
Jun 11
AI Is Rewriting mRNA Drug Design
The success of COVID-19 mRNA vaccines proved that messenger RNA can become a transformative therapeutic platform. Yet one of the field’s biggest challenges remains unresolved:
How do we design the optimal mRNA sequence among billions of possibilities?
A new review in Journal of Advanced Research highlights how artificial intelligence is rapidly becoming the engine that drives next-generation mRNA therapeutics.
Unlike conventional drugs, mRNA performance depends heavily on sequence architecture:
• 5′ untranslated region (5′UTR)
• Coding sequence (CDS)
• 3′ untranslated region (3′UTR)
• Secondary structure
• Codon usage patterns
Even when two mRNAs encode exactly the same protein, differences in sequence design can dramatically alter:
✓ Translation efficiency
✓ Stability
✓ Immunogenicity
✓ Tissue-specific expression
The review describes a major paradigm shift.
Generation 1: Rule-based optimization
Historically, mRNA engineering relied on:
• Codon adaptation indices
• Kozak sequence tuning
• Empirical UTR selection
• Trial-and-error screening
These approaches explore only tiny regions of an enormous design space.
For example, the synonymous coding space of the SARS-CoV-2 spike protein exceeds 10⁶³² possible mRNA sequences.
Generation 2: AI prediction models
Deep-learning systems such as:
• Optimus 5-Prime
• UTR-LM
• CodonBERT
• mRNABERT
learn sequence–function relationships directly from large experimental datasets.
Rather than relying on hand-crafted rules, these models predict:
• Ribosome loading
• Translation efficiency
• mRNA half-life
• Protein expression output
Generation 3: AI-generated mRNA
The most exciting development is the rise of generative design.
Instead of evaluating existing sequences, AI can now create entirely new ones.
Examples include:
🧬 UTRGAN
🧬 Smart5UTR
🧬 PARADE
🧬 GEMORNA
These systems generate synthetic UTRs and coding sequences optimized for specific objectives such as:
• High expression
• Increased stability
• Reduced immunogenicity
• Cell-type specificity
Some AI-designed UTRs produced:
🚀 Up to 34-fold increases in translation efficiency
🚀 Nearly 100-fold higher vaccine-induced antibody responses
compared with conventional designs.
The next frontier: coordinated design
The review argues that the field is moving beyond isolated optimization of individual sequence elements.
Current efforts increasingly focus on:
5′UTR CDS 3′UTR co-design
as a unified system.
Models such as:
• LinearDesign2
• GEMORNA
• mRNABERT
attempt to optimize the entire transcript simultaneously rather than treating each region independently.
This matters because translation, stability, structure, and immunogenicity emerge from interactions across the full-length mRNA molecule.
Why this matters
The future of mRNA medicine may resemble modern protein design.
Instead of manually optimizing sequence elements, researchers will specify desired properties:
✓ High expression
✓ Long half-life
✓ Low innate immune activation
✓ Liver targeting
✓ Efficient LNP delivery
and AI systems will generate candidate mRNAs automatically.
The authors envision a future built around:
• Foundation models for RNA biology
• Multi-objective optimization
• Generative AI
• Closed-loop design-build-test-learn platforms
where computational models and experimental validation continuously improve each other.
If protein engineering was transformed by AlphaFold and generative biology, mRNA therapeutics may be approaching a similar inflection point.
The next blockbuster mRNA drug may be designed not by manual codon tuning—but by AI.
Reference
Shi Y, Zeng C, Sheng X, et al.
Transforming mRNA drug design with AI: From UTR and codon optimization to coordinated design.
Journal of Advanced Research (2026)
DOI: 10.1016/j.jare.2026.06.013
#mRNA #ArtificialIntelligence #GenerativeAI #CodonOptimization #UTRDesign #RNAEngineering #DrugDiscovery #BioAI #PrecisionMedicine #JournalOfAdvancedResearch

1
6
318
Maximally Divergent Synonymous Gene Design with SIRIUS
1. The paper introduces SIRIUS, an integer-linear-programming (ILP) method to design N synonymous coding sequences that all translate to the same protein while minimizing shared DNA subsequences that can trigger homologous recombination and multi-copy instability.
2. Key idea: instead of using heuristics or requiring a user-chosen “max allowed repeat length”, SIRIUS directly optimizes an explicit objective over pairwise common subsequences, prioritizing the elimination of long identical fragments (the ones most relevant to recombination risk).
3. Formulation highlights: binary decision variables encode codon/base choices per amino-acid position per gene copy; additional variables represent whether two sequences match at each nucleotide position; products of these match-indicators model shared contiguous subsequences of length l starting at position i.
4. Objective highlights: the ideal goal is lexicographic minimization (first reduce the longest shared subsequences, then the next-longest, etc.), but that is too slow in practice. SIRIUS uses a single additive objective that minimizes the total contribution of shared subsequences across lengths up to k, summed across all gene pairs.
5. Practical scaling trick: SIRIUS uses GeneDiversifier as a warm-start to provide an initial feasible solution and to estimate k (the longest shared subsequence observed initially). The CP-SAT solver (Google OR-Tools) then refines the design to further break repeats.
6. Codon-usage constraints: SIRIUS can enforce host-aware codon usage thresholds and optionally filter disfavored codons using RSCU. It supports a “soft” RSCU threshold with probabilistic inclusion plus a per-amino-acid cap on how often low-RSCU codons can appear, balancing divergence vs. host preference.
7. Benchmarks (N=10 copies) on seven therapeutically/industrially relevant proteins (mCitrine, IFNA2, CSF3, EPO, PLAT, IGF1, CALB): SIRIUS consistently reduces long shared subsequences compared with GeneDiversifier and strongly outperforms random codon assignment (which can yield very long shared tracts).
8. Example result (mCitrine): with an 80-minute default time limit, SIRIUS reduced shared subsequences ≥10 nt by ~15.6% vs a 5-minute run, with diminishing returns beyond that. Compared to GeneDiversifier, SIRIUS cut the mean number of shared 10-mers across sequence pairs from ~10 to ~1.7, while sometimes increasing very short shared fragments that are less likely to drive recombination.
9. Limitations and outlook: some repeats are unavoidable due to genetic-code constraints (e.g., amino acids whose codons share fixed prefixes). The approach is memory/time intensive (ILPs with millions of binaries for realistic proteins), and the authors point to future work on reducing ILP complexity via more tailored constraints.
💻Code: github.com/ucrbioinfo/sirius
📜Paper: biorxiv.org/content/10.64898…
#SyntheticBiology #ComputationalBiology #Optimization #ILP #CodonOptimization #GenomeEngineering #Biomanufacturing #Bioinformatics #ORtools #CPSAT

