
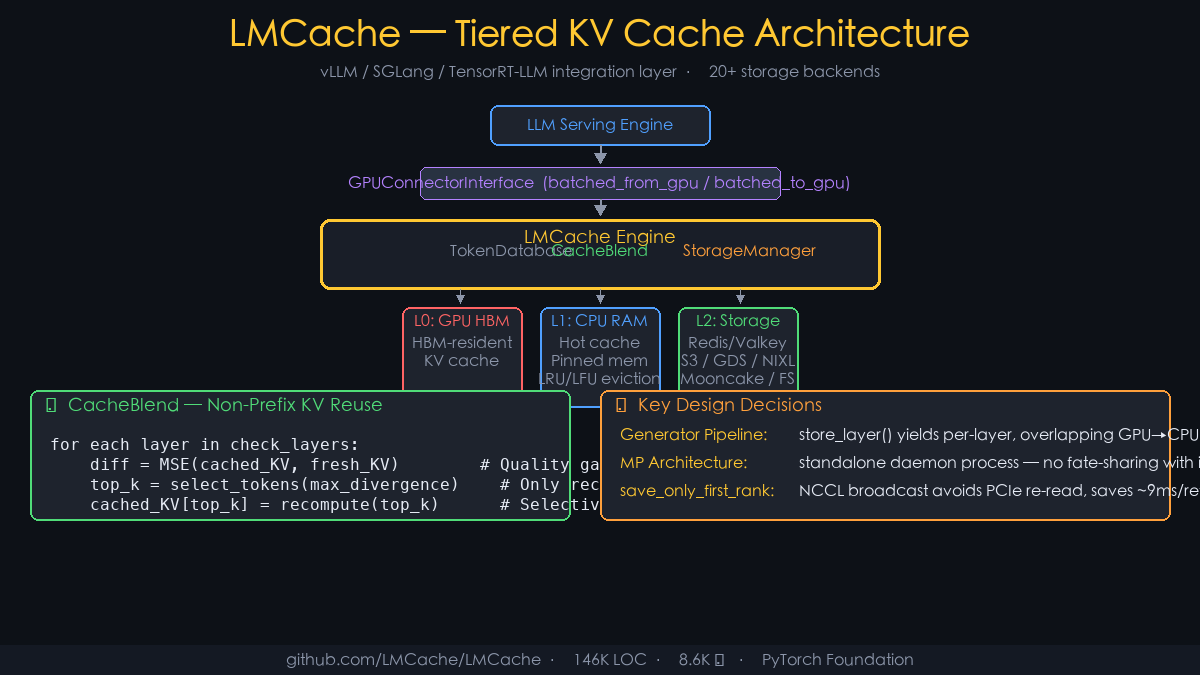
LMCache (8.6k⭐): KV cache layer for LLM inference. Integrates with vLLM/SGLang/TRT-LLM and 20 storage backends.\n\nArch insight: CacheBlend reuses KV at any position, not just prefix. MSE quality-check on key layers, only recomputes diverged tokens. github.com/LMCache/LMCache
1
37

Jun 12
KV cache本质上是LLM的“记忆”,但业界一直当临时缓冲区用完就扔,每个新请求都得重新prefill一遍,太浪费了。LMCache把这个层独立成守护进程,和推理引擎解耦,让KV cache变成可跨请求、跨会话甚至跨引擎持久复用的资源。实现上靠的是分层存储抽象:GPU放热数据,CPU做缓存,SSD和远端做冷存,再加上CacheBlend机制做非前缀匹配,能把重复计算砍掉一大截。长上下文和agent场景下,TTFT显著下降,这种架构设计才是推理系统走向规模化的正确方向。
github.com/LMCache/LMCache
2
9
67
3,783

