
【画像生成AIの心臓部】拡散モデルの仕組みを簡単解説!🎨
画像生成AIの裏側で大活躍している「Diffusion Model(拡散モデル)」の仕組みを解説します!
一言で言うと「ノイズから綺麗な画像を復元する」技術です。
1. 拡散:綺麗な画像に少しずつノイズを加えていき、完全なノイズ状態にします。
2. 逆拡散:そのノイズから元の綺麗な画像に戻す方法をAIが学習します。
このプロセスを繰り返すことで、ノイズから高精度な画像を再構築できるようになります。仕組みを知ることで、AI技術の理解がさらに深まります!✨
#画像生成AI #DiffusionModel
1
1
9
1,345

DiffusionGemmaが公開された。専用GPU上でトークン生成が最大4倍高速化。24GB VRAMの消費者向けGPUでも実用可能。
並列生成+自己修正に特化した速度を最優先したモデル。
詳細はこちら→ goo.gle/4vG0xcI
#AI #gemma #diffusionmodel #オープンソースモデル
Jun 10

DiffusionGemma is our new experimental open model with up to 4x faster output on dedicated GPUs.
Instead of predicting word-by-word, it generates entire blocks of text simultaneously. This lets the model self-correct and format complex markdown in real time.

ALT Intelligence vs Latency chart showing DiffusionGemma 26B A4B is much faster than Gemma 4 models with high intelligence.
200

May 21
LargeLanguageModel(テキスト生成)とDiffusionModel(マルチメディア生成)で、後者のみを生成AIと認識してる感じでしょうかね
テストの文脈理解するのはLLMの働きですので
1
14
5,758

A person walks around campus for 5 hours with cameras.
That's it. That's the training data.
The result? A humanoid robot that traverses unseen buildings, crowds, and glass walls — zero robot data, zero finetuning.
EgoNav is here.
egonav.weizhuowang.com/
None of these behaviors were pre-programmed:
• Waiting for a door to open before entering
• Steering around glass walls invisible to depth sensors
• Yielding to pedestrians and resuming
• Re-routing when furniture is rearranged
All emerged from 5 hours of a human walking around. The prior is real. (1/6)
#Humanoid #Robotics #DiffusionModel #EgoNav
15
67
305
35,527

Just got to know about diffusion model for generating images from noise.
even the looking at the idea from top is like bliss, who thought of it?
#diffusionmodel #AI
2
1
42

Mar 16
Recommend an article shared by Zhihu contributor tomsheep: PKU & ByteDance just open-sourced Helios, a long video generation model hitting 19.5 FPS real-time inference on a single H100 GPU, crossing the "real-time video generation" threshold!
Only downside: 14B params are too heavy for consumer GPUs. Let's break down its key tech insights👇
🎬 Current State of Video Generation
Diffusion-based video models (Sora, Keling, Wan 2.x) produce stunning short clips but remain in offline short-video mode. The ultimate goal is a continuous, interactive "world model" (AI NPC visuals, real-time game rendering, endless video streams), requiring minute-level long consistency ultra-low latency, not just brute-force compute.
🛣️ 3 Core Paradigms Compared
1️⃣ Pure Diffusion Video
• Logic: Treat video as a 3D spatiotemporal tensor, learn global joint distribution
• Pros: Strong global consistency, smooth dynamic transitions (models: Wan 2.x, Sora)
• Cons: Extremely high compute complexity, easy memory explosion; global synchronous denoising, no streaming support
2️⃣ Pure AR Video
• Logic: Split video into time-axis tokens, frame-by-frame causal prediction
• Pros: Native KV-Cache support, theoretically unlimited long video (models: CogVideo, VideoPoet)
• Cons: Extreme compression causes detail loss; token-by-token generation is slow, error-prone
• P(v) = \prod_{t=1}^{T} P(x_t | x_{\lt t}) \\
3️⃣ AR-Diffusion (Helios Core)
• Logic: Time progression handled by AR, spatial/local dynamics by Diffusion
• Pros: Aligns with physical laws, supports streaming, balances long consistency & top visual quality, solving pain points of both prior paradigms
• P(x_{1:T}) = \prod_{t=1}^{T} P(x_t \mid x_{\lt t}) \\
🔧 Helios Core Design (Based on Wan-2.1-T2V-14B)
Instead of training from scratch, Helios performs "architectural surgery" on a top bidirectional diffusion model, inheriting its spatial generation capability and transforming it into a streaming autoregressive engine:
1️⃣ Unified History Injection 🧩
Ditches complex causal masking, uses Guidance Attention to strictly separate clean historical frames from noisy current frames, avoiding reverse contamination. A single architecture natively supports T2V/I2V/V2V tasks.
2️⃣ Lightweight Anti-Drift Mechanism 🚫💨
3 zero-overhead strategies to fix long-video error accumulation:
• Relative RoPE: Solves position drift & repeated actions
• First-Frame Anchor: Retains the first frame as a global anchor, fixing color/identity drift
• Frame-Aware Corrupt: Adds noise/adjusts exposure to historical frames during training, boosting long-sequence robustness
⚡ Inference Acceleration: Deep Flow Compression (Key to 19.5 FPS)
1️⃣ Token Perspective: Spatiotemporal Extraction 🗜️
• Multi-Term Memory Patchification: Divides history into short/medium/long windows, higher compression for older history, constant input tokens to avoid memory explosion
• Multi-Scale Denoising: Low-res for global structure early on, full-res for fine details later, doubling throughput without quality loss
2️⃣ Step Perspective: Extreme Compression 🚀
Combines Distribution Matching Distillation (DMD) Adversarial Post-Training, compressing denoising steps from dozens to 3, breaking the quality ceiling of traditional distillation for single-card real-time speed.
🎯 Key Helios Breakthroughs
✅ Paradigm fusion: AR-Diffusion scaled to "single-card real-time, infinite-length" engineering scale
✅ Clean history injection: Guidance Attention perfectly decouples history & current frame computation
✅ Lightweight anti-drift: 3 simple designs eliminate long-video error accumulation
✅ Constant token context: Avoids 3D attention memory explosion
✅ 3-step inference: Distillation adversarial training achieves real-time speed & quality
🔮 Future Outlook
14B params are still unfriendly to consumer GPUs — looking forward to a lightweight version! Helios is a major breakthrough for real-time AI video, game AI, and world models. The era of real-time long video generation is here🌊
📖 Full article: zhihu.com/question/201509245…
#AI #VideoGeneration #DiffusionModel #Helios #ByteDance #PKU



