
Feb 12
📌Dify officially lists the Higress plugin: AI model integration solution.
🌱 Centralize multi-vendor access (text/image gen, embeddings)
🌱 Inherit gateway capabilities: traffic control, auth, monitoring
🌱Protocol support: OpenAI-compatible, Alibaba Cloud Bailian
🌱Works with open-source Higress & cloud-native AI Gateway
🌱Includes Agent & Workflow implementation guides
Learn More: int.alibabacloud.com/m/10004…
#AIGateway #ModelServing #Dify #Higress #AlibabaCloud #CloudComputing #AI #AInnovation #LLM

6
23
11,644

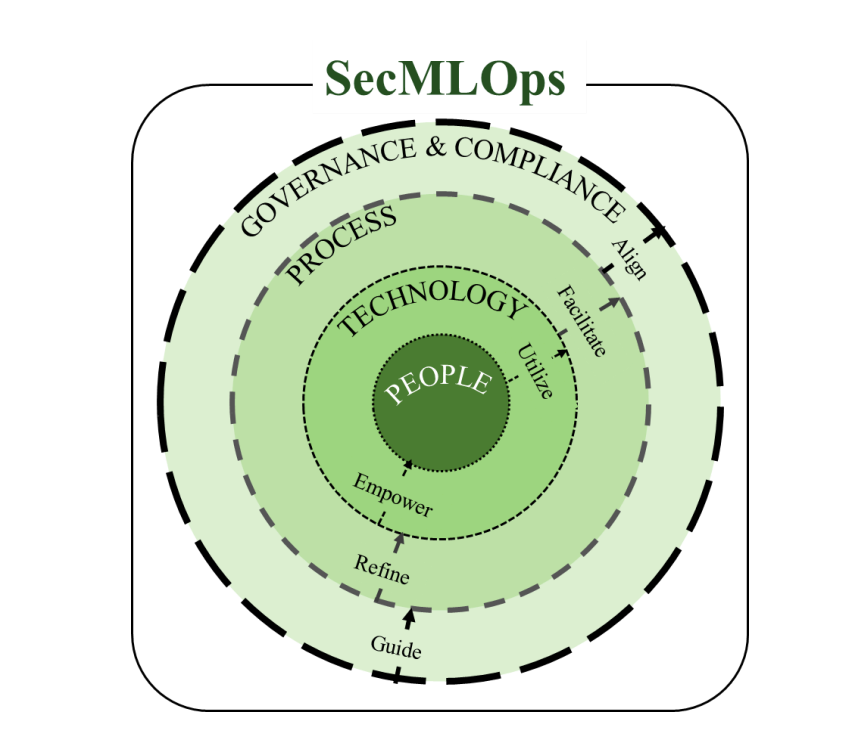
SecMLOps -arxiv.org/pdf/2601.10848
Integrating Security Throughout the Machine Learning Operations Lifecycle
Secure Machine Learning Operations (SecMLOps), providing a comprehensive framework designed to integrate robust security measures throughout the entire ML operations (MLOps) lifecycle.
SecMLOps builds on the principles of MLOps by embedding security considerations from the initial design phase through to deployment and continuous monitoring. This framework is particularly focused on safeguarding against sophisticated attacks that target various stages of the MLOps lifecycle, thereby enhancing the resilience and trustworthiness of ML applications.
With the increasing concerns over ML security risks, the concept of Secure Machine Learning Operations (SecMLOps) was proposed to extend the MLOps with security considerations. This paradigm advocates for the explicit integration of security measures throughout the entire MLOps lifecycle. By embedding security considerations from the outset, SecMLOps aims to cultivate more secure, reliable, and trustworthy ML-based systems.
This holistic security integration not only enhances the resilience of ML deployments but also ensures their alignment with organizational security policies and regulatory requirements, thereby fortifying the foundation of trust and dependability in ML applications across various sectors.
Xinrui Zhang, Pincan Zhao, @JasonJaskolka, @henglli, Rongxing Lu - @Carleton_U, @polymtl, @queensu
#SecMLOps #MLOps #MachineLearningSecurity #AdversarialMachineLearning #AdversarialExamples #DataPoisoning #STRIDE #ThreatModeling #AdversarialTraining #ModelServing #CityPersons #PedestrianDetection
1
21
949