Jun 4
テキストやベクトル埋め込み(Dense Embedding)を検索する従来のRAGから、「LLMの計算済みKVキャッシュ自体を外部のデータベース(あるいは分散ストレージ)にプールして検索・結合する」というパラダイムシフトが起きており、2025年から2026年にかけて爆発的に研究と実装が進んでいます。
このアプローチは、業界では主に Cache-Augmented Generation (CAG) や Disaggregated KV Cache(分離型KVキャッシュ) と呼ばれています。代表的な研究やアーキテクチャの動向をいくつか紹介します。
1. 外部KVキャッシュの検索と結合: LMCache / CacheBlend
従来のRAGは「検索したテキスト」をLLMのプロンプトに挿入し、そこからAttention(KV)を再計算するため、Time to First Token (TTFT) に大きなレイテンシが発生します。
これに対し、UC Berkeleyなどを中心とした研究(LMCache や CacheBlend 等)では、様々なドキュメントの「計算済みKVキャッシュ」を外部に保存し、検索クエリに応じて必要なKVキャッシュのチャンクを動的に取得・マージ(Knowledge Fusion)してLLMにロードする技術を実装しています。 これはもはや単なるキャッシュではなく、「知識そのものをKVテンソルの状態で蓄積・配信するネットワーク(Knowledge Delivery Network: KDN)」という概念に昇華されており、エンタープライズ向けの超高速な検索エンジンとしての応用が進んでいます。
2. トークン生成ごとの動的KV検索: ParisKV / FreeKV (2026年最新)
コンテキスト長が数百万トークン規模になると、KVキャッシュそのものがGPUメモリに収まらなくなります。そこで「巨大なKVキャッシュを外部(CPUメモリやNVMe、S3等のオブジェクトストレージ)に追い出し、推論のたびに必要な部分だけを検索(Retrieval)する」アプローチが急速に立ち上がっています。
ParisKV (2026年5月発表): 長文脈LLMにおいて、外部に退避させた膨大なKVキャッシュから、デコードの各ステップ(トークン生成)ごとに必要なTop-kのKVエントリをオンデマンドで高速に検索・取得するアーキテクチャです。
FreeKV (2026年2月発表): KVキャッシュの検索が推論のボトルネックにならないよう、投機的検索(Speculative Retrieval)を用いて先回りして必要なKVキャッシュを外部からフェッチする仕組みを提案しています。
3. 分散インフラとしてのKVルーティング (vLLM / llm-d)
研究段階だけでなく、プロダクション環境でも動きがあります。vLLMのような推論サーバーのクラスタリングにおいて、特定のノードに計算済みのKVキャッシュ(Prefix)が存在するかをリアルタイムにトラッキングする仕組み(llm-d など)が登場しています。 これは実質的に、「クラスター全体をひとつの巨大なKVキャッシュ・データベースとして扱い、最も関連するキャッシュを持つノードにリクエストをルーティングする」という巨大な検索・ルーティングエンジンとして機能しています。
1
4
933

May 6
𝐂𝐨𝐦𝐦𝐮𝐧𝐢𝐭𝐲 𝐡𝐞𝐥𝐩 𝐰𝐚𝐧𝐭𝐞𝐝: 𝐇𝐞𝐥𝐩 𝐮𝐬 𝐛𝐮𝐢𝐥𝐝 𝐋𝐌𝐂𝐚𝐜𝐡𝐞 𝐑𝐞𝐜𝐢𝐩𝐞𝐬! 🧑🍳
LMCache supports many model families, including Llama, Qwen, DeepSeek, and more. But compatibility is not just about the model name. It also depends on the architecture, serving engine, and LMCache functionality being used, such as CacheBlend or KV cache compression.
That’s why we’re building 𝐋𝐌𝐂𝐚𝐜𝐡𝐞 𝐑𝐞𝐜𝐢𝐩𝐞𝐬: a practical compatibility guide for open-source models and architectures.
For each architecture, we want to make it easier for developers to understand how to launch it with LMCache, which serving engines are supported, which LMCache functionality has been validated, and what limitations or known issues remain.
Even adding “not supported” is a contribution :)
📖 Check out the current recipes here:
docs.lmcache.ai/recipes/inde…
🛠️ Ready to contribute? Open a PR directly to our repo here:
github.com/LMCache/LMCache
#LMCache #inference #KVCache #AI

1
6
268
May 5
Semantic caching works at the service layer, but not every product wants to reuse final answers.
The lower-level approach is KV cache reuse: cache the model computation behind the response, not the response itself. LMCache helps avoid recomputing repeated context, and CacheBlend extends this beyond exact prefix matches by reusing shared chunks even when they appear in different positions.
The result is fresher user-facing responses with less redundant prefill underneath: a more fine-grained way to reduce inference cost at the infrastructure layer.
3
76