1
3
11
1,149

Our paper has been published in npj Drug Discovery!
“Interaction-constrained 3D molecular generation using a diffusion model enables structure-based pharmacophore modeling for drug design”
nature.com/articles/s44386-0…
#DrugDiscovery #DiffusionModel
🧵 Thread below
1
6
30
7,313

NNsight 0.6 also introduces first-class support for VisionLanguageModel (e.g., LLaVA, Qwen-VL) and DiffusionModel (e.g., Stable Diffusion, Flux)! Available remote on NDIF soon 👀

1
5
154

Feb 11
Stable Diffusion is a powerful open-source text-to-image model available on @Qubrid_AI 🚀
Built for high-quality image generation, creative design, and visual storytelling from simple text prompts.
Describe a scene in words, and it transforms your imagination into stunning visuals in seconds 🎨✨
From product mockups and marketing creatives to anime art and realistic portraits, Stable Diffusion makes visual creation effortless.
Try this model on Qubrid AI 👉 qubrid.com
#diffusionmodel #opensource #aimodels
1
4
224
PepEDiff: Zero-Shot Peptide Binder Design via Protein Embedding Diffusion
1. Researchers introduce PepEDiff, a novel peptide binder generator that designs binding sequences without relying on intermediate structure prediction. This approach leverages a continuous latent space derived from a pretrained protein embedding model, enhancing sequence and structural diversity.
2. The method employs a diffusion model to generate peptide sequences directly in the embedding space, conditioned on the target receptor sequence and pocket residues. This zero-shot strategy explores beyond known peptide distributions, enabling the discovery of novel binders.
3. Evaluated on the challenging TIGIT target, PepEDiff outperforms state-of-the-art methods in sequence diversity, structure diversity, and binding affinity. The model demonstrates superior performance in both general tests and the TIGIT case study, highlighting its potential for therapeutic applications.
4. The study incorporates a latent-space exploration mechanism to access binding-relevant regions outside the empirical peptide distribution. By perturbing known peptide embeddings, the model generates binders in previously unseen regions of the protein space.
5. Molecular dynamics simulations validate the stability and binding affinity of PepEDiff-generated peptides. The top binder for TIGIT shows stronger interactions and more stable engagement with the target compared to other methods.
📜Paper: arxiv.org/abs/2601.13327v1
#PeptideBinder #ProteinEmbedding #DiffusionModel #DrugDiscovery #AIinBiology