25 Nov 2025
🔥 5090 — The Best Price-to-Performance Inference GPU! Black Friday Special 🔥
Experience data-center–grade performance with the 5090 —
built for safe, stable, dedicated inference at scale.
Original Price: $0.70/h
✨ Black Friday Price: ONLY $0.45/h! ✨
Need high-performance inference?
Deploying large models?
Running real-time AI services?
The 5090 gives you unmatched value and power.
#AI #AIGPU #AICompute #GPUCloud #CloudInference #LLMInference #BlackFridayDeals #BlackFridaySale #ComputeSale #GPUSale #5090GPU #HighPerformanceGPU #HPC #DeepLearning #MachineLearning #NeuralNetworks #AIDeployment #AIPipeline #ModelServing
#AIInfrastructure #ScalableInference #DedicatedCompute #DataCenterGPU #ServerGradeGPU #BestValue #ComputePower #AIStartup #MLOps #AITools #NextGenAI #TechDeals

1
1,035

24 Oct 2025
Just wrapped up an incredible experience at @databricks DevConnect Bangalore, a day full of deep dives, future-ready ideas, and powerful conversations around data & AI!
#Databricks #DevConnect #ModelServing #CostOptimization #DataEngineering #BangaloreTech #AIInfrastructure



2
120

17 Oct 2025
Kicking off a focused deep dive into LLM inferencing - exploring optimization, quantization, and deployment pipelines.
If you’ve read any great papers/blogs/videos or tried interesting frameworks lately, drop them here 👇
#LLM #AI #ML #DeepLearning #MLOps #Inference #GenAI #AIResearch #AIInfra #ModelServing
2
206

29 Sep 2025
🎉 𝗞𝗦𝗲𝗿𝘃𝗲 𝗵𝗮𝘀 𝗯𝗲𝗲𝗻 𝗮𝗰𝗰𝗲𝗽𝘁𝗲𝗱 𝗮𝘀 𝗮 𝗖𝗡𝗖𝗙 𝗜𝗻𝗰𝘂𝗯𝗮𝘁𝗶𝗻𝗴 𝗣𝗿𝗼𝗷𝗲𝗰𝘁! 🚀
Just a short time ago, we shared that our application was under public comment. Now, the vote has officially passed and KServe is joining the @CloudNativeFdn as an incubating project.
This is a major milestone for the community and a big step forward for cloud-native model serving.
🙌 Huge thanks to everyone who contributed to this journey from writing code, reviewing docs, to supporting governance and community growth.
Stay tuned! We’ll be publishing a detailed announcement blog soon with more insights on what this means for users, contributors, and the future of model serving on @kubernetesio.
For now: thank you to the community for making this possible. 💙
#KServe #CNCF #OpenSource #ModelServing #AI #MLOps #CloudNative #Kubeflow #Kubernetes #k8s @kubeflow
1
5
31
2,592
9 Sep 2025
🚀 𝗠𝗮𝗷𝗼𝗿 𝗨𝗽𝗱𝗮𝘁𝗲 𝗳𝗼𝗿 𝗞𝗦𝗲𝗿𝘃𝗲! 🚀
We’ve officially taken the next step toward joining the 𝗖𝗡𝗖𝗙 𝗮𝘀 𝗮𝗻 𝗜𝗻𝗰𝘂𝗯𝗮𝘁𝗶𝗼𝗻 𝗣𝗿𝗼𝗷𝗲𝗰𝘁! 🎉
The CNCF TOCs have completed due diligence and are now sponsoring our application. The process is entering the 𝗽𝘂𝗯𝗹𝗶𝗰 𝗰𝗼𝗺𝗺𝗲𝗻𝘁 𝗽𝗲𝗿𝗶𝗼𝗱 (2 weeks) before moving to a formal TOC vote.
Application: github.com/cncf/toc/issues/1…
Due Diligence doc: github.com/cncf/toc/pull/186…
A huge thank you to @kevinwzf0126 and @FaseelaDilshan from the CNCF TOC for all the hard work. It’s been such a pleasure collaborating with you both on this milestone. Thank you to all the community members who have contributed!
This is a big step for the KServe community, and we’re excited about the road ahead in making cloud-native model serving more accessible and production-ready for everyone.
#KServe #CNCF #OpenSource #ModelServing #AI #MLOps #CloudNative @CloudNativeFdn @kubernetesio @kubeflow
1
6
27
2,807
Detecting Exposed LLM Servers: A Shodan Case Study on Ollama - blogs.cisco.com/security/det… by @TalosSecurity
This work investigates the prevalence and security posture of publicly accessible LLM servers, with a focus on instances utilizing the Ollama framework, which has gained popularity for its ease of use and local deployment capabilities. While Ollama enables flexible experimentation and local model execution, its deployment defaults and documentation do not explicitly emphasize security best practices, making it a compelling target for analysis.
#AISecurity #LLMSecurity #Ollama #Shodan #AttackSurfaceManagement #APISecurity #MLOps #DevSecOps #ModelServing #CloudSecurity
2
13
380

