
Jan 26
Some kind of pile-up in the Grand National would leave the way clear for an ungenuine plodder to come from behind, avoiding all the carnage. Foinavon fits the bill and looks huge at 200/1. No bet if the others don't fall over. #conditionalprobability
3
327

6 Dec 2025
I played around with the math for $GEOD a bit back in May.
I’m not going to share the details of how I calculated it, and don’t take it seriously anyway. I’m just posting it because it’s fun.
But I calculated the potential price of a single GEOD token to be somewhere between $25.6 USD - $7.5 million 🤣
#conditionalprobability
PS: I’m not really into math, but if money’s involved, I become Laplace.

4
7
272

2 Sep 2025
The babies born of mothers with Hep B actually are dumbasses. #ILoveMath #ConditionalProbability
1 Sep 2025

Heaven forbid we come off as JUDGMENTAL for saying that actions have consequences, like if you choose to be an infant born to a woman with Hep B, you absolute dumbass baby. #prolife
3
131

14 Jul 2025
Conditional probability is a crucial concept in statistics, as it allows us to incorporate prior information when making predictions. Without considering this, predictive models would lack accuracy and relevance. Understanding conditional probability is essential for creating effective models.
Thank you to @TivadarDanka for sharing this insightful post!
#Statistics #DataScience #PredictiveModeling #ConditionalProbability
13 Jul 2025

Conditional probability is the single most important concept in statistics.
Why? Because without accounting for prior information, predictive models are useless.
Here is what conditional probability is, and why it is essential.
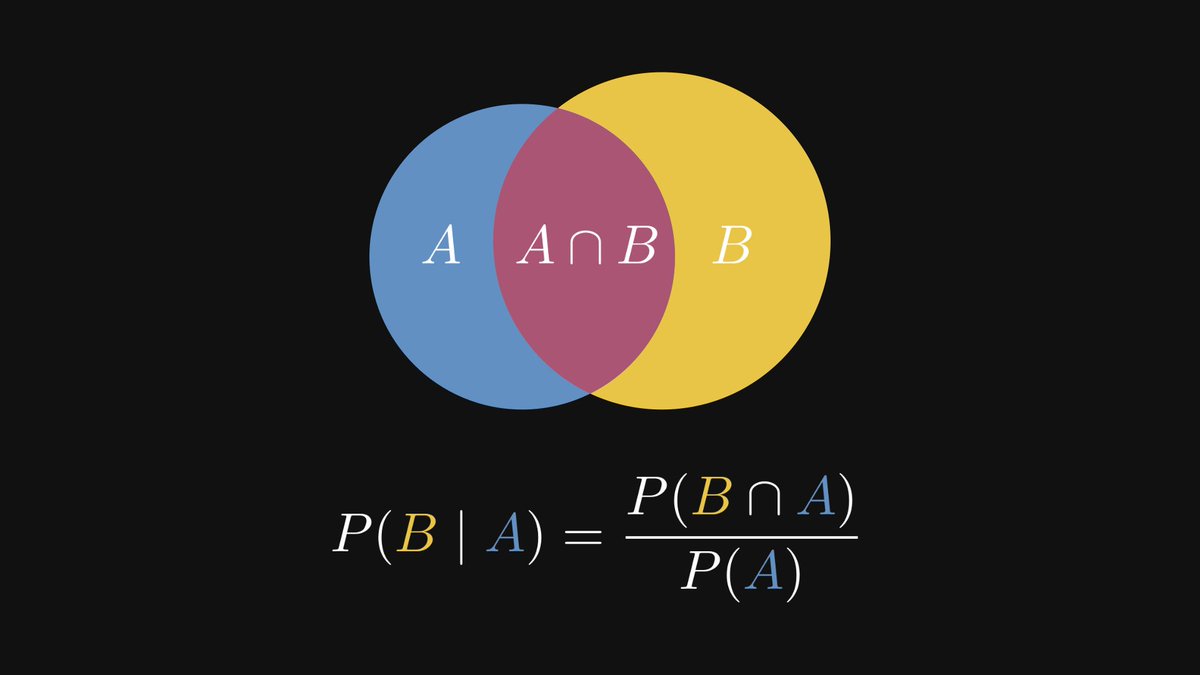
2
27
1,556

