
กระแส autonomous AI coding กำลังพา software engineering เข้าสู่จุดเปลี่ยนที่สำคัญ เพราะคำถามหลักไม่ได้อยู่ที่ว่า AI เขียนโค้ดได้หรือไม่อีกต่อไป แต่กำลังขยับไปสู่คำถามที่ยากกว่า คือถ้า AI สามารถอ่าน repo ทั้งชุด แก้หลายไฟล์ refactor architecture สร้าง test รัน command และปรับทั้งโปรเจกต์ได้เอง เราจะเชื่อถือมันได้แค่ไหน และควรวางกลไกแบบใดเพื่อไม่ให้ความเร็วของมันกลายเป็นความเสี่ยงเชิงระบบ
ปัญหาของ autonomous AI coding ไม่ใช่ว่า AI ไม่มีประโยชน์ ตรงกันข้าม มันมีประโยชน์มากในการสร้าง prototype เร็ว เขียน module เบื้องต้น แปลง idea ให้เป็น implementation สร้าง API endpoint จัดโครงสร้าง database schema ทำ documentation เขียน test case และช่วย refactor codebase ที่มีความซับซ้อนได้เร็วกว่าการทำงานแบบมนุษย์ล้วนหลายเท่า แต่ความเร็วนี้มีราคาของมัน เพราะ AI สามารถผลิตโค้ดจำนวนมากที่ดูสมเหตุผล ดู clean ดู modular และดูเหมือนเป็นระบบวิศวกรรมที่ดี ทั้งที่ยังมี bug เชิงความหมายซ่อนอยู่ในรอยต่อระหว่าง component
นี่คือจุดที่ต้องแยกให้ออกระหว่าง local plausibility กับ global correctness โค้ดแต่ละไฟล์อาจดูดี function แต่ละตัวอาจดูเข้ากับ schema อาจไม่พลาด service layer อาจแยกหน้าที่ชัดเจนใน database อาจทำการเปลี่ยนผ่านระบบใหม่สำเร็จ test บางชุดอาจผ่าน และ UI อาจแสดงผลได้ แต่ทั้งระบบอาจยังผิดในระดับ semantic invariant เช่น user permission ถูกเช็กใน layer หนึ่งแต่ถูก bypass ในอีก layer หนึ่ง cache เก็บข้อมูลเก่าที่ไม่ตรงกับ database transaction API หนึ่งใช้ field name คนละความหมายกับอีก API หนึ่ง หรือ background job หนึ่ง mutate state โดยไม่สร้าง audit record ความผิดแบบนี้ไม่จำเป็นต้องทำให้ระบบ crash แต่มันอันตรายกว่า เพราะระบบยังทำงานต่อไปอย่างมั่นใจบนความหมายที่ผิด
กรณีทั่วไปใน coding project คือ AI มักเก่งมากในการทำให้ระบบ “ดูครบ” แต่ยังไม่แน่เสมอไปว่าระบบ “ถูกต้อง” มันอาจสร้าง authentication flow ที่ดูมี middleware แต่ลืม enforce role ใน endpoint สำคัญ สร้าง payment flow ที่ดูเชื่อม checkout ได้แต่ไม่ handle idempotency สร้าง database schema ที่ migrate ได้แต่ไม่ preserve invariant ระหว่าง order, invoice และ payment สร้าง async worker ที่ดูประมวลผล queue ได้แต่ทำให้ event ถูก execute ซ้ำ หรือสร้าง admin dashboard ที่ดูดีแต่เปิดช่องให้ข้อมูล sensitive ถูกอ่านเกินสิทธิ์ นี่คือ bug ประเภทที่ไม่ใช่ syntax error แต่เป็น architecture error