1
2
953
HalluCodon enables species-specific codon optimization using multimodal language models
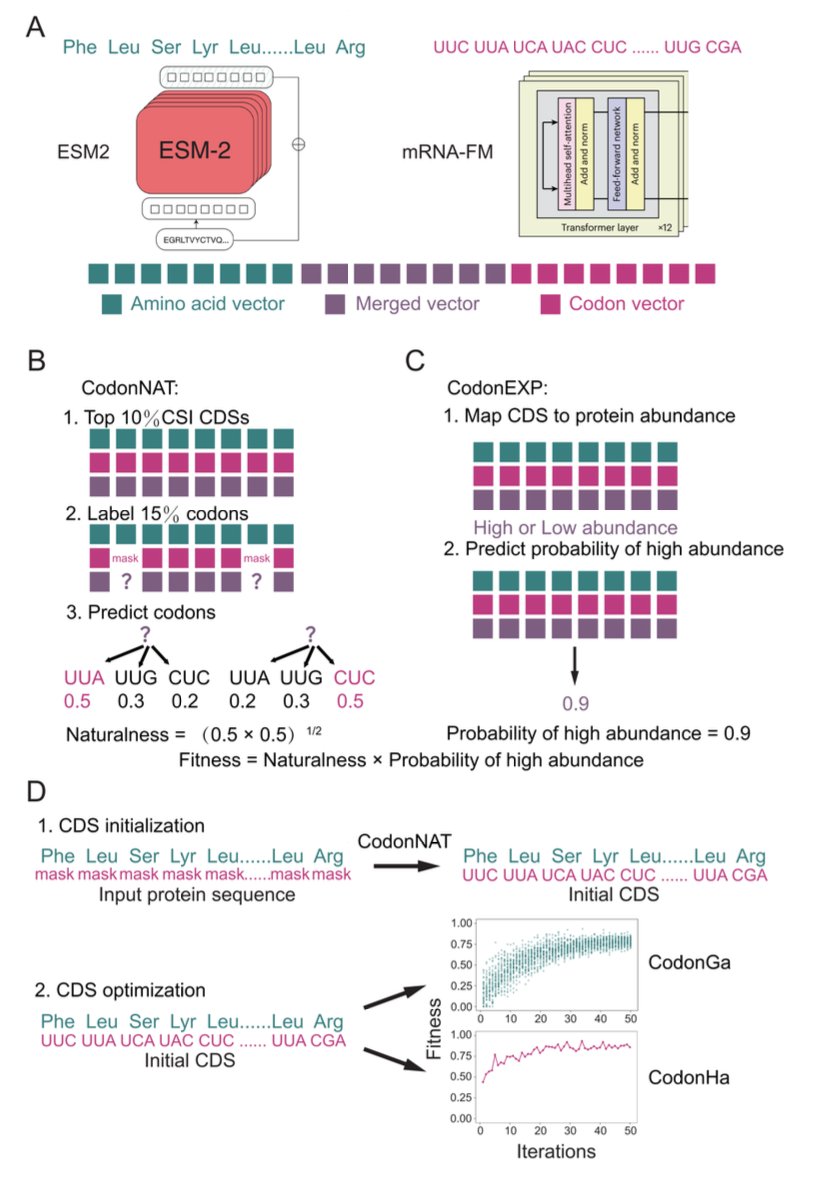
1 HalluCodon is a plant-focused codon-optimization framework that fine-tunes pre-trained protein and RNA language models to generate species-specific coding sequences, aiming to improve heterologous protein expression beyond simple codon-frequency heuristics.
2 The core idea is a two-module scoring system: CodonNAT quantifies “codon-context naturalness” (how compatible a CDS looks relative to endogenous host genes), while CodonEXP predicts the probability that a CDS will yield high protein abundance using experimental protein abundance labels.
3 CodonNAT is built via joint fine-tuning of ESM2-650M (protein LM) and mRNA-FM (codon-token RNA LM) under a masked-language-modeling objective, learning host-specific codon context signatures rather than only per-codon frequencies.
4 Across 15 plant species (including maize, rice, tobacco, wheat, tomato, potato, grape, etc.), CodonNAT achieved higher masked-codon prediction accuracy than a “pick the most frequent codon” baseline (average 66.5% vs 56.6%), with especially strong gains for amino acids with higher synonymous-codon diversity.
5 CodonNAT also showed biologically meaningful signal in a non-plant benchmark: in E. coli ccdA synonymous-mutation fitness data, it improved correlation between predicted and measured fitness (Spearman 0.41) compared with frequency-based scoring (0.32) and slightly above CodonTransformer (0.39), supporting that it captures context effects relevant to cellular fitness.
6 CodonEXP integrates nucleotide-level and protein-level information by learning from both CDS and amino acid sequence features, supervised with protein abundance data (PaxDb-derived labels: top 33% vs bottom 33%). It reached ~79.3% average accuracy and 86.1% average AUC across the 15 plant species, and outperformed RNA-only language model baselines in maize/rice/tobacco comparisons.
7 For sequence generation, HalluCodon offers (a) a genetic algorithm (CodonGa) and (b) a hallucination-style, gradient-guided optimizer (CodonHa). Both maximize a Fitness score defined as Naturalness (CodonNAT) × Expression probability (CodonEXP), but CodonHa converges far faster in compute.
8 In a tobacco DsRed2 optimization example, CodonHa reached near-maximal predicted expression probability in only a few iterations and ran ~46.8× faster than the genetic algorithm on the reported GPU setup, while maintaining codon-context compatibility.
9 Experimental transient expression in tobacco leaves tested five proteins (DsRed2, mCry2Ab, GAT, infliximab-A, infliximab-B). For DsRed2, CodonHa produced the strongest fluorescence and higher protein levels by Western blot (reported 1.57× vs CodonTransformer, 4.32× vs Genewiz, 13.58× vs a frequency baseline), suggesting the combined NAT EXP objective can translate to wet-lab gains.
10 The study highlights GC3 as a learned and actionable plant expression feature: HalluCodon optimization tends to increase GC3 toward host-like levels, and a GC3-rewarding variant (Ha-GC3) enabled expression of larger proteins that were difficult under the default CodonHa, while warning that extreme GC3/GC increases can complicate synthesis and increase methylation-site density.
💻Code: github.com/YuxuanLou/HalluCo…
📜Paper: biorxiv.org/content/10.64898…
#CodonOptimization #PlantSyntheticBiology #ComputationalBiology #Bioinformatics #LanguageModels #DeepLearning #ProteinExpression #Transgenic #MolecularFarming #ESM2 #RNAFM
2
20
1,334

🧬 Case Study: Tough #DNA sequence?
We solved a gene with:
• 17% rare codons
• ~110 nt hairpin
• Repetitive instability
Fix: #codonoptimization low copy strain (EPI400) fragment assembly
💡 Multi strategy beats trial and error
hubs.la/Q0481qHb0

