals that even the most advanced AI models still tend to disregard experimental premises, overlook the counter-evidence presented in the literature, and lack vigilance regarding data flaws.
When it comes to conducting research, AI lacks not computing power, but rather the ability to "think like a researcher" - as well as a trust foundation that enables every inference to be traceable and auditable.
OPENSCI is filling in this gap.
#AIforScience #ResearchInfrastructure #OPENSCI
1
16