
Yes exactly. I think the from_dlpack is working pretty well with torch and jax, easily fast enought for even dataloading. And I haven't try mlx but I remember seen that it was not yet properly working. About tensorflow ... who is using tensorflow anyway
1
1
15

Jun 9
BULK INSERT moves flat-file data into SQL Server at maximum speed.
BULK INSERT dbo.Orders
FROM 'D:\Import\orders.csv'
WITH (
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n',
TABLOCK,
BATCHSIZE = 50000
);
TABLOCK: takes a table lock instead of row locks — dramatically faster for large loads.
BATCHSIZE: commits every N rows. Smaller batches reduce log usage but add commit overhead.
For minimal logging (bulk-logged recovery model), add ROWS_PER_BATCH and ensure the table has no clustered index or you're inserting into an empty clustered index.
BCP is the command-line equivalent when you need automation or scripting.
#SQLServer #BULKINSERT #ETL #DataLoading
16

May 21
Together these will improve my arraybuffer dataloading trick a lot. Epic stuff @expo @Baconbrix @kudochien
1
2
128

May 20
implementing this was much easier than expected since flax is basically torch i managed to do this with minimal claude assistance (claude wrote the dataloading/testing func, helped me fix some variable passing and cleaned the `transformer` init into a dataclass, but that's it)
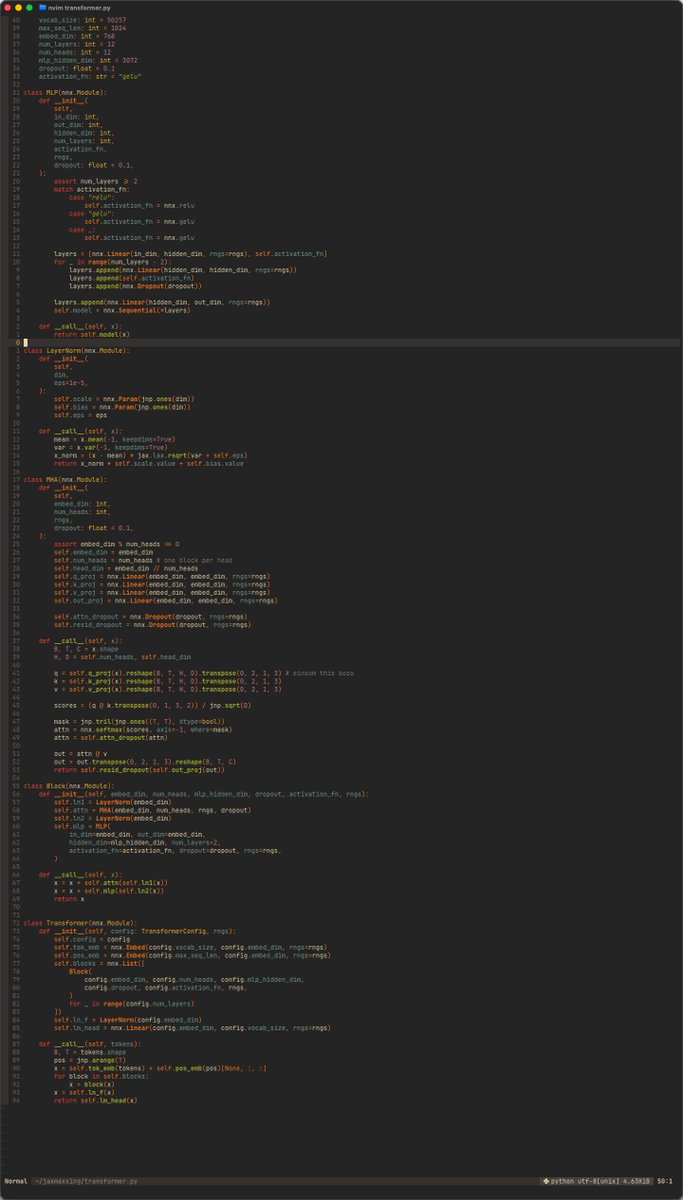