2
51

Mar 18
DeepCodon, a deep learning tool, excels in codon optimization, preserving rare codons & outperforming traditional methods! #CodonOptimization #DeepLearning
Details: doi.org/10.1016/j.bidere.202…
3
7
304
CodonRL: Multi-Objective Codon Sequence Optimization Using Demonstration-Guided Reinforcement Learning
1. The authors present CodonRL, a reinforcement learning framework that achieves flexible multi-objective optimization for mRNA codon sequences without requiring retraining for different objective combinations.
2. The method introduces demonstration-guided learning, where expert sequences from LinearDesign pre-populate replay buffers to accelerate convergence, particularly for global structure objectives like minimum free energy.
3. A key innovation is the two-stage framework: training learns a structural prior using fast LinearFold for intermediate rewards, while inference enables dynamic control over translation efficiency, stability, and composition through adjustable weights.
4. CodonRL addresses the sparse reward problem in long-range optimization through milestone-based intermediate rewards at 25%, 50%, and 75% sequence completion.
5. On a benchmark of 55 human proteins, CodonRL outperforms the state-of-the-art GEMORNA method with 9.5% higher codon adaptation index, 25.4 kcal/mol more favorable minimum free energy, and 3.4% lower uridine content on average.
6. The framework improves codon stabilization coefficient in over 90% of benchmark proteins while supporting continuous objective reweighting at inference time, offering greater design flexibility than fixed-objective alternatives.
7. Unlike deep generative models that require large-scale mRNA datasets, CodonRL learns efficiently from limited demonstrations and provides interpretable control over the optimization landscape.
💻Code: github.com/Kingsford-Group/c…
📜Paper: biorxiv.org/content/10.64898…
#CodonOptimization #ReinforcementLearning #mRNADesign #Bioinformatics #ComputationalBiology #SyntheticBiology #MachineLearning

3
15
1,320
Machine Learning Method for Optimizing Coding Sequences in Mammalian Cells
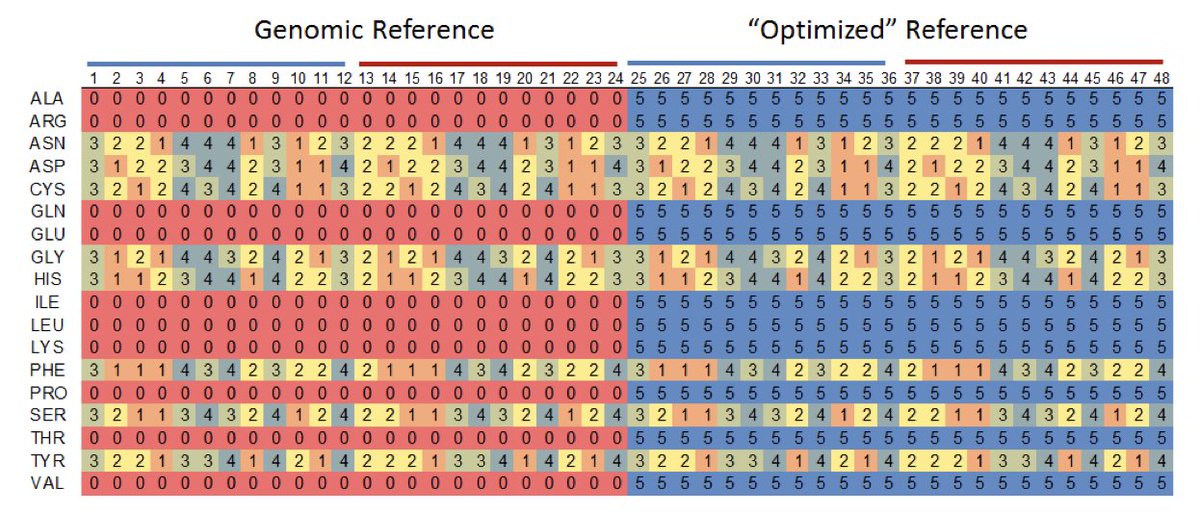
1. A new study shows synonymous codon choice can swing recombinant protein yield in HEK293 cells by >100-fold, dwarfing the gains promised by classic CAI or tRNA-matching rules.
2. The team designed 48 “Dasher-GFP” genes that differ only in codons, kept pairwise identity ~72 %, avoided splice sites and strong 5′-RNA structure, then let machine learning mine the expression map without mechanistic priors.
3. First-round PLS/ensemble models reached R² ≈ 0.62 using codon-usage frequencies alone; a second 48-gene iteration guided by the model pushed average fluorescence up another ~5×, proving true extrapolation beyond the training cloud.
4. Ribosome profiling and RNA-seq of selected variants revealed that higher protein output tracks almost linearly with mRNA abundance, not elongation speed, implying that optimal coding mainly protects transcripts from decay.
5. G:U wobble codons, long suspected to slow translation, explained no extra variance once non-wobble codons were fixed, debunking a widespread assumption for this mammalian system.
6. The same 48 sequences expressed in E. coli and Sf9 gave entirely different rankings (Spearman ≈ 0), underscoring that “codon optimization” recipes must be host-specific rather than universal.
7. A Dasher-only algorithm predicted expression of 302 genes spanning six unrelated proteins (scFvs, antibodies, membrane proteins) with R² = 0.64, showing the signal is protein-independent and portable across targets.
8. Authors position the workflow—systematic DoE libraries → ML model → iterative redesign—as a generic, hypothesis-free path to maximize yield for any biologic or host, moving synthetic biology from guesswork to data-driven engineering.
📜Paper: biorxiv.org/content/10.64898…
#CodonOptimization #MachineLearning #RecombinantProtein #SynonymousCodons #HEK293 #SyntheticBiology #Bioinformatics
5
31
2,318

💥 New Special Issue open for submission!
🔗 tinyurl.com/844xfpet
🕑 The deadline for manuscript submissions is 31 July 2026
📌 #syntheticbiology #codonoptimization #transformermodels #proteinengineering #biosensing #electrochemicalsensors #bioelectronics #geneticdesign

1
40
Jan 11
Introducing DeepCodon: AI tool boosts gene expression by preserving rare codons! #CodonOptimization #DeepLearning #SyntheticBio
Details: doi.org/10.1016/j.bidere.202…