30 Jun 2023
💊 Most machine learning research is about going from mathematical modeling to ML model implementation. Here’s how to go from conditional probability to a neural architecture.
Let's start by defining a simple conditional probability problem. Consider a supervised learning task where we have input data X and target data Y, and we want to model the conditional probability P(Y | X), meaning the probability of Y given X.
A common way to model this in machine learning is to assume that this probability follows some parametric form and then use the data to estimate the parameters of this model.
For instance, we could assume that P(Y | X) is a Gaussian distribution with mean µ(X) and standard deviation σ(X). This mean µ(X) and standard deviation σ(X) could be any functions of X, but in order to learn them from data, we often assume they can be parameterized with some parameters θ, and are differentiable with respect to these parameters.
This is where neural networks come in. A neural network is just a function approximator that's highly flexible and differentiable, making it suitable to represent these functions µ(X) and σ(X).
Let's assume that our neural network is a simple feed-forward network with parameters θ. Then we can write our model as:
µ(X; θ) = NN_µ(X; θ)
σ(X; θ) = NN_σ(X; θ)
P(Y | X; θ) = N(Y; NN_µ(X; θ), NN_σ(X; θ)^2)
Here, NN_µ and NN_σ are two neural networks which take the same input X and share the same parameters θ, and N is the Gaussian distribution. Their outputs represent the mean and standard deviation of the Gaussian distribution of Y given X.
To train this model, we would use a method called maximum likelihood estimation (MLE), which aims to find the parameters θ that maximize the likelihood of the observed data.
For our Gaussian model, this corresponds to minimizing the mean squared error between Y and NN_µ(X; θ).
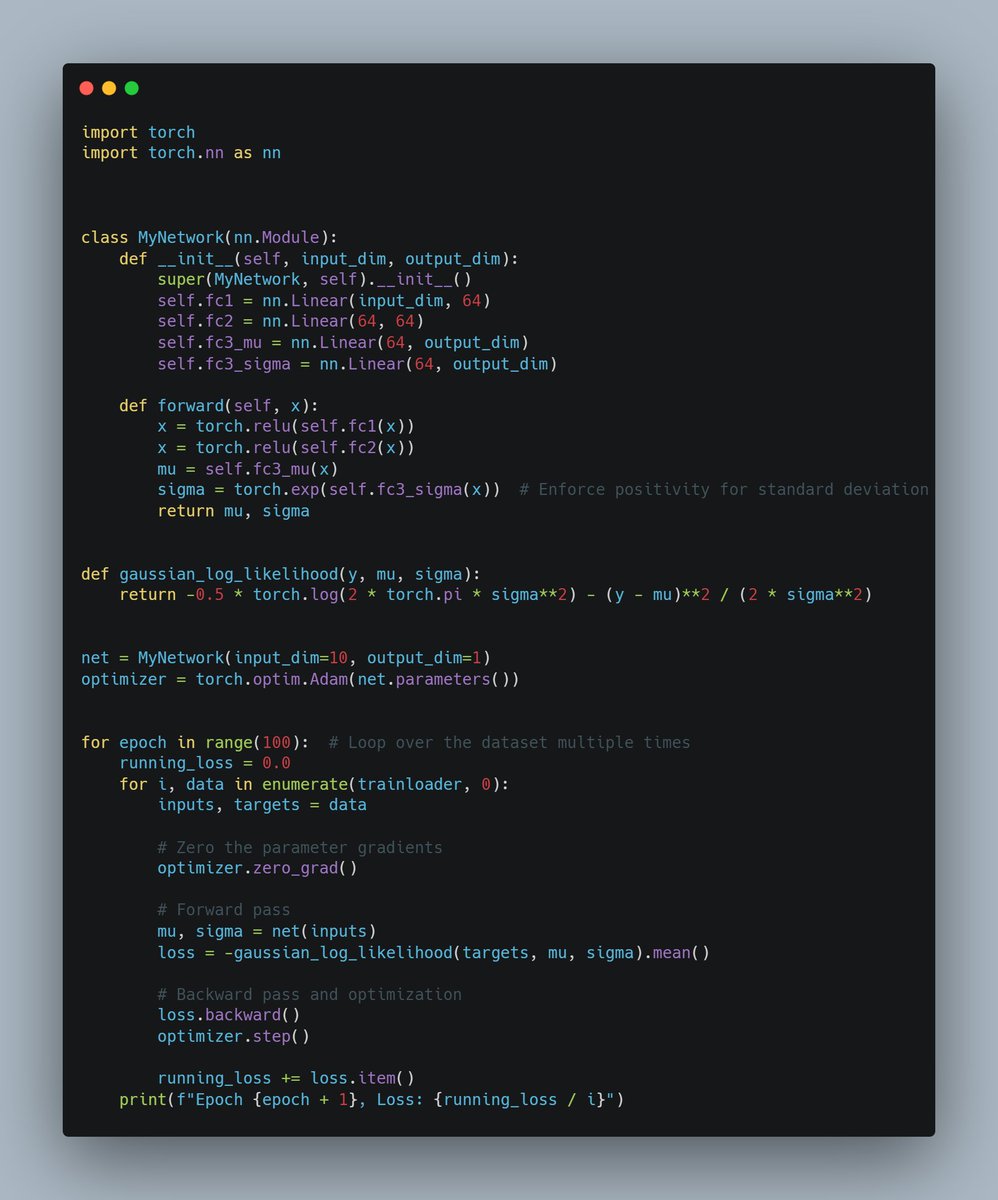
Below, you can see how we might implement this in code using PyTorch.
In this code, we have a neural network that outputs two values for each input: a mean and a standard deviation. The loss function is defined as the negative log-likelihood of the Gaussian distribution, which we try to minimize using gradient descent.
💡 Get technical insights just like this to help you become a better ML practitioner here: lnkd.in/dSgjuK5Z
#machinelearning #conditionalprobability
1
3
149