May 19

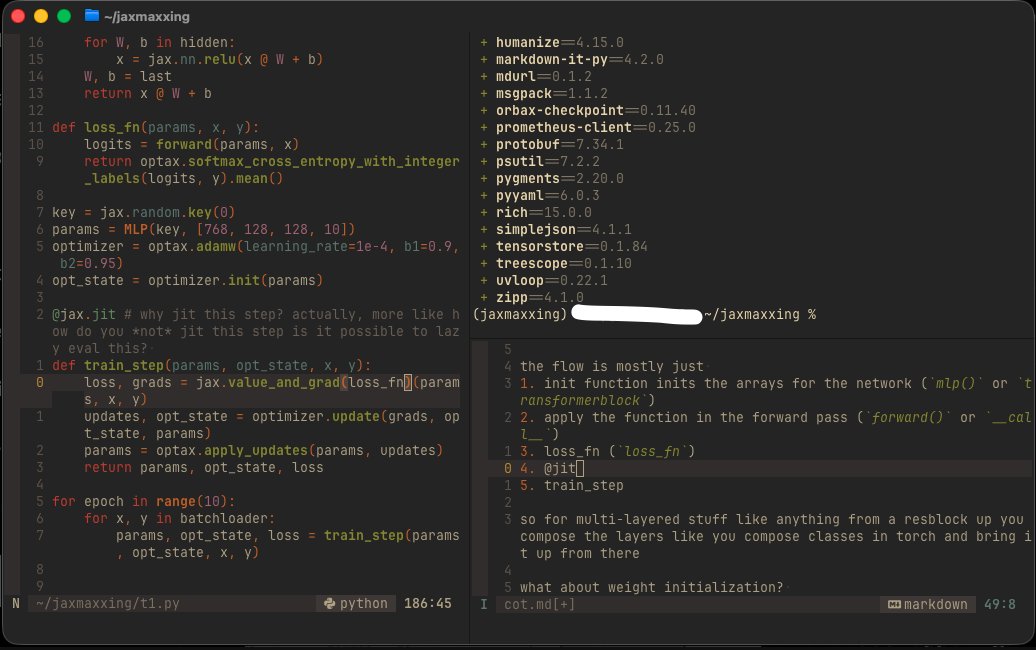
an excuse to procrastinate coursework and learn jax ig
spent ~2hrs learning jax, will try document this daily
1
2
452

May 15
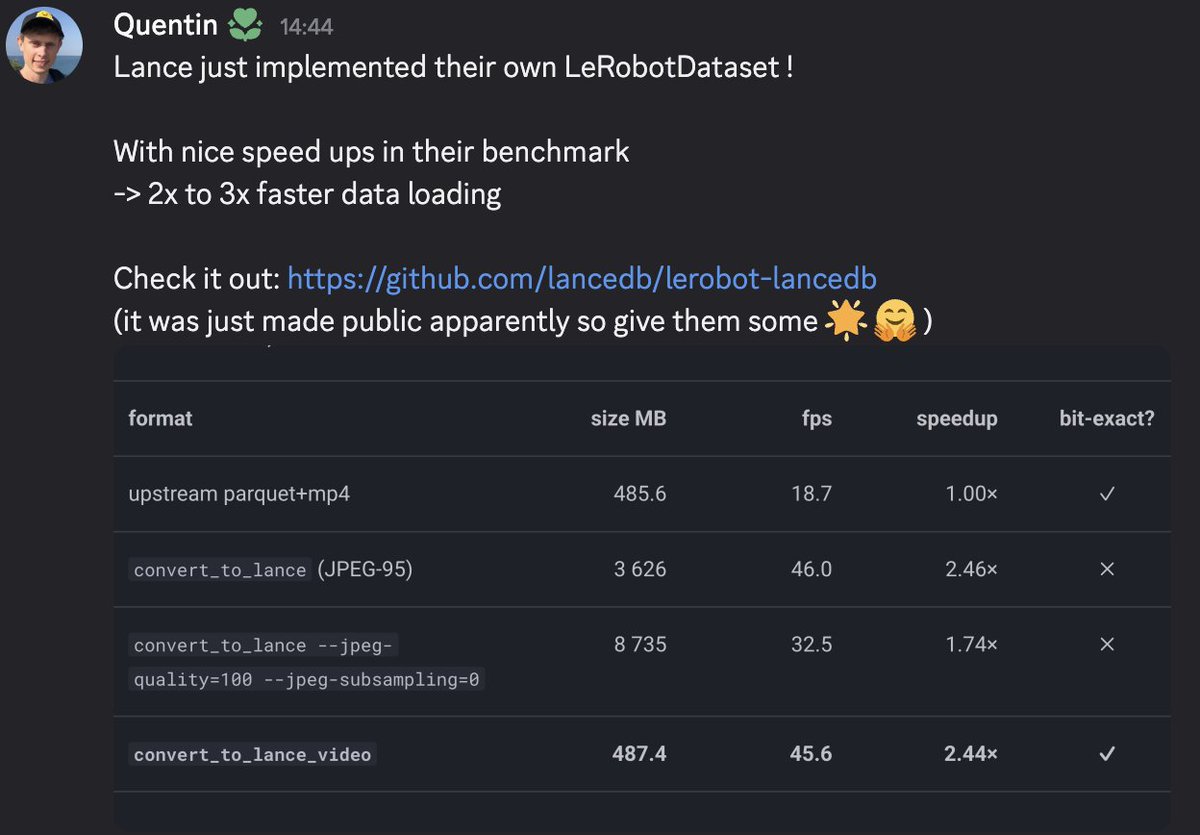
2-3x faster dataloading for LeRobot. Not bad at all :)