5
37
1,950
Designing AAV Capsid Protein with Viability-Guided Diffusion Model
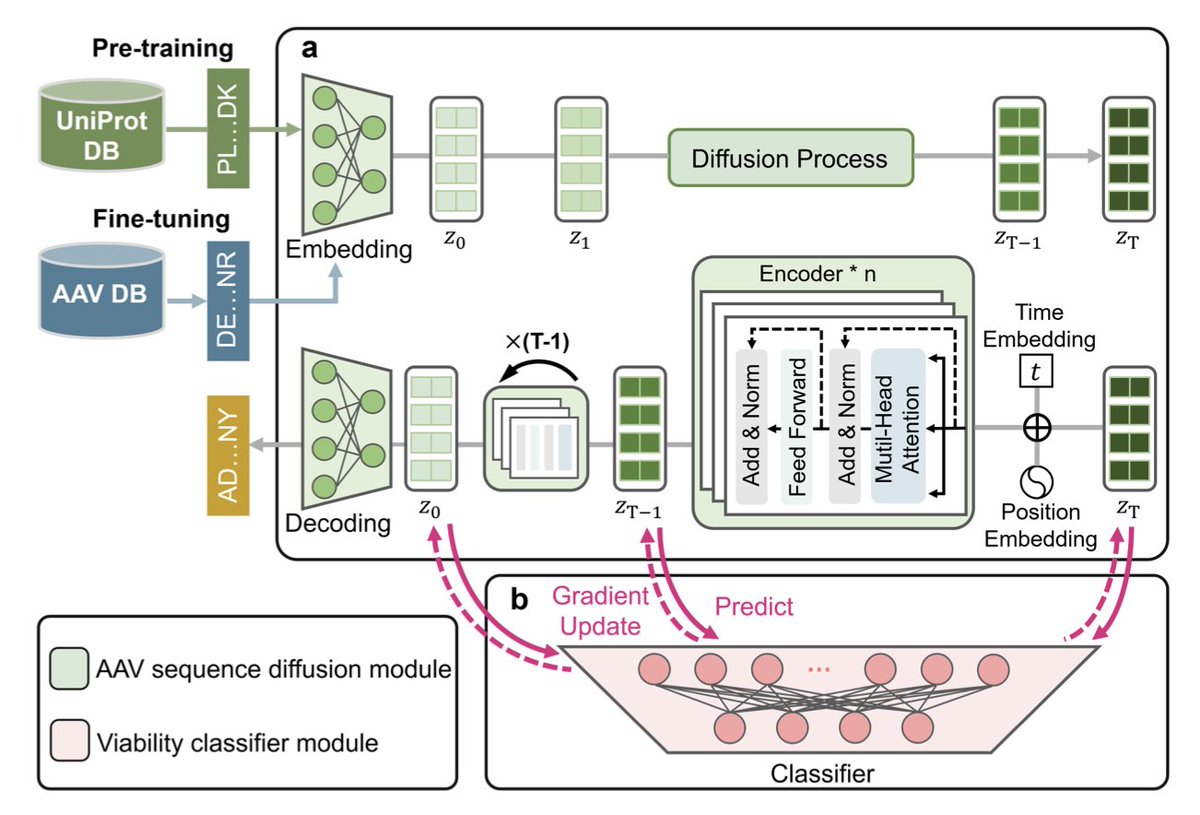
1. A new study introduces AAVDiffusion, a novel viability-guided diffusion model for designing viable AAV capsid proteins. This model leverages a diffusion process to iteratively denoise Gaussian vectors into AAV capsid protein sequences, integrating a viability classifier to enhance the generation of viable sequences.
2. AAVDiffusion outperforms existing methods in generating viable AAV sequences, achieving superior viability probabilities across multiple classifiers. The model's ability to generate sequences with enhanced stability and high binding affinity to the human transferrin receptor (hTfR1) suggests potential for crossing the blood-brain barrier.
3. The study demonstrates that AAVDiffusion effectively captures the intrinsic relationships within viable AAV sequences, preserving critical structural features while introducing sequence diversity. This is achieved through pre-training on the UniProt database and using a Transformer-based architecture for denoising.
4. A selection workflow identified 196 AAV candidates with higher binding affinities to hTfR1 than BI-hTfR1, a recently designed AAV variant. These candidates exhibit diverse binding modes and structural variations, highlighting the potential for novel gene therapies targeting the central nervous system.
5. AAVDiffusion provides a powerful computational method for generating viable AAV capsids, advancing the development of next-generation gene therapy vectors. The model's integration of viability-guided generation and structural optimization represents a significant step forward in AAV capsid design.
📜Paper: biorxiv.org/content/10.64898…
#AAVDiffusion #GeneTherapy #AAVCapsidDesign #DiffusionModel #ComputationalBiology
1
18
1,563