ดังนั้น autonomous coding ไม่ได้พังเพราะมันเขียนโค้ดไม่ได้ แต่มันอาจพังเพราะมันสร้างระบบที่ “ดูเป็นระบบ” ได้โดยยังไม่เข้าใจเงื่อนไขความจริงของ domain อย่างครบถ้วน ในระบบหนึ่ง ความจริงสำคัญอาจไม่ใช่แค่ว่า request ส่งมาแล้ว response 200 แต่ต้องรวมถึงความจริงที่ลึกกว่า เช่น actor ต้องมีสิทธิ์ก่อน action, state transition ต้องเป็นไปตาม lifecycle, transaction ต้อง atomic, retry ต้อง idempotent, audit log ต้องเกิดก่อน external side effect, secret ต้องไม่หลุดเข้า context, และ background worker ต้องไม่แตะ resource นอก policy ที่กำหนดไว้
นี่คือบทเรียนสำคัญของ AI coding ยุค agentic กล่าวคือ unit test อาจผ่าน แต่ system invariant อาจพัง endpoint อาจตอบถูก แต่ authorization boundary อาจรั่ว database migration อาจสำเร็จ แต่ data meaning อาจเสียความหาย CI อาจดูไม่มีปัญหา แต่ production behavior อาจผิด และเมื่อ AI coding ถูกปล่อยให้แก้ทั้งโปรเจกต์ในลักษณะ autonomous โดยไม่มี forensic loop ความผิดประเภทนี้จะยิ่งตรวจยาก เพราะ agent ไม่ได้แก้แค่บรรทัดเดียว แต่มันอาจปรับ schema, service, handler, worker, test, config และ documentation ไปพร้อมกัน ทำให้ระบบดูสอดคล้องขึ้น ทั้งที่ความจริงเชิง domain ยังไม่ได้ถูก enforce
อีกด้านหนึ่ง ปัญหา tokenmaxing ก็เป็นสัญญาณเตือนของอุตสาหกรรมเช่นกัน เมื่อองค์กรขนาดใหญ่เริ่มพบว่า autonomous coding สามารถใช้ token จำนวนมหาศาลได้ในเวลาอันสั้น คำถามจึงไม่ใช่แค่ “AI coding ทำงานได้ไหม” แต่คือ “token ที่ใช้ไปสร้าง value ที่ตรวจสอบได้จริงหรือไม่” ถ้าการใช้ AI coding กลายเป็นการรัน agent ยาว ๆ ให้เดินวนใน repo แก้ไฟล์จำนวนมาก อธิบายตัวเองจำนวนมาก และสร้าง diff จำนวนมาก โดยไม่มี output contract, token budget, acceptance criteria, test harness และ audit trail สิ่งที่เกิดขึ้นอาจไม่ใช่ productivity แต่เป็น computational bureaucracy หรือระบบราชการเชิงคำนวณที่ผลิต activity มากกว่าผลลัพธ์
ดังนั้นประเด็นที่ถูกต้องไม่ใช่การเลือกข้างแบบง่าย ๆ ว่า autonomous AI coding ดีหรือไม่ดี แต่คือการออกแบบ operating model ให้มันอยู่ในกรอบที่ถูกต้อง การเชื่อการโค้ดอัตโนมัติของเอไอแบบไม่ตรวจสอบอะไรเลยอาจไม่คุ้ม เพราะมันเร็วที่สุดก็จริง แต่แลกกับ runaway token spend, hidden semantic bugs และ trust ที่ต่ำ ดังนั้นการกำหนดให้มนุษย์อยู่ใน loop เพื่อช่วย coding หรือแม้เพียงตรวจสอบก็ยังจำเป็นสำหรับ critical core เพราะมนุษย์ยังมี judgment เชิง domain และความรับผิดชอบเชิงระบบ แต่ถ้าใช้มนุษย์ล้วนทุกส่วน ต้นทุนเวลาและความเร็วในการทดลองจะสูงเกินไป ส่วน governed agent coding เป็นเป้าหมายระยะยาวที่ดี แต่ต้องมี harness, CI, sandbox, policy, audit log และ evaluation infrastructure ที่แข็งแรงพอ
