
Send an array of prompts in one call.
The batch endpoint fans them across the network, each running whole on its own node, each with its own Proof-of-Execution.
Many prompts in, many nodes working at once.
api.parallelix.io
#ParalleliX #AI #BatchInference

2
8
57

Apr 8
Batch inference is not just an optimization it’s a necessity.
Modern LLM workloads demand processing massive datasets efficiently. InferScale’s roadmap embraces this with improved batching strategies, aligning with industry trends toward throughput-first systems.
This means better GPU utilization and scalable pipelines for real-world AI applications.
Learn more:
github.com/mbaddar1/InferSca…
#AI #BatchInference #LLM #DataProcessing #MLOps #AIEngineering #Infrastructure #Scaling #Tech
3
97

Most providers offer 50% off on batch inference. Two serverless patterns to actually use it: SQS polling for any provider, EventBridge for Bedrock. - hackernoon.com/batch-inferen… #batchinference #llm
1
2
321

14 Jun 2025
🤖🏗️☸️ 𝘾𝙤𝙣𝙨𝙩𝙧𝙪𝙘𝙩 𝙔𝙤𝙪𝙧 𝙊𝙥𝙚𝙣-𝙎𝙤𝙪𝙧𝙘𝙚 𝘼𝙄 𝘾𝙤𝙢𝙥𝙪𝙩𝙚 𝙎𝙩𝙖𝙘𝙠: 𝙆𝙪𝙗𝙚𝙧𝙣𝙚𝙩𝙚𝙨 𝙍𝙖𝙮 𝙋𝙮𝙏𝙤𝙧𝙘𝙝 𝙫𝙇𝙇𝙈 ☸️🏗️🤖
#for_ai_architects
#for_solutions_architects
#for_cloud_architects
#did_you_know_that the hottest DIY recipe for AI infrastructure is three layers deep-Kubernetes for cluster tenancy, Ray for distributed scheduling, and PyTorch vLLM for model magic?
Today, let's discover how @anyscalecompute calls it the "open-source AI compute stack" and companies like Pinterest, Uber, and Roblox are already cooking with it
🔗 𝙏𝙝𝙚 3-𝙇𝙖𝙮𝙚𝙧 𝘾𝙖𝙠𝙚
1️⃣ Training & Inference (L1) - PyTorch handles autograd model definition; vLLM supercharges GPU memory with PagedAttention for 10× faster token throughput.
2️⃣ Distributed Compute (L2) - Ray Core schedules thousands of tasks, autoscaling pods and moving tensors across GPUs or TPUs with near-linear speed-ups.
3️⃣ Cluster Orchestrator (L3) - Kubernetes (KubeRay) grants multi-tenant isolation, node pooling, and spot/regular mix-then tears it all down with a single kubectl delete.
🚀 𝙒𝙝𝙮 𝙩𝙝𝙞𝙨 𝙨𝙩𝙖𝙘𝙠
(1) Elastic Everything - Ray grows from laptop to 1 K GPUs; K8s node-autoscaler plugs cost leaks on low-traffic days.
(2) Model Velocity - vLLM's on-device KV cache means you serve 20 K tps with a single A100-tested by Ray Serve LLM APIs in v2.44.
(3) Cloud-Agnostic - Same YAML runs on GKE, EKS, AKS, or on-prem OpenShift; Ray abstracts the silicon.
(4) Community Muscle - 28 K GitHub stars on Ray and growing; patches drop weekly across PyTorch & vLLM integrations.
💡 𝙆𝙚𝙮 𝙏𝙖𝙠𝙚𝙖𝙬𝙖𝙮
Kubernetes gives you machines, Ray gives you distributed superpowers, PyTorch gives you the model canvas, and vLLM slams the gas pedal on inference. Glue them together and you've got a cloud-agnostic, wallet-friendly factory for training, fine-tuning, and serving any frontier LLM.
Thanks to @robertnishihara for his blog post:
An Open Source Stack for AI Compute: Kubernetes Ray PyTorch vLLM
lnkd.in/dxNvQshV
📬 Stay tuned!
lnkd.in/eYWBZ5ud
#OpenSourceAI #Kubernetes #Ray #PyTorch #vLLM #LLMStack #AIInfrastructure #KubeRay #DistributedTraining #BatchInference #VertexAI #GKE #GPU #SpotSavings #DevOps #MLOps #favikon #AI #SOTA #artificialintellgence #generativeai #cloud #cloudcomputing #infrastructure #cloudnative