26 Dec 2025
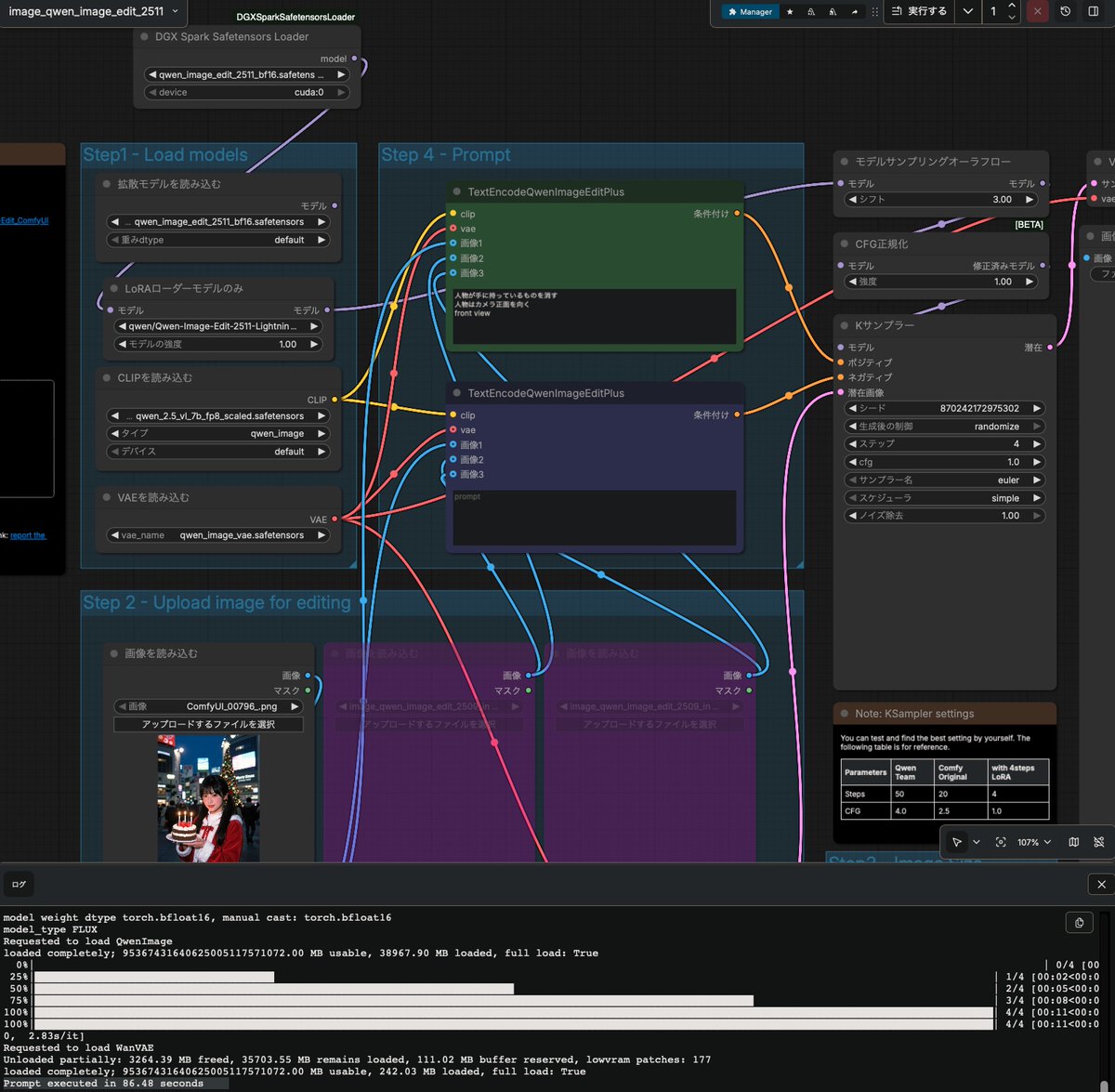
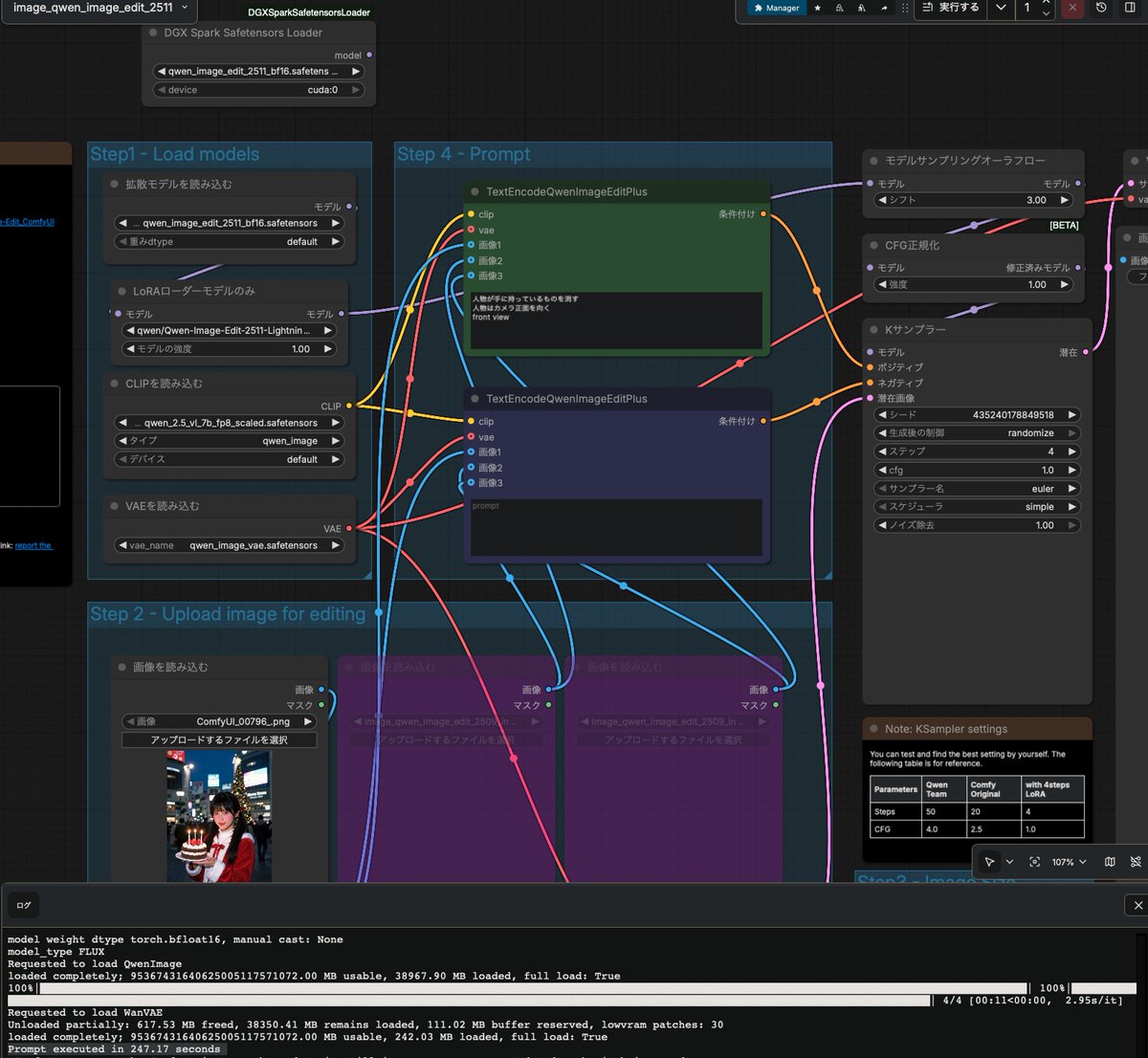
DGX SparkでComfuUI を使う方へお勧め
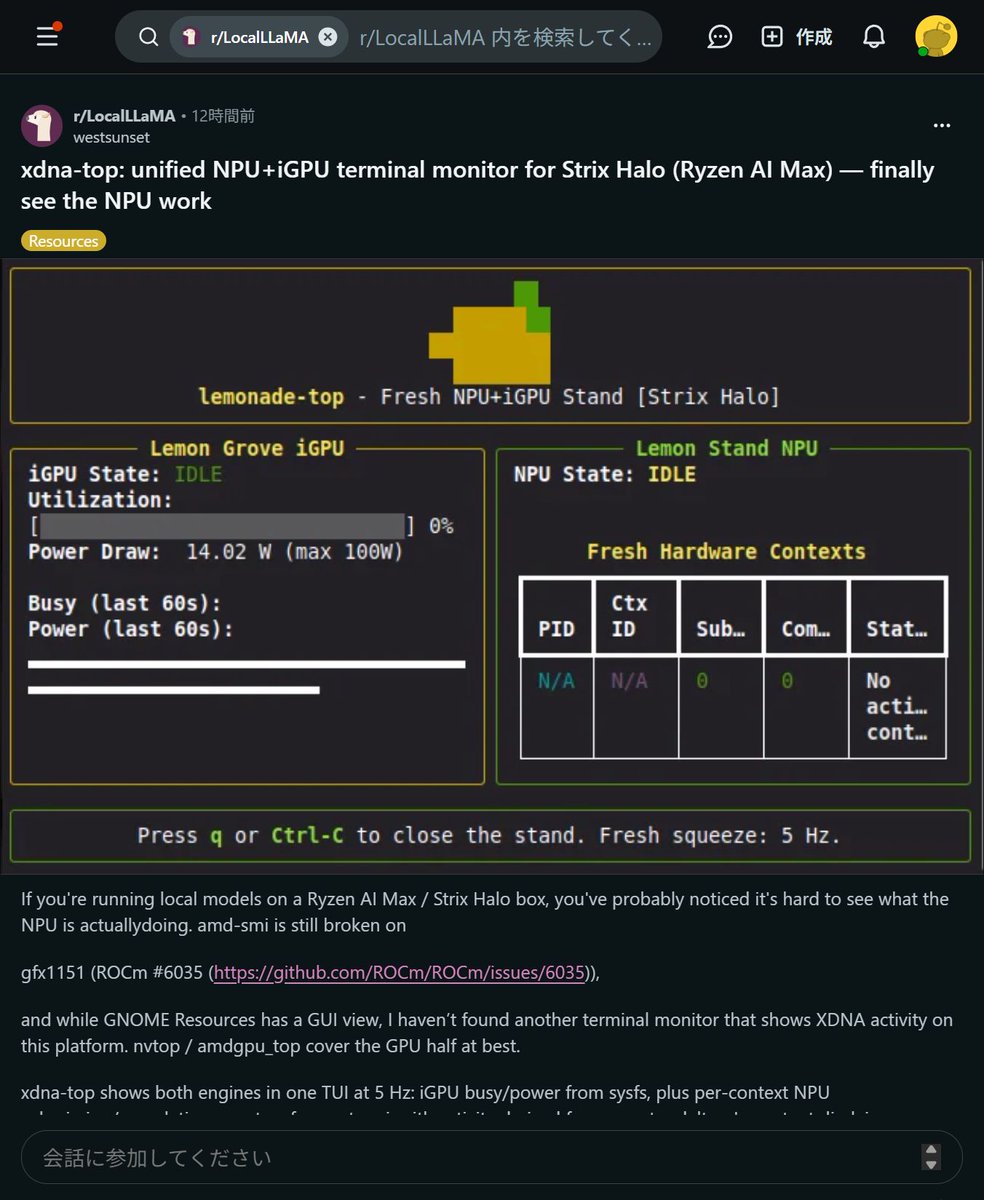
github.com/phaserblast/Comfy…
DiffusionModelの読み込みを高速化(感謝)
起動直後 1枚目生成:Qwen-Image-Edit-2511bf16 4step LoRA
あり:86.48 sec
なし:247.17 sec