State of the Model Serving Communities - August 2025
inferenceops.substack.com/p/…
#OpenSource #Kubernetes #AI #Inference #ModelServing #RedHat
1
3
153

18 Jul 2025
🚀Excited to see our collaboration with @lmsysorg bring Multiple Token Prediction (MTP) in SGLang to production!
Proud to support faster, smarter open-source LLM serving. #EigenAl #MTP #SGLang #LLMinfra #ModelServing #DeepSeek #OpenSourceAl #AskChatGPT

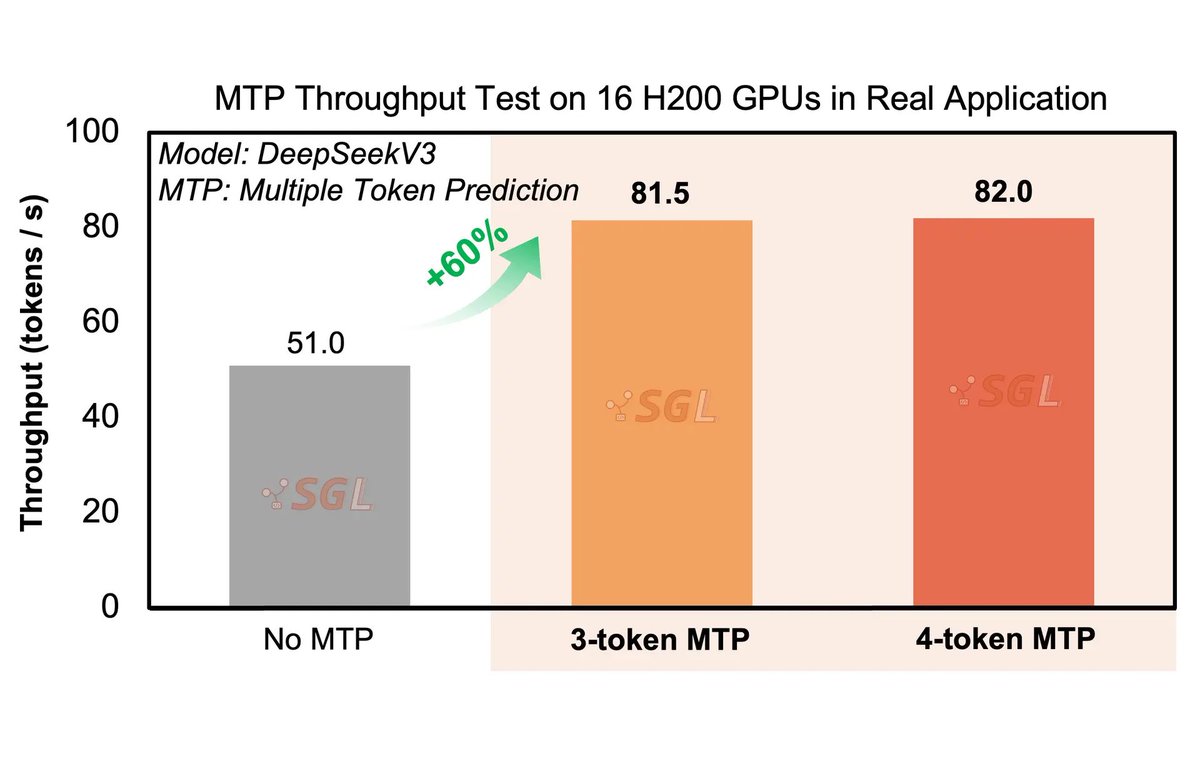
🚀 Summer Fest Day 5: Multiple Token Prediction in SGLang by @Eigen_AI_ and SGLang Team
1.6× throughput, same quality — open-source & production-ready!
We’ve integrated MTP into SGLang, unlocking up to 60% higher output throughput for models like DeepSeek V3, with zero quality trade-offs.
Key highlights:
- Plug-and-play MTP for any SGLang-served LLM
- Works with Expert Parallelism, PD disaggregation & CUDA Graph
- Draft-then-verify decoding with full model consistency
- 1.6× boost in small clusters, 14% at scale
- Easy tuning via draft_token_num; monitor acceptance length for max gains
Serving LLMs at scale? Don’t leave performance on the table👇 #SGLang #MTP #LLMInfra #ModelServing #DeepSeek #OpenSourceAI #AIInfrastructure #EigenAI
4
10
1,795