แนวทางที่ practical ที่สุดในตอนนี้จึงไม่ใช่ blind automation แต่คือ forensic-loop AI coding นั่นคือใช้ AI ในสิ่งที่มันถนัด คือสร้างต้นแบบเร็ว ขยาย codebase แปลง architecture เป็น implementation เขียน test และเสนอ repair path แต่ไม่ให้ AI เป็นผู้ตัดสินความจริงขั้นสุดท้าย ระบบต้องถูกนำกลับมาตรวจด้วย forensic inspection เสมอ ต้องดูว่า state จริงอยู่ที่ไหน action จริงเกิดที่ layer ใด database บันทึกอะไร log บอกอะไร permission ถูก enforce ที่จุดไหน side effect เกิดก่อนหรือหลัง validation worker ตัวไหนแตะข้อมูลอะไร และ invariant ใดที่ยังไม่มี code enforce
รูปแบบการทำงานที่เหมาะสมจึงคล้ายวงจรวิศวกรรมเชิงทดลองมากกว่าวงจร automation ธรรมดา เริ่มจาก vibe code เพื่อสร้าง prototype จากนั้นทำ forensic inspection เพื่อดูว่าระบบจริงทำอะไร ไม่ใช่ดูแค่ว่าโค้ดตั้งใจจะทำอะไร ต่อมาจึง extract invariant จาก failure แล้วสั่ง autonomous revision ภายใต้ constraint ที่ชัดขึ้น จากนั้นเพิ่ม adversarial tests เช่น missing permission, stale cache, duplicate event, partial transaction, unsafe file path, secret leakage, schema drift, race condition และ unauthorized side effect แล้วจึง re-forensic อีกครั้งเพื่อดูว่า repair นั้นแก้ causal chain จริงหรือแค่ทำให้ระบบดูสะอาดขึ้น
สุขอนามัยของ AI coding ที่ดีจึงควรเริ่มจาก token budget ทุก autonomous run ไม่ควรเป็นการปล่อย agent ไปเดินเล่นใน repo อย่างไม่มีขอบเขต แต่ควรมี spending cap และ expected artifact ชัดเจน เช่น patch สำหรับ module หนึ่ง test suite หนึ่ง migration หนึ่ง forensic script หนึ่ง หรือ design note หนึ่ง ถ้าไม่มี artifact ที่ตรวจสอบได้ token ที่ใช้ไปก็เป็นเพียงต้นทุน ไม่ใช่ value
ถัดมาคือ invariants ต้องมาก่อน implementation ในระบบทั่วไป requirement อาจบอกว่าให้เพิ่ม feature อะไร แต่ในระบบที่มีความเสี่ยงสูง requirement ไม่พอ ต้องบอกด้วยว่าอะไรห้ามเกิดขึ้นเด็ดขาด เช่น unknown action ต้อง deny, permission check ต้องเกิดก่อน side effect, payment retry ต้อง idempotent, database write ต้องอยู่ใน transaction, cache invalidation ต้องตามหลัง commit, background job ต้องไม่ bypass policy, status endpoint ต้องไม่ mutate state โดยไม่มี audit และ policy engine error ต้อง fail-closed สิ่งเหล่านี้คือความจริงเชิงระบบที่ AI ต้องถูกบังคับให้เคารพด้วย code ไม่ใช่แค่รับทราบใน prompt
หลัก fail-closed สำคัญมาก เพราะ AI มักถูกออกแบบให้ช่วยเหลือและเติมช่องว่าง แต่ในระบบจริง การเติมช่องว่างผิดอาจอันตรายกว่าการหยุดทำงาน ถ้าข้อมูลหาย ระบบไม่ควรเดา ถ้า user ไม่ชัดเจน ระบบไม่ควร assume permission ถ้า transaction ไม่ครบ ระบบไม่ควร commit บางส่วน ถ้า external API timeout ระบบไม่ควร retry โดยไม่ดู idempotency key ถ้า policy evaluator error ระบบไม่ควร allow โดย default ความฉลาดควรอยู่ใน planning, analysis และ review ไม่ใช่อยู่ใน execution path ที่สามารถแตะ state จริงโดยไม่มี gate