1
12
93
11,098

22 Dec 2025
HitPaw VikPea Mac V5.1.0 is here! 🍎🚀
✨ New AI Video Generator: Create videos from text or images
🧠 New AI Generative Model: Diffusion-powered results for low-res videos
🎬 Upgraded Frame Interpolation: Smoother, more natural motion
Upgrade now ↓
🔗 bit.ly/4aLG3rZ
#hitpawvikpea #macapp #aivideo #aigenerator #diffusionmodel #videoediting #contentcreation #hitpaw
1
3
148

14 Dec 2025
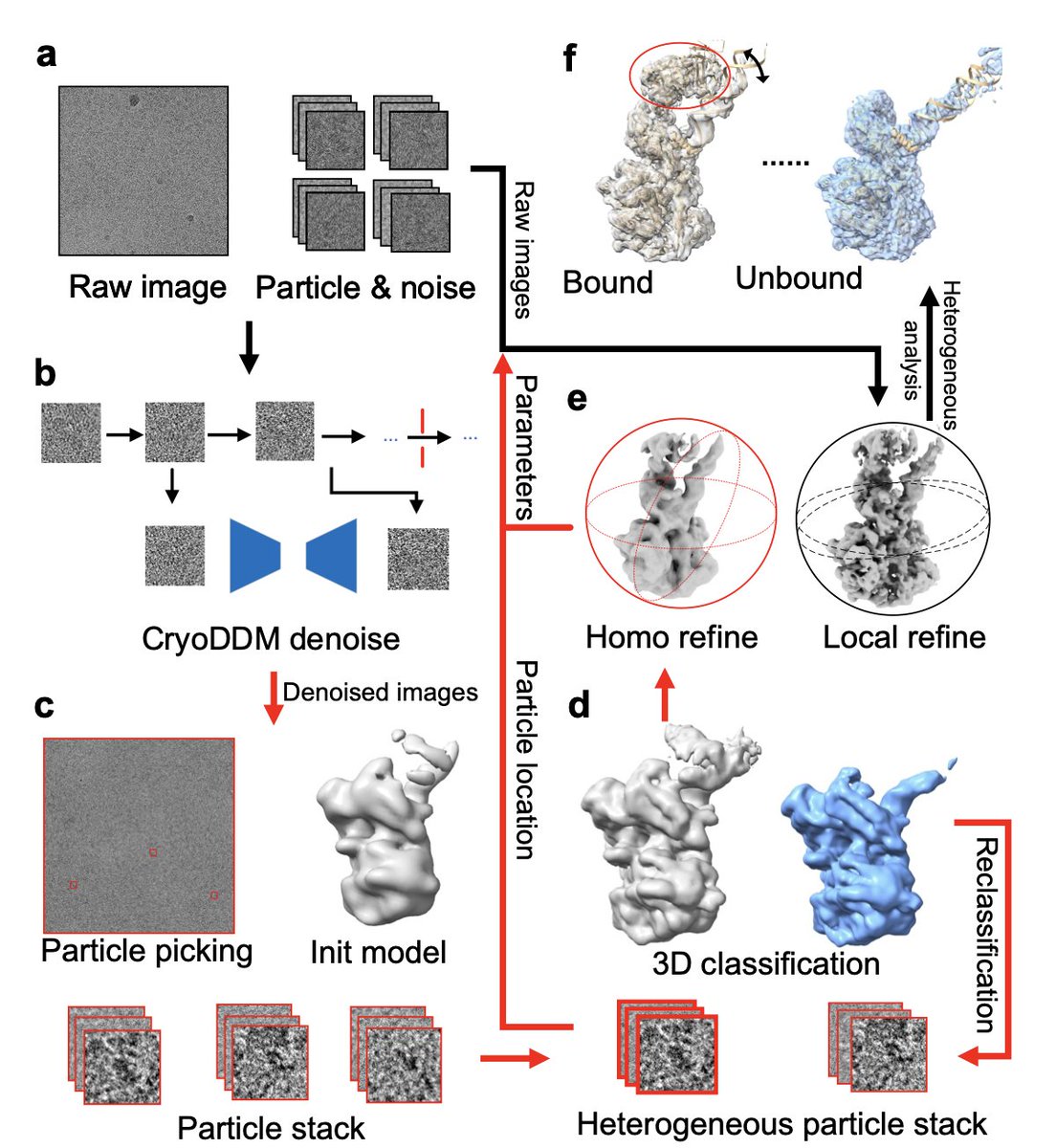
CryoDDM: CryoEM denoising diffusion model for heterogeneous conformational reconstruction
1. CryoDDM is a novel denoising diffusion model designed to enhance cryo-EM single-particle analysis by preserving high-frequency structural information while removing noise, significantly improving the accuracy of protein conformational heterogeneity classification and reconstruction.
2. The model introduces a two-phase diffusion process tailored for cryo-EM images, overcoming the limitations of Gaussian noise assumptions and reducing computational costs by optimizing diffusion steps.
3. CryoDDM outperforms existing methods by enabling high-resolution reconstruction of diverse proteins, including a proteasome, a membrane protein, and a spike protein, revealing previously undetected conformational states and motions.
4. The study demonstrates CryoDDM's ability to enhance downstream analysis, such as particle picking and 3D classification, by providing cleaner images without sacrificing structural details, thus advancing structural biology research.
5. CryoDDM's effectiveness is validated across multiple datasets, consistently showing superior performance in capturing dynamic protein behaviors and improving reconstruction quality, making it a valuable tool for cryo-EM studies.
📜Paper: biorxiv.org/content/10.64898…
#CryoEM #Denoising #DiffusionModel #ProteinStructure #CryoDDM #StructuralBiology
19
76
5,072