Naive Bayes calculates the conditional probability of each class given the input features using Bayes' theorem. kuisk.com/discipline/naive-b… via @my_twitter_username #naivebayes #bayesian #conditionalprobability #artificialintelligence #intelligence #artificialgeneralintelligence
1
116

22 Dec 2022
🚨POLL: Will US equities get the popular Santa Rally ?
Vote👇🏽
#Quad4 #datamining #curvefitting #conditionalprobability #setup #volatility #stocks $TSLA $AAPL $NVDA $LRCX $MU $MSFT $Vz $ABBV $VIX $MRK $RL $ULTA $LULU
40%
Yes, Santa is coming
60%
No, Santa doesn’t exist
1,282 votes • Final results
7
8
8
7,079

10 Dec 2022
Ta 50/50 och fundera på om de svaga åren har något gemensamt med 2022. #ConditionalProbability
4
3

27 Oct 2022
This thread is saved to your Notion database.
Tags: [Conditionalprobability]
27 Oct 2022
This thread is saved to your Notion database.
Tags: [Probability, Stats, Ml, Conditionalprobability]

29 Aug 2022
Let’s Understand Bayes’ Theorem in Details: python.plainenglish.io/lets-… #BayesTheorem #Statistics #DataScience #ConditionalProbability #MarginalProbability
1

26 Aug 2022
Let’s Understand Bayes’ Theorem in Details: python.plainenglish.io/lets-… #BayesTheorem #Statistics #DataScience #ConditionalProbability #MarginalProbability
1
2
2
24 Aug 2022
Let’s Understand Bayes’ Theorem in Details: python.plainenglish.io/lets-… #BayesTheorem #Statistics #DataScience #ConditionalProbability #MarginalProbability
3
3

26 Dec 2021
Because of the way the MSM report it. I’m still not sure whether they do t understand, or are deliberately mis-stating it.
But MSM says ‘you are less likely to be hospitalised with Omicron than with Delta’. What they mean is IF you have Omicron then…. #conditionalprobability
2

18 Oct 2021
A more accurate analogy would have been "the best way to know if a person is going to have a broken leg is if they have had multiple broken legs in the past"
(Yes I am THAT pedant! Also fun at parties)
#AECOPD #ConditionalProbability
16 Oct 2021

Send help. The research I established my career on has become a meme…
2

13 Sep 2021
Me to wife: I'll be late today from work. Kindly don't keep food for me
Wife: There is pizza for dinner today
Me: Oh, ill eat at home
#BayesTheorem explained
#ConditionalProbability
1
21

12 Aug 2021
great visualization of this model #datavisualization #math #conditionalprobability nytimes.com/interactive/2021…
1
5