นี่คือเหตุผลที่ execution layer ควร dumb, deterministic และ strict ส่วน intelligence ควรอยู่ในชั้น design, planning, diagnosis, testing และ explanation execution ไม่ควร infer ไม่ควร repair ไม่ควร substitute และไม่ควร fallback โดยพลการ ถ้า action ไม่มี permission ก็ reject ถ้า input ไม่ผ่าน schema ก็ reject ถ้า state transition ผิด lifecycle ก็ reject ถ้า side effect ไม่มี audit path ก็ reject ถ้า secret อาจหลุดก็ block หลักการนี้ฟังดู conservative แต่เป็น conservative ที่จำเป็น เพราะในระบบ agentic ความผิดไม่ได้อยู่แค่คำตอบผิด แต่อยู่ที่ action ผิดที่ถูก execute ไปแล้ว
ในภาพใหญ่ autonomous AI coding จึงจะคุ้มค่าก็ต่อเมื่อมันถูกวางไว้ใน forensic governance loop ไม่ใช่ถูกยกให้เป็น autonomous authority การใช้ AI coding อย่างมีวินัยคือการแบ่งงานให้ถูกต้อง model ทำสิ่งที่ model ถนัด คืออ่าน repo วิเคราะห์ pattern เขียน code เสนอ refactor สร้าง test และช่วยคิด causal chain ส่วน deterministic infrastructure ทำสิ่งที่ code ถนัด คือ enforce invariant, run test, gate execution, log provenance, block unsafe action, preserve audit trail และทำให้ทุก decision ย้อนรอยได้
นี่คือความต่างระหว่างการใช้ AI coding เป็นของเล่นกับการใช้ AI coding เป็นเครื่องมือวิศวกรรม ถ้าใช้แบบแรก เราจะได้ code มากขึ้น token burn มากขึ้น และ illusion of productivity มากขึ้น แต่ถ้าใช้แบบหลัง เราจะได้ระบบที่เรียนรู้จาก failure ได้เร็วขึ้น ลด cost of exploration ได้จริง และค่อย ๆ เปลี่ยน AI จากผู้ช่วยเขียนโค้ดให้กลายเป็นส่วนหนึ่งของ research and engineering loop ที่ตรวจสอบได้
ข้อสรุปจึงไม่ใช่ว่า autonomous AI coding ควรถูกปฏิเสธ แต่ก็ไม่ใช่ว่าควรถูกเชื่อโดยอัตโนมัติ คำตอบที่แม่นกว่าคือ autonomous AI coding คุ้มค่าเมื่อมันอยู่ในระบบที่มี token budget, invariant-first design, fail-closed execution, adversarial tests, provenance logging, sandbox, review gate และ forensic recheck มันไม่คุ้มเมื่อถูกใช้เป็น blind automation แต่คุ้มมากเมื่อถูกใช้เป็น disciplined acceleration
ในยุคต่อไป คนที่ได้เปรียบอาจไม่ใช่คนที่ปล่อย AI เขียนโค้ดได้มากที่สุด แต่คือคนที่สร้าง process ให้ AI เขียน แก้ พลาด ถูกตรวจ ถูกบังคับให้เรียนรู้จาก invariant และกลับมาแก้ใหม่ได้เร็วที่สุด Autonomous AI coding จึงไม่ใช่ปลายทางของ software engineering แต่มันคือ accelerator ของทีมที่มี engineering discipline มากพอจะควบคุมความเร็วของมันได้
#AITensibility #AICoding #AutonomousCoding #AgenticAI #SoftwareEngineering #AIEngineering #ForensicEngineering #GovernanceRuntime