May 5
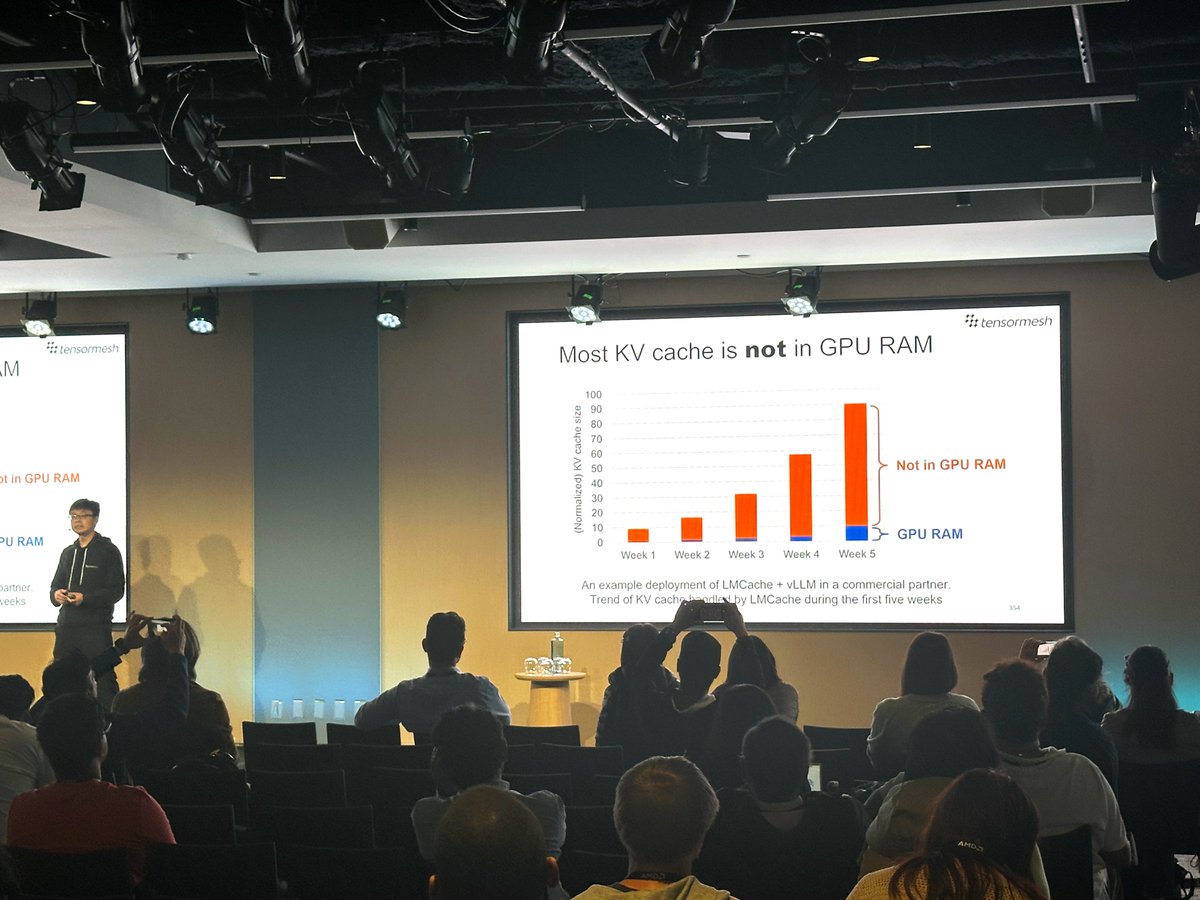
Tensormesh @ #AMD AI DevDay
Great turnout for @JunchenJiang ’s talk on KV Cache as new memory layer for AI. Agents don’t need more compute, just context.
Taking KV Cache from research to production with features like compression CacheBlend.
Thanks @AIatAMD for the invite🤝