1
1
8
1,529

May 10
more on VLM/VLM dataloading 🤔
What are friends using ? My understanding that everything from Energon/LitData/LanceDataloader will just do local shuffles (randomize chunks shuffle locally).
But iirc this sucks for acc/loss am I wrong ? for LLMs we have always done full global
3
5
639


Feb 27
Batched training and inference is standard today. But what about dataloading?
Proud to present GetBatch, a new object store API concept to fetch arbitrarily chosen data samples in a single batch up to 15x faster than with independent GET requests. Implemented in @nvidia AIStore.

2
2
13
410

What does this optimization stack deliver?
665M tokens/sec throughput with 0.01ms batch latency and only 224MB RSS footprint.
Result: High-throughput C /CUDA dataloading for GPU training and scalable ML pipelines. (6/6)
1
3
30

Feb 4
Writing tests can not only reveal bugs in your codebase but also in open source, established codebases your project depends on. Check out georgysavva.github.io/blog/p… to see how we discovered a long-overlooked actions dataloading bug in @OpenAI's VPT repo.
2
134
Jan 27
Yes. We estimate bucket bins (1D or 2D depending on arch) and then empirically find the max batch size that fits each bin without OOM (OOMptimizer). At dataloading time we dynamically bucket data (no preprocessing needed). OK to add packing on top.
1
3
101

Jan 26
More improvements:
- Improved dataloading with prefetching. Almost removed all the overheads in the data pipeline
- Muon is fully integrated. Give it a try!
- Proper validation loop with early stopping
- Gradient accumulation (though we can squeeze more!)
Jan 21