114

Radiology RCM: 30% fewer denials with autonomous coding. 6/9 demo; real-time billing, hybrid AI, <3mo implementation. Free for RBMA @RBMAConnect members: rbma.org/RBMAMembers/Educati…
#RBMA #Radiology #AutonomousCoding #RCM

30

Mar 28
IDEの時代が終わりつつあるのか、それともIDEが進化するのか。Claude CodeやDevin見てると、エディタで1行ずつ書く開発スタイル自体が変わりそうな気はする。Cursorがマルチエージェントに舵切ってるのは正しい判断だと思う。 #AI #AutonomousCoding #CursorAI

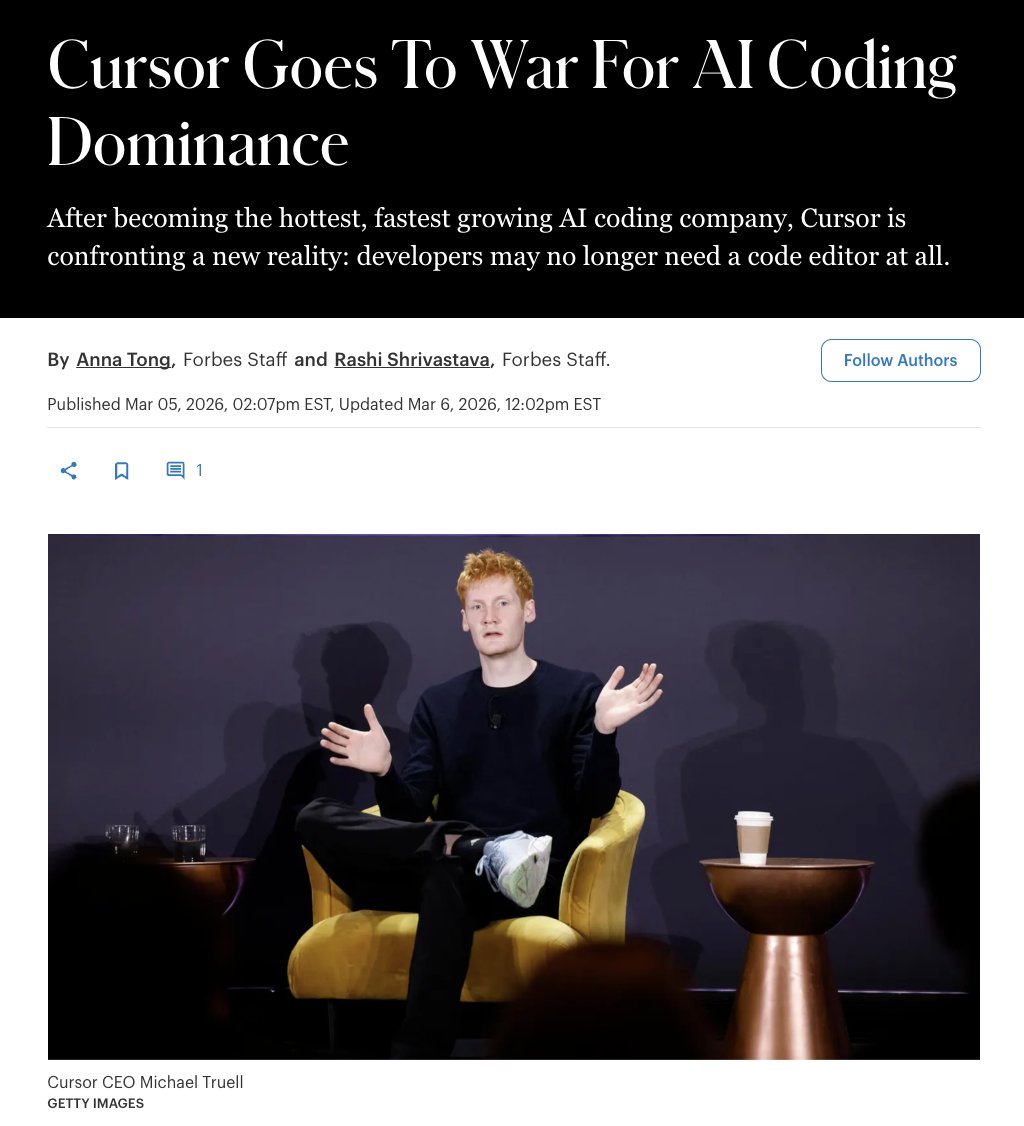
Cursor just hit a staggering $30 billion valuation with over $2 billion in revenue, but the very foundation of its business model is already under threat.
With the rise of hyper-advanced, autonomous coding agents like Anthropic's Claude Code, developers are moving away from writing code line-by-line entirely.
Cursor is now scrambling to pivot, building its own proprietary models and developing multi-agent systems to stay relevant in a world where the traditional code editor might soon be obsolete.
1
2
160