1
4
395

🌟 #DennysPick 🌟
Ever wondered how the folks behind the scenes at @Databricks actually scale generative AI for real-world, massive datasets? That’s exactly what Ankit Mathur (Engineering Lead, AI Serving) and Andrew Shieh (Software Engineer) are going to reveal at #DataAISummit — and trust me, this is the kind of session that turns “impossible” into “I can’t wait to try that!”
We all know generative AI models are powerful, but running them efficiently across millions (or billions) of records? That’s a whole different challenge. Ankit and Andrew have been deep in the trenches, solving these problems at scale, and now they’re ready to share their playbook.
Here’s what you’ll learn:
⚡️How to architect pipelines that push huge volumes of data through LLMs, text-to-image models, and more without blowing your budget
⚡️The secrets to optimizing token usage, prompt engineering, and balancing CPU/GPU resources for maximum efficiency
⚡️Techniques for parallel processing, chunking, and managing model weights and memory so your distributed inference just works
If you want to walk away with strategies you can actually use to make your generative AI workflows faster, cheaper, and more robust, don’t miss this one.
🔗 Check out the full list of my picks: databricks.com/blog/dennys-t…
🗓️ June 9–12
📍 San Francisco
💬 Want 50% off your ticket? Drop a comment with “#DennysPick” and I’ll DM you the code!
#GenerativeAI #LLM #BatchInference #DataAISummit #AIEngineering #Databricks