🚀 Summer Fest Day 5: Multiple Token Prediction in SGLang by @Eigen_AI_ and SGLang Team
1.6× throughput, same quality — open-source & production-ready!
We’ve integrated MTP into SGLang, unlocking up to 60% higher output throughput for models like DeepSeek V3, with zero quality trade-offs.
Key highlights:
- Plug-and-play MTP for any SGLang-served LLM
- Works with Expert Parallelism, PD disaggregation & CUDA Graph
- Draft-then-verify decoding with full model consistency
- 1.6× boost in small clusters, 14% at scale
- Easy tuning via draft_token_num; monitor acceptance length for max gains
Serving LLMs at scale? Don’t leave performance on the table👇 #SGLang #MTP #LLMInfra #ModelServing #DeepSeek #OpenSourceAI #AIInfrastructure #EigenAI
3
8
33
5,666
🚀Summer Fest Day 3: Cost-Effective MoE Inference on CPU from Intel PyTorch team
Deploying 671B DeepSeek R1 with zero GPUs? SGLang now supports high-performance CPU-only inference on Intel Xeon 6—enabling billion-scale MoE models like DeepSeek to run on commodity CPU servers.
Key highlights:
1. Full CPU backend for SGLang with Intel AMX
2. Native BF16 / INT8 / FP8 support for both Dense and Sparse FFNs
3. 6–14× TTFT and 2–4× TPOT speedup vs. llama.cpp
4. 85% memory bandwidth efficiency with optimized MoE kernels
5. Flash Attention V2 MLA MoE all optimized for CPU
6. Multi-NUMA parallelism mapped from GPU-style Tensor Parallelism
This work is now fully upstreamed to SGLang main—read how we achieved it, and how far you can go without a GPU 👇
#LLMInfra #ModelServing #MoE #Xeon6 #SGLang #FP8 #INT8 #CPUInference

6
15
38
19,174
🚨Day 1: OME blog from the Oracle team
OME (Open Model Engine) redefines LLM deployment infrastructure with a model-driven architecture.
No more complex YAMLs or deployment guesswork—OME treats models as first-class Kubernetes resources, enabling:
• Multi-node multi-phase serving
• Decode/prefill disaggregation
• Serverless autoscaling via tokens/sec or KV cache
• One-line deployment for billion-scale models
See how OCI GenAI teams cut model onboarding from months to days 👇
#LLMInfra #MLOps #Kubernetes #ModelServing #OCI #SGLang