Lot of new improvements:
- Dataloading with grain, and it comes with datalaoder checkpointing
- Layerwise lr and weight decay
- Improved and efficient KVCache for inference
- Bug fixes
- Refactor of the training code
More to come! 🤞🤞
1
23
3,016
Jan 21
Lot of new improvements:
- Dataloading with grain, and it comes with datalaoder checkpointing
- Layerwise lr and weight decay
- Improved and efficient KVCache for inference
- Bug fixes
- Refactor of the training code
More to come! 🤞🤞
Jan 2
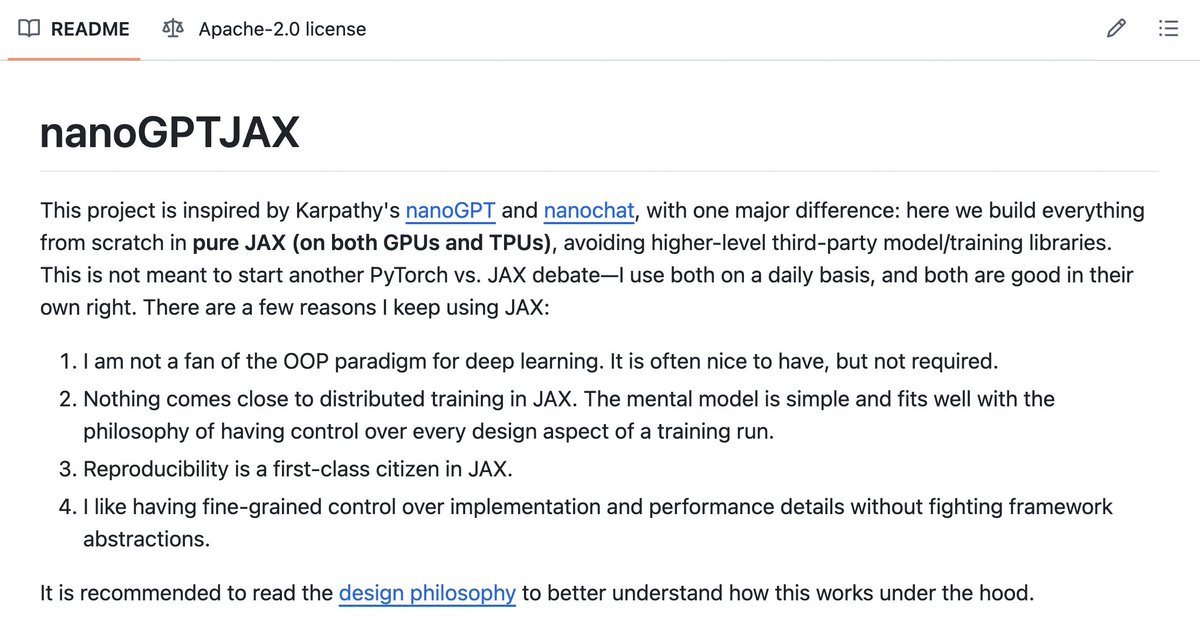
Kicking off 2026 by finally shipping a side project I've been obsessed with: nanoGPTJAX - Pure JAX LLM training (all stages) with no third-party ML libraries or frameworks. Inspired by .@karpathy nanoGPT and .@kellerjordan0 modded-nanogpt. Details below👇
23
4,299