5
241

2 Oct 2024
Struggling with high-throughput AI workloads? Why settle for less when you can optimize?
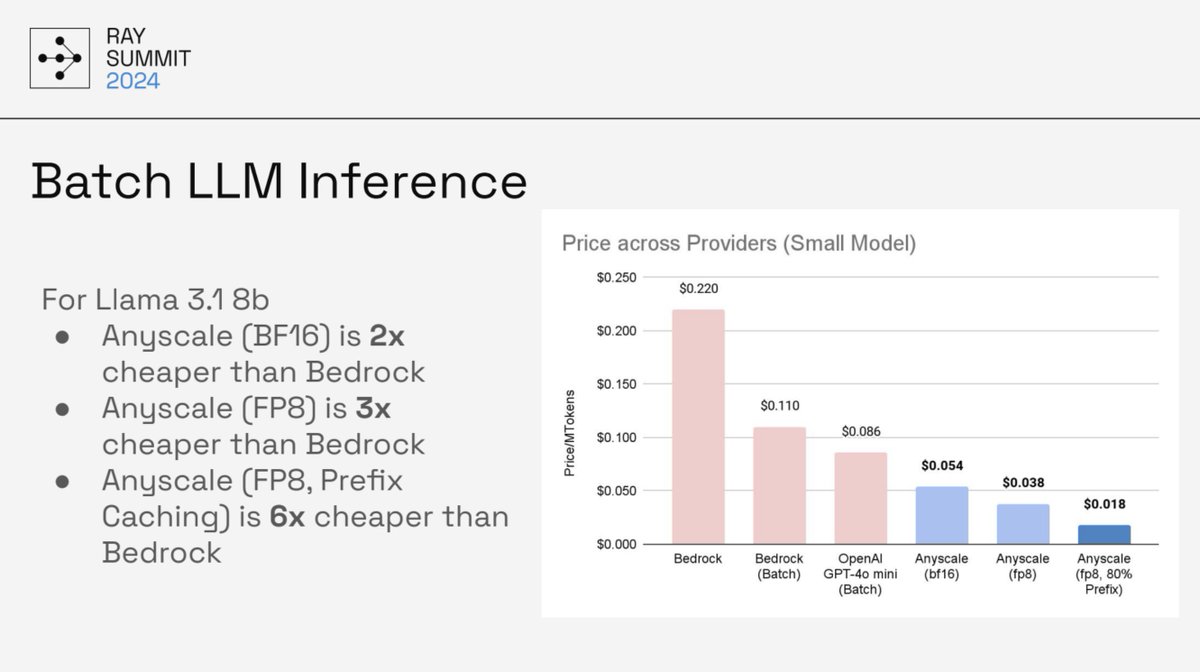
The @anyscalecompute team's last session at #RaySummit2024 dove deep into how Ray Data Anyscale deliver 2x faster batch inference and cut costs by up to 6x with FP8 optimizations.
Ready to supercharge your ML pipeline? 🚀
#AI #BatchInference #RaySummit
2
4
930
1 Oct 2024
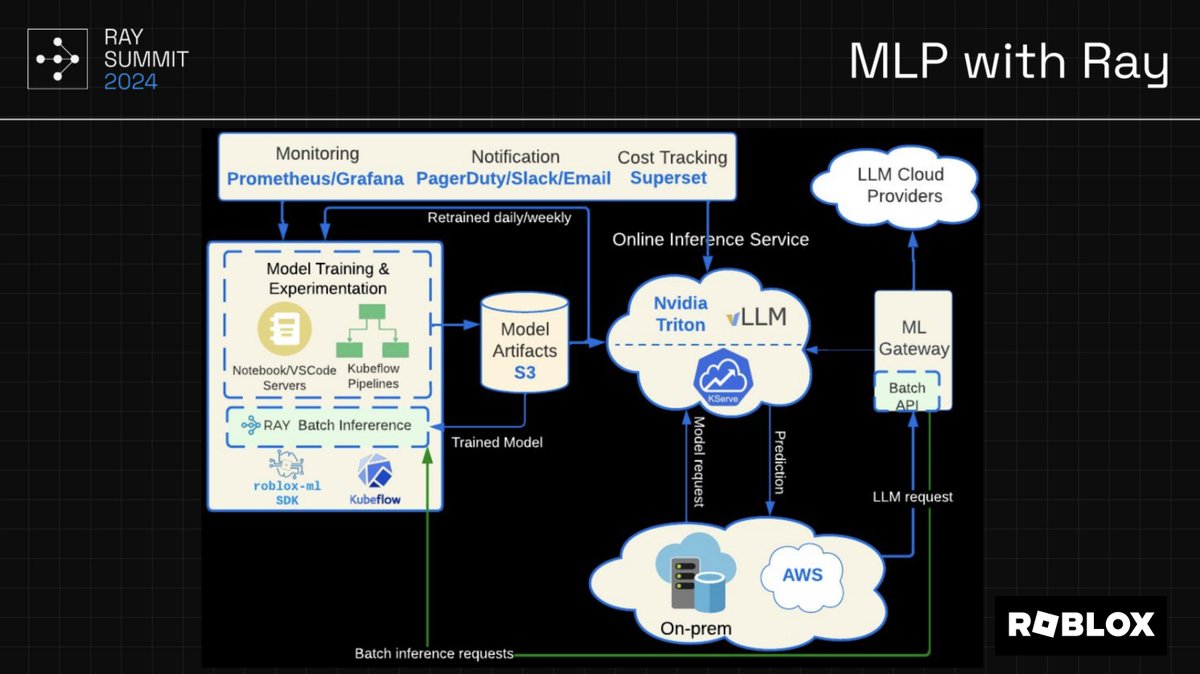
The #RaySummit session on Scaling Machine Learning at @Roblox showcased how Ray is transforming batch inference at scale. 🌟
Key takeaways:
-58% lower costs for image batch inference vs. traditional online inference
-9x faster LLM batch jobs vs. legacy online servers
By moving away from traditional methods like Spark for unstructured data, Ray is driving both performance and cost-efficiency at Roblox. 🚀 Recording coming soon on our YouTube channel—subscribe to get notified: youtube.com/@anyscale
#ML #RaySummit2024 #BatchInference
1
3
799

26 Jan 2023
An exciting blog post on how to unify #realtime and #batchinference with #BentoML and #ApacheSpark!
This approach improves performance, scalability, and cost savings. Check it out at modelserving.com/blog/unifyi… #mlops #modelserving #opensource
3
5
1,764