SGLang Summer Fest kicks off! 🤗From July 7–18, we’re dropping a series of deep-dive blogs on all things SGLang and its fast-growing ecosystem — from blazing-fast inference to production deployment, RL integration & beyond. Don’t miss a post! Follow & RT to join the fest!
2
5
31
12,489

24 Apr 2025
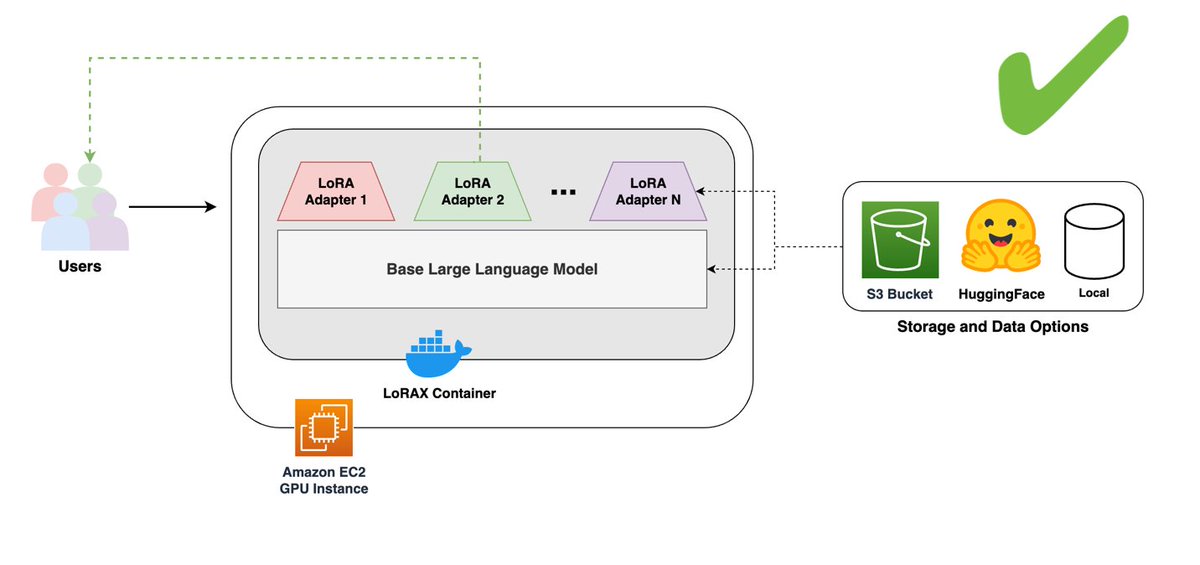
🚀 Introducing #LoRAX: Efficient Multi-LoRA Serving on Amazon Web Services (AWS)!
Discover how LoRAX, our #OpenSource inference software, enables concurrent serving of multiple #LoRA adapters on a single LLM instance with this new blog from our partners at AWS.
𝐖𝐡𝐲 𝐝𝐨𝐞𝐬 𝐭𝐡𝐢𝐬 𝐦𝐚𝐭𝐭𝐞𝐫?
Using LoRAX on AWS significantly reduces your infra costs and improves scalability for #GenAI applications.
𝐇𝐢𝐠𝐡𝐥𝐢𝐠𝐡𝐭𝐬 𝐟𝐫𝐨𝐦 𝐭𝐡𝐞 𝐛𝐥𝐨𝐠:
🔄 Dynamic #Adapter Swapping: Serve 100s of fine-tuned models without the need for separate instances.
💰 Cost #Efficiency: Reduce hosting costs by up to 80% by consolidating model serving.
✈️ Simplified Deployment: Utilize AWS and Predibase for streamlined model and adapter management.
Learn how LoRAX can transform your AI infrastructure with AWS: aws.amazon.com/blogs/machine…
#OpenSource #MLOps #ModelServing