1
11
576
Apr 1
📖 New blog alert!!!
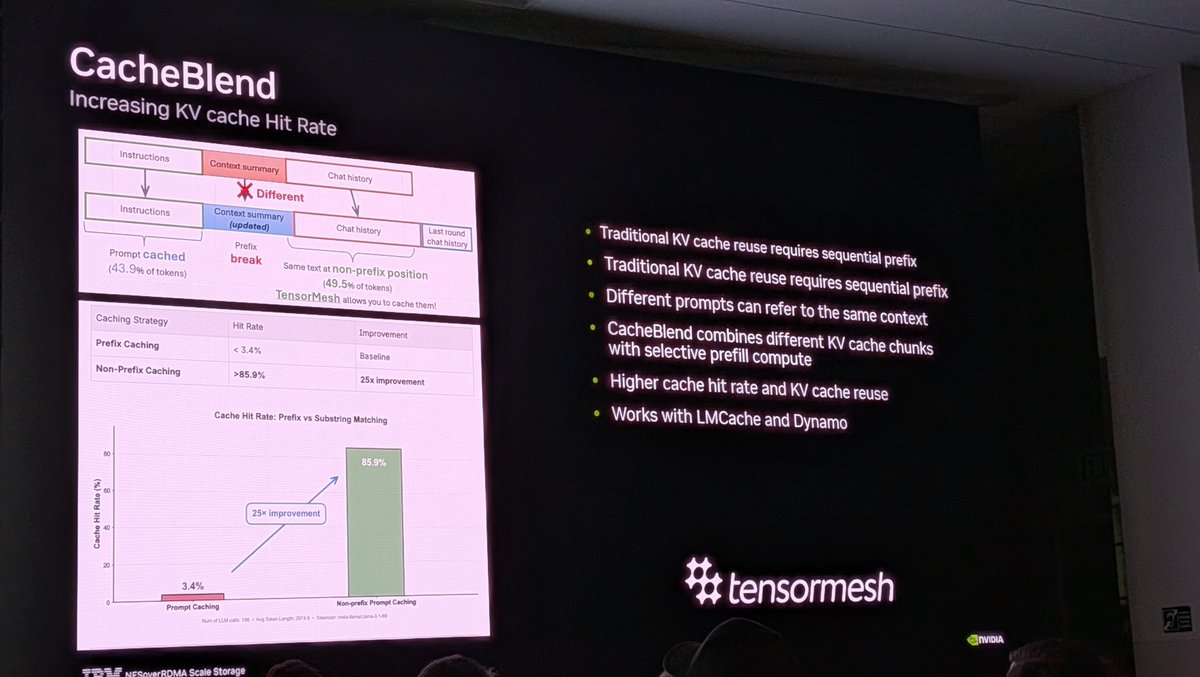
𝗡𝗼𝗻-𝗽𝗿𝗲𝗳𝗶𝘅 𝗰𝗼𝗻𝘁𝗲𝘅𝘁 𝗞𝗩 𝗖𝗮𝗰𝗵𝗶𝗻𝗴 𝗶𝗻 𝗢𝗽𝗲𝗻𝗰𝗹𝗮𝘄 --- 𝘄𝗶𝘁𝗵 𝗖𝗮𝗰𝗵𝗲𝗕𝗹𝗲𝗻𝗱.
KV Cache so far is reused 𝗼𝗻𝗹𝘆 at 𝗽𝗿𝗲𝗳𝗶𝘅𝗲𝘀, but in OpenClaw and similar agent harnesses, reused context do 𝗡𝗢𝗧 always appear as prefix.
⚠️ Retrieved context changes,
⚠️ Tool outputs move around, and
⚠️ Even small prompt shifts
can 𝘄𝗶𝗽𝗲 𝗼𝘂𝘁 𝘁𝗵𝗲 𝗯𝗲𝗻𝗲𝗳𝗶𝘁 𝗼𝗳 𝗽𝗿𝗲𝗳𝗶𝘅 𝗰𝗮𝗰𝗵𝗶𝗻𝗴.
𝗥𝗲𝗮𝗱 𝘁𝗵𝗲 𝗯𝗹𝗼𝗴: 𝗔𝗰𝗰𝗲𝗹𝗲𝗿𝗮𝘁𝗶𝗻𝗴 𝗢𝗽𝗲𝗻𝗖𝗹𝗮𝘄 𝗔𝗴𝗲𝗻𝘁𝘀 𝘄𝗶𝘁𝗵 𝗖𝗮𝗰𝗵𝗲𝗕𝗹𝗲𝗻𝗱
blog.lmcache.ai/en/2026/04/0…
We look at 𝗖𝗮𝗰𝗵𝗲𝗕𝗹𝗲𝗻𝗱, a method for 𝗻𝗼𝗻-𝗽𝗿𝗲𝗳𝗶𝘅 𝗞𝗩 𝗰𝗮𝗰𝗵𝗲 𝗿𝗲𝘂𝘀𝗲, and how it helps recover lost reuses in multi-turn OpenClaw. Our demo cuts agent response delay 𝗯𝘆 𝟰𝟮%.
We are working making CacheBlend easier to deploy in OpenClaw. Stay tune! 🔜
Read it and drop your thoughts in the comments. We'd love to hear from the community 👇
#OpenClaw #AI #AgenticAI #LMCache #KVCache
2
7
1,598
Mar 25
"𝗜𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 𝗰𝗼𝗻𝘁𝗲𝘅𝘁 𝗶𝘀 𝘁𝗵𝗲 𝗻𝗲𝘄 𝗯𝗼𝘁𝘁𝗹𝗲𝗻𝗲𝗰𝗸" — Kevin Deierling, SVP Networking #NVIDIA
At his #GTC talk last week, he highlighted 𝗖𝗠𝗫 and 𝗖𝗮𝗰𝗵𝗲𝗕𝗹𝗲𝗻𝗱 from 𝗟𝗠𝗖𝗮𝗰𝗵𝗲 (@tensormesh) were part of the new KV Cache memory stack for agents, and recognized @tensormesh among the 𝗖𝗠𝗫 𝘀𝘁𝗼𝗿𝗮𝗴𝗲 𝗽𝗮𝗿𝘁𝗻𝗲𝗿𝘀.
As the stack evolves, @tensormesh keeps building for what's next.
▶️ session Replay:
tinyurl.com/GTC-talk