6 Aug 2021
Dear student learn ✍️conditional probability with @TAPL_Official
Prepare yourself for the upcoming JEE exam
.
.
Call : 9310378303
Visit : takshilainstitute.in
#conditionalprobability #jeecoachingclass #jeecourse #bestcoachingforJEE #jeecoachingcenter #coachingindelhi
2

1 Aug 2021
Watching Howie’s video, it’s just occurred to me that some of my students might understand conditional probability better if I highlighted the similarities with rates.
#MakesNoteToSelf #Maths #ConditionalProbability
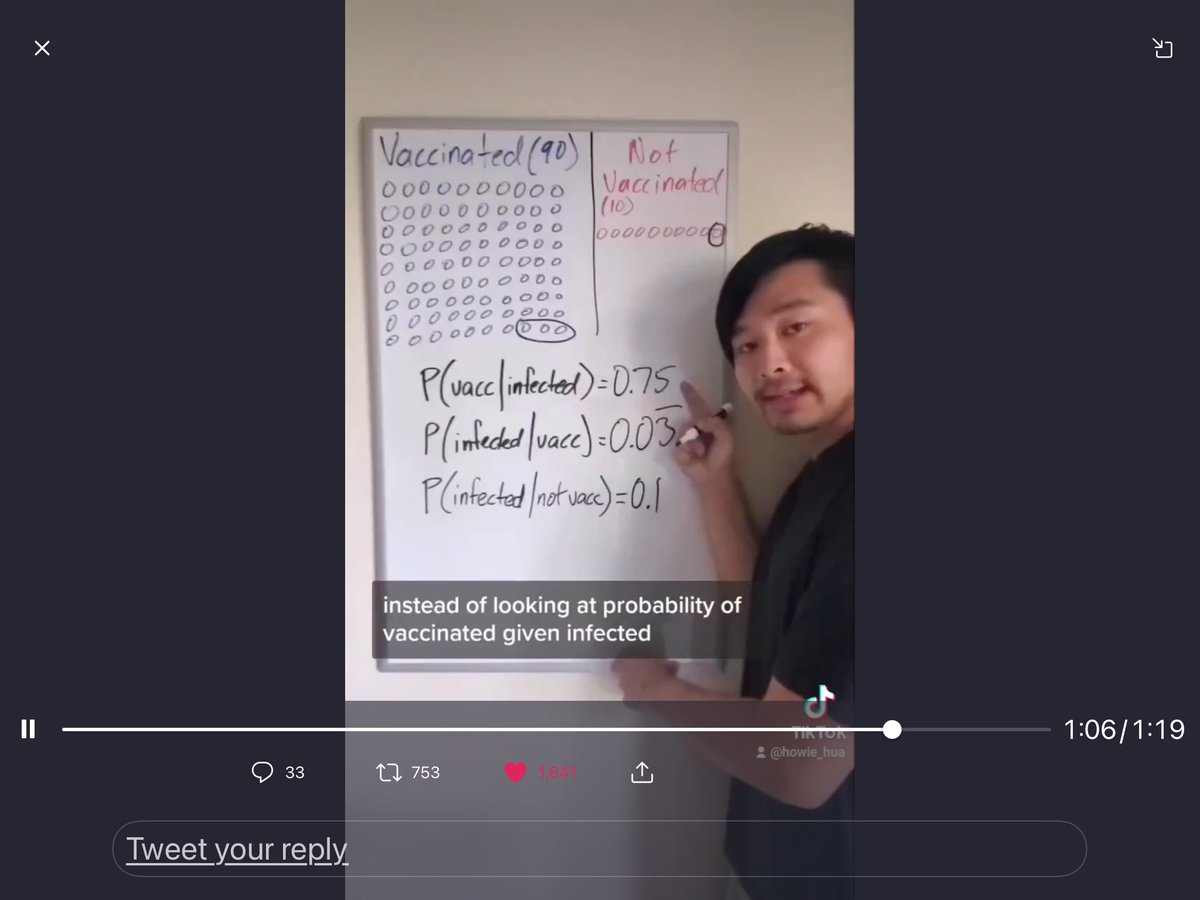
31 Jul 2021

New TikTok video: Doing my part in helping people understand the difference between P(vacc|infected) and P(infected|vacc)
2