Feb 5

New Engineering blog: We tasked Opus 4.6 using agent teams to build a C compiler. Then we (mostly) walked away. Two weeks later, it worked on the Linux kernel.
Here's what it taught us about the future of autonomous software development.
Read more: anthropic.com/engineering/bu…
145


16 Dec 2025
🤔 What does it take for an AI system to truly behave like an autonomous software engineer, not just a code assistant?
This paper introduces DeepCode, an open agentic coding framework that tackles one of the hardest problems in AI-assisted development: translating complex documents—like machine learning research papers—into complete, executable codebases with high fidelity.
The key insight is deceptively simple but powerful. The bottleneck isn’t model size or raw reasoning ability. It’s information flow. When long, multimodal specifications collide with finite context windows, critical details get lost, consistency breaks down, and execution fails. DeepCode reframes document-to-repository synthesis as a channel optimization problem, where the goal is to maximize task-relevant signal under strict context constraints.
To do this, the system orchestrates four principled information operations:
• Blueprint distillation to compress papers into precise, implementation-ready plans
• Stateful code memory to preserve global consistency across files without context bloat
• Conditional knowledge injection via retrieval to fill underspecified design gaps
• Closed-loop verification that turns runtime errors into corrective signals
The results are striking. On PaperBench, DeepCode not only outperforms leading commercial coding agents, but also surpasses PhD-level human experts on key reproduction metrics. This suggests a broader takeaway: architectural design and information orchestration matter more than simply scaling context or models.
Beyond paper reproduction, this work points toward a future where agentic systems can reliably turn high-level specifications into production-grade systems—and do so in a way that is auditable, scalable, and reproducible.
If you’re thinking about the next generation of AI software engineering, this paper is worth a close read.
#AgenticAI #AutonomousCoding #SoftwareEngineering #AIResearch #LLMs #CodeGeneration #ResearchReproducibility #AIArchitecture #InformationFlow #MachineLearning

2
815

while you orchestrate the vision.
O.XYZ isn’t building an app. They’re building the world where this becomes normal.
#OXYZ #Agents #AIEngineering #DeAI #AutonomousCoding #FutureOfWork #WorkGraph
2
58