AI TEST 😀😀#AI #ArtificialIntelligence #MachineLearning #DeepLearning #NeuralNetworks #GenerativeAI #LLM #LargeLanguageModel #ChatGPT #Grok #xAI #OpenAI #AGI #ASI #NLP #NaturalLanguageProcessing #ComputerVision #ReinforcementLearning #SupervisedLearning #UnsupervisedLearning #Transformer #BERT #GPT #DiffusionModel #StableDiffusion #DALLE #Midjourney #Lora #FineTuning #PromptEngineering #RAG #VectorDatabase #Embedding #Token #ContextWindow #Hallucination #AIEthics #BiasInAI #ExplainableAI #XAI #Alignment #SuperAlignment #AutonomousAI #Robotics #AIArt #TextToImage #ImageGeneration #SyntheticData #Multimodal #ChainOfThought
1
2
2,004

僕のデータサイエンスの全11講座は基礎中の基礎なので,データサイエンス,深層学習で何かやりたい人は"絶対に必要な"内容なわけなのでやればいいだけなんだけど,
問題はその後の学習
やりたい内容によって勉強しなきゃいけないものがだいぶ変わってきます.
画像,動画,音声生成系なのか,3D gaussianやNeRF系なのか,ロボティクスなのかで必要な分野が違う.
さらにいうと,ロボティクスでも,強化学習なのか模倣学習で変わってくる.
多分全て横断的に必要なスキルはTransformerとDiffusionModel
だから僕の深層学習第三弾がおわったらTransformerとDiffusionModelをやると🙆♂️
って考えるとやはりこの辺りの後続講座を作るべきか悩む🤔
1
2
78
10,792