2
3
159

30 Nov 2025
CodonTranslator: A Conditional Codon Language Model for Codon Optimization Across Life Domains
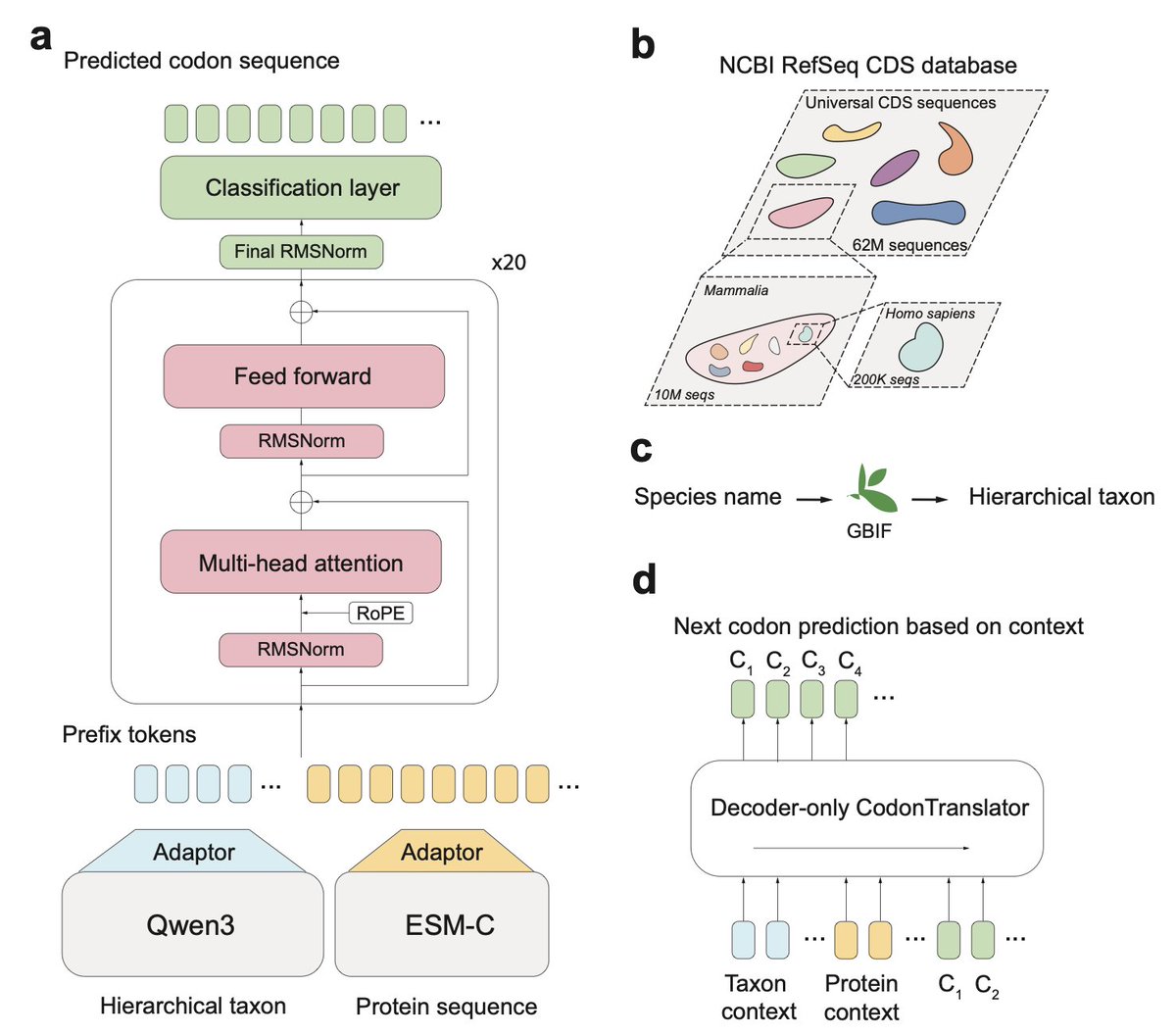
1. Codon optimization is crucial for heterologous gene expression, but existing methods often fail to capture the complex interplay between species-specific codon usage and protein function. This new study introduces CodonTranslator, a groundbreaking model that addresses these limitations by integrating species lineage and protein context into codon sequence generation.
2. The core innovation of CodonTranslator lies in its use of a decoder-only Transformer architecture, conditioned on both species and protein contexts. It leverages continuous embeddings derived from hierarchical taxonomic lineages and deep protein features to generate codon sequences that match or surpass existing methods in terms of biological stability and codon usage metrics.
3. Unlike previous models that rely on discrete species embeddings or BERT-style training objectives, CodonTranslator uses a large-scale dataset of over 62 million CDS–protein pairs from 2,163 species. This approach enables the model to learn the genetic code directly from data and generalize to unseen species and proteins.
4. The study demonstrates that CodonTranslator accurately captures species-specific codon usage patterns, even for species not seen during training. This capability is crucial for synthetic biology applications, where designing sequences for novel hosts is a common challenge.
5. In benchmark tests across five model organisms, CodonTranslator outperforms both traditional vendor tools and other deep learning models, achieving higher codon similarity and lower DTW distances. This indicates its ability to reproduce natural codon sequences with high fidelity.
6. CodonTranslator also excels in heterologous expression scenarios, where the goal is to optimize sequences for expression in a different host. The model reduces predicted negative cis elements, suggesting it can generate sequences with fewer liabilities for expression in non-native hosts.
7. The authors provide the dataset, pretrained models, and code, making this powerful tool accessible for further research and practical applications in synthetic biology and biotechnology.
📜Paper: biorxiv.org/content/10.1101/…
#CodonOptimization #DeepLearning #SyntheticBiology #Bioinformatics #Genomics
5
14
1,777

20 Nov 2025
🔗 A statistical-physics approach for codon usage optimisation. DOI: doi.org/10.1016/j.csbj.2024.…
📚 CSBJ: csbj.org/
#Genomics #CodonOptimization #SyntheticBiology #GeneticEngineering #SystemsBiology #GeneDesign #MolecularBiology @CSB_Journal