3
9
568
Mar 17
🔴 Live from #GTC2026
On the floor with our Chief Scientist @this_will_echo and CTO #Yihua Chang — #KVCache is the hottest topic of the day. Even Jensen opened with it.
🎙️They covered topics like:
#CacheBlend, @lmcache 0.4.0. and the super cool collab with @nvidia around a bot called #reachy using LMCache under the hood for 20x speedup
#GTC2026 #KVCache #LMCache #TensorMesh
3
14
463

Mar 6
Today I was exploring how to optimize Gemma 3 inference on Vertex AI.
I found LMCache.
It enhances vLLM, giving you 7x faster access to 100x more KV caches and reducing TTFT by 3–10x for multi-turn agents and long-context RAG.
It has two concepts: CacheGen and CacheBlend.
CacheGen encodes KV caches into bitstreams and stores them on cheap disks. You can now share unlimited KV caches across multiple vLLM instances in your cluster.
CacheBlend dynamically blends multiple KV caches to form a new KV cache. Minimal computation. Cross-attention preserved. You are no longer restricted to just prefix reuse.
Your LLM reads a popular document or chat history exactly once. Any other serving instance can instantly reuse that computed state.
Best of all, it acts as a drop-in replacement with the lmcache_vllm wrapper.
Repo: github.com/LMCache/LMCache
4
197
Feb 11
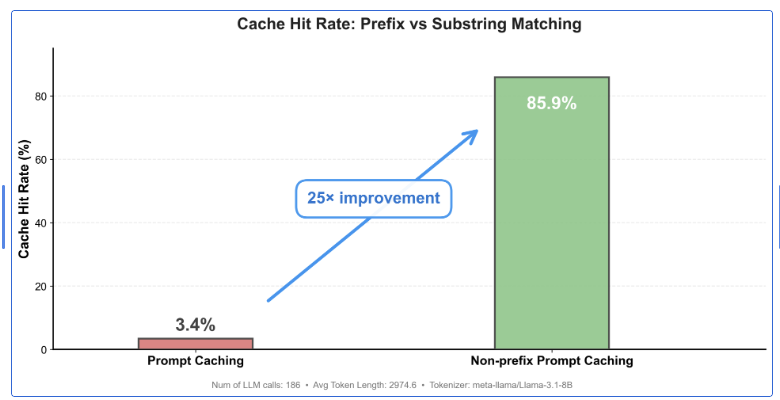
We analyzed RepoAgent's prompt caching and found a 25x gap between theory and reality.
Hit rate: 3.4% Reusable content: 85.9%
The problem? Prefix caching breaks when variables shift token positions, even when content is identical.
Non-prefix caching (CacheBlend) closes that gap.
Full breakdown: tensormesh.ai/blog-posts/blo…
4
83