24 Sep 2025
𝐌𝐞𝐞𝐭 𝐑𝐞𝐩𝐥𝐢𝐭 𝐀𝐠𝐞𝐧𝐭 3: 𝐓𝐡𝐞 𝐅𝐮𝐭𝐮𝐫𝐞 𝐨𝐟 𝐀𝐮𝐭𝐨𝐧𝐨𝐦𝐨𝐮𝐬 𝐀𝐩𝐩 𝐃𝐞𝐯𝐞𝐥𝐨𝐩𝐦𝐞𝐧𝐭
Replit’s Agent 3 is the most autonomous AI agent made to create ready-to-use apps with very little help. This AI agent does much more than just write code. It builds, tests, finds bugs, and ships complete apps all by itself.
--
𝐇𝐞𝐫𝐞’𝐬 𝐰𝐡𝐲 𝐀𝐠𝐞𝐧𝐭 3 𝐢𝐬 𝐚 𝐦𝐚𝐬𝐬𝐢𝐯𝐞 𝐥𝐞𝐚𝐩 𝐟𝐨𝐫 𝐝𝐞𝐯𝐞𝐥𝐨𝐩𝐞𝐫𝐬 𝐰𝐨𝐫𝐥𝐝𝐰𝐢𝐝𝐞:
1. True Autonomy for Longer Development Sessions - Agent 3 works autonomously for 200 minutes, handling complex builds without needing constant developer input.
2. Automated Real Browser App Testing - It tests apps automatically using a real browser, clicking buttons, forms, APIs, and finding bugs fast.
3. Two Distinct Build Approaches to Match Your Style - Choose visual prototyping first or full app build; Agent 3 adjusts to your preferred development style.
4. Builds Agents That Build Agents - Agent 3 builds other AI agents like Slackbots or Telegram bots using simple, natural language commands.
5. Integrated Complex API & Authentication Management - It manages APIs, databases, and authentication flows, helping developers ship production-ready apps faster, easier.
6. Real-Time Mobile Monitoring & Control - Monitor your app’s progress live on mobile, control builds remotely, and approve changes anytime, anywhere.
--
Ready to revolutionize your app development with AI? Email us at contact@techificial.ai to help you accelerate your innovation.
#ReplitAgent3 #AIForDevelopers #AutonomousCoding #NoCodeNoLimits #FutureOfDevelopment #TechificialAI
1
2
39

24 Jun 2025
The future of coding is agentic, transparent, and rewardable.
This is Autonomous Coding — and why we’re building it with @OpenLedger_xyz.
Here’s how it works. 👇
#BuildWithMorpheus #AutonomousCoding #BUIDLQuest

13
11
24
923

9 Jun 2025
🚀 Coding isn’t just about writing lines anymore, it’s about directing the vision
Vibe coding flips the old dev tool dynamic
We’re no longer just coders, we’re creators guiding ideas to life. While AI handles the details, we focus on the outcome
🧠 With io.net and Void Editor, limitations are a thing of the past
Forget tool call caps. Enjoy hours of uninterrupted autonomous workflows
This isn’t just about speed. It’s a new way of building
You don’t need to memorize syntax anymore. You just need a vision
The infrastructure doesn’t block you. It empowers you
💡 Whether you're a seasoned dev or a first time builder, vibe coding unlocks creativity and productivity like never before
Change one environment variable and step into the future
🌐 Vibe coding is here. Don’t just write code, own the flow
#VibeCoding #VoidEditor #IONet #AI #DevTools #AutonomousCoding

5
149

6 Jun 2025
Blackbox AI Agent autonomously built a self-hosted Mailchimp clone — capable of sending billions of emails.
No team. No all-nighter. Just one autonomous agent.
And this is just one example.
Join 15M devs already transforming how they build.
Get Started now 👉 blackbox.ai
@blackboxai #BlackboxAI #AutonomousCoding #MailchimpClone #DevTools #CodeSmarter
66
14
83
34,738

2 Jun 2025
Welcome to the New Era of Coding Automation 🚀
Blackbox AI just launched fully autonomous agents — running remotely in secure virtual machines.
✅ Plug directly into your repo
✅ Assign any task — frontend, backend, ML, you name it
✅ Run dozens (or hundreds) of tasks in parallel
✅ Access from mobile, wherever you are
✅ Trusted by 15M developers
Let your AI agent handle the code.
You focus on the big picture.
👉 Start now at blackbox.ai
@blackboxai
#BlackboxAI #AutonomousCoding #DevTools #AIProductivity
34
18
66
24,217

2 Jun 2025
Try Blackbox AI now → blackbox.ai/
#BlackboxAI #AIDev #ImageToApp #AutonomousCoding #DevTools #SoftwareDevelopment
3
212
2 Jun 2025
Meet the New Era of Coding Automation
Blackbox AI has just launched fully autonomous AI agents that run remotely in secure virtual machines.
✅ Connect them directly to your repo
✅ Assign any task - frontend, backend, ML, or whatever you want
✅ Run 10s or even 100s of tasks simultaneously
✅ Mobile access is also available
✅ Trusted by over 15 million developers today
Let the agent do the work while you focus on strategy.
👉 Get started now at blackbox.ai/
@blackboxai
#BlackboxAI #AutonomousCoding #DevTools #AIProductivity
63
13
84
34,901