ALT A statistical-physics approach for codon usage optimisation. Computational and Structural Biotechnology Journal, DOI: https://doi.org/10.1016/j.csbj.2024.07.020
1
2
44
16 Nov 2025
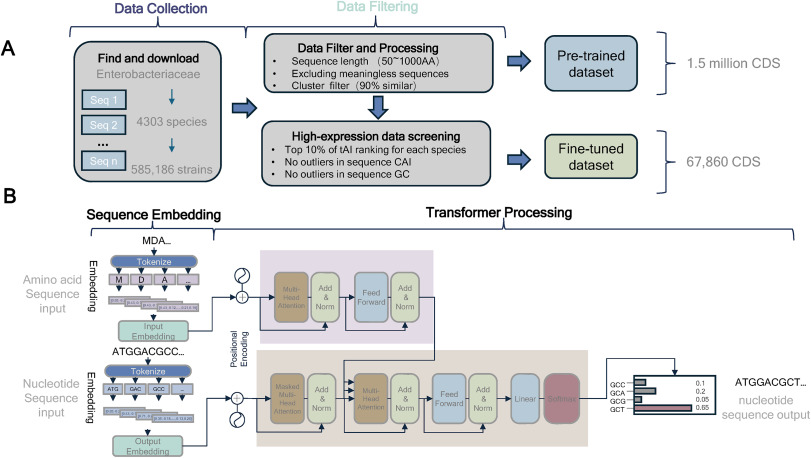
Introducing DeepCodon: a deep learning tool for codon optimization, preserving rare codons & outperforming traditional methods. #CodonOptimization #DeepLearning
Details: doi.org/10.1016/j.bidere.202…
1
3
3
159
25 Sep 2025
Learning the Native-Like Codons with a 5'UTR and RNA Secondary Structure Aided Species-Informed Transformer Model
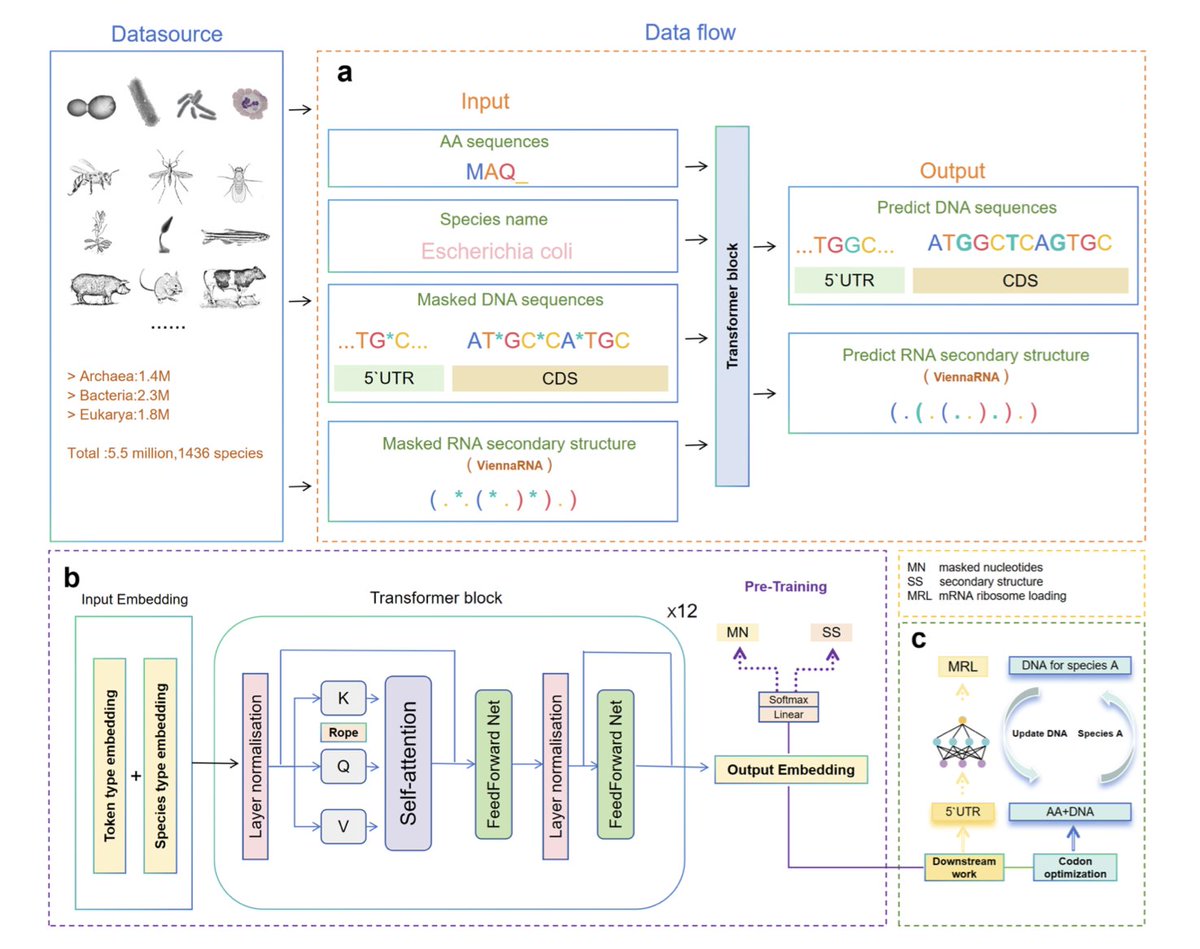
1. A new deep learning model named TransCodon has been introduced to address the challenge of efficient protein expression across different species by optimizing codon usage. The model leverages a Transformer architecture to learn nuanced codon usage patterns across diverse organisms, integrating 5'UTR and RNA secondary structure information for more accurate codon optimization.
2. TransCodon incorporates species-specific information and RNA secondary structure features, enabling it to capture both local and global determinants of codon preference. This approach significantly improves the model's ability to predict optimal synonymous codons, resulting in sequences that closely resemble natural gene sequences.
3. The model was trained on a large-scale dataset comprising 5.5 million gene sequences from 1436 species, ensuring robust cross-species generalization. Experimental results demonstrate that TransCodon outperforms traditional methods and recent machine learning-based approaches in multiple evaluation metrics, including codon recovery rate, Codon Similarity Index (CSI), and GC content.
4. TransCodon effectively captures the usage of low-frequency codons, which are often omitted by other methods. This feature is crucial for generating synthetic gene sequences that closely approach their natural counterparts, potentially enhancing protein expression and folding efficiency.
5. The model also shows a strong correlation between its fitness scores and experimentally measured protein expression levels, indicating its potential for predicting protein abundance. Additionally, TransCodon demonstrates superior performance in downstream tasks such as predicting mean ribosome load (MRL) based on 5'UTR sequences.
6. The study highlights the importance of considering regulatory regions like the 5'UTR and RNA secondary structure in codon optimization. TransCodon's ability to integrate these elements sets it apart from previous models and underscores its potential for applications in synthetic biology and gene expression studies.
📜Paper: biorxiv.org/content/10.1101/…
💻Code: github.com/guyuehuo/TransCod…
#TransCodon #CodonOptimization #DeepLearning #SyntheticBiology #GeneExpression #RNASecondaryStructure #5UTR #ProteinEngineering
2
2
7
1,104
5 Sep 2025
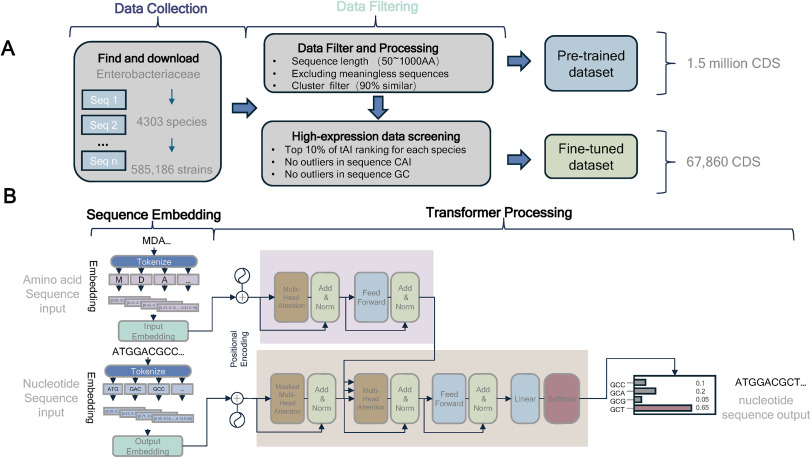
DeepCodon: AI tool boosts gene expression via smart codon optimization! #DeepLearning #CodonOptimization
Details: doi.org/10.1016/j.bidere.202…
4
5
513
25 Aug 2025
Advancing Codon Language Modeling with Synonymous Codon Constrained Masking
1. A new codon language model, SynCodonLM, was introduced that uses a novel training strategy to disentangle DNA-level from protein-level semantics. By constraining the model to predict only synonymous codons, it is able to focus on the nuances of codon usage.
2. A key finding is that the model’s learned embeddings cluster codons based on nucleotide features like the wobble base and suffix dinucleotides, unlike previous models which grouped them by amino acid identity. This shows that the model is learning biologically meaningful DNA-level patterns.
3. The SynCodonLM model consistently outperformed existing models on six out of seven benchmarks sensitive to DNA-level features, including those related to mRNA and protein expression.
4. The model was trained on the largest and most diverse dataset for codon language modeling to date, comprising over 66 million coding sequences from almost 35,000 species.
5. This research has significant implications for nucleotide-based therapeutics, such as mRNA vaccines and gene therapies, and offers a powerful new tool for codon optimization in synthetic and biotherapeutics.
📜Paper: biorxiv.org/content/10.1101/…
#ComputationalBiology #Bioinformatics #MachineLearning #SyntheticBiology #CodonOptimization