2
4
354
22 Apr 2025
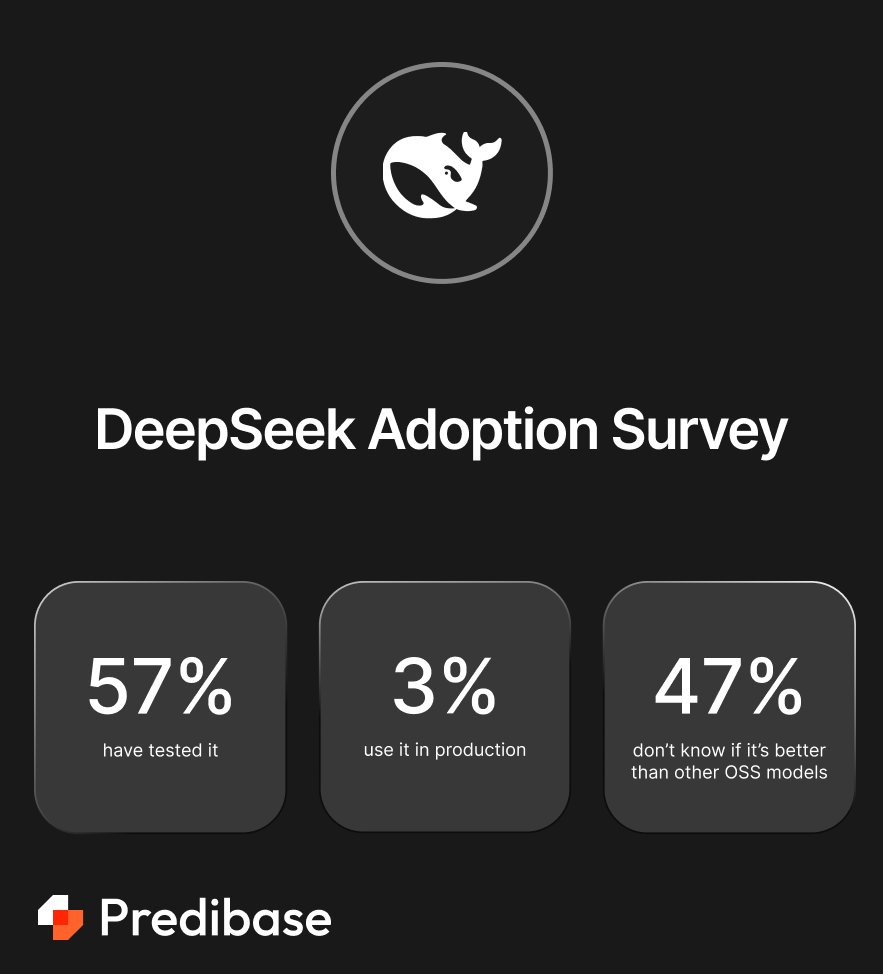
🧨 DeepSeek is everywhere—except in production.
Let’s be real: every AI team’s poked at DeepSeek-R1. But almost no one’s using it for real work. We surveyed 500 AI professionals and found:
📊 57% have tested it
😬 3% have deployed it
🤷 47% still don’t know if it’s better than other models
It’s the classic GenAI problem:
💡 Big promise
🧱 Bigger friction
⏳ Still waiting on proof
And yet...
🔧 46% of teams want to customize it with LoRA or distill it down
💼 Most traction? Specialized use cases (not chatbots, sorry)
The bottom line:
Teams want to believe in DeepSeek. But without benchmarks or tools to make it usable, they’re stuck guessing.
Wanna be the team that figures it out first?
👇 Fine-tune it. Deploy it. Own it. Free trial at Predibase.
#LLMs #OpenSourceAI #DeepSeek #InfraMatters #InferenceStack #GenAI #LoRA #Distillation #MLOps #ModelServing #Predibase
1
5
295