16 Sep 2025
My writing on LMCache techniques:
- 𝐂𝐚𝐜𝐡𝐞𝐆𝐞𝐧 - How to quickly transfer KV cache to GPU memory .
- 𝐂𝐚𝐜𝐡𝐞𝐁𝐥𝐞𝐧𝐝 - How to quickly combine multiple KV caches on demand .
@lmcache @JunchenJiang
LMCache github: github.com/LMCache/LMCache

1
1
4
81


2 Jul 2025
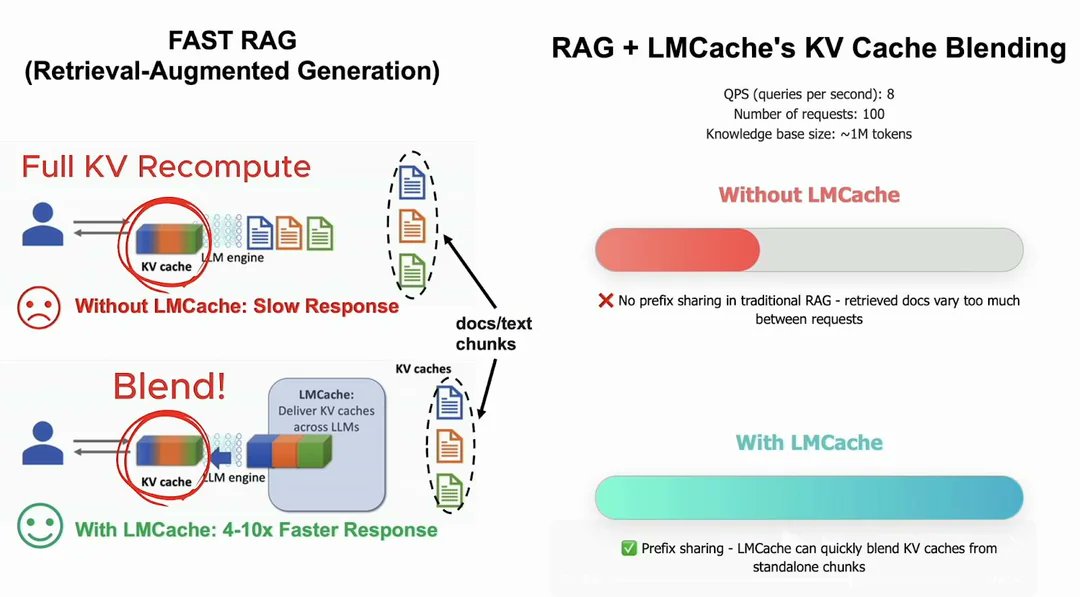
LMCache 又弄了个新优化, 能将RAG 速度提升 3 倍
做法也是极其简单但有效,在RAG系统中,从数据库或者接口中检索出来的数据,在一个任务中是会复用的,但是每次显卡缓存全都要被冲刷掉重新计算。于是这个叫做 CacheBlend 的新的优化,会将 KV Cache 全部缓存起来,即使 KVCache 对应的内容出现在 prompt 的任何部分,这个新的方法也能检测到,从而复用片段的 KVCache。来起到加速的效果
项目地址:github.com/LMCache/LMCache
6
13
108
9,621
9 May 2025
🚀𝗠𝗼𝗼𝗻𝗰𝗮𝗰𝗸𝗲 X 𝗟𝗠𝗖𝗮𝗰𝗵𝗲: KV Cache-centric Language Model Serving 🚀
We're thrilled to announce a strategic collaboration between LMCache and Mooncake to pioneer a KVCache-centric Large Language Model (LLM) serving system! This partnership is set to redefine efficiency, scalability, and responsiveness for LLM applications.
By uniting LMCache's cutting-edge KVCache management with Mooncake's robust and optimized backend infrastructure, we're unlocking new levels of performance for handling diverse LLM workloads. 𝗟𝗠𝗖𝗮𝗰𝗵𝗲 will serve as the 𝗰𝗼𝗻𝗻𝗲𝗰𝘁𝗼𝗿 between 𝗠𝗼𝗼𝗻𝗰𝗮𝗸𝗲 and 𝘃𝗟𝗟𝗠 to enable more cross-layer optimizations in LLM serving.
✨ 𝗪𝗵𝗮𝘁 𝘁𝗵𝗶𝘀 𝗺𝗲𝗮𝗻𝘀:
For LMCache users: Leverage Mooncake's advanced transfer engine and KVCache storage for significantly boosted data distribution and system performance.
For Mooncake users: Benefit from LMCache as the KVCache management layer, enabling flexible cache control and exciting future capabilities like CacheBlend.
📈 𝗣𝗿𝗼𝗼𝗳 𝗶𝗻 𝗣𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲:
Our joint integration with vLLM (LMCache Mooncake Store) has shown remarkable results on a Qwen2.5-72B-Instruct model (8xH800 GPUs):
⬇️ ~69% reduction in Average Time To First Token (TTFT)
⬆️ ~191% increase in Request Throughput
⬆️ ~185% increase in Output Token Throughput
...all thanks to efficient KVCache reuse!
For full results, please refer to our blog post: blog.lmcache.ai/2025-05-08-m…
🔮 𝗧𝗵𝗲 𝗙𝘂𝘁𝘂𝗿𝗲 𝗶𝘀 𝗕𝗿𝗶𝗴𝗵𝘁:
We're already collaborating on next-gen improvements, including optimized KVCache eviction/placement, asynchronous scheduling, zero-copy transfers, and more flexible caching strategies.
This is a significant step towards realizing the full potential of next-generation LLM serving architectures. Stay tuned for more updates!
𝗟𝗲𝗮𝗿𝗻 𝗠𝗼𝗿𝗲 & 𝗖𝗼𝗻𝗻𝗲𝗰𝘁: 👇
LMCache GitHub: github.com/LMCache/LMCache
Mooncake Github: github.com/kvcache-ai/Moonca…
vLLM Production Stack: github.com/vllm-project/prod…
LMCache Slack Space: join.slack.com/t/lmcachework…
#LLMs #AIServing #KVCache #OpenSource #TechCollaboration #LMCache #Mooncake #PerformanceOptimization #MachineLearning #AIInfrastructure #Innovation