1
3
15
2,249
20 Jul 2025
Learning The Native-Like Codons With A 5'UTR And Secondary RNA Structure Aided Species-Informed Transformer Model
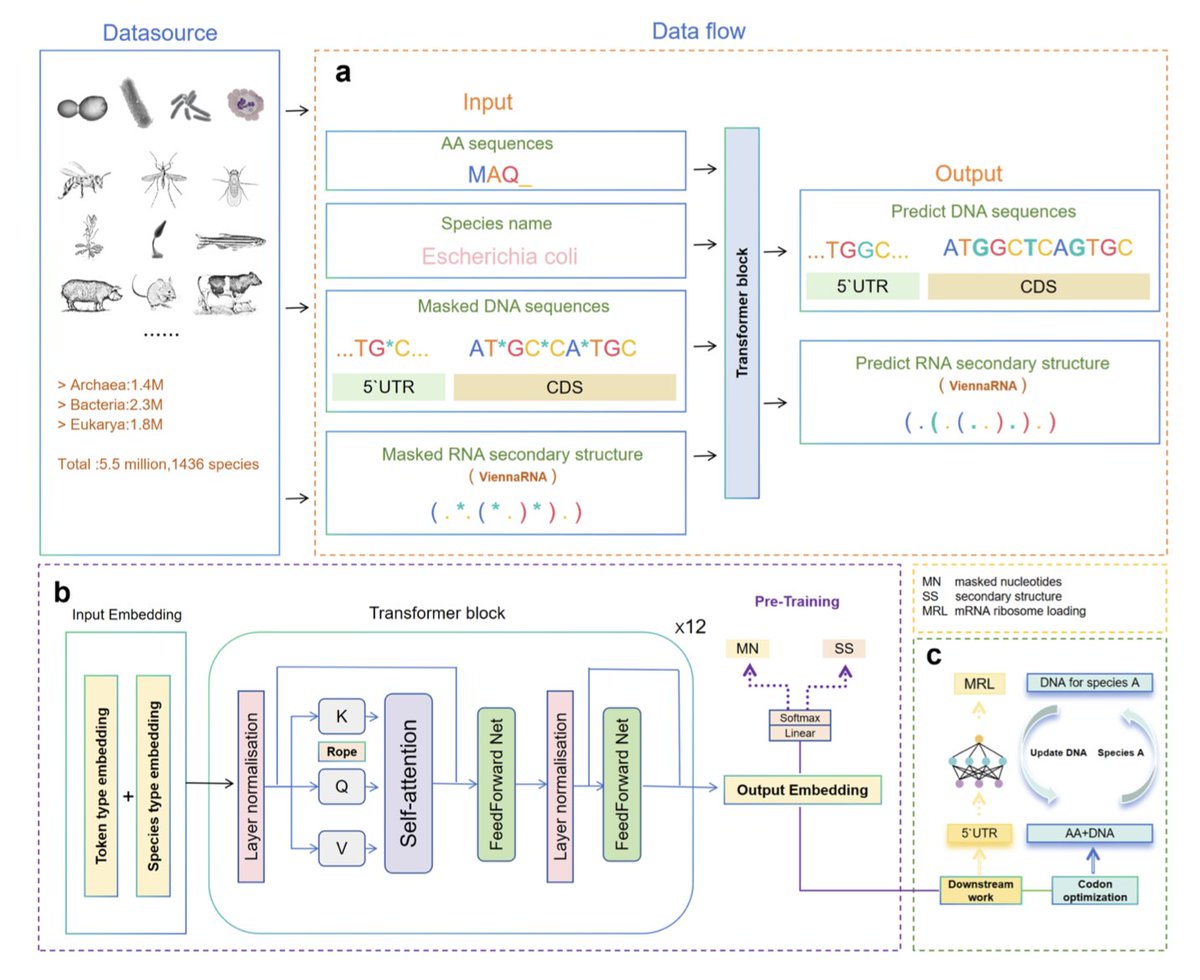
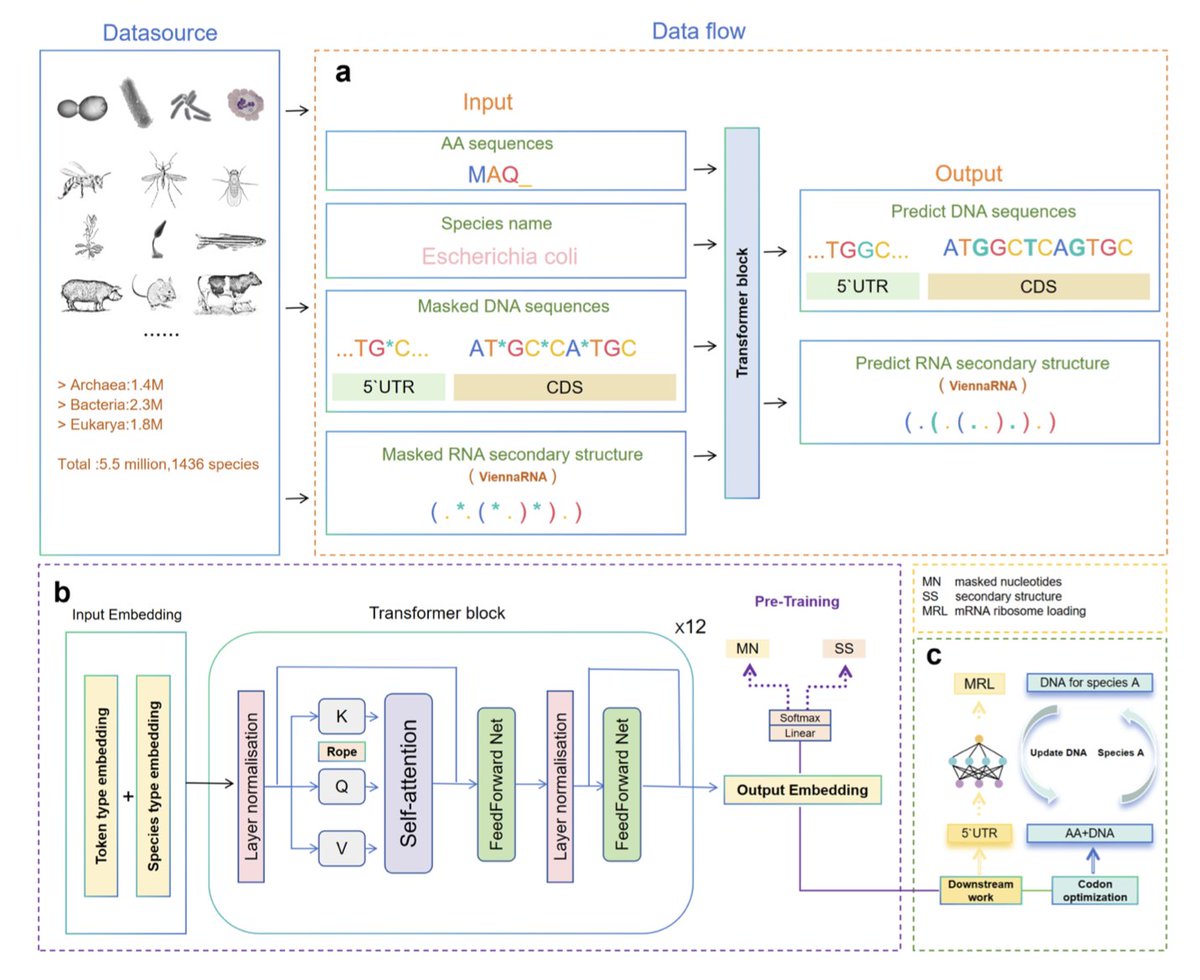
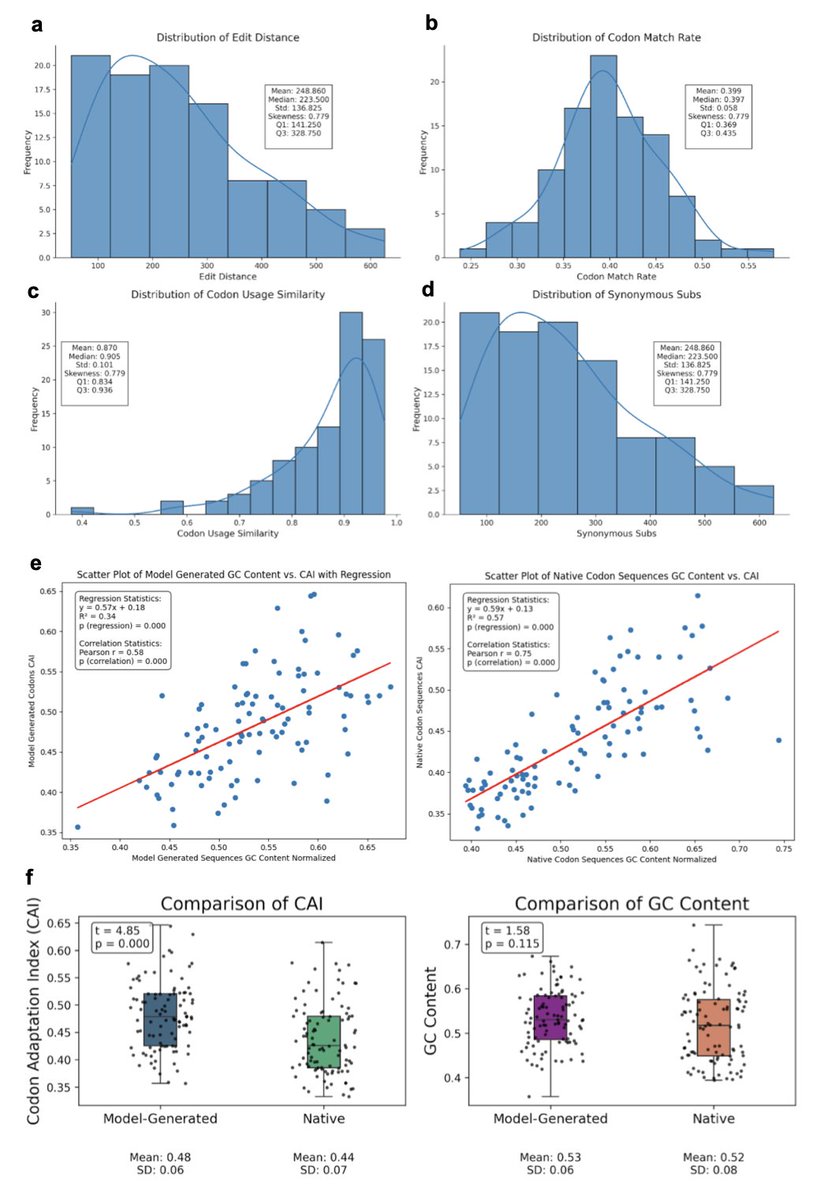
A new Transformer-based deep learning model, TransCodon, has been developed to address the challenge of efficient protein expression in heterologous hosts. It tackles the difficulty of reconstructing native-like codon landscapes by integrating 5' untranslated regions (5'UTRs), coding sequences (CDS), explicit species identifiers, and RNA secondary structure information.
TransCodon learns nuanced codon usage patterns across diverse organisms by incorporating multisource genomic data and modeling sequence dependencies via a masked language modeling paradigm. This allows it to effectively capture both local and global determinants of codon preference.
A key innovation is TransCodon's use of a finer-grained vocabulary based solely on nucleotides, which enables partial decoding and preserves richer sequence-level information compared to previous approaches. The model was trained on a large dataset of 5.5 million gene sequences from 1,436 species, ensuring robust cross-species generalization.
Experimental results demonstrate that TransCodon consistently outperforms existing codon optimization tools across multiple evaluation metrics. It identifies native-like codons with less divergence from natural sequences and can capture low-frequency codons often missed by other deep learning methods, especially for highly abundant proteins.
Beyond codon optimization, TransCodon shows robust effectiveness in predicting protein abundance, achieving high correlation with experimentally determined values in zero-shot scenarios. It also excels in 5' UTR-related downstream tasks, such as predicting Mean Ribosome Load (MRL), surpassing other state-of-the-art models.
These findings indicate that TransCodon is a robust codon language model with significant potential for designing genes to achieve high translational efficiency in target host organisms, marking a notable advancement in computational synthetic biology.
📜Paper: biorxiv.org/content/10.1101/…
#ComputationalBiology #SyntheticBiology #DeepLearning #ProteinExpression #CodonOptimization #Bioinformatics #Genomics #TransformerModels
1
2
923
20 Jul 2025
Learning The Native-Like Codons With A 5'UTR And Secondary RNA Structure Aided Species-Informed Transformer Model
A new Transformer-based deep learning model, TransCodon, has been developed to address the challenge of efficient protein expression in heterologous hosts. It tackles the difficulty of reconstructing native-like codon landscapes by integrating 5' untranslated regions (5'UTRs), coding sequences (CDS), explicit species identifiers, and RNA secondary structure information.
TransCodon learns nuanced codon usage patterns across diverse organisms by incorporating multisource genomic data and modeling sequence dependencies via a masked language modeling paradigm. This allows it to effectively capture both local and global determinants of codon preference.
A key innovation is TransCodon's use of a finer-grained vocabulary based solely on nucleotides, which enables partial decoding and preserves richer sequence-level information compared to previous approaches. The model was trained on a large dataset of 5.5 million gene sequences from 1,436 species, ensuring robust cross-species generalization.
Experimental results demonstrate that TransCodon consistently outperforms existing codon optimization tools across multiple evaluation metrics. It identifies native-like codons with less divergence from natural sequences and can capture low-frequency codons often missed by other deep learning methods, especially for highly abundant proteins.
Beyond codon optimization, TransCodon shows robust effectiveness in predicting protein abundance, achieving high correlation with experimentally determined values in zero-shot scenarios. It also excels in 5' UTR-related downstream tasks, such as predicting Mean Ribosome Load (MRL), surpassing other state-of-the-art models.
These findings indicate that TransCodon is a robust codon language model with significant potential for designing genes to achieve high translational efficiency in target host organisms, marking a notable advancement in computational synthetic biology.
📜Paper: biorxiv.org/content/10.1101/…
#ComputationalBiology #SyntheticBiology #DeepLearning #ProteinExpression #CodonOptimization #Bioinformatics #Genomics #TransformerModels
7
727
29 Jun 2025