Jan 13
IMPLICATIONS FOR HBM, DRAM, FLASH, AND HDD
HBM: BANDWIDTH REMAINS THE SCARCITY, EVEN IF BYTES PER OPERAND FALL
At the representation level, NVFP4 reduces operand payload versus BF16/FP16, but the end-to-end memory traffic profile depends on where master copies live and how often quantization is repeated. Transformer Engine examples indicate parameters may be stored in higher precision (e.g., BF16) and quantized to FP4 for compute, which implies additional read/convert/write steps relative to directly consuming BF16 in GEMM. In that regime, NVFP4 can simultaneously (a) reduce the bytes consumed by the GEMM operand stream into tensor cores and (b) introduce extra memory traffic for quantization and scale-factor handling. The net bandwidth relief is therefore not guaranteed; it becomes a kernel fusion and caching question.
DGX B200 specifications point to very high HBM provisioning: 1,440GB total GPU memory and 64 TB/s HBM3e bandwidth in the system configuration. Arithmetic implies ~180GB HBM per GPU and ~8 TB/s bandwidth per GPU in that specific platform configuration (derived from the published totals). The combination of extremely high FP4 compute throughput and high HBM bandwidth indicates that the expected operating point remains aggressively bandwidth-aware. If FP4 increases tensor-core throughput faster than HBM bandwidth scales, the binding constraint can migrate from compute to memory for an increasing fraction of kernels (including quantization/amax reductions, scale swizzles, and any non-GEMM layers left in higher precision).
From a supply-chain perspective, broader adoption of FP4 training is more likely to increase total “useful compute” per installed GPU-hour than to reduce absolute demand for high-end HBM. Efficiency gains have historically been reinvested into larger models, longer token horizons, and more experiments; the NVFP4 paper itself frames the motivation as reducing time/compute/energy barriers to frontier training, not as reducing absolute ambition. The more plausible near-term impact is accelerated demand for newer HBM generations to keep up with rapidly scaling compute density, rather than a structural reduction in HBM content per GPU.
DRAM: POTENTIAL SECOND-ORDER PRESSURE VIA HOST PIPELINES AND OFFLOAD STRATEGIES
System DRAM primarily supports dataloading, CPU-side preprocessing, and in some training stacks, offloading of optimizer state or activations. NVFP4’s direct effect on host DRAM is limited because dataset size and tokenization pipelines are unchanged. However, faster step times can increase pressure on the input pipeline to sustain higher batch delivery rates, raising the premium on host memory bandwidth, CPU core availability, and technologies such as GPUDirect Storage or NIC offload. The scale of this effect is workload-dependent and typically smaller than the GPU/HBM/interconnect envelope, but it becomes more relevant in regimes where the training loop is already close to input-bound (multi-modal, heavy augmentation, retrieval-augmented workloads).
FLASH STORAGE: TRAINING THROUGHPUT CAN INCREASE IO REQUIREMENTS EVEN IF CHECKPOINT SIZE DOES NOT FALL PROPORTIONALLY
NVFP4’s weight and optimizer state representation in practice is often dominated by higher-precision master weights and optimizer states, so checkpoint sizes may not compress as much as the “4-bit” narrative would suggest unless the full training stack adopts low-precision optimizers and checkpoint formats. NVFP4 can still increase aggregate storage demand through a different channel: if training becomes cheaper and faster, experimentation rate increases, multiplying checkpoints, intermediate artifacts, and dataset variants. Additionally, higher throughput can motivate higher reliance on local NVMe caching to avoid network filesystem bottlenecks.
HDD STORAGE: LIMITED DIRECT IMPACT, BUT “MORE RUNS” AND “MORE DATA” SCENARIOS CAN INCREASE COLD STORAGE REQUIREMENTS
HDD remains the economic tier for large-scale cold datasets and archival checkpoints. NVFP4 does not shrink raw training corpora. The most plausible linkage is indirect: lower training cost increases dataset scale and frequency of refresh, expanding cold storage needs over time.
IMPLICATIONS FOR NETWORKING, OPTICAL INTERCONNECTS, AND OPTICAL NETWORKING
INTRA-NODE / INTRA-RACK: NVLink AS A FIRST-CLASS REQUIREMENT
The performance regime implied by FP4 training intensifies dependence on high-bandwidth, low-latency intra-node connectivity. NVIDIA’s Blackwell Ultra discussion cites NVLink 5 at 1.8 TB/s bidirectional per GPU and scaling to large topologies, framing NVLink as an enabling fabric for rack-scale GPU pools. DGX B200 lists 14.4 TB/s aggregate NVLink bandwidth at the system level, consistent with 8 GPUs each with 1.8 TB/s. As compute throughput rises, the cost of synchronization and communication becomes more acute in wall-clock terms, increasing the value of fabrics that minimize collective latency and enable high all-to-all bandwidth for tensor/pipeline parallelism and MoE routing.
INTER-NODE: QUANTIZED COMMUNICATION REDUCES VOLUME BUT ADDS GLOBAL-STATISTICS DEPENDENCIES