1
10
22
1,567

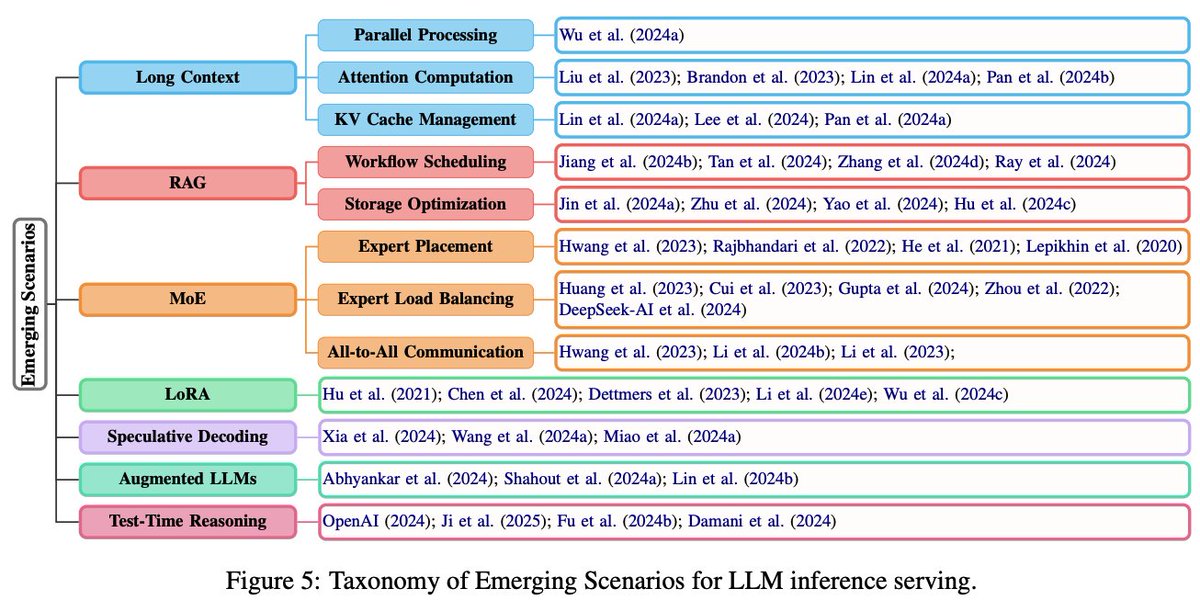
Emerging Scenarios
Key areas include long-context processing (e.g., RingAttention, DistAttention), RAG pipelines (PipeRAG, CacheBlend), MoE inference (with dynamic expert placement, load balancing, and All-to-All communication), LoRA adapter merging (dLoRA), speculative decoding, augmented LLMs (e.g., Parrot for agent scheduling), and test-time reasoning (e.g., Dynasor for adaptive compute).
There is a whole lot more in this paper. Take a read here: arxiv.org/abs/2504.19720
3
14
3,808