27 May 2025
Look, we all know developer time is precious.
Yet teams still waste hours fixing low-priority bugs, cleaning up messy code, and building out repetitive modules.
That is where @blackboxai’s autonomous agents come in.
These cloud-based AI workers take your list of tasks big or small and get to work asynchronously, delivering results when done.
You do not have to micromanage.
You do not even need to check in.
Just delegate and move on.
Thousands of devs are already leaning into this shift.
This is how you code smarter not harder.
Check out more details 👇
blackbox.ai
#BlackboxAI #ModernDevStack #DeveloperTimeMatters #AutonomousCoding
23
17
77
23,707
26 May 2025
Tired of writing endless tickets?
Burned out from context-switching?
Meet your new coding partner—
It listens.
It talks.
It codes.
And it actually understands your project.
Whether it’s spinning up a new web app, fixing a nasty bug, or breaking down gnarly logic, just speak—and it gets to work.
This is real-time, voice-powered AI development.
Feels like magic. Works like engineering.
Check out here
blackbox.ai
@blackboxai
#AIDevelopment #AutonomousCoding #VoiceAI #AIEngineer #FutureOfWork
3
12
46
23,826

25 May 2025
🚀 Your Code Just Got a 24/7 Teammate
Meet BLACKBOX.AI — the autonomous coding agent that actually understands your entire codebase.
No more jumping between files, fixing mystery bugs, or starting from scratch every time.
Here’s what it can do:
✅ Understands your full repo
✅ Builds features on its own
✅ Finds & fixes hidden bugs
✅ Turns ideas into working apps
✅ Works with or without you
Why devs love it:
— No more context switching
— No more late-night debugging
— No more zero-to-one grind
💡 From idea to production — without writing a line of code.
Try it free (no credit card):
👉 blackbox.ai
P.S. Remember when autocomplete felt magical? This is that—on steroids.
#BLACKBOXAI #DevTools #AutonomousCoding #AIForDevelopers #CodeSmarter #DevLife #WebDev #GPTForCode
15
10
30
11,580

11 Apr 2025
I think @demishassabis has a great perspective on how to view this huge advance in AI-assisted coding. In some ways it's evolutionary - higher level of abstraction - as has always happened in programming languages. On the other had, it does promise to make programming more accessible to non-programmers - the creatives, the marketing folks, and others.
@GoogleDeepMind #VibeCoding #AutonomousCoding #AI #GenAI #LLM
10 Apr 2025

"We are entering a new era of coding."
Nobel Prize Winner and @GoogleDeepMind CEO Demis Hassabis on coding with natural language.
2
63

31 Mar 2025
"Letting AI autonomously code out your entire project. No micromanaging, just setting the vibe and letting the AI do its thing."
Explore the future of app development with vibe coding and tools like AppLLM from Abacus AI, as discussed in this video by WorldofAI.
WorldofAI YouTube channel: youtube.com/@WorldofAI
This video delves into the concept of vibe coding, its rising popularity, and how AI tools like AppLLM are enabling non-coders to build fully functional apps effortlessly.
#vibecoding #AppLLM #CodeLLM #aiapps #nocodeai #agenticai #AndrejKarpathy #AbacusAI #aidevelopment #beginnerfriendly #autonomouscoding #buildwithai
youtube.com/watch?v=CW1aPily…
1
5
150

10 Jan 2025
An AI Software Engineering Agent that writes code, runs commands, calls APIs, and even browses the web—on autopilot.
And it’s 100% open-source. 🚀
#AIAgent #OpenSource #SoftwareEngineering #AutonomousCoding
3
1
15
1,496