Quantizing activations/gradients for communication can reduce bytes transferred (theoretical payload reductions of ~3.5x–4.0x versus BF16 depending on metadata and scaling scheme), which could relax pressure on scale-out network bandwidth. Radical Numerics Part 2, however, highlights that NVFP4 quantization may require global amax agreement across ranks, introducing an all-reduce dependency that can increase sensitivity to network latency and collective efficiency. The net effect is a trade-off: fewer bytes per all-gather versus more synchronization steps. In well-provisioned InfiniBand/NVLink-heavy environments, the reduction in volume can be material; in Ethernet-heavy or oversubscribed environments, the added synchronization can erode gains.
OPTICAL INTERCONNECTS AND OPTICAL NETWORKING
As GPU clusters scale, electrical reach constraints and port density push more links into optical form factors (OSFP/QSFP variants). DGX B200’s networking description references OSFP ports servicing ConnectX-7 VPI, consistent with high-speed network attachment where optics are common at scale. NVFP4’s main effect on optics demand is indirect: if FP4 increases the achievable compute per rack, more high-speed ports and switch bandwidth are typically required to keep the system balanced, even if per-message payloads shrink. Additionally, any move toward rack-scale composability and larger GPU pools tends to increase east-west traffic and the need for optical networking gear in the fabric.
IMPLICATIONS FOR POWER AND THERMAL MANAGEMENT
NVFP4 is motivated partly by energy efficiency. The NVFP4 paper frames frontier training as requiring 10s to 100s of yottaflops and emphasizes compute and energy costs as binding constraints, motivating narrower precision. Lower-precision tensor cores generally improve operations-per-watt at the math unit level, but the system-level outcome is shaped by 3 countervailing effects:
REBOUND EFFECT: If training becomes cheaper per token, more total tokens, larger models, and more experiments can be run, pushing aggregate power consumption upward even as efficiency improves.
BALANCE SHIFT: As compute becomes faster, a larger fraction of total energy can shift toward data movement (HBM, on-package interconnects, NICs, switches). This increases the value of architectural features that reduce memory traffic (fusion, on-chip buffering) and fabric energy per bit.
POWER DENSITY CONTINUES TO RISE: DGX B200 lists ~14.3 kW maximum system power for an 8-GPU system, indicating that high-density thermal design remains a core constraint regardless of per-operation efficiency. In this context, NVFP4’s most immediate operational impact can be improved throughput within a fixed thermal envelope, but it also accelerates the need for advanced cooling (liquid) and power delivery upgrades as cluster density rises.
ADJACENT RESEARCH SIGNALS: WHERE NVFP4 MAY EVOLVE NEXT
FOUR OVER SIX (4/6) ADAPTIVE BLOCK SCALING
Cook et al. propose “Four Over Six” as a modification to NVFP4 quantization that evaluates 2 potential scale factors per block (intuitively toggling the effective utilization of the FP4 codebook near its maximum), motivated by the observation that floating-point quantization error is largest for near-maximal values and can dominate downstream degradation. The abstract claims that 4/6 can prevent divergence in several pretraining settings and bring loss closer to BF16 compared with prior NVFP4 recipes, while being implementable efficiently on Blackwell. If validated broadly, this indicates that NVFP4 stability is still an active optimization frontier, and that incremental algorithmic refinements can have outsized commercial impact by widening the set of architectures and training regimes that can safely exploit FP4.
QUARTET AND “NATIVE FP4” TRAINING ALTERNATIVES
Castro et al. introduce Quartet as an approach for accurate end-to-end FP4 training (major computations in low precision) and argue for a low-precision scaling law to quantify accuracy-vs-computation trade-offs. The work is implemented with optimized CUDA kernels tailored for Blackwell GPUs and reports successful training of billion-scale models. This matters for ecosystem dynamics because it suggests multiple viable algorithmic paths to FP4 training beyond NVIDIA’s in-house NVFP4 recipe, potentially accelerating open-source adoption and diversifying software stacks that exploit FP4 hardware. The competitive moat then shifts from “format ownership” to “platform execution quality,” including kernel libraries, compiler maturity, and integration into mainstream frameworks.
RISKS, LIMITATIONS, AND MONITORING POINTS
ALGORITHMIC ROBUSTNESS RISK
NVFP4’s success is contingent on a multi-part stabilization recipe (RHT, SR, 2D scaling, selective precision). The degree to which this recipe generalizes across model families (dense Transformer, MoE, hybrid state-space models, multi-modal architectures) and across extreme training regimes (very long context, heavy RLHF/online learning dynamics, sparse activation distributions) remains an empirical question. The presence of subsequent work like Four Over Six suggests that baseline NVFP4 can still face divergence and accuracy gaps in some settings, implying that “stable FP4” is not yet a solved problem in all regimes.
SYSTEMS COMPLEXITY AND SOFTWARE MATURITY RISK