codonGPT: Reinforcement learning on a generative language model optimizes RNA sequences under biological constraints
1.codonGPT introduces the first generative language model trained directly on coding mRNA sequences (codons), addressing a major gap in RNA-based sequence modeling that has lagged behind advances in DNA and protein modeling.
2.A key innovation is the use of inference-time synonymous logit masking, ensuring that generated codon sequences preserve the original amino acid sequence with 100% fidelity—crucial for therapeutic applications.
3.Reinforcement learning (RL) is used on top of codonGPT for the first time to optimize codon sequences for specific proteins. This allows user-customizable optimization across multiple biological constraints such as CAI, GC content, RNA stability, codon diversity, and repeat usage.
4.Unlike prior models that apply universal optimization, codonGPT enables protein-specific fine-tuning through RL, making it ideal for personalized or target-specific gene design in therapeutics and synthetic biology.
5.codonGPT embeddings naturally cluster synonymous codons in vector space without supervision. This means the model learns the structure of the genetic code purely from sequence data, not from protein alignment.
6.Codon usage preferences related to expression (like CAI) and nucleotide composition (like GC content) emerge spontaneously in the model, reflecting codonGPT's internalization of biologically relevant biases.
7.On 100 human housekeeping genes, codonGPT-generated sequences preserved protein identity while producing biologically plausible sequence diversity, matching codon usage patterns with a median cosine similarity of 0.87 to native sequences.
8.When optimizing codons for two distinct genes (HLA-A and ACTB), RL fine-tuning achieved higher CAI and more stable mRNA structures (ΔG) than both native and competing models, without sacrificing codon diversity.
9.RL-guided sequences formed distinct high-reward clusters in principal component space, suggesting the model navigates toward optimal biological configurations unlikely to arise from traditional generative modeling.
10.codonGPT can support flexible inference-time constraints beyond RL—such as enforcing motif presence or excluding restriction sites—via its novel logit masking mechanism.
11.This foundation model shifts codon optimization from rule-based heuristics or masked BERT architectures toward generative, fine-tunable frameworks that can adapt to user-defined biological objectives in real time.
12.The study positions codonGPT as a scalable, modular solution for next-generation applications including mRNA vaccine design, therapeutic protein production, and multi-host expression tuning.
💻Code: huggingface.co/anuj2054/codo… 📜Paper: biorxiv.org/content/10.1101/…
#SyntheticBiology #mRNA #GenerativeAI #CodonOptimization #ProteinEngineering #Bioinformatics #ReinforcementLearning
7
30
2,067
7 Jun 2025
Negative epistasis limits current codon optimization approaches
1.A recent study explores the challenges in achieving high-yield protein expression through codon optimization, specifically addressing the impact of negative epistasis in protein production.
2.The research reveals that while codon optimization can increase protein expression, the variability in expression levels is significant, and achieving predictability remains difficult due to the "rugged" nature of the synonymous genotype-phenotype map.
3.It was found that negative epistasis—where certain synonymous mutations interact in ways that decrease expression—complicates predictions and introduces non-additive effects that limit current optimization strategies.
4.The study compared twelve different codon optimization approaches (six commercial and six open-source) to express a protein (AtCAD5) in E. coli strains. The results showed that non-proprietary methods could perform on par with commercial ones.
5.One of the key findings is that the synonymous sequence space for protein expression is influenced by epistatic effects, causing sudden drops in expression, often referred to as "expression valleys."
6.The authors suggest that the lack of a comprehensive predictive model for protein expression stems from the ruggedness of the synonymous sequence landscape, where optimization is not straightforward.
7.Overall, while codon optimization remains essential for high-yield protein expression, the study highlights fundamental limitations in predicting protein expression outcomes due to complex interactions between codons.
📜Paper: biorxiv.org/content/10.1101/…
#CodonOptimization #ProteinExpression #NegativeEpistasis #Biotechnology #Genomics