17 Apr 2025
Did you about about some @OpenledgerHQ
Use case?? Lets discuss some of them.
Do you Want to deploy multiple AI models without melting your GPU budget????? Enter OpenLora by OpenLedger: a scalable framework that lets you serve thousands of fine tuned models ,all on a single GPU! Serious gains for devs & AI startups. #AI #OpenLora #OpenLedger
💡 Imagine spinning up a whole army of customizable AI assistants each with their own personality, skills, or domain focus without spinning up a whole fleet of servers. That’s the LoRA adapters magic! #AIassistants #LoRA
💸 Cloud costs bleeding you dry? OpenLora is a cost-effective solution,efficient memory usage means less hardware, smaller bills, and way more scale. Get enterprise level AI serving on a startup budget! #AICosts #CloudComputing
Personalization FTW! With OpenLora, users can fine tune their own adapters and deploy models tailored to their unique needs think bespoke chatbots ,custom code assistants, or industry specific NLP tools. #FineTuning #PersonalizedAI
🤖 Devs, this is for you: OpenLora isn’t just about scale, it’s about flexibility. Deploy, update, and manage specialized models (in chat, code, or any NLP task) without the heavy infra overhead. #AIForDevelopers #ModelServing
TL;DR: OpenLora from OpenLedger = scalable, personalized, affordable AI model deployment. Perfect for companies, startups, and devs who want to do more with less. Dive into the details: [openledger.gitbook.io/openle…](openledger.gitbook.io/openle…) 🌐✨

3
4
72

16 Nov 2024
Awesome Production Machine Learning curates production-ready ML tools across the entire ML lifecycle.
It covers crucial MLOps components - from model serving to monitoring infrastructure.
The repo is particularly strong in documenting tools for deployment pipelines, feature stores, and model monitoring solutions.
You'll find battle-tested frameworks for distributed training, model versioning, and security hardening.
Think of it as your technical compass for building enterprise ML systems.
Most tools listed support RESTful APIs and container-based deployments, perfect for microservices architectures.
github: /EthicalML/awesome-production-machine-learning
#MLOps #MachineLearning #DevOps #ModelServing #FeatureStore #ModelMonitoring #DataEngineering #ProductionML
1
2
167
13 Nov 2024
Awesome LLMOps is a well-organized knowledge base covering the entire ML lifecycle, from model training to production deployment.
The repo acts as a curated index of tools spanning model serving, security, observability, and distributed training frameworks.
It focuses on production-grade LLM infrastructure - think vector DBs, model quantization, and serving optimizations.
github: /tensorchord/Awesome-LLMOps
#LLMOps #MLOps #AI #MachineLearning #DevOps #ProductionML #ModelServing
3
101
12 Nov 2024
This is a curated knowledge base for LLM resources, organizing content across critical ML engineering domains like data processing, fine-tuning, inference, and RAG architectures.
Key aspects:
- Structured sections for MLOps lifecycle stages
- Focus on production-ready tools for data preparation and model deployment
- RAG and agent implementation patterns
- Evaluation frameworks and metrics
- Integration examples with popular LLM APIs
It also has a comprehensive coverage of data processing pipelines (via tools like data-juicer) and detailed fine-tuning approaches. The repository emphasizes practical engineering over theory.
github: /WangRongsheng/awesome-LLM-resourses
#MachineLearning #LLM #MLOps #RAG #DataEngineering #ModelServing #FineTuning
3
193

7 Nov 2024
🌟 Mastering Generative AI: Building and Serving Models with Databricks 🌟
Join @learnwithabi from @databricks to discover how to harness Databricks for developing, deploying, and serving powerful Generative AI models. This session will guide you through streamlining machine learning workflows with Databricks Model Serving, leveraging scalable infrastructure for model training, and using MLflow to manage and deploy models at scale. Perfect for those focused on natural language generation, synthetic data, or AI-driven content, this talk will equip you with practical insights to bring AI solutions to production seamlessly.
Register Now: techxconf.com
#TechXConf #GenerativeAI #Databricks #ModelServing #MachineLearning #AIProduction #MLflow #TechXConf2024

1
4
89