The kernel deep dive shows that NVFP4 performance depends on fragile, highly specialized pipelines: persistent kernels with warp specialization, explicit tmem management, mbarrier choreography, TMA descriptors, and architecture-specific conversion and store instructions. This complexity raises operational risks: compiler regressions, library version incompatibilities, and performance cliffs for “non-ideal” shapes can materially reduce realized gains. cuBLAS requirements for block-scaled FP4 emphasize alignment and optimal dimension constraints, consistent with the existence of such cliffs.
LAYOUT AND PADDING OVERHEAD
Scale-factor swizzling and layout expectations can force padding that partially offsets the theoretical memory/communication advantages of FP4. This creates architectural pressure toward dimension choices that are multiples of 16/128 and batch/sequence structures that avoid ragged edges. For inference serving with highly variable batch sizes and sequence lengths, these constraints can reduce utilization unless mitigated by dynamic batching, shape bucketing, or specialized kernels.
SHIFTING BOTTLENECKS TO NETWORK AND MEMORY
Quantized communication can reduce bandwidth, but global amax synchronization can add latency sensitivity. As tensor-core compute scales, the system can become more sensitive to collective efficiency, switch oversubscription, and topology, increasing the strategic importance of high-end networking (NICs, switches) and potentially optics. In parallel, higher compute throughput can increase the premium on HBM bandwidth and memory subsystem efficiency, supporting continued demand for higher-bandwidth HBM generations rather than reducing memory importance.
ECOSYSTEM IMPLICATIONS SUMMARY BY COMPONENT
NVIDIA GPU (AND COMPETING ACCELERATORS)
NVFP4 strengthens the value proposition of Blackwell-class GPUs by tying practical training efficiency gains to FP4 block-scaled tensor cores and Blackwell-specific instruction support. Over time, cross-vendor block-scaled FP4 support (e.g., Triton claiming both NVIDIA and AMD support paths) can compress differentiation at the format level, but near-term differentiation likely persists in kernel maturity, library support, and end-to-end framework integration.
HBM (HBM3e/HBM4)
FP4 training does not eliminate HBM constraints; it reshapes them. Higher tensor-core throughput increases the likelihood that HBM bandwidth and on-package interconnects become bottlenecks, sustaining demand for higher-bandwidth HBM solutions. DGX B200’s published HBM3e bandwidth and capacity emphasize that memory provisioning remains central even in FP4-optimized platforms.
DRAM (SYSTEM MEMORY)
Primary impact is indirect via higher dataloader and orchestration throughput requirements and potential offload strategies. Direct reduction in DRAM needs is not implied by NVFP4 because master weights and optimizer states can remain higher precision in common training stacks.
FLASH (SSD/NVMe)
Indirect positive pressure through higher experimentation rate, increased checkpoint throughput, and greater use of local NVMe caches to sustain higher training throughput. Checkpoint size reductions are possible but not assured without low-precision optimizer/checkpointing adoption.
HDD
Limited direct linkage; indirect growth through larger and more frequent dataset refreshes and archival of increased run volume.
NETWORKING (ELECTRICAL OPTICAL)
Quantized collectives can reduce byte volume but can add synchronization points (global amax). NVLink bandwidth scaling remains critical intra-rack, while scale-out network efficiency becomes more important as step time shrinks. Optical demand is likely to remain structurally supported by cluster scaling and port bandwidth growth, even if per-message payload shrinks.
POWER AND HEAT
Platform-level power density remains extreme; DGX B200 lists ~14.3 kW maximum system power, and FP4’s main contribution is higher work per unit energy and time, not necessarily lower absolute facility power demand due to rebound effects.
BOTTOM LINE IMPLICATIONS FOR THE GENERATIVE AI ECOSYSTEM
NVFP4 materially increases the plausibility of stable FP4 pretraining at scale, but it does so by moving complexity into tightly engineered kernels, strict layout contracts, and hardware-dependent primitives. If NVFP4 (and successor refinements like Four Over Six) broadens from selected reference models into mainstream pretraining stacks, the likely macro effect is an acceleration of compute throughput per deployed GPU and a renewed “balance problem” across the AI factory: HBM bandwidth, intra-rack fabrics, scale-out networking collectives, and power/thermal density become increasingly binding as FP4 compute scales faster than the surrounding system. The net consequence is supportive for NVIDIA’s latest-generation GPU upgrade cycle and for adjacent high-bandwidth memory and networking ecosystems, with the caveat that any sustained step-change in training efficiency can, at the margin, moderate GPU unit demand per trained model while simultaneously expanding the feasible frontier of model size, token horizon, and experimentation frequency. The direction of travel implied by the cited work is that efficiency gains are more likely to be reinvested into ambition than harvested as cost savings, preserving secular demand for GPUs, HBM, networking, and power/cooling infrastructure, while increasing the premium on software stacks capable of extracting FP4 performance without destabilizing training.
3
5
802