3
927
2 Jun 2025
A New Deep-learning-Based Approach For mRNA Optimization: High Fidelity, Computation Efficiency, and Multiple Optimization Factors
1.A new deep learning framework called RNop is introduced to address a long-standing challenge in mRNA design: simultaneously ensuring sequence fidelity, computational efficiency, and comprehensive multi-objective optimization. RNop achieves all three, overturning the common trade-off triangle in codon optimization.
2.RNop employs a Transformer-based architecture and processes mRNA coding sequences (CDS) using a vision-inspired method. It encodes sequences as image-like matrices, enabling the use of Vision Transformer blocks for optimization. This approach ensures both speed and flexibility.
3.The model is trained on a large dataset of over 3 million mRNA sequences, far surpassing previous efforts in dataset size, improving generalizability across species and sequence types.
4.RNop introduces four novel loss functions tailored for biological relevance: ・GPLoss: enforces protein-coding fidelity by penalizing non-synonymous mutations ・CAILoss: boosts codon usage bias for species-specific translation efficiency ・tAILoss: promotes codons matching abundant tRNAs for enhanced elongation speed ・MFELoss: improves RNA stability by minimizing secondary structure free energy
5.The system achieves high computational throughput of 47.32 sequences per second, making it suitable for high-throughput synthetic biology and vaccine design workflows.
6.In silico tests show RNop consistently improves CAI and tAI across target species, including human, mouse, yeast, and E. coli. When optimizing human-targeted sequences, CAI increased from 0.7029 to 0.9735, and tAI from 10.95 to 13.16.
7.MFELoss demonstrates substantial impact in reducing minimum free energy, especially in yeast, showing its value for stabilizing mRNA structure and potentially prolonging transcript half-life.
8.RNop strictly preserves amino acid sequences when required, with 0% mutation and codon error under high GPLoss settings, while also supporting controlled mutation when desirable by tuning GPLoss weights.
9.In vivo experiments validate RNop’s performance using eGFP and SARS-CoV-2 spike protein. Optimized sequences resulted in protein expression levels up to 4.6× higher than baseline controls, confirming real-world biological benefit.
10.Ablation studies confirm that each loss function contributes meaningfully to performance. Balanced loss weights provide the best trade-off between CAI/tAI improvement and structural optimization.
11.Compared to other deep learning models like RNNs, LSTMs, and standard Transformers, the ViT-based RNop consistently delivers superior results in both accuracy and stability. Sequence error rates, especially length and codon errors, are minimized.
12.Overall, RNop sets a new benchmark for codon optimization tools by combining deep learning precision, biological interpretability, and practical effectiveness in both computation and wet-lab settings.
💻Code: github.com/HudenJear/RPLoss
📜Paper: arxiv.org/abs/2505.23862v1 #RNA
#DeepLearning #SyntheticBiology #CodonOptimization #mRNA #Bioinformatics #ProteinExpression

1
4
721