20 Nov 2025
シード値がランダムに与えられるAIベンダーのツール使ってたらそう見えるでしょうね。しかしDiffusionModelはその仕組み上、一意に中身取り出せるんですよ。
20 Nov 2025

さてはAI触ったことないなこの人。プロンプトが全く同じでも毎回違う画像が生成されるんだよ
1
1
6
2,932
19 Nov 2025
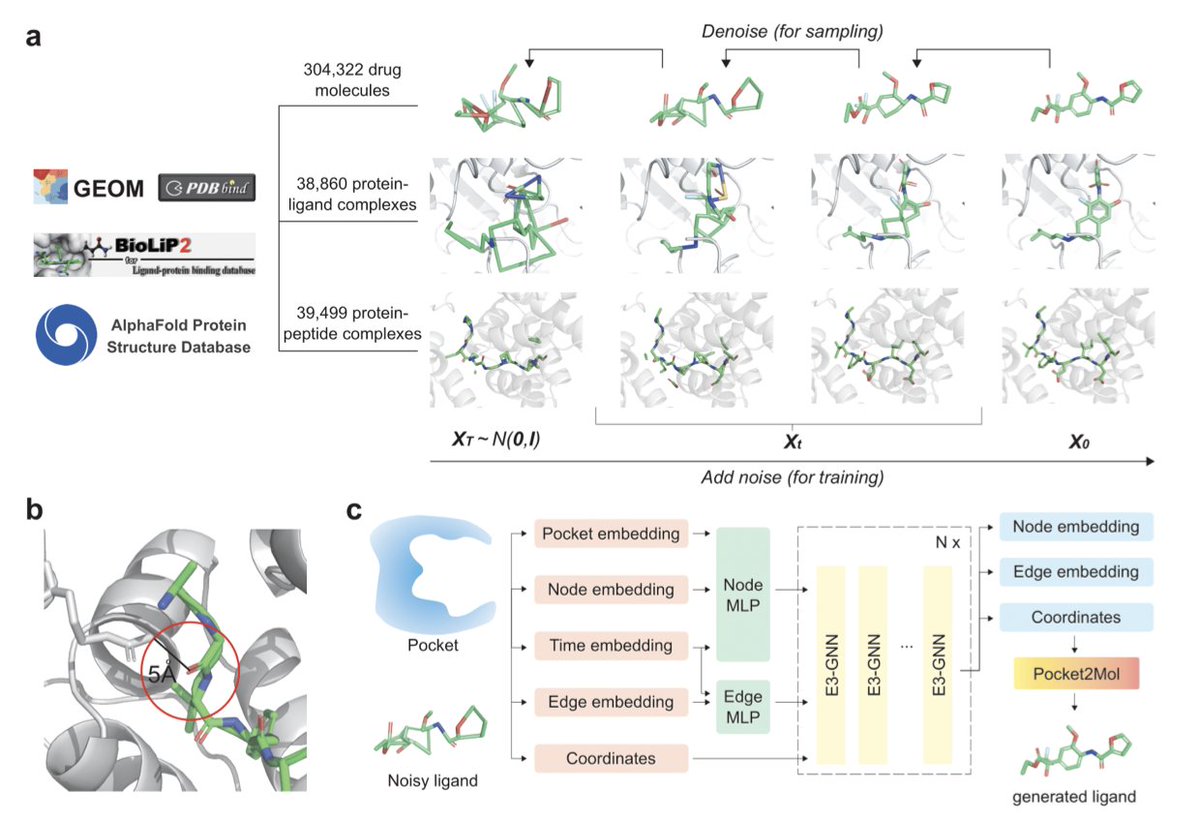
Peptide2Mol: A Diffusion Model for Generating Small Molecules as Peptide Mimics for Targeted Protein Binding
1. Peptide2Mol introduces a novel approach to generate small molecules that mimic peptide binders, leveraging an E(3)-equivariant graph neural network diffusion model. This innovation bridges the gap between peptides and small molecules in drug design, addressing limitations of traditional methods that often neglect peptide-protein interactions.
2. The model is trained on diverse datasets, including small-molecule conformation ensembles, protein-ligand complexes, and protein-peptide interactions. This comprehensive training enables Peptide2Mol to generate molecules that not only mimic peptide binding interactions but also maintain favorable drug-like properties.
3. Peptide2Mol achieves state-of-the-art performance in non-autoregressive generative tasks, producing molecules with high similarity to original peptide binders. The model also allows for partial diffusion processes to optimize molecules and design peptidomimetics, enhancing its practicality in drug discovery.
4. The study demonstrates that Peptide2Mol-generated molecules exhibit competitive chemical validity and plausibility, with improved performance on benchmarks such as PoseBusters when refined with a partially masked autoregressive step. This highlights the model's potential for generating structurally sound and dockable molecules.
5. Peptide2Mol's ability to identify preferred chemical groups for replacing amino acids provides valuable insights into residue-specific mimicry. This feature is crucial for transforming peptide binders into small molecules while preserving key binding interactions.
6. The authors suggest future directions, including coupling Peptide2Mol with physics-based simulations to assess stability and binding mechanisms beyond docking scores. This could further validate the model's applicability in drug design.
📜Paper: arxiv.org/abs/2511.04984v1
#Peptide2Mol #DrugDiscovery #AI #DiffusionModel #ProteinBinding #PeptideMimics
2
17
98
4,716


9 Nov 2025
You've seen AI turn words into art, but how does it really work?
Find out in Day 2 of our "AI Artist" series! 🤯
Watch Now: youtube.com/shorts/W6ViluF4U…
#AIart #TechnoLogic #AI #DiffusionModel #GenerativeArt #TechExplained

1
3
36