2 Apr 2025
The #EuroSys25 best paper awards go to Jiayi Yao et al. for their work on CacheBlend and Ruibo Fan et al. for their work on SpInfer. You can find the full text of the papers in the conference proceedings:
dl.acm.org/doi/10.1145/36890…
dl.acm.org/doi/10.1145/36890…

2
14
1,119

1 Apr 2025
Thrilled to be part of the CacheBlend project! 🥰
I’ve been contributing to the LMCache library (github.com/LMCache/LMCache), with a recent focus on high-performance KV cache compression and benchmarking.
Always happy to chat if you're interested!
1 Apr 2025

🏆 Exciting news from #EuroSys2025: Our work on CacheBlend won Best Paper! 🚀
CacheBlend delivers the first-ever speedup for RAG LLMs, achieving near-100% KV cache hit rates while maintaining output quality.
Catch Jiayi Yao, Kuntai Du, and Shan Lu at EuroSys/ASPLOS this week & learn more in our blog: blog.lmcache.ai/2025-04-01-e…
🤝CacheBlend is officially supported in: github.com/LMCache/LMCache
We always welcome comments and contributions!
#EuroSys2025 #LLM #AI #RAG #Research

2
9
2,938

1 Apr 2025
🚀 BIG Congrats to the LMCache team for winning the BEST PAPER at EuroSys'25! KV Cache hit rate can be too low? CacheBlend enables near-100% KV cache hit rate for RAG systems!
🔗 Blog: blog.lmcache.ai/2025-03-31-e…
🔗 Github (LMCache Library including CacheBlend): github.com/LMCache/LMCache
🔗 Github (Deployment Package): github.com/vllm-project/prod…
1 Apr 2025
🏆 Exciting news from #EuroSys2025: Our work on CacheBlend won Best Paper! 🚀
CacheBlend delivers the first-ever speedup for RAG LLMs, achieving near-100% KV cache hit rates while maintaining output quality.
Catch Jiayi Yao, Kuntai Du, and Shan Lu at EuroSys/ASPLOS this week & learn more in our blog: blog.lmcache.ai/2025-04-01-e…
🤝CacheBlend is officially supported in: github.com/LMCache/LMCache
We always welcome comments and contributions!
#EuroSys2025 #LLM #AI #RAG #Research
4
432
1 Apr 2025
🏆 Exciting news from #EuroSys2025: Our work on CacheBlend won Best Paper! 🚀
CacheBlend delivers the first-ever speedup for RAG LLMs, achieving near-100% KV cache hit rates while maintaining output quality.
Catch Jiayi Yao, Kuntai Du, and Shan Lu at EuroSys/ASPLOS this week & learn more in our blog: blog.lmcache.ai/2025-04-01-e…
🤝CacheBlend is officially supported in: github.com/LMCache/LMCache
We always welcome comments and contributions!
#EuroSys2025 #LLM #AI #RAG #Research
1
8
18
4,699