25 Dec 2025
🎄🎉Happy Holidays everyone, I wish health to every single one of you🎉🎄
What is Remix: a full stack web framework built on web standards.
Remix helps you build fast, resilient web apps by leaning into the browser’s native strengths (forms, HTTP, caching) and by making server data and UI routing work together instead of fighting each other.
@remix_run
🔗Tap below to dive deep into it👇
bytebrief.vercel.app/blog/wh…
#Remix #ReactFramework #FullStack #WebDevelopment #ReactRouter #ProgressiveEnhancement #NestedRouting #DataLoading #JavaScript #TypeScript #Frontend #ServerSideRendering
1
3
32

29 Nov 2025
Dataloading en acció gentilesa d'@a320cat .
I sí, obviament, com veieu en l'aparell, el dataloading en aviació també està estandarditzat, es tracta del protocol l'Arinc 615.


1
13
1,138

13 Nov 2025
This is so cool to see this, cc anyone @huggingface! 🤩
"Using Lance I was able to achieve high throughput dataloading for multi-node training on ~150B rows, with 10-20x the throughput of the streaming data loader from the huggingface/datasets library."
github.com/huggingface/datas…
2
6
410

This is clearly false. Nogil solves many real world issues, e.g. dataloading for machine learning (see @BenTheEgg's tweets). Why are you telling blatant lies?
16 Jun 2024

Week end experiment: bottlenecked on an export path by fetching payloads from S3 (1-10 per image, 2-20MB per payload), some CPU heavy operations per payload (image resize, ..).
Single node (I know, there are probably nice frameworks to throw many machines), Python/Go mini 🧵
27
2,986

🥳 Welcome another #Lancelot at the Roundtable, Ethan Rosenthal 🎉
On Ethan’s first day at @runwayml , he was tasked with building a multimodal 𝗱𝗮𝘁𝗮 𝘀𝘆𝘀𝘁𝗲𝗺 𝘁𝗵𝗮𝘁 𝘀𝘂𝗽𝗽𝗼𝗿𝘁𝗲𝗱 𝗯𝗼𝘁𝗵 𝗱𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗱𝗮𝘁𝗮𝗹𝗼𝗮𝗱𝗶𝗻𝗴 𝗮𝗻𝗱 𝗲𝘅𝗽𝗹𝗼𝗿𝗮𝘁𝗼𝗿𝘆 𝗱𝗮𝘁𝗮 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀. He said, “𝘛𝘩𝘢𝘵’𝘴 𝘢 𝘵𝘦𝘳𝘳𝘪𝘣𝘭𝘦 𝘪𝘥𝘦𝘢. 𝘠𝘰𝘶 𝘴𝘩𝘰𝘶𝘭𝘥 𝘯𝘦𝘷𝘦𝘳 𝘵𝘳𝘺 𝘵𝘰 𝘥𝘰 𝘵𝘩𝘪𝘴 𝘸𝘪𝘵𝘩 𝘰𝘯𝘦 𝘴𝘺𝘴𝘵𝘦𝘮!". He then found #Lance and did exactly what he said not to do. 😆

1
2
7
1,181

13 Aug 2025
Temporal Graph Modeling
Efficient and Modular Machine Learling on Temporal Graphs
TGM is a research open source library designed to accelerate training workloads over dynamic graphs and facilitate prototyping of temporal graph learning methods.
The main goal is to provide an efficient abstraction over dynamic graphs to enable new practitioners to quickly contribute to research in the field. It natively supports both discrete and continuous-time graphs.
Library Highlights
⏳ First library to support both discrete and continuous-time graphs
🔧 Built-in support for TGB datasets, MRR-based link prediction, and Node Property Prediction
✨ Modular, intuitive API for rapid model prototyping
:atom: Efficient dataloading with edge and time-based batching
✔️ Validated implementations of popular TG methods
⚡ Not that fast yet but it will be soon
github.com/tgm-team/TGM
#AI #DataScience #EmergingTech #Research #OpenSource #MachineLearning #Temporal
--
The Year of the Graph's next newsletter on all things Knowledge Graph, Graph Analytics / Data Science / AI and Semantic Tech is due in Autumn 2025.
Subscribe and follow to be in the know. Reach out if you'd like to be featured 👇
yearofthegraph.xyz/newslette…

5
29
1,943